Large-scale traffic signal control using machine learning: some traffic flow considerations
This paper uses supervised learning, random search and deep reinforcement learning (DRL) methods to control large signalized intersection networks. The traffic model is Cellular Automaton rule 184, which has been shown to be a parameter-free represen…
Authors: Jorge A. Laval, Hao Zhou
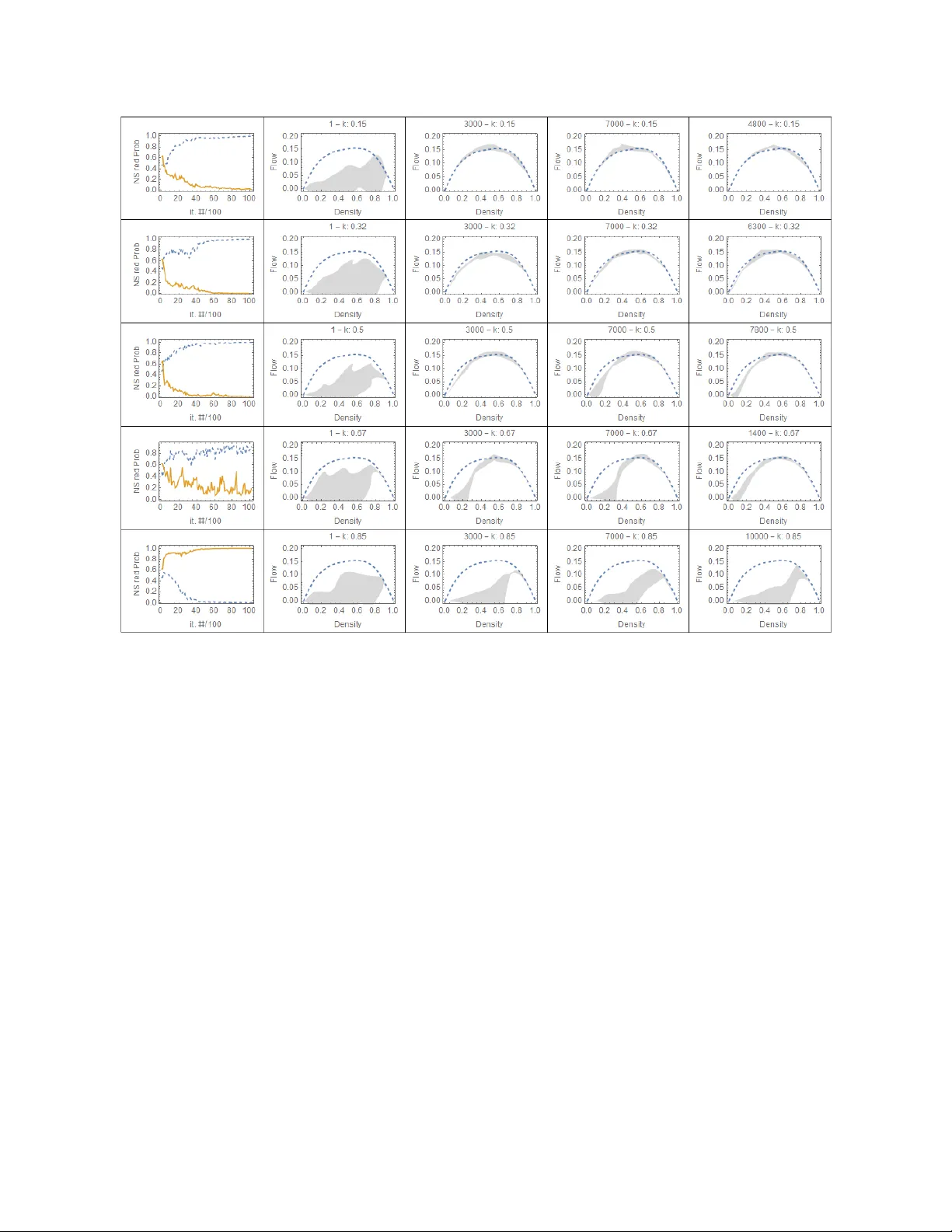
LARGE-SCALE TRAFFIC SIGNAL CONTR OL USING MA CHINE LEARNING: SOME TRAFFIC FLO W CONSIDERA TIONS Jor ge A. La val, Corr esponding A uthor Georgia Institute of T echnology 790 Atlantic Dri ve, Atlanta, GA 30332 T el: 404-894-2360 Email: jorge.lav al@ce.gatech.edu Hao Zhou Georgia Institute of T echnology 790 Atlantic Dri ve, Atlanta, GA 30332 T el: tel Email: email W ord Count: 4989 words + 10 fig(s) = 7489 words Lav al, and Zhou 1 ABSTRA CT This paper uses supervised learning, random search and deep reinforcement learning (DRL) meth- ods to control large signalized intersection networks. The control policy at each intersection is parameterized as a deep neural network, to approximate the “best” signal setting as a function of the state of its incoming and outgoing approaches. The traffic model is Cellular Automaton rule 184, which has been shown to be a parameter-free representation of traffic flow , and which is probably the most ef ficient implementation of the Kinematic W av e model with triangular fun- damental diagram. W e are interested in the steady-state performance of the system, both spatially and temporally: we consider a homogeneous grid network inscribed on a torus, which makes the network boundary-free, and dri vers choose random routes. As a benchmark we use the longest- queue-first (LQF) greedy [1] algorithm. W e find that: (i) a policy trained with supervised learning with only two examples outperforms LQF , (ii) random search is able to generate near -optimal poli- cies, (iii) the pre vailing a verage network occupancy during training is the major determinant of the ef fecti veness of DRL policies. When trained under free-flo w conditions one obtains DRL policies that are optimal for all traf fic conditions, but this performance deteriorates as the occupanc y dur - ing training increases. F or occupancies > 75% during training, DRL policies perform very poorly for all traffic conditions, which means that DRL methods cannot learn under highly congested conditions. W e conjecture that DRL ’ s inability to learn under congestion might be explained by a property of urban networks found here, whereby e ven a v ery bad policy produces an intersec- tion throughput higher than downstream capacity . This means that the actual throughput tends to be independent of the policy . Our findings imply that it is advisable for current DRL methods in the literature to discard any congested data when training, and that doing this will improv e their performance under all traffic conditions. They also suggest that this inability to learn under con- gestion might be alle viated by combining DRL for free-flo w and supervised learning for congested conditions. K eywor ds : T raffic signal control, machine learning, deep reinforcement learning Lav al, and Zhou 2 INTR ODUCTION The use of deep neural netw orks within Reinforcement Learning algorithms has produced im- portant breakthroughs in recent years. These deep reinforcement learning (DRL) methods hav e outperformed expert kno wledge methods in areas such as arcade games, backgammon, the game Go and autonomous driving [2, 3, 4]. In the area of traf fic signal control numerous DRL control methods ha ve been proposed both for isolated intersections [5, 6] and small networks [7, 8, 9, 10]. The vast majority of these methods ha ve been trained with a single (dynamic) traffic demand pro- file, and then v alidated using another one, possibly including a surge [10]. A gap in the literature appears to be a consistent analysis of the different aspects of large traf fic flo w networks that influence the performance of DRL methods. F or example, it is not clear if and how network congestion le vels af fect the learning process, or if other machine learning meth- ods are effecti ve, or if current findings also apply to lar ge netw orks. This paper is a step in this direction, where we e xamine the simplest possible DRL setup in order to g ain some insight on ho w the optimal polic y changes with respect to dif ferent configurations of the learning frame work. In particular , we are interested in the steady-state performance of the system, both spatially and tem- porally: we consider a homogeneous grid network inscribed on a torus, which makes the network boundary-free, and dri vers choose random routes. In the current signal control DRL literature the problem is treated, in variably , as an episode process, which is puzzling gi ven that the problem is naturally a continuing (infinite horizon) one. Here, we adopt the continuing approach to maximize the long-term av erage re ward. W e ar gue that in signal control there is no terminal state because the process actually goes on forev er . And what may appear as a terminal state, such as an empty network, cannot be considered so because it is not achie ved through the correct choice of actions b ut by the traf fic demand, which is uncontrollable. An explanation for this puzzling choice in the literature might be that DRL training methods for episodic problems have a much longer history and our implemented in most machine learning de velopment frame works. For continuing problems this is not unfortunately the case, and we propose here the training algorithm R E I N F O R C E - T D , which is in the spirit of REINFORCE with baseline [11] but for continuing problems. T o the best of our knowledge, this extension of REINFORCE is not av ailable in the literature. The remainder of the paper is organized as follows. W e start with the background section regarding DRL methods and the macroscopic fundamental diagram of urban networks, followed by a surve y of related work. Then, we define the problem set up and apply it to a series of experiments that highlight the main properties found here. Finally , the paper concludes with a discussion and outlook section. B A CKGROUND The macroscopic fundamental diagram (MFD) of urban netw orks Macroscopic models for traffic flow hav e become increasingly popular after the empirical veri- fication of a network-le vel Macroscopic Fundamental Diagram (MFD) on congested urban areas [12, 13]. For a gi ven traffic network, the MFD describes the relationship between traf fic variables av eraged across all lanes in the network. In this paper we will use the flo w-density MFD, which gi ves the a verage flo w on the network as a function of the a verage density on the network. The main requirement for a well-defined MFD is that congestion be homogeneously dis- tributed across the netw ork, i.e. there must be no ”hot spots” in the network. For analytical deri v ations it is often also assumed that each lane of the network obe ys the kinematic wav e model Lav al, and Zhou 3 [14, 15] with common fundamental diagram [16, 17]. In this way , upper bounds for the MFD ha ve been found using the method of cuts in the case of homogenous netw orks. For general networks, [17] show that (the probability distribution of) the MFD can be well approximated by a function of mainly two parameters: the mean distance between traf fic lights di vided by the mean green time, and the mean red-to-green ratio across the network. Reinf orcement lear ning Reinforcement learning is typically formulated within the frame work of a Markov decision pr ocess (MDP). At discrete time step t the en vironment is in state S t ∈ S , the agent will choose and action A t ∈ A , to maximize a function of future re wards R t + 1 , R t + 2 . . . with R − : S × A → ℜ . There is a state transition probability distribution P ( s 0 , r | s , a ) = Pr ( S t = s 0 , R t = r | S t − 1 = s , A t − 1 = a ) that giv es the probability of making a transition from state s to state s 0 using action a is denoted P ( s , a , s 0 ) , and is commonly referred to as the “model”. The model is Markovian since the state transitions are independent of any previous en vironment states or agent actions. For more details on MDP models the reader is referred to [18, 19, 20, 21] The agent’ s decisions are characterized by a stochastic policy π ( a | s ) , which is the proba- bility of taking action a in state s . In the continuing case the agent seeks to maximize the averag e r ewar d : η ( π ) ≡ lim T → ∞ 1 T T ∑ t = 1 E π [ R t ] (1) The term E π means that the e xpected value (with respect to the distribution of states) assumes that the policy is follo wed. In the case of traffic signal control for large-scale grid network, methods based on transition probabilities are impractical because the state-action space tends to be too large as the number of agents increases. An alternati ve approach that circumvents this curse of dimensionality problem— the approach we pursue here—are “polic y-gradient” algorithms, where the policy is parameterized as π ( a | s ; θ ) , θ ∈ R m , typically a neural network. Parameters θ are adjusted to improve the perfor - mance of the polic y π by following the gradient of cumulati ve future rew ards, gi ven by the identity ∇ η = E π [ G t ∇ θ log π ( a | s )] (2) as shown in [22] for both continuing and episodic problems. In continuing problems cumulati ve re wards G t are measured relati ve to the a verage cumulati ve re ward: G t = ∞ ∑ i = t + 1 ( R i − η ( π )) (3) and is kno wn as the differ ential r eturn . The value function is the expected dif ferential return the agent will gain if it starts in that state and ex ecutes the policy π . V ( s ) = E π [ G t | S t = s ] (4) Related work The existing literature is split between two approaches for formulating the large-scale traffic con- trol problem: either a centralized DRL algorithm or a decentralized method with communication Lav al, and Zhou 4 and cooperation among multi-agents. The centralized approach [5, 6, 23] usually adopts a single- agent learning algorithm as many DRL control problems and tries to tackle the high-diamentional continuous control problem by no vel algorithms like memory replay , dual networks and adv antage actor-critic [2, 24]. The decentralized method takes advantage of multiple agents and requires de- sign of ef ficient communication and coordination to address the limitation of partial observation of local agents. Current studies [9, 25, 26, 27] often decompose the large network into small regions or indi vidual intersections, and train the local-optimum policies separately giv en re ward functions reflecting certain lev el of cooperation. It is worth noting that different observational measures of the en vironment are used as communication information between agents, such as neighbour- ing intersections, downstream intersections or upstream intersections. How to incorporate those communication information to help design the re ward function for local agents remains an open question. The en vironment modeling, state representation and re ward function design are ke y in- gredients in DRL. For the en vironment emulator , most studies are based on popular microscopic traf fic simulation packages like AIMSUM or SUMO. Recently , FLO W [28] has been de veloped as a computational framew ork inte grating SUMO with some adv anced DRL libraries to implement DRL algorithm on ground traf fic scenarios. [29] provided a benchmark for major traffic control problems including the multiple intersection signal timing. There also exist studies [1, 7, 10] adopting methods to use self-defined traf fic models as the en vironment. Complementary to those microscopic simulation packages, macroscopic models are able to represent the traf fic state using cell or link flo ws. The advantage of macroscopic models is twofold: i) reducing complexity in state space and computation ii) being compatible with domain knowledge from traf fic flow theory such as MFD theory . Expert knowledge has been included in some studies to reduce the scale of the network control problem. In [30], critical nodes dictating the traf fic network were identified first before the DRL was implemented. The state space can be remarkably reduced. Macroscopic fundamental diagram (MFD) theory cannot pro vide suf ficient information to determine the traf fic state of a net- work. For instance, [7] successfully inte grated the MFD with a microscopic simulator to constrain the searching space of the control policies in their signal design problem. The y defined the re ward as the trip completion rate of the network, and simultaneously enforcing the netw ork to remain un- der or near the critical density . The numerical e xperiments demonstrated that their policy trained by the inte gration of MFD yields a more rob ust shape of the MFD, as well as a better performance of trip completion maximization, compared to that of a fixed and a greedy polic y . While most of the related studies on traffic control only focus on de veloping effecti ve and robust deep learning algorithms, fe w of them hav e shown traf fic considerations, such as the impact of traffic density . The learning performance of RL-based methods under dif ferent densities ha ve not been suf ficiently addressed. T o the best of our knowledge, [31] is the only study which trained a RL policy for specific and varied density le vels, but unfortunately their study only accounted for free-flow and mid-le vel congestion. [32] classified the traffic demand into four v ague lev els and reported that inflow rates at 1000 and 1200 veh/h needed more time for the algorithm to sho w con vergence. But they did not report network density , nor try more congested situations nor discussed why the con verging process has been delayed. Most studies only trained RL methods in non-congestion conditions, [10] adopted the Q-v alue transfer algorithm (QTCDQN) for the cooperati ve signal control between a simple 2*2 grid network and v alidated the adaptability of their algorithm to dynamic traffic en vironments with dif ferent densities, such as the the recurring Lav al, and Zhou 5 FIGURE 1 CA Rule 184: The top r ow in each of the eight cases sho ws the the neighborhood values ( c i − 1 , c i , c i + 1 ) and the updated c i in the bottom ro w . congestion and occasional congestion. In summary , most recent studies focus on de veloping effecti ve and robust multi-agent DRL algorithms to achiev e coordination among intersections. The number of intersections in those studies are usually limited, thus their results might not apply to large open network. Although the signal control is indeed a continuing problem, it has been always modeled as an episodic process. From the perspecti ve of traf fic considerations, expert knowledge has only been incorporated in do wn-scaling the size of the control problem or designing novel reward functions for DRL algo- rithm. Few studies have tested their methods giv en dif ferent traf fic demands, or shed lights on the learning performance under dif ferent traffic conditions, especially the congestion regimes. T o fill the gap, our study will treat the lar ge-scale traf fic control as a continuing problem and extend classical RL algorithm to fit it. More importantly , noticing the lack of traf fic considerations on learning performance, we will train DRL policies under different density le vels and explore the results from a traf fic flo w perspecti ve. PR OBLEM SET UP The traffic flow model used in this paper is the kinematic wav e model [14, 15] with a triangular flo w-density fundamental diagram, which is the simplest model able to predict the main features of traf fic flo w . The shape of the triangular fundamental diagram is irrele v ant due to a symmetry in the kinematic wav e model whereby flows and delays are in variant with respect to linear trans- formations, and renders the kinematic wa ve model parameter -free; see [33] for the details. This allo ws us to use an isosceles fundamental diagram, which in combination with a cellular automa- ton (CA) implementation of the kinematic wav e model, produces its most computationally efficient numerical solution method: Elementary CA Rule 184 [34]. In a CA model, each lane of the road is divided into small cells i = 1 , 2 , . . . n the size of a vehicle jam spacing, where cell n is the most do wnstream cell of the lane. The value in each cell, namely c i , can be either “1” if a vehicle is present and “0” otherwise. The update scheme for CA Rule 184, sho wn in Fig. 1, operates ov er a neighborhood of length 3, and can be written as: c i : = c i − 1 ∨ c i − 1 ∧ c i ∨ c i ∧ c i + 1 (5) The vector c is a vector of bits and (5) is Boolean algebra, which explains the high computational ef ficiency of this traf fic model. Notice that (5) implies that the current state of the system is described completely by the state in the previous time step; i.e. it is Markovian and deterministic. Stochastic components are added by the signal control polic y , and therefore our traf fic model satisfies the main assumption of the MDP frame work. The signalized netw ork corresponds to a homogeneous grid network of bidirectional streets, with one lane per direction of length n = 5 cells between neighboring traf fic lights. (6) Lav al, and Zhou 6 FIGURE 2 Example 3 × 4 traffic network. The connecting links to form the torus are sho wn as dashed directed links; we hav e omitted the cells on these links to avoid clutter . Each segment has n = 5 cells; an additional cell has been added downstream of each segment to indicate the traffic light color . T o attain spatial homogeneity , the network is defined on a torus: Street ends on the edge of the network are connected so that each street can be thought of as a ring road. This is illustrated in Fig. 2, where we hav e omitted the cells on the connecting links (to form the torus) to reduce clutter . Notice that in this setting all intersections hav e 4 incoming and 4 outgoing approaches. V ehicle r outing is such that reaching the stop line will choose to turn right, left or keep going straight with equal probability . This promotes a uniform distrib ution for density on the network. T raffic signals operate with only two restrictions: a red-red of one time step (of the CA model) to account for the lost time steps when switching lights, and a minimum green time, g of 3 time steps. This means that one iteration in the learning framework correspond to g time steps of the CA model. The DRL framework