Bandwidth-Efficient Adaptive Mixture-of-Experts via Low-Rank Compensation
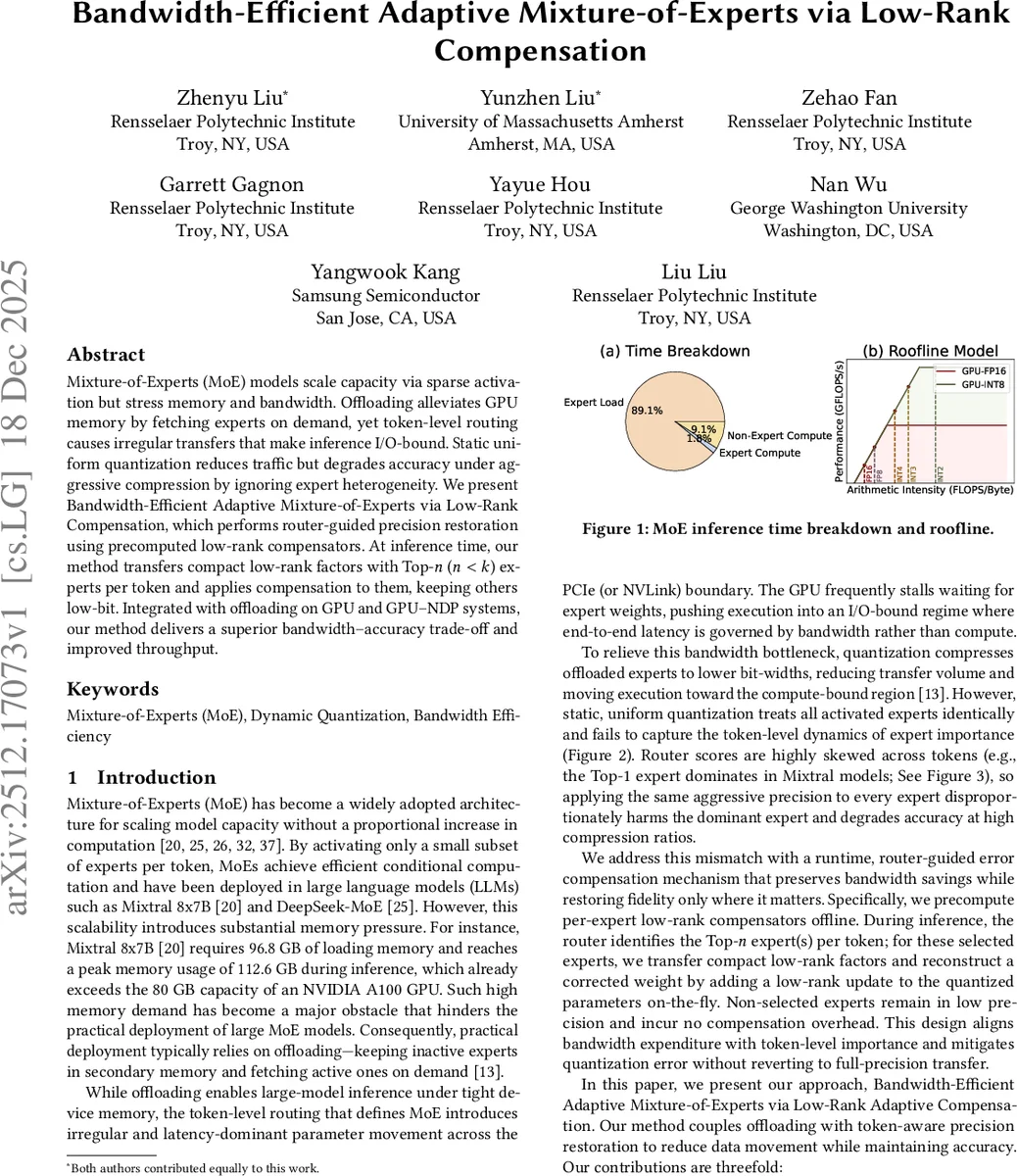
Mixture-of-Experts (MoE) models scale capacity via sparse activation but stress memory and bandwidth. Offloading alleviates GPU memory by fetching experts on demand, yet token-level routing causes irregular transfers that make inference I/O-bound. Static uniform quantization reduces traffic but degrades accuracy under aggressive compression by ignoring expert heterogeneity. We present Bandwidth-Efficient Adaptive Mixture-of-Experts via Low-Rank Compensation, which performs router-guided precision restoration using precomputed low-rank compensators. At inference time, our method transfers compact low-rank factors with Top-n (n<k) experts per token and applies compensation to them, keeping others low-bit. Integrated with offloading on GPU and GPU-NDP systems, our method delivers a superior bandwidth-accuracy trade-off and improved throughput.
💡 Research Summary
Mixture‑of‑Experts (MoE) models achieve large model capacity by activating only a few experts per token, but this conditional computation creates two practical bottlenecks during inference. First, the total number of expert parameters far exceeds GPU memory, so offloading is required: expert weights reside in host or CPU memory and are fetched on‑demand. Second, token‑level routing leads to irregular, latency‑dominant data movement; the GPU often stalls waiting for expert weights, making inference I/O‑bound. Quantizing offloaded experts to low‑bit formats (e.g., INT2, INT3) reduces the transfer volume, but uniform quantization treats all activated experts equally. Because routing scores are highly skewed—top‑1 or top‑2 experts receive a large fraction of the weight—aggressive compression of these dominant experts causes disproportionate accuracy loss.
