Generalizable Prompt Tuning for Audio-Language Models via Semantic Expansion
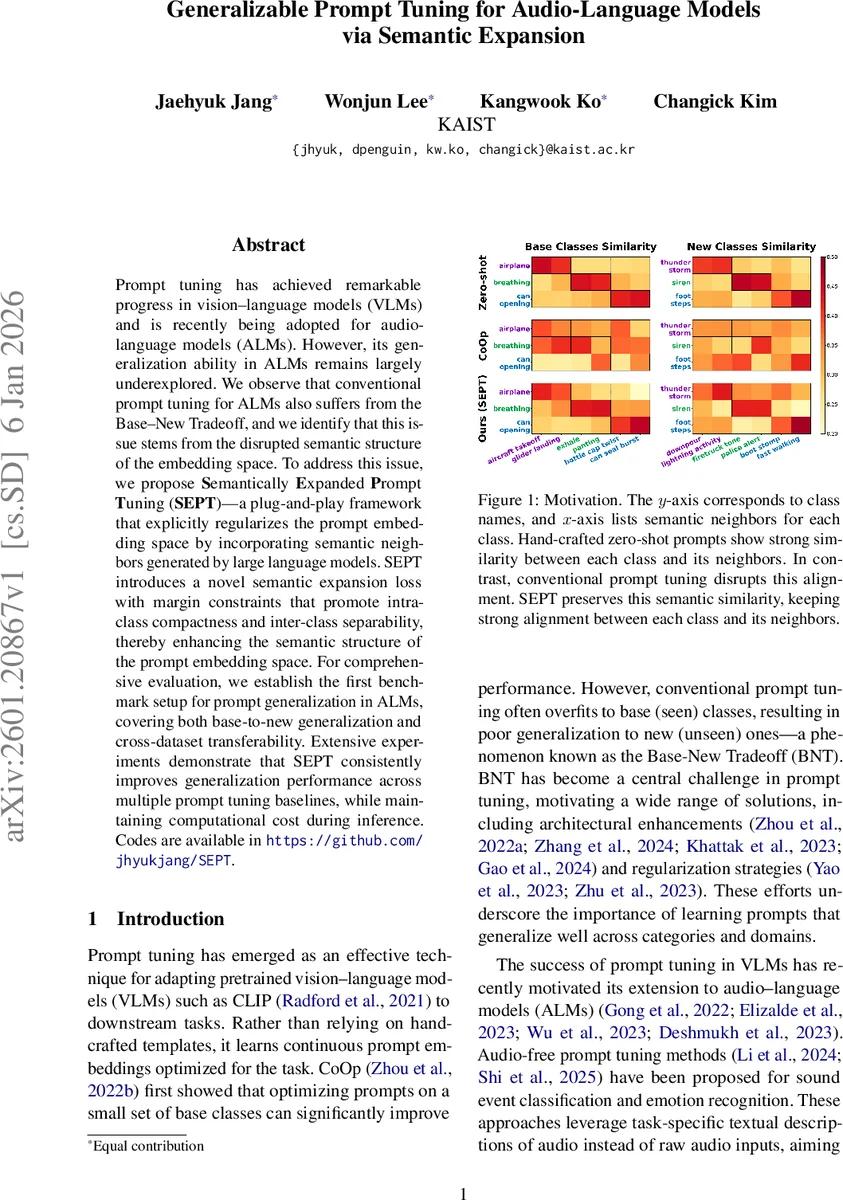
Prompt tuning has achieved remarkable progress in vision-language models (VLMs) and is recently being adopted for audio-language models (ALMs). However, its generalization ability in ALMs remains largely underexplored. We observe that conventional prompt tuning for ALMs also suffers from the Base-New Tradeoff, and we identify that this issue stems from the disrupted semantic structure of the embedding space. To address this issue, we propose Semantically Expanded Prompt Tuning (SEPT)-a plug-and-play framework that explicitly regularizes the prompt embedding space by incorporating semantic neighbors generated by large language models. SEPT introduces a novel semantic expansion loss with margin constraints that promote intra-class compactness and inter-class separability, thereby enhancing the semantic structure of the prompt embedding space. For comprehensive evaluation, we establish the first benchmark setup for prompt generalization in ALMs, covering both base-to-new generalization and cross-dataset transferability. Extensive experiments demonstrate that SEPT consistently improves generalization performance across multiple prompt tuning baselines, while maintaining computational cost during inference. Codes are available in https://github.com/jhyukjang/SEPT.
💡 Research Summary
The paper tackles a critical yet under‑explored problem in audio‑language models (ALMs): the poor generalization of prompt‑tuning methods, which suffer from the “Base‑New Tradeoff” (BNT) – strong performance on seen (base) classes but severe degradation on unseen (new) classes. While prompt tuning has become a standard technique for adapting large vision‑language models (VLMs) such as CLIP, its direct transfer to ALMs reveals a new challenge. Audio datasets typically contain only a few dozen categories, leading to a sparse semantic space. When conventional prompt‑tuning (e.g., CoOp) optimizes continuous context tokens only on base class names, the learned prompt embeddings drift away from the well‑structured text embedding space that CLIP‑style models rely on. Consequently, the semantic similarity between a class and its natural language neighbors collapses, making the model brittle for unseen sounds.
To remedy this, the authors propose Semantically Expanded Prompt Tuning (SEPT), a plug‑and‑play framework that regularizes the prompt embedding space by explicitly incorporating semantic neighbors generated by a large language model (LLM). For each base class (c_i), SEPT queries an LLM to obtain a set of (N) semantically related words ({p_{n}^{i}}{n=1}^{N}) (synonyms, paraphrases, or acoustically relevant descriptors). These neighbors are encoded with the same learnable context tokens as the original class, producing neighbor embeddings (p{n}^{i}=g(
Comments & Academic Discussion
Loading comments...
Leave a Comment