Can David Beat Goliath? On Multi-Hop Reasoning with Resource-Constrained Agents
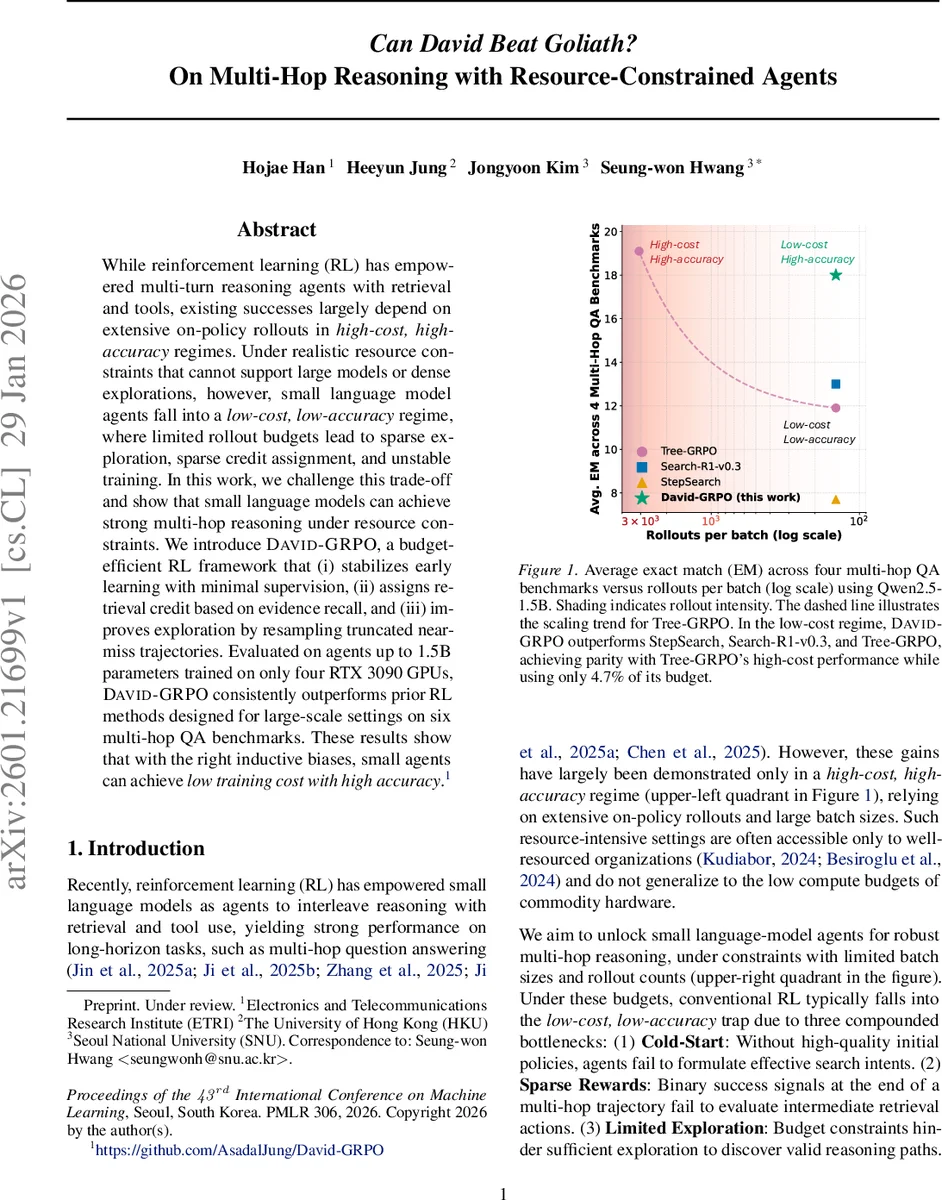
While reinforcement learning (RL) has empowered multi-turn reasoning agents with retrieval and tools, existing successes largely depend on extensive on-policy rollouts in high-cost, high-accuracy regimes. Under realistic resource constraints that cannot support large models or dense explorations, however, small language model agents fall into a low-cost, low-accuracy regime, where limited rollout budgets lead to sparse exploration, sparse credit assignment, and unstable training. In this work, we challenge this trade-off and show that small language models can achieve strong multi-hop reasoning under resource constraints. We introduce DAVID-GRPO, a budget-efficient RL framework that (i) stabilizes early learning with minimal supervision, (ii) assigns retrieval credit based on evidence recall, and (iii) improves exploration by resampling truncated near-miss trajectories. Evaluated on agents up to 1.5B parameters trained on only four RTX 3090 GPUs, DAVID-GRPO consistently outperforms prior RL methods designed for large-scale settings on six multi-hop QA benchmarks. These results show that with the right inductive biases, small agents can achieve low training cost with high accuracy.
