Improving Code-Switching Speech Recognition with TTS Data Augmentation
Automatic speech recognition (ASR) for conversational code-switching speech remains challenging due to the scarcity of realistic, high-quality labeled speech data. This paper explores multilingual text-to-speech (TTS) models as an effective data augmentation technique to address this shortage. Specifically, we fine-tune the multilingual CosyVoice2 TTS model on the SEAME dataset to generate synthetic conversational Chinese-English code-switching speech, significantly increasing the quantity and speaker diversity of available training data. Our experiments demonstrate that augmenting real speech with synthetic speech reduces the mixed error rate (MER) from 12.1% to 10.1% on DevMan and from 17.8% to 16.0% on DevSGE, indicating performance gains. These results confirm that multilingual TTS is an effective and practical tool for enhancing ASR robustness in low-resource, conversational code-switching scenarios.
💡 Research Summary
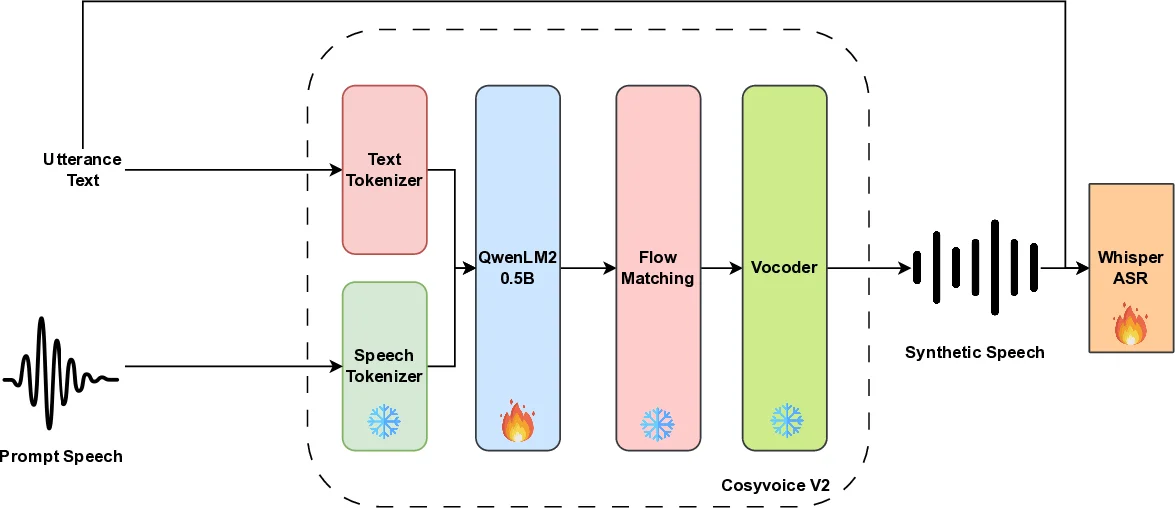
This paper tackles the persistent data‑scarcity problem in conversational code‑switching automatic speech recognition (ASR) by leveraging a state‑of‑the‑art multilingual text‑to‑speech (TTS) system, CosyVoice2, to generate high‑quality synthetic speech. The authors first fine‑tune only the language‑model component (QwenLM, 0.5 B parameters) of CosyVoice2 on the SEAME corpus, a 100‑hour collection of spontaneous Mandarin‑English code‑switching speech. By keeping the speech tokenizer, flow‑matching decoder, and vocoder fixed, the adaptation is computationally lightweight yet sufficient to capture the rapid intra‑sentence language alternations, informal lexical choices, and natural prosodic patterns characteristic of real conversational code‑switching.
After adaptation, each SEAME transcript is re‑synthesized multiple times using speaker embeddings (x‑vectors) sampled from a large pool, thereby creating a synthetic dataset with rich speaker diversity. Two synthetic variants are examined: TTS‑O, which re‑uses the original speaker embeddings, and TTS‑R, which replaces them with randomly sampled embeddings. The synthetic audio is mixed with the original 100 h of real speech and used to fine‑tune Whisper‑small, a 240 M‑parameter multilingual ASR model pre‑trained on 680 k h of multilingual audio.
Experimental results on the standard SEAME test sets (DevMan and DevSGE) demonstrate clear benefits. The baseline Whisper‑small fine‑tuned on real speech alone yields mixed‑error rates (MER) of 12.1 % (DevMan) and 17.8 % (DevSGE). Adding TTS‑O reduces MER to 11.1 % / 17.0 %, while the combination of real speech with TTS‑R achieves the best performance of 10.1 % / 16.0 %. Training on synthetic data alone (200 h of TTS‑R) underperforms the real‑only baseline, confirming that synthetic speech is most effective as a complementary resource rather than a full replacement.
A systematic study of synthetic data volume shows diminishing returns: increasing synthetic hours from 100 to 200 improves MER modestly, 300 h yields a further noticeable drop, but gains plateau beyond 400 h (improvements of ≤0.3 % MER). This suggests an optimal synthetic‑to‑real ratio of roughly 2–3 : 1, where most of the performance upside is captured without incurring excessive computational cost.
The authors also compare TTS‑based augmentation with conventional speed perturbation (±10 % tempo changes). Speed perturbation alone yields only marginal MER reductions, whereas TTS augmentation cuts MER by roughly one‑quarter relative to the baseline, making it the single most impactful technique. Combining both methods provides a small additional gain but at higher cost.
Crucially, the paper identifies speaker diversity as the key driver of improvement. Randomly sampled speaker embeddings (TTS‑R) consistently outperform the reuse of original speakers (TTS‑O), indicating that varied timbre, pitch, and speaking rate better prepare the ASR model for the acoustic variability encountered in real code‑switching conversations.
Finally, the authors transfer the fine‑tuned CosyVoice2 model to a different code‑switching corpus (ASCEND) and observe comparable MER reductions, demonstrating the generalizability of the pipeline across domains.
In summary, the work contributes (1) a lightweight domain‑adaptation strategy for large multilingual TTS models, (2) a systematic synthetic data generation process that emphasizes speaker diversity, and (3) extensive empirical evidence that such TTS‑augmented data substantially improves low‑resource conversational code‑switching ASR. The findings provide a practical roadmap for researchers and engineers seeking to boost multilingual ASR performance without costly new recordings.
Comments & Academic Discussion
Loading comments...
Leave a Comment