Each traf fic signal is considered an agent that learns from the en vironment. There are two possible actions for each agent: turning the light red/green for the North-South approaches (and therefore turns the light green/red for the East-W est approaches). W e don’t consider yello w phase in this paper . The state observ able by the agent is a 8 × n matrix of bits, gi ven the four incoming and the four outgoing c -vectors from the CA model, one for each approach to the intersection. The policy for each traffic signal agent is approximated by a deep neural network as shown in Fig. 3. It is a 3-layer perceptron with tanh nonlinearity , kno wn to approximate any continuous Lav al, and Zhou 7 FIGURE 3 Neural network architectur e to appr oximate the policy . The numbers on top of the arr ows indicate the dimensions of the corr esponding input/output vectors, and the numbers below the squares ar e as f ollows: the input is the state observable by the agent, 1: linear layer , 2: tanh function, 3: linear layer , 4: summation lay er , 5: sigmoid function, and the output is a single real number that gi ves the probability of turning the light r ed for the North-South approaches. function with an arbitrary accuracy provided the network is ”deep enough” [35]. The input to the network is the state observ able by the agent, while the output is a single real number that gi ves the probability of turning the light red for the North-South approaches. W e define the reward at time t , R t , as the incremental averag e flow per lane , defined here as the av erage flow through the intersection during ( t , t + g ) minus the flo w predicted by the network MFD at the prev ailing density . W e will see that this definition of re ward is superior to the more standard average flow per lane in that case the resulting parameter variance is lar ger , which makes it more dif ficult for training algorithms to con ver ge. In this context the MFD can be seen as a baseline for the learning algorithm, which reduces parameter variance. But for a baseline to be ef fecti ve it needs to be independent of the actions taken. T o this end, we use the maximum-queue- first (LQF) algorithm as a baseline, whose mean MFD is sho wn as a thick dashed curv e starting in Figure 4. Because our network is spatially homogeneous and without boundaries, there is no reason why policies should be dif ferent across agents, and therefore we will train a single a gent and share its parameters with all other agents. After training, we ev aluate the performance of the policy by observing the resulting MFD. The training algorithm R E I N F O R C E - T D In this paper we propose the training algorithm R E I N F O R C E - T D , which is in the spirit of RE- INFORCE with baseline [11] b ut for continuing problems. T o the best of our knowledge, this extension of REINFORCE is not av ailable in the literature. Notice that we tried other methods in the literature with very similar results, so R E I N F O R C E - T D is chosen here since it has the fe west hyper parameters: learning rates α and β for the parameters θ and the average rew ard, respecti vely . Using a grid search ov er these parameters resulted in α = 0 . 2 and β = 0 . 05. Recall that REINFORCE is probably the simplest polic y gradient algorithm that uses (2) to guide the parameter search. In the episode setting it is considered a Monte-Carlo method since it requires full episode replay , and it has been considered to be incompatible with continuing prob- lems in literature [36]. Here, we argue that a one-step T emporal Dif ference (TD) approach [37] can be used instead of the Monte-Carlo replay to fit the continuing setting. This boils down to estimating the dif ferential return (3) by the temporal one-step dif ferential return of an action: G t ≈ R t − η ( π ) (7) Notice that the second term in this e xpression can be interpreted as a baseline in REINFORCE, and baselines are kno wn to reduce parameter v ariance. The pseudocode is shown in Algorithm 1. Lav al, and Zhou 8 Algorithm 1 R E I N F O R C E - T D 1: Input: parameterized policy π ( a | s ; θ ) , θ ∈ R m , av erage density k 2: Set hyper-parameter α , β , set average re ward η = 0 3: Initialize vector θ 4: Initialize the network state S as a Bernoulli process with probability k ov er the cells in the network 5: repeat 6: Generate action A ∼ π ( ·| S ; θ ) 7: T ake action A , observe the ne w state S 0 and re ward R (by running the traffic simulation model for g time steps) 8: G ← R − η 9: η ← η + β G 10: θ ← θ + α G ∇ θ log π ( A | S ; θ ) 11: S ← S 0 12: until forev er EXPERIMENTS In this section we perform a series of experiments to highlight the main properties of our problem. The dif ferent policies will be compared based on the MFD they produce once deployed to all intersections in the network. The MFD for each polic y is obtained by simulating this policy for se veral network densities and reporting the average flow in the network after 40 time steps. This process is repeated 20 times for each density value to obtain an approximate 95%-confidence interv al (mean ± 2 standard deviations) of the flo w for each density v alue, sho wn as the shaded areas in all flo w-density diagrams that follo w . As a visual benchmark we also use the a greedy method, i.e. longest-queue-first (LQF) policy , whose mean MFD is shown as a thick dashed curve on the follo wing flow-density dia- grams (only the mean v alues are reported here to a void clutter). In this way , we are able to test the hypotheses that the policy outperforms LQF simply by observing if the shaded area is above the dashed line. In particular , we will say that a policy is “optimal” if it outperforms LQF , “competi- ti ve” if it performs similarly to LQF (shaded area ov erlaps with dashed line), and “suboptimal” if it underperforms LQF (shaded area belo w the dashed line). Random policies In this experiment the weights θ for the policy are set according to a standard normal distrib ution. As illustrated in Fig. 4, it is possible to find a competitiv e policy after just a few trials; as in trial 9 in the figure, similar random search method for RL problems can be found in [31, 38]. A visual analysis of a lar ge collection of such images rev eals that about 15% of these random policies are competiti ve. Notice that this figure also rev eals that all policies, no matter how bad, are optimal when the density exceeds approximately 75%. T o the best of our knowledge, this property of signal- ized traffic networks has not been reported previously . [31] was the only study being close to it, which compared a verage delay by using random search, LQF , and RL-based policies under den- sities ranging from 0.1 to 0.75. Howe ver , they did not show any results under density higher than 0.75, and no explanation or discussion was provided. Although the y did not discuss the learn- Lav al, and Zhou 9 FIGURE 4 Random policies. Each diagram is a different trial, and shows the av erage density versus average flow in the network. The dashed line corr esponds to the benchmark LQF policy . The r ed and green en velope curves sho w the MFD bounds. ing performance under density higher than 0.75, their results gi ven density from 0.1 to 0.75 sho w consistency with our finding, and supported the density threshold value 0.75 rev ealed in our study . T o see the property , consider the upper and lo wer bounds on the MFD in the figure, as a way of defining a feasibility region for the MFD. The existence of this lower bound is unexpected, and since it ov erlaps with the upper bound for congested densities means that intersection throughput is not af fected by the control. A possible explanation is that under heavily congested conditions there will alw ays be a queue waiting to discharge at all intersections, and therefore which approach gets the green becomes irrele v ant. Supervised lear ning policies In this section we will report a rather surprising result, training the polic y with only tw o examples yields a near-optimal policy . These examples are shown in Fig. 5 and correspond to two extreme situations where the choice is trivial: the left panel sho ws extreme state s 1 , where both North-South approaches are empty and the East-W est ones are at jam density (and therefore red should be giv en to those approaches with probability one), while the middle panel shows s 2 , the opposite situation (and therefore red should be giv en to North-South approaches with probability zero); in both cases all outgoing approaches are empty . The training data is simply: π ( s 1 ) → 1 , π ( s 2 ) → 0 . (8) The figure also sho ws the MFD resulting from this polic y , where it can be seen that it outperforms our benchmark for all densities. Lav al, and Zhou 10 FIGURE 5 Supervised learning experiment. Left: extr eme state s 1 , wher e both North-South approaches are empty and the East-W est ones are at jam density; we ha ve omitted the cells on links other than the ones observable by the middle intersection to av oid clutter . Middle: extreme state s 2 , the opposite of s 1 . Right: resulting MFD (shaded ar ea). DRL policies Here we training the policy using DRL, as discussed earlier . W e included two experiments. In the first one the policy is trained under a constant number of vehicles in the network, and we show that as soon as congestion builds up the learning process deteriorates. The second e xperiment considers the standard definition of rew ard in the literature, and we show that it produces a slo wer con ver gence. Constant demand In these experiments we consider a constant traf fic demand, i.e. the density of vehicles in the network, k , is kept constant during the entire training process. The results for three le vels of demand, and for random and supervised initial conditions for the polic y weights are sho wn in Fig. 6 and Fig. 7, respecti vely . Each ro w corresponds to a constant density lev el, while the first column depicts the NS red probabilities of the extreme states, π ( s 1 ) and π ( s 2 ) (described in section 5.2) as a function of the iteration number , and these probabilities should tend to (5) for “sensible” policies. These figures reveals considerable insight: 1. the first column in Fig. 6 rev eals that a sensible policy cannot be achiev ed for k = 0 . 85. This is apparent because probabilities π ( s 1 ) and π ( s 2 ) con ver ge to the wrong values. W e hav e verified that for congested traf fic conditions with k ≥ 0 . 75 this result is observed. 2. for k ≥ 0 . 5 in Fig. 6 all the policies obtained are suboptimal and deteriorate as density increases. 3. the best policies in Fig. 6, albeit only competiti ve, are obtained for free-flo w conditions, i.e. k ≤ = 0 . 5, with lower density leading to slightly better policies. 4. Fig. 7 shows that even starting with initial parameters from the supervised experiment, the additional DRL training under congested conditions, k ≥ 0 . 5, leads to a deterioration of the policy . Under free-flo w , con versely , policies seem to improv e slightly . These observations indicate that DRL policies lose their ability to learn and deteriorate as density increases. A possible explanation that deserv es further research is elaborated momentarily Lav al, and Zhou 11 FIGURE 6 Policies trained with constant demand and random initial parameters θ . The la- bel in each diagram giv es the iteration number and the constant density value. First column: NS red probabilities of the extreme states, π ( s 1 ) in dashed line and π ( s 2 ) in solid line. The remaining columns show the flow-density diagrams obtained at different iterations, and the last column shows the iteration producing the highest flow at k = 0 . 5 , if not reported on a earlier column. in the discussion section. W e conjecture that this result is a consequence of a property of congested urban networks and has nothing to do with the algorithm to train the DRL polic y . Non-incr emental r ewar ds In this experiment we define the rew ard at time t , R t , as the avera ge flow per lane through the intersection during ( t , t + g ) , without subtracting the MFD flow at the prev ailing density , as in all previous e xperiments. This is the standard definition in the literature and we show here that incremental re wards produce faster con ver gence. This is sho wn in Fig. 8, which depicts the NS red probabilities π ( s 1 ) and π ( s 2 ) for random initial parameters θ , for the same density lev els in the previous experiments. Comparing these results with the first column in Fig. 6 we can see that within the first 2000 or so iterations π ( s 1 ) and π ( s 2 ) tend to the wrong v alues b ut then con ver ge to the expected ones, e xcept for the heavily congested case. Lav al, and Zhou 12 FIGURE 7 Policies trained with constant demand and supervised initial parameters θ . The label in each diagram gives the iteration number and the constant density value. First col- umn: NS red probabilities of the extreme states, π ( s 1 ) in dashed line and π ( s 2 ) in solid line. The remaining columns show the flow-density diagrams obtained at differ ent iterations, and the last column shows the iteration pr oducing the highest flow at k = 0 . 5 , if not reported on a earlier column. DISCUSSION AND OUTLOOK This paper exposed se veral important properties of machine learning methods applied to traffic signal control on large networks. W e ha ve raised more questions than answers at this point, b ut our future research will focus on formalizing and extending these results. It is important to note that we have v erified that these results remain true for configurations not shown here, i.e. for dif ferent (i) number of cells n in each lane and minimum green time g , (ii) number of intersections in the network, and (iii) DRL training algorithm. Based on our results and to facilitates this discussion, we ar gue that networks hav e 4 dis- tincti ve traffic states: extreme free-flo w , moderate free-flo w , moderate congestion and extreme congestion; see Fig. 9. T o see this, we reason as follo ws. W e know that traffic is symmetric with respect to the critical density: free-flo w traf fic and congested traf fic share the same mathematical properties. In particular , close to the critical density in moderate free-flo w and moderate conges- tion, the network flow exhibits moderate v ariance, but in extreme free-flo w or extreme congestion Lav al, and Zhou 13 FIGURE 8 Non-incremental rewards with random initial parameters θ : NS red probabili- ties of the extreme states, π ( s 1 ) in dashed line and π ( s 2 ) in solid line. FIGURE 9 Learning potential for DRL in MFD: U B f f denotes the upper bound f or free- flow , U B cg denotes the upper bound f or congestion, and LB repr esents the lower bound the network flow becomes deterministic, as can be confirmed from the numerous simulated MFDs sho wn here (or from the method of cuts in [17]). W e found a property of congested urban networks, namely the congested network pr operty , that makes DRL methods unable to find sensible policies under congested traffic conditions. W e conjecture that this behavior is consistent with the shape of the MFD bounds unco vered in section 5.1, whereby the more the congestion, the less the policy affects intersection throughput. This tendency of the flo w to be independent of the policy under congestion renders gradient information less meaningful, which corrupts the learning process. Even starting with initial weights giv en by the supervised training policy , we saw that additional training under congested conditions leads to a deterioration of the policy . Similarly , we have v erified similar behavior under dynamic demands whene ver congestion appears in the netw ork. T o the best of our knowledge, this behavior has been mentioned only once in the literature [39], but no follow-up research has been generated since. This is unfortunate because this means, potentially , that all the DRL methods proposed in the literature to date are unable to learn as soon as congestion appears on the network. It also means that the limited success of DRL for traffic signal control might be explained by the congested network property , which has been ov erlooked so far . But the current explanation in the literature to explain the limited success of DRL is that the problem is non-stationary and/or non-Marko vian [40, 41], which probably e xplain why we still hav e not solved the problem. Lav al, and Zhou 14 It is important to in vestigate ne w DRL methods able to cope with the congested network property , i.e. methods able to e xtract relev ant knowledge from congested conditions. In the meantime, it is advisable to train DRL policies under free-flow conditions only , discarding any information from heavily congested ones. W e hav e sho wn here that such policies are nearly optimal for all traf fic conditions. This intriguing result indicates that most of what the agent needs to learn is encoded in free-flow conditions, and that the data in congestion is irrelev ant. W e will challenge this idea in future studies with networks that are not “ideal” as in here. W e suspect, that the congested network property will still hold for general networks be- cause ev ery network should hav e a lo wer bound for the MFD that is greater than zero under con- gestion. T o see this, consider a very bad policy that gi ves the green to the smallest queue at ev ery time instant. In free-flow conditions it is likely that the smallest queue will be an empty queue and therefore the throughput would be zero. But under congestion the smallest queue will tend to be greater than zero and therefore the throughput has no choice but to increase. W e can for- malize this idea by assuming that at each time instant the number of vehicles in the network is described by a Bernoulli process of probability k . It follows that the number of vehicles in the NS approaches is binomial with parameters n 1 + n 2 and k , where n 1 , n 2 are the number of cells of both NS approaches, respectiv ely . And similarly for the distribution of the number of v ehicles in the EW approaches. This can be used to obtain the flow through the intersection (provided outgoing approaches do not block traf fic) simply by di viding by 2 n to obtain the density and multiplying by the free-flow speed of 1 to obtain the flow . Therefore, the distrib ution of the number of vehicles flo wing through the intersection under this bad policy is simply linear transformation of the dis- tribution of the minimum of these two binomial random variables. It turns out that the percentile function of this distribution for small probabilities exhibits the desired shape for the MFD lo wer bound. The left panel in Fig. 10 (left) sho ws this function for n 1 = n 2 = n and for selected prob- abilities along with the MFD for the LQF policies for reference, where the infeasible re gion for the MFD becomes apparent. Similar behavior is observ ed for different v alues of n 1 , n 2 , not shown here for bre vity , and therefore these lower bounds should e xist in general networks. For the upper bounds, the method of cuts pro vides the answer , and the reader is referred to [16, 17] for the details. Giv en this upper bound, it becomes clear that the congested states beyond the intersection point “ A ” in Fig. 9 obe y v ery dif ferent rules compared to congestion near capacity . In this extreme congestion state the control has absolutely no influence on network flow , which is deterministic in which explains the f ailure of DRL methods to learn (because there is nothing to learn!). In moderate congestion closer to the critical density the flo w is stochastic and the lower bound starts activ ating, causing the distance between upper and lower bounds to decrease with density , which might explain the learning difficulties in this traf fic state. Moderate free-flow is similar , except that the lo wer bound remains at zero flo w . Finally , extreme free-flow is dif ferent than extreme congestion because in the former the lo wer bound is zero. The above paragraph suggests that at an y giv en density the distance between the upper bound in congestion and the lo wer bound is a measure of the potential for DRL methods to learn. This “learning potential” is maximum in free-flo w and starts shrinking until disappearing at point “ A ” in Fig. 9. But in practice this learning potential might be much narro wer than sho wn in the figure, which explains why learning difficulties start near the critical density . T o see this, consider the median outflo w in Fig. 10 (left), which indicates that most of the time a bad policy will produce remarkably high flo ws; e.g. for k = 0 . 5 the median outflow is around 0.2. But this high outflo w will be above the upper bounds in Fig. 9. This means that most of the time the throughput of an Lav al, and Zhou 15 FIGURE 10 Per centiles for the minimum (left) and maximum (right) of two independent binomial random variables with parameters 2 n and k . intersection is dictated by the infrastructure (the upper bounds) rather than the policy . This is the simplest explanation consistent with the results in this paper, b ut research is needed to understand ho w to use it for learning under congesti ve conditions. Notably , we also found that supervised learning with only two examples yields a near- optimal policy . This intriguing result indicates that extreme states s 1 and s 2 encode vital informa- tion and that the neural network can successfully extrapolate to all other states. (Notice howe ver , that this result cannot be obtained if the i nput to the neural network is a 4 × n matrix instead of the 8 × n matrix used in this paper .) Understanding precisely why this happens could lead to very ef fec- ti ve supervised learning methods based on expert knowledge, and to supplement DRL ’ s inability to learn under congested conditions. Combining the results in this paper with those in [17] we conjecture that a necessary con- dition for a policy to be optimal under congestion is that the av erage green time gi ven to any incoming approach be proportional to the length of the approach. T o see this, recall that [17] sho w that the MFD can be well approximated by a function of mainly tw o parameters: λ = the mean distance between traf fic lights divided by the mean green time, and ρ = the mean red-to-green ratio across the network. Since our network is spatially homogeneous we hav e ρ = 1. Using this in equation (17b) of [17] we infer that in the deterministic case ( δ = 0 in (17b)) the slope of the MFD in extreme congestion, namely − w ; see Fig. 9, is gi ven by: w = λ 1 / 2 + λ . (9) The reader can verify from the many MFD’ s sho wn here that w ≈ 2 / 3 and therefore that λ ≈ 1. This means that the mean green time produced by the policy matches the mean distance between traf fic lights (in dimensionless form)busy working so. Notice that λ < 1 was shown in [17] to be the short-block condition, i.e. the network becomes prone to spill back, which can hav e a severe ef fect on capacity . Con versely , a network with λ > 1 has long blocks (compared to the green time) and therefore will not exhibit spill back. Therefore, that an optimal policy produce λ < 1 is not surprising as it indicates that green times are just long enough as to not produce spill back. This highlights the importance of considering segment length when deciding signal timing, a subject rarely mentioned in the signal control literature. Lav al, and Zhou 16 A CKNO WLEDGEMENTS This study has recei ved funding from NSF research projects # 1562536 and # 1826162. REFERENCES [1] Arel, I., C. Liu, T . Urbanik, and A. Kohls, Reinforcement learning-based multi-agent system for network traffic signal control. IET Intelligent T ransport Systems , V ol. 4, No. 2, 2010, pp. 128–135. [2] Mnih, V ., K. Kavukcuoglu, D. Silver , A. A. Rusu, J. V eness, M. G. Bellemare, A. Grav es, M. Riedmiller , A. K. Fidjeland, G. Ostrovski, et al., Human-le vel control through deep rein- forcement learning. Natur e , V ol. 518, No. 7540, 2015, p. 529. [3] Silver , D., J. Schrittwieser , K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T . Hubert, L. Baker , M. Lai, A. Bolton, et al., Mastering the game of go without human kno wledge. Natur e , V ol. 550, No. 7676, 2017, p. 354. [4] Chen, J., B. Y uan, and M. T omizuka, Model-free Deep Reinforcement Learning for Urban Autonomous Dri ving. arXiv pr eprint arXiv:1904.09503 , 2019. [5] Li, L., Y . Lv , and F .-Y . W ang, T raffic signal timing via deep reinforcement learning. IEEE/CAA J ournal of Automatica Sinica , V ol. 3, No. 3, 2016, pp. 247–254. [6] Genders, W . and S. Razavi, Using a deep reinforcement learning agent for traffic signal con- trol. arXiv pr eprint arXiv:1611.01142 , 2016. [7] Chu, T . and J. W ang, Traf fic signal control with macroscopic fundamental diagrams. In 2015 American Contr ol Confer ence (ACC) , IEEE, 2015, pp. 4380–4385. [8] Chu, T ., J. W ang, L. Codecà, and Z. Li, Multi-Agent Deep Reinforcement Learning for Large- Scale T raf fic Signal Control. IEEE T ransactions on Intelligent T ransportation Systems , 2019. [9] T an, T ., F . Bao, Y . Deng, A. Jin, Q. Dai, and J. W ang, Cooperativ e deep reinforcement learn- ing for large-scale traf fic grid signal control. IEEE transactions on cybernetics , 2019. [10] Ge, H., Y . Song, C. W u, J. Ren, and G. T an, Cooperativ e Deep Q-Learning W ith Q-V alue T ransfer for Multi-Intersection Signal Control. IEEE Access , V ol. 7, 2019, pp. 40797–40809. [11] W illianms, R., T o ward a theory of reinforcement-learning connectionist systems. T echnical Report NU-CCS-88-3, Northeastern University , 1988. [12] Daganzo, C. F ., Urban gridlock: Macroscopic modeling and mitigation approaches. T rans- portation Resear ch P art B: Methodological , V ol. 41, No. 1, 2007, pp. 49–62. [13] Geroliminis, N. and C. F . Daganzo, Existence of urban-scale macroscopic fundamental diagrams: Some e xperimental findings. T ransportation Resear ch P art B: Methodological , V ol. 42, No. 9, 2008, pp. 759–770. [14] Lighthill, M. J. and G. B. Whitham, On kinematic wa ves II. A theory of traffic flow on long cro wded roads. Pr oceedings of the Royal Society of London. Series A. Mathematical and Physical Sciences , V ol. 229, No. 1178, 1955, pp. 317–345. [15] Richards, P . I., Shock wav es on the highway . Operations r esear ch , V ol. 4, No. 1, 1956, pp. 42–51. [16] Daganzo, C. F . and N. Geroliminis, An analytical approximation for the macroscopic funda- mental diagram of urban traffic. T ransportation Resear ch P art B: Methodological , V ol. 42, No. 9, 2008, pp. 771–781. [17] Lav al, J. A. and F . Castrillón, Stochastic approximations for the macroscopic fundamental diagram of urban networks. T ransportation Resear ch Pr ocedia , V ol. 7, 2015, pp. 615–630. Lav al, and Zhou 17 [18] Bellman, R., A Markovian decision process. J ournal of mathematics and mechanics , 1957, pp. 679–684. [19] Bertsekas, D. P ., Dynamic Pr ogramming: Determinist. and Stochast. Models . Prentice-Hall, 1987. [20] How ard, R. A., Dynamic programming and markov processes., 1960. [21] Puterman, M., Markovian decision pr oblems , 1994. [22] Sutton, R., The policy pr ocess: an overvie w . Overseas De velopment Institute London, 1999. [23] Chu, T ., S. Qu, and J. W ang, Large-scale traf fic grid signal control with regional reinforce- ment learning. In 2016 American Contr ol Confer ence (ACC) , IEEE, 2016, pp. 815–820. [24] Lillicrap, T . P ., J. J. Hunt, A. Pritzel, N. Heess, T . Erez, Y . T assa, D. Silver , and D. W ier- stra, Continuous control with deep reinforcement learning. arXiv pr eprint arXiv:1509.02971 , 2015. [25] Khamis, M. A. and W . Gomaa, Adaptiv e multi-objectiv e reinforcement learning with hybrid exploration for traffic signal control based on cooperativ e multi-agent framework. Engineer - ing Applications of Artificial Intelligence , V ol. 29, 2014, pp. 134–151. [26] W ei, H., N. Xu, H. Zhang, G. Zheng, X. Zang, C. Chen, W . Zhang, Y . Zhu, K. Xu, and Z. Li, CoLight: Learning Network-le vel Cooperation for T raffic Signal Control. arXiv pr eprint arXiv:1905.05717 , 2019. [27] Gong, Y ., M. Abdel-Aty , Q. Cai, and M. S. Rahman, A Decentralized Network Level Adaptive Signal Contr ol Algorithm By Deep Reinfor cement Learning , 2019. [28] Kheterpal, N., K. Parv ate, C. W u, A. Kreidieh, E. V initsky , and A. Bayen, Flow: Deep reinforcement learning for control in sumo. SUMO , 2018, pp. 134–151. [29] V initsky , E., A. Kreidieh, L. Le Flem, N. Kheterpal, K. Jang, F . W u, R. Liaw , E. Liang, and A. M. Bayen, Benchmarks for reinforcement learning in mixed-autonomy traf fic. In Confer- ence on Robot Learning , 2018, pp. 399–409. [30] Xu, M., J. W u, L. Huang, R. Zhou, T . W ang, and D. Hu, Network-wide traffic signal control based on the discov ery of critical nodes and deep reinforcement learning. J ournal of Intelli- gent T ransportation Systems , 2018, pp. 1–10. [31] Camponogara, E. and W . Kraus, Distrib uted learning agents in urban traffic control. In P or- tuguese Confer ence on Artificial Intelligence , Springer , 2003, pp. 324–335. [32] Dai, Y ., J. Hu, D. Zhao, and F . Zhu, Neural network based online traffic signal controller de- sign with reinforcement training. In 2011 14th International IEEE Confer ence on Intelligent T ransportation Systems (ITSC) , IEEE, 2011, pp. 1045–1050. [33] Lav al, J. A. and B. R. Chilukuri, Symmetries in the kinematic wa ve model and a parameter- free representation of traffic flow . T ransportation Resear ch P art B: Methodological , V ol. 89, 2016, pp. 168 – 177. [34] W olfram, S., Cellular automata as models of complexity . Nature , V ol. 311, No. 5985, 1984, p. 419. [35] Kurko vá, V ., Kolmogoro v’ s theorem and multilayer neural networks. Neural networks , V ol. 5, No. 3, 1992, pp. 501–506. [36] Sutton, R. S. and A. G. Barto, Reinfor cement learning: An intr oduction . MIT press, 2018. [37] Sutton, R. S., Learning to predict by the methods of temporal dif ferences. Machine learning , V ol. 3, No. 1, 1988, pp. 9–44. [38] Mania, H., A. Guy , and B. Recht, Simple random search provides a competitiv e approach to reinforcement learning. arXiv pr eprint arXiv:1803.07055 , 2018. Lav al, and Zhou 18 [39] de Oli veira, D., A. L. Bazzan, B. C. da Silva, E. W . Basso, L. Nunes, R. Rossetti, E. de Oli veira, R. da Silv a, and L. Lamb, Reinforcement Learning based Control of T raf- fic Lights in Non-stationary En vironments: A Case Study in a Microscopic Simulator . In EUMAS , 2006. [40] Choi, S. P ., D.-Y . Y eung, and N. L. Zhang, Hidden-mode mark ov decision processes for nonstationary sequential decision making. In Sequence Learning , Springer , 2000, pp. 264– 287. [41] Da Silv a, B. C., E. W . Basso, A. L. Bazzan, and P . M. Engel, Dealing with non-stationary en vironments using context detection. In Pr oceedings of the 23r d international confer ence on Machine learning , A CM, 2006, pp. 217–224.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment