Model-Free Practical Cooperative Control for Diffusively Coupled Systems
In this paper, we develop a data-based controller design framework for diffusively coupled systems with guaranteed convergence to an $\epsilon$-neighborhood of the desired formation. The controller is comprised of a fixed controller with an adjustabl…
Authors: Miel Sharf, Anne Koch, Daniel Zelazo
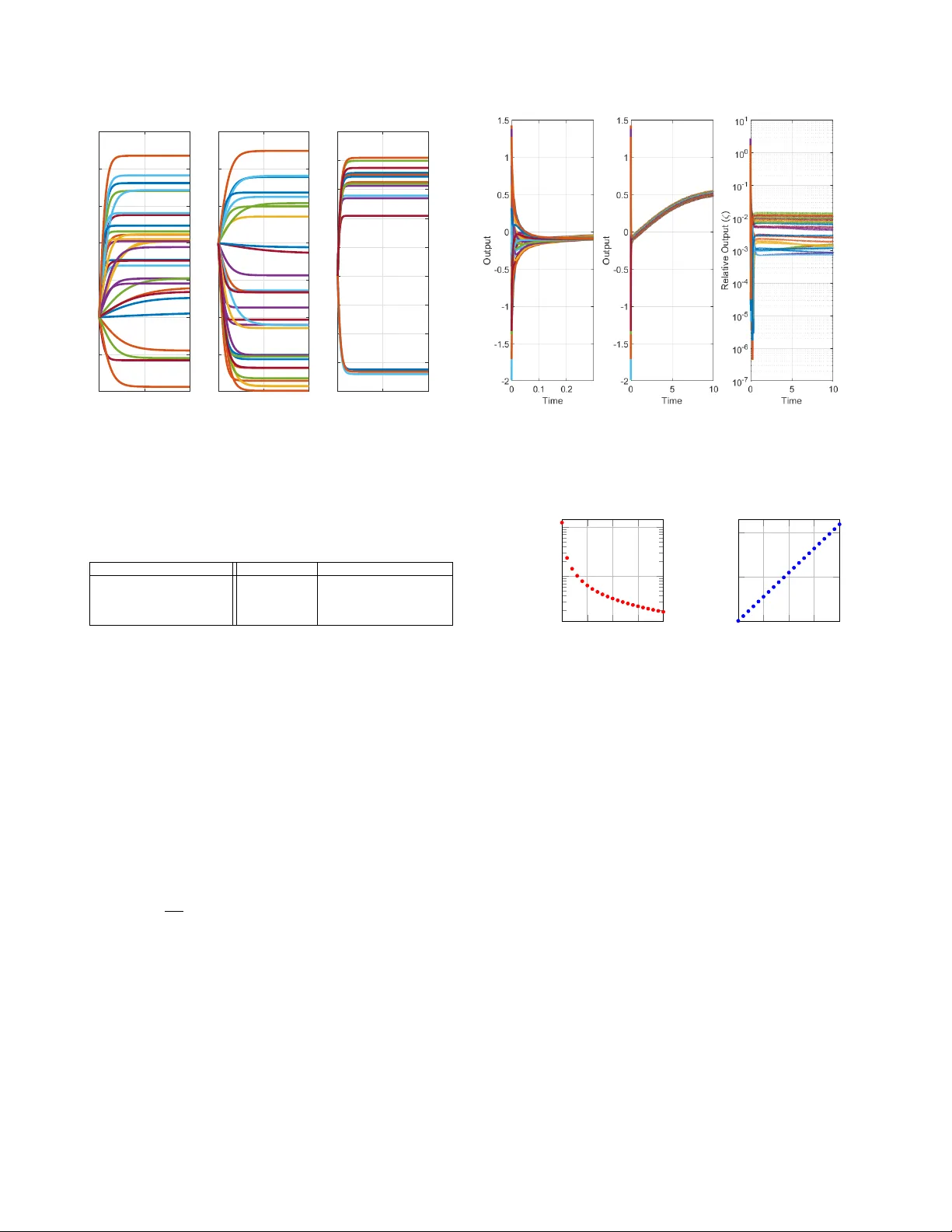
1 Model-Free Practical Cooperati v e Control for Dif fusi v ely Coupled Systems Miel Sharf, Anne K och, Daniel Zelazo and Frank Allg ¨ ower Abstract —In this paper , we develop a data-based controller de- sign framework f or diffusively coupled systems with guaranteed con vergence to an -neighborhood of the desired formation. The controller is comprised of a fixed controller with an adjustable gain on each edge. Via passivity theory and network optimization we not only prov e that there exists a gain attaining the desired formation control goal, but we present a data-based method to find an upper bound on this gain. Furthermore, by allowing for additional experiments, the conservatism of the upper bound can be reduced via iterative sampling schemes. The introduced scheme is based on the assumption of passive systems, which we relax by discussing different methods for estimating the systems’ passivity shortage, as well as applying transf ormations passivizing them. Finally , we illustrate the developed model-free cooperative control scheme with a case study . I . I N T RO D U C T I O N Multi-agent systems hav e recei ved e xtensiv e attention in the past years, due to their appearance in many fields of engineering, exact sciences and social sciences. Examples include robotics [1], traf fic engineering [2] and ecology [3]. The state-of-the-art approach to model-based control for multi- agent systems offers rigorous stability analysis, performance guarantees and systematic insights into the considered prob- lem. Howe ver , with the growing complexity of systems, the modeling process is reaching its limits. Obtaining a reliable mathematical model of the agents becomes a time-intensive and arduous task. At the same time, modern technology allo ws for gathering and storing more and more data from systems and processes, inciting an increasing interest in data-driven contr ol . There are two main approaches for data-driv en control. The first is model-based data-driv en control, which uses data to identify a model from the problem, which is in turn used to solve the synthesis problem [4], [5]. In this case, the model estimation errors must be taken into account when solving the synthesis problem. The second is model-free control, which does not try to estimate a model for the system. The latter can be further bisected into approximate dynamic programming methods and direct policy search. The former ev aluates a score for each state-action pair , and then obtains an optimal control policy using dynamic programming [6], and the latter tries to find the optimal policy directly , e.g. by gradient descent or via M. Sharf is with the Division of Decision and Control Systems, KTH Royal Institute of T echnology , Stockholm, Sweden. sharf@kth.se . A. K och and F . Allg ¨ ower are with the Institute for Systems Theory and Automatic Control, Univ ersity of Stuttgart, Germany . { anne.koch,frank.allgower } @ist.uni-stuttgart.de . D. Zelazo is with the Faculty of Aerospace Engineering, Israel Institute of T echnology , Haifa, Israel dzelazo@technion.ac.il . This work was supported by the German-Israeli Foundation for Scientific Research and Dev elopment. a non-parametric description of the possible trajectories [7]. These methods ha ve all been applied to multi-agent systems as well, with varying degrees of success [6], [8]–[10]. In this work, we develop a data-driv en controller synthesis approach for multi-agent systems that comes with rigorous theoretical analysis and stability guarantees for the closed loop, with almost no assumptions on the agents and few measure- ments needed. Our approach is based on high-gain control as well as passivity . Some ideas on high-gain approaches to cooperati ve control can be found in [11] and references therein. In [12], the authors provide a high-gain condition in the design of distributed H ∞ controllers for platoons with undirected topologies, while there are also many approaches to (adaptiv ely) tune the coupling weights, e.g. [13]. Our approach provides an upper bound on a high-gain controller using passivity measures. Passivity properties of the components can provide suf ficient abstractions of their detailed dynamical models for guaranteed control. Such passivity properties can be obtained from data as ongoing work sho ws (e.g., [14]–[16]). Passi vity is a well-known tool for controller synthesis [17], which is useful, beyond con ver gence analysis, for its powerful properties such as compositionality . It was first introduced in the field of multi-agent systems in the seminal works of Arcak [18], [19], and was since explored in many v ariants in the context of multi-agent systems in many other works [1], [20]– [26]. W e focus on the variant known as maximal equilibrium independent passivity (MEIP), presented in [22]. The notion of MEIP establishes a connection between multi-agent systems and network optimization, see [22]–[26]. Dif ferent synthesis problems have been solved using this network optimization framew ork assuming an exact model for each of the agents exists [23], [24], [27]. More precisely , one needs a perfect description of the steady-state input-output beha vior of the agents. Thus, these methods cannot be applied in our case. As we said, this work generally studies the problem of con- troller synthesis for dif fusiv ely coupled systems. The control objectiv e is to conv erge to an -neighborhood of a constant prescribed relativ e output vector . That is, for some tolerance > 0 , we aim to design controllers so that the steady-state limit of the relativ e output is -close to the prescribed values. The related problem of practical synchronization of multi- agent systems hav e been considered in [28], in which the agents were assumed to be known up to some bounded additi ve disturbance. Howe ver , a nominal model was needed to get practical synchronization. It was also pursued in [29], where strong coupling was used to driv e agents close to a common trajectory , but again, a model for the agents was needed. Our contributions are as follows. W e present a model-free 2 data-driv en method for solving the practical formation control problem. This is done by cascading a fixed controller and an adjustable gain on each edge. W e show that this gain can be chosen to guarantee a solution to the practical formation control problem. W e then provide schemes to compute this gain offline only from input-output data without any model of the agents. In fact, this gain can be computed from only three experiments (per agent), and it can become less conservati ve with further data samples. If iterativ e experiments can be performed, we also provide an approach for applying different gains ov er different edges to further reduce any conservatism. W e surve y the different advantages for each of the methods and discuss their applicability in terms of the number of required measurements, or trade-offs in terms of energy . W e also provide simulations presenting the effecti veness of the presented model-free control methods. T o the best of the au- thors’ knowledge, no prior works consider data-driv en control of multi-agent systems using passi vity . Furthermore, this is the first application of the network optimization framework of [22], [24] where the agents do not hav e an exact model. Notations: W e employ use notions from algebraic graph theory [30]. An undirected graph G = ( V , E ) consists of finite sets of vertices V and edges E ⊂ V × V . W e denote the edge having ends i and j in V by k = { i, j } ∈ E . For each edge k , we pick an arbitrary orientation and denote k = ( i, j ) . The incidence matrix E ∈ R | E |×| V | of G is defined such that for an edge k = ( i, j ) ∈ E , we have [ E ] ik = +1 , [ E ] j k = − 1 , and [ E ] `k = 0 for ` 6 = i, j . diam( G ) denotes the diameter of G . W e also use notions from linear algebra. For ev ery vector v ∈ R n , diag ( v ) denotes the n × n diagonal matrix with the entries of v on its diagonal. The image of any linear map T between v ector spaces will be denoted by Im( T ) . Also, for two sets A, B ⊆ R d , we define A + B = { a + b : a ∈ A, b ∈ B } . Furthermore, k · k is the Euclidean norm. Lastly , if Σ is a dynamical system, and M is a linear map of appropriate dimension, we can consider the cascaded system of Σ and M . The cascade of Σ after M is denoted Σ M , and the cascade of Σ before M is denoted M Σ . I I . B A C K G RO U N D : N E T W O R K O P T I M I Z A T I O N A N D P A S S I V I T Y I N C O O P E R A T I V E C O N T R O L Our goal in this subsection is to describe the diffusi ve coupling networks studied in [22], and to present the passivity- based network optimization frame work achie ved for multi- agent systems. See also [23], [24]. A. Diffusively Coupled Systems and Steady-State Relations Diffusi vely coupled networks are composed of agents { Σ i } i ∈ V interacting ov er a graph G = ( V , E ) using edge controllers { Π e } e ∈ E . Each vertex i ∈ V represents an agent and each edge e ∈ E represents a controller . W e model them as SISO dynamical systems: Σ i : ( ˙ x i = f i ( x i , u i ) y i = h i ( x i , u i ) , Π e : ( ˙ η e = φ e ( η e , ζ e ) µ e = ψ e ( η e , ζ e ) , (1) where the agents’ state, input and output are x i , u i , y i respec- tiv ely , and the controllers’ state, input and output are η e , ζ e , µ e respectiv ely . T o understand the coupling of these systems, we E E T ζ ( t ) µ ( t ) u ( t ) y ( t ) Σ 1 Σ 2 Σ | V | . . . Π 1 Π 2 Π | E | . . . Fig. 1. Block-diagram of the diffusiv ely-coupled network (Σ , Π , G ) . consider the stacked inputs and outputs of the agents and controllers as y = [ y 1 , ..., y | V | ] T , and similarly for u, ζ , µ . The system is connected via the relations ζ = E T y and u = −E µ , where E is the incidence matrix of the graph G . In other words, if we stack all agents to a dynamical system Σ , and stack all controllers to a dynamical system Π , the closed-loop is the feedback connection of Σ and E Π E T . See Fig. 1 for an illustration of the network, which we will denote by ( G , Σ , Π) . W e will be interested in steady-states of the closed-loop system. It’ s clear that if the stacked vectors (u , y , ζ , µ ) are a steady-state for ( G , Σ , Π) , then for every vertex i ∈ V , (u i , y i ) is a steady-state input-output pair for the system Σ i , and for ev ery edge e ∈ E , ( ζ e , µ e ) is a steady-state input-output pair for the system Π e . This motiv ates the exploration of steady- state input-output relations , first defined in [22]. Definition 1. The steady-state relation of a system is a set containing all the steady-state input-output pair s of the system. W e will denote the steady-states relations of Σ i , Π e , Σ , and Π as k i , γ e , k , and γ , accordingly . Remark 1. W e will sometimes abuse the notation and consider this relation as a set-valued map. Indeed, for any input u we can define the set k (u) by k (u) = { y : (u , y) ∈ k } , and similarly for k i , γ e , and γ . W e also consider the inver se r elation k − 1 as the set-valued map assigning to a steady-state output y the set k − 1 (y) = { u : y ∈ k (u) } , i.e., the set of all steady-state inputs corr esponding to the steady-state output y . W e define this similarly for k i , γ e , and γ . Thus, (u , y , ζ , µ ) is a steady-state of ( G , Σ , Π) if and only if y ∈ k (u) , µ ∈ γ ( ζ ) , ζ = E T y and u = −E µ . Equiv alently , y is a steady-state output of ( G , Σ , Π) if and only if the zero vector 0 lies in the set k − 1 (y) + E γ ( E T y) [22], [23]. B. Maximum Equilibrium-Independent P assivity and the Net- work Optimization F rame work The main tool allowing us to connect multi-agent systems to the network optimization world is monotone relations. 3 Definition 2. A steady-state relation is monotone if for any two points (u 1 , y 1 ) and (u 2 , y 2 ) in the r elation, u 1 < u 2 implies y 1 ≤ y 2 . W e say that a monotone r elation is maximally monotone if it is not contained in a lar ger monotone r elation. In order to connect this definition to the system-theoretic world, we define the following variant of passivity: Definition 3 ( [22]) . A SISO system is said to be (output- strictly) maximum equilibrium-independent passiv e (MEIP) if the following two conditions hold: i) The system is (output-strictly) passive with respect to any steady-state input-output pair it has, and ii) it’s steady-state r elation is maximally monotone. One important property of maximally monotone relations is that they are subgradients of con ve x functions [31]. In this direction, we assume that the agents and controllers of the diffusi vely-coupled network ( G , Σ , Π) are MEIP . Let K i , and Γ e be the corresponding conv ex integral functions for the steady-state relations k i , γ e . In other words, ∂ K i = k i and ∂ Γ e = γ e , where ∂ denotes the subdif ferential of con ve x functions [31]. W e shall denote K = P i ∈ V K i and Γ = P e ∈ E Γ e , so that ∂ K = k and ∂ Γ = γ . The dual functions of K i , Γ e , K, Γ are defined using the Legendre transform, K ? (y) = sup u { u T y − K (u) } = − inf u { K (u) − u T y } , and similarly for K ? i , Γ ? e and Γ ? . W e note that ∂ K ? = k − 1 , ∂ Γ ? = γ − 1 , ∂ K ? i = k − 1 i and ∂ Γ ? e = γ − 1 e [31]. W e now resume our interest in steady-states for the diffu- siv ely coupled network ( G , Σ , Π) . W e recall that y was the steady-state output of the diffusi vely coupled network if and only if 0 ∈ k − 1 (y) + E γ ( E T y) . Restating this result in the language of conv ex functions giv es the following theorem. Theorem 1 ( [22]) . Consider the diffusively coupled network ( G , Σ , Π) . Assume all agents Σ i ar e MEIP , and all contr ollers Π e ar e output-strictly MEIP (or vice versa). Let k i , γ e , k and γ be the steady-state relations of Σ i , Π e , Σ and Π accor dingly , and let K i , Γ e , K, Γ be the corresponding conve x integr al functions. Then the closed-loop system conver ges to a steady- state (u , y , ζ , µ ) , such that (y , ζ ) and (u , µ ) ar e dual optimal solutions to the following con vex optimization pr oblems: Optimal P otential Problem Optimal Flow Problem min y ,ζ K ? ( y ) + Γ( ζ ) s . t . E T y = ζ min u,µ K ( u ) + Γ ? ( µ ) s . t . µ = −E u. The two network optimization problems above will be de- noted often by (OPP) and (OFP) respecti vely . These problems are fundamental in the field of network optimization, dealing with optimization problems defined on graphs [31]. The names “optimal potential problem” and “optimal flow problem” are inspired from standard nomenclature in this field. I I I . P RO B L E M F O R M U L A T I O N W e focus on relative-output based formation control. In this problem, the agents know the relati ve output ζ e = y i − y j with respect to their neighbors, and the control goal is to con verge to a steady-state with prescribed relative outputs ζ e = y i − y j . Examples include the consensus problem, in which all outputs must agree, as well as relative-position based formation control of robots, in which the robots are required to org anize themselves in a desired spatial structure [32]. More specifically , we are given a graph G and agents Σ , and our goal is to design controllers Π so that the signal ζ ( t ) of the diffusi vely coupled network ( G , Σ , Π) will con verge to a desired, gi ven steady-state vector ζ ? . One e vident solution is to apply a (shifted) integrator as a controller . Howe ver , this solution will not always work ev en when the agents are MEIP . Example 1. Consider agents Σ i with inte grator dynamics, together with (shifted) integr ator contr ollers Π e , wher e we desir e consensus (i.e., ζ ? = 0 ) over a connected graph G , Σ i : ( ˙ x i = u i y i = x i , Π e : ( ˙ η e = ζ e µ e = η e . The trajectories of the diffusively-coupled system can be understood by noting that the closed-loop system yields the second-or der dynamics ¨ x = −E E T x . Decomposing x using a basis of eigen vectors of the graph Laplacian E E T , which is a positive semi-definite matrix, we see that the trajectory of x ( t ) oscillates ar ound the consensus manifold { x : ∃ λ ∈ R x = λ 1 n } . Specifically , x ( t ) − 1 n 1 T n x ( t ) 1 n = P n i =2 c i cos( √ λ i t + ϕ i ) v i , where λ 2 , . . . , λ n > 0 are the non-trivial eigen values of the graph Laplacian, v 2 , . . . , v n ar e corresponding unit- length eigen vectors, and c i , ϕ i ar e constants depending on the initial conditions x (0) , η (0) . Thus x ( t ) = y ( t ) does not con verg e anywher e, let alone to consensus. Moreo ver , ζ ( t ) does not con verg e as t → ∞ , as E ζ ( t ) = E E T y ( t ) = P n i =2 λ i c i cos( √ λ i t + ϕ i ) v i . Thus the integr ator contr oller does not solve the formation contr ol problem in this case. Even if the integrator would solve this problem in general, we would like more freedom in choosing the controller . In practice, one might want to design the controller to satisfy extra requirements (like H 2 - or H ∞ -norm minimization, or making sure that certain restrictions on the behavior of the system are not broken). W e do not try and satisfy these more complex requirements, but instead show that a large class of controllers can be used to solve the practical formation control problem. In turn, this allo ws one to choose from a wide range of controllers, and try and satisfy additional desired properties. [23] offers an algorithm solving the problem, assuming the agents are MEIP and a perfect model of them is known. This algorithm allows a lot of freedom in the choice of controllers. Howe ver , in practice we oftentimes have no exact model of the agents, or any closed-form model. T o formalize the goals we aim at, we define the notion of practical formation control. Problem 1. Given a graph G , agents Σ , a desir ed formation ζ ? ∈ Im( E T ) , and an error mar gin ε , find a contr oller Π so that the relative output vector ζ ( t ) of the network ( G , Σ , Π) con verg es to some ζ 0 such that k ζ ? − ζ 0 k ≤ ε . By choosing suitable error margins ε , practical formation control (compared to formation control) comprises no re- striction or real drawback in any application case. Therefore, solving the practical formation control problem constitutes an interesting problem especially for unknown dynamics of the agents. Thus, we striv e to dev elop an algorithm solving this 4 Fig. 2. Block-diagram of the diffusiv ely-coupled network (Σ , Π , G , A ) . practical formation control problem without a model of the agents while still providing rigorous guarantees. The underlying idea of our approach is amplifying the controller output. Consider the scenario depicted in Fig. 2, where the graph G , the agents Σ and the nominal controller Π are fixed, and the gain matrix A is a diagonal matrix A = diag( { a e } e ∈ E ) with positiv e entries. W e will show in the following that when the gains a e become large enough, the controller dynamics Π become much more emphasized than the agent dynamics Σ . By correctly choosing the nominal controller Π according to ζ ? , we can hence achieve arbitrarily close formations to ζ ? , as the ef fect of the agents on the closed- loop dynamics will be dampened. W e denote the diffusi vely- coupled system in Fig. 2 as the 4-tuple ( G , Σ , Π , A ) , or as ( G , Σ , Π , a ) where a is the vector of diagonal entries of A . In case A has uniform gains, i.e., A = α I , we denote the system as ( G , Σ , Π , α 1 n ) . W e make an assumption in order to apply the network optimization framew ork of Theorem 1: Assumption 1. The agents { Σ i } i ∈ V ar e all MEIP , and the chosen contr ollers { Π e } e ∈ E ar e all output-strictly MEIP . Before expanding on the suggested controller design, we discuss Assumption 1. In practice, we might not know if an agent is MEIP . Hence, we discuss how to either verify MEIP for the agents, or otherwise determine their shortage of passi vity . W e also discuss how to passivize the agents in the latter case. First, in some occasions, we might not know a model for the agents, but some known general structure properties. For example, one might know that an agent can be modeled by a gradient system, or a Euler-Lagrange system, but the exact model is unknown due to uncertainty on the characterizing parameters. In that case, we can use analytical results to verify MEIP . T o exemplify this idea, we show how a very rough model can be used to prove that a system is MEIP . Proposition 1. Consider a contr ol-affine SISO system: ˙ x = − f ( x ) + g ( x ) u ; y = h ( x ) . (2) Assume that g is positive, that f /g , h : R → R ar e continuous ascending functions, and that either lim | x |→∞ | f ( x ) /g ( x ) | = ∞ or lim | x |→∞ | h ( x ) | = ∞ . Then (2) is MEIP . The proof is available in the appendix. See also [24] y i u i − Σ i C i Fig. 3. Passi vation of a passivity-short agent using feedback. for a treatment on gradient systems with oscillatory terms. Similarly , one can use a highly uncertain model to gi ve an estimate about equilibrium-independent passivity indices. Another approach for verifying Assumption 1 is learning input-output passivity properties from trajectories. For L TI systems, the shortage of passivity can be asymptotically re- vealed by iterati vely probing the agents and measuring the output signal [15]. In [16], the authors showed that ev en one input-output trajectory (with persistently exciting input) is sufficient to find the shortage of passivity of an L TI system. For nonlinear agents, one can apply approaches presented in [14], [33], under an assumption on Lipschitz continuity of the steady-state relation. Howe ver , for general non-linear systems, this is still a work in progress. W e note that for L TI systems, output-strict passivity directly implies output strict MEIP [22]. Using either approach, we can either find that an agent is MEIP , or that it has some shortage of passivity , and we need to render the agent passive in order to apply the model-free con- trol approaches presented in this paper . W e can use passivizing transformations in order to get a passive augmented agent. For example, if the agent has output-shortage of passivity s i > 0 , we can apply a controller C i : y i 7→ ν i y i to the agent as in [25], with ν i > s i , as shown in Fig. 3. It can be shown that the augmented agent is output-strictly MEIP in this case. More generally , one could deal with more complex shortages of passivity , namely simultaneous input- and output-shortage of passi vity , using more complex transformations [26]. W ith this discussion and relaxation of Assumption 1, we re- turn to our solution of the practical formation control problem. W e considered closed-loop systems of the form ( G , Σ , Π , a ) , where a is a vector of edge gains. From here, the paper div erges into two sections. The next section deals with theory and analysis for uniform edge gains. The following section deals with the case of heterogeneous edge gains. I V . P R AC T I C A L F O R M A T I O N C O N T RO L W I T H U N I F O R M G A I N S The chapter is split into two parts. The first part deals with the theory , and the second part deals with the corresponding implementation of practical formation control synthesis using uniform gains on the edges. A. Theory W e wish to understand the effect of amplification on the steady-state of the closed-loop system. For the remainder of the section, we fix a graph G , agents Σ and controllers Π such that Assumption 1 holds. W e consider the dif fusiv ely coupled system ( G , Σ , Π , α 1 n ) in Fig. 2, where the gains ov er all edges are identical and equal to α > 0 , and wish to understand the 5 effect of α . W e let K and Γ denote the sum of the integral functions of the agents and of the controllers, respectiv ely . W e first study the steady-states of this diffusi vely coupled system. Lemma 1. Under the assumptions above, the closed-loop con verg es to a steady-state, and the steady-states y , ζ of the closed-loop system are minimizers of the following problem: min y ,ζ K ? ( y ) + α Γ( ζ ) (3) s.t. E T y = ζ . Pr oof. W e define a ne w stacked controller, ¯ Π = α Π , by cascading the previous controller Π with the gain α . The resulting controller ¯ Π is again output-strictly MEIP, and we let ¯ γ , ¯ Γ denote the corresponding steady-state input-output relation and integral function. Theorem 1 implies that the closed-loop system (with ¯ Π ) con verges to minimizers of (OPP) for the system ( G , Σ , ¯ Π) . Hence, we have ¯ γ ( ζ ) = αγ ( ζ ) for any ζ ∈ R | E | . Therefore, (OPP) for the system ( G , Σ , ¯ Π) reads: min y ,ζ K ? ( y ) + α Γ( ζ ) s.t. E T y = ζ , as ¯ Γ = α Γ . Our goal is to show that when α 1 , the relativ e output vector ζ of the diffusi vely coupled system ( G , Σ , Π , α 1 n ) globally asymptotically con verges to an ε = ε ( α ) -ball around the minimizer of Γ , and lim α →∞ ε ( α ) = 0 . Thus, if we design the controllers so that Γ is minimized at ζ ? , then α 1 provides a solution to the ε -practical formation control problem. Indeed, we can prove the following theorem: Theorem 2. Consider the closed-loop system ( G , Σ , Π , α 1 n ) , wher e the agents are MEIP and the controller s ar e output- strictly MEIP. Assume Γ has a unique minimizer in Im( E T ) , denoted ζ 1 . F or any ε > 0 , ther e e xists some α 0 > 0 , such that for all α > α 0 and for all initial conditions, the closed- loop conver ges to a vector y satisfying kE T y − ζ 1 k < ε . In particular , if ζ 1 = ζ ? , we solve the practical contr ol problem. In order to prove the theorem, we study (OPP) for the diffusi vely coupled system ( G , Σ , Π , α 1 n ) , as described in Lemma 1. In order to do so, we need to prove a couple of lemmas. The first deals with lo wer bounds on the v alues of con vex functions away from their minimizers. Lemma 2. Let U be a finite-dimensional vector space. Let f : U → R be con vex, and suppose x 0 ∈ U is the unique minimum of f . Then for any δ > 0 there is some M > f ( x 0 ) such that for any point x ∈ U , if f ( x ) < M then k x − x 0 k < δ . Pr oof. W e assume without loss of generality that f ( x 0 ) = 0 . Let µ be the minimum of f on the set { x ∈ U : || x − x 0 || = δ } , which is positi ve since x 0 is f ’ s unique minimum and the set { x ∈ U : k x − x 0 k = δ } is compact. W e know that, for any y ∈ U , the difference quotient f ( x 0 + λy ) − f ( x 0 ) λ is an increasing function of λ > 0 (see Theorem 23.1 of [31]). Manipulating this inequality shows that for any x ∈ U , || x || ≥ δ implies f ( x ) ≥ || x || δ µ , and in particular f ( x ) ≥ µ whene ver || x || ≥ δ . Thus, if f ( x ) < µ then we must have || x − x 0 || < δ , so we can choose M = µ and complete the proof. The second lemma deals with minimizers of perturbed versions of con ve x functions on graphs. Lemma 3. Fix a graph G = ( V , E ) and let E be its incidence matrix. Let K : R | V | → R be a con vex function, and let Γ : R | E | → R be a conve x function with a unique minimum ζ 1 when r estricted to the set Im( E T ) . F or any α > 0 , consider the function F α (y) = K ? (y) + α Γ( E T y) . Then for any ε > 0 , ther e exists some α 0 > 0 such that if α > α 0 then all of F α ’ s minima, y , satisfy kE T y − ζ 1 k < ε . Pr oof. By subtracting constants from K ? and Γ , we may assume without loss of generality that min( K ? ) = min(Γ) = 0 . Choose some y 0 ∈ R | V | such that E T y 0 = ζ 1 and let m = K ? (y 0 ) . Note that F α ( y 0 ) = m , meaning that if y is any minimum of F α , it must satisfy F α (y) ≤ m , and in particular Γ( E T y) ≤ m α . Now , from Lemma 2 we know that there is some M > 0 such that if Γ( E T y) < M then kE T y − ζ 1 k < ε . If we choose α 0 = m M , then whenev er α > α 0 we ha ve Γ( E T y) < M , implying kE T y − ζ 1 k < ε . W e now connect the pieces and prove Theorem 2. Pr oof. Lemma 1 implies that the closed-loop system always con verges to a minimizer of (3). Lemma 3 prov es that there exists α 0 > 0 such that if α > α 0 then all minimizers of (OPP) satisfy kE T y − ζ 1 k < ε . This prov es the theorem. Remark 2. The parameter s ε and ζ ? can be used to estimate the minimal r equired gain α 0 by following the pr oofs of Lemma 2 and Lemma 3. Namely , α 0 ≤ m M wher e M is the minimum of Γ on the set { ζ ∈ Im( E T ) : k ζ − ζ ? k = ε } , and m = K ? (y 0 ) − min y K ? (y) = K ? (y ? ) + K (0) wher e y ? ∈ R | V | is any vector satisfying E T y ? = ζ ? . Corollary 1. Let ( G , Σ , Π , α 1 n ) satisfy Assumption 1 and let ( G , Σ Int , Π) be a network comprised of integr ator dynamics for each agent. Denote the r elative outputs of each system as ζ ( t ) and ζ Int ( t ) respectively . Then for any ε > 0 , ther e exists an α 0 > 0 such that if α ≥ α 0 , then the r elative outputs ζ ( t ) and ζ Int ( t ) both conver ge to constant vectors ζ ? and ζ ? Int r espectively , and satisfy k ζ ? − ζ ? Int k ≤ ε . Pr oof. The agents Σ Int are MEIP . Thus, by Theorem 1, we know that the diffusi vely-coupled system ( G , Σ Int , Π) con- ver ges to a steady-state, and its steady-state output is a min- imizer of the associated (OPP) problem. Note that the input- output relation of Σ Int is giv en via k − 1 (y) = 0 , meaning the integral function K ? is the zero function. Thus the associated problem (OPP) is the unconstrained minimization of Γ( E T y) , meaning that the system ( G , Σ Int , Π) con verges, and its output con verges to a minimizer of Γ( E T y) , i.e., its relativ e output ζ ( t ) conv erges to the minimizer of Γ on Im( E T ) . Applying Theorem 2 now completes the proof. Remark 3 (Almost Data-free control) . Cor ollary 1 can be thought of as a synthesis pr ocedur e. Indeed, we can solve the synthesis pr oblem as if the agents wer e single inte grators, and then amplify the contr oller output by a factor α . The cor ollary 6 shows that for any ε > 0 , ther e is a threshold α 0 > 0 such that if α > α 0 , the closed-loop system con verg es to an ε - neighborhood of ζ ? . W e note that we only know that α 0 exists as long as the agents are MEIP . Computing an estimate on α 0 , however , r equir es one to conduct a few experiments. Ther e ar e a few possible appr oaches to over come this r equirement. One can try an iterative scheme, in which the edge gains ar e updated between iterations. Gradient-descent and extr emum-seeking approac hes are discussed in the next section (see Algorithm 3), but both r equir e to measur e the system between iterations. Another appr oach is to update the edge gains on a much slower time-scale than the dynamics of the system. This r esults in a two time-scale dynamical system, wher e the gains a e of the system ( G , Σ , Π , a ) ar e updated slowly enough to allow the system to con ver ge. T aking a e as uniform gains of size α , and slowly increasing α , assur es that eventually , α > α 0 , so the system will con verg e ε -close to ζ ? . The only data we need is whether or not the system has alr eady con verg ed to an ε -neighborhood of ζ ? 1 , to know whether α should be updated or not. This r equires no data on the trajectories themselves, nor information on the specific steady- state limit, but only knowing whether the contr ol goal has been achie ved, which is the coarsest form of data. This results in an almost data-free solution of the practical formation contr ol pr oblem, which is valid as long as the agents ar e MEIP . B. Data-Driven Determination of Gains In the previous subsection, we introduced a formula for a uniform gain α described by the ratio of m and M , that solves the practical formation problem, where m and M are as defined in Remark 2. The parameter M depends on the inte gral function Γ of the controllers, ev aluated on well-defined points, namely { ζ ∈ Im( E T ) : k ζ − ζ ? k = ε } . Thus we can compute M exactly with no prior knowledge on the agents. This is not the case for the parameter m , which depends on the integral function of the agents. Without knowledge of any model of the agents, we need to obtain an estimate of m solely on the basis of input-output data from the agents. From Remark 2, we kno w that m = P n i =1 ( K ? i (y ? i ) + K i (0)) = P n i =1 m i for some y ? ∈ R n such that E T y ? = ζ ? . W ithout a model of the agents, m cannot be computed directly , but we can find an upper bound on m from measured input- output trajectories via the in verse relations k − 1 i , i = 1 , . . . , n . Proposition 2. Let (u ? i , y ? i ) , (u i, 1 , y i, 1 ) , (u i, 2 , y i, 2 ) , . . . , (u i,r , y i,r ) and (0 , y i, 0 ) be steady-state input-output pairs for agent i , for some r ≥ 0 . Then: m i ≤ u i, 1 (y i, 1 − y i, 0 ) + · · · + u i,r (y i,r − y i,r − 1 ) + u ? i (y ? i − y i,r ) . Pr oof. W e prov e the claim by induction on the number of steady-state pairs, r + 2 . First, consider the case r = 0 of two steady-state pairs. Because (0 , y i, 0 ) is a steady-state pair , we know that K i (0) = − K ? i (y i, 0 ) by Fenchel duality . Similarly , K i (u ? i ) = u ? i y ? i − K ? i (y ? i ) . Thus, m i = K ? i (y ? i )+ K i (0) = K ? i (y ? i ) − K ? i (y i, 0 ) ≤ u ? i (y ? i − y i, 0 ) , 1 Such data can be obtained by different methods, e.g. checking the size of the derivati ves, using physical intuition in some cases, or using passivity to determine conv ergence rates as in [27]. where we use the inequality K ? i ( b ) − K ? i ( c ) ≥ k − 1 i ( c )( b − c ) for b = y i, 0 and c = y ? i . Now , we move to the case r ≥ 1 . W e write m i as ( K ? i (y ? i ) − K ? i (y i,r )) + ( K ? i (y i,r ) − K i (0)) . The first element can be shown to be bounded by u ? i (y ? i − y i,r ) by the case r = 0 . The second element is bounded by u i, 1 (y i, 1 − y i, 0 ) + · · · + u i,r (y i,r − y i,r − 1 ) by induction hypothesis, as we use a total of r + 1 steady-state pairs. Thus, m i is no greater than the sum of the two bounds, u i, 1 (y i, 1 − y i, 0 ) + · · · + u i,r (y i,r − y i,r − 1 ) + u ? i (y ? i − y i,r ) . Remark 4. If we only have two steady-state pairs, (u ? i , y ? i ) and (0 , y i, 0 ) , the estimate on m i becomes m i ≤ u ? i (y ? i − y i, 0 ) . Thus two steady-state pairs, corresponding to two measur e- ments/experiments, ar e enough to yield a meaningful bound on m i . W e do note that mor e experiments yield better estimates of m i , i.e., if r ≥ 1 the estimate in Pr oposition 2 is better as long as (y i, 0 , y i, 1 , ..., y i,r , y ? i ) is a monotone series. W ith can use Remark 4 to compute an upper bound on m from the two steady-state pairs (u ? i , y ? i ) and (0 , y i, 0 ) per agent. Designing experiments to measure these quantities is possible, but can require additional information on the plant, e.g. output- strict passivity . Instead, we take another path and estimate y i, 0 and u ? i instead of computing them directly . Indeed, we use the monotonicity of the steady-state input-output relation to bound u ? i and y i, 0 from abov e and below . The approach is described in Algorithm 1. It is important to note that the closed-loop experiments are done with a output-strictly MEIP controller , which assure that the closed-loop system indeed con verges. Algorithm 1: Estimating m i for an MEIP Agent 1 Run the system in Fig. 4 with β i small and y ref = 1 β i ; 2 W ait for con vergence, and measure the steady-state output y i, + and the steady-state input u i, + ; 3 Run the system in Fig. 4 with β i small and y ref = − 1 β i ; 4 W ait for con vergence, and measure the steady-state output y i, − and the steady-state input u i, − ; 5 if y i, + < y ? i then 6 Run the system in Fig. 4 with β i = 1 and y ref y ? i ; 7 W ait for con vergence, and measure the steady-state input u i, 2 and output y i, 2 ; 8 else 9 Run the system in Fig. 4 with β i = 1 , y ref y ? i ; 10 W ait for con vergence, and measure the steady-state input u i, 2 and output y i, 2 ; 11 end 12 Sort { u i, − , u i, + , u i, 2 } . Denote the result by { U 1 , U 2 , U 3 } ; 13 Sort { y i, − , y i, + , y i, 2 } . Denote the result by { Y 1 , Y 2 , Y 3 } ; 14 if U 2 > 0 then 15 Define y i, 0 = Y 1 and y i, 0 = Y 2 ; 16 else 17 Define y i, 0 = Y 2 and y i, 0 = Y 3 ; 18 end 19 if Y 2 > y ? i then 20 Define u ? i = U 1 and u ? i = U 2 ; 21 else 22 Define u ? i = U 2 and u ? i = U 3 ; 23 end 24 return m i as the maximum over ω (y ? i − υ ) , where ω ∈ { u ? i , u ? i } and υ ∈ { y i, 0 , y i, 0 } ; W e prov e the follo wing: 7 Proposition 3. The output m i of Algorithm 1 is an upper bound on m i . Pr oof. First, we show that the closed-loop experiments con- ducted by the algorithm indeed con ver ge. The plant Σ i is assumed to be passive with respect to any steady-state input-output pair it possesses. Moreover , the static controller u = β i ( y − y ref ) is output-strictly passiv e with respect to any steady-state input-output pair it possesses. Thus it is enough to show that the closed-loop system has a steady- state, which will prove con ver gence as this is a feedback connection of a passi ve system with an output-strictly passiv e system. Indeed, a steady-state input-output pair (u i , y i ) of the system must satisfy u i ∈ k − 1 i (y i ) and u i = − β i (y i − y ref ) , or − β i (y i − y ref ) ∈ k − 1 (y i ) . This is equiv alent to 0 ∈ k − 1 (y i ) + β i (y i − y ref ) = ∇ K ? i (y i ) + β i 2 (y i − y ref ) 2 , so y i exists and is equal to the minimizer of K ? i (y i ) + β i 2 (y i − y ref ) 2 . This shows that the closed-loop experiments con ver ge. it remains to show that it outputs an upper-bound on m i . Using Remark 4, it is enough to show that y i, 0 ∈ [y i, 0 , y i, 0 ] and u ? i ∈ [u ? i , u ? i ] . T o do so, we first claim that U 1 ≤ u ? i ≤ U 3 and Y 1 ≤ y i, 0 ≤ Y 3 . W e first show that Y 1 ≤ y i, 0 , by showing that y i, − ≤ y i, 0 . Indeed, because k i is a monotone map, this is equiv alent to saying that u i, − ≤ 0 . By the structure of the second experiment, the steady-state input is close to − 1 , and in particular smaller than 0 . The inequality y i, 0 ≤ y i, + is proved similarly . W e note that because u i, − ≈ − 1 and u i, + ≈ 1 , we hav e u i, − ≤ u i, + and thus y i, − ≤ y i, + . as k i is monotone. Next, we prov e that U 1 ≤ u ? i . By monotonicity of k i , this is equiv alent to Y 1 ≤ y ? i . Because y i, − ≤ y i, + , it is enough to show that either y i, − ≤ y ? i or y i, 2 ≤ y ? i . If the first case is true, then the proof is complete. Otherwise, y i, − > y ? i , so the algorithm finds y i, 2 by running the closed-loop system in Fig. 4 with β i = 1 and y ref y ? i . The increased coupling strength implies that the steady-state output y i, 2 should be close to y ref , which is much smaller than y ? i . Thus y i, 2 < y ? i , which shows that Y 1 ≤ y ? 1 , or equiv alently U 1 ≤ u ? 1 . The proof that u ? 1 ≤ U 3 is similar . This completes the proof. Remark 5. Algorithm 1 demands us to run a certain system with parameter β i small and wait until conver gence. In prac- tice, determining when the system has conver ged can be done by measuring the output or its derivative. Alternatively , one can use a Lypaunov-based appr oach [27]. One could also use engineering intuition and simulations to conclude an estimate on the termination time of the experiments. The parameter β i can be chosen in a similar manner . Remark 6. One can run mor e experiments to give tighter estimates of m i . Indeed, by construction, take a collection { ( U i,k , Y i,k ) } r +1 k =0 of steady-state input-output pairs, and use the monotonicity of the steady-state relation to sort them in such a way that Y i, 0 ≤ · · · ≤ Y i,r ≤ y ? i ≤ Y i,r +1 , U i, 0 ≤ 0 ≤ U i, 1 ≤ · · · ≤ U i,r +1 . W e would like to use Pr oposition 2, but we do not know the exact values of y i,r , u i, 0 . Instead, we again use the monotonicity of the steady-state r elation and bound U i,r ≤ u ? i ≤ U i,r +1 and Y i, 0 ≤ y i, 0 ≤ Y i, 1 . Thus: m i ≤ M i , r X k =1 U i,k ( Y i,k − Y i,k − 1 ) + U i,r +1 (y ? i − Y i,r ) . (4) W e claim that M i is a r elatively tight estimate of m i . Indeed: Proposition 4. Let ∆ k = Y i,k − Y i,k − 1 ≥ 0 , and assume that k − 1 i is an L -Lipschitz function. Then | M i − m i | ≤ C max { L, 1 } max k ∆ k , for a constant C = C (y i, 0 , u ? i , y ? i ) . Pr oof. First, m i = K ? i (y ? i ) − K ? i (y i, 0 ) = R y ? i y i, 0 k − 1 i ( s ) ds . Thus, it is enough to bound each of the follo wing terms: i) | R Y i,k Y i,k − 1 k − 1 i ( s ) ds − U i,k ( Y i,k − Y i,k − 1 ) | , k = 2 , · · · , r . ii) | R y ? i Y i,r k − 1 i ( s ) ds − u ? i (y ? i − Y i,r ) | . iii) | R Y i, 1 y i, 0 k − 1 i ( s ) ds − U i, 1 ( Y i, 1 − y i, 0 ) | . iv) | ( U i,r +1 − u ? i )(y ? i − Y i,r ) | . v) | U i,r +1 ( Y i,r +1 − y ? i ) | vi) | U i, 1 (y i, 0 − Y i, 0 ) | The first term can be bounded by: Z Y i,k Y i,k − 1 | k − 1 ( s ) − k − 1 ( Y i,k ) | ds ≤ L Z Y i,k Y i,k − 1 | s − Y i,k | ds = L ∆ 2 k . Similarly , the second term is bounded by L ( y ? i − Y i,r ) 2 and the third term is bounded by L ( Y i, 1 − y i, 0 ) 2 . The sum of the three terms is thus bounded by: L " r X k =2 ( Y i,k − Y i,k − 1 ) 2 + ( y ? i − Y i,r ) 2 + ( Y i, 1 − y i, 0 ) 2 # ≤ L max(∆ k ) " r X k =2 ( Y i,k − Y i,k − 1 ) + ( y ? i − Y i,r ) + ( Y i, 1 − y i, 0 ) # ≤ L max(∆ k )(y ? i − y i, 0 ) , where we use y ? i − Y i,r ≤ ∆ r +1 and Y i, 1 − y i, 0 ≤ ∆ 1 . Similarly , the fourth term is bounded by L ∆ 2 r +1 , the fifth term is bounded by U i,r +1 ∆ r +1 and the last term is bounded by U i, 1 ∆ 0 . This completes the proof, as 0 ≤ U i, 1 ≤ u ? i = k − 1 i (y ? i ) , and U i,r +1 = k − 1 ( Y i,r +1 ) ≤ k − 1 (y ? i ) + L ∆ r +1 . Remark 7. A natural question that arises is how to con- duct experiments assuring that max k ∆ k is small. If we run the system in F ig. 4 with β i 1 , then the steady- state output would be very close to y ref . Thus, if we run r additional e xperiments with β i 1 and refer ences y ref , 1 ≤ y ref , 2 ≤ · · · ≤ y ref , r (i.e., a total of r + 3 experiments), then max ∆ k = O (max k | y ref , k+1 − y ref , k | ) . Thus, choosing y ref , k as r equally spaced points in an appr opriate interval would give max k ∆ k = O (1 /r ) , and a uniformly r andom choice gives max k ∆ k = O (log r/r ) with high probability [34]. W e saw that m i can be bounded using three experiments for general MEIP agents, and that additional measurements can be used to provide more accurate estimates of m i . Other recent works about data-dri ven control focus on the case of L TI systems, using them as a base to build to ward a solution for nonlinear systems [4], [7], [35]. If we restrict ourselves to this case, we can exactly compute m i from a single experiment: Proposition 5. Suppose that the ag ent Σ i is known to be both MEIP and LTI. Let (˜ u , ˜ y) be any steady-state input-output pair 8 y i u i y ref − − Σ i β i Fig. 4. Experimental setup of the closed-loop experiment for estimating m i as used in Algorithm 1. for which either ˜ u 6 = 0 or ˜ y = 0 . 2 Then m i = (y ? i ) 2 ˜ u 2˜ y . Thus m i can be exactly calculated using a single experiment. Pr oof. W e know that k is a linear function, and the system state matrix is Hurwitz [21], [24]. Moreover , unless the transfer function of the agent is 0 , k − 1 is a linear function k − 1 (y) = s y for some s > 0 [36]. Thus K ? (y) = s 2 y 2 . No w , k − 1 (0) = s · 0 = 0 , so (0 , 0) is a steady-state input-output pair , meaning that y i, 0 = 0 . Moreov er, we know that ˜ u = s ˜ y , and not both are zero, so we conclude that ˜ y 6 = 0 , and that s = ˜ u ˜ y . Thus, K ? i (y i, 0 ) = K ? i (0) = 0 and K ? i (y ? i ) = s 2 (y ? i ) 2 . This completes the proof, as m i = K ? i (y ? i ) − K ? i (y i, 0 ) . The chapter concludes with Algorithm 2 for solving the practical formation control problem using the single-gain amplification scheme, which is applied in Section VI. Algorithm 2: Synthesis Procedure for Practical For - mation Control 1 Choose some output-strictly MEIP controllers Π e such that the integral function Γ has a single minimizer ζ ? when restricted to the set Im( E T ) ; 2 Choose some y ? ∈ R n such that E T y ? = ζ ? ; 3 for i = 1 , ..., n do 4 Run Algorithm 1. Let m i be the output; 5 end 6 Let m = P n i =1 m i ; 7 Compute M = min { ζ ∈ Im( E T ) : k ζ − ζ ? k = ε } ; 8 Compute α = m / M ; 9 return the controllers { α Π e } e ∈ E ; Remark 8. Step 1 of the algorithm allows almost complete fr eedom of choice for the contr ollers. One possible choice ar e the static contr ollers µ e = ζ e − ζ ? e . Moreo ver , if Π e is any MEIP contr oller for each e ∈ E , and γ e ( ζ e ) = 0 has a unique solution for each e ∈ E , then the “formation r econfiguration” scheme fr om [23] suggests a way to find the r equired contr ollers using mild augmentation. Remark 9. The algorithm allows one to choose any vector y ? such that E T y ? = ζ ? . All possible choices lead to some gain α which assur es a solution of the practical formation contr ol pr oblem, but some choices yield better results (i.e., smaller gains) than others. The optimal y ? , minimizing the estimate α , can be found as the minimizer of the pr oblem min { K ? (y) : E T y = ζ ? } , which we cannot compute using data alone. One can use physical intuition to choose a vector 2 e.g., by running the system in Fig. 4 with some β > 0 and y ref 6 = 0 y ? which is r elatively close to the actual minimizer , but the algorithm is still valid no matter which y ? is chosen. V . I T E R A T I V E P R AC T I C A L F O R M AT I O N C O N T R O L : A P P L Y I N G D I FF E R E N T G A I N S O N D I FF E R E N T E D G E S Let us revisit Fig. 2 and let A = diag ( { a e } e ∈ E ) with positiv e, but distinct entries a e . These additional degrees of freedom can be used, for example, to reduce the conservatism and retrieve a smaller norm of the adjustable gain vector a while still solving the practical formation control problem. It follows directly from Theorem 2 that there always exists a bounded vector a solving the practical formation control problem. Howe ver , the question remains how a can be chosen based on sampled input-output data and passivity properties. Our idea here is to probe our diffusi vely coupled system for giv en gains a e and adjust the gains according to the resulting steady-state output. By iteratively performing experiments in this way , we strive to find controller gains that solve the practical formation control problem. This approach is tightly connected to iterative learning control, where one iterativ ely applies and adjusts a controller to improv e the performance of the closed-loop for a repetiti ve task [37]. Our approach here is based on passivity and network optimization with only requiring the possibility to perform iterativ e experiments. One natural idea in this direction is to define a cost function that penalizes the distance of the resulting steady-state to the desired formation control goal and then apply a gradient descent approach, adjusting the gain a for each experiment. Howe ver , to obtain the gradient of kE T y( a ) − ζ ? k 2 with respect to the vector a , where y( a ) is the steady-state output of ( G , Σ , Π , a ) , one requires knowledge of the in verse relations k − 1 i for all i = 1 , . . . , n . With no model of the agents av ail- able, a direct gradient descent approach is hence infeasible. W e thus look for a simple iterativ e multi-gain control scheme without kno wledge on the exact steepest descent direction. W e start off with an arbitrarily chosen gain vector a 0 with only positive entries. Due to Assumption 1, the closed-loop con verges to a steady state. According to the measured state, the idea is then to iteratively perform experiments and update the gain vector until we reach our control goal, i.e., practical formation control. The update formula can be summarized by a ( j +1) e = a ( j ) e + hv e , e ∈ E , (5) where h > 0 is the step size and v , with entries v e , e = 1 , . . . , | E | , is the update direction. In practice, the update can either be instantaneous or gradual, e.g. using linear interpolation or higher-order splines. W e denote the e -th entry of E T y as f e and choose v in each iteration such that v e = ( f e − ζ ? e γ e (f e ) γ e (f e ) 6 = 0 0 otherwise , e ∈ E . (6) If k − 1 and γ are differentiable functions, then we claim that F ( a ) = ||E T y( a ) − ζ ? || 2 decreases in the direction of v , i.e., v T ∇ F ( a ) < 0 . This leads to a multi-gain distributed control scheme, using (5) with (6), summarized in Algorithm 3. This multi-gain distributed control scheme is guaranteed to solve the practical formation problem after a finite number of iterations, and is summarized in the following theorem. 9 Algorithm 3: Practical Formation control with deriv ativ e-free optimization 1 Initialize a (0) , e.g. with 1 | E | ; 2 Choose step size h and set j = 0 ; 3 while F ( a ) = kE T y( a ) − ζ ? k 2 > ε do 4 Apply a ( j ) to the closed loop ; 5 Compute v e = ( f e − ζ ? e γ e (f e ) γ (f e ) 6 = 0 0 γ (f e ) = 0 ∀ e ; 6 Update a ( j +1) e = a ( j ) e + hv e , j = j + 1 ; 7 end 8 return a Theorem 3. Suppose that the functions k − 1 , γ ar e differ en- tiable, and that ther e exists an agent i 0 ∈ V such that dk − 1 i 0 d y i 0 > 0 for any point y i 0 ∈ R . Mor eover , assume that dγ e dζ e > 0 for any e ∈ E , ζ e ∈ R . Then v T ∇ F ( a ) ≤ 0 , with v , F as defined in Algorithm 3 (and equality if and only if E T y( a ) = ζ ? ). Furthermor e, if the step size h > 0 is small enough, then the Algorithm 3 halts after finite time, pr oviding a gain vector that solves the practical formation contr ol pr oblem. Sketch of pr oof. The proof is based on sho wing that ∇ F can be written as − diag( γ (f )) X (y( a ))(f − ζ ? ) , where X (y( a )) is a positiv e-definite matrix depending on y( a ) . W e can no w show that v T ∇ F = − (f − ζ ? ) T X (y( a ))(f − ζ ? ) ≤ 0 . The full proof of Theorem 3 is av ailable in the appendix. Algorithm 3 together with the theoretical results from Theorem 3 provide us with a very simple and distributed, iterativ e control scheme with theoretical guarantees. Note also, that the steady-states of the agents are independent of their initial condition. For each iteration, the agents can hence also start from the position they con ver ged to at the last iteration. This can be interpreted similarly to Remark 3, where gains are updated on a slower time scale than conv ergence of the agents. Howe ver , instead of only the information whether practical formation control is achieved, we generally need the actual difference E T y − ζ ? that is achiev ed with the current controller in each iteration. In the special case of proportional controllers µ e = ζ e − ( ζ ? ) e , yielding v e = 1 , we retrie ve the exact controller scheme proposed in Remark 3. An alternative gradient-free control scheme is the extremum seeking framew ork presented in [38]. Assuming that k − 1 and γ are twice continuously dif ferentiable, a step in the direction of steepest descent is approximated ev ery 4 | E | steps (cf. [38, Theorem 1]). While the extremum seeking framework approximates the steepest descent (and the simple multi- gain approach only guarantees a descending direction), it also requires large amounts of experiments per approximated gradient step. Furthermore, the algorithm as presented in [38] cannot be computed in a purely distributed fashion. Therefore, the simple distributed control scheme in Algorithm 3 displays significant adv antages in the present problem setup. V I . C A S E S T U DY : V E L O C I T Y C O O R D I N A T I O N I N V E H I C L E S W I T H D R A G A N D E X O G E N O U S F O R C E S Consider a collection of 30 one-dimensional robot vehicles, each modeled by a double integrator G ( s ) = 1 s 2 . The robots try to coordinate their v elocity . Each of them has its own drag profile f ( ˙ p ) , which is unknown to the algorithm, but it is known that f is increasing and f (0) = 0 . Moreover , each vehicle experiences external forces (e.g., wind, and being placed on a slope). The velocity of the vehicles is gov erned by the equation Σ i : ( ˙ x i = − f i ( x i ) + u i + w i y i = x i , (7) where x i is the v elocity of the i -th vehicle, f i is its drag model, w i are the exogenous forces acting on it, u i is the control input, and y i is the measurement. In the simulation, the drag models f i are given by c d | x | x , where the drag coefficient c d is chosen as a log-uniformly distributed random variable. W e assume that the vehicles are light, so the wind accelerates the vehicles by a non-negligible amount. Thus, w i is randomly chosen between − 2 and 2 . W e wish to achiev e velocity consensus, with error no greater than = 0 . 2 . W e consider a diffusi ve coupling of the agents with the cycle graph G = C 30 , and take proportional controllers ζ e = µ e . W e apply the amplification scheme presented in Algorithm 2 and choose the consensus value y ? i = 1 . 5 m/sec to use in the estimation algorithm. Note that the plants are MEIP , but not output-strictly MEIP , and use Algorithm 1 to estimate the required uniform gain α . The first two experiments are conducted with β i = 0 . 01 , and y ref = ± 100 . Based on their results, we run a third experiment on each of the agents for which this is required, this time with β i = 1 and y ref = ± 10 , where the sign is chosen according to Algorithm 1. The experimental results are av ailable in Figure 5(a). W e estimate each m i using Remark 4. For example, for agent 1 we get the three steady-state input-output pairs (0 . 9947 , 0 . 5203) , ( − 0 . 9687 , − 3 . 1294) , and (3 . 4268 , 3 . 5732) . Monotonicity implies that it has steady-states ( u ? 1 , y ? 1 ) = ( u ? 1 , 1 . 5) and (0 , y 1 , 0 ) with 0 . 9947 ≤ u ? 1 ≤ 3 . 4268 and − 3 . 1294 ≤ y 1 , 0 ≤ 0 . 5203 . W e can thus estimate m 2 ≤ 3 . 4268 · (1 . 5 − ( − 3 . 1294)) = 15 . 864 . Repeating this calculation for each of the agents and summing giv es m = 256 . 3658 . As for estimating M , we have Γ e ( ζ e ) = ζ 2 e , so Γ( ζ ) = k ζ k 2 . The minimum is at ζ ? = 0 , and by definition we hav e M = min ζ ∈ Im( E T ): k ζ − ζ ? k = ε Γ( ζ ) = | E | ε 2 . Thus, we get α = m M = m 30 ε 2 = 213 . 64 . T o verify the algorithm, we run the closed-loop system ( G , Σ , Π , α 1 ) with the gain α we found. The results are av ailable in Figure 5(b). One can see that the overall control goal is achieved - the agents con ver ge to a steady-state which is ε -close to consensus. Howe ver , the agents actually con ver ge to a much closer steady-state than predicted by the algorithm. Namely , the distance of the steady- state output from consensus is roughly 0 . 04 , much smaller than 0 . 2 . Uncoincidentally , the true value of m = K (0) + K ? ( y ? ) is 50 . 15 , meaning we overestimate it (and hence m/ M ) by about 411% . One can mitigate this by using more experiments to improve the estimate m i , as in Proposition 2 or in Remark 6. W e follow this approach and conduct further experiments on each of the agents using β i = 10 and choosing y ref randomly . The resulting v alues of α , as well as the error from the true value of m/ M , can be seen in the table below . It can be 10 0 10 20 Time -2 -1 0 1 2 3 4 5 Velocity (Exp. 1) 0 10 20 Time -4 -3 -2 -1 0 1 2 3 4 5 Velocity (Exp. 2) 0 10 20 Time -4 -3 -2 -1 0 1 2 3 Velocity (Exp. 3) (a) Results of First Set of Experiments for the V ehicles. Each plot corresponds to a different agent. (b) The Closed-Loop with Uniform Gain α = 213 . 638 . The two leftmost graphs plot the agents’ trajectories over 0.3 seconds and over 10 seconds. The rightmost graph plots the relative outputs. Fig. 5. Experiment results for vehicle case study . seen that ev en a single additional measurement per agent can significantly reduce the estimation error of m/ M . Measurements Per Agent V alue of α Overestimation of m/ M 3 213 . 638 411% 4 104 . 308 150% 10 67 . 316 61% 20 55 . 161 32% Altogether we sho wed that Algorithm 2 manages to solve the practical consensus problem for vehicles, affected by drag and exogenous inputs, without using any model for the agents, while conducting very few experiments for each agent. Howe ver , it ov erestimates the required coupling, and thus has unnecessarily large energy consumption. Let us now apply the iterati ve multi-gain control strategy . W e start with a (0) = 0 . 1 ⊗ 1 | E | , we choose the step size h = 2 and apply Algorithm 3. In fact, since ζ ? = 0 and ζ e = µ e , we recei ve v = 1 | E | , which constitutes the special case of Remark 3. The corresponding norm of the gain vector and the resulting ε in each iteration is illustrated in Fig. 6. After 20 iterations, we already arrive at a vector , which solves the practical formation problem with k a (19) k = 208 . 68 , while ε = 0 . 195 < 0 . 2 . Note that the controller with the uniform gain had k a k = p | E | · 213 . 638 = 1170 . 1 , so the iterativ e scheme beats it by a factor of 5 in terms of energy . V I I . C O N C L U S I O N S A N D F U T U R E W O R K W e presented an approach for model-free practical coop- erativ e control for diffusi vely coupled systems only on the premise of passivity of the agents. The presented approach led to two control schemes: with additional two or three experiments on the agents, we can upper bound the controller gain which solves the practical formation problem, or we can iterativ ely adapt the adjustable gain vector until practical formation is reached. Both approaches are especially simple in their application, while still being scalable and providing theoretical guarantees. Future research might try and improv e 0 5 10 15 20 10 0 10 1 Iterations j ε ( a ( j ) ) 0 5 10 15 20 0 100 200 Iterations j k a j k Fig. 6. The resulting ε and the norm of the gain vector k a ( j ) k ov er iterations j when applying the iterative multi-gain control strategy to the case study of velocity coordination in vehicles. the presented methods, either by reducing the number of experiments needed on each agent, or by achie ving faster practical con ver gence using iterations. One might also try to use very limited knowledge on the agents to achieve the said improvement. Other possible directions include data- driv en solutions to more intricate problems using the network optimization frame work, e.g. fault detection and isolation. R E F E R E N C E S [1] A. Franchi, P . R. Giordano, C. Secchi, H. I. Son, and H. H. Bulthoff, “Passi vity-based decentralized approach for the bilateral teleoperation of a group of uavs with switching topology , ” in IEEE International Confer ence on Robotics and Automation , pp. 898–905, 2011. [2] M. Bando, K. Hasebe, A. Nakayama, A. Shibata, and Y . Sugiyama, “Dynamical model of traffic congestion and numerical simulation, ” Phys. Rev . E , vol. 51, pp. 1035–1042, Feb 1995. [3] D. Urban and T . Keitt, “Landscape connectivity: A graph-theoretic perspectiv e, ” Ecology , vol. 82, no. 5, pp. 1205–1218, 2001. [4] B. Recht, “ A tour of reinforcement learning: The view from continuous control, ” Annual Review of Control, Robotics, and Autonomous Systems , vol. 2, no. 1, pp. 253–279, 2019. [5] S. Dean, H. Mania, N. Matni, B. Recht, and S. Tu, “On the sample com- plexity of the linear quadratic regulator, ” F oundations of Computational Mathematics , 10 2017. [6] D. G ¨ orges, “Distributed adaptiv e linear quadratic control using dis- tributed reinforcement learning, ” IF AC-P apersOnLine , vol. 52, no. 11, pp. 218 – 223, 2019. 5th IF AC Conference on Intelligent Control and Automation Sciences ICONS 2019. 11 [7] J. Coulson, J. Lygeros, and F . D ¨ orfler , “Data-enabled predictive control: In the shallows of the DeePC, ” in 18th Eur opean Contr ol Conf. , pp. 307– 312, 2019. [8] S. Fattahi, N. Matni, and S. Sojoudi, “Efficient learning of distributed linear-quadratic controllers, ” arXiv preprint , 2019. [9] H. Jiang and H. He, “Data-driv en distributed output consensus control for partially observable multiagent systems, ” IEEE Tr ans. Cybernetics , pp. 1–11, 2018. [10] F . Bianchini, G. Fenu, G. Giordano, and F . A. Pellegrino, “Model-free tuning of plants with parasitic dynamics, ” in Proc. 56th IEEE Conf. on Decision and Contr ol , pp. 499–504, Dec 2017. [11] D. D. ˇ Siljak, “Decentralized control and computations: Status and prospects, ” A. Rev . Control , vol. 20, 1996. [12] Y . Zheng, S. E. Li, K. Li, and W . Ren, “Platooning of connected vehicles with undirected topologies: Robustness analysis and distributed H-infinity controller synthesis, ” IEEE Tr ans. Intelligent Tr ansportation Systems , vol. 19, pp. 1353–1364, 2018. [13] W . Y u, P . DeLellis, G. Chen, M. di Bernardo, and J. Kurths, “Distributed adaptiv e control of synchronization in complex networks, ” IEEE T rans. Automat. Contr ol , vol. 57, pp. 2153–2158, 2012. [14] J. M. Montenbruck and F . Allg ¨ ower , “Some problems arising in con- troller design from big data via input-output methods, ” in Pr oc. 55th IEEE Conf. on Decision and Control , pp. 6525–6530, 2016. [15] A. Koch, J. M. Montenbruck, and F . Allgower , “Sampling strategies for data-driv en inference of input-output system properties, ” IEEE T rans. Automat. Contr ol , 2021. [16] A. Romer , J. Berberich, J. K ¨ ohler , and F . Allg ¨ ower , “One-shot verifi- cation of dissipativity properties from input-output data, ” IEEE Contr ol Systems Letters , vol. 3, pp. 709–714, 2019. [17] H. K. Khalil, Nonlinear Systems . Pearson, 3rd ed., 2001. [18] M. Arcak, “Passivity as a design tool for group coordination, ” IEEE T rans. Automat. Control , vol. 52, pp. 1380–1390, Aug. 2007. [19] H. Bai, M. Arcak, and J. W en, Cooperative Control Design: A System- atic, P assivity-Based Appr oach . Communications and Control Engineer- ing, Springer, 2011. [20] A. Pavlo v and L. Marconi, “Incremental passivity and output regulation, ” Systems & Contr ol Letters , vol. 57, no. 5, pp. 400 – 409, 2008. [21] G. H. Hines, M. Arcak, and A. K. Packarda, “Equilibrium-independent passivity: A new definition and numerical certification, ” Automatica , vol. 47, no. 9, pp. 1949–1956, 2011. [22] M. B ¨ urger , D. Zelazo, and F . Allg ¨ ower , “Duality and network theory in passivity-based cooperative control, ” Automatica , vol. 50, no. 8, pp. 2051–2061, 2014. [23] M. Sharf and D. Zelazo, “ A network optimization approach to coopera- tiv e control synthesis, ” IEEE Contr ol Systems Letters , v ol. 1, pp. 86–91, July 2017. [24] M. Sharf and D. Zelazo, “ Analysis and synthesis of mimo multi-agent systems using network optimization, ” IEEE T ransactions on Automatic Contr ol , vol. 64, no. 11, pp. 4512–4524, 2019. [25] A. Jain, M. Sharf, and D. Zelazo, “Regulatization and feedback pas- siv ation in cooperati ve control of passivity-short systems: A network optimization perspecti ve, ” IEEE Contr ol Systems Letter s , v ol. 2, pp. 731– 736, 2018. [26] M. Sharf, A. Jain, and D. Zelazo, “ A geometric method for passiv a- tion and cooperative control of equilibrium-independent passivity-short systems, ” arXiv preprint , 2019. [27] M. Sharf and D. Zelazo, “ A data-driven and model-based approach to fault detection and isolation in networked systems, ” arXiv preprint arXiv:1908.03588 , 2019. [28] J. M. Montenbruck, M. B ¨ urger , and F . Allg ¨ ower , “Practical synchro- nization with diffusiv e couplings, ” Automatica , vol. 53, pp. 235 – 243, 2015. [29] J. Kim, J. Y ang, H. Shim, J. Kim, and J. H. Seo, “Robustness of synchronization of heterogeneous agents by strong coupling and a large number of agents, ” IEEE T rans. Automat. Control , vol. 61, no. 10, pp. 3096–3102, 2016. [30] C. Godsil and G. Royle, Algebraic Graph Theory . Graduate T exts in Mathematics, Springer New Y ork, 2001. [31] R. T . Rockafellar, Con vex Analysis . Princeton Landmarks in Mathemat- ics and Physics, Princeton University Press, 1997. [32] K.-K. Oh, M.-C. Park, and H.-S. Ahn, “ A survey of multi-agent formation control, ” Automatica , vol. 53, pp. 424 – 440, 2015. [33] A. Romer, J. M. Montenbruck, and F . Allg ¨ ower , “Determining dissipa- tion inequalities from input-output samples, ” in Pr oc. 20th IF A C W orld Congr ess , pp. 7789–7794, 2017. [34] L. Holst, “On the lengths of the pieces of a stick broken at random, ” Journal of Applied Pr obability , vol. 17, no. 3, pp. 623–634, 1980. [35] C. De Persis and P . T esi, “Formulas for data-driv en control: Stabilization, optimality and robustness, ” IEEE T rans. Automat. Control , 2019. [36] M. Sharf and D. Zelazo, “Network identification: A passivity and network optimization approach, ” in Pr oc. 57th IEEE Conf. on Decision and Control , 2018. [37] D. A. Bristow , M. Tharayil, and A. G. Alleyne, “ A surve y of iterativ e learning control, ” IEEE Contr ol Systems Magazine , vol. 26, no. 3, pp. 96–114, 2006. [38] J. Feiling, A. Zeller, and C. Ebenbauer, “Deri vati ve-free optimization algorithms basen on non-commutative maps, ” IEEE Contr ol Systems Letters , vol. 2, pp. 743–748, 2018. A P P E N D I X W e no w gi ve full proofs of Proposition 1 and Theorem 3. A. Pro ving Proposition 1 In order to prove the proposition, we use the notion of cursiv e relations established in [26]: Definition 4 (Cursi ve Relations, [26]) . A set A ⊂ R 2 is called cursiv e if ther e exists a curve α : R → R 2 such that the following conditions hold: i) The set A is the imag e of α . ii) The map α is continuous. iii) The map α satisfies lim | t |→∞ k α ( t ) k = ∞ . iv) { t ∈ R : ∃ s 6 = t, α ( s ) = α ( t ) } has measur e zer o. A r elation Υ is called cursive if the set { ( p, q ) : q ∈ Υ ( p ) } is cursive . The notion of cursiv e relations is useful as it can help prove that systems are MEIP . Specifically , Theorem 4 ( [26]) . A monotone cursive r elation is maximally monotone. W e can no w prov e Proposition 1: Pr oof. Consider an arbitrary steady-state of the system. As h is continuous and strictly monotone ascending, hence in vert- ible, we must hav e ˙ x = 0 for any steady-state input-output pair . Thus, we conclude that any steady-state input-output pair can be written as ( f ( σ ) /g ( σ ) , h ( σ )) for some σ ∈ R . W e first show passivity with respect to ev ery steady-state, and then show that the steady-state input-output relation is maximally monotone. T ake a steady-state ( f ( x 0 ) /g ( x 0 ) , h ( x 0 )) of the system, and define S ( x ) = R x x 0 h ( σ ) − h ( x 0 ) g ( σ ) dσ . W e claim that S is a storage function for the steady-state input-output pair ( f ( x 0 ) /g ( x 0 ) , h ( x 0 )) . Indeed, S ( x ) ≥ 0 , with equality only at x 0 , immediately follows from strict monotonicity of h and g > 0 . As for the inequality defining passivity , we hav e: d dt S ( x ) = h ( x ) − h ( x 0 ) g ( x ) ( − f ( x ) + g ( x ) u ) = ( h ( x ) − h ( x 0 )) u − f ( x ) g ( x ) ( h ( x ) − h ( x 0 )) = ( h ( x ) − h ( x 0 )) u − f ( x 0 ) g ( x 0 ) − f ( x ) g ( x ) − f ( x 0 ) g ( x 0 ) ( h ( x ) − h ( x 0 )) , where the second term is negati ve as f g , h are monotone ascending, and the first term is ( y − h ( x 0 ))( u − f ( x 0 ) g ( x 0 ) ) . Hence, the system is indeed passiv e with respect to any steady- state input-output pair . As for maximal monotonicity of the steady-state relation, we recall that it can be parameterized 12 as ( f ( σ ) /g ( σ ) , h ( σ )) for σ ∈ R . W e claim that this relation is both monotone and cursiv e, which will prove maximal monotonicity . Monotonicity holds as for any x 0 , x 1 , f ( x 0 ) g ( x 0 ) > f ( x 1 ) g ( x 1 ) ⇐ ⇒ x 0 > x 1 ⇐ ⇒ h ( x 0 ) > h ( x 1 ) (8) due to strict monotonicity . As for cursiveness, the map σ 7→ ( f ( σ ) /g ( σ ) , h ( σ )) is a curve whose image is the relation. Moreov er , it is clear that the map is continuous, and also injectiv e due to (8). Lastly , we have lim | t |→∞ f ( t ) g ( t ) , h ( t ) ≥ lim | t |→∞ max f ( t ) g ( t ) , | h ( t ) | = ∞ (9) so the proof is complete by Theorem 4. B. Pro ving Theorem 3. W e first state and prove the following lemma: Lemma 4. Suppose that the assumptions of Theorem 3 hold, and let C > 0 be any constant. Define A 1 = { y ∈ R n : kE T y − ζ ? k ≤ C } and A 2 = { y ∈ R n : P i k − 1 i (y i ) = 0 } . Then the set A 1 ∩ A 2 is bounded. Pr oof. First, we note that the inequality kE T y − ζ ? k ≤ C im- plies that for any edge { i, j } ∈ E , we ha ve | y i − y j | ≤ C + || ζ ? || by the triangle inequality . W e let ω = ( C + || ζ ? || )diam( G ) , where diam( G ) is the diameter of the graph G , so that if there exists some i, j ∈ V such that | y i − y j | > ω then y 6∈ A 1 . Moreov er , let z = k (0) , so P i k − 1 i (z i ) = 0 , so that if y ∈ R n satisfies ∀ i : y i > z i , then y 6∈ A 2 . Indeed, for each i we hav e k − 1 i (y i ) ≥ k − 1 i (z i ) , and k − 1 i 0 (z i 0 ) > k − 1 i 0 (y i 0 ) , meaning that P i k − 1 i (y i ) > P i k − 1 i (z i ) = 0 . Similarly , if ∀ i, z i > y i then y 6∈ A 2 . W e claim that for any y ∈ A 1 ∩ A 2 and any i ∈ V , we hav e C 1 < y i < C 2 , where C 1 = min j z j − ω − 1 and C 2 = max j z j + ω + 1 . Indeed, take any y ∈ R n , and suppose that y i ≥ C 2 for some i ∈ V . There are two possibilities. • There is some k ∈ V such that y k < max j z j + 1 . Then | y i − y k | > ω , implying that y 6∈ A 1 . • For any k ∈ V , y k ≥ max j z j + 1 , implying that y 6∈ A 2 . Similarly , one shows that if there is some i such that y i ≤ C 1 , then y 6∈ A 1 ∩ A 2 . This completes the proof. Pr oof of Theor em 3. Consider the solution y( a ) of 0 = k − 1 (y) + E diag ( a ) γ ( E T y) as a function of a . Then y( a ) is a differentiable function by the inv erse function theorem, and its differential is giv en by d y da = − X (y( a )) E diag( γ ( E T y( a ))) , where the matrix X (y) is giv en by X (y) = [diag( ∇ k − 1 (y)) + E diag ( ∇ γ ( E T y)) E T ] − 1 . (10) W e note that X (y) is positiv e-definite for any y ∈ R n , by Proposition 2 in [36]. Thus, the gradient of F is giv en by: ∇ F ( a ) = − diag( γ ( E T y( a ))) E T X (y( a )) E ( E T y( a ) − ζ ? ) . (11) W e note that v T diag( γ ( E T y( a )) = E T y( a ) − ζ ? , as γ e ( x e ) = 0 if and only if x e = ζ ? e by strict monotonicity . Thus, v T ∇ F ( a ) = − ( E ( E T y( a ) − ζ ? )) T X (y( a )) E ( E T y( a ) − ζ ? ) (12) which is non-positiv e as X (y( a )) is a positive-definite matrix. Now , we claim that v T ∇ F ( a ) = 0 if and only if E T y( a ) = ζ ? . Indeed, ζ ? ∈ Im( E T ) , so we denote ζ ? = E T y 0 for some y 0 . As X (y( a )) is positi ve definite, (12) implies that v T ∇ F ( a ) = 0 if and only if E ( E T y( a ) − ζ ? ) = E E T (y( a ) − y 0 ) is the zero vector . The kernel of the Laplacian E E T is the span of the all-one vector 1 n , so y( a ) − y 0 = κ 1 n for some κ , hence E T y( a ) = E T y 0 = ζ ? . This concludes the first part of the proof. As for con vergence, we know that if h is small enough, then F ( a ( j +1) ) < F ( a ( j ) ) . Howe ver , the value of h so that F ( a ( j +1) ) < F ( a ( j ) ) can depend on a ( j ) itself, but it is obvious that if h is small enough, then for any j , we have F ( a ( j ) ) ≤ F ( a (0) ) . W e let C = F ( a (0) ) = kE T y( a (0) ) − ζ ? k , and consider the sets A 1 = { y : kE T y − ζ ? k ≤ C } and A 2 = { y : P i k − 1 i (y i ) = 0 } . F or any j , we know that y( a ( j ) ) ∈ A 1 by abov e, and that y( a ( j ) ) ∈ A 2 by the steady- state equation 0 = k − 1 (y( a )) + E diag( a ) γ ( E T y( a )) . Thus, all steady-state outputs achie ved during the algorithm are in the set D = A 1 ∩ A 2 , which is bounded by Lemma 4. The map sending a matrix to its minimal singular v alue is continuous, meaning that σ ( X (y)) achiev es a minimum on the set D at some point y 1 , and the minimum is positi ve as X (y 1 ) is positiv e-definite. W e denote the minimum value by σ ( D ) . Now , consider equation (12). W e get that v T ∇ F ( a ) is bounded by above − σ ( D ) ||E ( E T y( a ) − ζ ? ) || 2 . In turn, we saw abov e that unless E T y( a ) = ζ ? , E ( E T y( a ) − ζ ? ) 6 = 0 , meaning that kE ( E T y( a ) − ζ ? ) k ≥ ς ||E T y( a ) − ζ ? || 2 , where ς is the minimal nonzero singular value of E . Hence, at any time step j , v T ∇ F ( a ( j ) ) < − σ ( D ) ς F ( a ( j ) ) . In turn we conclude that F ( a ( j +1) ) = F ( a ( j ) ) − hσ ( D ) ς F ( a ( j ) ) + O ( h ) = (1 − hσ ( D ) ς ) F ( a ( j ) ) + O ( h ) . Iterating this equation shows that ev entually , F ( a ( j ) ) < ε , completing the proof.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment