AEDR: Training-Free AI-Generated Image Attribution via Autoencoder Double-Reconstruction
The rapid advancement of image-generation technologies has made it possible for anyone to create photorealistic images using generative models, raising significant security concerns. To mitigate malicious use, tracing the origin of such images is essential. Reconstruction-based attribution methods offer a promising solution, but they often suffer from reduced accuracy and high computational costs when applied to state-of-the-art (SOTA) models. To address these challenges, we propose AEDR (AutoEncoder Double-Reconstruction), a novel training-free attribution method designed for generative models with continuous autoencoders. Unlike existing reconstruction-based approaches that rely on the value of a single reconstruction loss, AEDR performs two consecutive reconstructions using the model’s autoencoder, and adopts the ratio of these two reconstruction losses as the attribution signal. This signal is further calibrated using the image homogeneity metric to improve accuracy, which inherently cancels out absolute biases caused by image complexity, with autoencoder-based reconstruction ensuring superior computational efficiency. Experiments on eight top latent diffusion models show that AEDR achieves 25.5% higher attribution accuracy than existing reconstruction-based methods, while requiring only 1% of the computational time.
💡 Research Summary
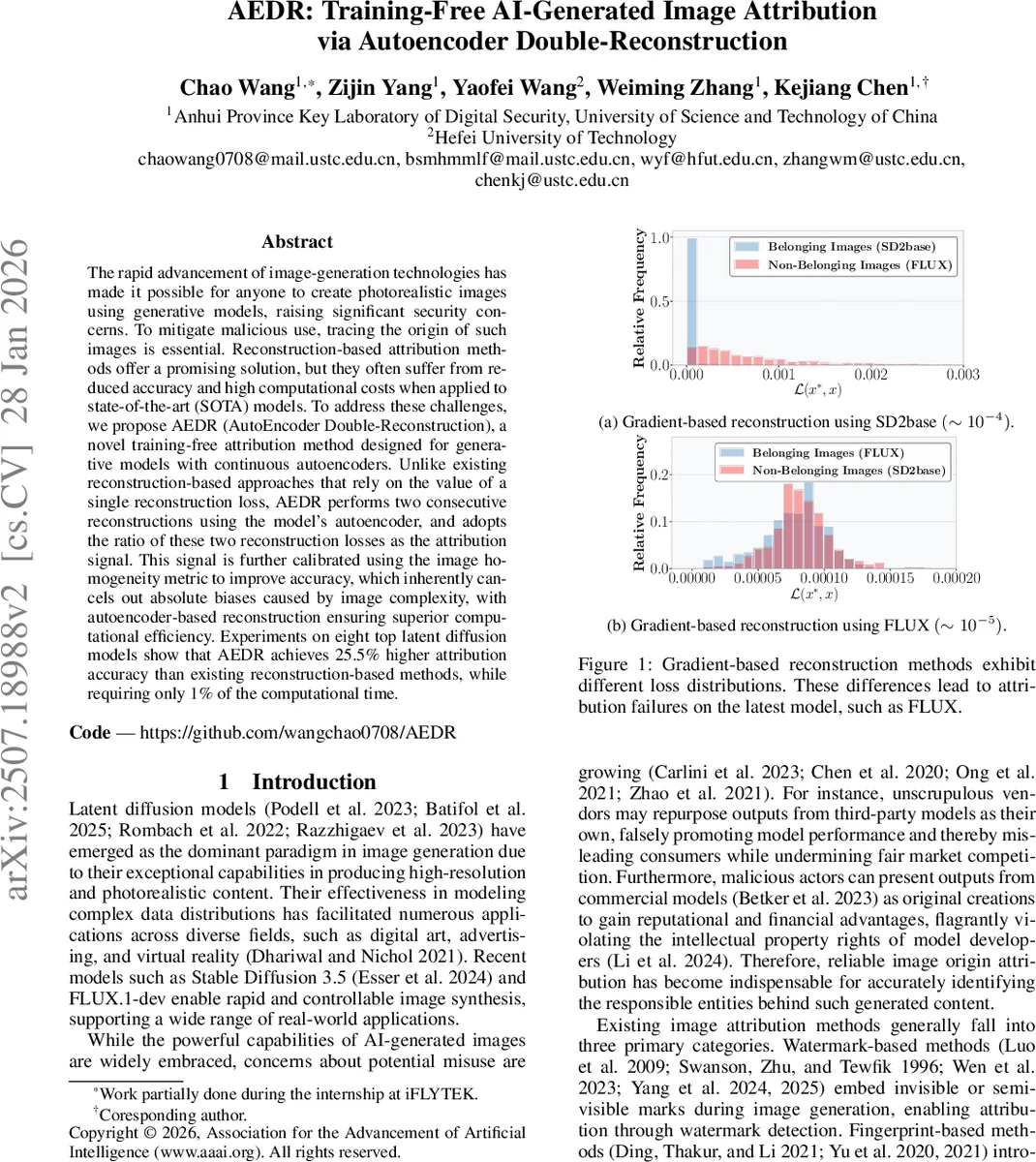
The paper introduces AEDR (AutoEncoder Double‑Reconstruction), a training‑free method for attributing AI‑generated images to their source diffusion models. Existing reconstruction‑based attribution techniques, such as RONAN and LatentTracer, rely on a single reconstruction loss obtained via gradient‑based optimization. While effective on older models, these approaches falter on state‑of‑the‑art latent diffusion models (e.g., Stable Diffusion 3.5, FLUX.1‑dev) because both belonging and non‑belonging images yield extremely low losses, causing severe overlap in loss distributions and a dramatic drop in attribution accuracy. Moreover, gradient‑based reconstruction is computationally intensive, requiring many optimization steps.
AEDR addresses these issues by exploiting the autoencoder that is already part of many diffusion pipelines. For a test image x, the method performs two successive reconstructions using the model’s encoder E and decoder D: first reconstruct x to x* and compute loss L₁ = MSE(x*, x); then reconstruct x* to x** and compute L₂ = MSE(x**, x*). The uncalibrated attribution signal is the ratio t = L₁/L₂. The key insight is that images generated by the target model (belonging images) lie within the autoencoder’s learned data manifold, so the two reconstructions are almost identical and t ≈ 1. In contrast, images not generated by the model (non‑belonging) are initially outside the manifold; the first reconstruction projects them closer to the manifold, leading to a substantially lower second loss and thus t ≫ 1.
