Discovering Hidden Gems in Model Repositories
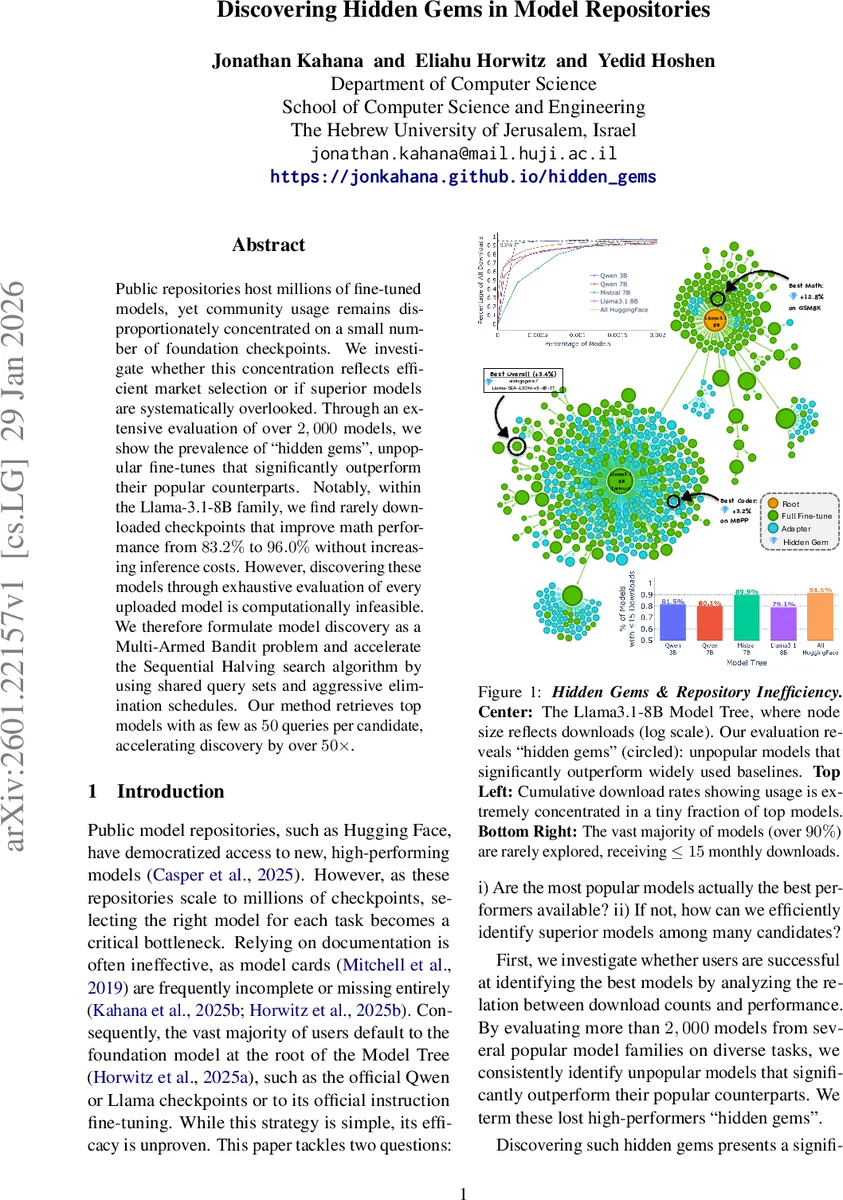
Public repositories host millions of fine-tuned models, yet community usage remains disproportionately concentrated on a small number of foundation checkpoints. We investigate whether this concentration reflects efficient market selection or if superior models are systematically overlooked. Through an extensive evaluation of over 2,000 models, we show the prevalence of “hidden gems”, unpopular fine-tunes that significantly outperform their popular counterparts. Notably, within the Llama-3.1-8B family, we find rarely downloaded checkpoints that improve math performance from 83.2% to 96.0% without increasing inference costs. However, discovering these models through exhaustive evaluation of every uploaded model is computationally infeasible. We therefore formulate model discovery as a Multi-Armed Bandit problem and accelerate the Sequential Halving search algorithm by using shared query sets and aggressive elimination schedules. Our method retrieves top models with as few as 50 queries per candidate, accelerating discovery by over 50x.
