We Can Hide More Bits: The Unused Watermarking Capacity in Theory and in Practice
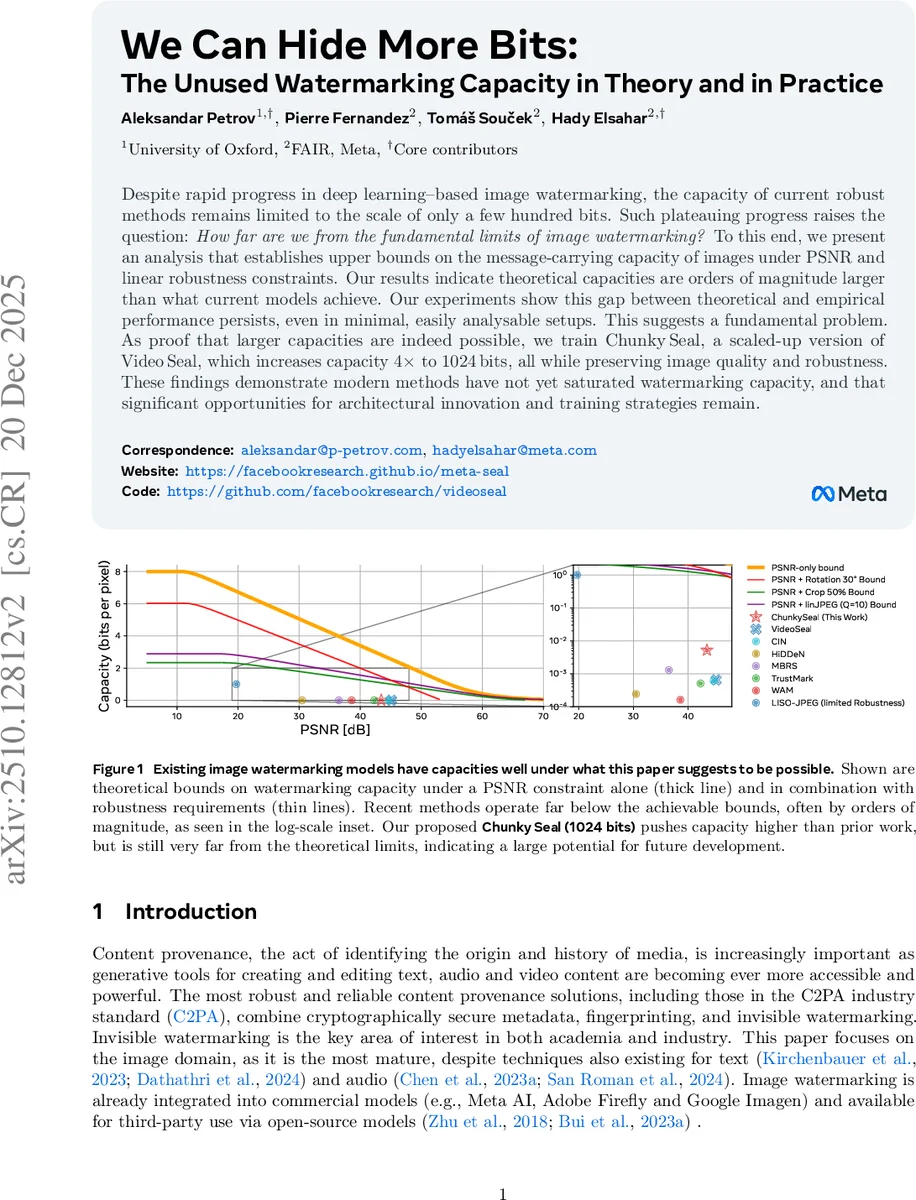
Despite rapid progress in deep learning-based image watermarking, the capacity of current robust methods remains limited to the scale of only a few hundred bits. Such plateauing progress raises the question: How far are we from the fundamental limits of image watermarking? To this end, we present an analysis that establishes upper bounds on the message-carrying capacity of images under PSNR and linear robustness constraints. Our results indicate theoretical capacities are orders of magnitude larger than what current models achieve. Our experiments show this gap between theoretical and empirical performance persists, even in minimal, easily analysable setups. This suggests a fundamental problem. As proof that larger capacities are indeed possible, we train ChunkySeal, a scaled-up version of VideoSeal, which increases capacity 4 times to 1024 bits, all while preserving image quality and robustness. These findings demonstrate modern methods have not yet saturated watermarking capacity, and that significant opportunities for architectural innovation and training strategies remain.
💡 Research Summary
The paper investigates the gap between the theoretical limits of image watermarking capacity and the performance of current deep‑learning based watermarking methods. While recent neural approaches can embed only a few hundred bits into an image while preserving visual quality (typically PSNR > 40 dB) and robustness to common attacks, it is unclear whether this plateau reflects a fundamental ceiling or merely an under‑exploited potential.
To answer this, the authors first develop a rigorous information‑theoretic framework that treats an image as a point on a high‑dimensional integer lattice. The absolute capacity of an image format (c channels, width w, height h, k‑bit depth) is simply the logarithm of the total number of possible pixel configurations, i.e., cw h k bits. This trivial bound corresponds to the raw uncompressed size of the image (e.g., ~1.57 Mbit for a 256 × 256 8‑bit colour image).
Next, they impose a perceptual constraint using Peak Signal‑to‑Noise Ratio (PSNR). By converting a minimum PSNR τ into an ℓ₂‑ball of radius ϵ(τ) = ρ √(c w h) · 10^{‑τ/20} (where ρ = 2^k − 1), the set of admissible watermarked images becomes the intersection of this ball with the hyper‑cube that represents all valid pixel values. The authors analyze three regimes: (1) low τ where the ball fully contains the cube (capacity reduces to the absolute bound), (2) high τ where the ball lies entirely inside the cube (capacity equals the number of integer lattice points inside the ball), and (3) intermediate τ where the ball partially overlaps the cube (capacity is bounded by the volume of the intersection). Closed‑form approximations are derived using sphere‑packing arguments and lattice‑point counting techniques.
To capture robustness, the analysis is extended to linear geometric attacks: rotations, cropping, and JPEG compression. Each attack is modeled as a transformation that maps the original ℓ₂‑ball to another region in the lattice; the robust capacity is then the number of lattice points that survive the intersection of all transformed balls with the PSNR ball. The resulting bounds show that even under a combination of PSNR ≥ 40 dB, 30° rotation, 50 % cropping, and JPEG quality = 10, the theoretical capacity remains on the order of 10⁵–10⁶ bits for typical image sizes—orders of magnitude larger than what existing methods achieve.
Empirically, the authors retrain VideoSeal, a state‑of‑the‑art image/video watermarking model, under the simplest PSNR‑only setting. VideoSeal fails to embed 1024 bits, and even a naïve linear model can only embed 2048 bits by tiling low‑resolution watermarks, while a handcrafted scheme reaches about 456 k bits. This demonstrates that current architectures are structurally limited and do not fully exploit the available lattice space.
To prove that higher capacities are attainable, the authors introduce ChunkySeal, a scaled‑up version of VideoSeal. By quadrupling channel width, resolution, and network depth, and training with a loss that jointly enforces PSNR ≥ 40 dB and robustness to the same set of attacks, ChunkySeal successfully embeds 1024 bits. It maintains comparable visual quality (PSNR ≈ 40 dB) and similar robustness metrics to the original model. However, its capacity still falls far short of the theoretical upper bounds, confirming a large untapped potential.
The paper concludes that modern image watermarking has not reached its fundamental capacity ceiling; instead, there exists a substantial “unused” capacity gap. Closing this gap will likely require novel architectural designs that better utilize the high‑dimensional integer lattice, more sophisticated loss functions that directly target lattice‑point density, and training strategies that explicitly account for geometric transformations. The work opens a clear research agenda: develop watermarking systems that approach the information‑theoretic limits while preserving imperceptibility and robustness, thereby enabling far richer provenance and ownership tagging for visual media.
Comments & Academic Discussion
Loading comments...
Leave a Comment