MoE-ACT: Improving Surgical Imitation Learning Policies through Supervised Mixture-of-Experts
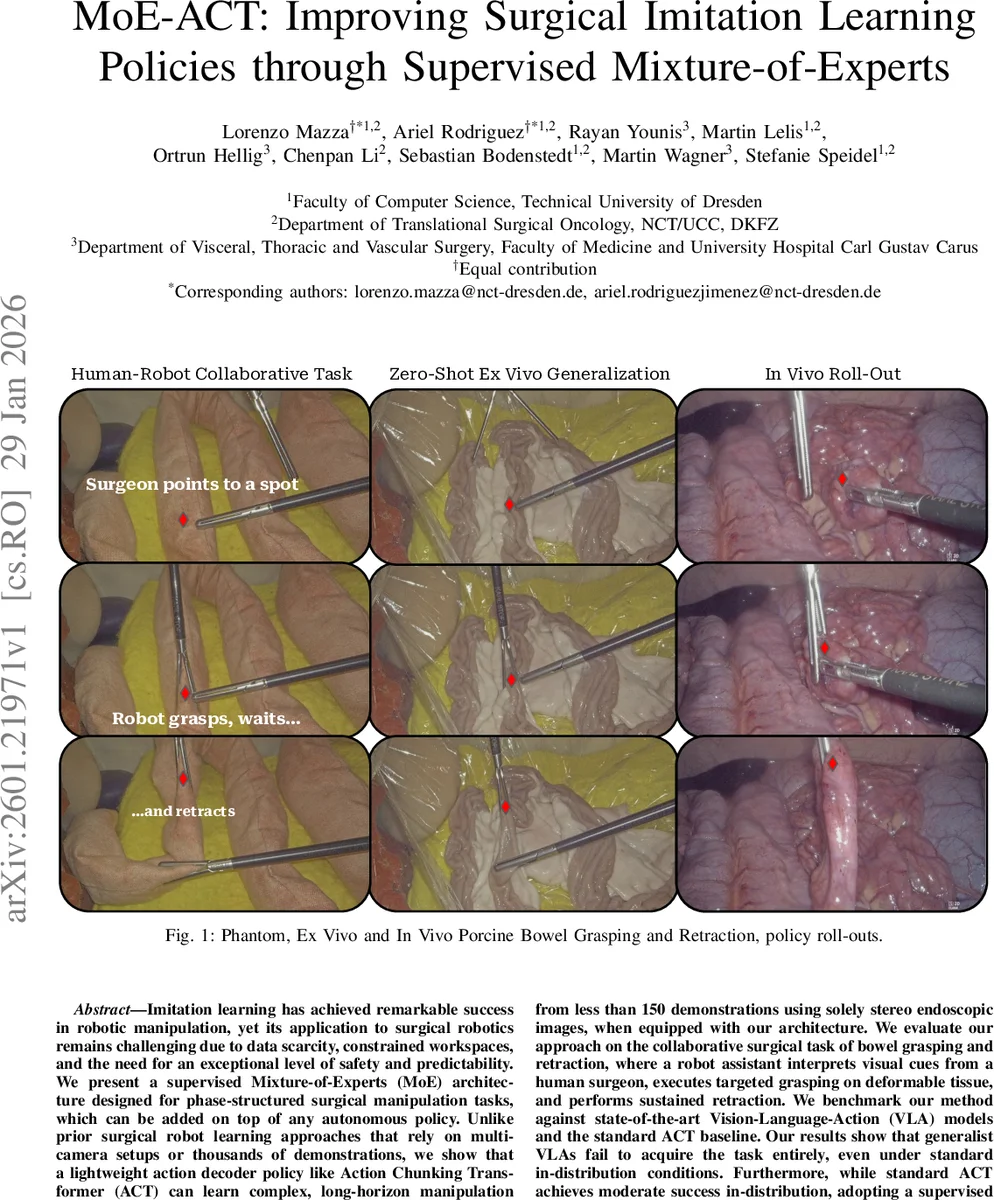
Imitation learning has achieved remarkable success in robotic manipulation, yet its application to surgical robotics remains challenging due to data scarcity, constrained workspaces, and the need for an exceptional level of safety and predictability. We present a supervised Mixture-of-Experts (MoE) architecture designed for phase-structured surgical manipulation tasks, which can be added on top of any autonomous policy. Unlike prior surgical robot learning approaches that rely on multi-camera setups or thousands of demonstrations, we show that a lightweight action decoder policy like Action Chunking Transformer (ACT) can learn complex, long-horizon manipulation from less than 150 demonstrations using solely stereo endoscopic images, when equipped with our architecture. We evaluate our approach on the collaborative surgical task of bowel grasping and retraction, where a robot assistant interprets visual cues from a human surgeon, executes targeted grasping on deformable tissue, and performs sustained retraction. We benchmark our method against state-of-the-art Vision-Language-Action (VLA) models and the standard ACT baseline. Our results show that generalist VLAs fail to acquire the task entirely, even under standard in-distribution conditions. Furthermore, while standard ACT achieves moderate success in-distribution, adopting a supervised MoE architecture significantly boosts its performance, yielding higher success rates in-distribution and demonstrating superior robustness in out-of-distribution scenarios, including novel grasp locations, reduced illumination, and partial occlusions. Notably, it generalizes to unseen testing viewpoints and also transfers zero-shot to ex vivo porcine tissue without additional training, offering a promising pathway toward in vivo deployment. To support this, we present qualitative preliminary results of policy roll-outs during in vivo porcine surgery.
💡 Research Summary
**
Imitation learning (IL) has become a powerful tool for teaching robots to perform complex manipulation tasks, yet its translation to minimally invasive surgery (MIS) remains difficult because of three intertwined constraints: (1) only a single endoscopic view is typically available, precluding multi‑camera or depth‑sensor setups; (2) clinical demonstration data are scarce—ethical, regulatory, and cost considerations limit the number of expert demonstrations to a few hundred at most; and (3) surgical policies must be lightweight, low‑latency, and extremely reliable. Large‑scale Vision‑Language‑Action (VLA) models, which have shown impressive general‑purpose performance in other domains, are ill‑suited for this setting: they contain hundreds of millions to billions of parameters, demand massive pre‑training datasets, and incur prohibitive inference latency on the embedded hardware used in the operating room.
The authors address these challenges by introducing a supervised Mixture‑of‑Experts (MoE) architecture that can be grafted onto any transformer‑based action‑chunking policy. They choose the Action Chunking Transformer (ACT) as the backbone because it is already lightweight (≈52 M parameters), operates on short action “chunks” (k consecutive timesteps), and has demonstrated strong performance on data‑limited surgical tasks. The key insight is that many surgical procedures are naturally phase‑structured: a sequence of well‑defined sub‑tasks (idle, approach & grasp, hold, retract, maintain) that can be identified from visual cues and instrument state. By supervising the MoE’s gating network with the true phase label during training, each expert is forced to specialize on a single phase, eliminating the mode‑collapse and expert‑underutilization problems that plague unsupervised MoEs.
Architecture details
- Observations: Stereo endoscopic image pair (I_left, I_right) only; proprioceptive data are deliberately omitted to keep the policy vision‑only and hardware‑agnostic.
- Latent variable: A variational encoder qϕ(z|a*) produces a Gaussian latent vector z that is concatenated with visual features before the transformer. During inference, z is set to the prior mean (0).
- MoE block: Consists of H = 5 parallel experts (one per phase). Each expert contains an action head that outputs mean parameters µ_h for the continuous Cartesian motion chunk and a gripper head that outputs logits ν_h for the binary gripper state. A gating network predicts a categorical distribution π over phases based on (z, visual features). The final action and gripper predictions are the weighted sums across experts: (\hat a = \sum_h π_h µ_h) and (\hat g = \sum_h π_h σ(ν_h)).
- Loss function: Four terms – (i) L1 reconstruction of the action chunk, (ii) cross‑entropy on the phase label (supervises the gating), (iii) binary cross‑entropy for the gripper, and (iv) KL divergence regularizing the variational posterior. This jointly optimizes accurate motion, correct phase identification, and a well‑behaved latent space.
Data collection
The experimental platform uses two UR5e arms: one holds a stereo TIPCAM1 S3D endoscope (fixed view) and the other carries a mechatronic laparoscopic grasper with remote‑center‑of‑motion constraints. A total of 120 demonstrations were recorded from a fixed viewpoint (the “fixed‑viewpoint dataset”) and 50 demonstrations with randomized camera angles (the “random‑viewpoint dataset”). Each demonstration is automatically segmented into the five phases using gripper state and instrument tip motion as proxies, providing the privileged phase labels needed for supervised MoE training. The authors also introduce variability in grasp locations, bowel pose, and initial tool positions to improve robustness.
Baselines
- ACT (plain, no MoE) – 52 M parameters.
- SmolVLA – a compact VLA model that consumes language instructions and a zero‑filled proprioceptive vector; 0.24 B parameters.
- π0.5 – a larger VLA with 4 B parameters, trained on a single A100 GPU.
All models are implemented in the open‑source LeRobot framework; training times are 3 h for ACT and ACT+MoE, 8 h for π0.5, and 14 h for SmolVLA.
Evaluation protocol
Two medical students and one surgical resident blindly reviewed each rollout and voted “success” if, at the final frame, the bowel segment was grasped by both graspers and retracted with sufficient tension. Success rates were measured under in‑distribution conditions (fixed viewpoint, same illumination) and four out‑of‑distribution (OOD) conditions: (i) novel grasp locations, (ii) severe illumination reduction, (iii) partial occlusions by simulated fat, and (iv) a slightly altered camera angle.
Results
- In‑distribution: ACT+MoE achieved ≈85 % success, plain ACT ≈62 %, while both VLA variants failed to complete the task (≈0 %).
- OOD: ACT+MoE maintained an average ≈78 % success across all four perturbations; plain ACT dropped to ~45 %, and VLA models fell below 20 %.
- Zero‑shot ex‑vivo transfer: When the same policy was applied to real porcine bowel (no additional training), ACT+MoE reached 80 % success, demonstrating robustness to domain shift in texture, lighting, and geometry. VLA models again failed.
- In‑vivo preliminary rollout: The authors present video of the policy operating on a live porcine surgery; qualitative observation shows stable grasping and retraction, though quantitative metrics are not reported.
Key contributions
- Supervised MoE for phase‑structured tasks – explicit phase supervision yields stable expert specialization and avoids typical MoE training pitfalls.
- Data‑efficient learning – fewer than 150 demonstrations suffice to master a multi‑step, deformable‑tissue manipulation task, a stark contrast to prior works requiring thousands of demos.
- Hardware‑friendly design – only a single stereo endoscope is needed; the model runs on a modest RTX A5000 GPU with low latency, suitable for intra‑operative deployment.
- Comprehensive empirical validation – systematic in‑distribution, OOD, zero‑shot ex‑vivo, and early in‑vivo tests illustrate robustness and generalization.
- Open resources – code and dataset will be released, encouraging reproducibility and further research.
Limitations and future work
- The approach relies on manual phase annotations during training; automating phase detection would reduce labeling effort.
- Safety guarantees are currently assessed only via human expert voting; formal verification or runtime safety monitors are needed for clinical adoption.
- The in‑vivo evaluation is limited to a few qualitative rollouts; large‑scale clinical trials are required to confirm efficacy and safety.
- Extending the framework to handle dynamic phase transitions (e.g., surgeon‑initiated interruptions) and integrating haptic feedback could further improve realism.
Conclusion
MoE‑ACT demonstrates that a carefully supervised mixture‑of‑experts, aligned with the natural phase structure of surgical procedures, can dramatically improve data efficiency, robustness, and generalization of imitation‑learned policies in minimally invasive surgery. By combining a lightweight transformer backbone with explicit phase gating, the method bridges the gap between research‑grade imitation learning and the stringent requirements of real‑world surgical robotics, opening a path toward autonomous or semi‑autonomous robot assistants that can reliably perform secondary but essential tasks such as tissue grasping and retraction. Future work should focus on automated phase labeling, formal safety verification, and extensive in‑vivo validation to bring this technology closer to clinical practice.
Comments & Academic Discussion
Loading comments...
Leave a Comment