💡 Research Summary
**
The paper tackles a pressing problem in reinforcement‑learning (RL) based multi‑hop question answering (QA): existing successes rely on large language models (LLMs) and massive on‑policy rollouts, which demand high compute budgets that are unavailable to most practitioners. Small language‑model agents, when trained under realistic resource constraints (limited GPU memory, few rollouts per batch), fall into a low‑cost/low‑accuracy regime characterized by three intertwined challenges: (1) cold‑start, where the policy has no useful priors and quickly collapses; (2) sparse rewards, because only the final answer is typically rewarded, leaving intermediate retrieval actions uncredited; and (3) limited exploration, as the vast search space makes high‑reward trajectories extremely rare under a tight rollout budget.
To overcome these bottlenecks, the authors introduce DAVID‑GRPO, a budget‑efficient RL framework that injects three inductive biases inspired by classic information‑retrieval (IR) techniques:
-
Few‑shot warm‑start – Instead of requiring thousands of annotated multi‑step trajectories (as in prior “behavior‑cloning” approaches), DAVID‑GRPO uses a tiny set of expert demonstrations (k ≪ |X_train|, often only a few dozen). These expert trajectories are treated as off‑policy samples and mixed with on‑policy rollouts in the Group‑Relative Policy Optimization (GRPO) objective. An off‑policy importance weight ρ* and a dedicated advantage term ensure that the agent receives strong gradient signals early on, preventing collapse while still allowing it to discover novel high‑reward paths.
-
Grounded retrieval reward (r_g) – The authors recognize that rewarding only the final answer (r_o) is insufficient for multi‑hop reasoning. They define a cumulative retrieved set D_union as the union of all documents fetched across the trajectory (excluding the final answer step). The grounded retrieval reward is the recall of the gold evidence set D* within D_union: r_g = |D_union ∩ D*| / |D*|. This dense, set‑based reward is noise‑free compared with lexical‑similarity heuristics and explicitly credits intermediate “bridge” documents that are essential for multi‑hop reasoning. The total reward is a weighted sum R = λ r_g + (1 − λ) r_o.
-
Grounded expansion – When the rollout budget is tight, many sampled groups contain only sub‑optimal trajectories, which leads to unstable advantage estimates in GRPO. Grounded expansion dynamically rescues partially successful trajectories: it identifies trajectories that have retrieved some correct evidence, extracts their intermediate states, and re‑samples new rollouts conditioned on those states. This near‑miss resampling dramatically increases the probability of discovering full‑evidence trajectories without expanding the overall budget.
The method is evaluated on six multi‑hop QA benchmarks (including HotpotQA, MuSiQue, ComplexWebQuestions, WikiHop, and OpenBookQA). Experiments use a 1.5 B parameter Qwen2.5 model trained on only four RTX 3090 GPUs (≈48 GB total) and a modest rollout budget (≈5 rollouts per batch). DAVID‑GRPO consistently outperforms prior large‑scale RL baselines such as Tree‑GRPO, StepSearch, and Search‑R1‑v0.3, achieving parity with the high‑cost regime of Tree‑GRPO while using only 4.7 % of its compute budget. Exact‑match scores improve by 4.7 %–12 % across datasets. Ablation studies confirm that each component contributes significantly: removing the warm‑start leads to early policy collapse, dropping r_g reduces final accuracy by 6 %–9 %, and disabling grounded expansion cuts exploration efficiency by roughly 15 %.
The paper’s contributions are threefold: (i) it demonstrates that small LMs can perform robust multi‑hop reasoning when equipped with appropriate RL inductive biases; (ii) it introduces a principled, set‑based retrieval reward that aligns RL objectives with the true evidence‑retrieval task; and (iii) it proposes a practical resampling strategy that leverages partial successes to mitigate the scarcity of high‑reward trajectories under tight budgets.
Limitations are acknowledged. The few‑shot warm‑start still requires expert trajectories, which in practice may come from a larger model or human annotation, so the approach is not completely annotation‑free. Moreover, the grounded retrieval reward assumes the availability of a gold evidence set D*; many real‑world scenarios lack such explicit annotations. Future work could explore automatic pseudo‑positive generation, self‑supervised evidence discovery, and scaling the method to even larger models or open‑domain settings where evidence is not pre‑specified.
In summary, “Can David Beat Goliath?” is answered affirmatively: with carefully designed RL mechanisms—few‑shot warm‑starting, evidence‑based dense rewards, and adaptive trajectory expansion—small language‑model agents can achieve high‑accuracy multi‑hop reasoning while operating under severe compute constraints. This work opens the door to more accessible, low‑cost QA systems and suggests a promising research direction for resource‑constrained RL in language understanding.
Comments & Academic Discussion
Loading comments...
Leave a Comment