NEMO: Execution-Aware Optimization Modeling via Autonomous Coding Agents
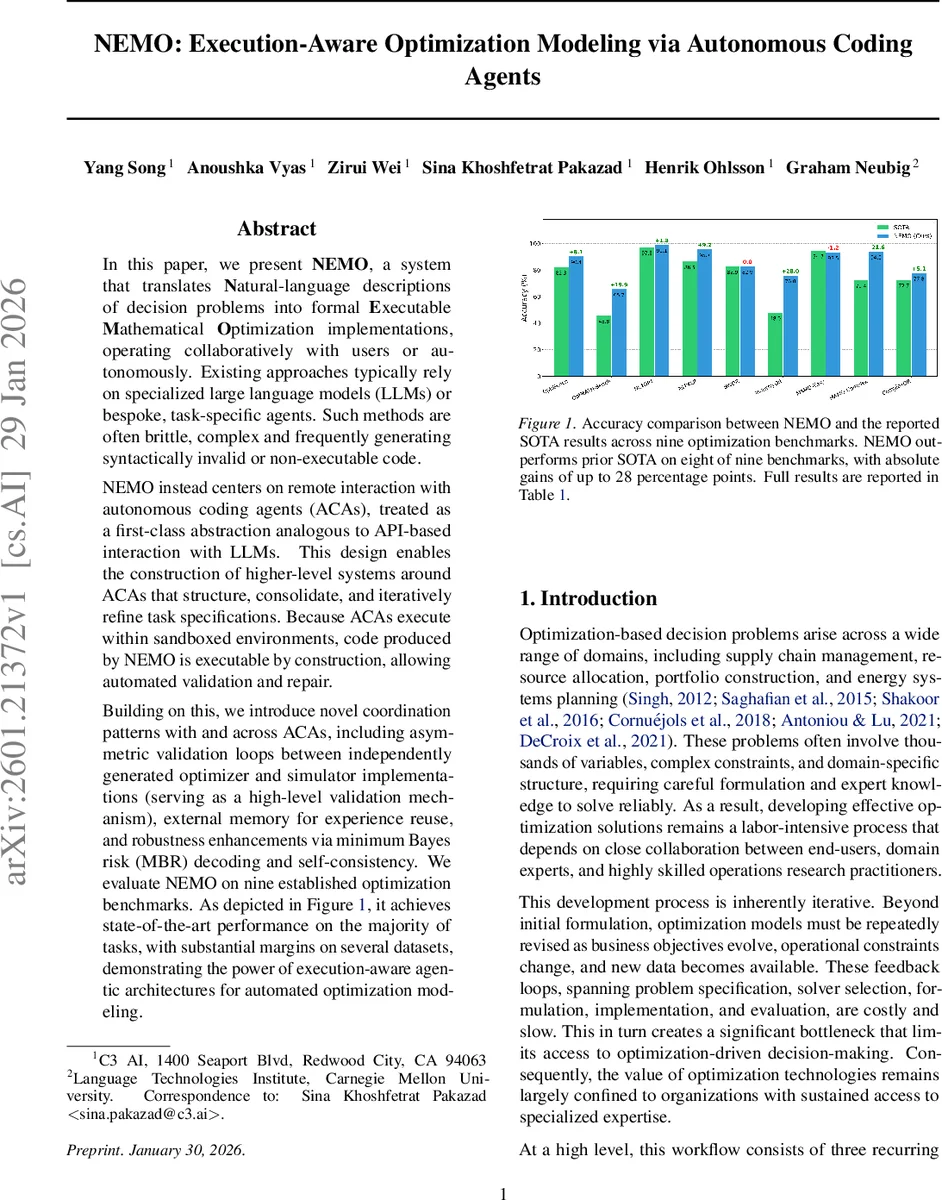
In this paper, we present NEMO, a system that translates Natural-language descriptions of decision problems into formal Executable Mathematical Optimization implementations, operating collaboratively with users or autonomously. Existing approaches typically rely on specialized large language models (LLMs) or bespoke, task-specific agents. Such methods are often brittle, complex and frequently generating syntactically invalid or non-executable code. NEMO instead centers on remote interaction with autonomous coding agents (ACAs), treated as a first-class abstraction analogous to API-based interaction with LLMs. This design enables the construction of higher-level systems around ACAs that structure, consolidate, and iteratively refine task specifications. Because ACAs execute within sandboxed environments, code produced by NEMO is executable by construction, allowing automated validation and repair. Building on this, we introduce novel coordination patterns with and across ACAs, including asymmetric validation loops between independently generated optimizer and simulator implementations (serving as a high-level validation mechanism), external memory for experience reuse, and robustness enhancements via minimum Bayes risk (MBR) decoding and self-consistency. We evaluate NEMO on nine established optimization benchmarks. As depicted in Figure 1, it achieves state-of-the-art performance on the majority of tasks, with substantial margins on several datasets, demonstrating the power of execution-aware agentic architectures for automated optimization modeling.
💡 Research Summary
NEMO (Execution‑Aware Optimization Modeling via Autonomous Coding Agents) is a system that automatically translates natural‑language descriptions of decision‑making problems into formally correct, executable mathematical optimization code. The authors identify two major shortcomings of prior work: (1) reliance on large language models (LLMs) that generate text‑only outputs, which frequently produce syntactically invalid or non‑executable code, and (2) the absence of a robust feedback loop between a simulator and an optimizer, which is essential for detecting logical inconsistencies in real‑world optimization pipelines.
To overcome these issues, NEMO introduces Autonomous Coding Agents (ACAs) as a first‑class abstraction analogous to an API call. An ACA runs in a sandboxed environment where it can generate code, execute it, inspect execution traces, and iteratively modify the implementation. This guarantees “executable‑by‑construction” code and enables immediate, execution‑based validation and repair. The system is built on top of OpenHands, but the ACA interface is deliberately platform‑agnostic.
The architecture consists of four coordinated modules:
-
Decision Process Extractor – Converts the natural‑language problem description (D) and a set of retrieved few‑shot examples (M*) into a structured decision process (P) containing variables, dynamics, objective, and constraints. Because reasoning LLMs are nondeterministic, the extractor employs a hybrid Minimum Bayes Risk (MBR) decoding strategy: it generates multiple candidate extractions, scores each candidate by component‑wise semantic similarity (using dense embeddings), aggregates scores with pre‑defined component weights, selects the top‑q candidates, and finally passes them to an LLM‑based logical verifier (LLM‑Judge) that checks mathematical consistency against the original description.
-
Solver Recommender – Takes the structured process P and a library of available solvers (SO) and produces a ranked list of suitable solvers with usage guidelines. The ranking is generated by a reasoning model that matches problem characteristics (e.g., linear vs. integer, presence of stochastic elements) to solver capabilities (MILP, CP, reinforcement‑learning based, etc.).
-
Simulator – Using P, the simulator ACA builds an executable model that can evaluate candidate decision variable assignments for feasibility and objective value. The simulator acts as a fixed reference implementation; it does not change during a single optimization run.
-
Optimizer – Generates the actual optimization code for the chosen solver. This module also uses MBR decoding and self‑consistency aggregation: multiple optimizer candidates are produced, a utility function based on execution success and alignment with the simulator’s outputs is computed, and the most reliable candidate is selected.
A key novelty is the asymmetric validation loop between the independent simulator and optimizer agents. After the optimizer produces a solution, the optimizer ACA executes it, and the resulting solution is fed to the simulator ACA for verification. If the simulator detects infeasibility, constraint violations, or objective mismatches, it returns a corrective signal that triggers another refinement cycle in the optimizer. This loop mimics the manual “simulator‑optimizer feedback” workflow used by professional operations‑research practitioners, but it is fully automated.
To improve few‑shot performance, NEMO incorporates an external memory bank built from 3,000 curated examples from the OptMATH dataset, covering 15 problem families (knapsack, scheduling, routing, facility location, etc.). Problem descriptions are embedded into a dense vector space; at inference time, the most similar examples are retrieved, and a diversity‑aware greedy selection (balancing relevance and redundancy) yields a compact set M* that guides both the extractor and optimizer.
Robustness is further enhanced by:
- Minimum Bayes Risk decoding – reduces nondeterminism in extraction and code generation.
- Self‑consistency aggregation – combines multiple independent ACA outputs to select the most consistent answer.
- External memory retrieval – provides diverse, high‑quality in‑context examples without over‑fitting to a single pattern.
Evaluation: The authors benchmark NEMO on nine established optimization tasks, including classic combinatorial problems (knapsack, job‑shop scheduling), network design, and resource allocation. Using only publicly available, pre‑2026 LLMs (no proprietary frontier models), NEMO achieves state‑of‑the‑art performance on eight benchmarks, with absolute accuracy gains ranging from 2 to 28 percentage points over the previously reported best results (SO‑TA). The remaining benchmark shows competitive performance. Ablation studies demonstrate that removing the simulator‑optimizer loop or the MBR decoding leads to substantial drops in accuracy, confirming the importance of each component.
Key insights and contributions:
- Treating code‑generating agents as execution‑capable services (ACAs) eliminates syntactic errors and enables systematic debugging.
- An asymmetric validation loop provides a principled, automated way to catch semantic modeling errors that pure LLM generation cannot.
- Hybrid MBR decoding plus self‑consistency yields stable, high‑quality structured outputs despite the inherent nondeterminism of LLMs.
- External memory‑based few‑shot learning supplies diverse problem patterns, improving generalization across heterogeneous optimization domains.
In summary, NEMO demonstrates that an execution‑aware, agentic architecture can bridge the gap between natural‑language problem statements and reliable, runnable optimization models. By combining sandboxed coding agents, asymmetric validation, and advanced decoding strategies, the system delivers robust, state‑of‑the‑art results while relying only on generic LLMs. This work opens a path toward democratizing optimization modeling, allowing users without deep OR expertise to obtain correct, executable models directly from textual specifications.
Comments & Academic Discussion
Loading comments...
Leave a Comment