Analyzing Diffusion and Autoregressive Vision Language Models in Multimodal Embedding Space
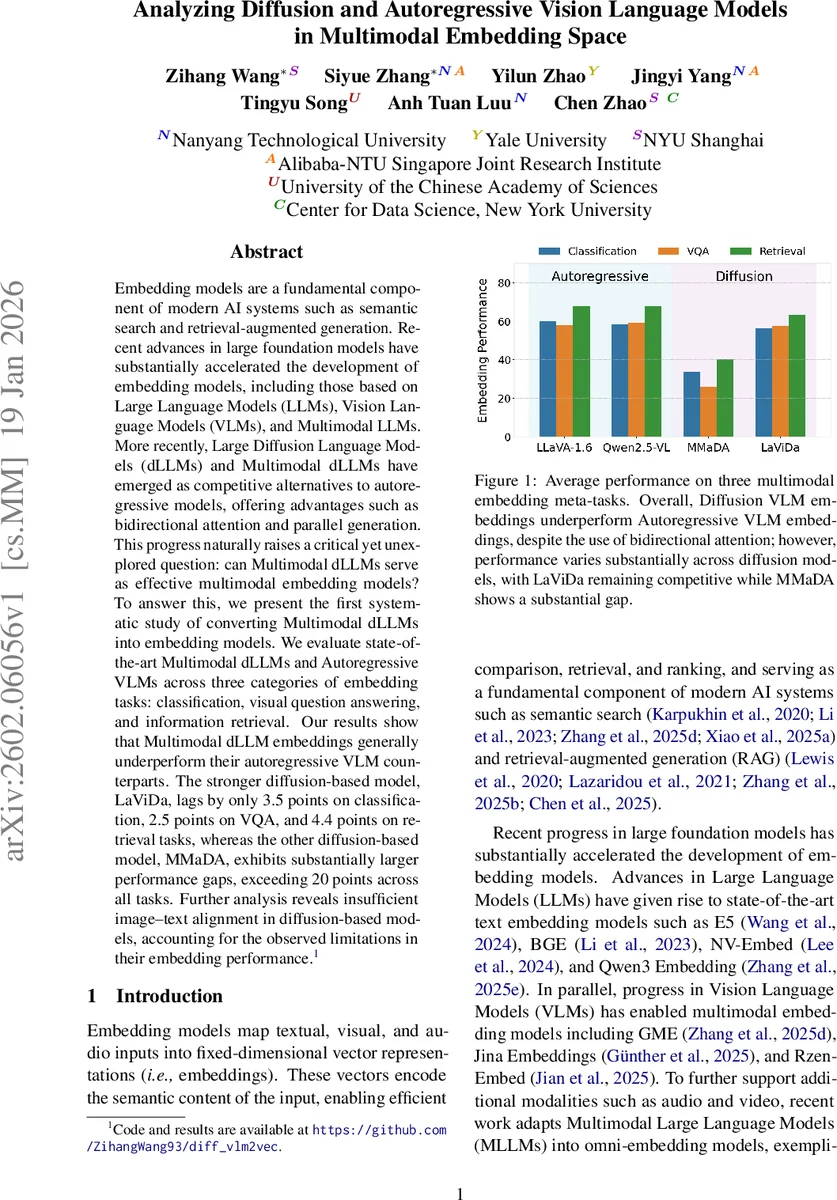
Embedding models are a fundamental component of modern AI systems such as semantic search and retrieval-augmented generation. Recent advances in large foundation models have substantially accelerated the development of embedding models, including those based on Large Language Models (LLMs), Vision Language Models (VLMs), and Multimodal LLMs. More recently, Large Diffusion Language Models (dLLMs) and Multimodal dLLMs have emerged as competitive alternatives to autoregressive models, offering advantages such as bidirectional attention and parallel generation. This progress naturally raises a critical yet unexplored question: can Multimodal dLLMs serve as effective multimodal embedding models? To answer this, we present the first systematic study of converting Multimodal dLLMs into embedding models. We evaluate state-of-the-art Multimodal dLLMs and Autoregressive VLMs across three categories of embedding tasks: classification, visual question answering, and information retrieval. Our results show that Multimodal dLLM embeddings generally underperform their autoregressive VLM counterparts. The stronger diffusion-based model, LaViDa, lags by only 3.5 points on classification, 2.5 points on VQA, and 4.4 points on retrieval tasks, whereas the other diffusion-based model, MMaDA, exhibits substantially larger performance gaps, exceeding 20 points across all tasks. Further analysis reveals insufficient image-text alignment in diffusion-based models, accounting for the observed limitations in their embedding performance.
💡 Research Summary
This paper presents the first systematic investigation of whether large multimodal diffusion language models (dLLMs) can serve as effective multimodal embedding models, and how they compare to the prevailing autoregressive vision‑language models (VLMs). The authors focus on two state‑of‑the‑art diffusion‑based VLMs—LaViDa and MMaDA—and two autoregressive VLMs—LLaVA‑1.6 and Qwen2.5‑VL—chosen for comparable scale and recent strong performance on multimodal understanding benchmarks.
Methodologically, the study adopts the contrastive fine‑tuning paradigm popularized by VLM2Vec. Both diffusion and autoregressive models are first equipped with a vision encoder (e.g., CLIP‑L, SigLIP) that converts images into token sequences. For autoregressive VLMs, embeddings are extracted from the final token (CLS) after causal attention processing; for diffusion VLMs, embeddings are obtained by mean‑pooling the contextualized token representations from the last transformer layer, reflecting the bidirectional nature of diffusion pre‑training. The same InfoNCE loss, temperature‑scaled cosine similarity, in‑batch positives, and hard negatives are used across all models, ensuring a fair comparison.
The evaluation covers three meta‑tasks—classification, visual question answering (VQA), and information retrieval—spanning 32 datasets (10 classification, 10 VQA, 12 retrieval). Classification tasks involve an instruction‑image pair as query and a set of class labels as candidates; VQA tasks require answering questions grounded in images; retrieval tasks test cross‑modal ranking with text, images, and natural‑language instructions. Both in‑domain (datasets seen during fine‑tuning) and out‑of‑domain settings are examined.
Results show a consistent pattern: diffusion‑based embeddings underperform autoregressive embeddings, but the gap varies dramatically between the two diffusion models. LaViDa lags behind the autoregressive baselines by only 3.5 points on average for classification, 2.5 points for VQA, and 4.4 points for retrieval. In contrast, MMaDA suffers a severe degradation of more than 20 points across all meta‑tasks. Detailed per‑dataset numbers reveal that LaViDa maintains competitive accuracy on large‑scale image classification (e.g., ImageNet‑1K: 64.3 vs. 68.9) and respectable VQA scores (e.g., OK‑VQA: 61.1 vs. 73.1). MMaDA, however, collapses on the same tasks (ImageNet‑1K: 27.0, OK‑VQA: 42.0).
The authors attribute these gaps to insufficient image‑text alignment in diffusion models. Cosine similarity analyses between image and text embeddings show lower alignment for diffusion models (average 0.31) compared with autoregressive models (average 0.42). Moreover, MMaDA’s unified tokenization—using a VQ‑GAN image tokenizer and a single diffusion stream for both modalities—creates a mismatch between visual and linguistic token spaces, weakening cross‑modal signals during denoising. LaViDa’s architecture, which keeps a separate vision encoder and projects visual features into the language space, mitigates this issue, explaining its relatively modest performance drop.
Another key finding concerns data efficiency. Autoregressive VLMs achieve most of their performance gains with as few as 1–5 k labeled pairs, while diffusion VLMs require substantially more (10–50 k) to close the gap, and even then converge more slowly. This suggests that bidirectional attention alone does not guarantee superior embeddings when the underlying multimodal representations are poorly aligned.
In summary, the paper concludes that current multimodal embedding technology is still dominated by autoregressive VLMs. Diffusion VLMs, despite theoretical advantages, need dedicated pre‑training strategies that explicitly enforce strong image‑text alignment—such as joint token space learning, cross‑modal masking, or contrastive objectives at the token level—to become competitive. LaViDa demonstrates that a hybrid design (separate vision encoder + diffusion language model) can narrow the gap, offering a promising direction for future research. The work provides extensive benchmark data, analysis scripts, and a public code repository, laying a solid foundation for subsequent studies on diffusion‑based multimodal embeddings.
Comments & Academic Discussion
Loading comments...
Leave a Comment