S2D: Sparse-To-Dense Keymask Distillation for Unsupervised Video Instance Segmentation
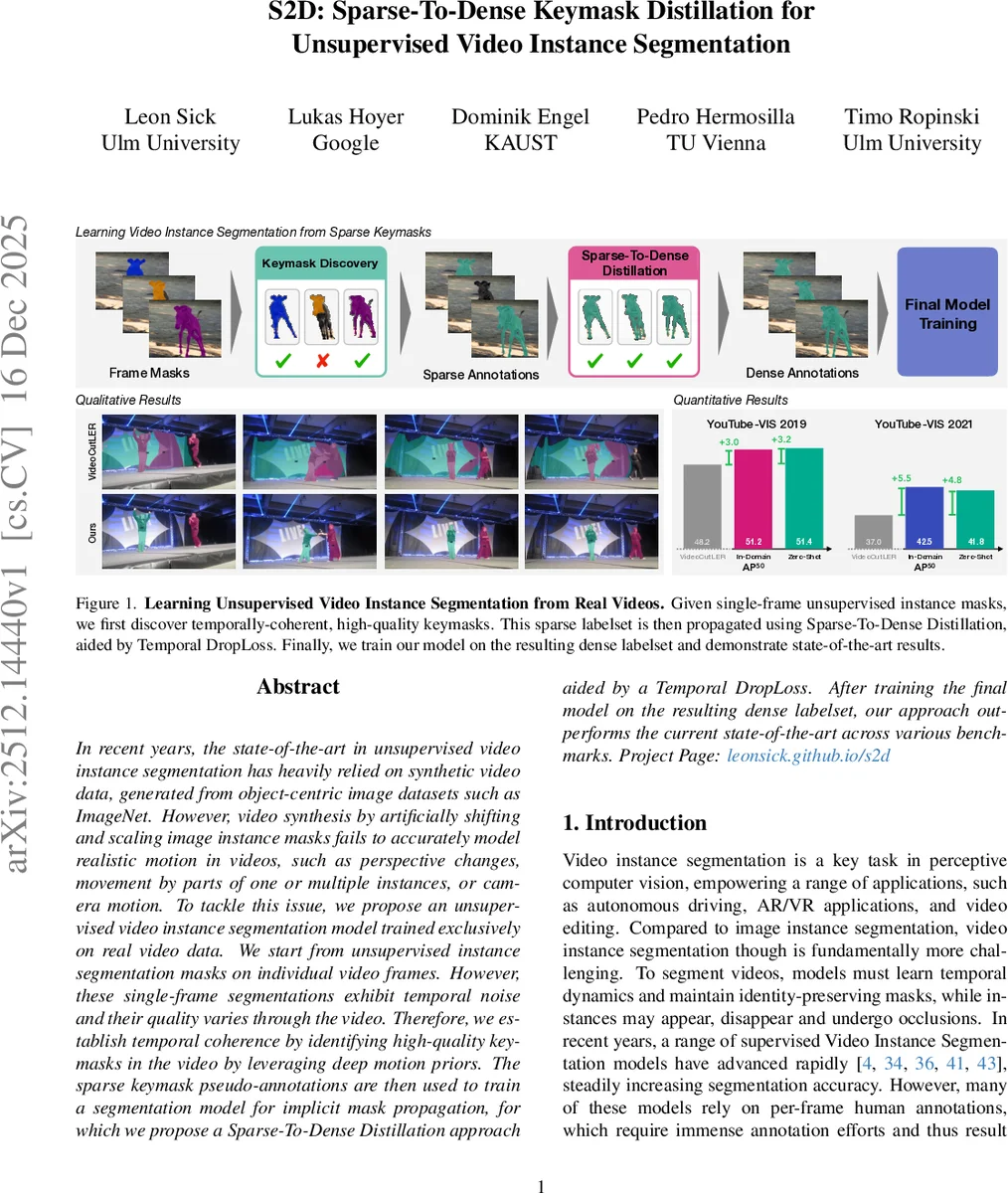
In recent years, the state-of-the-art in unsupervised video instance segmentation has heavily relied on synthetic video data, generated from object-centric image datasets such as ImageNet. However, video synthesis by artificially shifting and scaling image instance masks fails to accurately model realistic motion in videos, such as perspective changes, movement by parts of one or multiple instances, or camera motion. To tackle this issue, we propose an unsupervised video instance segmentation model trained exclusively on real video data. We start from unsupervised instance segmentation masks on individual video frames. However, these single-frame segmentations exhibit temporal noise and their quality varies through the video. Therefore, we establish temporal coherence by identifying high-quality keymasks in the video by leveraging deep motion priors. The sparse keymask pseudo-annotations are then used to train a segmentation model for implicit mask propagation, for which we propose a Sparse-To-Dense Distillation approach aided by a Temporal DropLoss. After training the final model on the resulting dense labelset, our approach outperforms the current state-of-the-art across various benchmarks.
💡 Research Summary
The paper introduces S2D (Sparse‑to‑Dense Keymask Distillation), a framework for unsupervised video instance segmentation (VIS) that relies solely on real video footage, eliminating the need for synthetic data. The authors start from frame‑wise unsupervised image instance masks generated by a model such as CutS3D. Because these masks are noisy and lack temporal consistency, the first contribution is a Keymask Discovery algorithm that extracts a sparse set of high‑quality, temporally coherent masks (keymasks).
Keymask discovery proceeds in two sub‑steps. First, each mask is equipped with a set of sampled points that are tracked forward and backward through the video using an off‑the‑shelf point tracker. From the visibility of these points a binary visibility vector is built for every mask. DBSCAN clustering on these vectors groups masks that appear and disappear together, forming “visibility groups”. This step filters out many noisy masks that have inconsistent visibility.
Second, within each visibility group the authors perform a Proxy Propagate‑And‑Match operation. Tracked points of a reference mask are projected onto other frames, and the overlap between the projected point set and candidate masks is measured by a Point‑Mask Jaccard index. When the index exceeds a (very low) threshold, a match is recorded. A second DBSCAN clustering on the resulting match matrix separates instances that share the same visibility window (e.g., two objects visible throughout the video). The outcome is a set of keymasks that are both spatially accurate and temporally aligned, albeit sparse in time.
Having obtained a sparse pseudo‑label set, the next challenge is to train a video segmentation model that can predict masks for every frame. The authors adopt VideoMask2Former as the backbone and propose two novel training mechanisms.
-
Temporal DropLoss – Traditional supervised losses penalize predictions on every frame, assuming ground‑truth exists everywhere. Since many frames lack annotations, Temporal DropLoss randomly drops the loss for unlabeled frames, forcing the network to focus on the labeled frames while still learning temporal dynamics from the video context.
-
Sparse‑to‑Dense Distillation – The keymasks serve as a teacher. A student network with the same architecture is trained to mimic the teacher’s dense predictions. The teacher is first trained on the sparse keymasks, producing dense pseudo‑labels for all frames. The student then learns from these dense labels, smoothing out remaining ambiguities. This two‑stage distillation converts the sparse supervision into a dense label set without any human annotation.
The final model, trained on the dense pseudo‑labels, achieves state‑of‑the‑art results on several VIS benchmarks. On YouTube‑VIS 2019 and 2021 it reaches AP50 scores of 51.2 % and 51.4 %, respectively, surpassing the previous best unsupervised method VideoCutLER (≈48 %). Moreover, when the training data is expanded beyond the in‑domain videos, the model exhibits strong zero‑shot performance on unseen datasets, confirming the scalability of the approach.
Ablation studies demonstrate that removing Temporal DropLoss degrades performance by 2–3 % points, and omitting the Proxy Propagate‑And‑Match step reduces the quality of keymasks, leading to lower final scores. Qualitative examples show that S2D produces finer, less noisy masks, especially for thin structures and objects undergoing complex motion.
The paper’s contributions are threefold: (1) a fully unsupervised keymask discovery pipeline that leverages point‑track based motion cues, (2) the Sparse‑to‑Dense Distillation framework with Temporal DropLoss for learning from sparse annotations, and (3) a VIS model trained exclusively on real videos that outperforms prior synthetic‑data‑driven methods. Limitations include dependence on the robustness of the point tracker and DBSCAN clustering; fast motions or severe occlusions may cause keymask extraction failures. Future work could integrate learned trackers and adaptive matching thresholds to improve resilience.
Overall, S2D establishes a new paradigm for unsupervised video instance segmentation: start with a few reliable masks, propagate them densely through a teacher‑student distillation process, and achieve high‑quality segmentation without any manual labeling. This opens the door to scaling VIS to massive, unlabeled video collections across diverse domains.
Comments & Academic Discussion
Loading comments...
Leave a Comment