💡 Research Summary
The paper tackles the paradox that public model repositories such as Hugging Face host millions of fine‑tuned checkpoints, yet the community overwhelmingly uses a tiny fraction of foundation models. The authors ask two questions: (1) Do the most downloaded models actually represent the best performance? (2) If not, how can we efficiently discover superior “hidden‑gem” models among a massive candidate pool?
To answer (1), they evaluate over 2,000 fine‑tuned models drawn from four major model trees—Qwen‑2.5 (3B & 7B), Mistral‑7B, and Llama‑3.1‑8B—using a unified benchmark suite called RouterBench, which aggregates tasks such as MBPP, Winograd, MMLU, ARC‑Challenge, and GSM8K. All models are compared under identical inference cost, and only the fine‑tune itself is allowed to differ. They define a “Hidden Gem” as a model that (i) is not in the top‑1 % of download counts (obscure), (ii) lies in the top‑1 % of performance on a given task (elite), and (iii) strictly outperforms the best popular model. Their analysis shows that popularity is a poor proxy for quality: for example, an obscure Llama‑3.1‑8B checkpoint raises GSM8K accuracy from 83.2 % to 96.0 % without extra compute, and similar gains appear across the other trees. Over 90 % of the identified gems lack any performance documentation, explaining why users miss them.
Because exhaustive evaluation of every checkpoint would require billions of inference calls, the authors reformulate model discovery as a fixed‑budget best‑arm identification problem in the multi‑armed bandit (MAB) framework. The arms correspond to candidate models, each pull is a single query evaluation, and rewards are binary correctness signals. Their baseline is Sequential Halving (SH), which iteratively allocates a small budget, ranks models, and eliminates the bottom half. However, vanilla SH is sample‑inefficient for LLM evaluation.
The paper introduces two key modifications:
-
Correlated Sampling (Shared Query Sets) – In each round, all surviving models are evaluated on the exact same set of queries. This dramatically reduces variance in pairwise performance estimates, allowing reliable ranking with far fewer samples.
-
Aggressive Elimination Schedule – Observing that the majority of uploads are low‑quality, they prune the candidate pool dramatically in the first round, shrinking it to a fixed size of 100 models. The saved budget is then concentrated on discriminating among the elite survivors.
Experiments compare the proposed method against eight strong baselines (Uniform, UCB, UCB‑E, UCB‑StdDev, Successive Rejects, TTTS, Bayesian Elimination, and vanilla SH) under two query‑per‑model budgets: N = 10 (very low) and N = 50 (moderate). For each setting they repeat 100 runs and report mean rank and top‑1 accuracy. With N = 10, most baselines fail to beat the popular base models, while the proposed approach consistently retrieves a hidden gem within the top‑3 and achieves accuracies of 0.726–0.791. With N = 50, baselines improve modestly but still lag behind; the new method reaches mean ranks of 1–3 and accuracies of 0.729–0.796, representing more than a 50× speed‑up over exhaustive search.
Ablation studies confirm that both correlated sampling and aggressive pruning independently contribute to performance gains; removing either component degrades accuracy substantially.
The authors conclude that (i) public repositories contain a substantial number of high‑performing but under‑downloaded models, refuting the “efficient discovery” hypothesis, and (ii) a budget‑constrained, bandit‑based search with shared queries and early aggressive pruning offers a practical solution for discovering these hidden gems. They suggest future work on adaptive query selection, integration of model metadata, and deployment of the algorithm as an automated recommendation service within model hubs.
Comments & Academic Discussion
Loading comments...
Leave a Comment