Improving Value-based Process Verifier via Low-Cost Variance Reduction
Large language models (LLMs) have achieved remarkable success in a wide range of tasks. However, their reasoning capabilities, particularly in complex domains like mathematics, remain a significant challenge. Value-based process verifiers, which estimate the probability of a partial reasoning chain leading to a correct solution, are a promising approach for improving reasoning. Nevertheless, their effectiveness is often hindered by estimation error in their training annotations, a consequence of the limited number of Monte Carlo (MC) samples feasible due to the high cost of LLM inference. In this paper, we identify that the estimation error primarily arises from high variance rather than bias, and the MC estimator is a Minimum Variance Unbiased Estimator (MVUE). To address the problem, we propose the \textsc{Com}pound \textsc{M}onte \textsc{C}arlo \textsc{S}ampling (ComMCS) method, which constructs an unbiased estimator by linearly combining the MC estimators from the current and subsequent steps. Theoretically, we show that our method leads to a predictable reduction in variance, while maintaining an unbiased estimation without additional LLM inference cost. We also perform empirical experiments on the MATH-500 and GSM8K benchmarks to demonstrate the effectiveness of our method. Notably, ComMCS outperforms regression-based optimization method by 2.8 points, the non-variance-reduced baseline by 2.2 points on MATH-500 on Best-of-32 sampling experiment.
💡 Research Summary
Large language models (LLMs) have demonstrated impressive capabilities across many tasks, yet their performance on complex, multi‑step reasoning problems such as mathematics remains far from perfect. A promising line of work addresses this gap by training a value‑based process verifier: a model that, for each intermediate reasoning step, predicts the probability that the current partial solution will eventually lead to a correct final answer. These probabilities are used during inference to re‑rank or prune candidate continuations, thereby improving overall accuracy.
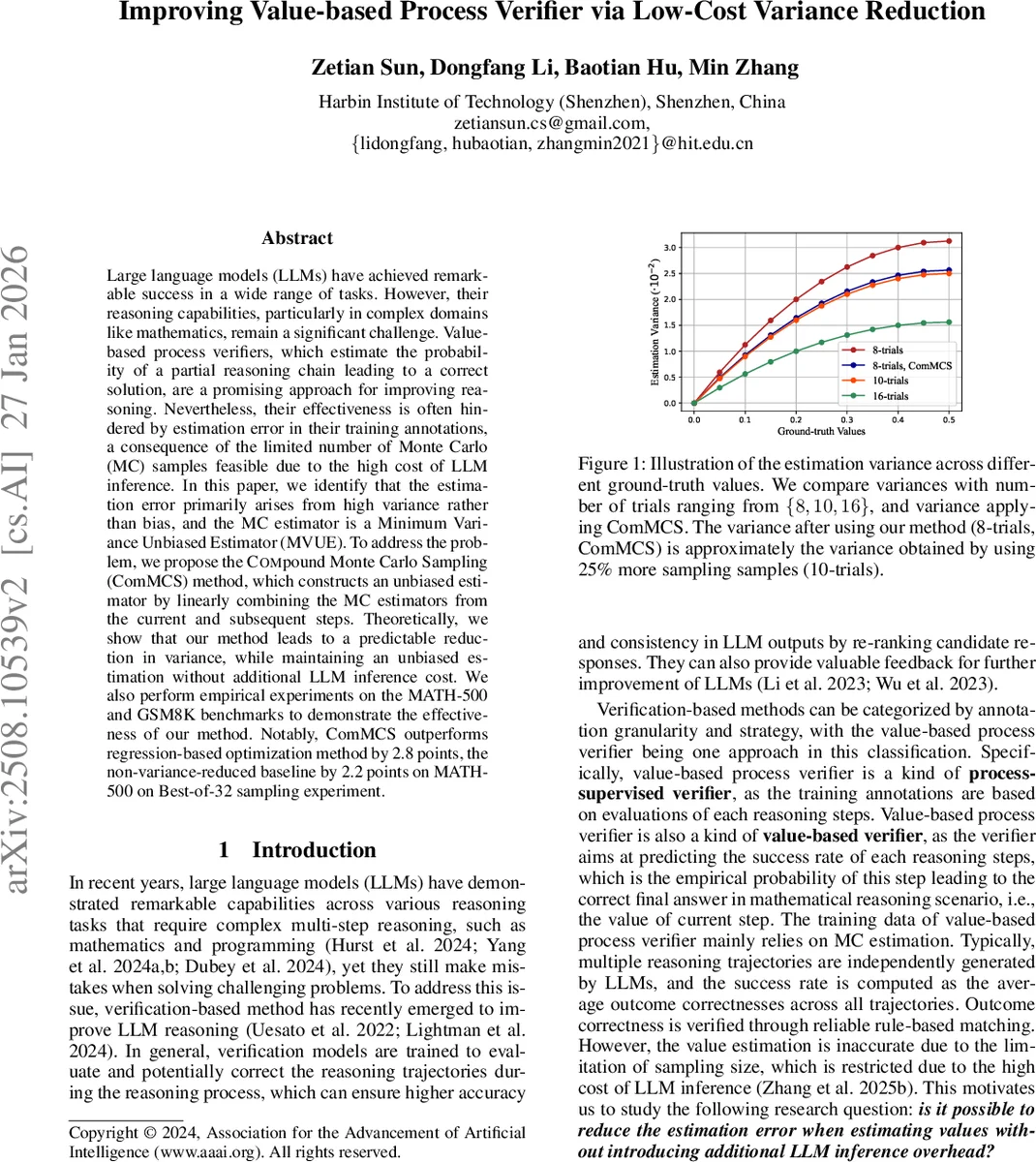
The standard way to obtain training labels for the verifier is Monte‑Carlo (MC) estimation. For a given state‑action pair (s, a), many independent reasoning trajectories are generated by the LLM, the final outcome (correct/incorrect) is recorded as a binary reward, and the empirical average of these rewards is taken as the target value. Because LLM inference is expensive, the number of sampled trajectories N is kept small (often 8–16), which introduces substantial noise into the labels and limits the verifier’s effectiveness.
Key theoretical insight
The authors first formalize the reasoning process as a deterministic Markov Decision Process (MDP) with binary rewards. They prove that MC estimation of the state value Vπ(s) is mathematically equivalent to drawing N samples from a binomial distribution B(N, p) where p = Vπ(s). Consequently, the MC estimator is unbiased (its expectation equals the true value) and, more importantly, it is the Minimum‑Variance Unbiased Estimator (MVUE) for the given number of samples. This means that, without additional information, the variance of the estimator cannot be reduced by any other unbiased method.
Compound Monte Carlo Sampling (ComMCS)
Inspired by Temporal‑Difference (TD) learning in reinforcement learning, the authors propose to incorporate future unbiased information to reduce the variance of the current estimate. The Bellman equation for a deterministic transition reduces to Qπ(s,a) = R(s,a) + γ Vπ(s′). By linearly combining the MC estimate of the current step with the MC estimate of the next step,
\
Comments & Academic Discussion
Loading comments...
Leave a Comment