ECO: Quantized Training without Full-Precision Master Weights
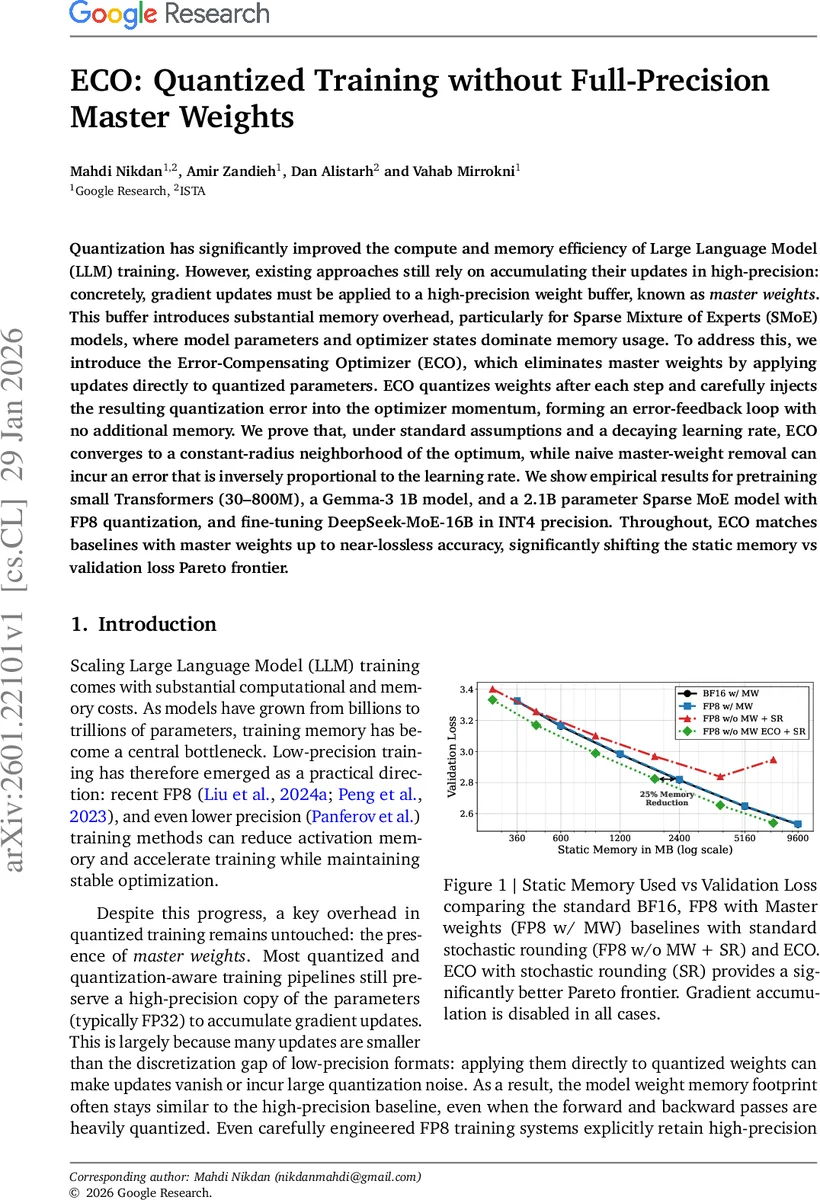
Quantization has significantly improved the compute and memory efficiency of Large Language Model (LLM) training. However, existing approaches still rely on accumulating their updates in high-precision: concretely, gradient updates must be applied to a high-precision weight buffer, known as $\textit{master weights}$. This buffer introduces substantial memory overhead, particularly for Sparse Mixture of Experts (SMoE) models, where model parameters and optimizer states dominate memory usage. To address this, we introduce the Error-Compensating Optimizer (ECO), which eliminates master weights by applying updates directly to quantized parameters. ECO quantizes weights after each step and carefully injects the resulting quantization error into the optimizer momentum, forming an error-feedback loop with no additional memory. We prove that, under standard assumptions and a decaying learning rate, ECO converges to a constant-radius neighborhood of the optimum, while naive master-weight removal can incur an error that is inversely proportional to the learning rate. We show empirical results for pretraining small Transformers (30-800M), a Gemma-3 1B model, and a 2.1B parameter Sparse MoE model with FP8 quantization, and fine-tuning DeepSeek-MoE-16B in INT4 precision. Throughout, ECO matches baselines with master weights up to near-lossless accuracy, significantly shifting the static memory vs validation loss Pareto frontier.
💡 Research Summary
The paper tackles a critical bottleneck in large‑scale language model training: the memory overhead of high‑precision “master weights” that are kept to accumulate gradient updates even when the forward and backward passes are heavily quantized. While low‑precision training (e.g., FP8, INT4) dramatically reduces activation memory and compute, the master‑weight copy—typically stored in FP32—remains a dominant component of the model’s static memory footprint, especially for Sparse Mixture‑of‑Experts (SMoE) architectures where only a subset of parameters is active per token but all master copies must reside in memory.
To eliminate this overhead, the authors introduce the Error‑Compensating Optimizer (ECO). The core idea is simple yet powerful: after each optimizer step, the updated high‑precision parameters are quantized back to the target low‑precision format, and the quantization error (the difference between the pre‑quantized and quantized tensors) is injected into the optimizer’s momentum buffer. This creates an error‑feedback loop that carries the “lost” update information forward to subsequent steps, allowing the optimizer to operate directly on quantized weights without any separate high‑precision accumulator.
Algorithmically, for SGD with momentum (SGDM) the procedure is:
- Compute a provisional high‑precision update ˜θₜ₊₁ = ˆθₜ – η·˜mₜ₊₁, where ˜mₜ₊₁ is the momentum‑updated buffer.
- Quantize ˜θₜ₊₁ to obtain the new low‑precision weight ˆθₜ₊₁ = q(˜θₜ₊₁).
- Compute the quantization error eₜ₊₁ = ˜θₜ₊₁ – ˆθₜ₊₁.
- Update the momentum buffer with the error: ˆmₜ₊₁ = ˜mₜ₊₁ + (1/η)(1 – 1/β)·eₜ₊₁, where β is the momentum coefficient.
For Adam, the same principle applies, but the scalar learning rate η is replaced by Adam’s element‑wise effective step size εₜ = η·(1–β₁)/(√(vₜ₊₁/(1–β₂)) + ε). The error is multiplied by this per‑parameter step size before being added to the first‑moment buffer. Crucially, the momentum (or first‑moment) buffer itself serves as the error storage, so no extra memory is required beyond what the optimizer already maintains.
The authors provide a rigorous convergence analysis under standard non‑convex L‑smooth assumptions and a decaying learning rate schedule. They prove that ECO converges to a neighborhood of a stationary point whose radius is only a factor 1/(1–β²) larger than the optimal bound achievable with full‑precision master weights. This bound is shown to be tight via a constructed quadratic example. In contrast, a naïve removal of master weights (i.e., applying updates directly to quantized weights without error injection) yields an error term that scales as 1/η, diverging as the learning rate decays to zero.
Empirically, the authors evaluate ECO across a spectrum of models and quantization precisions:
- Small Transformers (30 M–800 M parameters) trained with FP8.
- A 1 B‑parameter Gemma‑3 model pretrained in FP8.
- A 2.1 B‑parameter SMoE model pretrained in FP8.
- Fine‑tuning a 16 B‑parameter DeepSeek‑MoE model in INT4.
In all cases, ECO matches or nearly matches the validation loss of baselines that retain master weights (BF16 or FP8 with master weights). Moreover, static memory usage is reduced by up to 25 % because the master‑weight buffer is eliminated. The authors also demonstrate that combining ECO with stochastic rounding (SR) yields a markedly better memory‑vs‑loss Pareto frontier than FP8 with master weights or FP8 without master weights but with SR alone.
Overall, ECO offers a practical, drop‑in replacement for the master‑weight component of quantized training pipelines. It preserves convergence guarantees, incurs no extra hyper‑parameter tuning, and delivers substantial memory savings—particularly valuable for SMoE models where optimizer states already dominate memory consumption. The work opens avenues for hardware implementations that exploit the momentum buffer as an error‑feedback channel and for extending the technique to even lower‑bit formats (e.g., INT2) or to other optimizer families.
Comments & Academic Discussion
Loading comments...
Leave a Comment