HeRo-Q: A General Framework for Stable Low Bit Quantization via Hessian Conditioning
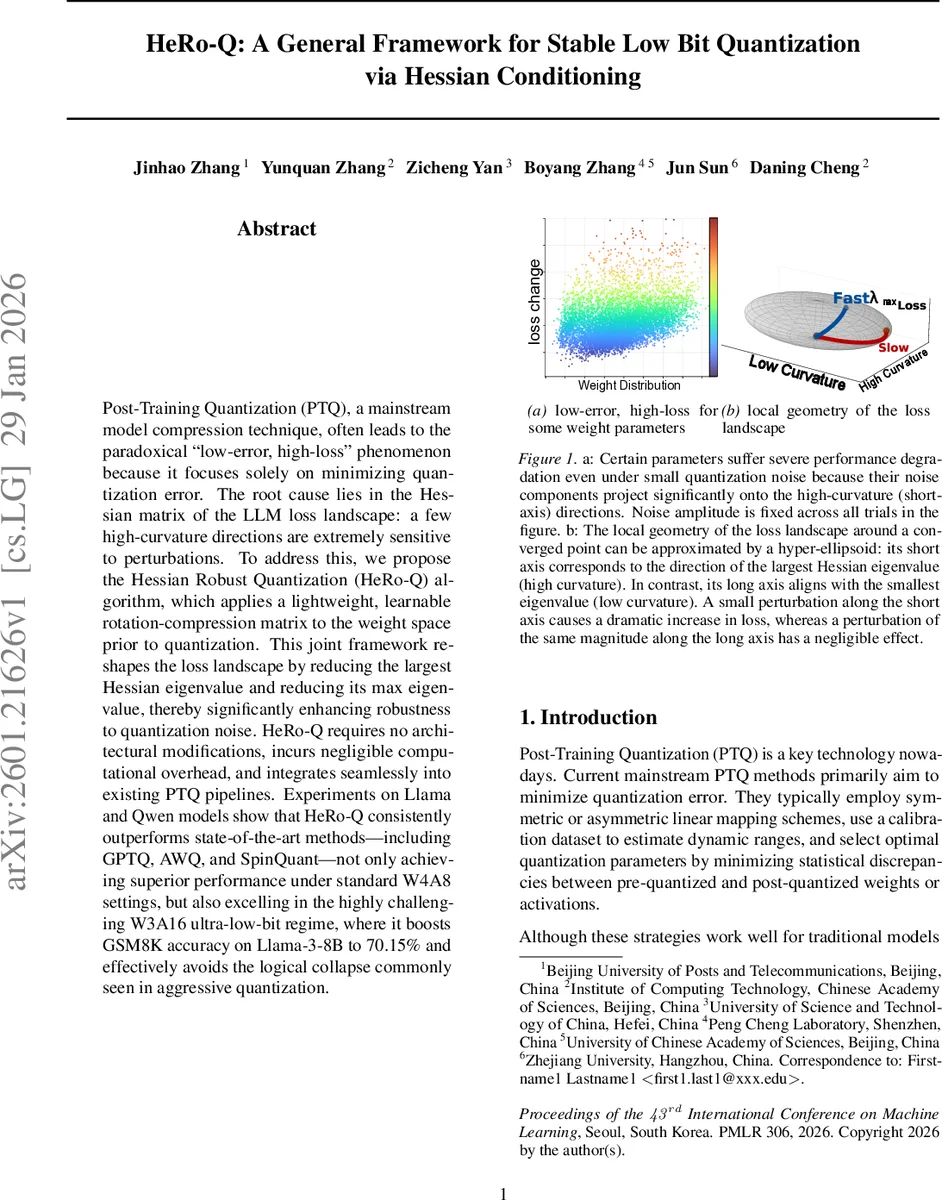
Post Training Quantization (PTQ), a mainstream model compression technique, often leads to the paradoxical ’low error, high loss’ phenomenon because it focuses solely on minimizing quantization error. The root cause lies in the Hessian matrix of the LLM loss landscape: a few high curvature directions are extremely sensitive to perturbations. To address this, we propose the Hessian Robust Quantization (HeRo Q) algorithm, which applies a lightweight, learnable rotation-compression matrix to the weight space prior to quantization. This joint framework reshapes the loss landscape by reducing the largest Hessian eigenvalue and reducing its max eigenvalue, thereby significantly enhancing robustness to quantization noise. HeRo-Q requires no architectural modifications, incurs negligible computational overhead, and integrates seamlessly into existing PTQ pipelines. Experiments on Llama and Qwen models show that HeRo Q consistently outperforms state of the art methods including GPTQ, AWQ, and SpinQuant not only achieving superior performance under standard W4A8 settings, but also excelling in the highly challenging W3A16 ultra low bit regime, where it boosts GSM8K accuracy on Llama3 8B to 70.15% and effectively avoids the logical collapse commonly seen in aggressive quantization.
