Scaling Laws for Black box Adversarial Attacks
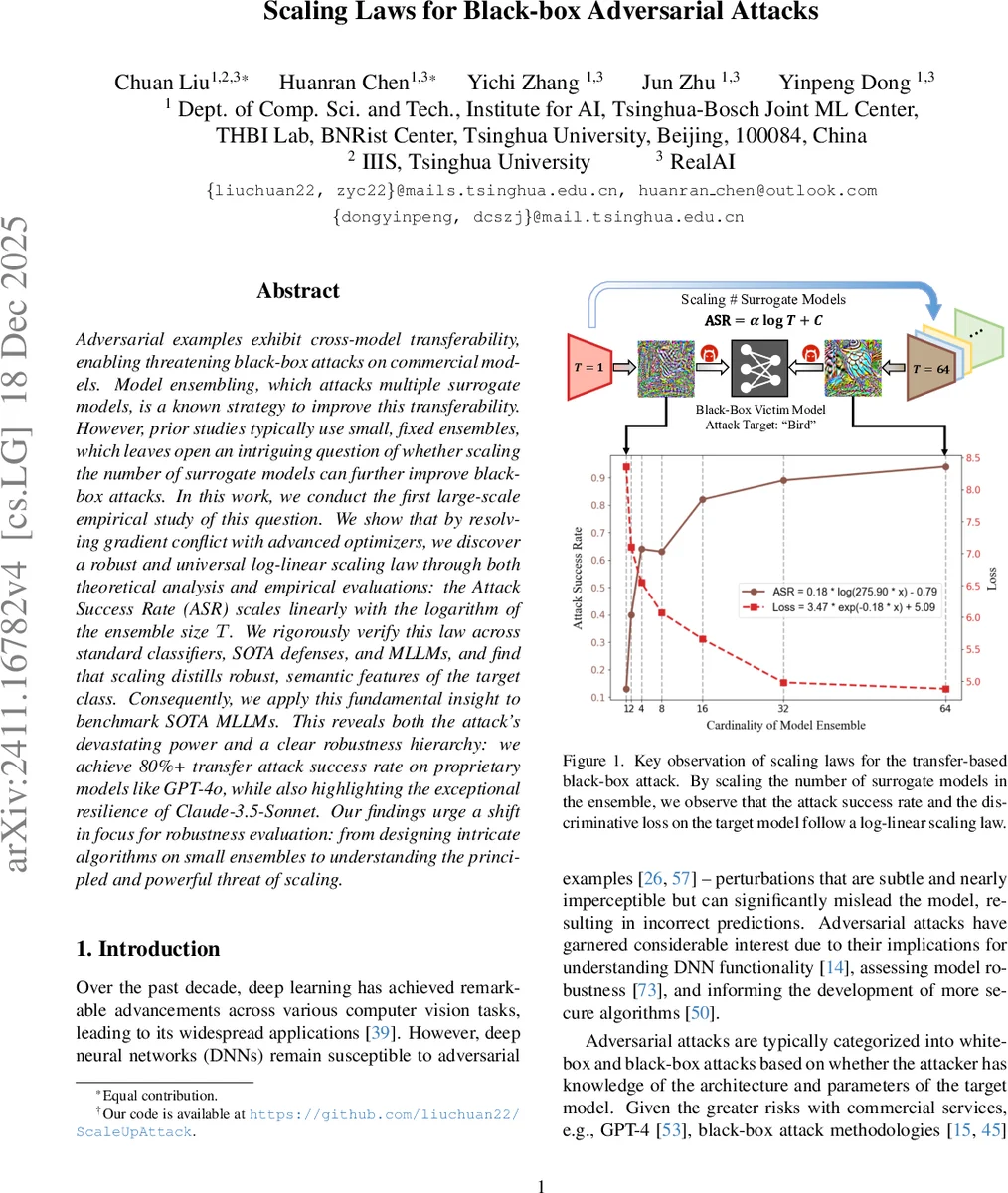
Adversarial examples exhibit cross-model transferability, enabling threatening black-box attacks on commercial models. Model ensembling, which attacks multiple surrogate models, is a known strategy to improve this transferability. However, prior studies typically use small, fixed ensembles, which leaves open an intriguing question of whether scaling the number of surrogate models can further improve black-box attacks. In this work, we conduct the first large-scale empirical study of this question. We show that by resolving gradient conflict with advanced optimizers, we discover a robust and universal log-linear scaling law through both theoretical analysis and empirical evaluations: the Attack Success Rate (ASR) scales linearly with the logarithm of the ensemble size $T$. We rigorously verify this law across standard classifiers, SOTA defenses, and MLLMs, and find that scaling distills robust, semantic features of the target class. Consequently, we apply this fundamental insight to benchmark SOTA MLLMs. This reveals both the attack’s devastating power and a clear robustness hierarchy: we achieve 80%+ transfer attack success rate on proprietary models like GPT-4o, while also highlighting the exceptional resilience of Claude-3.5-Sonnet. Our findings urge a shift in focus for robustness evaluation: from designing intricate algorithms on small ensembles to understanding the principled and powerful threat of scaling.
💡 Research Summary
The paper investigates whether increasing the number of surrogate models in an ensemble can systematically improve the transferability of black‑box adversarial attacks. While prior work has shown that ensembling a few (typically 2–5) surrogate models can boost attack success, the effect of scaling the ensemble size has not been studied. The authors first identify a fundamental obstacle: as the number of surrogates grows, the gradients contributed by each model tend to point in different directions, causing a “gradient‑conflict” that collapses the norm of the ensemble gradient and stalls optimization. To overcome this, they adopt a state‑of‑the‑art optimizer that combines Spectrum Simulation Attack (SSA) – an input‑transformation technique that diversifies the loss landscape – with the Common Weakness Attack (CWA) – a method that aligns gradients by minimizing a second‑order Taylor expansion of each model’s loss. This hybrid SSA‑CWA algorithm both mitigates gradient conflict and achieves top‑tier transfer performance.
Theoretical analysis treats the surrogate models as i.i.d. samples from a distribution over classifiers. Under this idealized setting, the authors prove two theorems: (1) the adversarial example generated from an ensemble of size T converges to the true population optimum at a rate O(1/√T); (2) the difference between the empirical loss (averaged over the ensemble) and the population loss shrinks at O(1/T). Although real surrogate models are not truly independent, these results provide a qualitative justification that larger ensembles should close the gap between surrogate‑based optimization and the true black‑box objective.
Empirically, the authors construct a pool of 64 diverse image classifiers (AlexNet, ResNet, ViT, DeiT, EfficientNet, etc.) and sample ensembles of size T ranging from 1 (2⁰) to 64 (2⁶) on a logarithmic scale. For each T they generate a fixed set of adversarial images using SSA‑CWA for 40 iterations under an ℓ∞ budget of ε = 8/255. They then evaluate the same adversarial set against three families of target models:
- Standard image classifiers – seven popular architectures (Swin‑Transformer variants, ConvNeXt, ResNeXt, etc.).
- State‑of‑the‑art defended models – including adversarially trained and ensemble‑adversarial‑trained networks.
- Multimodal large language models (MLLMs) – vision encoders of CLIP‑based systems such as GPT‑4o, Qwen‑VL‑235B, Gemini‑2.5‑Pro, and Claude‑3.5‑Sonnet.
Across all families, two metrics are tracked: Attack Success Rate (ASR) and the average cross‑entropy loss on the target model. Both metrics exhibit a striking log‑linear relationship with ensemble size: plotting ASR (or loss) against log₂ T yields an almost perfect straight line (R² > 0.98). When T reaches 32 or 64, ASR surpasses 70 % for standard classifiers and exceeds 80 % for many defended models, a three‑fold improvement over the best small‑ensemble baselines reported in prior literature. The scaling law holds for untargeted attacks as well, though the slope is slightly lower.
A qualitative analysis shows that as T grows, the optimizer discards model‑specific, non‑robust high‑frequency perturbations and instead learns perturbations that align with semantic features of the target class (e.g., shape, color, texture of a “bird”). This “feature distillation” explains why larger ensembles produce more universally transferable adversarial patterns.
When applied to MLLMs, the scaling law remains effective. The authors achieve 85 %–90 % transfer success against GPT‑4o and Qwen‑VL‑235B, while Claude‑3.5‑Sonnet shows markedly lower susceptibility (<30 %). These results reveal a clear robustness hierarchy among commercial multimodal models and demonstrate that scaling the surrogate ensemble is a potent tool for benchmarking their security.
In conclusion, the paper establishes a universal log‑linear scaling law for black‑box adversarial attacks: ASR ≈ a · log₂ T + b, where a and b are model‑dependent constants. The law is validated across standard classifiers, advanced defenses, and cutting‑edge multimodal systems. The authors argue that the community should shift focus from designing ever more intricate attack algorithms on tiny ensembles to understanding and defending against the fundamentally powerful threat posed by large‑scale surrogate ensembling. Future directions include (i) modeling correlations among surrogate models to select optimal subsets under computational constraints, (ii) developing defenses that specifically target the log‑linear scaling effect, and (iii) extending the analysis to other modalities such as audio or text.
Comments & Academic Discussion
Loading comments...
Leave a Comment