VLM2GeoVec: Toward Universal Multimodal Embeddings for Remote Sensing
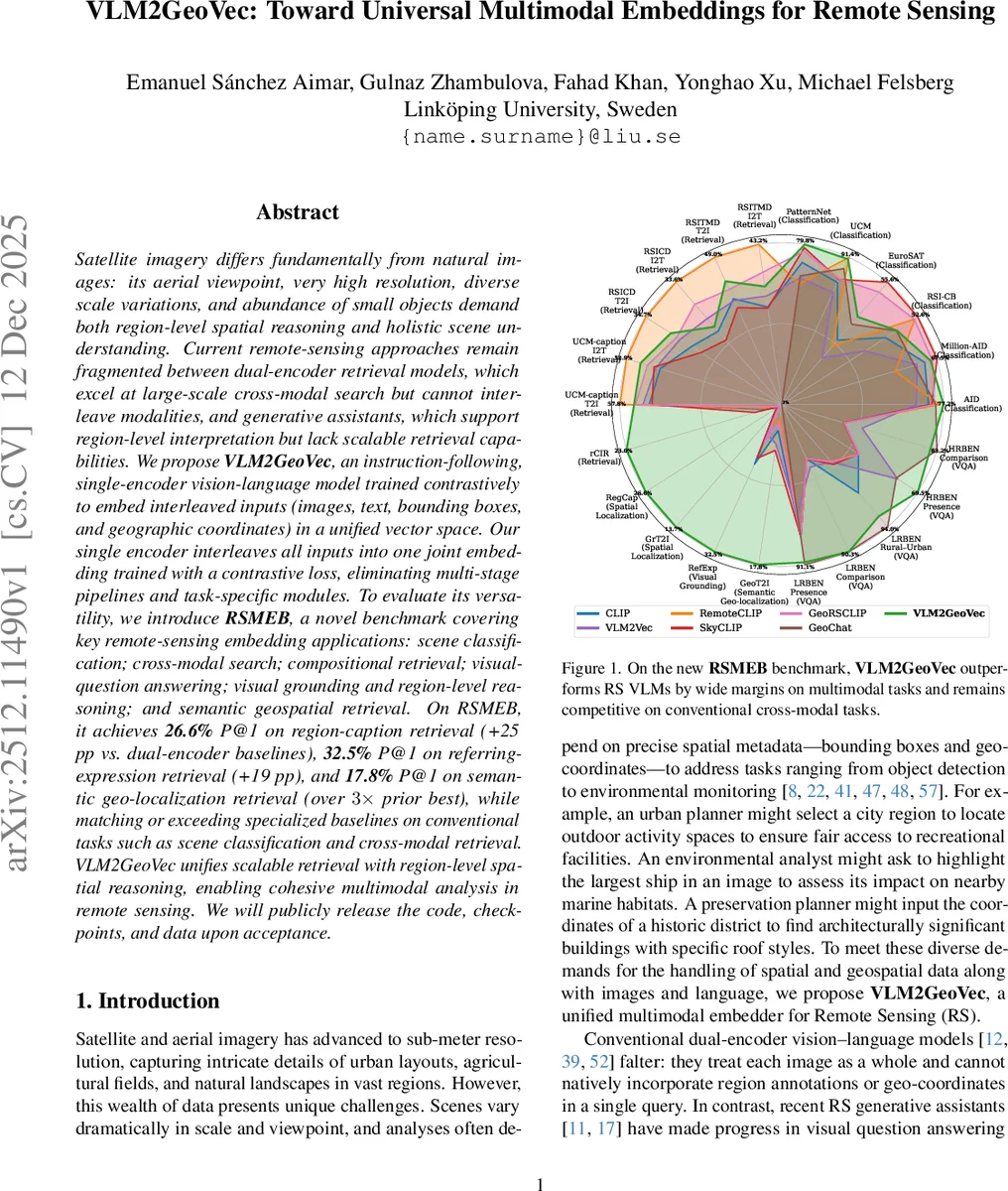
Satellite imagery differs fundamentally from natural images: its aerial viewpoint, very high resolution, diverse scale variations, and abundance of small objects demand both region-level spatial reasoning and holistic scene understanding. Current remote-sensing approaches remain fragmented between dual-encoder retrieval models, which excel at large-scale cross-modal search but cannot interleave modalities, and generative assistants, which support region-level interpretation but lack scalable retrieval capabilities. We propose $\textbf{VLM2GeoVec}$, an instruction-following, single-encoder vision-language model trained contrastively to embed interleaved inputs (images, text, bounding boxes, and geographic coordinates) in a unified vector space. Our single encoder interleaves all inputs into one joint embedding trained with a contrastive loss, eliminating multi-stage pipelines and task-specific modules. To evaluate its versatility, we introduce $\textbf{RSMEB}$, a novel benchmark covering key remote-sensing embedding applications: scene classification; cross-modal search; compositional retrieval; visual-question answering; visual grounding and region-level reasoning; and semantic geospatial retrieval. On RSMEB, it achieves $\textbf{26.6%}$ P@1 on region-caption retrieval (+25 pp vs. dual-encoder baselines), $\textbf{32.5%}$ P@1 on referring-expression retrieval (+19 pp), and $\textbf{17.8%}$ P@1 on semantic geo-localization retrieval (over $3\times$ prior best), while matching or exceeding specialized baselines on conventional tasks such as scene classification and cross-modal retrieval. VLM2GeoVec unifies scalable retrieval with region-level spatial reasoning, enabling cohesive multimodal analysis in remote sensing. We will publicly release the code, checkpoints, and data upon acceptance.
💡 Research Summary
This paper introduces VLM2GeoVec, a novel unified multimodal embedding model for remote sensing, and proposes RSMEB, a comprehensive benchmark for evaluating such models.
The core problem addressed is the unique nature of satellite imagery—characterized by an aerial viewpoint, very high resolution, diverse scales, and abundant small objects—which demands both holistic scene understanding and fine-grained spatial reasoning. Current approaches are fragmented: dual-encoder models (e.g., CLIP-based) excel at large-scale cross-modal retrieval but cannot natively handle region-specified queries or integrate geographic coordinates. Conversely, generative assistant VLMs support region-level interpretation but lack efficient, scalable retrieval capabilities over large archives.
To bridge this gap, the authors propose VLM2GeoVec, an instruction-following, single-encoder model. Its key innovation is the ability to interleave four modalities—RGB images, text, normalized bounding boxes (for regions), and geographic coordinates (as text tuples)—into a single token sequence, processed by a unified encoder. The model architecture is based on a frozen pre-trained VLM backbone (like LLaVA), augmented with injectable Low-Rank Adaptation (LoRA) modules for parameter-efficient fine-tuning. A task instruction in natural language guides the model’s intent. The entire model is trained end-to-end using a contrastive InfoNCE loss, which aligns diverse query-target pairs in a shared embedding space. The training data comprises approximately 2 million instruction-conditioned samples curated from existing remote sensing datasets (GeoChat-Instruct, FIT-RS, etc.), reformatted into contrastive pairs spanning various tasks.
To holistically evaluate the capabilities of embedding models like VLM2GeoVec, the paper introduces the Remote Sensing Multimodal Embedding Benchmark (RSMEB). RSMEB consolidates 21 tasks from public datasets into 6 meta-tasks, all formulated as ranking problems: 1) Scene Classification, 2) Multimodal Retrieval (including cross-modal and region-based composed retrieval), 3) Visual Question Answering (VQA), 4) Visual Grounding (referring expression retrieval), 5) Spatial Localization (region-caption and grounded text-to-image retrieval), and 6) Semantic Geo-localization (retrieving images using coordinate + semantic text). This unified framework allows for direct comparison of models across both conventional and advanced remote sensing tasks using consistent metrics like Precision at 1 (P@1).
Comprehensive evaluation on RSMEB demonstrates VLM2GeoVec’s superior versatility. It achieves state-of-the-art performance on tasks requiring spatial and geospatial reasoning: 26.6% P@1 on region-caption retrieval (RegCap, +25 percentage points over dual-encoder baselines), 32.5% P@1 on referring expression retrieval (RefExp, +19 pp), and 17.8% P@1 on semantic geo-localization retrieval (GeoT2I, over 3x the prior best). Crucially, it also matches or exceeds the performance of specialized remote-sensing baselines (RemoteCLIP, SkyCLIP, GeoChat) on conventional tasks like scene classification and standard cross-modal retrieval. An ablation study confirms the importance of initializing with pre-trained universal embedding weights (VLM2Vec) and using LoRA for adaptation.
In conclusion, VLM2GeoVec successfully unifies scalable, vector-based retrieval with fine-grained region-level spatial reasoning in a single model, overcoming the traditional fragmentation between retrieval and generative models in remote sensing. The RSMEB benchmark provides a much-needed unified evaluation suite for the community. The authors commit to releasing the code, model checkpoints, and data upon acceptance.
Comments & Academic Discussion
Loading comments...
Leave a Comment