The paper proposes “Bandwidth‑Efficient Adaptive Mixture‑of‑Experts via Low‑Rank Compensation” (BE‑AMoE‑LRC), which restores precision only for the most important experts while keeping others in low‑bit form. The method consists of two complementary components:
-
Kurtosis‑Guided Rank Allocation
- For each expert weight matrix (W_i), the authors compute the statistical kurtosis (\kappa_i) of its elements. Empirically, higher kurtosis correlates with larger quantization residuals (|E_i|_F / |W_i|_F).
- A small set of rank buckets ({0,16,32,128,256,512,1024}) is defined. Experts are sorted by decreasing (\kappa_i) and assigned the largest feasible bucket such that the global average rank budget (R_{\text{avg}}) is respected. High‑kurtosis experts receive larger low‑rank compensators, low‑kurtosis experts may receive none.
- After quantizing all experts with a high‑quality quantizer (HQQ), the residual (E_i = W_i - Q^{-1}(Q(W_i))) is factorized by truncated SVD of rank (r_i): (E_i \approx U_i V_i). The factors are re‑parameterized as (U_i \leftarrow U_i \Sigma_i) and (V_i \leftarrow \Sigma_i V_i^\top), then quantized (INT3/INT4) and stored offline as the low‑rank compensator for expert (i).
-
Router‑Guided Dynamic Precision Restoration
- During inference, the router produces a score vector for each token. The top‑(n) experts (with (n < k), where (k) is the usual number of activated experts) are selected.
- For these top‑(n) experts, both the quantized weight (Q^{-1}(Q(W_e))) and the pre‑computed low‑rank factors ((U_e, V_e)) are transferred from host/CPU memory to the GPU. The compensated weight is reconstructed on‑device as (\hat{W}_e = Q^{-1}(Q(W_e)) + U_e V_e).
- All other activated experts remain in their low‑bit dequantized form without compensation, drastically reducing bandwidth usage. Because only a few experts per token require compensation, the method aligns data movement with token‑level importance.
System Integration and Evaluation
The authors integrate BE‑AMoE‑LRC into two hardware settings: (1) a GPU‑only system (NVIDIA H100 PCIe) and (2) a GPU‑Near‑Data‑Processing (GPU‑NDP) system where a memory‑side processing unit can host the low‑rank factors. Experiments cover three state‑of‑the‑art MoE LLMs—Mixtral‑8×7B, Mixtral‑8×22B, and DeepSeek‑MoE‑16B—using the C4 calibration set to compute kurtosis and routing statistics, and a suite of downstream benchmarks (MMLU, MathQA, HellaSwag, etc.) for accuracy.
Key results include:
- Accuracy: Compared with uniform INT2/INT3 quantization, BE‑AMoE‑LRC reduces perplexity degradation by 0.3–0.7% absolute and improves downstream task scores by similar margins. The benefit is most pronounced when only the top‑1 expert is compensated.
- Bandwidth and Throughput: By sending low‑rank factors only for top‑(n) experts, the total data transferred per token drops to 30–45% of the baseline low‑bit offloading. End‑to‑end latency improves 1.4×–2.1×, and throughput (tokens/s) scales accordingly. In the GPU‑NDP configuration, additional gains arise because the compensators are applied directly in memory, further cutting PCIe traffic.
- Ablation Studies: The paper evaluates (a) uniform vs. kurtosis‑guided rank allocation, showing the latter yields up to 0.2% higher accuracy under the same rank budget; (b) varying (n) (top‑1, top‑2, top‑3) and observing diminishing returns beyond top‑2; (c) different bucket configurations, confirming that a modest set of buckets suffices. Sensitivity to the average rank budget (R_{\text{avg}}) is also reported, illustrating a smooth trade‑off between bandwidth and accuracy.
Strengths and Limitations
BE‑AMoE‑LRC cleverly exploits two intrinsic properties of MoE inference: (i) expert heterogeneity captured by kurtosis, and (ii) the highly skewed routing distribution. By aligning low‑rank compensation with these properties, the method achieves a superior bandwidth‑accuracy trade‑off without requiring changes to the model architecture or training pipeline. The offline computation of compensators is a one‑time cost, and the runtime overhead is limited to transferring a few small matrices per token.
Potential limitations include the storage overhead of low‑rank factors for very large expert pools (thousands of experts), and the reliance on accurate routing scores at inference time; if the router’s predictions are noisy, the selected top‑(n) may not correspond to the truly most sensitive experts. Future work could explore adaptive selection of (n), dynamic rank scaling, or joint training of compensators to further reduce storage.
Conclusion
The paper presents a practical, system‑aware solution for accelerating offloaded MoE inference. By combining kurtosis‑guided low‑rank compensation with router‑guided selective precision restoration, it reduces offload traffic dramatically while preserving—or even improving—model accuracy. The approach is validated across multiple large‑scale MoE models, hardware platforms, and benchmark tasks, establishing a new baseline for bandwidth‑efficient MoE deployment.
Comments & Academic Discussion
Loading comments...
Leave a Comment