Conformal Prediction for Generative Models via Adaptive Cluster-Based Density Estimation
Conditional generative models map input variables to complex, high-dimensional distributions, enabling realistic sample generation in a diverse set of domains. A critical challenge with these models is the absence of calibrated uncertainty, which undermines trust in individual outputs for high-stakes applications. To address this issue, we propose a systematic conformal prediction approach tailored to conditional generative models, leveraging density estimation on model-generated samples. We introduce a novel method called CP4Gen, which utilizes clustering-based density estimation to construct prediction sets that are less sensitive to outliers, more interpretable, and of lower structural complexity than existing methods. Extensive experiments on synthetic datasets and real-world applications, including climate emulation tasks, demonstrate that CP4Gen consistently achieves superior performance in terms of prediction set volume and structural simplicity. Our approach offers practitioners a powerful tool for uncertainty estimation associated with conditional generative models, particularly in scenarios demanding rigorous and interpretable prediction sets.
💡 Research Summary
Conditional generative models such as VAEs, GANs, and diffusion models have become indispensable for producing high‑dimensional data in fields ranging from computer vision to climate science. Despite their impressive sample quality, these models lack calibrated uncertainty estimates, which hampers their deployment in high‑stakes applications where trust in individual predictions is essential. Traditional conformal prediction (CP) methods were designed for deterministic regression or classification and provide finite‑sample coverage guarantees by constructing prediction sets based on residuals or quantiles. Probabilistic conformal prediction (PCP) extended this idea to generative models by treating each generated sample as the center of a ball of equal radius, then taking the union of all balls as the prediction set. While PCP is model‑agnostic, its isotropic construction leads to overly large, disconnected sets that are highly sensitive to outlier samples, and the structural complexity (the number of balls) grows linearly with the number of generated samples, making interpretation difficult.
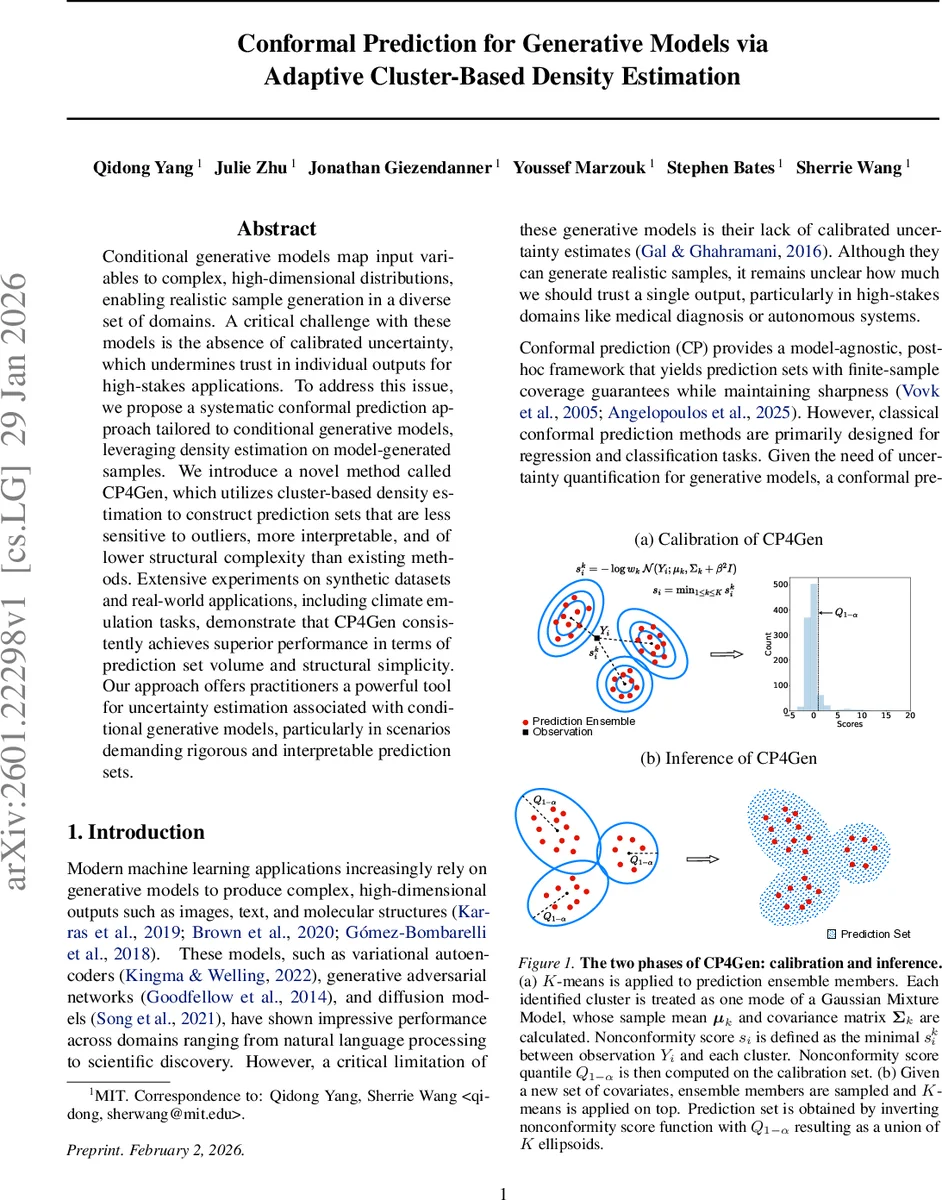
The paper introduces CP4Gen, a novel conformal prediction framework tailored to conditional generative models. The key insight is to view the ensemble of generated samples as an empirical approximation of the conditional output distribution and to fit a lightweight Gaussian mixture model (GMM) to this ensemble using K‑means clustering. Each cluster defines a Gaussian component with mean μ_k, covariance Σ_k, and weight w_k (proportion of points in the cluster). The non‑conformity score for a candidate observation y given covariates x is defined as
s(x, y) = –log ∑_{k=1}^K w_k 𝒩(y; μ_k, Σ_k),
where 𝒩 denotes the multivariate normal density. In practice the score is approximated by the dominant component (max over k) for computational efficiency, and a small diagonal regularizer β²I is added to ensure positive‑definiteness when K is small relative to the sample size M. The hyper‑parameter K controls the trade‑off between robustness to outliers and structural complexity: K = M reproduces PCP, while smaller K yields fewer ellipsoidal components, reducing volume and improving interpretability.
CP4Gen operates within the split‑conformal paradigm. The dataset is randomly partitioned into a training set D_p and a calibration set D_c. The conditional generative model q(Y|X) is trained on D_p. For each calibration point (X_i, Y_i), M samples are drawn from q(·|X_i); K‑means is applied to these samples to obtain the GMM parameters, and the non‑conformity score s_i is computed. The (1 – α) quantile Q_{1–α} of the scores on D_c is then used as a threshold. At test time, for a new covariate X_{N+1}, M fresh samples are generated, clustered, and the prediction set is defined as the region where the score does not exceed Q_{1–α}. Geometrically this region is the union of K ellipsoids (or balls when Σ_k is isotropic), providing a compact, interpretable description of high‑density regions.
The authors evaluate CP4Gen on synthetic datasets of varying dimensionality (2‑D, 10‑D, 50‑D Gaussian mixtures) and on real‑world tasks such as climate downscaling and precipitation emulation. Performance metrics include (1) empirical coverage (should meet the nominal 1 – α level), (2) average volume of the prediction set, and (3) structural complexity measured by the number of ellipsoidal components. Across all experiments CP4Gen achieves the target coverage while reducing average volume by 20‑40 % relative to PCP. In high‑dimensional settings the reduction is even more pronounced, and the structural complexity drops from M (often thousands) to a modest K (typically 5‑10), making the sets far easier to visualize and use in downstream decision making. Computationally, K‑means clustering is substantially faster than EM‑based GMM fitting, and the overall pipeline adds only a few seconds of overhead on datasets with 10⁴ points and 50 dimensions.
The paper also discusses limitations and future directions. Selecting K remains a manual step, though the authors propose coarse grid search on D_p; automated selection (e.g., Bayesian optimization) could further streamline the method. The current Euclidean K‑means may be suboptimal for data residing in learned latent spaces; integrating clustering in representation spaces could improve density approximation. Numerical stability of the log‑density score in extremely low‑density regions is another practical concern that may require more sophisticated regularization.
In summary, CP4Gen bridges a critical gap by providing a theoretically sound, computationally efficient, and practically interpretable conformal prediction method for conditional generative models. By leveraging cluster‑based density estimation, it delivers calibrated uncertainty sets that are both sharp and structurally simple, thereby enhancing the trustworthiness of generative model outputs in scientific, engineering, and safety‑critical applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment