Perplexity Cannot Always Tell Right from Wrong
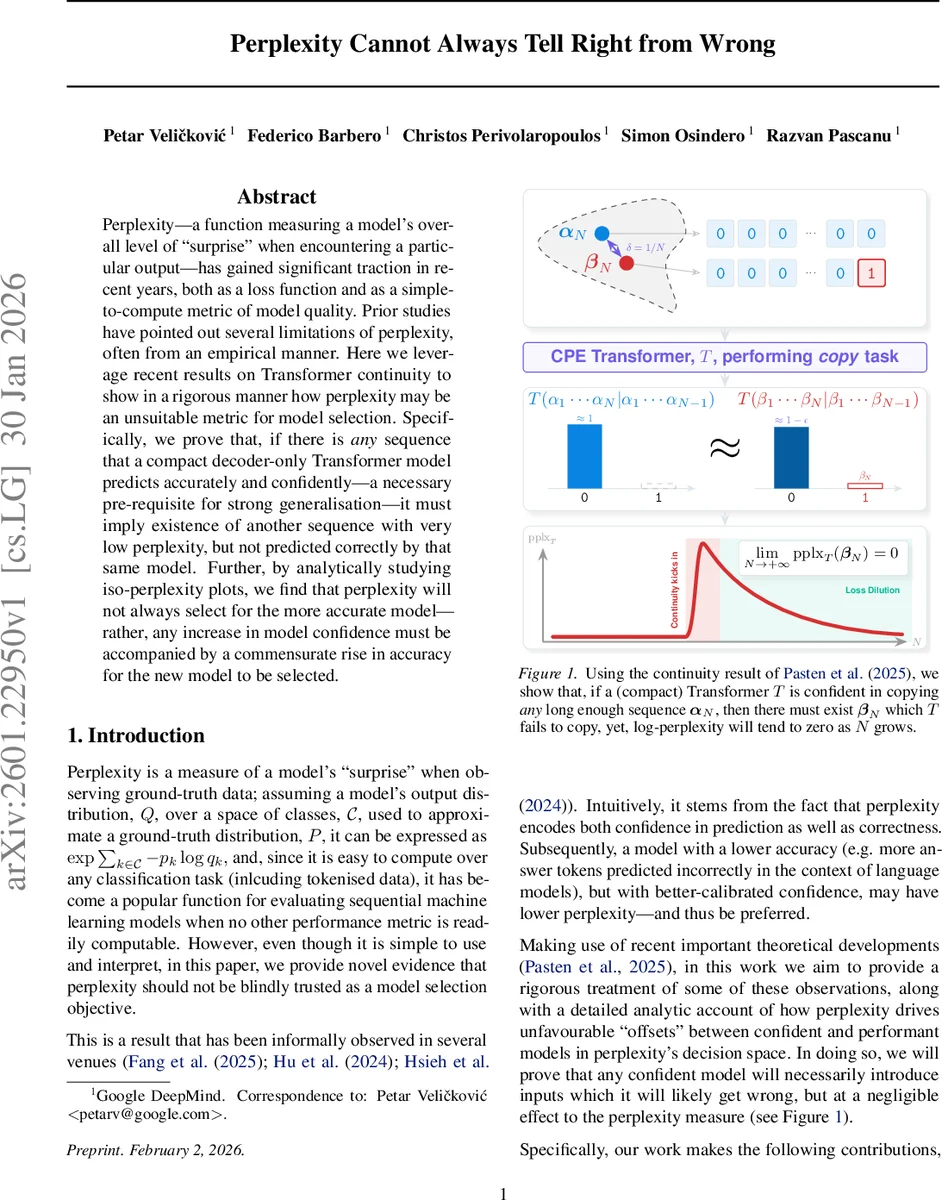
Perplexity – a function measuring a model’s overall level of “surprise” when encountering a particular output – has gained significant traction in recent years, both as a loss function and as a simple-to-compute metric of model quality. Prior studies have pointed out several limitations of perplexity, often from an empirical manner. Here we leverage recent results on Transformer continuity to show in a rigorous manner how perplexity may be an unsuitable metric for model selection. Specifically, we prove that, if there is any sequence that a compact decoder-only Transformer model predicts accurately and confidently – a necessary pre-requisite for strong generalisation – it must imply existence of another sequence with very low perplexity, but not predicted correctly by that same model. Further, by analytically studying iso-perplexity plots, we find that perplexity will not always select for the more accurate model – rather, any increase in model confidence must be accompanied by a commensurate rise in accuracy for the new model to be selected.
💡 Research Summary
The paper investigates a fundamental flaw in using perplexity as a sole metric for selecting language models, especially decoder‑only Transformers with compact positional embeddings (CPE). Perplexity, defined as the exponential of the average negative log‑likelihood, is attractive because it is easy to compute and interpret, but prior work has shown empirical mismatches between low perplexity and actual generation quality, long‑context performance, and calibration. This work provides a rigorous theoretical analysis that explains why perplexity can mislead model selection.
The authors build on the continuity results of Pasten et al. (2025), which show that a compact‑position‑embedding Transformer can model exactly one sequence from each infinite collection of sequences. Using the bit‑string copy task as a clean proxy, they prove Lemma 3.1: if a Transformer can correctly copy every finite prefix of an infinite sequence α with probability greater than ½ + ε, then for any small ξ there exists a length‑N prefix α_N and another sequence β_N such that the log‑perplexities of α_N and β_N differ by less than ξ, yet β_N is not copied correctly.
Proposition 3.2 strengthens this result by assuming the model copies α with high confidence (1 − γ). It shows that for any ε > 0 there exists a length N after which a sequence β_N exists whose perplexity is bounded by −log(1 − γ) + ε, even though the model fails to copy β_N. The corollary states that if γ = 0 (perfect confidence), then there is a family of β_N whose perplexity converges to zero while the model never copies them correctly. In other words, increasing confidence on some inputs inevitably creates “confounding” inputs that are wrong but have negligible impact on the perplexity score.
The paper extends the analysis to stochastic sampling (temperature > 0) by showing that temperature can be absorbed into an effective confidence level γ′, so the same conclusions hold. Using Boole’s inequality they bound the probability of any bit‑flip error by Nγ, demonstrating that when Nγ ≪ 1 the model behaves like the greedy case, while larger Nγ leads to substantial error probability but still negligible perplexity differences due to continuity.
A key learning‑dynamics implication is captured in Corollary 3.7: as the loss on the correctly copied sequence α_N approaches zero, the loss on the incorrect β_N also approaches zero, causing the gradient with respect to β_N to vanish. Consequently, the model receives almost no learning signal from the hard, mis‑predicted examples, making it difficult to improve on them during training.
Empirically, the authors train a small CPE Transformer on the copy task and also evaluate the 3.4 B‑parameter Gemma model. They set α_N = 0…0 and β_N = 0…01 and measure log‑perplexity, copying probability, and token‑level distributions as N grows. Both models exhibit the predicted behavior: the log‑perplexity gap between α_N and β_N shrinks to near zero, while the probability of correctly copying β_N collapses. The large model shows additional noise due to a richer vocabulary, but the overall trend matches the theory.
Finally, the paper introduces iso‑perplexity curves in the confidence‑accuracy plane. These curves delineate regions where a model’s increase in confidence is not accompanied by a commensurate rise in accuracy; models lying in this “unfavourable” region will be preferred by perplexity despite being less accurate. The authors observe that distribution shifts during training frequently push checkpoints into this region, explaining why perplexity‑driven model selection can favor inferior models in practice.
In conclusion, the work demonstrates that perplexity conflates confidence and correctness, and because of the continuity properties of compact‑position‑embedding Transformers, high confidence on some sequences inevitably creates low‑perplexity but incorrect sequences. Therefore, relying solely on perplexity for model selection is unsafe; practitioners should incorporate calibrated accuracy measures, calibration diagnostics, and robustness to distribution shift alongside perplexity. The paper provides both a rigorous theoretical foundation and empirical evidence for this claim.
Comments & Academic Discussion
Loading comments...
Leave a Comment