Because raw reconstruction loss is heavily influenced by image complexity (simple textures produce lower losses than intricate scenes), AEDR introduces a homogeneity‑aware calibration. It computes a homogeneity metric H based on gray‑level co‑occurrence probabilities, which quantifies how uniform an image is. The calibrated signal becomes t′ = t × H = (L₁/L₂) × H, effectively normalizing out complexity bias.
To decide whether an image belongs to the model, AEDR does not assume any parametric distribution for t′. Instead, it collects t′ values from a set of known belonging images (500 samples in the experiments) and estimates their probability density using kernel density estimation (KDE). The decision threshold τ is chosen as the smallest value for which the cumulative density reaches 1 − α (α = 0.05), i.e., the 95th percentile of the belonging‑image distribution. This non‑parametric threshold adapts automatically to each model and is robust to outliers.
Extensive experiments on eight leading latent diffusion models demonstrate that AEDR achieves an average 25.5 % higher attribution accuracy than the best gradient‑based baselines while requiring only about 1 % of their computational time. The method remains stable across a wide range of image resolutions and texture complexities, and its calibration step significantly reduces false‑negative rates on complex images.
The contributions are threefold: (1) identifying the failure of single‑loss reconstruction methods on modern diffusion models; (2) proposing a double‑reconstruction loss ratio, calibrated by image homogeneity, as a robust, training‑free attribution signal; (3) introducing a KDE‑based, data‑driven thresholding scheme that requires no prior distributional knowledge. Limitations include dependence on the availability of the model’s autoencoder (closed‑source models may be inaccessible) and reliance on MSE, which could be sensitive to color shifts or high‑frequency noise. Future work may explore alternative perceptual loss functions, multi‑scale reconstructions, or surrogate encoders for models lacking a public autoencoder.
In summary, AEDR offers a practical, efficient, and highly accurate solution for tracing the provenance of AI‑generated images, paving the way for more reliable forensic tools in the era of increasingly sophisticated generative models.
Comments & Academic Discussion
Loading comments...
Leave a Comment