ARE: Scaling Up Agent Environments and Evaluations
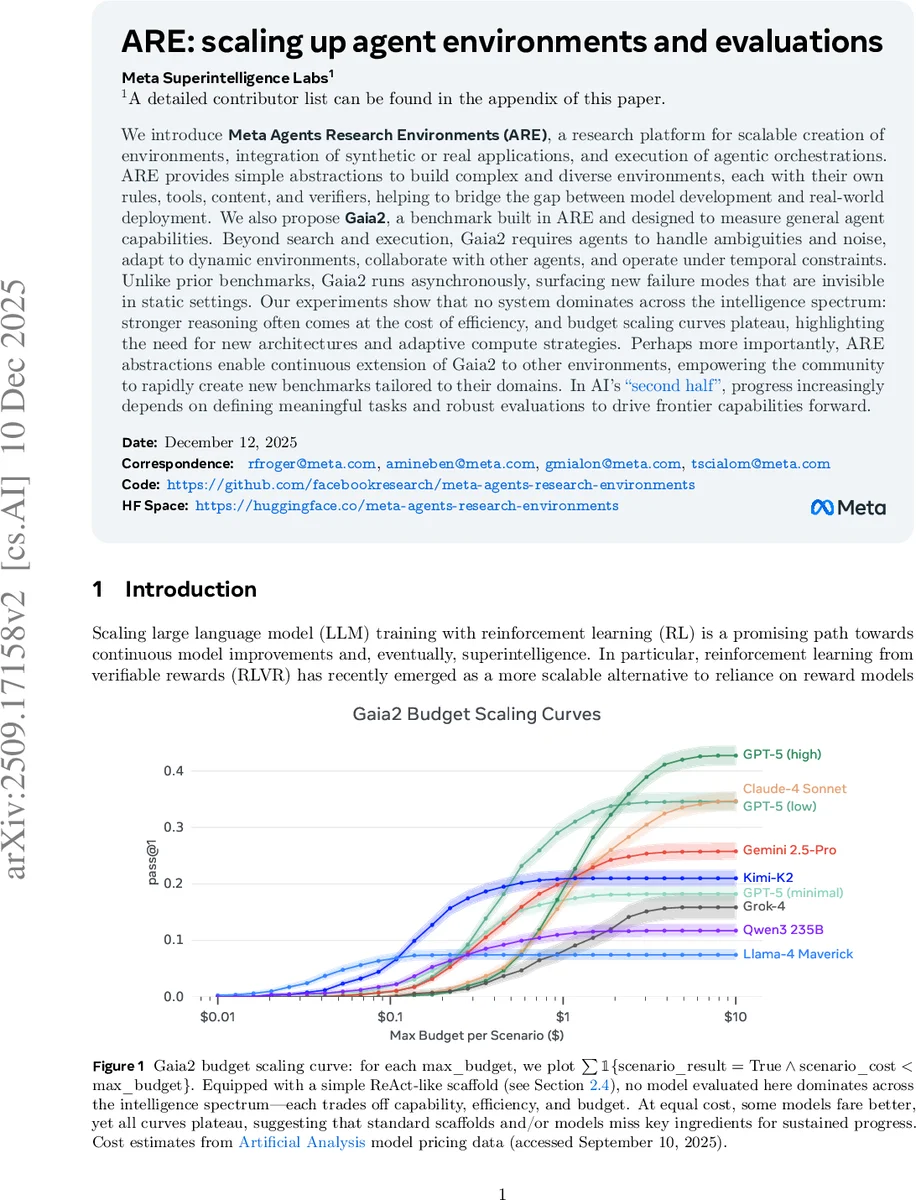
We introduce Meta Agents Research Environments (ARE), a research platform for scalable creation of environments, integration of synthetic or real applications, and execution of agentic orchestrations. ARE provides simple abstractions to build complex and diverse environments, each with their own rules, tools, content, and verifiers, helping to bridge the gap between model development and real-world deployment. We also propose Gaia2, a benchmark built in ARE and designed to measure general agent capabilities. Beyond search and execution, Gaia2 requires agents to handle ambiguities and noise, adapt to dynamic environments, collaborate with other agents, and operate under temporal constraints. Unlike prior benchmarks, Gaia2 runs asynchronously, surfacing new failure modes that are invisible in static settings. Our experiments show that no system dominates across the intelligence spectrum: stronger reasoning often comes at the cost of efficiency, and budget scaling curves plateau, highlighting the need for new architectures and adaptive compute strategies. Perhaps more importantly, ARE abstractions enable continuous extension of Gaia2 to other environments, empowering the community to rapidly create new benchmarks tailored to their domains. In AI’s second half, progress increasingly depends on defining meaningful tasks and robust evaluations to drive frontier capabilities forward.
💡 Research Summary
The paper “ARE: Scaling Up Agent Environments and Evaluations” introduces a comprehensive research platform and a novel benchmark aimed at advancing the development and evaluation of AI agents.
The authors begin by identifying key limitations in current agent research: a reliance on non-reproducible real-world environments like the web, and a prevalence of static, sequential simulation environments that fail to capture the asynchronous, time-sensitive, and dynamic nature of real-world tasks. This gap hinders both reproducible evaluation and the development of capabilities crucial for practical deployment, such as adaptability, proactivity, and handling ambiguity.
To address this, they present Meta Agents Research Environments (ARE), a platform designed for the scalable creation of simulated environments, integration of synthetic or real applications (e.g., via Model Context Protocol), and execution of agentic orchestrations. ARE’s core innovation is its asynchronous, time-driven, event-based simulation model. The environment state evolves continuously independent of the agent’s actions, with time advancing and events (e.g., incoming messages) occurring on a schedule. This unlocks the evaluation of “always-on” agent behaviors. ARE is built upon five foundational abstractions:
- Apps: Stateful API interfaces (e.g., Email, Messaging) that expose tools (read/write) operating on internal data stores.
- Environment: A collection of Apps, their data, and governing rules, forming a deterministic Markov Decision Process.
- Events: Any action or state change, logged with timestamps. Events can be agent-initiated, user-initiated, or scheduled by the environment, and are managed via a Directed Acyclic Graph (DAG) for complex scheduling and dependencies.
- Notifications: Configurable messages from the environment to the agent about events, creating a spectrum of environmental observability based on a “notification policy.”
- Scenarios: Dynamic sequences of initial state and scheduled events within an environment, replacing static single-turn tasks.
Built using ARE, the authors introduce Gaia2, a new benchmark for evaluating general agent capabilities. It consists of 1,120 verifiable scenarios set in a simulated smartphone environment with apps like email, messaging, and calendar. Gaia2 moves beyond simple search-and-execute tasks to require agents to handle ambiguity, noise, dynamic changes, collaboration with other agents, and temporal constraints. Its most significant departure from prior benchmarks is its asynchronous execution, where the world state changes even when the agent is not acting, surfacing new failure modes related to timing and adaptation. A robust verification system compares agent write actions against pre-defined oracle actions.
Experimental results evaluating frontier models (GPT-5, Claude-4, Gemini 2.5-Pro, etc.) with a simple ReAct-like scaffold on Gaia2 reveal several critical insights:
- No single system dominates across the entire intelligence spectrum. Models exhibit trade-offs between capability, efficiency, and cost.
- Budget scaling curves plateau, suggesting that simply increasing compute budget with current scaffolds and models is insufficient for sustained progress.
- These findings highlight the need for new agent architectures and adaptive compute strategies beyond mere model scaling.
The paper concludes by emphasizing the role of ARE’s abstractions in empowering the community to rapidly create new, domain-specific benchmarks without rewriting boilerplate code. The authors posit that in AI’s “second half,” defining meaningful tasks and robust evaluations will be increasingly vital for driving frontier capabilities forward, and ARE/Gaia2 are contributions toward that goal.
Comments & Academic Discussion
Loading comments...
Leave a Comment