Dynamical Adapter Fusion: Constructing A Global Adapter for Pre-Trained Model-based Class-Incremental Learning
Class-Incremental Learning (CIL) requires models to continuously acquire new classes without forgetting previously learned ones. A dominant paradigm involves freezing a pre-trained model and training lightweight, task-specific adapters. However, maintaining task-specific parameters hinders knowledge transfer and incurs high retrieval costs, while naive parameter fusion often leads to destructive interference and catastrophic forgetting. To address these challenges, we propose Dynamical Adapter Fusion (DAF) to construct a single robust global adapter. Grounded in the PAC-Bayes theorem, we derive a fusion mechanism that explicitly integrates three components: the optimized task-specific adapter parameters, the previous global adapter parameters, and the initialization parameters. We utilize the Taylor expansion of the loss function to derive the optimal fusion coefficients, dynamically achieving the best balance between stability and plasticity. Furthermore, we propose a Robust Initialization strategy to effectively capture global knowledge patterns. Experiments on multiple CIL benchmarks demonstrate that DAF achieves state-of-the-art (SOTA) performance.
💡 Research Summary
Class‑incremental learning (CIL) aims to continuously acquire new categories while preserving knowledge of previously learned ones. A prevailing approach freezes a large pre‑trained model (PTM) and fine‑tunes only lightweight adapters for each incremental task, which dramatically reduces computation and memory compared with training from scratch. However, most adapter‑based CIL methods keep a separate adapter for every task and retrieve the appropriate one at inference time. This design incurs growing storage, retrieval latency, and the risk of selecting an incorrect adapter, which can cause severe performance degradation.
The paper introduces Dynamical Adapter Fusion (DAF), a theoretically grounded framework that builds a single global adapter after each task, eliminating the need to store or retrieve historic adapters. The authors start from a PAC‑Bayes generalization bound that decomposes the expected risk into three terms: (1) empirical risk on the current task (plasticity), (2) a KL divergence between the task‑specific posterior and a robust initialization (generalization regularization), and (3) a KL divergence between the current global posterior and the previous global posterior (forgetting regularization). This decomposition explicitly shows that a good fusion must simultaneously minimize the current loss while staying close to both the initialization and the prior global state.
Guided by this bound, DAF fuses three parameter sets after each task: the optimized task‑specific adapter θ_t, the previous global adapter θ*{t‑1}, and a robust initialization θ_p. The fusion rule is
θ*{t}=β_t θ_p + β_t θ*{t‑1} + (1‑2β_t) θ_t,
where β_t is an element‑wise coefficient that balances stability and plasticity. Rather than fixing β_t heuristically (e.g., exponential moving average), the authors derive an optimal closed‑form expression for β_t by formulating a constrained optimization problem. They approximate the loss difference L(θ*{t})‑L(θ_t) with a second‑order Taylor expansion around θ_t, introduce a parameter shift Δθ = θ*{t}‑θ*{t‑1}+θ_t‑θ_p, and enforce the constraint Δθ + θ*{t‑1}+θ_p‑θ_t‑θ*{t}=0 via a Lagrange multiplier. Solving the resulting Lagrangian yields β_t as a function of the first‑ and second‑order loss derivatives (L′, L″) and the linear combination of the three parameter vectors. Consequently, β_t is recomputed dynamically for each task, automatically adapting to the data distribution and the magnitude of parameter changes.
A second contribution is the Robust Initialization strategy. Instead of using a naïve random or fixed initialization, DAF recursively aggregates past adapters (which are not stored explicitly) to form a prior θ_p that captures global knowledge patterns. This prior is incorporated into the fusion, anchoring the new global adapter to the accumulated experience and reducing drift.
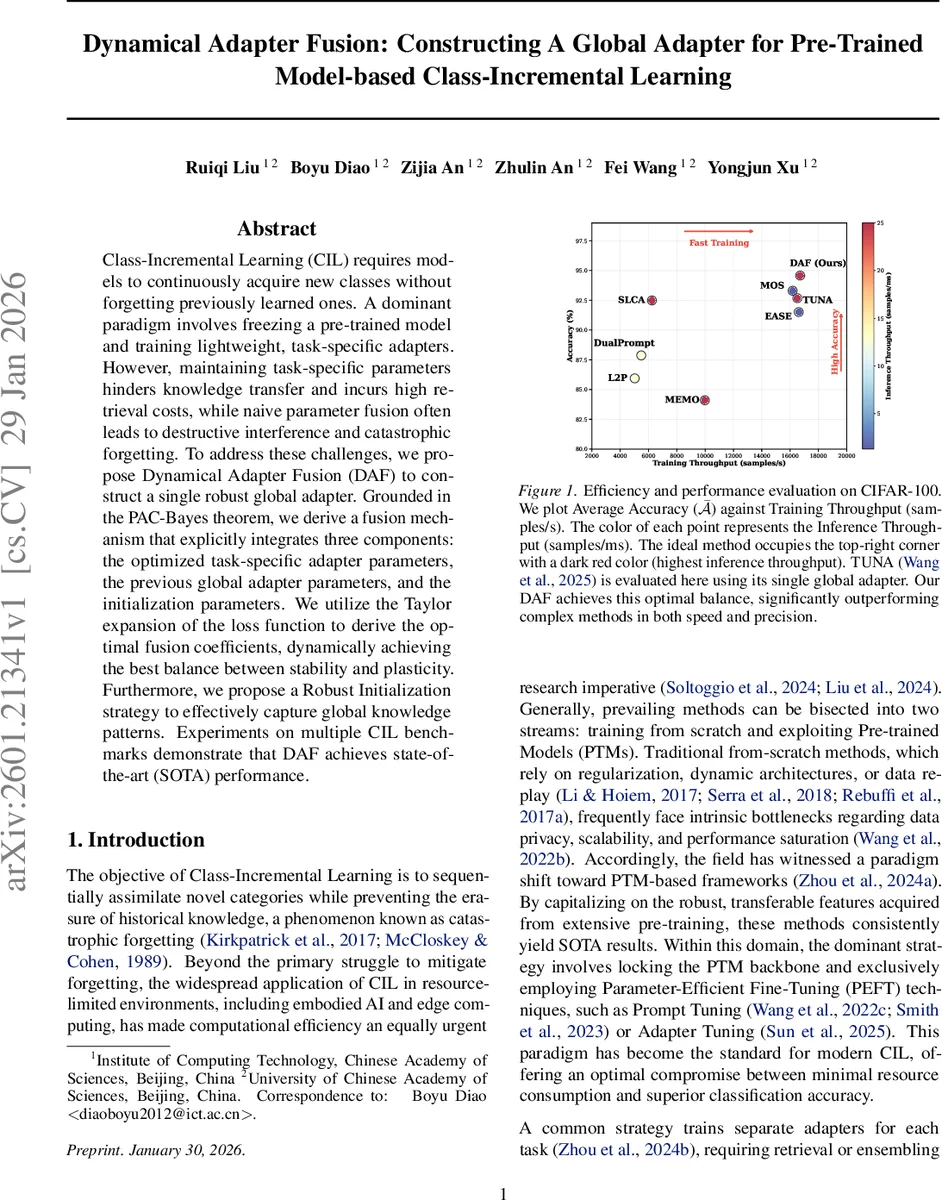
Experiments are conducted on several CIL benchmarks, including CIFAR‑100, ImageNet‑R, and multiple task splits (e.g., 10‑task, 20‑task). The evaluation measures average accuracy across all seen classes, training throughput (samples / second), and inference throughput (samples / millisecond). DAF consistently outperforms state‑of‑the‑art methods such as TUNA, MOS, and EMA‑based fusion, achieving 1.5 %–2.7 % absolute accuracy gains while delivering higher training and inference speeds. Figure 1 illustrates that DAF occupies the top‑right corner of the accuracy‑throughput trade‑off plot, indicating an optimal balance of performance and efficiency. Importantly, DAF stores only a single global adapter, so memory usage remains O(1) regardless of the number of tasks, and inference requires no task‑ID lookup, making it well‑suited for edge devices and real‑time applications.
In summary, the paper makes three key contributions: (1) a PAC‑Bayes‑derived risk decomposition that clarifies the stability‑plasticity dilemma in CIL, (2) a Lagrangian‑based derivation of optimal, dynamically computed fusion coefficients that integrate current, prior, and initialization parameters, and (3) a memory‑efficient robust initialization that captures historical knowledge without explicit storage. DAF thus provides a principled, efficient, and high‑performing solution for class‑incremental learning with pre‑trained models.
Comments & Academic Discussion
Loading comments...
Leave a Comment