Cinder: A fast and fair matchmaking system
A fair and fast matchmaking system is an important component of modern multiplayer online games, directly impacting player retention and satisfaction. However, creating fair matches between lobbies (pre-made teams) of heterogeneous skill levels prese…
Authors: Saurav Pal
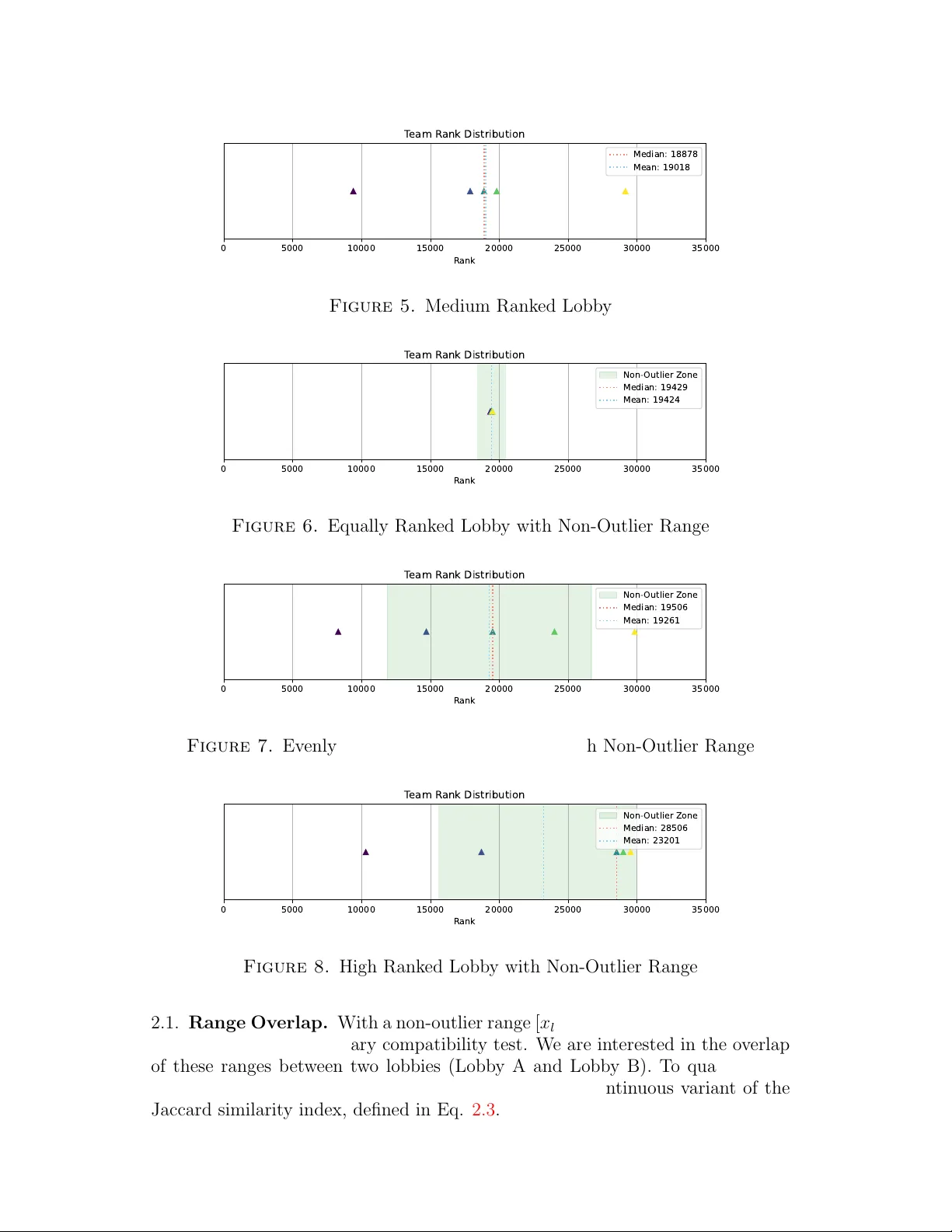
CINDER: A F AST AND F AIR MA TCHMAKING SYSTEM SA URA V P AL 1 ∗ Abstract. A fair and fast matc hmaking system is an imp ortan t comp onen t of mo dern multipla y er online games, directly impacting play er retention and satisfaction. How ev er, creating fair matches b et w een lobbies (pre-made teams) of heterogeneous skill levels presen ts a significant c hallenge. Matc hing based simply on a v erage team skill metrics, suc h as mean or median rating or rank, often results in unbalanced and one-sided games, particularly when skill dis- tributions are wide or sk ew ed. This pap er introduces Cinder, a t w o-stage matc hmaking system designed to pro vide fast and fair matches. Cinder first emplo ys a rapid preliminary filter by comparing the “non-outlier” skill range of lobbies using the Ruzic k a similarit y index. Lobbies that pass this initial c hec k are then ev aluated using a more precise fairness metric. This second stage inv olves mapping pla yer ranks to a non-linear set of skill buc k ets, gen- erated from an inv erted normal distribution, to pro vide higher gran ularity at a v erage skill lev els. The fairness of a potential matc h is then quantified using the Kan torovic h distance [ 3 , 5 ] on the lobbies’ sorted buck et indices, pro duc- ing a “Sanction Score.” W e demonstrate the system’s viability by analyzing the distribution of Sanction Scores from 140 million sim ulated lobby pairings, pro viding a robust foundation for fair matc hmaking thresholds. Keywor ds. Matchmaking, Game, Rank, F air, Statistics 1. Intr oduction In the competitive online gaming scene, the matchmaking system serv es as the foundational mediator of pla y er exp erience. Its primary directive is to pair w aiting teams for a matc h that is both fair and engaging. This task is trivial when all pla y ers in the queue are of similar skill, or “rating” or “rank” (as illustrated in Fig. 1 ). How ev er, mo dern games actively encourage so cial pla y , allo wing pla y ers to form “lobbies” or pre-made parties with friends who ma y hav e widely div ergent skill levels. This social dynamic introduces significan t complexit y . A single lobby may hav e a wide rank distribution, b e evenly spread across the skill sp ectrum (Figure 2 ), or b e heavily skew ed to wards one end (Fig. 3 and 4 ). In these common scenar- ios, traditional matchmaking metrics that rely on simple statistical measures of cen tral tendency , suc h as the mean or median rank, pro v e inadequate. As demon- strated in Fig. 2 - 5 , the mean or median can b e a p oor represen tativ e of the team Date : Published: No vem b er 2, 2025. ∗ Corresp onding author © Saurav Pal 2025. This article is licensed under a Creativ e Commons A ttribution 4.0 In ternational Lice nse. T o view a copy of the licence, visit https://creativecommons.org/licenses/by/4.0/ . 1 2 S. P AL as a whole. Matc hing based on these metrics can create a disastrous exp erience for pla y ers far from the a verage, forcing lo w-rank ed play ers into ov erwhelmingly difficult matches or high-ranked pla yers in to trivial ones, ultimately frustrating all participants. This pap er proposes Cinder, a no vel, t wo-stage matc hmaking system designed to create fair matches ev en for lobbies with high skill v ariance. The system is built on tw o key principles: (1) F ast Preliminary Filtering: A computationally inexp ensiv e prelimi- nary chec k to quickly discard incompatible lobby pairings. (2) Accurate F airness Quan tification: A follo wing precise c heck that con- siders the skill distribution of all play ers in the lobb y to generate a single fairness score. This pap er is structured as follo ws: Section 2 details the first stage of our system, a preliminary filter based on a non-outlier range o v erlap. Section 3 de- scrib es our non-linear skill buck eting metho d. Section 4 introduces our primary fairness metric, the “Sanction Score,” based on the W asserstein distance. Section 5 presents the distribution of this score based on large-scale sim ulation. Finally , Section 6 concludes the pap er and suggests a ven ues for future work. 2. Center of Ra tings 0 5000 10000 15000 20000 25000 30000 35000 R ank T eam R ank Distribution Median: 19529 Mean: 19524 Figure 1. Equally Ranked Lobb y Before committing to a computationally exp ensiv e comparison of tw o lobbies, w e employ a preliminary filter. The goal of this filter is to quic kly identify and discard obviously p oor matches. This filter is based on comparing the primary cluster of play ers in eac h lobb y , whic h w e define as the non-outlier range. As p opular rating systems suc h as ELO [ 1 ] or Glic ko-2 [ 2 ] often lack a theoret- ical upp er limit for ratings, for practical purp oses, we establish a mathematical cap, x ucap , and a lo wer cap, x lcap (whic h often is 0). An y rating ab o v e x ucap is treated as x ucap , and any rating b elo w x lcap is treated as x lcap . T o find the non-outlier range, w e use a mo dified Z-Score calculation. W e first define a mo dified standard deviation, σ ′ , and then use it to define the low er and upp er b ounds of this range ( x l and x u ), as shown in Eq. 2.1 . This mo dification ensures a minim um range width, preven ting it from collapsing to zero in lobbies where all play ers hav e very similar ranks. CINDER 3 σ ′ = max { σ, x ucap − x lcap n buck et } x l = µ − σ ′ x u = µ + σ ′ (2.1) where µ and σ are the mean and standard deviation of the lobb y’s ranks, and n buck et is the total n um b er of skill buc k ets (detailed in Section 3 ). Figures 6 - 10 illustrate the non-outlier ranges for the lobbies previously sho wn in Figures 1 - 5 . 