💡 Research Summary
The paper tackles a persistent problem in post‑training quantization (PTQ) of large language models (LLMs): despite achieving very low overall quantization error, model performance can still degrade dramatically—a phenomenon the authors call “low‑error, high‑loss.” They attribute this paradox to the anisotropic nature of the Hessian of the loss landscape. In LLMs the Hessian spectrum is highly skewed: a few directions have extremely large eigenvalues (high curvature) while the majority are near‑zero (flat). Uniform quantization noise, even if small in norm, can project onto these high‑curvature directions and cause a large increase in loss.
To formalize the relationship, the authors derive a quadratic upper bound on loss change (Theorem 3.1):
ΔL ≤ ½ λ_max ‖δ‖² ≤ ½ ‖δ‖² B(α),
where δ is the quantization perturbation and B(α) is a spectral surrogate that depends on a smoothing hyper‑parameter α. This bound shows that when λ_max is huge, the loss is dominated by the Hessian’s curvature rather than the magnitude of the noise.
The proposed solution, Hessian Robust Quantization (HeRo‑Q), introduces a lightweight linear transformation T = D⁻¹_α R applied to the weight matrix before quantization. D_α is a diagonal scaling matrix whose entries are |H_ii|^{α/2}, effectively compressing large diagonal Hessian entries. R is an orthogonal rotation matrix (RᵀR = I) learned via the Cayley transform. The transformation simultaneously (i) reduces the spectral radius of the Hessian (by damping large diagonal entries) and (ii) redistributes quantization noise away from the most sensitive directions (by rotating the space). Theorem 3.2 proves that for any long‑tail Hessian there exists an α∈(0,1) such that B(α) < B(0), guaranteeing a strictly tighter loss bound after smoothing.
HeRo‑Q operates in three phases for each linear layer:
-
Statistics extraction – Using a calibration dataset, the diagonal of the Hessian (approximated by XᵀX where X are activation samples) is computed, yielding per‑channel sensitivity h.
-
Joint optimization – For each candidate α from a predefined grid, a diagonal matrix D_α is built. If the layer is “online” (e.g., KV‑cache), a fixed Hadamard rotation is used for speed. Otherwise, an orthogonal matrix R is learned by minimizing the reconstruction error ‖XW – X·Quant(T⁻¹W)‖_F via SGD on the Cayley‑parameterized S. The loss for each (α, R) pair is recorded.
-
Final quantization – The pair (α*, R*) achieving the lowest reconstruction error is selected. The optimal transform T* = D⁻¹_{α*} R* is applied, the weights are quantized with any standard PTQ method (GPTQ, RTN, etc.), and the inverse transform restores the quantized weights to the original space.
Computational overhead is minimal. D⁻¹_α can be folded into existing normalization layers, eliminating extra multiplications. The learned rotation R is fused offline into adjacent weight matrices (W←WR and W←RᵀW), preserving the original graph. For components where fusion is impossible, HeRo‑Q adopts the fast Walsh‑Hadamard Transform (FWHT) to implement online rotations efficiently, similar to SpinQuant.
Empirical evaluation spans several LLM families (Llama‑3‑8B, Llama‑3.2‑1B/3B, Qwen2.5‑3B/7B) and a suite of tasks: language modeling (C4, Wiki2), mathematical reasoning (GSM8K), commonsense reasoning (HellaSwag), and multitask understanding (MMLU). Quantization configurations include W4A4, W4A8, W4A16, and the ultra‑low‑bit W3A16. Key findings:
- Spectral shaping – HeRo‑Q consistently reduces the maximum Hessian eigenvalue by roughly 30‑40% and compresses the long tail of the spectrum, confirming the theoretical predictions.
- Accuracy gains – Under the challenging W3A16 regime, Llama‑3‑8B’s GSM8K accuracy jumps to 70.15%, surpassing GPTQ, AWQ, and SpinQuant, and avoiding the “logical collapse” where models produce nonsensical outputs. In more conventional W4A8 settings, HeRo‑Q yields 1.2‑1.5 percentage‑point improvements across benchmarks.
- Throughput – Because the transformation is merged into existing layers, inference speed improves by 5‑10% relative to baseline PTQ on identical hardware.
The paper’s contributions are threefold: (1) a rigorous theoretical link between Hessian eigenstructure and quantization‑induced loss, (2) a simple yet effective pre‑quantization transformation that requires only a single learnable matrix per layer, and (3) extensive experimental validation showing superior performance and negligible inference overhead.
Limitations include the need for a calibration set to estimate Hessian diagonals, which can be memory‑intensive for very large models, and the non‑convex joint optimization of α and R, which may be sensitive to initialization and grid granularity. Future work could explore low‑memory Hessian approximations, meta‑learning of α and R, and distributed training strategies to scale HeRo‑Q to multi‑billion‑parameter models.
Comments & Academic Discussion
Loading comments...
Leave a Comment