Hint: hierarchical inter-frame correlation for one-shot point cloud sequence compression
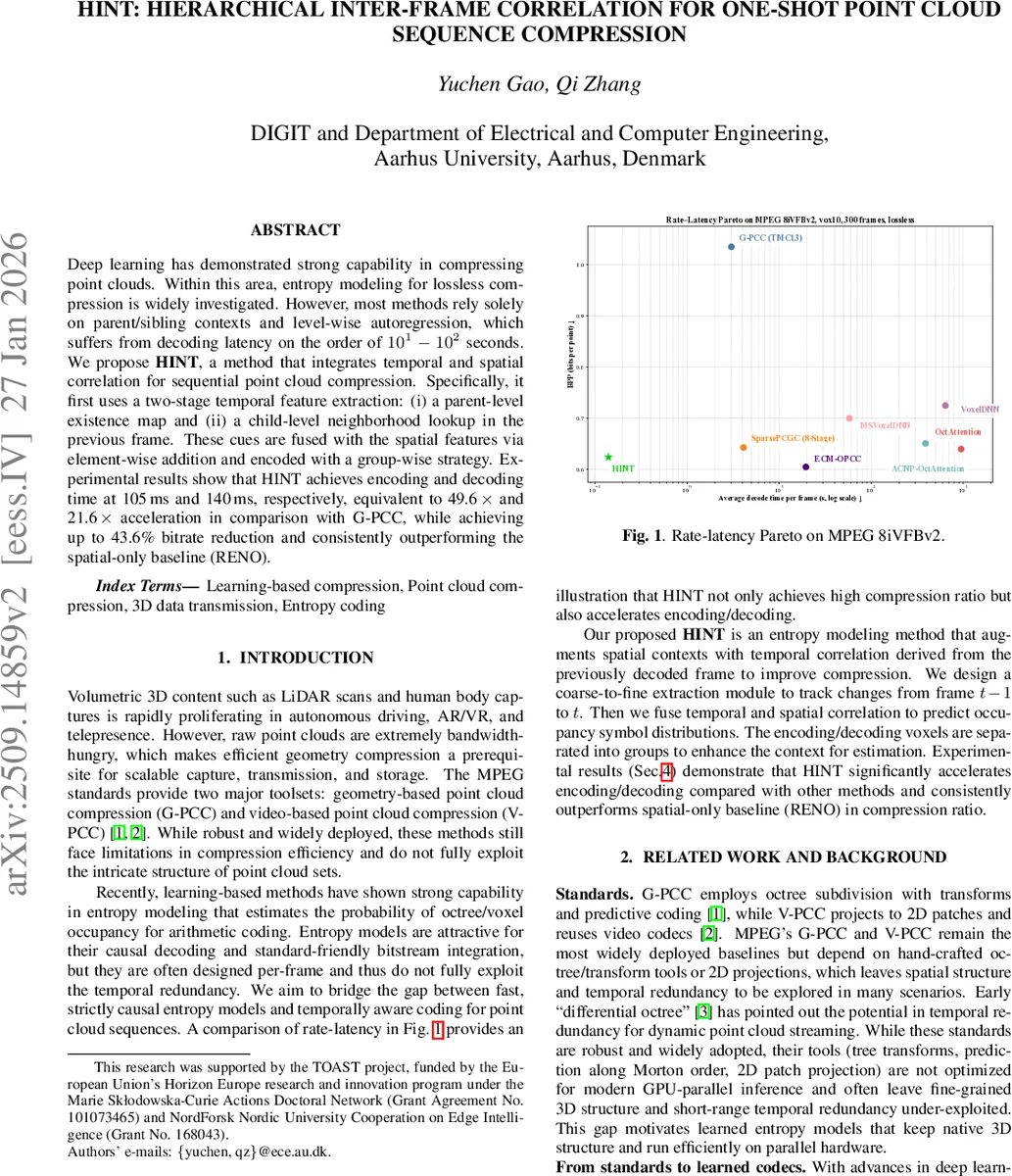
Deep learning has demonstrated strong capability in compressing point clouds. Within this area, entropy modeling for lossless compression is widely investigated. However, most methods rely solely on parent/sibling contexts and level-wise autoregression, which suffers from decoding latency on the order of 10^1-10^2 seconds. We propose HINT, a method that integrates temporal and spatial correlation for sequential point cloud compression. Specifically, it first uses a two-stage temporal feature extraction: (i) a parent-level existence map and (ii) a child-level neighborhood lookup in the previous frame. These cues are fused with the spatial features via element-wise addition and encoded with a group-wise strategy. Experimental results show that HINT achieves encoding and decoding time at 105 ms and 140 ms, respectively, equivalent to 49.6x and 21.6x acceleration in comparison with G-PCC, while achieving up to 43.6% bitrate reduction and consistently outperforming the spatial-only baseline (RENO).
💡 Research Summary
**
The paper addresses the long‑standing problem of high decoding latency in learning‑based point‑cloud sequence compression. Existing entropy models for lossless compression (e.g., OctAttention, ECM‑OPCC, SparsePCGC) rely almost exclusively on spatial contexts derived from parent and sibling voxels within a single frame and on level‑wise autoregressive decoding. This design forces a sequential processing order that can take tens to hundreds of seconds per frame, making such methods impractical for real‑time applications such as autonomous driving, AR/VR, or telepresence.
HINT (Hierarchical Inter‑frame Correlation for One‑shot Point cloud sequence compression) proposes a fundamentally different approach that fuses lightweight temporal cues from the previously decoded frame with spatial features extracted by the RENO backbone. The method consists of three main components:
-
Two‑stage Temporal Feature Extraction
Coarse (parent‑level) module: For each parent voxel at level d in the current frame t, a cubic neighborhood (default 3 × 3 × 3) is examined in both frames t and t‑1. The binary existence of each neighbor (1 = present, 0 = absent) yields a 2 V_d‑dimensional vector that is passed through a small MLP, producing a 32‑dimensional temporal feature T_d. This feature is added element‑wise to the spatial feature F_s (output of RENO’s Prior ResNet) and broadcast to all eight children, forming a coarse child‑level feature F_d.
Fine (child‑level) module: For each child voxel at level d + 1, a larger 5 × 5 × 5 window is queried in the previous frame. The 8‑bit occupancy codes of the found neighbors are embedded via a learned 256 × 32 table, averaged, and linearly transformed (matrix W_t) to obtain another 32‑dimensional temporal feature T_{d+1}. This is added to the broadcast coarse feature F_d, yielding the final child‑level feature F_{d+1}=F_d+T_{d+1}. -
Sibling‑group Context Modeling
The eight children of a parent are split into two parity groups: even (G_e = {0,3,5,6}) and odd (G_o = {1,2,4,7}). For G_e, HINT follows the classic two‑stage bitwise coding used in RENO: first predict the lower 4 bits (s0) of the 8‑bit occupancy code, encode them, embed the ground‑truth s0, add it to the feature, and then predict the upper 4 bits (s1). For G_o, the already decoded G_e codes are embedded (256‑entry table) and concatenated with each child’s 3‑D relative position inside the parent. A linear projection W_s creates a sibling context vector F(G_e) which is added to F_{d+1} to form an enriched feature ˜F_{d+1}. The same two‑stage prediction (s0 then s1) is applied to each odd child. Because the parity groups are complementary, odd children only depend on already decoded even siblings, preserving strict causality while exploiting richer sibling information. -
Efficient Implementation
HINT is built on PyTorch and TorchSparse, using sparse tensor operations for all voxel‑wise computations. The Fast Occupancy Generator (FOG) and Fast Coordinates Generator (FCG) are non‑learned modules that reconstruct child occupancy codes and coordinates from parent data without explicit octree construction, enabling massive parallelism on GPUs. The entire model contains only 3.4 MB of parameters, far smaller than comparable learned codecs.
Experimental Evaluation
The authors evaluate HINT on the MPEG 8iVFBv2 dataset (Loot, Longdress, Redandblack, Soldier), each quantized to 10 bits and consisting of 300 frames. Baselines include the MPEG standard G‑PCC, several recent learned entropy models (OctAttention, ACNP‑OctAttention, ECM‑OPCC, SparsePCGC, VoxelDNN, MSVoxelDNN) and the spatial‑only RENO. Results show:
- Compression efficiency – HINT achieves up to 43.6 % bitrate reduction relative to G‑PCC and consistently outperforms all baselines except ECM‑OPCC, where the gap is modest (≈2 %).
- Latency – Encoding time is 105 ms per frame and decoding time 140 ms, representing 49.6× and 21.6× speed‑ups over G‑PCC respectively, and 36.2×/29.3× over SparsePCGC.
- Model size – 3.4 MB, smaller than SparsePCGC (4.9 MB).
- Temporal correlation benefit – In sequences with low inter‑frame motion, HINT yields an additional 4‑5 % bitrate saving (up to 6.7 % on the Soldier sequence). When motion is high, the benefit diminishes but HINT still remains superior to spatial‑only methods.
Key Contributions and Impact
- Introduces a lightweight, two‑stage temporal feature extraction that captures both coarse parent‑level existence and fine child‑level occupancy patterns without expensive motion estimation.
- Proposes a parity‑based sibling grouping that enriches context while preserving strict causal decoding, thereby eliminating the need for costly autoregressive passes across levels.
- Demonstrates that a compact model (3.4 MB) can achieve near‑state‑of‑the‑art compression ratios while delivering real‑time encoding/decoding on a modern GPU, making it suitable for deployment in latency‑sensitive pipelines.
The paper convincingly shows that integrating hierarchical inter‑frame correlation into entropy modeling bridges the gap between high compression efficiency and low latency. Future work could explore more sophisticated motion prediction, adaptive group sizes, or extension to lossy compression where perceptual quality metrics guide bitrate allocation. Overall, HINT represents a significant step toward practical, high‑performance point‑cloud video codecs.
Comments & Academic Discussion
Loading comments...
Leave a Comment