0 5000 10000 15000 20000 25000 30000 35000 R ank T eam R ank Distribution Median: 19506 Mean: 19261 Figure 2. Evenly Distributed Rank ed Lobb y 0 5000 10000 15000 20000 25000 30000 35000 R ank T eam R ank Distribution Median: 28506 Mean: 23201 Figure 3. High Ranked Lobb y 0 5000 10000 15000 20000 25000 30000 35000 R ank T eam R ank Distribution Median: 8878 Mean: 12018 Figure 4. Low Rank ed Lobby σ ′ = max { σ, ( x ucap − x lcap ) /n buck et } x l = µ − σ ′ x u = µ + σ ′ (2.2) 4 S. P AL 0 5000 10000 15000 20000 25000 30000 35000 R ank T eam R ank Distribution Median: 18878 Mean: 19018 Figure 5. Medium Ranked Lobb y 0 5000 10000 15000 20000 25000 30000 35000 R ank T eam R ank Distribution Non- Outlier Zone Median: 19429 Mean: 19424 Figure 6. Equally Ranked Lobb y with Non-Outlier Range 0 5000 10000 15000 20000 25000 30000 35000 R ank T eam R ank Distribution Non- Outlier Zone Median: 19506 Mean: 19261 Figure 7. Evenly Distributed Rank ed Lobb y with Non-Outlier Range 0 5000 10000 15000 20000 25000 30000 35000 R ank T eam R ank Distribution Non- Outlier Zone Median: 28506 Mean: 23201 Figure 8. High Ranked Lobb y with Non-Outlier Range 2.1. Range Ov erlap. With a non-outlier range [ x l , x u ] defined for eac h lobby , we can p erform our preliminary compatibilit y test. W e are interested in the o verlap of these ranges b et w een tw o lobbies (Lobb y A and Lobby B). T o quantify this o verlap, w e use the Ruzic k a similarit y index [ 4 ] S R , a contin uous v ariant of the Jaccard similarity index, defined in Eq. 2.3 . CINDER 5 0 5000 10000 15000 20000 25000 30000 35000 R ank T eam R ank Distribution Non- Outlier Zone Median: 8878 Mean: 12018 Figure 9. Low Rank ed Lobby with Non-Outlier Range 0 5000 10000 15000 20000 25000 30000 35000 R ank T eam R ank Distribution Non- Outlier Zone Median: 18878 Mean: 19018 Figure 10. Medium Ranked Lobb y with Non-Outlier Range S R ( A, B ) = P i min( a i , b i ) P i max( a i , b i ) (2.3) A high S R v alue indicates significant o verlap b et ween the core skill ranges of the t w o lobbies (Figure 11 ), suggesting a potentially go od match. A low S R v alue indicates a large disparit y (Figure 12 ). Fig. 11 and 12 ha ve S R as 0 . 8796 and 0 . 0684 respectively . W e can then define a minim um S R threshold to quickly reject unlik ely lobb y pairings, reducing the computational load on the more intensiv e second stage of the matchmak er. 0 5000 10000 15000 20000 V alue R uzick a Similarity Inde x L obby 1 L obby 2 Figure 11. High Overlapping Lobbies 0 5000 10000 15000 20000 V alue R uzick a Similarity Inde x L obby 1 L obby 2 Figure 12. Low Ov erlapping Lobbies 6 S. P AL 3. Buckets Lobbies that pass the preliminary ov erlap filter pro ceed to a more detailed fairness ev aluation. This ev aluation is based on mapping the en tire skill range ( x lcap to x ucap ) into n buck et skill buck ets. A simple linear division (i.e., giving all buck ets equal width) is sub optimal, as the ma jority of play ers are clustered around the median rank, as in the case of a normal distribution. This w ould result in p oor skill differentiation for the largest segmen t of the play er base. Instead, we require a non-linear distribution where buc kets are narro wer (pro viding higher granularit y) near the center of the rank distribution and wider at the extremes. T o achiev e this, w e use a mo dified in verted normal distribution to determine the width of eac h buc ket, as shown in Figure 13 . W e also enforce an empirical minim um buck et width, W min (e.g., 150 rank points), to ensure the cen tral trough do es not dip to zero. The final width W i of the i -th buc ket is calculated using Eq. 3.1 . This metho d effectiv ely scales the width according to the in verted normal PDF, concentrating precision where it is most needed. W i = W min + ( ϕ max − ϕ ( x i )) · " R total − ( n buck et · W min ) P n buck et j =1 ( ϕ max − ϕ ( x j )) # (3.1) where: • W min is the minimum allo wed buc ket width. • R total is the total rank range ( x ucap − x lcap ). • ϕ ( x i ) is the v alue of the normal probabilit y densit y function (PDF) for the i -th buck et’s p osition. • ϕ max is the maximum v alue of the normal PDF (at the mean). 0 5000 10000 15000 20000 25000 30000 R ank 0.0 0.2 0.4 0.6 0.8 1.0 Edges Buck et Edges 0 5 10 15 20 25 30 Buck et Inde x 200 400 600 800 1000 1200 1400 1600 W idth W idth Figure 13. Rank Buck ets CINDER 7 4. Ma tchmaking F airness Once the skill buc kets are defined, we can represen t each play er in a lobby b y the index of the buc ket their rating falls into. This discretization transforms the non-linear, con tin uous space of play er ratings into a linear, discrete space of buc ket indices. This allows us to accurately quantify the dissimilarity b et ween t wo lobbies using the Kantoro vic h distance [ 3 ] or W asserstein distance [ 5 ]. As shown in Eq. 4.1 , the W 1 distance b et w een t wo 1D distributions U and V of equal size n is the sum of the absolute differences b et w een their sorted elemen ts. W 1 ( U, V ) = n X i =1 | u ( i ) − v ( i ) | (4.1) where u ( i ) and v ( i ) are the i -th sorted buc ket indices for the pla y ers in lobb y U and lobby V , resp ectiv ely . F or example, the highly o v erlapping lobbies from Figure 11 yield a low Sanction Score of 2.8, indicating a go od matc h. Con v ersely , the lobbies with low ov erlap from Figure 12 yield a high Sanction Score of 11.2. W e define this distance as the “Sanction Score.” A larger score signifies greater dissimilarit y b et ween the tw o lobbies and, thus, a less fair match. This step is distinct from the Ruzic k a similarity index [ 4 ] discussed earlier b ecause it considers all pla yers in the lobb y , including outliers, rather than just the central non-outlier range. With this metric, a matchmak er has tw o options: (1) Iterate o ver all w aiting lobbies to find the pairing with the absolute min- im um Sanction Score. (2) Define a maxim um acceptable Sanction Score threshold and pair the first matc h that fall b elo w it. The latter approac h is significantly faster and provides consistently go o d re- sults, provided the threshold is chosen w ell. 5. Resul ts T o understand the practical b eha vior of the Sanction Score, w e simulated 140,000,000 random lobby pairings. The distribution of the resulting Sanction Scores is shown in Figure 14 . As can b e seen in the histogram, the frequency of scores is not normally dis- tributed; rather, it forms a right-sk ewed distribution. The distribution p eaks at a Sanction Score of approximately 20-25 and has a long tail extending to the righ t. This indicates that while the v ast ma jority of random pairings are clustered around a certain level of “unfairness,” extremely p o or matc hes (high scores) are p ossible but increasingly rare. This empirical distribution is inv aluable for setting an intelligen t threshold for the matchmaking system, allo wing for a data-driven trade-off b et ween matc h quality and queue sp eed. 8 S. P AL 0 20 40 60 80 Sanction Scor e 0 1 2 3 4 F r equency 1e6 Sanction Scor e vs F r equency Figure 14. Sanction Score vs F requency 6. Conclusion This pap er introduced Cinder, a no vel t wo-stage system for fast and fair match- making in online games. Cinder addresses the failures of p opular matching by analyzing the entire skill distribution of lobbies. The system’s first stage acts as a high-sp eed preliminary filter, using the Ruzick a similarity index [ 4 ] to com- pare the non-outlier skill ranges of lobbies and discard incompatible pairings. The second, more precise stage quantifies match fairness by mapping all pla y- ers to a non-linear, gran ularity-focused set of skill buc kets. By calculating the 1D W asserstein distance b et ween the sorted buck et indices of tw o lobbies, w e generate a “Sanction Score” whic h is a single, robust metric that represen ts the dissimilarit y , or unfairness, of a p oten tial match b et w een t w o lobbies. Our analysis of 140 million sim ulated pairings demonstrates that this Sanction Score pro vides a predictable normal distribution, enabling the selection of an effectiv e matchmaking threshold. This allo ws a system to balance match qualit y against queue time efficien tly . F uture w ork could in volv e testing Cinder in a live en vironment to measure its impact on pla yer satisfaction and queue dynamics. F urther research could also explore the in tegration of other factors, suc h as play er w ait time or role preference, in to the Sanction Score calculation, as w ell as optimizing the buck et distribution (Eq. 3.1 ) based on a game’s sp ecific pla yer-rank demographics. References 1. Arpad E. Elo, The r ating of chessplayers, p ast and pr esent , Arco Pub., New Y ork, 1978. 2. Mark E Glic kman and Albyn C Jones, R ating the chess r ating system , CHANCE-BERLIN THEN NEW YORK- 12 (1999), 21–28. 3. Leonid V Kantoro vich, Mathematic al metho ds of or ganizing and planning pr o duction , Man- agemen t science 6 (1960), no. 4, 366–422. 4. M Ruˇ zi ˇ ck a, Anwendung mathematisch-statisticher metho den in der ge ob otanik (synthetische b e arb eitung von aufnahmen) , Biologia, Bratislav a 13 (1958), 647. CINDER 9 5. Leonid Nisonovic h V aserstein, Markov pr o c esses over denumer able pr o ducts of sp ac es, de- scribing lar ge systems of automata , Problemy Peredac hi Informatsii 5 (1969), no. 3, 64–72. 1 Dep ar tment of Computer Science and Engineering, Na tional Institute of Technology, Silchar, India. Email addr ess : palsaurav.2020@gmail.com
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment