diffDemorph: Extending Reference-Free Demorphing to Unseen Faces
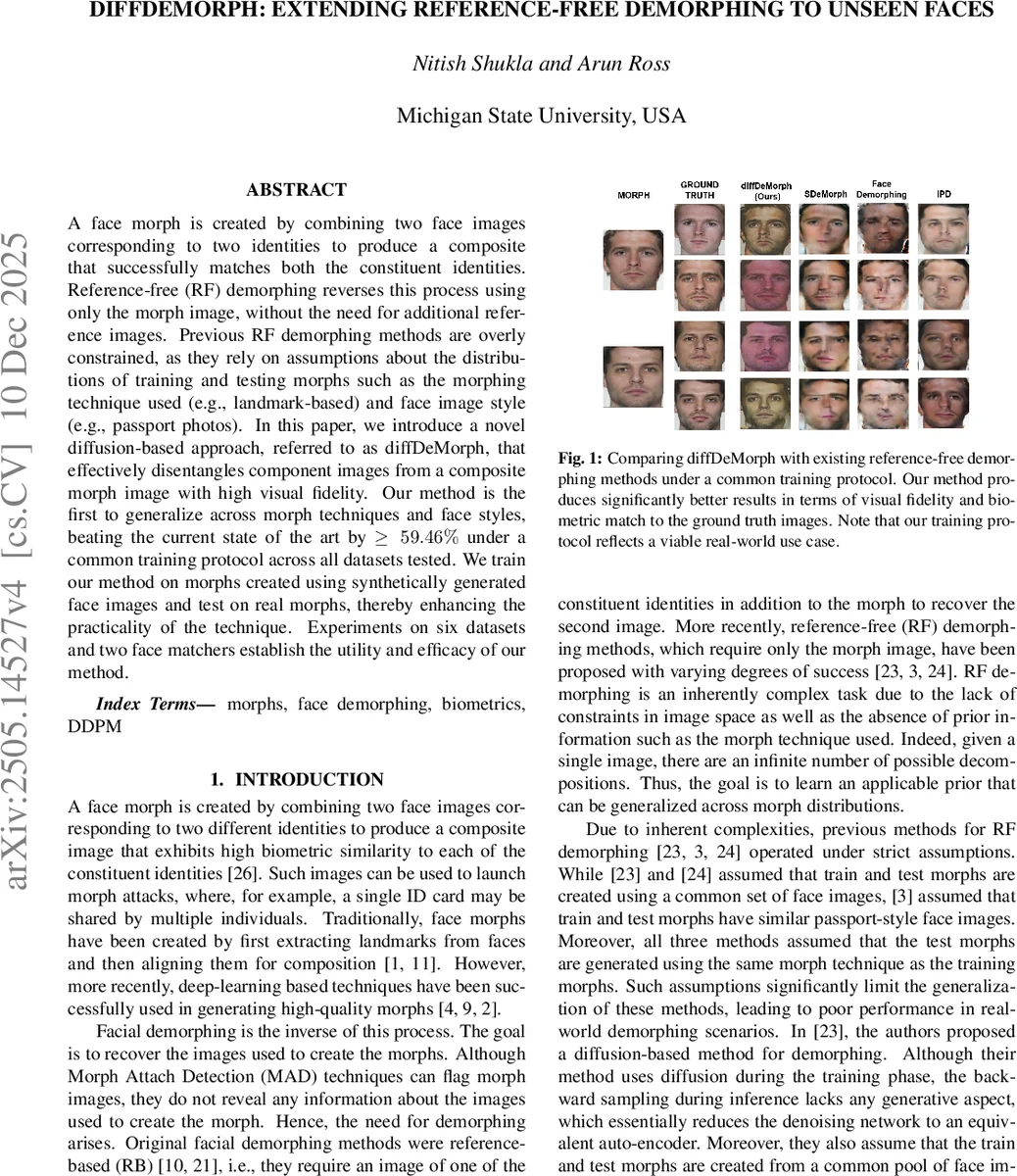
A face morph is created by combining two face images corresponding to two identities to produce a composite that successfully matches both the constituent identities. Reference-free (RF) demorphing reverses this process using only the morph image, without the need for additional reference images. Previous RF demorphing methods are overly constrained, as they rely on assumptions about the distributions of training and testing morphs such as the morphing technique used (e.g., landmark-based) and face image style (e.g., passport photos). In this paper, we introduce a novel diffusion-based approach, referred to as diffDeMorph, that effectively disentangles component images from a composite morph image with high visual fidelity. Our method is the first to generalize across morph techniques and face styles, beating the current state of the art by $\geq 59.46%$ under a common training protocol across all datasets tested. We train our method on morphs created using synthetically generated face images and test on real morphs, thereby enhancing the practicality of the technique. Experiments on six datasets and two face matchers establish the utility and efficacy of our method.
💡 Research Summary
The paper addresses the challenging problem of reference‑free face demorphing, where only a single morphed image is available and the goal is to recover the two original constituent faces. Existing reference‑free methods are heavily constrained: they assume that training and testing morphs are generated from the same pool of faces, that the same morphing technique (e.g., landmark‑based) is used, and that the image style (often passport‑type) is consistent. These assumptions limit real‑world applicability, especially when the morphing algorithm or image style differs between enrollment and attack scenarios.
To overcome these limitations, the authors propose diffDeMorph, a diffusion‑based demorphing framework that removes all such constraints. The core idea is to treat the pair of original faces as a single coupled variable (i₁, i₂) and to condition a Denoising Diffusion Probabilistic Model (DDPM) on the morph image x in the RGB domain. Unlike typical diffusion models that use low‑dimensional text or class embeddings for conditioning, diffDeMorph concatenates the full‑resolution morph (3 channels) with the noisy coupled sample (6 channels) at every denoising step. This “morph‑guided denoiser” receives a 9‑channel input and predicts the previous‑step noisy sample, effectively guiding the reverse diffusion toward a pair of faces that jointly explain the observed morph.
Training follows the standard DDPM objective: an L2 loss on the predicted noise ε at each timestep t, but the loss is computed on the concatenated input (noisy pair + morph). The forward diffusion adds Gaussian noise according to a linear β‑schedule from 1e‑4 to 0.02 over 1000 timesteps; during inference, 100 reverse steps are used. The denoising network is a UNet with 9 input channels and 6 output channels, enabling simultaneous reconstruction of both faces.
A major practical contribution is the use of synthetic data for training. Because large, privacy‑preserving morph datasets are scarce, the authors generate 15 000 morphs from the SMDD synthetic face set using a standard OpenCV/dlib landmark‑based morphing pipeline. This synthetic training set provides diverse identities, poses, and expressions while avoiding any real biometric data. The model is then evaluated on three real‑world morph datasets: AMSL, FRLL‑Morphs, and MorDiff, which contain morphs created by a variety of techniques (OpenCV, StyleGAN, WebMorph, FaceMorph) and image styles (passport‑type, natural photos).
Performance is measured using True Match Rate (TMR) at a fixed 10 % False Match Rate (FMR) with two state‑of‑the‑art face matchers (AdaFace and ArcFace). diffDeMorph consistently outperforms prior methods (SDeMorph, IPD, Face Demorphing) across all datasets, achieving improvements of at least 59 % in TMR. Notably, under the most stringent scenario (Scenario 3), where training and testing face pools are disjoint and morphing techniques differ, diffDeMorph attains TMRs ranging from 58 % to 100 % depending on the dataset, whereas competing methods often collapse to near‑zero performance. Visual inspection also shows that the recovered faces retain fine details such as hair, background, and lighting, leading to high perceptual fidelity.
The authors discuss limitations: the current implementation operates at 256 × 256 resolution, which may lose high‑frequency details in real‑world high‑resolution images; synthetic training data may not capture the full demographic variability of real populations. Future work is suggested in the directions of high‑resolution diffusion models, domain adaptation techniques, and lightweight inference for real‑time deployment.
In summary, diffDeMorph introduces a novel morph‑guided diffusion framework that eliminates restrictive assumptions of prior reference‑free demorphing methods, leverages synthetic training data to address privacy concerns, and demonstrates robust, high‑fidelity recovery of constituent faces across diverse morphing techniques and image styles. This represents a significant step toward practical demorphing solutions for biometric security applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment