AnomalyVFM -- Transforming Vision Foundation Models into Zero-Shot Anomaly Detectors
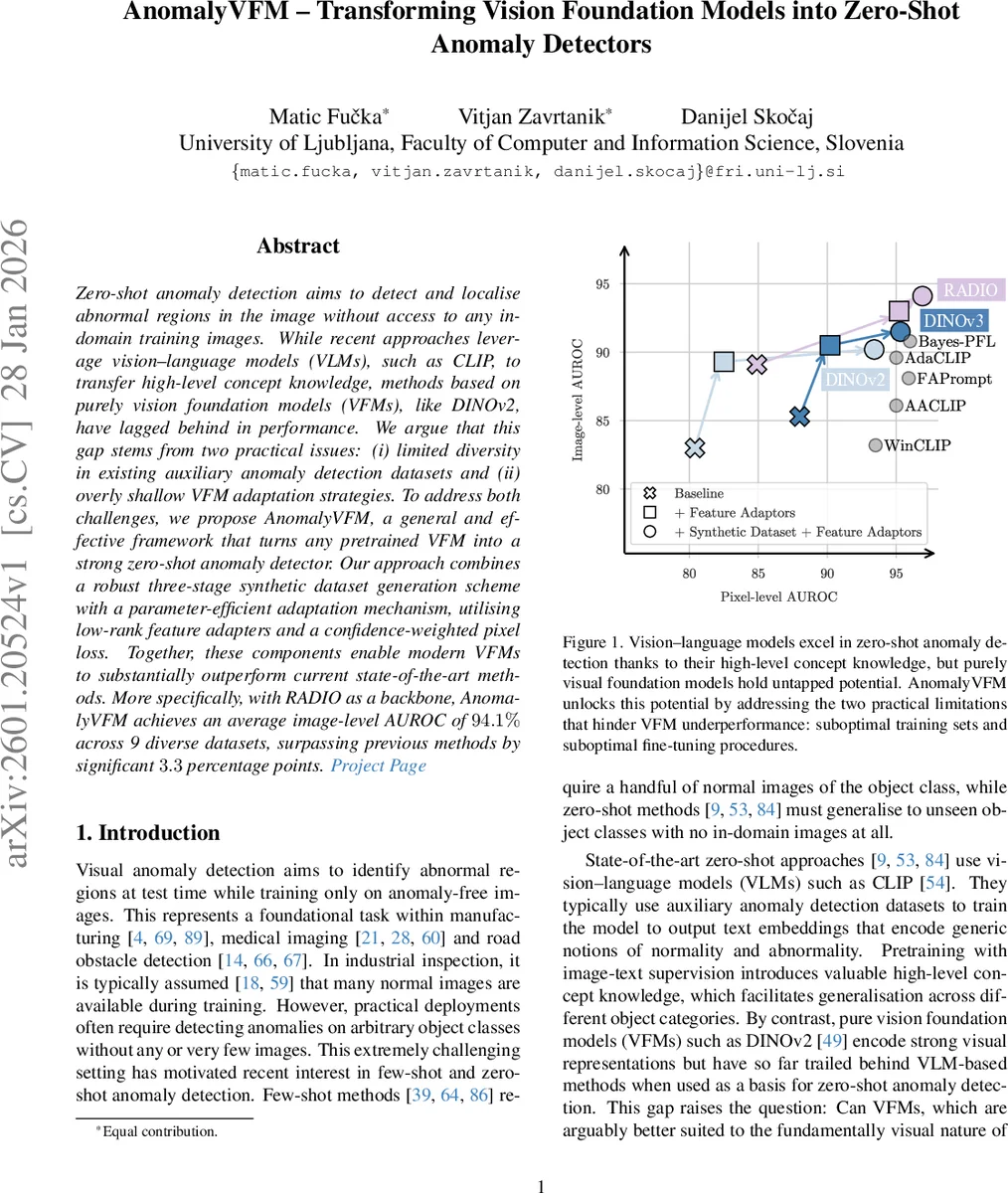
Zero-shot anomaly detection aims to detect and localise abnormal regions in the image without access to any in-domain training images. While recent approaches leverage vision-language models (VLMs), such as CLIP, to transfer high-level concept knowledge, methods based on purely vision foundation models (VFMs), like DINOv2, have lagged behind in performance. We argue that this gap stems from two practical issues: (i) limited diversity in existing auxiliary anomaly detection datasets and (ii) overly shallow VFM adaptation strategies. To address both challenges, we propose AnomalyVFM, a general and effective framework that turns any pretrained VFM into a strong zero-shot anomaly detector. Our approach combines a robust three-stage synthetic dataset generation scheme with a parameter-efficient adaptation mechanism, utilising low-rank feature adapters and a confidence-weighted pixel loss. Together, these components enable modern VFMs to substantially outperform current state-of-the-art methods. More specifically, with RADIO as a backbone, AnomalyVFM achieves an average image-level AUROC of 94.1% across 9 diverse datasets, surpassing previous methods by significant 3.3 percentage points. Project Page: https://maticfuc.github.io/anomaly_vfm/
💡 Research Summary
AnomalyVFM presents a comprehensive framework that converts any pretrained vision foundation model (VFM) into a strong zero‑shot anomaly detector. The authors identify two practical bottlenecks that have limited the performance of pure‑vision models in prior zero‑shot work: (i) the lack of diversity in auxiliary anomaly detection datasets, and (ii) shallow adaptation strategies that only fine‑tune a small output head while leaving the bulk of the transformer backbone unchanged.
To overcome the first bottleneck, the paper introduces a three‑stage synthetic data generation pipeline that leverages modern text‑conditioned image synthesis (specifically the FLUX flow‑matching model). First, a large pool of normal images is created by prompting FLUX with object‑and‑background combinations generated by a large language model (GPT‑4o). Second, a salient‑object segmentation network (IS‑Net) extracts foreground masks, and random rectangles are sampled within these masks to define anomaly locations. Third, defect‑specific prompts (e.g., “cracked”, “smudged”) are used to in‑paint realistic anomalies via the RePaint technique. After generation, DINOv2 features of the normal and anomalous versions are compared; only samples whose cosine distance exceeds a threshold are retained, effectively filtering out failed in‑painting attempts. This pipeline yields millions of image‑anomaly‑mask triplets without any human annotation, dramatically increasing the variety of objects, textures, and defect types available for training.
Addressing the second bottleneck, the authors propose a parameter‑efficient adaptation mechanism based on low‑rank adapters (LoRA). LoRA modules are inserted into the query, key, value, and output projection matrices of every transformer block, with a default rank of 64. This allows the internal representations of the VFM to be fine‑tuned while adding less than 0.1 % extra parameters. The adapted features from the final block are reshaped and fed into a lightweight convolutional decoder consisting of two up‑sampling blocks (Conv‑GroupNorm‑ReLU‑Bilinear) followed by a final convolution that outputs both a pixel‑wise anomaly score map and a confidence map. The CLS token is passed through a simple linear layer to produce an image‑level anomaly score.
Training employs a confidence‑weighted loss. The image‑level loss uses focal loss to handle class imbalance. The pixel‑level loss combines L1 and focal terms (β = 5) and is multiplied by a confidence factor C = 1 + exp(c), where c is the decoder’s confidence map; an additional logarithmic term (α = 0.1) further down‑weights uncertain regions. This design mitigates the impact of noisy synthetic labels and encourages the model to focus on reliable supervision.
Extensive experiments are conducted on nine industrial anomaly detection benchmarks (including MVTec‑AD, BTAD, and others) as well as medical imaging datasets. Using RADIO as the backbone, AnomalyVFM achieves an average image‑level AUROC of 94.1 %, surpassing the previous state‑of‑the‑art zero‑shot methods by 3.3 percentage points. Pixel‑level AUROC improves by 10–13 percentage points across the same benchmarks. Similar gains are observed with DINOv2 and DINOv3 backbones, confirming the method’s model‑agnostic nature. Moreover, when fine‑tuned with only a handful of normal samples (few‑shot setting), AnomalyVFM matches the performance of dedicated few‑shot approaches, demonstrating its flexibility.
In summary, AnomalyVFM combines (1) a scalable, high‑quality synthetic dataset generator, (2) low‑rank adapter‑based internal feature adaptation, and (3) a confidence‑aware loss to unlock the full potential of vision foundation models for zero‑shot anomaly detection. The approach is computationally efficient, requires no in‑domain training data, and generalises across industrial and medical domains, making it a practical solution for real‑world deployment.
Comments & Academic Discussion
Loading comments...
Leave a Comment