MORE: Multi-Objective Adversarial Attacks on Speech Recognition
The emergence of large-scale automatic speech recognition (ASR) models such as Whisper has greatly expanded their adoption across diverse real-world applications. Ensuring robustness against even minor input perturbations is therefore critical for ma…
Authors: Xiaoxue Gao, Zexin Li, Yiming Chen
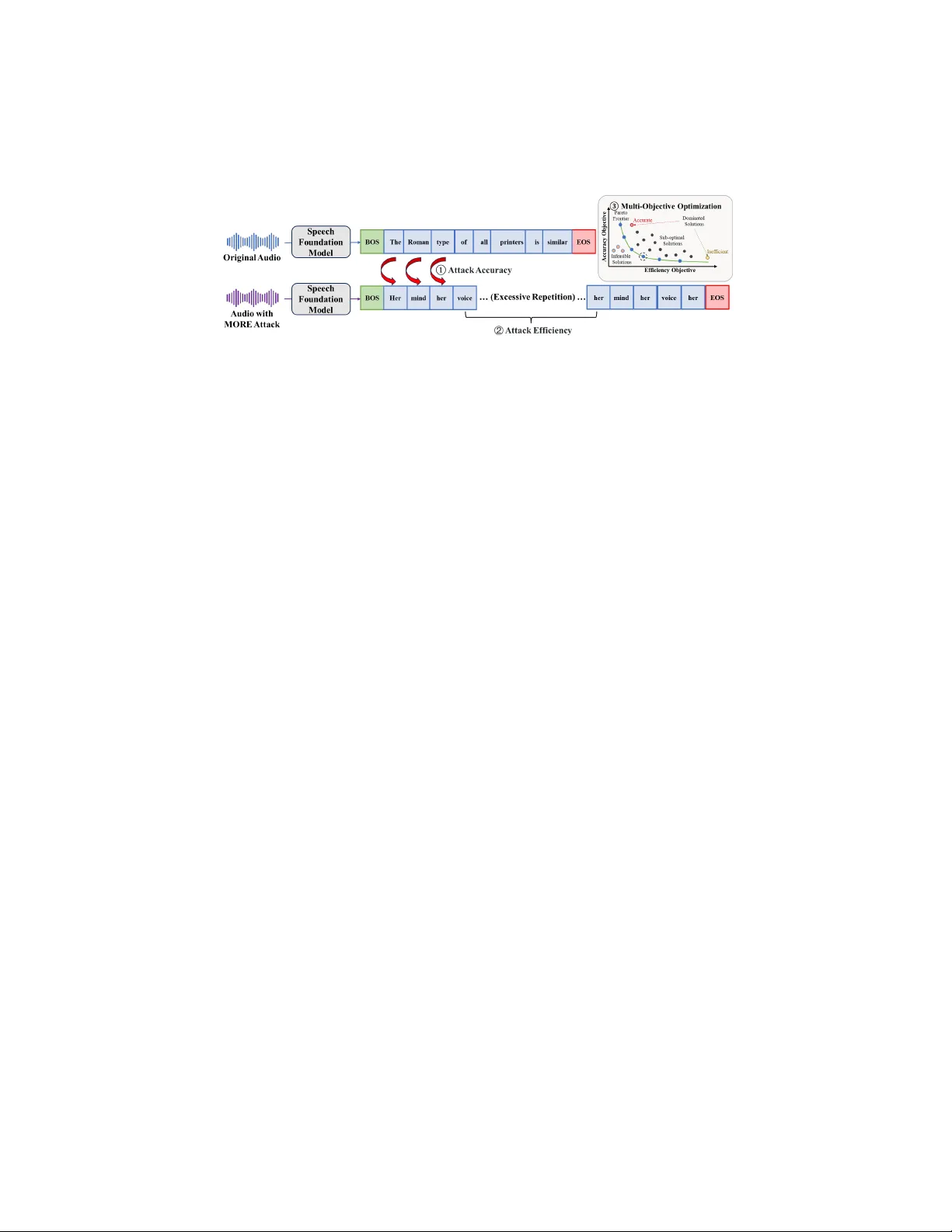
MORE: Multi-Objecti v e Adversarial Attacks on Speech Recognition Xiaoxue Gao 1 Zexin Li 2 Y iming Chen 3 * Nancy F . Chen 1 1 Agency for Science, T echnology and Research, Singapore 2 Uni versity of California, Ri verside, United States 3 National Uni versity of Singapore, Singapore { Gao Xiaoxue,nancy chen } @a-star.edu.sg January 15, 2026 Abstract The emergence of lar ge-scale automatic speech recognition (ASR) models such as Whisper has greatly expanded their adoption across diverse real-w orld applica- tions. Ensuring robustness ag ainst ev en minor input perturbations is therefore crit- ical for maintaining reliable performance in real-time environments. While prior work has mainly examined accuracy de gradation under adversarial attacks, robust- ness with respect to efficiency remains largely une xplored. This narro w focus pro- vides only a partial understanding of ASR model vulnerabilities. T o address this gap, we conduct a comprehensive study of ASR robustness under multiple attack scenarios. W e introduce MORE, a multi-objective repetitiv e doubling encourage- ment attack, which jointly degrades recognition accuracy and inference efficiency through a hierarchical staged repulsion–anchoring mechanism. Specifically , we reformulate multi-objectiv e adv ersarial optimization into a hierarchical frame work that sequentially achieves the dual objecti ves. T o further amplify effecti veness, we propose a novel repetitiv e encouragement doubling objecti ve (REDO) that induces duplicativ e te xt generation by maintaining accuracy degradation and periodically doubling the predicted sequence length. Overall, MORE compels ASR models to produce incorrect transcriptions at a substantially higher computational cost, trig- gered by a single adversarial input. Experiments show that MORE consistently yields significantly longer transcriptions while maintaining high word error rates compared to existing baselines, underscoring its effecti veness in multi-objective adversarial attack. 1 Intr oduction Automatic speech recognition (ASR) models, exemplified by the Whisper family [26], hav e become integral to a wide range of applications, including virtual assistants, real- time subtitling, clinical documentation, and spoken navigation [11]. Despite their suc- cess, the reliability of these systems in practical deployments remains fragile: ev en 1 small adversarial perturbations can substantially de grade recognition accuracy or dis- rupt inference efficienc y—for instance, by causing misinterpretation of user commands or inducing denial-of-service behaviors. These vulnerabilities underscore the need for a systematic examination of ASR robustness across both accuracy and efficiency , which is essential for ensuring dependable performance in real-world, time-sensiti ve environ- ments. Most prior work has been dedicated to accuracy robustness under adversarial at- tacks [28, 27, 24, 21, 9, 33, 13]. While these ef forts help understanding ASR model accuracy vulnerabilities, the efficienc y rob ustness of ASR models, and their ability to maintain real-time inference under adversarial conditions remain largely unexplored. Such efficienc y is critical, as adversaries can exploit it to de grade system responsive- ness, e.g., causing systems to output unnaturally long transcripts, severely impacting usability and causing the inference process to be excessi vely time-consuming. There- fore, enhancing and ev aluating the efficiency robustness of ASR models is crucial to ensure their practicality in real-time, user-f acing systems. As efficienc y robustness plays a piv otal role in the real-w orld applicability of deep learning models, there is a gro wing need to systematically assess it. Recent research has proposed adversarial attack methods to ev aluate efficienc y robustness in various domains, including computer vision [19, 6], machine translation [5], natural language processing [7, 18, 10, 17], and speech generation models [12]. Howe ver , research on the ef ficiency rob ustness of ASR models under attacks remains critically scarce, with SlothSpeech [15] standing as the only known effort. Y et, SlothSpeech does not con- sider the impact of efficienc y attacks on accuracy and does not systematically explore adversarial output patterns. This leav es the efficienc y dimension of ASR robustness insufficiently e xamined and calls for further in vestigation. Nev ertheless, the robustness of both accuracy and efficienc y in ASR models still lags considerably behind human speech recognition performance [15, 13]. This stark disparity underscores the need for a more holistic in vestigation into the vulnerabilities of these models. In this paper, we conduct a comprehensive study of the robustness of the Whisper family , a set of representativ e lar ge-scale ASR models, with respect to both accuracy and ef ficiency . T o this end, we propose a novel M ulti- O bjecti ve R epetitive D oubling E ncouragement attack approach ( MORE ) that simultaneously targets both accuracy and ef ficiency vul- nerabilities. Unlike prior attacks that optimize a single objectiv e, MORE incorporates a multi-objectiv e repulsion–anc horing optimization strate gy that unifies accuracy-based and efficienc y-based adversarial attacks within a single network. Motiv ated by natural human speech repetitions and repetiti ve decoding loops observ ed in transformer-based models [35], we introduce a repetitiv e encouragement doubling objecti ve (REDO) that promotes duplicativ e text pattern generation periodically by maintaining accurac y degradation in producing elongated transcriptions. An asymmetric interleaving mech- anism further reinforces periodic context doubling while an EOS suppression objective discourages early termination. The contrib utions of this paper include: (a) this paper presents the first unified at- tack approach that jointly tar gets both accuracy and ef ficiency robustness against lar ge- scale ASR models via a multi-objective repulsion-anchoring optimization strategy; (b) we propose REDO , which bridges ef ficiency with accuracy gradients via guiding the 2 accuracy-modified gradients towards repetitive elongated semantic contexts, thereby inducing incorrect yet extended transcriptions; and (c) we provide a comprehensive comparativ e study of diverse attack methods with insightful findings to balance accu- racy and efficienc y degradation. Extensiv e experiments demonstrate that the proposed MORE consistently outperforms all baselines in producing longer transcriptions while maintaining strong accuracy attack performance. 