Multiple-Instance, Cascaded Classification for Keyword Spotting in Narrow-Band Audio
We propose using cascaded classifiers for a keyword spotting (KWS) task on narrow-band (NB), 8kHz audio acquired in non-IID environments -- a more challenging task than most state-of-the-art KWS systems face. We present a model that incorporates Deep…
Authors: Ahmad AbdulKader, Kareem Nassar, Mohamed El-Geish
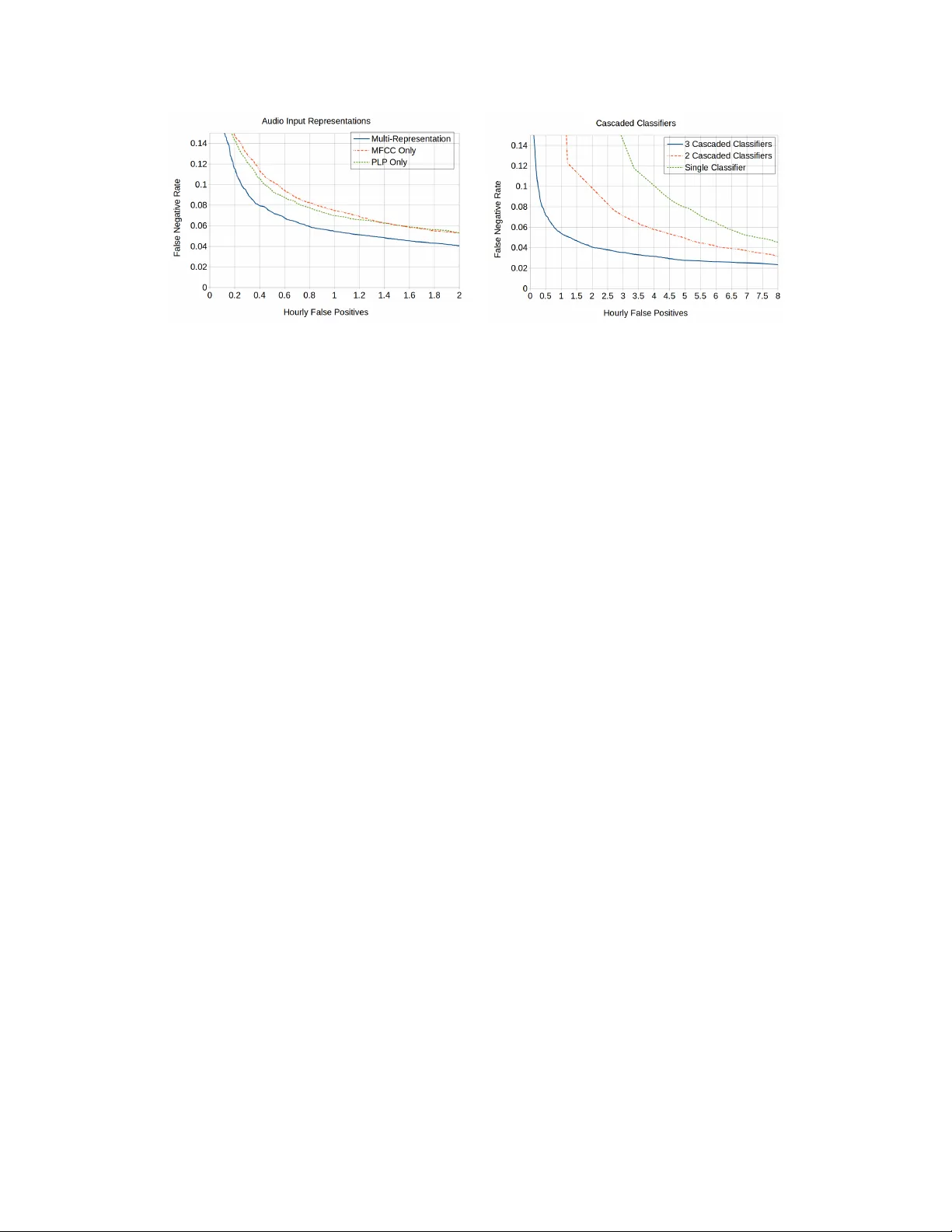
Multiple-Instance, Cascaded Classification f or K eyword Spotting in Narr ow-Band A udio Ahmad Abdulkader V oicera ahmada@voicera.ai Kareem Nassar V oicera kareemn@voicera.ai Mohamed Mahmoud V oicera geish@voicera.ai Daniel Galvez V oicera dt.galvez@gmail.com Chetan Patil V oicera chetanp@voicera.ai Abstract W e propose using cascaded classifiers for a keyw ord spotting (KWS) task on narrow-band (NB), 8kHz audio acquired in non-IID en vironments — a more challenging task than most state-of-the-art KWS systems face. W e present a model that incorporates Deep Neural Networks (DNNs), cascading, multiple-feature representations, and multiple-instance learning. The cascaded classifiers handle the task’ s class imbalance and reduce po wer consumption on computationally- constrained devices via early termination. The KWS system achieves a false negati ve rate of 6% at an hourly f alse positive rate of 0.75. 1 Introduction and Pr oblem Description At V oicera, we are b uilding Ev a — Enterprise V oice Assistant — to collaborate with meeting participants using voice [ 1 ]. W e belie ve interactions with Ev a should feel as natural as interactions with any other participant in the meeting, so we have designed Ev a to recognize and respond to voice commands. Eva continuously listens to the con versation during a meeting and v erbally acknowledges the wake word "Okay Eva." In order for this interaction to feel natural, Eva’ s KWS and audible responses need to be real-time. Eva continuously predicts whether or not the ke ywords of interest were uttered in a real-time audio stream. For fear that users find Eva vexing due to unsolicited interruptions, the false positiv e rate should be less than 1 per hour; on the other hand, users may abandon the service if Eva doesn’t respond when addressed, so we striv e to maximize recall while maintaining a low false positi ve rate. In addition to challenges that other KWS systems f ace while working with real-time speech, Ev a’ s KWS system — in order to be ubiquitous — needs to support speech signals carried over the public- switched telephone netw ork, which typically uses G.711: an NB audio codec that operates at a low bit-rate and at a sample rate of 8kHz [ 2 ]. Both human and automatic speech recognition suf fer significantly from loss of accuracy when listening to NB audio [ 2 , 3 , 4 ]. Moreover , Eva’ s KWS system needs to adapt to new microphones, en vironment settings, speakers, and noise profiles whose characteristics vary drastically — making the input signal to the KWS system non-IID. 2 Prior Art V oice-enabled AI assistants — like Apple’ s Siri, Amazon’ s Alexa, and Google Assistant — perform similar KWS tasks to enable users to interact with their devices. Google proposed a model that uses 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA. Con volutional Neural Netw orks for performing a KWS task to detect 14 dif ferent phrases [ 5 ]; this architecture showed a 27-44% relati ve improv ement in false positiv e rate compared to its predecessor that used a Deep Neural Network (DNN) [ 6 ], which in turn sho wed a 45% relativ e improvement in confidence score compared to KWS using Hidden Markov Models (HMM) [ 7 ]. In [ 8 ], Apple uses a DNN to predict scores for 20 sound classes every 10ms, combining these scores in an HMM-like graph to calculate a composite score indicating that "Hey Siri" was uttered. Similar to our approach, which we detail belo w , the authors used a cascade of two classifiers to conserve po wer . Giv en the control Apple, Amazon, and Google hav e over their hardware specifications, they can acquire wide-band audio, which significantly improv es the accuracy of speech recognition systems. 3 A pproach Our approach to the KWS problem is shown in Figure 1. The KWS system is triggered every 10ms. The audio signal from the past 500ms is captured for processing, since we found that the median command duration is 500ms. In this paper, we often call these 500ms windo ws "examples". Each of our six classifiers — three cascaded classifiers composed of two DNNs trained on dif ferent feature representations — are fully connected DNNs with two 128-input hidden layers. PLP PLP PLP Feature Extraction MFCC MFCC MFCC Cascaded Classifiers Noisy Or Non-Ke yword Non-Ke yword Non-Ke yword Ke yword Figure 1: KWS system diagram: (i) Feature Extraction (ii) Cascaded classifiers (iii) Noisy Or 3.1 Data W e initially collected 19k user examples from 200 indi viduals using a crowdsourcing platform. The collection cov ered a wide v ariety of speakers living in the continental United States. These examples act as positive e xamples in our experiments. Negativ e examples for each cascaded classifier were generated from a repository of audio samples from a v ariety of meeting recordings that do not contain the keyw ord. All of the audio examples were either acquired as or con verted to NB, 8kHz audio. 80% of the data were designated for training; the remaining 20% were used for ev aluation. The data were stratified over indi vidual speakers: A speaker belongs to either the training or the ev aluation set. 3.2 Multi-Representation F eature Extraction It is challenging to sample neg ative examples adequately . As such, discriminati ve classifiers suf fer from the so-called "Novelty Detection" problem: a sound not encountered during the training process can be misclassified as a keyw ord — resulting in a false positiv e. This happens because the decision boundary learned by the discriminative classifier is undefined in the areas that were not sampled during training. T o ov ercome this, we train two classifiers on two dif ferent representations, Mel Frequenc y Cepstral Coefficient (MFCC) and Perceptual Linear Prediction (PLP) features; both are commonly used in speech recognition [ 9 ]. These features are extracted on the same audio input for each stage of the cascade. These classifiers are ensembled using model-av eraging to compute the final probability of an audio windo w being a keyw ord. Because these classifiers were trained on different representations of the same data, the classifiers concur on areas of the distribution that they were trained on and behav e randomly otherwise. This results in a lower rate of f alse positiv es. In our system, both were extracted from 30ms frames with a stride of 10ms and concatenated for each 500ms e xample. 2 3.3 Cascading Cascaded classifiers are commonly used to deal with highly asymmetric classification problems; they hav e been popularized through their use in man y practical machine learning solutions; the V iola-Jones face detector is one notable example [10]. Cascading is an instance of ensemble learning based on the concatenation of sev eral classifiers of increasing complexity . Each classifier is trained on the examples that are not filtered-out by the previous classifiers. A threshold is established on the output of each classifier such that a portion of the negati ve (non-keyword) examples it is subjected to get correctly classified. The remaining examples are either positi ve (ke yword) examples or hard ne gativ e examples. For training the next classifier of the cascade, we run the previous classifiers of the cascade on a large repository of audio guaranteed not to ha ve instances of the tar get keyword, using the discov ered false positi ves as hard negati ve e xamples. This allows subsequent classifiers in the cascade to focus on ne gativ e examples that previous classifiers confuse with the positiv e examples. The distribution of positi ve to negati ve data gets more symmetric for subsequent classifiers. One drawback of this technique is that extracting hard e xamples for training subsequent classifiers in the cascade tak es longer as the cascade gets better . In our experiments belo w , the first cascade classifier is trained with a ratio of 100 negati ve examples for every positi ve example. The second and third cascade classifier maintain a ratio of 2 negati ve examples for e very positi ve example. During inference time, cascaded classifiers provide a way to early-terminate subsequent KWS computations on non-keyw ord windows. 3.4 Multiple-Instance Learning The final stage of the pipeline, in Figure 1(iii), aggregates the outputs of the current and the past outputs of the cascaded classifiers to make a final decision about the triggering of the targeted keyw ord. The KWS problem, as we modeled it, is innately a Multiple-Instance Learning (MIL) [ 11 ] problem: The keyw ord is somewhere in the audio signal, b ut at an imprecisely defined location and may v ary drastically in duration as humans have a wide range of w ays of pronouncing the same word. W e’ ve found that the "Okay Ev a" utterance could v ary from 300ms to 900ms. In MIL, training examples are not singletons; the y come in “bags” such that all of the examples in a bag share a label [ 11 , 12 ]. A positi ve bag of windo ws means that at least one window in the bag is positiv e while a negati ve bag means that all windo ws in the bag are negati ve. In MIL, learning must simultaneously learn which examples in the positi ve bags are positi ve, along with the parameters of the classifier . In our case, a bag is a group of 500ms windows strided by 10ms. As such we have designed our learning process to learn simultaneously on all windows encompassed in a particular positiv e or negati ve bag of windows. The outputs corresponding to all of the windows in the bag are aggregated by a "Noisy Or ." 4 Experiments and Results W e e valuated detection of the phrase "Okay Ev a" using the hourly false positiv e rate plotted against the false neg ativ e rate. Multiple-Featur e Representations The R OC characteristics of a 3-stage cascade with only one feature representation (MFCCs or PLPs individually) compared to a 3-stage cascade with both representations is shown in Figure 2. The multi-representation scheme improves the trade-off between False Positiv es and False Reject rates. For example, at a False Reject rate of around 7% (0.07), MFCCs hav e an hourly False Positi ve rate of 1.2; PLPs ha ve an hourly F alse Positiv e rate of 1.0; the multi-representation has an hourly False Positi ve rate of 0.55. Cascading W e trained one-, two-, and three-cascaded classifiers for comparison. Because the first classifier is trained on mostly neg ative examples, the threshold on the output probability of the first classifier in each cascade was computed to guarantee that most of the positiv e examples would not be filtered out. The ROC characteristics of each of the stages of the cascaded classifiers are sho wn in Figure 3. The R OC characteristics significantly improv es as more classifiers are cascaded. 3 Figure 2: A plot sho wing the effects of using PLPs, MFCCs, and multi-representation models. Figure 3: A plot sho wing the effects of using cascaded classifiers 5 Conclusion W e demonstrate significant gains in KWS in narrow-band audio while minimizing computational resource usage. By incorporating multiple feature representations and three cascaded classifiers, we reduce our false positives per hour at 5% false negati ve rate from 8 to 1.2, a reduction of 85%. Although they are not directly comparable due to dif ferences in datasets, our system performs better on narrow-band 8kHz audio than Google’ s DNN system [5] performs on wide-band 16kHz audio. References [1] O. T awak ol, “Introducing e va by voicera, ” Feb 2017, (Accessed 29-Oct-2017). [Online]. A vailable: https://www .voicera.com/introducing- ev a- by- workfit/ [2] L. Gallardo, Human and A utomatic Speaker Recognition over T elecommunication Channels , ser . T -Labs Series in T elecommunication Services. Springer Singapore, 2015. [3] S. V oran, “Listener ratings of speech passbands, ” in 1997 IEEE W orkshop on Speech Coding for T elecom- munications Pr oceedings. Back to Basics: Attacking Fundamental Pr oblems in Speech Coding , Sep 1997, pp. 81–82. [4] S. Möller , F . Köster , L. F . Gallardo, and M. W agner, “Comparison of transmission quality dimensions of narrowband, wideband, and super -wideband speech channels, ” in 2014 8th International Confer ence on Signal Pr ocessing and Communication Systems (ICSPCS) , Dec 2014, pp. 1–6. [5] T . N. Sainath and C. Parada, “Con volutional neural networks for small-footprint k eyword spotting, ” in INTERSPEECH 2015, 16th Annual Confer ence of the International Speech Communication Association, Dr esden, Germany , September 6-10, 2015 . ISCA, 2015, pp. 1478–1482. [6] G. Chen, C. Parada, and G. Heigold, “Small-footprint ke yword spotting using deep neural netw orks, ” in 2014 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2014, pp. 4087–4091. [7] J. R. Rohlicek, W . Russell, S. Roukos, and H. Gish, “Continuous hidden markov modeling for speaker - independent word spotting, ” in International Confer ence on Acoustics, Speech, and Signal Pr ocessing, , May 1989, pp. 627–630 vol.1. [8] S. T eam, “Hey siri: An on-device dnn-powered voice trigger for apple’s personal assistant - apple, ” Oct 2017, (Accessed 29-Oct-2017). [Online]. A vailable: https://machinelearning.apple.com/2017/10/01/ hey- siri.html [9] S. Y oung, G. Evermann, M. Gales, T . Hain, D. Kersha w , X. Liu, G. Moore, J. Odell, D. Ollason, D. Povey et al. , “The htk book, ” Cambridge university engineering department , vol. 3, 2002. [10] P . V iola and M. J. Jones, “Robust real-time face detection, ” International journal of computer vision , vol. 57, no. 2, pp. 137–154, 2004. [11] C. Zhang, J. C. Platt, and P . A. V iola, “Multiple instance boosting for object detection, ” in Advances in neural information pr ocessing systems , 2006, pp. 1417–1424. [12] T . G. Dietterich, R. H. Lathrop, and T . Lozano-Pérez, “Solving the multiple instance problem with axis-parallel rectangles, ” Artificial intelligence , vol. 89, no. 1, pp. 31–71, 1997. 4
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment