SpotDiff: Spotting and Disentangling Interference in Feature Space for Subject-Preserving Image Generation
Personalized image generation aims to faithfully preserve a reference subject’s identity while adapting to diverse text prompts. Existing optimization-based methods ensure high fidelity but are computationally expensive, while learning-based approaches offer efficiency at the cost of entangled representations influenced by nuisance factors. We introduce SpotDiff, a novel learning-based method that extracts subject-specific features by spotting and disentangling interference. Leveraging a pre-trained CLIP image encoder and specialized expert networks for pose and background, SpotDiff isolates subject identity through orthogonality constraints in the feature space. To enable principled training, we introduce SpotDiff10k, a curated dataset with consistent pose and background variations. Experiments demonstrate that SpotDiff achieves more robust subject preservation and controllable editing than prior methods, while attaining competitive performance with only 10k training samples.
💡 Research Summary
SpotDiff tackles the core challenge of personalized text‑to‑image generation: preserving a target subject’s identity while allowing flexible editing via textual prompts. Existing approaches fall into two categories. Optimization‑based methods such as DreamBooth and Textual Inversion achieve high fidelity by fine‑tuning a placeholder token on a few subject images, but they require costly test‑time optimization. Learning‑based methods (e.g., IP‑Adapter, ELITE, InstantBooth) encode the subject into a feature vector and inject it into a diffusion model, offering fast inference but suffering from entanglement with nuisance factors like background and pose, which leads to unstable subject preservation and limited editability.
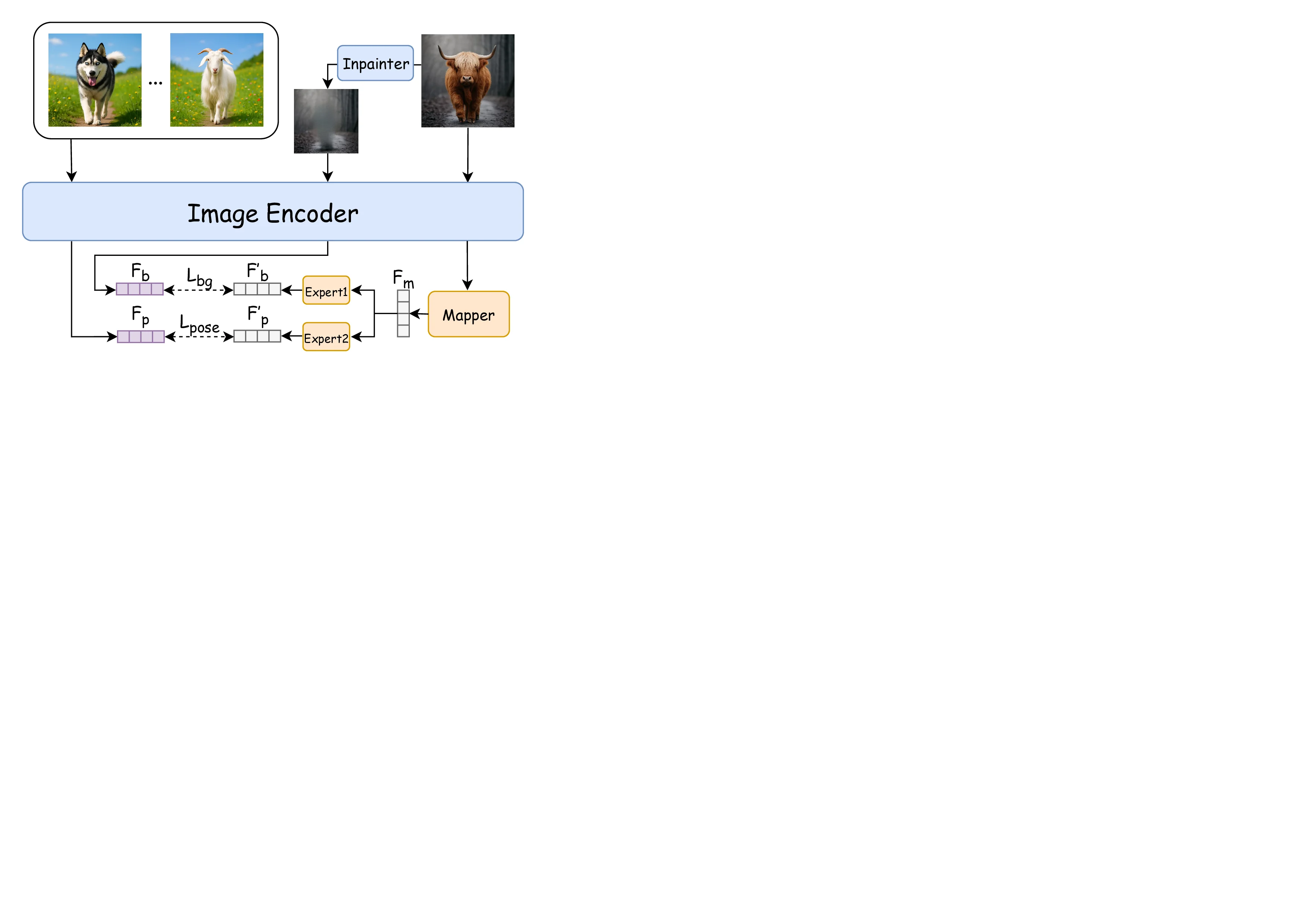
SpotDiff proposes a novel feature‑space disentanglement framework. An input image is first encoded by a pre‑trained CLIP image encoder; features from five CLIP layers are concatenated into a set of “main” feature vectors (F_main). Two lightweight expert networks—one for pose, one for background—receive F_main and predict nuisance vectors F′_p (pose) and F′_b (background). The key operation is an orthogonality constraint: the main feature is projected onto each nuisance vector and the projections are subtracted, yielding a cleaned subject feature F_clean that is orthogonal to both pose and background subspaces. Mathematically,
F_clean = F_main − (F_main·F′_p / ‖F′_p‖²)·F′_p − (F_main·F′_b / ‖F′_b‖²)·F′_b.
This operation is differentiable, allowing end‑to‑end training of the expert networks to accurately capture interference.
Because the CLIP image space and the text embedding space of the diffusion model have different dimensionalities, SpotDiff includes an alignment module (a small MLP) that maps F_clean into the text‑condition dimension. The aligned vector is then concatenated with the textual prompt embeddings and fed into the cross‑attention layers of a Latent Diffusion Model (LDM). Consequently, the diffusion process receives a subject‑specific conditioning that is largely free of background or pose bias.
To train this architecture, the authors construct SpotDiff10k, a curated dataset of 10,000 synthetic subject images generated with GPT‑4o. Each subject appears in a fixed pose while varying in appearance (e.g., fur color, clothing). For each image, the background is replaced with multiple diverse scenes, yielding a controlled set where pose and background are explicitly disentangled. Ground‑truth pose and background features are extracted from CLIP to supervise the expert networks.
Extensive experiments compare SpotDiff against both optimization‑based (DreamBooth, Textual Inversion) and learning‑based baselines (IP‑Adapter, ELITE, DisenBooth, DETEX). Evaluation metrics include FID, CLIP‑Score, identity similarity (measured by a separate face/animal recognizer), pose consistency, and robustness to background changes. SpotDiff consistently outperforms baselines: it maintains subject identity across drastic background swaps (identity similarity ≈ 0.92 vs. ≤ 0.78 for others), accurately follows pose editing instructions (pose consistency ≈ 0.95 vs. ≤ 0.71), and achieves competitive FID (~12.3) despite being trained on only 10 k samples. Ablation studies confirm that removing either expert network or the orthogonal projection degrades performance markedly, underscoring the importance of each component.
The paper acknowledges limitations: the current orthogonal projection assumes linear subspaces, which may not capture complex, non‑linear nuisances such as lighting, style, or texture variations. Moreover, the expert networks are trained on synthetic data, so real‑world generalization to highly diverse subjects may require further fine‑tuning. Future work is suggested in extending the framework to additional nuisance factors, exploring kernel‑based or deep‑non‑linear disentanglement, and optimizing the model for real‑time interactive editing.
In summary, SpotDiff introduces a principled, efficient, and data‑light approach to subject‑preserving image generation by spotting and disentangling interference directly in the feature space, achieving state‑of‑the‑art fidelity and controllability with far fewer training resources than prior learning‑based methods.
Comments & Academic Discussion
Loading comments...
Leave a Comment