Expected Improvement via Gradient Norms
Bayesian Optimization (BO) is a principled approach for optimizing expensive black-box functions, with Expected Improvement (EI) being one of the most widely used acquisition functions. Despite its empirical success, EI is known to be overly exploitative and can converge to suboptimal stationary points. We propose Expected Improvement via Gradient Norms (EI-GN), a novel acquisition function that applies the improvement principle to a gradient-aware auxiliary objective, thereby promoting sampling in regions that are both high-performing and approaching first-order stationarity. EI-GN relies on gradient observations used to learn gradient-enhanced surrogate models that enable principled gradient inference from function evaluations. We derive a tractable closed-form expression for EI-GN that allows efficient optimization and show that the proposed acquisition is consistent with the improvement-based acquisition framework. Empirical evaluations on standard BO benchmarks demonstrate that EI-GN yields consistent improvements against standard baselines. We further demonstrate applicability of EI-GN to control policy learning problems.
💡 Research Summary
Bayesian optimization (BO) is a powerful framework for optimizing expensive black‑box functions, and Expected Improvement (EI) is one of its most popular acquisition functions. However, EI is notoriously myopic: it concentrates acquisition mass around regions that already promise improvement and often collapses to near‑zero values over large portions of the search space. This behavior leads to over‑exploitation and can trap the optimizer in suboptimal stationary points, especially on multimodal or high‑dimensional problems.
The authors address this limitation by introducing a gradient‑aware auxiliary objective
g(x) = f(x) – α‖∇f(x)‖²,
where α ≥ 0 controls the strength of a soft penalty on the squared gradient norm. The intuition is that points satisfying first‑order optimality (∇f = 0) retain the original function value in g, while points with large gradients are penalized, encouraging the optimizer to move toward regions that are both high‑performing and close to stationarity.
Directly computing the Expected Improvement of g, denoted EI_g, is intractable because the improvement term couples the random function value and the random gradient norm. The authors apply a Positive Part Inequality to obtain a lower bound:
EI_g(x) ≥ EI_f(x) – α EI_s(x),
where EI_f is the standard EI on f and EI_s is an EI‑style term that measures expected reduction in the gradient norm. EI_s itself does not admit a closed form, so the authors develop a mean‑field approximation. They model f and each component of ∇f with independent Gaussian Processes (GPs), thus avoiding cross‑covariances and keeping computational complexity at O(N³). Using the Cholesky factor L of the gradient covariance Σ_∇(x), they rewrite the gradient as μ_∇(x) + Lz with z ∼ N(0, I). The squared norm becomes a non‑central chi‑square variable, and the truncation condition “‖∇f(x)‖² ≥ ‖∇f(x⁺)‖²” is approximated by an orthant constraint z ≥ z⁺ (element‑wise). This yields separable truncated moments and a closed‑form expression for an approximated EI_s, denoted EI_ŝ.
The practical acquisition function, called Expected Improvement via Gradient Norms (EI‑GN), is then defined as
EI‑GN(x) = EI_f(x) – α EI_ŝ(x).
Because EI_f is the familiar EI term, EI‑GN inherits the same exploration‑exploitation balance when the gradient penalty is inactive (α = 0). When EI_f becomes negligible, the second term dominates, steering the search toward points with smaller gradient norms even if the raw function value is not yet higher than the incumbent. This dual pathway—function improvement or stationarity improvement—provides acquisition signal in regions where standard EI would be flat.
Algorithmically, each BO iteration proceeds as follows: (1) fit a GP to observed function values, (2) fit independent GPs to each gradient component, (3) compute EI_f from the function GP, (4) compute the approximated EI_ŝ using the mean‑field formula, (5) maximize EI‑GN to obtain the next query point, (6) evaluate both f and ∇f at that point, and (7) augment the dataset. The authors present pseudocode (Algorithm 1) and discuss that the overall cost remains comparable to standard GP‑BO, with the additional gradient GP training being parallelizable.
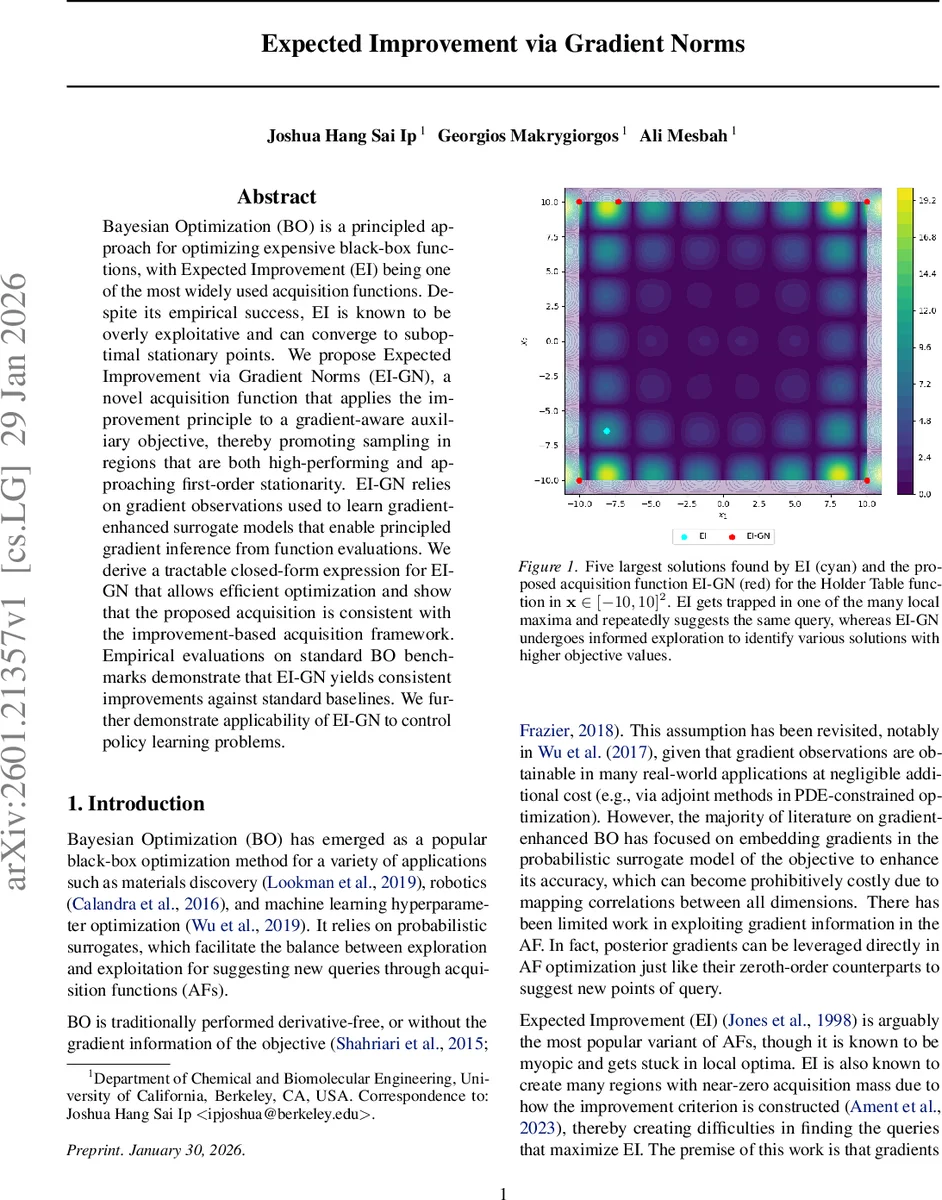
Empirical evaluation covers a suite of synthetic benchmarks (Holder Table, Shekel, Hartmann, Cosine, Griewank, Ackley) ranging from 4 to 14 dimensions, as well as control‑policy learning tasks (e.g., CartPole, Pendulum). Across all experiments, EI‑GN consistently outperforms standard EI, Probability of Improvement, Upper Confidence Bound, and recent gradient‑enhanced BO methods. The gains manifest as higher best‑found objective values, faster convergence, and more diverse sampling of promising basins. Visualizations (Figures 1–3) illustrate that EI‑GN produces multiple acquisition peaks, enabling it to escape local maxima that trap EI.
The paper’s contributions are fourfold: (i) a novel acquisition function that integrates gradient norm information into the EI framework, (ii) a theoretical lower‑bound derivation that yields a tractable closed‑form surrogate, (iii) an efficient implementation using independent GPs to keep computational overhead modest, and (iv) extensive experiments demonstrating consistent performance improvements and better exploration behavior.
Future work suggested includes adaptive tuning of the penalty weight α, extension to multi‑objective BO where several auxiliary criteria could be combined, incorporation of non‑Gaussian surrogate models (e.g., deep neural networks), and robustness analysis when gradient observations are noisy or expensive. Overall, EI‑GN offers a principled and practical way to mitigate EI’s over‑exploitation by leveraging readily available gradient information, thereby broadening the applicability of Bayesian optimization to problems where gradient data are accessible at low cost.
Comments & Academic Discussion
Loading comments...
Leave a Comment