A Step Back: Prefix Importance Ratio Stabilizes Policy Optimization
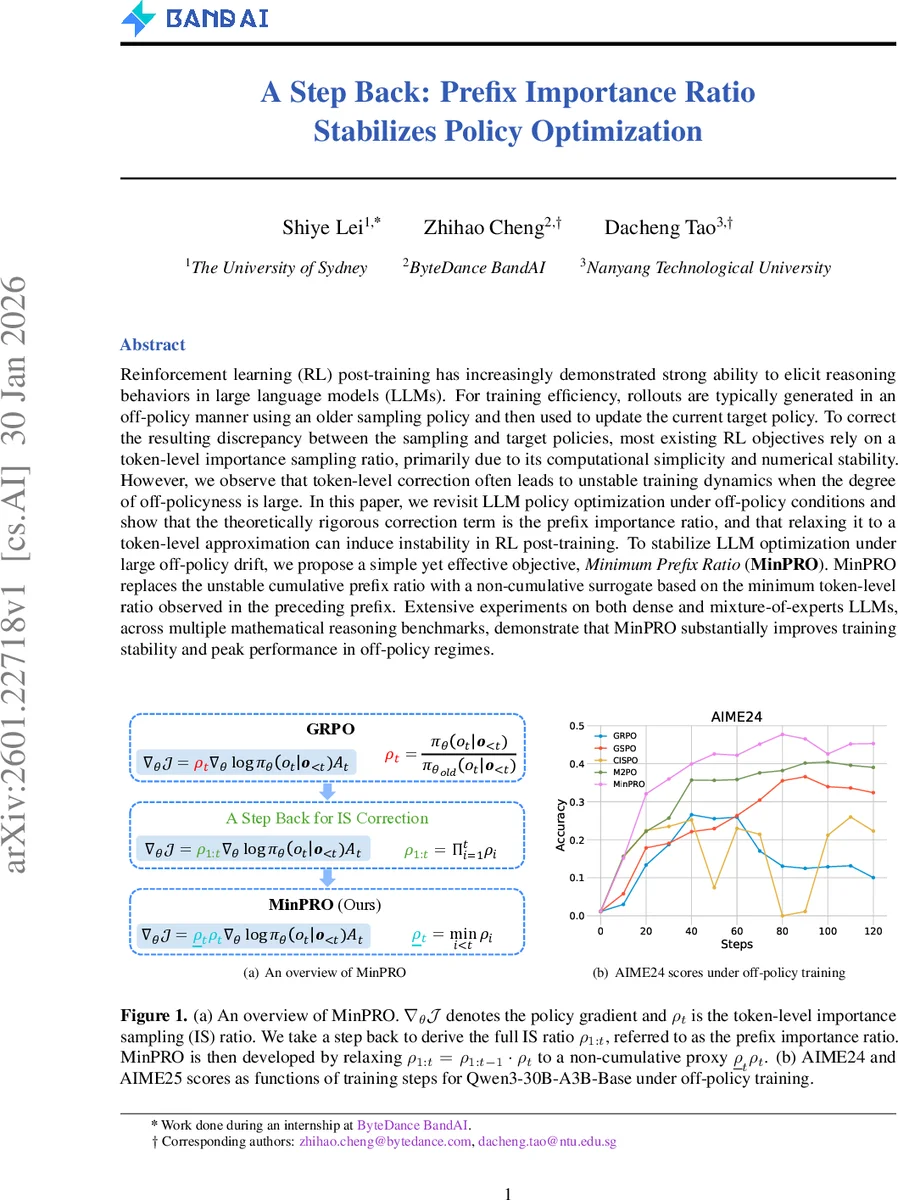
Reinforcement learning (RL) post-training has increasingly demonstrated strong ability to elicit reasoning behaviors in large language models (LLMs). For training efficiency, rollouts are typically generated in an off-policy manner using an older sampling policy and then used to update the current target policy. To correct the resulting discrepancy between the sampling and target policies, most existing RL objectives rely on a token-level importance sampling ratio, primarily due to its computational simplicity and numerical stability. However, we observe that token-level correction often leads to unstable training dynamics when the degree of off-policyness is large. In this paper, we revisit LLM policy optimization under off-policy conditions and show that the theoretically rigorous correction term is the prefix importance ratio, and that relaxing it to a token-level approximation can induce instability in RL post-training. To stabilize LLM optimization under large off-policy drift, we propose a simple yet effective objective, Minimum Prefix Ratio (MinPRO). MinPRO replaces the unstable cumulative prefix ratio with a non-cumulative surrogate based on the minimum token-level ratio observed in the preceding prefix. Extensive experiments on both dense and mixture-of-experts LLMs, across multiple mathematical reasoning benchmarks, demonstrate that MinPRO substantially improves training stability and peak performance in off-policy regimes.
💡 Research Summary
This paper investigates the instability that arises in reinforcement‑learning (RL) post‑training of large language models (LLMs) when rollouts are generated off‑policy—i.e., by an older “sampling” policy (π_old) and then used to update a newer target policy (π). While most recent LLM‑RL methods adopt the token‑level importance‑sampling (IS) ratio ρ_t = π(o_t | o_{<t}) / π_old(o_t | o_{<t}) because it is cheap and numerically stable, the authors show that this approximation is theoretically insufficient in the off‑policy regime. By re‑deriving the policy‑gradient theorem for off‑policy trajectories, they prove (Theorem 1) that the correct correction factor is the prefix importance ratio ρ_{1:t} = ∏_{i=1}^t ρ_i, which accounts for the entire prefix generated up to token t.
Using the full prefix ratio directly, however, is impractical: the product grows exponentially with sequence length, leading to extreme variance, numerical overflow/underflow, and a strong length bias that concentrates gradient magnitude on the tail of long generations (often >10 000 tokens). Consequently, methods that rely on ρ_t (e.g., GRPO, GSPO, CISPO, M2PO) exhibit severe oscillations, exploding entropy, and sometimes complete training collapse when the off‑policy lag is large.
To address these issues, the authors propose Minimum Prefix Ratio (MinPRO). Instead of the cumulative product, MinPRO computes a non‑cumulative surrogate: for each token t it multiplies the current token‑level ratio ρ_t by the smallest token‑level ratio observed earlier, ρ_min^{<t}=min_{i<t} ρ_i. The surrogate ρ̃_{1:t}=ρ_t·ρ_min^{<t} preserves the essential information that the prefix is unlikely under the current policy (when the minimum is tiny) while avoiding the exponential blow‑up of the full product. The final objective clips this surrogate with lower and upper bounds (ε_low, ε_high) and multiplies it by the advantage estimate, exactly as in standard PPO‑style formulations, but with the gradient stopped on the clipping term.
Empirically, the authors evaluate MinPRO on three LLM families: dense Qwen3‑8B‑Base, Qwen3‑14B‑Base, and a mixture‑of‑experts (MoE) Qwen3‑30B‑A3B‑Base. They simulate a heavy off‑policy regime by storing rollouts for two global steps before using them for updates, thereby creating a substantial policy lag. The models are fine‑tuned on a suite of mathematical reasoning benchmarks—AMC23, AIME24, AIME25, Math500, Olympiad, Minerva, and GSM8K. Baselines include GRPO (hard clipping), GSPO (full‑sequence IS), CISPO (soft clipping), and M2PO (dynamic clipping).
Key findings:
- Reward curves: MinPRO consistently yields higher average rewards across all models and datasets, with especially large gains on the hardest tasks (AIME24/25).
- Entropy stability: While baselines show erratic entropy spikes or collapses under off‑policy training, MinPRO maintains a smooth, moderate entropy trajectory, indicating stable exploration‑exploitation balance.
- Training robustness: Baselines frequently suffer from sudden reward drops and divergence, sometimes terminating training early. MinPRO’s training curves are monotonic or gently plateauing, never collapsing.
- MoE applicability: The method works equally well for the expert‑routing MoE model, suggesting that the minimum‑prefix surrogate mitigates additional variance introduced by dynamic routing.
The paper’s contributions are twofold: (1) a rigorous theoretical clarification that the prefix importance ratio is the correct off‑policy correction for autoregressive LLMs, and (2) a simple, computationally cheap surrogate (MinPRO) that captures the essential prefix information while eliminating the numerical pitfalls of the full product. The authors argue that MinPRO can be readily plugged into any existing PPO‑style LLM‑RL pipeline, offering immediate stability gains without extra hyper‑parameter tuning.
Future directions suggested include combining MinPRO with value‑function‑based critics, exploring alternative non‑cumulative statistics (e.g., median or trimmed mean of past ratios), and extending the analysis to other off‑policy RL settings such as offline RL or multi‑agent dialogue generation. Overall, the work provides a compelling solution to a practical bottleneck in large‑scale LLM reinforcement learning and is likely to become a standard component in future RL‑based LLM fine‑tuning toolkits.
Comments & Academic Discussion
Loading comments...
Leave a Comment