2 Related W ork Adversarial Attacks on Speech Recognition. Automatic speech recognition has been extensi vely studied regarding its vulnerability to attacks. These attacks primarily seek to degrade recognition accuracy by introducing typically subtle perturbations into speech inputs, thereby compromising transcription accuracy [15, 23, 29, 32, 36, 14]. Notable examples include attacks in the MFCC feature domain [30, 8], tar geted attacks designed to trigger specific commands [3], and perturbations constrained to ultrasonic frequency bands (e.g., DolphinAttack [37]). Most prior works on attacking ASR have concentrated on traditional architectures, such as CNN or Kaldi-based systems [31], with limited exploration into modern lar ge-scale transformer-based ASR models. Recent advances in ASR hav e been driven by the emergence of large-scale mod- els, notably OpenAI Whisper [26], a transformer-based encoder-decoder architecture trained on lar ge-scale datasets (680K hours of data), demonstrating greater robustness and generalization across div erse speech scenarios. Consequently , there has been an increasing research interest in ev aluating the adversarial robustness of Whisper, par- ticularly focusing on accurac y-oriented attacks. Such efforts include univ ersal at- tacks [28, 27], targeted Carlini & W agner (CW) attacks [24] and gradient-based meth- ods, i.e., projected gradient descent (PGD) [21], momentum iterative f ast gradient sign method (MI-FGSM) [9], v ariance-tuned momentum iterativ e fast gradient sign method (VMI-FGSM) [33], as well as speech-aware adversarial attacks [13]. Howe ver , most existing approaches focus only on accuracy robustness and overlook vulnerabilities in inference ef ficiency , which can be exploited through decoding manipulation. Sloth- Speech [15] represents the only prior efficienc y-focused attack in ASR, but it does not jointly consider accuracy de gradation or structured repetition, limiting its ability to assess multi-dimensional robustness. Motivations and Applications. Different from previous attacks, our proposed MORE systematically ev aluates and undermines both accuracy and efficiency within a sin- gle adversarial network, offering a comprehensive understanding of large-scale ASR model’ s vulnerabilities that previous single-objective methods cannot provide. The significance of studying the adversarial robustness of ASR models, particularly Whis- per , is amplified by their potential deployment in hate speech moderation [20, 34] and priv ate speech data protection. Practically , our proposed MORE can be applied to distort the transcription of harmful or priv ate speech, pre venting ASR systems from reliably con verting such content into readable text. By inducing incorrect and exces- siv ely long transcriptions, MORE exposes decoding weaknesses that are not re vealed by accuracy-only attacks, of fering a more comprehensiv e view of ASR vulnerability . 3 3 MORE 3.1 Problem F ormulation V ictim model. W e consider a raw speech input represented as a sequence X = [ x 1 , x 2 , . . . , x T ] . Its corresponding ground-truth transcription is a sequence of text tokens Y = [ y 1 , y 2 , . . . , y L ] . The target ASR model is denoted by a function f ( · ) that maps a speech sequence to a predicted transcription, i.e., f ( X ) = ˆ Y . The model v o- cabulary is denoted by V , and EOS ∈ V is the end-of-sequence token. Our objecti ve is to construct an adversarial perturbation δ such that the perturbed input X + δ triggers harmful behavior during decoding. Attack objective. Most existing adversarial attacks on ASR aim solely to maximize transcription error . Ho wever , practically disruptive attacks must also de grade inference efficienc y , especially in real-time ASR systems where excessi ve decoding time can break user interactions. W e therefore formulate a dual-objectiv e optimization targeting both transcription accuracy and computational ef ficiency: S = arg max δ ∈ ∆ ∞ ( ϵ ) (WER f ( X + δ ) , Y , f ( X + δ ) ) (1) where WER( · ) denotes the word error rate and | f ( · ) | denotes the length of the predicted sequence. This formulation explicitly seeks perturbations that (i) increase transcription error relati ve to the ground truth and (ii) induce excessi vely long outputs, thereby amplifying computational ov erhead. Perturbation constraint. W e impose both energy- and peak-based constraints for imperceptibility . A standard measure is the signal-to-noise ratio (SNR), which com- pares the energy of the signal and the perturbation: SNR dB = 20 log 10 ∥ X ∥ 2 ∥ δ ∥ 2 . (2) While SNR constrains ov erall perturbation energy , it may still allow short, high-amplitude distortions. T o av oid this, we additionally bound the perturbation’ s peak amplitude us- ing the ℓ ∞ norm: ∆ = { δ | ∥ δ ∥ ∞ ≤ ϵ } , where ϵ = ∥ X ∥ ∞ SNR . (3) This ℓ ∞ constraint ensures that no single sample deviates excessi vely , which aligns with psychoacoustic masking principles. The adversarial example is thus defined as X adv = X + δ with δ ∈ ∆ . 3.2 Design Overview and Moti vations The proposed MORE attack is moti vated by the autoregressi ve nature of ASR mod- els and the different optimization dynamics of our two goals: reducing transcription accuracy and prolonging decoding for efficiency degradation, as illustrated in Fig. 1. 4 Figure 1: Overvie w of our proposed m ulti- o bjectiv e r epetitive e ncouragement dou- bling (MORE) adversarial attack method. In autoregressi ve models, each predicted token influences all future predictions, with the end-of-sentence (EOS) token being particularly sensitive; small perturbations to its logits can drastically alter when decoding stops [28, 24], b ut it receives sparse gradient signal compared with ordinary tokens. The accuracy attack objectiv e, in contrast, dis- tributes across many token positions, encouraging mis-transcriptions and resulting in a relativ ely large feasible adversarial set, as many incorrect transcripts are possible. The efficienc y attack objective, howe ver , mainly tar gets the non-stopping behavior associ- ated with a single EOS token, where gradients are narrowly concentrated and typically smaller in magnitude compared with those of the broader accuracy objecti ve. Because accuracy gradients are broad and ef ficiency gradients are sharp and concentrated, com- bining them in a single-step optimization often causes one objectiv e to dominate. This makes direct multi-objecti ve optimization unstable. T o address this, our proposed MORE uses a hierarchical two-stage strategy consist- ing of a repulsion stage for accuracy de gradation and an anchoring stage for efficienc y degradation. The repulsion stage forces the model aw ay from the correct transcription. The anchoring stage then exploits remaining de grees of freedom to extend decoding. Formally , we approximate the hierarchical formulation in Eq. 4 using a two-stage repulsion-anchoring method. In the r epulsion stage, we maximize a differentiable proxy of WER. In the anchoring stage, we extend the decoded sequence length while preserving the high error rate obtained in the r epulsion stage. The follo wing sections describe the optimization procedure for each in detail. S = arg max δ ∈ ∆ ∞ ( ϵ ) WER f ( X + δ ) , Y , δ ∗ = arg max δ ∈ S f ( X + δ ) , (4) This staged hierarchical design avoids forcing accurac y and ef ficiency gradients to compete simultaneously and provides a stable optimization path. 3.3 Repulsion Stage: Accuracy Attack The first pillar of our MORE attack is the r epulsion stage, which focuses on degrading transcription accuracy . The repulsion stage applies a standard gradient-based accurac y- degradation attack using cross-entropy (CE) as a differentiable proxy for WER. Mini- mizing negati ve CE reduces the probability of ground-truth tokens, pushing the model tow ard incorrect outputs and increasing WER. 5 The accuracy attack loss is formulated as: L acc = − CE f ( X + δ ) , Y . (5) T aking gradient changing steps w .r .t. this loss function encourages the ASR model to output incorrect tokens, which directly correlates with an increase in the ultimate WER. This serves as the initial “destabilization” repulsion stage of our attack to destabilize the decoding trajectory and prepare the model for the subsequent efficienc y attack. 