Arbitrary Entropy Policy Optimization Breaks The Exploration Bottleneck of Reinforcement Learning
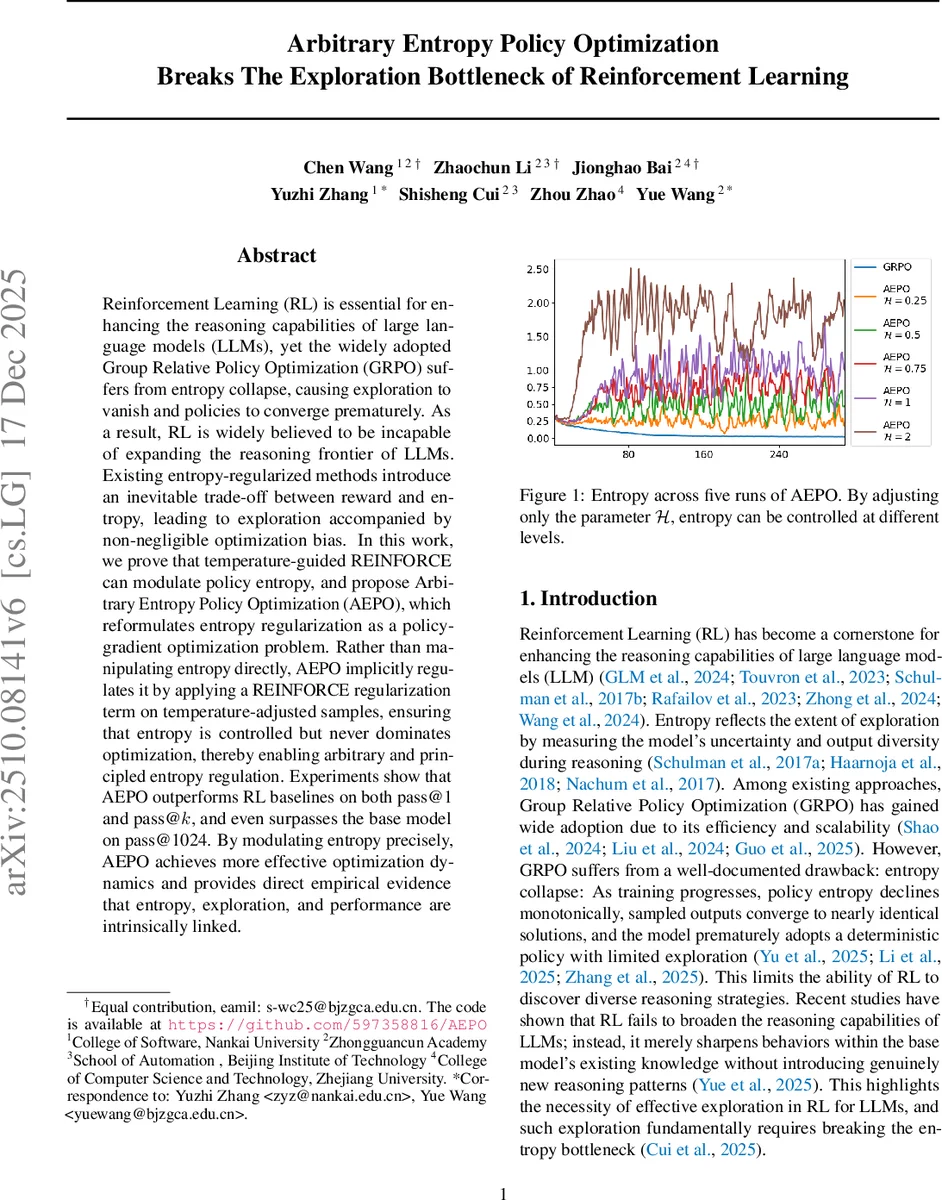
Reinforcement Learning (RL) is essential for enhancing the reasoning capabilities of large language models (LLMs), yet the widely adopted Group Relative Policy Optimization (GRPO) suffers from entropy collapse, causing exploration to vanish and policies to converge prematurely. As a result, RL is widely believed to be incapable of expanding the reasoning frontier of LLMs. Existing entropy-regularized methods introduce an inevitable trade-off between reward and entropy, leading to exploration accompanied by non-negligible optimization bias. In this work, we prove that temperature-guided REINFORCE can modulate policy entropy, and propose Arbitrary Entropy Policy Optimization (AEPO), which reformulates entropy regularization as a policy-gradient optimization problem. Rather than manipulating entropy directly, AEPO implicitly regulates it by applying a REINFORCE regularization term on temperature-adjusted samples, ensuring that entropy is controlled but never dominates optimization, thereby enabling arbitrary and principled entropy regulation. Experiments show that AEPO outperforms RL baselines on both pass@1 and pass@$k$, and even surpasses the base model on pass@1024. By modulating entropy precisely, AEPO achieves more effective optimization dynamics and provides direct empirical evidence that entropy, exploration, and performance are intrinsically linked.
💡 Research Summary
The paper addresses a critical bottleneck in Reinforcement Learning (RL) for Large Language Models (LLMs): the “entropy collapse” phenomenon observed in widely-used algorithms like Group Relative Policy Optimization (GRCO). As RL progresses, the policy’s entropy tends to decrease rapidly, leading to a loss of exploration capability. This prevents the model from discovering new, complex reasoning paths, effectively capping the expansion of the LLM’s reasoning frontier.
The authors identify a fundamental flaw in existing entropy-regularized methods. Traditional approaches attempt to balance reward maximization and entropy maintenance by adding an entropy term to the loss function. However, this creates an inherent trade-off and introduces “optimization bias,” where the regularization term can interfere with the primary goal of reward maximization, or conversely, the drive for rewards leads to premature convergence.
To overcome this, the paper introduces Arbitrary Entropy Policy Optimization (AEPO). The core innovation lies in reformulating entropy regularization as a policy-gradient optimization problem rather than a direct penalty term. By utilizing a temperature-guided REINFORCE mechanism, AEPO applies a regularization term to temperature-adjusted samples. This allows for the implicit regulation of entropy. Unlike previous methods that manipulate entropy directly—often leading to optimization instability—AEPO ensures that entropy is controlled in a principled manner without dominating the overall optimization process. This enables “arbitrary” entropy regulation, allowing researchers to tune the level of exploration without sacrificing the integrity of the reward optimization.
The empirical results are highly significant. AEPO outperforms standard RL baselines in both pass@1 and pass@k metrics. Most strikingly, the model even surpasses the performance of the base model in the pass@1024 metric. This indicates that AEPO does not merely refine existing knowledge but actively enables the model to discover and master new reasoning trajectories that were previously inaccessible. The study provides definitive empirical evidence that entropy, exploration, and final performance are intrinsically linked, establishing AEPO as a powerful tool for pushing the boundaries of LLM reasoning capabilities.
Comments & Academic Discussion
Loading comments...
Leave a Comment