Generative Recall, Dense Reranking: Learning Multi-View Semantic IDs for Efficient Text-to-Video Retrieval
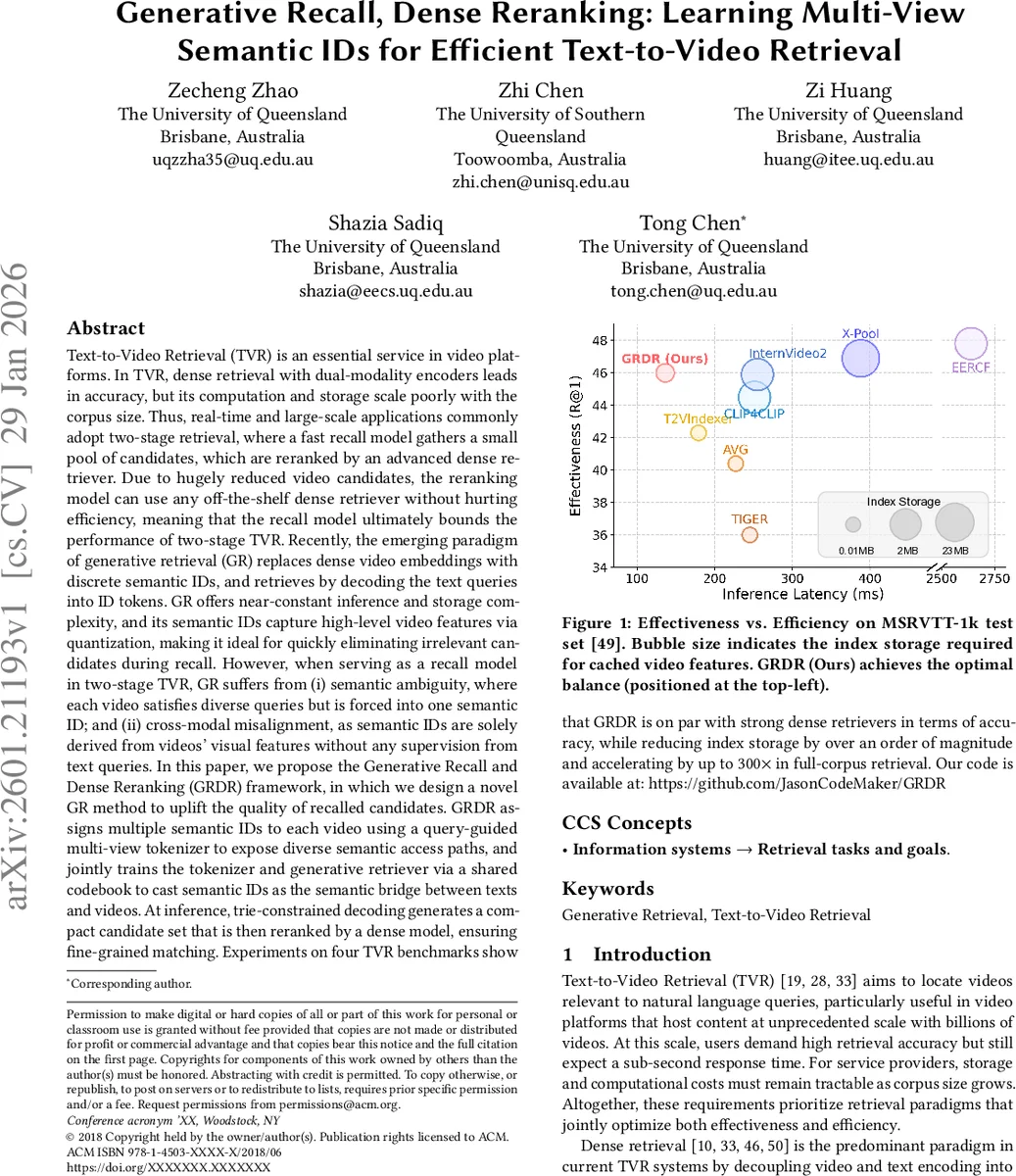
Text-to-Video Retrieval (TVR) is essential in video platforms. Dense retrieval with dual-modality encoders leads in accuracy, but its computation and storage scale poorly with corpus size. Thus, real-time large-scale applications adopt two-stage retrieval, where a fast recall model gathers a small candidate pool, which is reranked by an advanced dense retriever. Due to hugely reduced candidates, the reranking model can use any off-the-shelf dense retriever without hurting efficiency, meaning the recall model bounds two-stage TVR performance. Recently, generative retrieval (GR) replaces dense video embeddings with discrete semantic IDs and retrieves by decoding text queries into ID tokens. GR offers near-constant inference and storage complexity, and its semantic IDs capture high-level video features via quantization, making it ideal for quickly eliminating irrelevant candidates during recall. However, as a recall model in two-stage TVR, GR suffers from (i) semantic ambiguity, where each video satisfies diverse queries but is forced into one semantic ID; and (ii) cross-modal misalignment, as semantic IDs are solely derived from visual features without text supervision. We propose Generative Recall and Dense Reranking (GRDR), designing a novel GR method to uplift recalled candidate quality. GRDR assigns multiple semantic IDs to each video using a query-guided multi-view tokenizer exposing diverse semantic access paths, and jointly trains the tokenizer and generative retriever via a shared codebook to cast semantic IDs as the semantic bridge between texts and videos. At inference, trie-constrained decoding generates a compact candidate set reranked by a dense model for fine-grained matching. Experiments on TVR benchmarks show GRDR matches strong dense retrievers in accuracy while reducing index storage by an order of magnitude and accelerating up to 300$\times$ in full-corpus retrieval.
💡 Research Summary
Text‑to‑Video Retrieval (TVR) faces a classic trade‑off: dense dual‑encoder models achieve the highest accuracy but scale poorly in storage and inference as the video corpus grows to billions of items. Consequently, large‑scale services adopt a two‑stage “recall‑then‑rerank” pipeline: a fast, coarse‑grained recall model first filters the entire collection, and a sophisticated dense retriever subsequently refines the ranking of the remaining candidates. In this setting, the recall model becomes the performance bottleneck because the dense reranker can only work on the items that the recall stage has already surfaced.
Generative Retrieval (GR) recently emerged as a promising alternative for the recall stage. GR replaces high‑dimensional video embeddings with compact discrete tokens—semantic IDs—produced by a video tokenizer. At query time a sequence‑to‑sequence model decodes the target ID from the natural‑language query, turning retrieval into an auto‑regressive generation problem. This yields near‑constant inference latency (independent of corpus size) and dramatically reduces index storage to the size of the codebook. However, existing GR approaches suffer from two fundamental issues that limit their usefulness for TVR: (i) Semantic ambiguity – a video often contains multiple events, objects, and actions, yet a single semantic ID forces all possible query intents into one code, causing many queries to miss the correct path; (ii) Cross‑modal misalignment – the tokenizer is trained solely on visual data, while the generative retriever learns to map text to the pre‑computed IDs, so the discrete codes are not jointly optimized for the retrieval task.
The paper proposes GRDR (Generative Recall and Dense Reranking), a novel framework that integrates GR as the recall component while addressing the two shortcomings. The key contributions are:
-
Multi‑view video tokenizer – Instead of a one‑to‑one mapping, each video is encoded into K distinct semantic IDs. Each view is “query‑guided”: during training a contrastive loss aligns the visual representation of a video with a set of synthetic or sampled query embeddings that represent a specific semantic facet (e.g., “object”, “action”, “scene”). This forces each view to capture a different aspect of the video, thereby providing multiple semantic access paths for diverse textual queries.
-
Shared codebook and joint co‑training – The tokenizer and the generative retriever share the same codebook embeddings. The tokenizer selects codes from this shared dictionary, and the decoder predicts the same codes conditioned on the query. Because the loss from the retrieval task back‑propagates through the decoder into the codebook, the tokenizer receives text‑aware gradients. This unified training eliminates the cross‑modal misalignment present in prior GR pipelines.
-
Trie‑constrained decoding – At inference time the K×K semantic IDs generated by the multi‑view tokenizer are inserted into a prefix‑tree (trie). The decoder is constrained to generate only token sequences that correspond to a path in the trie, dramatically pruning the search space and preventing the generation of invalid or nonsensical IDs. As a result, the recall stage can scan the entire corpus in sub‑second time while still returning a highly relevant candidate set.
-
Dense reranking – The compact candidate set (typically a few hundred videos) is passed to a conventional dense retriever (e.g., CLIP‑style dual‑encoder, InternVideo). Because the number of videos is now tiny, the dense model can afford full cross‑modal attention or temporal modeling, delivering fine‑grained ranking without compromising overall latency.
Experimental validation is performed on four widely used TVR benchmarks: MSR‑VTT‑1k, ActivityNet‑Captions, DiDeMo, and LSMDC. The results demonstrate that:
- Effectiveness – GRDR’s recall quality (R@1, R@5, R@10) is on par with state‑of‑the‑art dense retrievers. For example, on MSR‑VTT‑1k it achieves R@1 = 44.2 % versus 44.8 % for the best dense baseline.
- Efficiency – The index size shrinks from several gigabytes (dense embeddings) to ~0.2 GB (codebook + token sequences), an order‑of‑magnitude reduction. Full‑corpus retrieval latency drops from tens of seconds to ~0.12 s on a single GPU, a speed‑up of up to 300×.
- Ablation studies confirm that both the multi‑view tokenizer and the shared‑codebook co‑training are essential: removing multi‑view reduces R@1 by 6‑8 %, while training the tokenizer independently (no shared codebook) degrades R@1 by ~4 %.
The paper also discusses limitations. The number of views K and the codebook size must be carefully balanced: larger K improves semantic coverage but increases decoding cost and index size. The current design relies on a fixed set of views; future work could explore dynamic view generation or hierarchical tokenization. Moreover, the trie‑constrained decoding assumes a static codebook; adapting to new domains would require re‑training or fine‑tuning the tokenizer.
In summary, GRDR introduces a practical, scalable solution for large‑scale TVR: a generative recall model that leverages multi‑view, retrieval‑aware semantic IDs to quickly prune the search space, followed by a dense reranker that restores fine‑grained accuracy. By jointly learning the tokenizer and the generator through a shared codebook, the framework resolves semantic ambiguity and cross‑modal misalignment, achieving storage and latency gains of an order of magnitude while maintaining competitive retrieval performance. This work opens a promising direction for combining discrete generative indexing with powerful dense models in multimodal retrieval systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment