CETCAM: Camera-Controllable Video Generation via Consistent and Extensible Tokenization
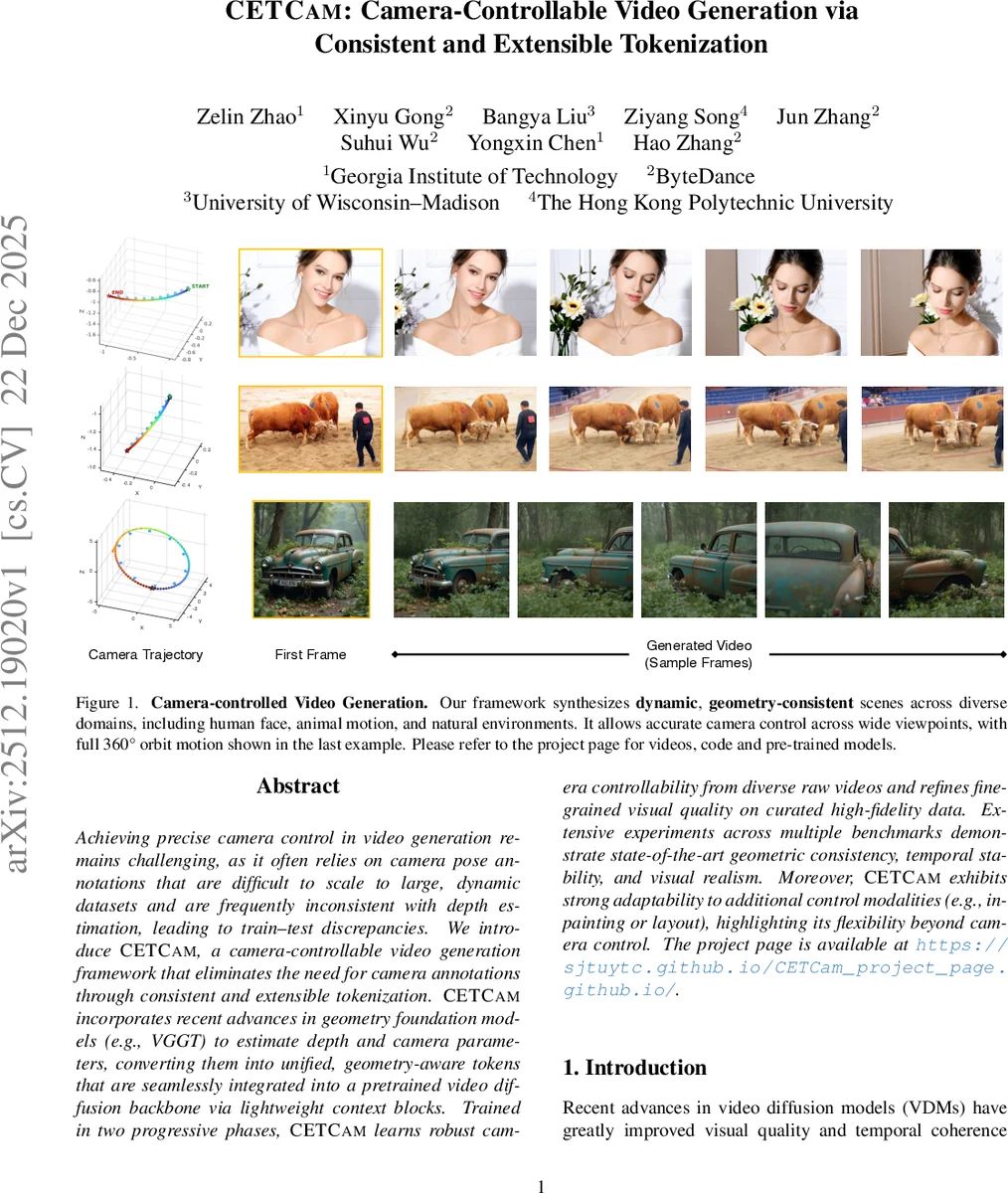
Achieving precise camera control in video generation remains challenging, as existing methods often rely on camera pose annotations that are difficult to scale to large and dynamic datasets and are frequently inconsistent with depth estimation, leading to train-test discrepancies. We introduce CETCAM, a camera-controllable video generation framework that eliminates the need for camera annotations through a consistent and extensible tokenization scheme. CETCAM leverages recent advances in geometry foundation models, such as VGGT, to estimate depth and camera parameters and converts them into unified, geometry-aware tokens. These tokens are seamlessly integrated into a pretrained video diffusion backbone via lightweight context blocks. Trained in two progressive stages, CETCAM first learns robust camera controllability from diverse raw video data and then refines fine-grained visual quality using curated high-fidelity datasets. Extensive experiments across multiple benchmarks demonstrate state-of-the-art geometric consistency, temporal stability, and visual realism. Moreover, CETCAM exhibits strong adaptability to additional control modalities, including inpainting and layout control, highlighting its flexibility beyond camera control. The project page is available at https://sjtuytc.github.io/CETCam_project_page.github.io/.
💡 Research Summary
CETCAM (Consistent and Extensible Tokenization for Camera‑controllable video generation) tackles the long‑standing problem of precise camera control in diffusion‑based video synthesis without relying on costly camera pose annotations. The core idea is to convert geometry information—depth maps and camera parameters—estimated by a frozen Visual Geometry Grounded Transformer (VGGT) into compact, geometry‑aware tokens. During training, raw “in‑the‑wild” videos are fed to VGGT, which jointly predicts per‑frame depth, extrinsics, and intrinsics. Using the first frame’s depth and intrinsics, a point‑cloud is back‑projected, then re‑projected into each target frame using the predicted extrinsics, yielding rendered views and binary visibility masks. The rendered images and masks are embedded via a learnable embedder (initialized from the WAN video embedder) to produce visual tokens, while the camera parameters (quaternion, translation, focal length) are linearly projected into camera tokens. Concatenating visual and camera tokens along the sequence dimension yields the final CETCAM token sequence.
These tokens are injected into a frozen, large‑scale video diffusion backbone (WAN‑DiT) through lightweight “CETCAM Context Blocks”. Each block consists of zero‑initialized linear layers that align token dimensions, followed by simple addition to the backbone’s internal representations. This design allows the backbone to remain untouched while still receiving rich 3D‑aware conditioning. The overall generation pipeline also incorporates other token types: noisy latents (the diffusion noise), Visual Condition Unit (VCU) tokens (text prompt, first‑frame image, mask), and optional VACE tokens for additional controls such as sketches, layouts, or inpainting masks. By treating all conditioning signals as tokens, CETCAM achieves a unified, compositional control interface.
Training proceeds in two stages. Stage 1 uses a large, diverse collection of raw videos to teach the model robust camera controllability across varied scenes and complex trajectories. Stage 2 fine‑tunes on a curated high‑fidelity dataset (e.g., the newly introduced HoIHQ benchmark) to boost visual fidelity and fine‑grained detail. Extensive quantitative evaluations on VBench, CameraBench, Uni3C‑OOD‑Challenging, and HoIHQ demonstrate that CETCAM surpasses prior methods (Uni3C, ReCam‑Master, Gen3C, EPiC) in geometric consistency, pose‑tracking error (over 15 % reduction), temporal stability, and perceptual quality (human scores improved by >6 %). Qualitative results show accurate 360° orbit motions and realistic dynamic scenes (human faces, animal motion, natural environments).
Beyond camera control, CETCAM’s token‑based architecture is inherently extensible. By integrating VACE tokens, the system can simultaneously handle inpainting, layout guidance, or other semantic conditions without redesigning the core model. This flexibility distinguishes CETCAM from earlier camera‑specific frameworks that required separate pipelines for each modality.
In summary, CETCAM introduces a novel, annotation‑free tokenization pipeline that bridges geometry estimation and diffusion video synthesis, enabling precise, scalable camera control while preserving the expressive power of large pretrained video diffusion models. Its two‑stage training, lightweight context integration, and composable token interface make it a strong foundation for future multi‑modal video generation, virtual‑reality content creation, and advanced video editing applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment