FLARE: Agile Flights for Quadrotor Cable-Suspended Payload System via Reinforcement Learning
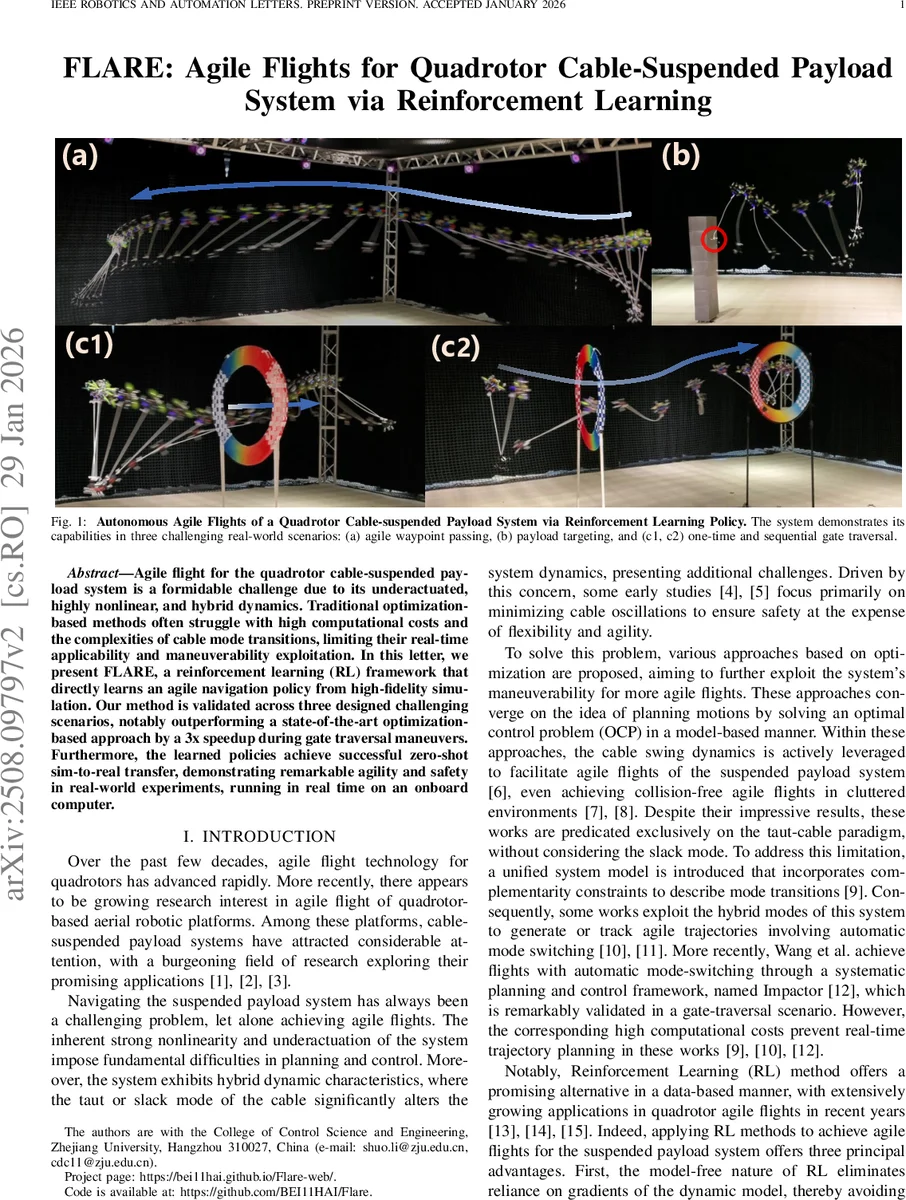
Agile flight for the quadrotor cable-suspended payload system is a formidable challenge due to its underactuated, highly nonlinear, and hybrid dynamics. Traditional optimization-based methods often struggle with high computational costs and the complexities of cable mode transitions, limiting their real-time applicability and maneuverability exploitation. In this letter, we present FLARE, a reinforcement learning (RL) framework that directly learns agile navigation policy from high-fidelity simulation. Our method is validated across three designed challenging scenarios, notably outperforming a state-of-the-art optimization-based approach by a 3x speedup during gate traversal maneuvers. Furthermore, the learned policies achieve successful zero-shot sim-to-real transfer, demonstrating remarkable agility and safety in real-world experiments, running in real time on an onboard computer.
💡 Research Summary
This paper introduces FLARE, a reinforcement‑learning (RL) framework that enables agile, real‑time flight of a quadrotor carrying a cable‑suspended payload. Traditional planning for such systems relies on model‑based optimal control, which assumes a taut cable, ignores the slack‑taut hybrid dynamics, and incurs high computational cost—making real‑time deployment infeasible. FLARE tackles these challenges by formulating the motion‑planning problem as an infinite‑horizon Markov Decision Process (MDP) and training a model‑free policy directly in a high‑fidelity simulator.
System Modeling and MDP Design
The state vector combines quadrotor kinematics (velocity and rotation matrix, 12 dimensions) and payload swing angles (ϕ, θ, 2 dimensions). This “general observation” is shared across all tasks. For each of three benchmark scenarios—(1) agile waypoint passing, (2) payload targeting, and (3) narrow‑gate traversal—additional task‑specific observations are appended (e.g., relative waypoint positions, gate center offsets). Actions are normalized collective thrust and body‑rate commands, later scaled to physical thrust and angular‑rate limits.
Reward Structure
A composite reward r = r_general + r_specific is used. The general component consists of:
- Safety (r_safe): penalizes payload deviation angles exceeding a preset threshold (ϕ_max), preventing propeller‑cable entanglement.
- Crash (r_crash): large negative reward and episode termination when the quadrotor or payload leaves the admissible workspace.
- Smoothness (r_smooth): L2 penalty on successive action differences, encouraging feasible control rates.
Scenario‑specific rewards encourage progress toward the immediate goal (distance reduction), and for the gate task, a two‑stage term that first guides the vehicle toward the gate (velocity projection onto the gate‑to‑waypoint vector) and then awards a large bonus upon successful passage.
Training Procedure
Policies are trained with Proximal Policy Optimization (PPO) using a multilayer perceptron (2 × 128 hidden units, tanh output). Input observations are normalized and concatenated with the previous action to preserve the Markov property. Domain randomization is applied: initial payload swing angles are varied within ±10°, and target/gate positions are uniformly sampled in a 3‑D volume each episode, ensuring robustness to real‑world variations.
Simulation is performed in Genesis, a GPU‑vectorized quadrotor simulator that models the cable as a serial chain of rigid links. With a 0.01 s integration step, the policies converge after 102 M (scenario 1), 123 M (scenario 2), and 252 M (scenario 3) timesteps—equivalent to only 0.45 h, 0.52 h, and 2.42 h of wall‑clock training time, respectively. This is orders of magnitude faster than solving an optimal control problem for each maneuver.
Results and Real‑World Validation
In simulation, FLARE achieves a three‑fold speedup over the state‑of‑the‑art optimization‑based method “Impaactor” during gate traversal, while maintaining comparable safety and smoothness metrics. The learned policies run onboard a modest embedded computer (e.g., Raspberry Pi 4) at >200 Hz, satisfying real‑time constraints. Crucially, zero‑shot sim‑to‑real transfer is demonstrated: the same policies, without any fine‑tuning, successfully execute the three tasks on a physical quadrotor‑payload platform, preserving the agility and safety observed in simulation.
Contributions and Implications
- A unified RL framework that directly handles the hybrid slack/taut dynamics of cable‑suspended payloads, eliminating the need for explicit mode‑switching optimization.
- Tailored observation and reward designs that enable three distinct high‑agility tasks while guaranteeing safety and smooth control.
- Empirical evidence that model‑free RL can outperform sophisticated model‑based planners in both speed and real‑time feasibility, and that policies trained in simulation can transfer to hardware without additional adaptation.
The work opens the door for extending RL‑based agile control to more complex scenarios such as multi‑payload transport, windy outdoor environments, and cooperative multi‑robot operations, where traditional optimal‑control pipelines would be prohibitively expensive or intractable.
Comments & Academic Discussion
Loading comments...
Leave a Comment