3.4 Anchoring Stage: Efficiency Attack Complementing the accurac y degradation, MORE’ s ef ficiency attack targets the no w- vulnerable model by anchoring it to generate excessi vely long and computationally expensi ve transcriptions. This anchoring stage is accomplished through the two com- ponents below . EOS suppression. Decoding normally terminates when EOS is predicted. By pe- nalizing the probability of this token, we can deceiv e the model into prolonging the decoding process indefinitely , often resulting in the generation of irrelev ant or mean- ingless tokens. Penalizing only the EOS token is insufficient since its probability is typically dominant at the final decoding step. T o enhance attack effecti veness, we re- duce the likelihood of the EOS token. In addition, we increase the probability of the competing token with the second-largest likelihood. Reinforcing this alternativ e to- ken not only diminishes EOS dominance but also guides the model toward continued generation. Therefore, the EOS-suppression loss is formulated as: L EOS = P EOS L − P z L , (6) where P EOS L is the probability that the model emits EOS at the final position L . z is the token with the second lar gest probabilities at position L : z = arg max v ∈ V \{ EOS } P v L (7) W e denote L as the output sequence length, and P v L is the model’ s predicted probability of token v being produced at output position L . This dual adjustment ensures the model is discouraged from selecting EOS while being nudged toward an alternativ e contin- uation, thereby minimizing this loss reduces EOS dominance and fav ors continuation tokens, which in turn prolongs decoding. Repetitive Encouragement Doubling Objective (REDO). While effecti ve, simple EOS suppression can lead to unstable optimization or low-confidence, random out- puts. T o introduce a more structured and potent method for sequence elongation, we propose a novel r epetitive encouragement doubling objective (REDO) , inspired by repetition loops observed in transformer models [35] and natural speech disfluencies. T ransformer models are known to enter self-reinforcing repetition loops where once a sentence with high generation probability is produced, the model tends to reproduce it in subsequent steps, as its presence in the context further boosts its likelihood of being 6 selected again [35]. This recursive amplification leads to a self-sustaining loop of repe- tition, wherein repeated sentences reinforce their o wn future generation by dominating the context. Our REDO le verages this mechanism to force long structured repetitions, thereby reliably increasing sequence length, as demonstrated in Figure 1. At each period, REDO constructs a duplicated version of the earlier decoded segment and uses CE to encourage the model to reproduce the extended sequence consistently . This produces stable semantic repetition and much longer sequences than EOS suppression alone. Specifically , gi ven an initial decoding output ˆ Y , we construct a new target sequence ¯ Y that contains a repeated segment. W e then force the model to predict this new , longer sequence using a cross-entropy objective. The target sequence ¯ Y i for step i is constructed as: ¯ Y i = ˆ y ⌊ i D ⌋ [1 : L − 1] ∥ ˆ y ⌊ i D ⌋ [1 : L − 1] , (8) where L is the length of target sequence length at step i D , D is the the doubling period, controlling how frequently the sequence is duplicated. The floor function i D ensures that the repeated segment remains fixed within each interval of D steps, only updating once e very D steps. This periodic repetition creates stable semantic loops that encourage longer and more redundant model outputs. The doubling loss REDO is: L REDO = CE ( f ( X + δ ) , ¯ Y i ) . (9) For a concrete example, if the target sequence for attacking step 0 is ¯ Y = [ y 1 , y 2 , y 3 , EOS ] , the target sequence for attacking step 0 to 9 should be ¯ Y = [ y 1 , y 2 , y 3 , y 1 , y 2 , y 3 ] with doubling the re gular tokens and strictly eliminating the EOS token. This loss e xplicitly guides the model to produce periodic, repeated segments, which serve to rapidly and reliably inflate the output token count while maintaining a degree of linguistic struc- ture, making the attack more potent. Finally , for efficienc y attack, the loss is formulated as L eff = L REDO + L EOS . Asymmetric interlea ving. Applying a single-stage long-repeated target for attack can destabilize gradient optimization with the long-horizon optimization difficulties [2, 1, 22]. T o mitigate this, REDO breaks the long-horizon repetition task into a sequence of easier subproblems, yielding smoother optimization than trying to force a single-stage long-tar get objecti ve. REDO is therefore formulated as a stepwise, curriculum-style attack that progressi vely optimizes for longer repeated outputs. Con- cretely , we interleave : for step s maintain the repeated tar get fix ed when s mod D = 0 and extend it to the next longer form when s mo d D = 0 . This “periodic booster” concentrates high-v ariance, long-horizon REDO updates sparsely while using frequent short-horizon updates to stabilize learning, and is distinct from summing losses or ap- plying dense REDO updates at ev ery step. Algorithm Details. W e integrate these components into a unified hierarchical pro- cedure (Algorithm 1) to the dual-objective problem. W e provide a detailed analysis in Appendix B. In particular , Appendix B characterizes ho w the computational cost 7 Algorithm 1 M O R E : Hierarchical Attack with Curriculum Interleaved Efficiency Losses 1: Input: Original audio X , true transcript Y , ℓ ∞ radius ϵ , step size α , total steps K , accuracy steps K a , doubling period D , ASR model f ( · ) . 2: Output: Adversarial perturbation δ 3: Initialize δ ← 0 4: Repulsion Stage: Accuracy (steps 1 . . . K a ) 5: for i = 1 to K a do 6: Compute L ← L acc by Eq. 5 7: δ ← clip [ − ϵ,ϵ ] δ − α · sign( ∇ δ L ) 8: end for 9: Anchoring Stage: Efficiency (steps K a +1 . . . K ) 10: for i = K a + 1 to K do 11: s ← i − K a 12: if ( s − 1) mo d D = 0 then 13: Calculate ¯ Y by Eq. 8 14: end if 15: Compute L EOS by Eq. 6 16: Compute L RDEO by Eq. 9 17: L ← L EOS + L RE DO 18: δ ← clip [ − ϵ,ϵ ] δ − α · sign( ∇ δ L ) 19: end for 20: return δ of both the repulsion (accuracy-de gradation) and anchoring (REDO-based repetition) stages scales with model depth, width, and the REDO-induced growth in output length. W e additionally provide FLOPs analysis in Appendix C. 4 Experiments Datasets. W e utilize two widely used ASR datasets from HuggingFace, LibriSpeech [25] and LJ-Speech [16], and ev aluate the first 500 utterances from each (LJ-Speech and the test-clean subset of LibriSpeech), with all audio resampled to 16,000 Hz. Threat Model. W e conduct white-box attacks with full access to the model on fiv e Whisper-f amily models [26], including Whisper-tiny , Whisper-base, Whisper-small, Whisper-medium, and Whisper-lar ge, all obtained from HuggingFace. T o benchmark the proposed MORE approach, we compare it against fiv e strong white-box attack baselines: PGD [24], MI-FGSM [9], VMI-FGSM [33], the speech-a ware gradient op- timization (SA GO) method [13], and SlothSpeech [15]. Experimental Setup. In MORE, the hyperparameters I and K a are set to 10 and 50, respecti vely . T o ensure imperceptibility to human listeners, we set the perturbation magnitudes ϵ to 0.002 and 0.0035, which correspond to average signal-to-noise ratios (SNRs) of 35 dB and 30 dB, respecti vely , both within the range generally considered inaudible to humans [13]. All e xperiments are conducted using a NVIDIA H100 GPU. 8 Whisper-tiny Whisper-base Whisper -small Whisper-medium Whisper -large Attack Methods WER length WER length WER length WER length WER length LibriSpeech Dataset clean 6.66 21.84 4.90 21.77 3.64 21.84 2.99 21.84 3.01 21.84 PGD 93.17 35.02 88.73 31.65 75.23 27.93 64.77 26.94 33.33 21.80 SlothSpeech 46.80 119.38 54.63 156.07 38.25 110.40 31.09 81.75 34.21 79.78 SA GO 93.19 31.93 88.23 33.85 74.67 27.45 62.46 25.97 30.26 21.12 VMI-FGSM 87.91 32.39 93.47 33.90 73.84 27.34 60.74 25.38 29.77 20.79 MI-FGSM 93.32 34.38 87.57 34.44 74.18 27.07 61.16 25.70 34.27 21.40 MORE 91.01 296.28 88.42 300.13 74.28 213.94 64.04 234.25 53.72 301.47 LJ-Speech Dataset clean 5.34 18.55 3.77 18.65 3.33 18.64 3.33 18.55 3.36 18.55 PGD 93.63 30.60 90.23 29.98 77.08 22.67 65.07 22.71 26.54 18.55 SlothSpeech 47.10 116.05 59.98 187.9 32.52 65.85 22.23 101.11 21.14 35.33 SA GO 89.53 31.63 84.46 26.69 72.08 22.31 59.08 21.80 21.03 19.11 VMI-FGSM 90.26 29.75 93.85 30.97 75.27 21.90 60.56 21.10 23.00 18.13 MI-FGSM 93.98 32.48 89.14 28.19 74.55 21.80 59.10 22.31 28.02 18.37 MORE 90.85 296.66 89.53 313.64 74.33 208.51 58.86 204.18 43.13 231.52 T able 1: Comparison of a verage recognition accurac y (WER%) and average tran- scribed text token length of various attack methods on the LibriSpeech and LJ-Speech datasets at an SNR of 35 dB. The reported accuracy and token length are averaged over 500 utterances for each dataset. ’Clean’ denotes performance on the original, unper- turbed speech. Note that higher WER and longer transcribed token length indicate a more successful attack. Evaluation Metrics. T o ev aluate ASR accuracy degradation, we adopt word error rate (WER) as the metric, which quantifies the proportion of insertions, substitutions, and deletions relativ e to the number of ground-truth words. Given that adversarial transcriptions may be excessi vely long, we truncate the predicted sequence to match the length of the reference text to better ev aluate accuracy degradation in the initial por - tion of the output, where meaningful recognition should occur; WER v alues exceeding 100.00% are capped at 100.00% for normalization. Higher WER indicates lower ASR performance and thus a more effecti ve accuracy attack. Efficienc y attack performance is measured by the length of the predicted text tok ens, where a greater length indicates a more effecti ve efficienc y attack. 5 Results and Discussion W e e valuate MORE against state-of-the-art baselines on both accuracy and efficiency across multiple ASR models, examine its robustness under dif ferent SNR levels, and conduct ablations to analyze component contributions. A case study with adversarial examples and decoded transcriptions further illustrates its ef fectiv eness. 5.1 Main Results Across Differ ent Attacks and Models W e compare MORE with SOT A baselines across multiple ASR models, with results on two datasets at 30 dB and 35 dB sho wn in T able 1 and T able 2. Our MORE approach consistently achieves superior ef ficiency attack performance, 9 Whisper-tiny Whisper -base Whisper -small Whisper-medium Whisper-large Attack Methods WER length WER length WER length WER length WER length LibriSpeech Dataset clean 6.66 21.84 3.77 21.77 3.64 21.84 2.99 21.84 3.36 21.84 PGD 96.22 35.30 93.90 33.21 85.83 31.40 78.77 28.87 47.93 21.92 SlothSpeech 60.06 123.93 69.33 152.82 56.45 102.15 41.75 77.43 48.34 78.65 SA GO 95.64 34.44 93.72 32.95 83.94 28.28 74.67 27.00 45.67 21.75 VMI-FGSM 93.23 37.53 96.08 37.72 83.15 28.06 73.66 27.02 42.75 22.07 MI-FGSM 96.18 34.37 93.08 33.22 83.49 28.37 72.52 27.54 45.35 22.11 MORE 94.73 300.79 93.70 324.05 86.15 238.52 77.84 202.34 60.90 277.65 LJ-Speech Dataset Clean 5.34 18.55 4.90 18.65 3.33 18.64 3.33 18.55 3.01 18.55 PGD 96.56 31.79 94.46 30.50 86.08 25.69 79.45 24.42 42.87 19.97 SlothSpeech 61.62 123.58 71.51 187.87 51.33 76.59 38.33 103.33 35.74 37.50 SA GO 91.23 29.77 87.85 29.67 80.80 22.58 71.50 22.65 33.22 19.08 VMI-FGSM 93.46 28.67 96.57 33.55 84.15 24.15 73.05 22.16 36.28 19.31 MI-FGSM 96.15 31.04 93.37 29.18 83.97 23.37 73.15 22.47 42.71 18.21 MORE 94.80 326.62 94.08 310.57 85.49 222.04 75.01 229.66 54.13 229.08 T able 2: Comparison of a verage recognition accurac y (WER%) and average tran- scribed text token length of various attack methods on the LibriSpeech and LJ-Speech datasets at an SNR of 30 dB. generating significantly longer transcriptions while maintaining high WER for accu- racy degradation across both SNR lev els. Specifically , accuracy-oriented baselines (PGD, SA GO, MI-FGSM, and VMI-FGSM) achie ve substantially lower transcription lengths (e.g., 31.65 vs. our 300.13), highlighting the ef fectiv eness of our novel repeti- tiv e encouragement doubling objecti ve (REDO). Compared to SlothSpeech, a baseline specifically designed for efficiency attacks, MORE still achieves significantly longer outputs (e.g., 208.52 vs. 65.85), underscoring the efficacy of our doubling loss design in REDO to effecti vely induce repetitiv e and extended transcriptions. Notably , on the robust Whisper-lar ge model, our MORE approach exhibits excep- tional performance in both accuracy and efficienc y dimensions. It achieves higher accuracy de gradation (WER of 53.72 compared to about 30 for accuracy-oriented at- tack baselines) while producing average transcription lengths of 301.47—roughly 10 times longer than accuracy-oriented baselines and approximately 3.8 times longer than SlothSpeech (79.78). Additionally , SlothSpeech’ s weaker accurac y degradation (WER of 46.80 vs. MORE’ s 91.01) highlights the limitations of optimizing solely for ef- ficiency and underscores the necessity of incorporating accuracy objectives for com- prehensiv e attacks. These findings validate the robustness and utility of our proposed multi-objectiv e optimization approach. 5.2 Impact of SNR Conditions W e further in vestigate the effect of varying SNR levels on attack effecti veness. By comparing results under 30 dB SNR (T able 2) and 35 dB SNR (T able 1), we observe that attacks under 30 dB SNR generally yield stronger performance, characterized by higher WER and significantly longer transcriptions (length). This confirms that lo wer SNR (i.e., noisier conditions) provides a more fav orable en vironment for adversarial perturbations to succeed. 10 Attack methods WER Length WER Length SNR 35 35 30 30 MORE 90.85 296.66 94.80 326.62 MORE - L acc 27.58 293.03 34.33 296.91 MORE - L eff 93.63 30.60 96.56 31.79 MORE - L EOS 93.92 233.84 96.68 269.36 MORE - L REDO 92.42 120.67 95.72 146.54 MORE - L REDO - L acc 47.10 116.05 61.62 123.58 MORE - L EOS - L acc 6.97 270.21 7.96 307.38 Clean 5.34 18.55 5.34 18.55 T able 3: Ablation study of the proposed MORE approach by removing different com- ponents, ev aluating adversarial attack performance in terms of accuracy (WER) and efficienc y (length) on the LJ-Speech dataset under SNR of 35 dB and 30 dB. The sym- bol ‘ − ’ denotes component remov al. Attacks Adversarial decoded text transcriptions from adv ersarial speech Length WER Clean The Roman type of all these printers is similar in character . 12 0.00 PGD of Rutland who tried before gallopy was ventenies for contempo- rary priorath probes. 18 100.00 SlothSpeech The Roman type of all these. The Roman type of all these. W e’re still in a learning career . W e’re still in a learning career . W e’ re still in a learning career . W e’ re still in a learning career . 42 72.73 SA GO the Rolling Tide. For more on our latest ventilators for summary of Fire Esther . 17 90.91 VMI-FGSM Roman plight, although he’ s fengomed for the century of my af- fairs. 14 100.00 MI-FGSM and Rutland tied for Broadway’ s ventilence for Senior Order of Fire efforts. 18 100.00 MORE her mind, her voice, her voice, and her voice, and her voice, and her voice, and her voice, and her voice, and her voice, and her voice, ....... (repeat 100 times) and her voice , ...... and her voice, and her voice, and her v oice, and 334 100.00 T able 4: Comparison of decoded transcriptions from adversarially generated speech samples across dif ferent attacks: clean, PGD, SlothSpeech, SA GO, VMI-FGSM, MI- FGSM and the proposed MORE approaches. Clean represents the original text of the clean speech sample. 5.3 Ablation Study W e conduct an ablation study to assess the contribution of each component in the pro- posed MORE approach (T able 3). Eliminating the accuracy attack loss leads to the 11 collapse of the accuracy attack performance (from 90.85 to 27.58), whereas the ef- ficiency attack remains effecti ve. This indicates that the proposed REDO and EOS objectiv es are critical for sustaining the efficiency attack. Removing the L EOS leads to a decline in efficienc y performance from 296.66 to 233.84, indicating that the EOS loss facilitates longer output generation by the Whisper model. Ho wever , both accu- racy (WER > 90) and efficienc y (length > 200) attacks remain effecti ve, suggesting that REDO and multi-objective optimization (MO) with accuracy objecti ve are more critical than EOS loss. When REDO is removed, efficiency performance drops dras- tically from 296.66 to 120.67, highlighting REDO’ s central role in promoting struc- tured repetition. Meanwhile, the WER remains above 90, suggesting that sacrificing a small amount of accuracy can substantially benefit efficiency—reflecting the inher- ent trade-off in balancing the two objectives. Eliminating L acc in addition to L REDO sharply degrades both accuracy attack (WER 90.85 → 47.10) and efficienc y (length 296.66 → 116.05), underscoring the importance of the proposed MO in jointly sup- porting both attack objectiv es. Removing both accuracy loss and EOS leads to a WER of 6.97, indicating complete failure of accuracy attacks. Howe ver , efficienc y remains high (270.21), showing that REDO alone can still sustain efficiency attacks without MO with accuracy loss or EOS. Removing all ef ficiency attack components—EOS and REDO—causes efficienc y to fail completely (length drops to 30.60), with only the ac- curacy attack (WER 93.63) remaining effecti ve. This confirms that all efficienc y design components are essential for achieving successful ef ficiency de gradation. Ov erall, all components are critical and effecti vely contribute to the success of the attacks against the victim ASR models. 5.4 Case Study: Adversarial Samples T o qualitativ ely demonstrate the effecti veness of MORE, we present decoded adver - sarial transcriptions in T able 4. Unlike other baselines, which produce either incorrect outputs, MORE generates a fully incorrect transcription with a structured repetition of the sentence “and her voice” over 100 times, resulting in a length of 334 and a WER of 100.00. This showcases the strength of our proposed multi-objectiv e optimization and the repetitive doubling encouragement objectiv e in simultaneously disrupting transcrip- tion accuracy and inducing extreme inefficienc y through systematic and semantically coherent redundancy . More case studies can be found in Appendix A. 6 Conclusion W e propose MORE , a novel adversarial attack approach that introduces multi-objectiv e repulsion-anchoring optimization to hierarchically target recognition accuracy and in- ference efficiency in ASR models. MORE integrates a periodically updated repeti- tiv e encouragement doubling objectiv e (REDO) with end-of-sentence suppression to induce structured repetition and generate substantially longer transcriptions while re- taining effecti veness in accurac y attacks. Experimental results demonstrate that MORE outperforms e xisting baselines in efficienc y attacks while maintaining comparable per- formance in accuracy degradation, ef fectively revealing dual vulnerabilities in ASR 12 models. The code will be made publicly av ailable upon acceptance. Ethics Statement All authors have read and agree to adhere to the ICLR Code of Ethics. W e understand that the Code applies to all conference participation, including submission, re viewing, and discussion. This work does not in volve human-subject studies, user experiments, or the collection of new personally identifiable information. All e valuations use publicly av ailable research datasets under their respecti ve licenses. No attempts were made to attack deployed systems, bypass access controls, or interact with real users. Our contribution, MORE , is an adversarial method that can degrade both recog- nition accuracy and inference efficienc y of ASR systems. While our goal is to ad- vance robustness research and stress-test modern ASR models, the same techniques maybe misused to (i) impair assisti ve technologies (e.g., captioning for accessibility), (ii) disrupt safety- or time-critical applications (e.g., clinical dictation, emergenc y call transcription, navig ation), or (iii) increase computational costs for shared services via artificially elongated outputs. W e do not provide instructions or artifacts intended to target any specific deployed product or service, and we caution that adversarial per- turbations, especially those designed to be inconspicuous, present real risks if applied maliciously . T o reduce misuse risk and support defenders, we suggest that some concrete de- fenses should be integrated into ASR systems: decoding-time safe guards such as rep- etition/loop detectors; input-time defenses such as band-limiting; and training-time strategies such as adv ersarial training focused on EOS/repetition pathologies. W e will explore some tar geting defense mechanisms against MORE in future work. Repr oducibility Statement W e take several steps to support independent reproduction of our results. Algorith- mic details for MORE are provided in Sec. 3 and further clarified in the Appendix B. Dataset choices and preprocessing (LibriSpeech & LJ-Speech, first 500 utterances per set, 16 kHz resampling) are specified in Sec. 4, while exact model variants (Whisper - tiny/base/small/medium/lar ge from HuggingFace), hardware, perturbation budgets/SNRs, and all attack h yperparameters are detailed in Sec. 4. The ev aluation protocol is defined in Sec. 4. W e will not include the code archiv e in the submission due to proprietary re- quirements. Upon acceptance, we will release a public repository mirroring the anony- mous package as soon as we get permission. Refer ences [1] Samy Bengio, Oriol V inyals, Navdeep Jaitly , and Noam Shazeer . Scheduled sam- pling for sequence prediction with recurrent neural networks. Advances in neural information pr ocessing systems , 28, 2015. 13 [2] Y oshua Bengio, J ´ er ˆ ome Louradour , Ronan Collobert, and Jason W eston. Cur- riculum learning. In Proceedings of the 26th annual international conference on machine learning , pages 41–48, 2009. [3] Nicholas Carlini, Pratyush Mishra, T avish V aidya, Y uankai Zhang, Micah Sherr , Clay Shields, David W agner, and W enchao Zhou. Hidden voice commands. In 25th USENIX security symposium (USENIX security 16) , pages 513–530, 2016. [4] Adam Casson. Transformer flops. https://www.adamcasson.com/ posts/transformer- flops . Accessed: 2025-11-20. [5] Simin Chen, Cong Liu, Mirazul Haque, Zihe Song, and W ei Y ang. Nmtsloth: understanding and testing efficienc y degradation of neural machine translation systems. In Pr oceedings of the 30th ACM Joint European Softwar e Engineering Confer ence and Symposium on the F oundations of Softwar e Engineering , pages 1148–1160, 2022. [6] Simin Chen, Zihe Song, Mirazul Haque, Cong Liu, and W ei Y ang. Nicgslo w- down: Evaluating the efficienc y robustness of neural image caption generation models. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition , pages 15365–15374, 2022. [7] Y iming Chen, Simin Chen, Zexin Li, W ei Y ang, Cong Liu, Robby T an, and Haizhou Li. Dynamic transformers provide a false sense of efficienc y . In Proceed- ings of the 61st Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pages 7164–7180, T oronto, Canada, 2023. Association for Computational Linguistics. [8] Mike Jermann Dan Iter , Jade Huang. Generating adv ersarial examples for speech recognition. Stanfor d T echnical Report , 2017. [9] Y inpeng Dong, Fangzhou Liao, T ianyu Pang, Hang Su, Jun Zhu, Xiaolin Hu, and Jianguo Li. Boosting adversarial attacks with momentum. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) , pages 9185–9193, 2018. [10] Javid Ebrahimi, Anyi Rao, Daniel Lo wd, and Dejing Dou. Hotflip: White-box adversarial examples for text classification. In Pr oceedings of the 56th Annual Meeting of the Association for Computational Linguistics (V olume 2: Short P a- pers) . Association for Computational Linguistics, 2018. [11] Xiaoxue Gao and Nancy F Chen. Speech-mamba: Long-context speech recogni- tion with selective state spaces models. In 2024 IEEE Spoken Langua ge T echnol- ogy W orkshop (SLT) , pages 1–8. IEEE, 2024. [12] Xiaoxue Gao, Y iming Chen, Xianghu Y ue, Y u Tsao, and Nancy F Chen. Ttslow: Slow do wn text-to-speech with efficienc y robustness e valuations. IEEE T ransac- tions on Audio, Speec h and Language Pr ocessing , 2025. 14 [13] Xiaoxue Gao, Zexin Li, Y iming Chen, Cong Liu, and Haizhou Li. Transferable adversarial attacks against asr . IEEE Signal Pr ocessing Letters , 31:2200–2204, 2024. [14] Y unjie Ge, Lingchen Zhao, Qian W ang, Y iheng Duan, and Minxin Du. Advddos: Zero-query adversarial attacks against commercial speech recognition systems. IEEE T ransactions on Information F or ensics and Security , 2023. [15] Mirazul Haque, Rutvij Shah, Simin Chen, Berrak S ¸ is ¸ man, Cong Liu, and W ei Y ang. Slothspeech: Denial-of-service attack against speech recognition models. Interspeech , 2023. [16] Keith Ito and Linda Johnson. The lj speech dataset. https://keithito. com/LJ- Speech- Dataset/ , 2017. [17] J Li, S Ji, T Du, B Li, and T W ang. T extbugger: Generating adversarial text against real-world applications. In 26th Annual Network and Distrib uted System Security Symposium , 2019. [18] Y ufei Li, Zexin Li, Y ingfan Gao, and Cong Liu. White-box multi-objectiv e ad- versarial attack on dialogue generation. arXiv preprint , 2023. [19] Zexin Li, Bangjie Y in, T aiping Y ao, Junfeng Guo, Shouhong Ding, Simin Chen, and Cong Liu. Sibling-attack: Rethinking transferable adv ersarial attacks against face recognition. In Pr oceedings of the IEEE/CVF Conference on Computer V i- sion and P attern Recognition , pages 24626–24637, 2023. [20] Sean MacA vane y , Hao-Ren Y ao, Eugene Y ang, Katina Russell, Nazli Goharian, and Ophir Frieder . Hate speech detection: Challenges and solutions. PloS one , 14(8):e0221152, 2019. [21] Aleksander Madry , Aleksandar Makelov , Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. T o wards deep learning models resistant to adversarial attacks. International Confer ence on Learning Repr esentations (ICLR) , 2018. [22] Aleksander Madry , Aleksandar Makelov , Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. T ow ards deep learning models resistant to adversarial attacks. In International Confer ence on Learning Repr esentations , 2018. [23] Raphael Oli vier and Bhiksha Raj. Recent impro vements of asr models in the face of adversarial attacks. arXiv preprint , 2022. [24] Raphael Olivier and Bhiksha Raj. There is more than one kind of robustness: Fooling whisper with adversarial examples. arXiv pr eprint arXiv:2210.17316 , 2022. [25] V assil Panayotov , Guoguo Chen, Daniel Pov ey , and Sanjeev Khudanpur . Lib- rispeech: an asr corpus based on public domain audio books. In IEEE ICASSP , pages 5206–5210, 2015. 15 [26] Alec Radford, Jong W ook Kim, T ao Xu, Greg Brockman, Christine McLeave y , and Ilya Sutske ver . Robust speech recognition via lar ge-scale weak supervision. In International Conference on Machine Learning , pages 28492–28518. PMLR, 2023. [27] Vyas Raina and Mark Gales. Controlling whisper: Univ ersal acoustic adv ersarial attacks to control multi-task automatic speech recognition models. In 2024 IEEE Spoken Languag e T echnolo gy W orkshop (SL T) , pages 208–215. IEEE, 2024. [28] Vyas Raina, Rao Ma, Charles McGhee, Kate Knill, and Mark Gales. Muting whisper: A uni versal acoustic adversarial attack on speech foundation models. In Pr oceedings of the 2024 Confer ence on Empirical Methods in Natural Language Pr ocessing , pages 7549–7565, 2024. [29] Lea Sch ¨ onherr , Katharina Kohls, Steffen Zeiler, Thorsten Holz, and Dorothea K olossa. Adv ersarial attacks against automatic speech recognition systems via psychoacoustic hiding. arXiv pr eprint arXiv:1808.05665 , 2018. [30] T avish V aidya, Y uankai Zhang, Micah Sherr, and Clay Shields. Cocaine noo- dles: exploiting the gap between human and machine speech recognition. In 9th USENIX W orkshop on Offensive T ec hnologies (WOO T 15) , 2015. [31] Donghua W ang, Rangding W ang, Li Dong, Diqun Y an, Xueyuan Zhang, and Y ongkang Gong. Adversarial examples attack and countermeasure for speech recognition system: A surve y . In International Conference on Security and Pri- vacy in Digital Economy , pages 443–468. Springer , 2020. [32] Shen W ang, Zhaoyang Zhang, Guopu Zhu, Xinpeng Zhang, Y icong Zhou, and Jiwu Huang. Query-ef ficient adversarial attack with lo w perturbation against end- to-end speech recognition systems. IEEE T ransactions on Information F or ensics and Security , 18:351–364, 2022. [33] Xiaosen W ang and K un He. Enhancing the transferability of adversarial attacks through v ariance tuning. In Proceedings of the IEEE/CVF Confer ence on Com- puter V ision and P attern Recognition (CVPR) , pages 1924–1933, 2021. [34] Ching Seh W u and Unnathi Bhandary . Detection of hate speech in videos using machine learning. In 2020 international confer ence on computational science and computational intelligence (CSCI) , pages 585–590. IEEE, 2020. [35] Jin Xu, Xiaojiang Liu, Jianhao Y an, Deng Cai, Huayang Li, and Jian Li. Learning to break the loop: Analyzing and mitigating repetitions for neural te xt generation. Advances in Neural Information Pr ocessing Systems , 35:3082–3095, 2022. [36] Chaoning Zhang, Philipp Benz, Adil Karjauv , Jae W on Cho, Kang Zhang, and In So Kweon. In vestigating top-k white-box and transferable black-box attack. In Proceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition , pages 15085–15094, 2022. 16 [37] Guoming Zhang, Chen Y an, Xiaoyu Ji, T ianchen Zhang, T aimin Zhang, and W enyuan Xu. Dolphinattack: Inaudible voice commands. In Pr oceedings of the 2017 ACM SIGSAC confer ence on computer and communications security , pages 103–117, 2017. 17 A Mor e Adversarial T ranscriptions T o showcase the effecti veness of MORE, we present more decoded adversarial tran- scriptions in T able 5 and T able 6. B Complexity Analysis Scope and assumptions. W e analyze two costs: (i) attack-time compute to craft δ via Algorithm 1, and (ii) victim-time compute when the ASR model decodes on X + δ . Our deriv ation accounts for encoder self-attention, decoder self-/cross-attention, feed- forward layers, vocab ulary projection/softmax, greedy decoding used to materialize doubled targets, and the backw ard/forward constant factor . W e express totals in terms of model hyperparameters and the scheduling parameters ( K, K a , D ) defined in Algo- rithm 1, and we refer to the objectiv es in Eqs. 5, 6, 8, and 9. Notation. Let F be the number of encoder time steps (e.g., log-Mel frames). Encoder depth/width/FF width/heads are N e , d e , d ff ,e , h e ; decoder counterparts are N d , d d , d ff ,d , h d . V ocab ulary size is V . The total PGD steps are K , Stage 1 steps are K a , and the Stage 2 block length is D (Algorithm 1). Stage 2 has M = ⌈ ( K − K a ) /D ⌉ blocks indexed by m = 1 , . . . , M . W e denote by B m the base segment (non-EOS) used to b uild the doubled tar get in block m , and by L m = | B m | its length. The doubly repeated target in block m has length ¯ ℓ m = 2 L m . W e write κ ∈ [2 , 3] (empirically range) for the backward/forward multiplier . Let T be the number of ra w samples in X (used only for the O ( T ) PGD update). On the construction of doubled targets. Eq. 8 defines ¯ Y i via ˆ y ⌊ i D ⌋ but does not specify how the hypothesis ˆ Y is obtained at the start of each block. T o make Eq. 8 operational, we explicitly realize ˆ Y with a gr eedy decode on the current perturbed input: ˆ Y ( m ) = G R E E D Y D E C O D E f , X + δ , (10) B m = S T R I P E O S ˆ Y ( m ) , (11) ¯ Y ( m ) = B m ∥ B m , (12) ¯ ℓ m = 2 | B m | . (13) Here, Eq. 10 computes decoding the perturbed input X + δ with the victim model f ( · ) using greedy decoding (selecting the most probable token at each step until ter- mination). In Eq. 11, S T R I P E O S ( · ) removes the terminal EOS token from the de- coded hypothesis, leaving only the content-bearing tokens. The notation “ ∥ ” denotes sequence concatenation, so Eq. 12 constructs the doubled sequence by repeating B m back-to-back. Finally , ¯ ℓ calculated by Eq. 13 is the length of this doubled target. This makes Eq. 8 explicit and adds a per -block greedy-decoding cost accounted for belo w . 18 Sample 1 Adversarial decoded text from adversarial speech Length WER Clean in fourteen sixty-five sweynheim and pannartz began printing in the monastery of subiaco near rome 22 0.00 PGD W ith a 14-a-tip to the dog, framed by its and clan herbs begin in renting a Ramona scurrying, home-or-dity-actyl-healed blo wing. 31 100 SlothSpeech In 1365. T wain, and patterns. W e began printing in the monastery on Superacro. W e are going to be here. W e are going to be here. W e are going to be here. W e are going to be here. W e are going to be here. W e are going to be here. W e are going to be here. 32 57.14 SA GO In recaing 50 5, engra ved ideas and claim herbs begin renting a maimanda scurrant you’ll be able to k eep the app’ s raw huge role. 32 92.86 VMI-FGSM The importance in tips to guide, 3D appliance and clan-obes video granting a new monoscaring different types of CDR tools here in the life. 30 100 MI-FGSM W ith the important tip to di vide, engrav ed piles and clan herbs begin grinsling a Murmana scurin per Cynthia of Hugh Bully . 29 100 MORE Say 14-2 to the yard. So, I am glad herbs begin in the printing, they were modest, they’ re in the home, I just keep the actual yield going. W ell, I’m glad. W ell, I’m glad. W ell, I’m glad. W ell, I’m glad. W ell, I’m glad. W ell, I’m glad. W ell, I’m glad. W ell, I’m glad. W ell, I’m glad. ... (repeat 50 times) W ell, I’m glad. ... W ell, I’m glad. W ell, I’m glad. W ell, I’m glad. W ell, I’m glad. W ell, I’m glad. W ell, I’m glad. W ell, I’m glad. W ell, I’m glad. W ell, I’m glad. W ell 303 100.00 Sample 2 Adversarial decoded text transcriptions from adversarial speech Length WER Clean they printed very few books in this type, three only; but in their very first books in rome, be ginning with the year fourteen sixty- eight 26 0.00 PGD There’ s quite a very few dobs on the street. It’s v ery close to New Y ork, so I’m more alanists. If you’ re in the Euro-Saushen, I’m so creativ e. 39 100.00 SlothSpeech They printed very pure robsimbus type. Three only . And they’ re very first robs in Rome. Y ou’ re getting with the year 14, 16-8. 31 52.17 SA GO I print a very few dobs on the sc yphs. But it’ s in there there tortiros you can morelice, within any effort near the coat your rooms might create. 37 52.17 VMI-FGSM And as front ha ve there, with your bumps and best dri ves, the case also may fax them their source-of-fit of f some well-ince if the pay- ment Okuniro 40 or a safety aid. 37 100.00 MI-FGSM There’ s currently as very few dobs on the street flaps in their very torti-doxing Berliners, depending of a year of caf feine I’m so pleased. 33 86.96 MORE There’ s quite a very few dubs on the street. It’ s a great place. Y ou seem very close to Y ork, so I’m more alanists. It’ s the band-in- the-in-a-day . Are you or I? So, I’m 16, I’m 6, I create. It’ s a great place. It’ s a great place. It’ s a great place. It’ s a great place. ... (repeat 55 times) It’s a great place. ... It’s a great place. It’ s a great place. It’ s a great place. It’ s a great place. It’ s a great place. It’ s a great place. It’ s 369 100.00 T able 5: Comparison of decoded transcriptions from adversarially generated speech samples across dif ferent attacks: clean, PGD, SlothSpeech, SA GO, VMI-FGSM, MI- FGSM and the proposed MORE approaches. Clean represents the original text of the clean speech sample. 19 Sample 3 Adversarial decoded text from adversarial speech Length WER Clean and it was a matter of course that in the middle ages, when the craftsmen took care that beautiful form should always be a part of their productions whatev er they were 32 0.00 PGD If Anif wasn’t battle with court, he’ s cut, can him believe dunesque? By McClack to slimped up K-9’ s ex to use with lit- tle pillo ws to be beldled his beat if lag and bail for gothician in his Trump’ s Lloyd-A vergen alone. 60 96.77 SlothSpeech And it was a matter of course, in the middle ages, when the crafts- men took care that beautiful forms should rollers be a part of their productions, whatever they are. But everything. Y eah, you’re not .. (repeat 18 times) Y eah, you’re not. ... Y eah, you’re not. 114 16.13 SA GO And until some battle with the Polish scut Hindu-dulisciensky by McPlac slimed some care and ex-eutectful of toarungs, be thrilled he’ s be a flag of bamper gothish in his tomb, to play out a dang horror . 60 93.55 VMI-FGSM If anything is in battle with court he’ s gun kingdom of the Alliance Samuel Pratt has limped up Keanu and read youth with reform on each of the children who has beat up flag on boyfriend on to shamed us and point out your don’t you lotta? 55 100 MI-FGSM I don’t know if hasn’t battled with the poor, Scott, given with the diligence. By McClagg slimps, he hears, ends up doing to a toil- ing, shrid the soldier, he’ s beat up fog and bounced her goth or shin his stance and deploy ev erything, hoda.. MORE I don’t know if I was in battle with court. He’ s got... He’ s got him in the lead, do you? I’m a clapped, it’s slim, it’ s okay , I’m exactly ... He’s lik e, it’s so o wn, it’ s a bit older, he’ s a bit flack, it’ s a bit off the gothician, it’ s strong. What else is this? ... (repeat 66 times) What else is this? ... What else is this is this? What else is this is this is this is this is this is this is this is this 363 100.00 Sample 4 Adversarial decoded text from adversarial speech Length WER Clean and which dev eloped more completely and satisfactorily on the side of the ”lower -case” than the capital letters. 20 0.00 PGD I’ ve entered Richard of Omen with her work from 2018 and status factor audio. My style Roman roman rumpims Dominic Pappett, all to my idealist. 36 100.00 SlothSpeech And which denote more completely and satisfactorily , oh, beside the molecules? Y ou’ ve done the capital. ....... (repeat 8 times) Y ou’v e done the capital. ...... Y ou’ ve done the capital. 63 61.11 SA GO and which the Omen of the Fomor from P-plea Mensec satisfac- tory are postiad Roman root pins. No more powerful of her influ- ence. 31 88.89 VMI-FGSM If you’re a richer dog old, for more can keep these and to have a spare theory , I’m not today Roman Oruk winds. Roman, we’re glad to be here. 35 100.00 MI-FGSM Y ou’ ve had a rich dev olt of her warmth from cleaved deno de t ´ eras diasporoia, her stayered Roman rificims. No meekly out the glud- ermervialis. 43 100.00 MORE I’ ve had a witcher development with her work on 22 and excited as faculty earlier . My style at Roman Roman pimps. Gonna make it happen. I’m all you’ re glad you’ re leaving. I’m glad you’re leaving. ... (repeat 54 times) I’m glad you’ re lea ving. ... I’m glad you’ re leaving. I’m glad you’re 387 100.00 T able 6: Comparison of decoded transcriptions from adversarially generated speech samples across dif ferent attacks: clean, PGD, SlothSpeech, SA GO, VMI-FGSM, MI- FGSM and the proposed MORE approaches. Clean represents the original text of the clean speech sample. 20 Per -pass b uilding blocks. W e use standard T ransformer accounting; QKV and out- put projections are absorbed in big- O terms. For a decoder sequence length ℓ , C enc ( F ) = O N e F 2 d e + F d e d ff ,e , (14) C dec - TF ( ℓ, F ) = O N d ℓ 2 d d + ℓF d d + ℓd d d ff ,d , (15) C dec - gen ( ℓ, F ) = O N d ℓ 2 d d + ℓF d d + ℓd d d ff ,d . (16) The encoder cost in Eq. 14, C enc ( F ) , measures the cost of processing F input frames, scaling as F 2 d e for self-attention and F d e d ff ,e for feed-forward layers over N e encoder layers. The decoder cost under teacher forcing in Eq. 15, C dec - TF ( ℓ, F ) , captures the cost of processing a tar get sequence of length ℓ , scaling quadratically in ℓ from decoder self-attention, linearly in ℓF from cross-attention with encoder outputs, and linearly in ℓd ff ,d from feed-forw ard layers over N d decoder layers. The decoder cost under gener- ation in Eq. 16, C dec - gen ( ℓ, F ) , has the same asymptotic form as teacher forcing since autoregressi ve decoding still requires self-attention, cross-attention, and feed-forward passes, though ke y–value caching can reduce constants in practice. In both modes, an additional O ( ℓV ) term arises from vocab ulary projection and softmax, which is signif- icant for large vocabularies but dominated by ℓ 2 self-attention when ℓ is large. Both Eq. 15 and Eq. 16 scale as ℓ 2 (self-attention) and as ℓF (cross-attention). The v ocab- ulary projection/softmax adds O ( ℓV ) per forward/backward; we keep it e xplicit when informativ e. Loss conditioning and r euse of passes. Eqs. 5 and 9 are cross-entropy (CE) objec- tiv es and must be computed under teacher forcing to provide stable gradients. W e assume CE terms use teacher forcing throughout. For Eq. 6, we define P v L at the last teacher-for ced position (so L = ¯ ℓ m in Stage 2). W ith Algorithm 1 summing L EOS + L REDO each Stage 2 step, both losses share one forw ard/backward pass at length ¯ ℓ m ; no additional pass is required for EOS. Attack-time complexity Stage 1 (Accuracy; K a steps). Each step backpropagates L acc (Eq. 5) under teacher forcing on Y of length L acc = | Y | : C (1) step = κ [ C enc ( F ) + C dec - TF ( L acc , F )] + O ( L acc V ) . (17) Optional early-stopping ev aluations (e.g., greedy WER every E steps) add C ev al,S1 ≈ l K a E m · C enc ( F ) + C dec - gen ( L ev al , F ) + O ( L ev al V ) , (18) where L ev al is the decoded length at ev aluation. 21 Stage 2 (Efficiency; K − K a steps). Stage 2 consists of M blocks of D steps. In each block m : • Gr eedy anchor (once per block). Build ¯ Y ( m ) by decoding ˆ Y ( m ) and doubling (Eq. 8): C (2) greedy ,m = C enc ( F ) + C dec - gen ( L gen m , F ) + O ( L gen m V ) , with L gen m ≈ L m . (19) • PGD steps (every step in the block). Algorithm 1 uses the sum L EOS + L REDO each step, with teacher-forced length ¯ ℓ m = 2 L m . Hence, per step: C (2) step ( m ) = κ C enc ( F ) + C dec - TF ( ¯ ℓ m , F ) + O ( ¯ ℓ m V ) , (20) and ov er D steps: C (2) block ( m ) = D C (2) step ( m ) = D κ [ C enc ( F ) + C dec - TF (2 L m , F )] + O ( D 2 L m V ) . (21) Summing ov er blocks, C Stage2 = M X m =1 C (2) greedy ,m + C (2) block ( m ) = κ ( K − K a ) C enc ( F ) | {z } encoder re-run each PGD step + κN d M X m =1 h D (2 L m ) 2 d d + D (2 L m ) ( F d d + d d d ff ,d ) i + M X m =1 C (2) greedy ,m + O V M X m =1 D (2 L m + L gen m ) . (22) Gro wth en velopes for L m . The doubled-target curriculum encourages L m to in- crease across blocks. • Geometric (until cap). In this case, L m grows by doubling until it reaches the cap L max : L m = min { L 0 2 m − 1 , L max } , (23) M ⋆ = min n M , 1+ ⌊ log 2 ( L max /L 0 ) ⌋ o . (24) Then the sums are M X m =1 L m = L 0 (2 M ⋆ − 1) + ( M − M ⋆ ) L max , (25) M X m =1 L 2 m = L 2 0 3 (4 M ⋆ − 1) + ( M − M ⋆ ) L 2 max . (26) Plugging into Eq. 22, the self-attention term scales as Θ D · 4 M ⋆ before saturation at L max . 22 • Linear (until cap). If L m = L 0 + ( m − 1)∆ (capped at L max ), then the uncapped sums are M X m =1 L m = M 2 2 L 0 + ( M − 1)∆ , (27) M X m =1 L 2 m = M L 2 0 + L 0 ∆ M ( M − 1) + ∆ 2 6 ( M − 1) M (2 M − 1) . (28) Here the dominant term in the self-attention sum is Θ( D M 3 ∆ 2 ) when ∆ > 0 . T otal attack-time cost. Combining stages, C attack = κK a [ C enc ( F ) + C dec - TF ( L acc , F )] + C ev al,S1 + C Stage2 , (29) with C Stage2 calculated from Eq. 22. The PGD update is O ( T ) and ne gligible. V ictim-time (inference) complexity When decoding on X + δ without backprop, expected per -example compute is C infer ( ℓ adv ) = C enc ( F ) + C dec - gen ( ℓ adv , F ) + O ( ℓ adv V ) , (30) where ℓ adv is the induced output length under the chosen decoding policy (greedy by default). Focusing on decoder -dominant terms, the slo wdo wn relativ e to the clean case ( ℓ clean ) is C infer ( ℓ adv ) C infer ( ℓ clean ) ≈ ℓ 2 adv + ℓ adv F + ℓ adv d ff ,d d d ℓ 2 clean + ℓ clean F + ℓ clean d ff ,d d d , highlighting quadratic sensitivity to ℓ adv from decoder self-attention. Under the ge- ometric en velope above, ℓ adv can grow proportionally to 2 M ⋆ L 0 until capped by the implementation’ s maximum length, potentially yielding a Θ(4 M ⋆ ) increase in decoder FLOPs before saturation. Summary bound. With M = ⌈ ( K − K a ) /D ⌉ and ¯ ℓ m = 2 L m , the attack-time com- pute admits C attack ∈ O κK C enc ( F ) + κN d D M X m =1 ¯ ℓ 2 m |{z} 4 L 2 m d d + ¯ ℓ m ( F d d + d d d ff ,d ) + M X m =1 C (2) greedy ,m + V · D M X m =1 ¯ ℓ m . (31) This bound separates: (i) repeated encoder passes linear in K and F ; (ii) decoder self- attention terms growing with P m L 2 m (the principal driv er under elongation); and (iii) vocab ulary and greedy-decoding ov erheads linear in sequence length and V . 23 T able 7: Estimated per -example inference FLOPs (in billions) for Whisper under base- line decoding vs. MORE on LibriSpeech, using standard Transformer FLOPs esti- mates [1]. Model Params (M) Baseline tok ens (avg) MORE tokens (avg) Baseline FLOPs (G) MORE FLOPs (G) × Increase Tin y 39 22 296 1.7 23.1 13 . 5 × Base 74 22 300 3.3 44.4 13 . 6 × Small 244 22 214 10.7 104.4 9 . 7 × Medium 769 22 234 33.8 359.9 10 . 6 × Large 1550 22 301 68.2 933.1 13 . 7 × C Additional Efficiency Analysis of MORE T o complement our analysis based on output length, we provide a more explicit charac- terization of the computational ov erhead induced by MORE in terms of floating-point operations (FLOPs). C.1 Estimated Inference FLOPs Under MORE vs. Baselines Follo wing standard FLOPs estimates for T ransformer models, i.e., approximately 2 · N FLOPs per generated token for a model with N parameters [4], we approximate the per-e xample inference cost (encoder + decoder) for Whisper . Since the encoder runs once per utterance while the decoder runs once per output token, the relative increase in FLOPs is dominated by the increase in output length caused by MORE. In typical (non- attack) conditions on LibriSpeech, Whisper produces transcriptions roughly the same length as the reference transcript—about 22 tok ens on a verage per utterance. Based on T able 1, MORE can induce 10 × to 14 × longer transcripts compared to normal outputs across different Whisper model sizes. Using the parameter sizes of Whisper models and the av erage output lengths observed in our experiments, we obtain the following per-e xample FLOP on the LibriSpeech dataset. Here we approximate (1) FLOPs per token ≈ 2 · N params ; (2) T otal FLOPs per example ≈ FLOPs encoder + (# tokens ) · 2 · N params . And we use the empirical baseline vs. MORE token lengths from our experiments. These estimates sho w that, across all Whisper sizes, MORE increases per -example inference compute by roughly an order of magnitude ( ≈ 9 – 14 × ), purely by forcing the model to generate much longer , repetiti ve transcripts. This quantifies an efficiency vulnerability : MORE does not just degrade accuracy , b ut also inflates the FLOPs required for inference, threatening the real-time and resource efficienc y of ASR deployments. C.2 Analysis of ASR Inference T ime In Fig. 2, we profile the inference time of the Whisper-Large model as a function of the number of output tokens. The inference time increases almost linearly with the output length. Moreover , Whisper-Lar ge pads all inputs shorter than 30 seconds to a fix ed 30- second window before processing, so utterances shorter than 30 seconds incur identical encoding time, making the output length the only factor that determines the overall 24 0 100 200 300 400 # Output T ok ens 0 1 2 3 4 5 6 7 8 Infer ence T ime (s) Figure 2: Inference Time of Whisper -large v ersus output length. resource consumption. These observations support our motiv ation to maximize the output length in order to induce the greatest possible waste of computational resources. D The Use of Large Language Models W e used a large language model (ChatGPT) solely as a writing assist tool for grammar checking, wording consistency , and style polishing of author -written text. All techni- cal content, results, and conclusions originate from the authors. Suggested edits were revie wed by the authors for accuracy and appropriateness before inclusion. No con- fidential or proprietary data beyond manuscript text was provided to the tool. This disclosure is made in accordance with the venue’ s policy on LLM usage. 25
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment