Fully Decentralized Joint Learning of Personalized Models and Collaboration Graphs
We consider the fully decentralized machine learning scenario where many users with personal datasets collaborate to learn models through local peer-to-peer exchanges, without a central coordinator. We propose to train personalized models that levera…
Authors: Valentina Zantedeschi, Aurelien Bellet, Marc Tommasi
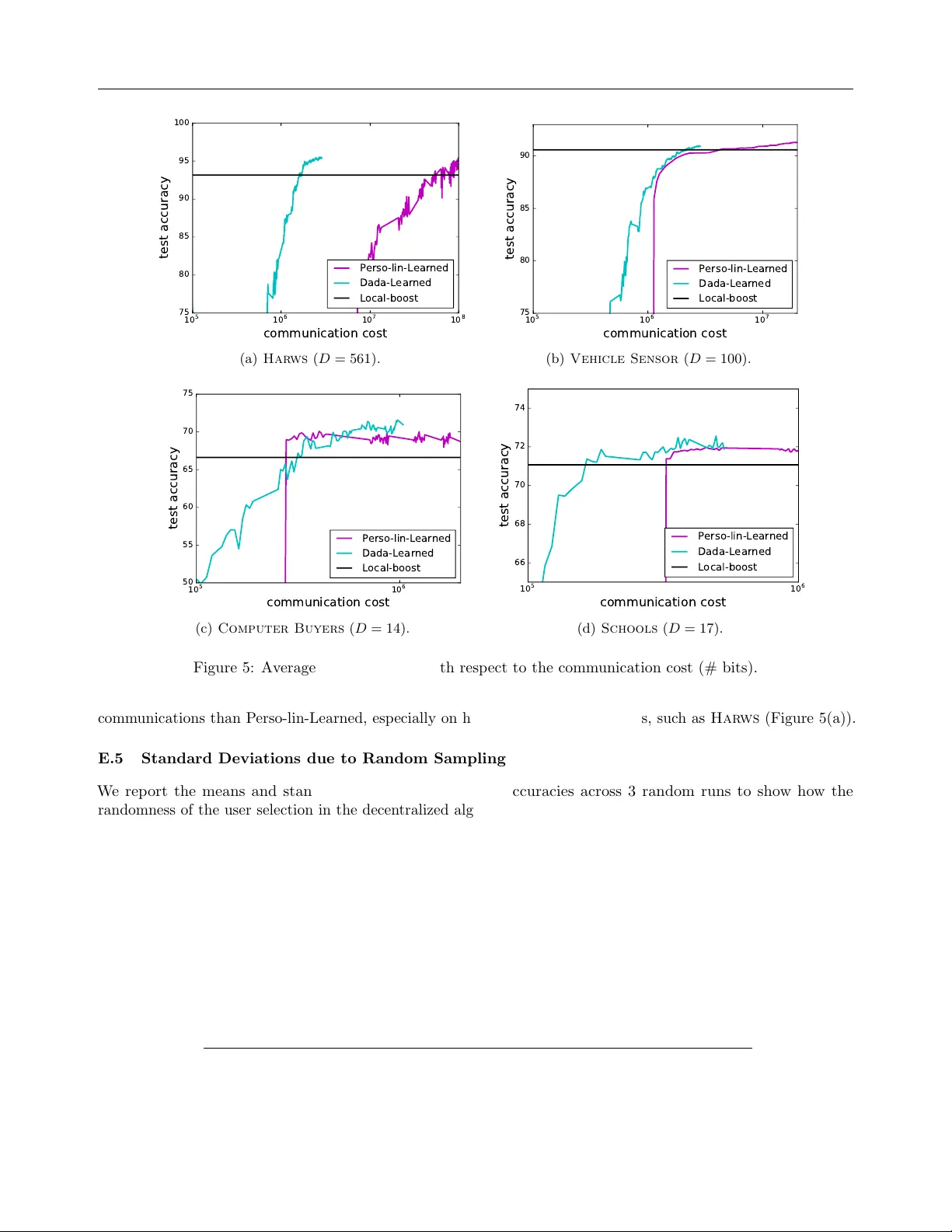
F ully Decen tralized Join t Learning of P ersonalized Mo dels and Collab oration Graphs V alen tina Zan tedeschi Aur´ elien Bellet Marc T ommasi GE – Global Researc h, 1 Researc h Circle, Nisk ayuna, NY 12309 1 Inria, F rance Univ ersit´ e de Lille & Inria, F rance Abstract W e consider the fully decen tralized machine learning scenario where many users with per- sonal datasets collab orate to learn models through lo cal peer-to-p eer exc hanges, with- out a central coordinator. W e prop ose to train p ersonalized models that leverage a col- lab oration graph describing the relationships b et w een user p ersonal tasks, whic h w e learn join tly with the mo dels. Our fully decen- tralized optimization procedure alternates b e- t ween training nonlinear models given the graph in a greedy bo osting manner, and up- dating the collab oration graph (with con- trolled sparsit y) given the models. Through- out the process, users exchange messages only with a small num b er of p eers (their direct neigh b ors when up dating the mo dels, and a few random users when up dating the graph), ensuring that the pro cedure naturally scales with the num b er of users. Ov erall, our ap- proac h is communication-efficien t and av oids exc hanging p ersonal data. W e pro vide an extensiv e analysis of the conv ergence rate, memory and communication complexit y of our approac h, and demonstrate its b enefits compared to comp eting tec hniques on syn- thetic and real datasets. 1 INTR ODUCTION In the era of big data, the classical paradigm is to build huge data centers to collect and process user data. This centralized access to resources and datasets is conv enien t to train machine learning mo dels, but Pro ceedings of the 23 rd In ternational Conference on Artificial In telligence and Statistics (AIST A TS) 2020, Palermo, Italy. PMLR: V olume 108. Cop yright 2020 b y the author(s). also comes with important dra wbacks. The service pro vider needs to gather, store and analyze the data on a large cen tral serv er, which induces high infrastructure costs. As the server represen ts a single p oin t of entry , it m ust also b e secure enough to preven t attacks that could put the en tire user database in jeopardy . On the user end, disadv antages include limited control o ver one’s p ersonal data as w ell as possible priv acy risks, whic h may come from the aforementioned attacks but also from p oten tially loose data go vernance p olicies on the part of service pro viders. A more subtle risk is to b e trapp ed in a “single though t” mo del which fades individual users’ sp ecificities or leads to unfair predictions for some of the users. F or these reasons and thanks to the adven t of p o werful p ersonal devices, we are currently witnessing a shift to a differen t paradigm where data is kept on the users’ devices, whose computational resources are lev eraged to train mo dels in a collab orativ e manner. The resulting data is not typically balanced nor independent and iden tically distributed across machines, and additional constrain ts arise when many parties are inv olv ed. In particular, the sp ecificities of each user result in an increase in mo del complexity and size, and information needs to b e exchanged across users to comp ensate for the lac k of local data. In this con text, communication is usually a ma jor b ottlenec k, so that solutions aiming at reac hing an agreement b et ween user mo dels or requiring a cen tral co ordinator should b e av oided. In this work, we fo cus on ful ly de c entr alize d le arning , whic h has recently attracted a lot of interest (Duchi et al., 2012; W ei and Ozdaglar, 2012; Colin et al., 2016; Lian et al., 2017; Jiang et al., 2017; T ang et al., 2018; Lian et al., 2018). In this setting, users exchange in- formation through local p eer-to-peer exchanges in a sparse communication graph without relying on a cen- tral serv er that aggregates up dates or co ordinates the 1 This w ork was carried out while the author w as affili- ated with Univ Lyon, UJM-Sain t-Etienne, CNRS, Institut d Optique Graduate Sc ho ol, Lab oratoire Hub ert Curien UMR 5516, F rance F ully Decen tralized Joint Learning proto col. Unlike federated learning which requires suc h cen tral co ordination (McMahan et al., 2017; Kone ˇ cn` y et al., 2016; Kairouz et al., 2019), fully decentralized learning naturally scales to large num b ers of users with- out single p oin t of failure or communication bottlenecks (Lian et al., 2017). The present work stands out from existing approaches in fully decentralized learning, which train a single global mo del that may not be adapted to all users. Instead, our idea is to lev erage the fact that in many large-scale applications (e.g., predictiv e mo deling in smartphones apps), each user exhibits distinct b eha v- iors/preferences but is sufficien tly similar to some other p eers to b enefit from sharing information with them. W e thus prop ose to jointly discov er the relationships b et w een the personal tasks of users in the form of a sparse c ol lab or ation gr aph and learn personalized mo dels that leverage this graph to achiev e b etter gen- eralization p erformance. F or scalability reasons, the collab oration graph serves as an ov erla y to restrict the comm unication to pairs of users whose tasks app ear to b e sufficiently similar. In such a framework, it is cru- cial that the graph is well-aligned with the underlying similarit y b et w een the p ersonal tasks to ensure that the collab oration is fruitful and av oid conv ergence to p oorly-adapted mo dels. W e formulate the problem as the optimization of a join t ob jective ov er the mo dels and the collab oration graph, in which collab oration is ac hieved by introduc- ing a trade-off betw een (i) having the personal mo del of eac h user accurate on its lo cal dataset, and (ii) making the mo dels and the collab oration graph smo oth with resp ect to each other. W e then design and analyze a fully decentralized algorithm to solve our collab orativ e problem in an alternating pro cedure, in which we iter- ate b et ween up dating p ersonalized mo dels given the curren t graph and up dating the graph (with controlled sparsit y) given the current mo dels. W e first prop ose an approach to learn p ersonalized nonlinear classifiers as combinations of a set of base predictors inspired from l 1 -Adab oost (Shen and Li, 2010). In the pro- p osed decentralized algorithm, users greedily up date their p ersonal mo dels by incorp orating a single base predictor at a time and send the up date only to their direct neighbors in the graph. W e establish the conv er- gence rate of the pro cedure and show that it requires v ery low communication costs (linear in the num b er of edges in the graph and lo garithmic in the num b er of base classifiers to combine). W e then prop ose an ap- proac h to learn a sparse collab oration graph. F rom the decen tralized system persp ectiv e, users up date their neigh b orho od of similar p eers b y communicating only with small random subsets of p eers obtained through a p eer sampling service (Jelasity et al., 2007). Our approac h is flexible enough to accommo date v arious graph regularizers allowing to easily control the spar- sit y of the learned graph, whic h is key to the scalability of the mo del up date step. F or strongly conv ex regu- larizers, we prov e a fast conv ergence for our algorithm and show how the num b er of random users requested from the peer sampling service rules a trade-off betw een comm unication and conv ergence sp eed. T o summarize, we prop ose the first approach to train in a fully decen tralized wa y , i.e. without any central serv er, p ersonalized and nonlinear mo dels in a collab o- rativ e wa y while also learning the collab oration graph. Our main contr ibutions are as follows. (1) W e formal- ize the problem of learning with whom to collab orate, together with p ersonalized mo dels for collab orative de- cen tralized learning. (2) W e propose and analyze a fully decen tralized algorithm to learn nonlinear p ersonalized mo dels with low comm unication costs. (3) W e derive a generic and scalable approach to learn sparse collab- oration graphs in the decen tralized setting. (4) W e sho w that our alternating optimization scheme leads to b etter p ersonalized mo dels at low er communication costs than existing metho ds on several datasets. 2 RELA TED W ORK F ederated m ulti-task learning. Our work can be seen as m ulti-task learning (MTL) where each user is considered as a task. In MTL, multiple tasks are learned sim ultaneously with the assumption that a structure captures task relationships. A p opular ap- proac h in MTL is to join tly optimize mo dels for all tasks while enforcing similar mo dels for similar tasks (Ev- geniou and Pon til, 2004; Maurer, 2006; Dhillon et al., 2011). T ask relationships are often considered as kno wn a priori but recent work also tries to learn this struc- ture (see Zhang and Y ang, 2017, and references therein). Ho wev er, in classical MTL approac hes data is collected on a central server where the learning algorithm is p er- formed (or it is iid ov er the machines of a computing cluster). Recen tly , distributed and federated learning approac hes (W ang et al., 2016b,a; Baytas et al., 2016; Smith et al., 2017) ha ve b een prop osed to o vercome these limitations. Each no de holds data for one task (non iid data) but these approaches still rely on a cen tral serv er to aggregate updates. The federated learning approac h of (Smith et al., 2017) is closest to our work for it jointly learns p ersonalized (linear) mo dels and pairwise similarities across tasks. How ever, the simi- larities are up dated in a centralized wa y by the server whic h must regularly access all task mo dels, creating a significan t communication and computation b ottlenec k when the num b er of tasks is large. F urthermore, the task similarities do not form a v alid weigh ted graph and are typically not sparse. This makes their problem V alentina Zan tedeschi, Aur´ elien Bellet, Marc T ommasi form ulation p o orly suited to the fully decentralized setting, where sparsit y is key to ensure scalability . Decen tralized learning. There has b een a recen t surge of interest in fully decentralized machine learn- ing. In most existing w ork, the goal is to learn the same global mo del for all users by minimizing the av erage of the lo cal ob jectiv es (Duchi et al., 2012; W ei and Ozdaglar, 2012; Colin et al., 2016; Lafond et al., 2016; Lian et al., 2017; Jiang et al., 2017; T ang et al., 2018; Lian et al., 2018). In this case, there is no personal- ization: the graph merely enco des the communication top ology without any semantic meaning and only af- fects the con vergence sp eed. Our work is more closely inspired b y recent decentralized approaches that hav e sho wn the b enefits of collab orativ ely learning p erson- alized mo dels for each user by leveraging a similarit y graph given as input to the algorithm (V anhaesebrouck et al., 2017; Li et al., 2017; Bellet et al., 2018; Almeida and Xa vier, 2018). As in our approach, this is achiev ed through a graph regularization term in the ob jectiv e. A sev ere limitation to the applicability of these metho ds is that a relev ant graph must b e known b eforehand, whic h is an unrealistic assumption in many practical scenarios. Crucially , our approach lifts this limitation b y allowing to learn the graph along with the mo dels. In fact, as we demonstrate in our exp erimen ts, our decen tralized graph learning procedure of Section 5 can b e readily combined with the algorithms of (V an- haesebrouc k et al., 2017; Li et al., 2017; Bellet et al., 2018; Almeida and Xavier, 2018) in our alternating op- timization pro cedure, thereby broadening their scop e. It is also w orth mentioning that (V anhaesebrouc k et al., 2017; Li et al., 2017; Bellet et al., 2018; Almeida and Xa vier, 2018) are restricted to linear mo dels and hav e p er-iteration communication complexity linear in the data dimension. Our bo osting-based approac h (Sec- tion 4) learns nonlinear mo dels with logarithmic com- m unication cost, providing an interesting alternativ e for problems of high dimension and/or with complex decision b oundaries, as illustrated in our exp erimen ts. 3 PR OBLEM SETTING AND NOT A TIONS In this section, w e formally describ e the problem of in terest. W e consider a set of users (or agents) [ K ] = { 1 , . . . , K } , each with a personal data distri- bution ov er some common feature space X and lab el space Y defining a p ersonal sup ervise d le arning task . F or example, the p ersonal task of each user could b e to predict whether he/she likes a given item based on features describing the item. Each user k holds a lo cal dataset S k of m k lab eled examples drawn from its personal data distribution ov er X × Y , and aims to learn a model parameterized b y α k ∈ R n whic h generalizes well to new data p oin ts dra wn from its distribution. W e assume that all users learn mo dels from the same hypothesis class, and since they ha ve datasets of different sizes we introduce a notion of “confidence” c k ∈ R + for each user k whic h should b e though t of as prop ortional to m k (in practice w e simply set c k = m k / max l m l ). In a non-collab orativ e setting, eac h user k w ould t ypically select the mo del parameters that minimize some (p oten tially regularized) loss func- tion L k ( α k ; S k ) ov er its local dataset S k . This leads to p oor generalization p erformance when lo cal data is scarce. Instead, w e prop ose to study a collaborative learning setting in which users discov er relationships b et w een their p ersonal tasks whic h are leveraged to learn b etter p ersonalized mo dels. W e aim to solve this problem in a fully decentralized wa y without relying on a cen tral co ordinator no de. Decen tralized collab orativ e learning. F ollowing the standard practice in the fully decentralized litera- ture (Boyd et al., 2006), each user regularly b ecomes activ e at the ticks of an indep enden t lo cal clo c k which follo ws a Poisson distribution. Equiv alently , we con- sider a global clo c k (with counter t ) which ticks each time one of the lo cal clo c k ticks, whic h is conv enient for stating and analyzing the algorithms. W e assume that eac h user can send messages to any other user (like on the Internet) in a peer-to-p eer manner. How ever, in order to scale to a large num b er of users and to achiev e fruitful collab oration, we consider a semantic ov erlay on the communication la yer whose goal is to restrict the message exchanges to pairs of users whose tasks are most similar. W e call this ov erlay a c ol lab or ation gr aph , whic h is mo deled as an undirected w eighted graph G w = ([ K ] , w ) in which no des corresp ond to users and edge weigh ts w k,l ≥ 0 should reflect the similarity b e- t ween the learning tasks of users k and l , with w k,l = 0 indicating the absence of edge. A user k only sends messages to its direct neighbors N k = { l : w k,l > 0 } in G w , and p otentially to a small random set of p eers obtained through a p eer sampling service (see Jelasity et al., 2007, for a decentralized version). Imp ortantly , w e do not enforce the graph to b e connected: different connected comp onen ts can b e seen as mo deling clusters of unrelated users. In our approach, the collab oration graph is not known b eforehand and iteratively evolv es (con trolling its sparsity) in a learning scheme that al- ternates b etw een learning the graph and learning the mo dels. This scheme is designed to solve a global, joint optimization problem that w e introduce b elo w. Ob jective function. W e prop ose to learn the per- sonal classifiers α = ( α 1 , . . . , α K ) ∈ ( R n ) K and the collab oration graph w ∈ R K ( K − 1) / 2 to minimize the follo wing joint optimization problem: F ully Decen tralized Joint Learning min α ∈M w ∈W J ( α, w ) = P K k =1 d k ( w ) c k L k ( α k ; S k ) + µ 1 2 P k ∇ [ f ( α ( t − 1) )] k = β sign ( − ( ∇ [ f ( α ( t − 1) )] k ) j ( t ) k ) e j ( t ) k , (3) where j ( t ) k = ar g max j [ |∇ [ f ( α ( t − 1) )] k | ] j and e j ( t ) k is the unit vector with 1 in the j ( t ) k -th entry (Clarkson, 2010; Jaggi, 2013). In other words, FW up dates a single co- ordinate of the current mo del α ( t − 1) k whic h corresp onds to the maxim um absolute v alue entry of the partial gradien t ∇ [ f ( α ( t − 1) )] k . In our case, we hav e: ∇ [ f ( α ( t − 1) )] k = − d k ( w ) c k η > k A k + µ 1 ( d k ( w ) α ( t − 1) k − P l w k,l α ( t − 1) l ) , (4) with η k = exp( − A k α ( t − 1) k ) P m k i =1 exp( − A k α ( t − 1) k ) i . The first term in ∇ [ f ( α ( t − 1) )] k pla ys the same role as in standard Ad- ab oost: the j -th entry (corresp onding to the base pre- dictor h j ) is larger when h j ac hieves a large margin on the training sample S k rew eighted by η k (i.e., p oints that are currently po orly classified get more imp or- tance). On the other hand, the more h j is used b y the neigh b ors of k , the larger the j -th en try of the second term. The FW up date (3) th us preserves the fla vor of b o osting (incorp orating a single base classi- fier at a time which p erforms well on the reweigh ted sample) with an additional bias tow ards selecting base predictors that are p opular amongst neighbors in the collab oration graph. The relative imp ortance of the t wo terms dep ends on the user confidence c k . Decen tralized FW. W e are now ready to state our decen tralized FW algorithm to optimize f . Each user corresp onds keeps its p ersonal dataset locally . The fixed collab oration graph G w pla ys the role of an ov er- la y: user k only needs to communicate with its direct neigh b orho od N k in G w . The size of N k , | N k | , is typ- ically small so that up dates can occur in parallel in differen t parts of the netw ork, ensuring that the pro ce- dure scales w ell with the num b er of users. Our algorithm pro ceeds as follows. Let us denote by α ( t ) ∈ M the curren t mo dels at time step t . Eac h p ersonal classifier is initialized to some feasible p oin t α (0) k ∈ M k (suc h as the zero vector). Then, at each step t ≥ 1, a random user k w akes up and p erforms the follo wing actions: 1. Up date step: user k p erforms a FW up date on its lo cal mo del based on the most recent information α ( t − 1) l receiv ed from its neighbors l ∈ N k : α ( t ) k = (1 − γ ( t ) ) α ( t − 1) k + γ ( t ) s ( t ) k , with s ( t ) k as in (3) and γ ( t ) = 2 K/ ( t + 2 K ) . 2. Communic ation step: user k sends its up dated mo del α ( t ) k to its neigh b orho od N k . Imp ortan tly , the ab o ve up date only requires the knowl- edge of the models of neighboring users, which were receiv ed at earlier iterations. 4.2 Con vergence Analysis, Comm unication and Memory Costs The conv ergence analysis of our algorithm essentially follo ws the pro of technique prop osed in (Jaggi, 2013) and refined in (Lacoste-Julien et al., 2013) for the case of blo c k co ordinate F rank-W olfe. It is based on defining a surrogate for the optimalit y gap f ( α ) − f ( α ∗ ), where α ∗ ∈ ar g min α ∈M f ( α ). Under an appropriate notion of smo othness for f o ver the feasible domain, the conv ergence is established by showing that the gap decreases in exp ectation with the num b er of iterations, b ecause at a given iteration t the blo c k-wise surrogate gap at the current solution is minimized by the greedy up date s ( t ) k . W e obtain that our algorithm achiev es an O (1 /t ) conv ergence rate (see supplementary for the pro of ). Theorem 1. Our de c entr alize d F r ank-Wolfe algo- rithm takes at most 6 K ( C ⊗ f + p 0 ) /ε iter ations to find an appr oximate solution α that satisfies, in exp e ctation, f ( α ) − f ( α ∗ ) ≤ ε , wher e C ⊗ f ≤ 4 β 2 P K k =1 d k ( w )( c k k A k k 2 + µ 1 ) and p 0 = f ( α (0) ) − f ( α ∗ ) is the initial sub-optimality gap. Theorem 1 shows that large degrees for users with low confidence and small margins p enalize the conv ergence rate muc h less than for users with large confidence and large margins. This is rather intuitiv e as users in the latter case ha ve greater influence on the o verall solution in Eq. (1). Remark ably , using a few tricks in the representation of the sparse up dates, the comm unication and mem- ory cost needed b y our algorithm to conv erge to an -appro ximate solution can b e shown to b e linear in the num b er of edges of the graph and lo garithmic in the n umber of base predictors. W e refer to the sup- plemen tary material for details. F or the classic case F ully Decen tralized Joint Learning where base predictors consist of a constan t num b er of decisions stumps per feature, this translates in to a logarithmic cost in the dimensionality of the data leading to significantly b etter complexities than the state-of-the-art (see the exp erimen ts of Section 6). Remark 1 (Other loss functions) . We fo cus on the A dab o ost lo g loss (2) to emphasize that we c an le arn nonline ar mo dels while ke eping the formulation c onvex. We p oint out that our algorithm and analysis r e adily extend to other c onvex loss functions, as long as we ke ep an L1-c onstr aint on the p ar ameters. 5 DECENTRALIZED LEARNING OF COLLABORA TION GRAPH In the previous section, we ha ve prop osed and analyzed an algorithm to learn the model parameters α giv en a fixed collab oration graph w . T o make our fully de- cen tralized alternating optimization scheme complete, w e now turn to the conv erse problem of optimizing the graph weigh ts w giv en fixed mo dels α . W e will work with flexible graph regularizers g ( w ) that are weight and de gr e e-sep ar able : g ( w ) = P k 1 (as eac h w eight is shared b y t wo users). W e build up on the PCD analysis due to (W right, 2015), which w e adapt to account for our ov erlapping blo c k structure. The de- tails of our analysis can b e found in the supplementary material. F or the case where g is strongly conv ex, we obtain the follo wing conv ergence rate. 3 Theorem 2. Assume that g ( w ) is σ -str ongly c on- vex. L et T > 0 and h ∗ b e the optimal obje ctive value. Our algorithm cuts the exp e cte d sub optimal- ity gap by a c onstant factor ρ at e ach iter ation: we have E [ h ( w ( T ) ) − h ∗ ] ≤ ρ T ( h ( w (0) ) − h ∗ ) with ρ = 1 − 2 κσ K ( K − 1) L max with L max = max ( k, K ) L k, K . The rate of Theorem 2 is typically faster than the sub- linear rate of the bo osting subproblem (Theorem 1), suggesting that a small num b er of up dates p er user is sufficien t to reach reasonable optimization error b e- fore re-up dating the mo dels given the new graph. In the supplementary , we further analyze the trade-off 3 F or the general con vex case, we can obtain a slow er O (1 /T ) conv ergence rate. V alentina Zan tedeschi, Aur´ elien Bellet, Marc T ommasi b et w een communication and memory costs and the con vergence rate ruled by κ . Prop osed regularizer. In our exp eriments, we use a graph regularizer defined as g ( w ) = λ k w k 2 − 1 > log ( d ( w ) + δ ), whic h is inspired from (Kalofolias, 2016). The log term ensures that all nodes ha v e nonzero degrees (the small p ositiv e constan t δ is a simple trick to mak e the logarithm smo oth on the feasible domain, see e.g., (Koriche, 2018)) without ruling out non-connected graphs with several connected comp onen ts. Crucially , λ > 0 provides a direct wa y to tune the sparsity of the graph: the smaller λ , the more concentrated the w eights of a given user on the p eers with the closest mo dels. This allows us to control the trade-off b et ween accuracy and comm unication in the mo del up date step of Section 4, whose communication cost is linear in the n umber of edges. The resulting ob jectiv e is strongly con vex and blo c k-Lipsc hitz contin uous (see supplemen- tary for the deriv ation of the parameters and analysis of the trade-offs). Finally , as discussed in (Kalofolias, 2016), tuning the imp ortance of the log-degree term with resp ect to the other graph terms has simply a scaling effect, th us we can simply set µ 2 = µ 1 in (1). Remark 2 (Reducing the num b er of v ariables) . T o r e duc e the numb er of variables to optimize, e ach user c an ke ep to 0 the weights c orr esp onding to users whose curr ent mo del is most differ ent to theirs. This heuristic has a ne gligible imp act on the solution quality in sp arse r e gimes (smal l λ ). 6 EXPERIMENTS In this section, we study the practical b eha vior of our approach. Denoting our decen tralized Adabo ost metho d introduced in Section 4 as Dada, we study t wo v arian ts: Dada-Oracle (which uses a fixed oracle graph giv en as input) and Dada-Learned (where the graph is learned along with the mo dels). W e com- pare against v arious competitors, which learn either global or p ersonalized mo dels in a cen tralized or decen- tralized manner. Global-b o ost and Global-lin learn a single global l 1 -Adab oost mo del (resp. linear mo del) o ver the centralized dataset S = ∪ k S k . Lo cal-bo ost and Lo cal-lin learn (Adab oost or linear) p ersonalized mo dels indep enden tly for eac h user without collab o- ration. Finally , P erso-lin is a decentralized metho d for collab orativ ely learning personalized linear mod- els (V anhaesebrouck et al., 2017). This approach re- quires an oracle graph as input (Perso-lin-Oracle) but it can also directly b enefit from our graph learning approac h of Section 5 (we denote this new v ariant by P erso-lin-Learned). W e use the same set of base predic- tors for all b oosting-based metho ds, namely n simple decision stumps uniformly split b etw een all D dimen- T able 1: T est accuracy (%) on real data, av eraged o ver 3 runs. Best results in b oldface, second b est in italic. D A T ASET HAR WS VEH. COMP . SCH. Global-linear 93.64 87.11 62.18 57.06 Local-linear 92.69 90.38 60.68 70.43 Perso-linear-Learned 96.87 91.45 69.10 71.78 Global-Adabo ost 94.34 88.02 69.16 69.96 Local-Adab oost 93.16 90.59 66.61 70.69 Dada-Learned 95.57 91.04 73.55 72.47 sions and v alue ranges. F or all metho ds we tune the h yp er-parameters with 3-fold cross v alidation. Models are initialized to zero v ectors and the initial graphs of Dada-Learned and P erso-lin-Learned are learned using the purely local classifiers, and then up dated after ev ery 100 iterations of optimizing the classifiers, with κ = 5. All rep orted accuracies are a veraged ov er users. Additional details and results can b e found in the supplemen tary . The source code is av ailable at https://github.com/vzantedeschi/Dada . Figure 1: Results on the Moons dataset. T op: T raining and test accuracy w.r.t. iterations (we display the p er- formance of non-collab orativ e baselines at conv ergence with a straight line). Global-lin is off limits at ∼ 50% accuracy . Bottom: Average num b er of neighbors w.r.t. iterations for Dada-Learned. Syn thetic data. T o study the b eha vior of our ap- proac h in a controlled setting, our first set of exp eri- men ts is carried out on a synthetic problem ( Moons ) constructed from the classic tw o interlea ving Mo ons dataset which has nonlinear class b oundaries. W e con- sider K = 100 users, clustered in 4 groups of 10, 20, 30 and 40 users. Users in the same cluster are asso ciated with a similar rotation of the feature space and hence F ully Decen tralized Joint Learning T able 2: T est accuracy (%) with different fixed communication budgets (# bits) on real datasets. BUDGET MODEL HAR WS VEHICLE COMPUTER SCHOOL DZ × 160 Perso-lin-Learned - - - - Dada-Learned 95.70 75.11 52.03 56.83 DZ × 500 Perso-lin-Learned 81.06 89.82 - - Dada-Learned 95.70 89.57 62.22 71.90 DZ × 1000 Perso-lin-Learned 87.55 90.52 68.95 71.90 Dada-Learned 95.70 90.81 68.83 72.22 ha ve similar tasks. W e construct an oracle collab ora- tion graph based on the difference in rotation angles b et w een users, whic h is giv en as input to Dada-Oracle and Perso-lin-Oracle. Eac h user k obtains a training sample random size m k ∼ U (3 , 15). The data dimen- sion is D = 20 and the n umber of base predictors is n = 200. W e refer to the supplementary material for more details on the dataset generation. Figure 1 (left) sho ws the accuracy of all metho ds. As exp ected, all lin- ear mo dels (including Perso-lin) p erform p o orly since the tasks hav e highly nonlinear decision b oundaries. The results show the clear gain in accuracy provided b y our metho d: b oth Dada-Oracle and Dada-Learned are successful in reducing the ov erfitting of Local-b o ost, and also achiev e higher test accuracy than Global-bo ost. Dada-Oracle outp erforms Dada-Learned as it makes use of the oracle graph computed from the true data distributions. Despite the noise i ntroduced by the finite sample setting, Dada-Learned effectively makes up for not having access to any kno wledge on the relations b e- t ween the users’ tasks. Figure 1 (right) shows that the graph learned by Dada-Learned remains sparse across time (in fact, alw ays sparser than the oracle graph), ensuring a small communication cost for the mo del up date steps. Figure 2 (left) confirms that the graph learned by Dada-Learned is able to approximately re- co ver the ground-truth cluster structure. Figure 2 (righ t) pro vides a more detailed visualization of the learned graph. W e can clearly see the effect of the inductiv e bias brought b y the c onfidence-w eighted loss term in Problem (1) discussed in Section 3. In partic- ular, no des with high confidence and high loss v alues tend to hav e small degrees while no des with low confi- dence or lo w loss v alues are more densely connected. Real data. W e present results on real datasets that are naturally collected at the user level: Human Activ- it y Recognition With Smartphones ( Har ws , K = 30, D = 561) (Anguita et al., 2013), Vehicle Sen- sor (Duarte and Hu, 2004) ( K = 23, D = 100), Com- puter Buyers ( K = 190, D = 14) and School (Gold- stein, 1991) ( K = 140, D = 17). As shown in T able 3, Dada-Learned and P erso-lin-Learned, whic h b oth mak e use of our alternating pro cedure, ac hieve the b est p er- formance. This demonstrates the wide applicabilit y of our graph learning approach, for it enables the use 5 4 4 7 4 3 4 3 3 4 5 3 6 5 3 9 4 2 4 6 1 2 5 1 2 9 1 3 9 1 3 6 1 5 2 1 3 7 1 2 5 1 2 5 1 4 6 1 4 8 1 5 3 1 3 0 1 4 9 1 3 2 1 4 1 1 3 6 1 4 4 1 2 9 1 4 7 1 4 1 3 1 5 3 0 1 3 2 7 3 3 2 3 3 5 3 2 0 3 1 0 2 9 1 3 2 5 3 3 5 3 2 9 3 1 4 3 0 9 3 2 3 3 1 8 2 8 4 3 1 3 3 0 9 3 2 4 3 1 4 3 0 8 3 0 8 3 1 3 2 8 8 3 1 8 2 9 8 3 2 1 2 8 4 3 2 3 3 1 8 2 3 2 2 1 3 2 3 0 2 3 0 2 2 6 2 3 7 2 1 4 2 2 3 2 0 3 2 4 2 2 3 6 2 3 4 2 3 1 2 2 1 2 2 2 2 4 2 2 3 8 2 2 8 2 2 6 2 6 0 2 1 7 2 0 8 2 2 6 2 2 3 2 2 5 2 1 9 2 1 0 2 1 4 2 1 9 2 2 8 2 3 6 2 1 2 2 1 0 2 2 9 2 1 7 2 4 6 2 2 6 2 2 5 2 2 3 2 2 5 Figure 2: Graph learned on Moons . T op: Graph w eights for the oracle and learned graph (with users group ed by cluster). Bottom: Visualization of the graph. The no de size is prop ortional to the confidence c k and the color reflects the relative v alue of the lo cal loss (greener = smaller loss). No des are lab eled with their rotation angle, and a darker edge color indicates a higher w eight. of Perso-lin (V anhaesebrouck et al., 2017) on datasets where no prior information is av ailable to build a pre- defined collab oration graph. Thanks to its logarithmic comm unication, our approach Dada-Learned achiev es higher accuracy under limited communication budgets, esp ecially on higher-dimensional data (T able 2). More details and results are giv en in the supplementary . 7 FUTURE WORK W e plan to extend our approach to (functional) gra- dien t b o osting (F riedman, 2001; W ang et al., 2015) V alentina Zan tedeschi, Aur´ elien Bellet, Marc T ommasi where the graph regularization term would need to b e applied to an infinite set of base predictors. An- other promising direction is to mak e our approach differen tially-priv ate (Dwork, 2006) to formally guaran- tee that p ersonal datasets cannot b e inferred from the information sent by users. As our algorithm comm uni- cates very scarcely , we think that the priv acy/accuracy trade-off ma y b e b etter than the one known for linear mo dels (Bellet et al., 2018). Ac knowledgmen ts The authors would lik e to thank R ´ emi Gilleron for his useful feedback. This researc h was partially sup- p orted by grants ANR-16-CE23-0016-01 and ANR-15- CE23-0026-03, by the Europ ean Union’s Horizon 2020 Researc h and Inno v ation Program under Grant Agree- men t No. 825081 COMPRISE and b y a grant from CPER Nord-Pas de Calais/FEDER DA T A Adv anced data science and tec hnologies 2015-2020. References Almeida, I. and Xavier, J. (2018). DJAM: Distributed Jacobi Async hronous Metho d for Learning Personal Mo dels. IEEE Signal Pr o c essing L etters , 25(9):1389– 1392. Anguita, D., Ghio, A., Oneto, L., P arra, X., and Reyes- Ortiz, J. L. (2013). A public domain dataset for h uman activity recognition using smartphones. In ESANN . Ba ytas, I. M., Y an, M., Jain, A. K., and Zhou, J. (2016). Async hronous Multi-task Learning. In ICDM . Bellet, A., Guerraoui, R., T aziki, M., and T ommasi, M. (2018). Personalized and Priv ate Peer-to-P eer Mac hine Learning. In AIST A TS . Berger, P ., Buchac her, M., Hannak, G., and Matz, G. (2018). Graph Learning Based on T otal V ariation Minimization. In ICASSP . Bo yd, S. P ., Ghosh, A., Prabhak ar, B., and Shah, D. (2006). Randomized gossip algorithms. IEEE T r ans- actions on Information The ory , 52(6):2508–2530. Clarkson, K. L. (2010). Coresets, sparse greedy ap- pro ximation, and the F rank-W olfe algorithm. ACM T r ansactions on Algorithms , 6(4):1–30. Colin, I., Bellet, A., Salmon, J., and Cl´ emen¸ con, S. (2016). Gossip dual av eraging for decentralized opti- mization of pairwise functions. In ICML . Dhillon, P . S., Sellamanic k am, S., and Selv ara j, S. K. (2011). Semi-sup ervised mu lti-task learning of struc- tured prediction mo dels for w eb information extrac- tion. In CIKM , pages 957–966. Dong, X., Thanou, D., F rossard, P ., and V an- dergheynst, P . (2016). Learning Laplacian matrix in smo oth graph signal representations. IEEE T r ans- actions on Signal Pr o c essing , 64(23):6160–6173. Duarte, M. F. and Hu, Y. H. (2004). V ehicle classi- fication in distributed sensor netw orks. Journal of Par al lel and Distribute d Computing , 64(7):826–838. Duc hi, J. C., Agarwal, A., and W ainwrigh t, M. J. (2012). Dual Averaging for Distributed Optimization: Con vergence Analysis and Netw ork Scaling. IEEE T r ansactions on Automatic Contr ol , 57(3):592–606. Dw ork, C. (2006). Differential Priv acy . In ICALP , v olume 2. Evgeniou, T. and Pon til, M. (2004). Regularized multi- task learning. In KDD . F rank, M. and W olfe, P . (1956). An algorithm for quadratic programming. Naval R ese ar ch L o gistics (NRL) , 3:95–110. F riedman, J. H. (2001). Greedy function approxima- tion: A gradient b oosting machine. The Annals of Statistics , 29(5):1189–1232. Goldstein, H. (1991). Multilevel mo delling of survey data. Journal of the R oyal Statistic al So ciety. Series D (The Statistician) , 40(2):235–244. Jaggi, M. (2013). Revisiting F rank-W olfe: Pro jection- F ree Sparse Conv ex Optimization. In ICML . Jelasit y , M., V oulgaris, S., Guerraoui, R., Kermarrec, A.-M., and v an Steen, M. (2007). Gossip-based p eer sampling. ACM T r ans. Comput. Syst. , 25(3). Jiang, Z., Balu, A., Hegde, C., and Sark ar, S. (2017). Collab orativ e Deep Learning in Fixed T op ology Net- w orks. In NIPS . Kairouz, P ., McMahan, H. B., Aven t, B., Bellet, A., Bennis, M., Bhago ji, A. N., Bona witz, K., Charles, Z., Cormode, G., Cummings, R., D’Oliv eira, R. G. L., Roua yheb, S. E., Ev ans, D., Gardner, J., Garrett, Z., Gasc´ on, A., Ghazi, B., Gibb ons, P . B., Gruteser, M., Harc haoui, Z., He, C., He, L., Huo, Z., Hutchinson, B., Hsu, J., Jaggi, M., Javidi, T., Joshi, G., Kho- dak, M., Koneˇ cn´ y, J., Korolov a, A., Koushanfar, F., Ko yejo, S., Lep oin t, T., Liu, Y., Mittal, P ., Mohri, M., Nock, R., ¨ Ozg ¨ ur, A., Pagh, R., Rayk ov a, M., Qi, H., Ramage, D., Rask ar, R., Song, D., Song, W., Stich, S. U., Sun, Z., Suresh, A. T., T ram ` er, F., V epakomma, P ., W ang, J., Xiong, L., Xu, Z., Y ang, Q., Y u, F. X., Y u, H., and Zhao, S. (2019). Adv ances and Op en Problems in F ederated Learning. T echnical rep ort, Kalofolias, V. (2016). How to learn a graph from smo oth signals. In AIST A TS . Kone ˇ cn` y, J., McMahan, H. B., Y u, F. X., Ric ht´ arik, P ., Suresh, A. T., and Bacon, D. (2016). F ederated F ully Decen tralized Joint Learning learning: Strategies for impro ving communication efficiency. arXiv pr eprint arXiv:1610.05492 . Koric he, F. (2018). Compiling Combinatorial Predic- tion Games. In ICML . Lacoste-Julien, S., Jaggi, M., Schmidt, M., and Pletsc her, P . (2013). Blo ck-Coordinate F rank-W olfe Optimization for Structural SVMs. In ICML . Lafond, J., W ai, H.-T., and Moulines, E. (2016). D-FW: Comm unication efficient distributed algorithms for high-dimensional sparse optimization. In ICASSP . Li, J., Arai, T., Baba, Y., Kashima, H., and Miwa, S. (2017). Distributed Multi-task Learning for Sensor Net work. In ECML/PKDD . Lian, X., Zhang, C., Zhang, H., Hsie h, C.-J., Zhang, W., and Liu, J. (2017). Can Decentralized Algo- rithms Outp erform Centralized Algorithms? A Case Study for Decentralized Parallel Sto c hastic Gradient Descen t. In NIPS . Lian, X., Zhang, W., Zhang, C., and Liu, J. (2018). Async hronous Decen tralized P arallel Sto c hastic Gra- dien t Descent. In ICML . Maurer, A. (2006). The Rademac her Complexit y of Linear T ransformation Classes. In COL T . McMahan, H. B., Mo ore, E., Ramage, D., Hampson, S., and Ag ¨ uera y Arcas, B. (2017). Communication- efficien t learning of deep net works from decen tralized data. In AIST A TS . Raza viya yn, M., Hong, M., and Luo, Z.-Q. (2013). A unified con vergence analysis of blo c k successive minimization metho ds for nonsmo oth optimization. SIAM Journal on Optimization , 23(2):1126–1153. Ric ht´ arik, P . and T ak´ ac, M. (2014). Iteration complex- it y of randomized blo c k-co ordinate descen t metho ds for minimizing a comp osite function. Mathematic al Pr o gr amming , 144(1-2):1–38. Shen, C. and Li, H. (2010). On the dual form ulation of b oosting algorithms. IEEE T r ansactions on Pat- tern Analysis and Machine Intel ligenc e , 32(12):2216– 2231. Smith, V., Chiang, C.-K., Sanjabi, M., and T alwalk ar, A. S. (2017). F ederated Multi-T ask Learning. In NIPS . T ang, H., Lian, X., Y an, M., Zhang, C., and Liu, J. (2018). D 2 : Decen tralized T raining ov er Decentral- ized Data. In ICML . Tseng, P . (2001). Conv ergence of a blo c k co ordinate descen t metho d for nondifferentiable minimization. Journal of Optimization The ory and Applic ations , 109(3):475–494. Tseng, P . and Y un, S. (2009). Block-coordinate gradien t descen t metho d for linearly constrained nonsmo oth separable optimization. Journal of Optimization The ory and Applic ations , 140(3):140–513. V anhaesebrouck, P ., Bellet, A., and T ommasi, M. (2017). Decentralized Collab orativ e Learning of Per- sonalized Mo dels ov er Net works. In AIST A TS . W ang, C., W ang, Y., Schapire, R., et al. (2015). F unc- tional F rank-W olfe Bo osting for General Loss F unc- tions. arXiv pr eprint arXiv:1510.02558 . W ang, J., Kolar, M., and Srebro, N. (2016a). Dis- tributed Multi-T ask Learning with Shared Represen- tation. arXiv pr eprint arXiv:1603.02185 . W ang, J., Kolar, M., and Srebro, N. (2016b). Dis- tributed Multitask Learning. In AIST A TS . W ei, E. and Ozdaglar, A. E. (2012). Distributed Alter- nating Direction Metho d of Multipliers. In CDC . W right, S. J. (2015). Co ordinate descent algorithms. Mathematic al Pr o gr amming , 151(1):3–34. Zhang, Y. and Y ang, Q. (2017). A survey on m ulti-task learning. arXiv pr eprint arXiv:1707.08114 . V alentina Zan tedeschi, Aur´ elien Bellet, Marc T ommasi SUPPLEMENT AR Y MA TERIAL This supplementary material is organized as follo ws. Section A provides the conv ergence analysis for our decen tralized F rank-W olfe b o osting algorithm. Section B describ es the conv ergence analysis of our decentralized graph learning algorithm. In Section C, w e derive the strong con vexit y and smo othness parameters of g ( w ) = λ k w k 2 − 1 > log ( d ( w ) + δ ) needed to apply Theorem 2. Section D discusses the communication and memory costs of our metho d, with an emphasis on the scalability . Finally , Section E gives more details on our exp erimen tal setting and presen t additional results. A PR OOF OF THEOREM 1 W e first recall our optimization problem ov er the classifiers α = [ α 1 , . . . , α K ] ∈ ( R n ) K : min k α 1 k 1 ,..., k α K k 1 ≤ β f ( α ) = K X k =1 d k ( w ) c k log 1 m k m k X i =1 exp − ( A k α k ) i + µ 1 2 K X k =1 k − 1 X l =1 w k,l k α k − α l k 2 . (6) W e recall some notations. F or any k ∈ [ K ], w e let M k = { α k ∈ R n : α k 1 ≤ β } and denote by M = M 1 × · · · × M K our feasible domain in (6) . W e also denote by v [ k ] ∈ M the zero-padding of any v ector v k ∈ M k . Finally , for conciseness of notations, for a given γ ∈ [0 , 1] we write ˆ α = α + γ ( s [ k ] − α [ k ] ) and ˆ α k = (1 − γ ) α k + γ s k . A.1 Curv ature Bound W e first sho w that our ob jectiv e function satisfies a form of smoothness ov er the feasible domain, which is expressed b y a notion of curv ature. Precisely , the global pro duct curv ature constant C ⊗ f of f o ver M is the sum ov er each blo c k of the maximum relativ e deviation of f from its linear approximations o ver the blo c k (Lacoste-Julien et al., 2013): C ⊗ f = K X k =1 C k f = K X k =1 sup α ∈M ,s k ∈M k γ ∈ [0 , 1] n 2 γ 2 f ( ˆ α ) − f ( α ) − ( ˆ α k − α k ) > ∇ k f ( α ) o . (7) W e will use the fact that each partial curv ature constan t C k f is upp er b ounded b y the (blo ck) Lipschitz constant of the partial gradient ∇ k f ( α ) times the squared diameter of the blo ckwise feasible domain M k (Lacoste-Julien et al., 2013). The next lemma gives a b ound on the pro duct space curv ature C ⊗ f . Lemma 1. F or Pr oblem (6) , we have C ⊗ f ≤ 4 β 2 P K k =1 d k ( w )( c k A k 2 1 + µ 1 ) . Pr o of. F or the follo wing proof, w e rely on tw o key concepts: the Lipschitz contin uity and the diameter of a compact space. A function f : X → R is L -lipschitz w.r.t. the norm . 1 if ∀ ( x, x 0 ) ∈ X 2 : | f ( x ) − f ( x 0 ) | ≤ L x − x 0 1 . (8) The diameter of a compact normed v ector space ( M , k . k ) is defined as: diam k . k ( M ) = sup x,x 0 ∈M k x − x 0 k . W e can easily b ound the diameter of the subspace M k = { α k ∈ R n : α k 1 ≤ β } as follows: diam k . k 1 ( M k ) = max α k ,α 0 k ∈M k α k − α 0 k 1 = 2 β . (9) W e recall the expression for the partial gradient: ∇ k f ( α ) = − d k ( w ) c k η k ( α ) > A k + µ 1 d k ( w ) α [ k ] − X l w k,l α [ l ] , (10) F ully Decen tralized Joint Learning where we denote η k ( α ) = exp( − A k α [ k ] ) P m k i =1 exp( − A k α [ k ] ) i . W e b ound the Lipsc hitz constan t of η k ( α ) by b ounding its first deriv ative: ∇ k ( η k ( α )) 1 = ( − η k ( α ) + η k ( α ) 2 ) > A k 1 ≤ A k 1 . (11) Eq. (11) is due to the fact that η k ( α ) 1 ≤ 1 and η k ( α ) ≥ 0. It is then easy to see that considering any tw o v ectors α, α 0 ∈ M differing only in their k -th blo c k ( α [ l ] = α 0 [ l ] ∀ l 6 = k ), the Lipschitz constant L k of the partial gradien t ∇ k f in (10) is b ounded by d k ( w )( c k k A k k 2 1 + µ 1 ). Finally , we obtain Lemma 1 by combining the ab o ve results (9) and (11): C ⊗ f = K X k =1 C k f ≤ K X k =1 L k diam 2 k . k 1 ( M k ) ≤ 4 β 2 P K k =1 d k ( w )( c k A k 2 1 + µ 1 ) . (12) A.2 Con vergence Analysis W e can now pro ve the conv ergence rate of our algorithm by follo wing the pro of technique prop osed by Jaggi in (Jaggi, 2013) and refined b y (Lacoste-Julien et al., 2013) for the case of blo ck co ordinate F rank-W olfe. W e start by introducing some useful notation related to our problem (6): gap( α ) = max s ∈M { ( α − s ) > ∇ ( f ( α )) } = P K k =1 gap k ( α k ) = P K k =1 max s k ∈M k { ( α k − s k ) > ∇ k f ( α ) } (13) The quan tity gap ( α ) can serve as a certificate for the quality of a current approximation of the optimum of the ob jective function (Jaggi, 2013). In particular, one can show that f ( α ) − f ( α ∗ ) ≤ gap ( α ) where α ∗ is a solution of (6) . Under a b ounded global pro duct curv ature constant C ⊗ f , w e will obtain the conv ergence of F rank-W olfe b y showing that the surrogate gap decreases in exp ectation ov er the iterations, b ecause at a given iteration t the blo c k-wise surrogate gap at the curren t solution gap k ( α ( t ) k ) is minimized b y the greedy up date s ( t ) k ∈ M k . Using the definition of the curv ature (7) and rewriting ˆ α k − α k = − γ k ( α k − s k ), w e obtain f ( ˆ α ) ≤ f ( α ) − γ ( α k − s k ) > ∇ k f ( α ) + γ 2 C k f 2 . In particular, at any iteration t , the previous inequality holds for γ = γ ( t ) = 2 K t +2 K , α ( t +1) = α ( t ) + γ ( t ) ( s ( t +1) k − α ( t +1) k ) with s ( t +1) k = ar g min s ∈M k { s > ∇ k f ( α ( t ) ) } as defined in (3) . Therefore, ( α k − s k ) > ∇ k f ( α ) is by definition gap k ( α k ) and f ( α ( t +1) ) ≤ f ( α ( t ) ) − γ ( t ) gap k ( α ( t ) k ) + ( γ ( t ) ) 2 C k f 2 . By taking the exp ectation ov er the random c hoice of k ∼ U (1 , K ) on b oth sides, we obtain E k [ f ( α ( t +1) )] ≤ E k [ f ( α ( t ) )] − γ ( t ) E k [gap k ( α ( t ) k )] + ( γ ( t ) ) 2 E k [ C k f ] 2 ≤ E k [ f ( α ( t ) )] − γ ( t ) gap( α ( t ) ) K + ( γ ( t ) ) 2 C ⊗ f 2 K . (14) Let us define the sub-optimality gap p ( α ) = f ( α ) − f ∗ with f ∗ the optimal v alue of f . By subtracting f ∗ from b oth sides in (14), we obtain E k [ p ( α ( t +1) )] ≤ E k [ p ( α ( t ) )] − γ ( t ) K E k [ p ( α ( t ) )] + ( γ ( t ) ) 2 C ⊗ f 2 K (15) ≤ 1 − γ ( t ) K E k [ p ( α ( t ) )] + ( γ ( t ) ) 2 C ⊗ f 2 K . (16) V alentina Zan tedeschi, Aur´ elien Bellet, Marc T ommasi Inequalit y (15) comes from the definition of the surrogate gap (13) which ensures that E k [ p ( α )] ≤ gap( α ). Therefore, we can show by induction that the exp ected sub-optimalit y gap satisfies E k [ p ( α ( t +1) )] ≤ 2 K ( C ⊗ f + p 0 ) t +2 K , with p 0 = p ( α (0) ) the initial gap. This shows that the exp ected sub-optimality gap E k [ p ( α )] decreases with the n umber of iterations with a rate O ( 1 t ), which implies the conv ergence of our algorithm to the optimal solution. The final conv ergence rate can then b e obtained by the same pro of as (Lacoste-Julien et al., 2013) (App endix C.3 therein) com bined with Lemma 1. B PR OOF OF THEOREM 2 W e first show that our algorithm can b e explicitly formulated as an instance of proximal blo c k co ordinate descent (Section B.1). Building up on this formulation, we prov e the conv ergence rate in Section B.2. B.1 In terpretation as Proximal Co ordinate Descen t First, we reformulate our graph learning subproblem as an equiv alent unconstrained optimization problem b y incorp orating the nonnegativity constraints into the ob jective: min w ∈ R K ( K − 1) / 2 F ( w ) = h ( w ) + r ( w ) , (17) where h ( w ) = K X k =1 d k ( w ) c k L k ( α k ; S k ) + µ 1 2 X k [ ∇ h ( w ( t ) )] k, K + L k, K 2 k z − w ( t ) k, K k 2 + X l ∈K I ≥ 0 ( z k,l ) o w ( t +1) ← w ( t ) + U k, K ( z ( t ) k, K − w ( t ) k, K ) (20) F or notational conv enience , U k, K denotes the column submatrix of the K ( K − 1) / 2 × K ( K − 1) / 2 identit y matrix suc h that w > U k, K = w k, K ∈ R κ for an y w ∈ R K ( K − 1) / 2 . Notice that the minimization problem in (20) is separable and can b e solved indep enden tly for each co ordinate. Denoting b y ˜ z ( t ) = ar g min z ∈ R K ( K − 1) / 2 ( z − w ( t ) ) > ∇ h ( w ( t ) ) + L k, K 2 k z − w ( t ) k 2 + r ( z ) , (21) w e can thus rewrite (20) as: w ( t +1) j,l = ( ˜ z ( t ) j,l if j = k and l ∈ K w ( t ) j,l otherwise (22) F ully Decen tralized Joint Learning Finally , recalling the definition of the proximal op erator of a function f : pr ox f ( w ) = ar g min z n f ( z ) + 1 2 k w − z k 2 o , w e can rewrite (21) as: ˜ z ( t ) = pr ox 1 L k, K r ( w ( t ) − (1 /L k, K ) ∇ h ( w ( t ) )) . (23) W e hav e indeed obtained that (22) corresp onds to a proximal blo c k co ordinate descent up date (Rich t´ arik and T ak´ ac, 2014), i.e. a proximal gradient descent step restricted to a blo c k of co ordinates. When f is the characteristic function of a set, the proximal op erator corresp onds to the Euclidean pro jection on to the set. Hence, in our case we hav e pr ox r ( w ) = max (0 , w ) (the thresholding op erator), and we recov er the simple up date introduced in the main text. B.2 Con vergence Analysis W e start by introducing a conv enien t lemma. Lemma 2. F or any blo ck of size κ indexe d by ( k , K ) , any w ∈ R K ( K − 1) / 2 and any z ∈ R κ , we have: h ( w + U k, K z ) ≤ h ( w ) + z > [ ∇ h ( w )] k, K + L k, K 2 k z k 2 . Pr o of. This is obtained b y applying T aylor’s inequality to the function q w : R κ → R z 7→ h ( w + U k, K z ) com bined with the conv exity and L k, K -blo c k smo othness of h . W e are now ready the prov e the conv ergence rate of our algorithm. W e fo cus b elo w on the more interesting cases where the blo c k size κ > 1, since the case κ = 1 (blo c ks of size 1) reduces to standard proximal co ordinate descent and can b e addressed directly by previous work (Rich t´ arik and T ak´ ac, 2014; W right, 2015). Recall that in our algorithm, at each iteration an user k is dra wn uniformly at random from [ K ], and then this user samples a set K of κ other users uniformly and without replacement from the set { 1 , . . . , K } \ { k } . This giv es rise to a blo ck of co ordinates indexed by ( k , K ). Let B b e the set of such p ossible blo c k indices. Note that B has cardinality K K − 1 κ since for κ > 1 all K − 1 κ blo c ks that can b e sampled b y an user are unique (i.e., they cannot b e sampled by other users). How ever, it is imp ortan t to note that unlike commonly assumed in the blo c k co ordinate descent literature, our blo c ks exhibit an ov erlapping structure: each co ordinate blo c k b ∈ B shares some of its co ordinates with several other blo c ks in B . In particular, eac h co ordinate (graph weigh t) w i,j is shared b y user i and user j can th us b e part of blo c ks drawn by b oth users. Our analysis builds up on the pro of tec hnique of (W right, 2015), adapting the arguments to handle our up date structure based on ov erlapping blo cks rather than single co ordinates. Let b t = ( k , K ) ∈ B b e the block of co ordinates selected at iteration t . F or notational con venience, we write ( j, l ) ∈ b t to denote the set of co ordinates indexed by blo c k b t (i.e., index pairs ( j, l ) suc h that j = k and l ∈ K ). Consider the exp ectation of the ob jective function F ( w ( t +1) ) in (17) o ver the c hoice of b t , plugging in the up date (20): V alentina Zan tedeschi, Aur´ elien Bellet, Marc T ommasi E b t [ F ( w ( t +1) )] = E b t h h w ( t ) + U b t ( z ( t ) b t − w ( t ) b t ) + X ( j,l ) ∈ b t I ≥ 0 ( z ( t ) j,l ) + X ( j,l ) / ∈ b t I ≥ 0 ( w ( t ) j,l ) i = 1 K K − 1 κ X b ∈B h h w ( t ) + U b ( z ( t ) b − w ( t ) b ) + X ( j,l ) ∈ b I ≥ 0 ( z ( t ) j,l ) + X ( j,l ) / ∈ b I ≥ 0 ( w ( t ) j,l ) i ≤ 1 K K − 1 κ X b ∈B h h ( w ( t ) ) + ( z ( t ) b − w ( t ) b ) > [ ∇ h ( w ( t ) )] b + L b 2 k z ( t ) b − w ( t ) b k 2 + X ( j,l ) ∈ b I ≥ 0 ( z ( t ) j,l ) + X ( j,l ) / ∈ b I ≥ 0 ( w ( t ) j,l ) i , (24) where w e hav e used Lemma 2 to obtain (24), and z ( t ) b is defined as in (20) for an y blo c k b = ( k , K ). W e no w need to aggregate the blo c ks o ver the sum in (24) , taking into account the o verlapping structure of our blo cks. W e rely on the observ ation that each co ordinate w k,l app ears in exactly 2 K − 2 κ − 1 blo c ks. Grouping co ordinates accordingly in (24) gives: E b t [ F ( w ( t +1) )] ≤ K K − 1 κ − κ K − 2 κ − 1 K K − 1 κ F ( w ( t ) ) + κ K − 2 κ − 1 K K − 1 κ h ( w ( t ) ) + ( ˜ z ( t ) − w ( t ) ) ∇ h ( w ( t ) ) + L max 2 k ˜ z ( t ) − w ( t ) k 2 + r ( ˜ z ( t ) ) , (25) where ˜ z ( t ) is defined as in (21). This is b ecause the blo ck b of ˜ z ( t ) is equal to z ( t ) b , as explained in Section B.1. W e now deal with the second term in (25). Let us consider the following function H : H ( w ( t ) , z ) = h ( w ( t ) ) + ( z − w ( t ) ) > ∇ h ( w ( t ) ) + L max 2 k z − w ( t ) k 2 + r ( z ) . By σ -strong conv exity of h , we hav e: H ( w ( t ) , z ) ≤ h ( z ) − σ 2 k z − w ( t ) k 2 + L max 2 k z − w ( t ) k 2 + r ( z ) = F ( z ) + 1 2 ( L max − σ ) k z − w ( t ) k 2 . (26) Note that H achiev es its minimum at ˜ z ( t ) defined in (21). If we minimize ov er z b oth sides of (26) we get H ( w ( t ) , ˜ z ( t ) ) = min z H ( w ( t ) , z ) ≤ min z F ( z ) + 1 2 ( L max − σ ) k z − w ( t ) k 2 . By σ -strong conv exity of F , 4 w e hav e for any w , w 0 and α ∈ [0 , 1]: F ( αw + (1 − α ) w 0 ) ≤ αF ( w ) + (1 − α ) F ( w 0 ) − σ α (1 − α ) 2 k w − w 0 k 2 . (27) Using the c hange of v ariable z = α w ∗ + (1 − α ) w ( t ) for α ∈ [0 , 1] and (27) w e obtain: H ( w ( t ) , ˜ z ( t ) ) ≤ min α ∈ [0 , 1] F αw ∗ + (1 − α ) w ( t ) + 1 2 ( L max − σ ) α 2 k w ∗ − w ( t ) k 2 ≤ min α ∈ [0 , 1] αF ( w ∗ ) + (1 − α ) F ( w ( t ) ) + 1 2 ( L max − σ ) α 2 − σ α (1 − α ) k w ∗ − w ( t ) k 2 (28) ≤ σ L max F ( w ∗ ) + 1 − σ L max F ( w ( t ) ) , (29) 4 F = h + r is σ -strongly conv ex since h is σ -strongly conv ex and r is conv ex. F ully Decen tralized Joint Learning where the last inequalit y is obtained by plugging the v alue α = σ /L max , whic h cancels the last term in (28). W e can now plug (29) in to (25) and subtract F ( w ∗ ) on b oth sides to get: E b t [ F ( w ( t +1) )] − F ( w ∗ ) ≤ K K − 1 κ − 2 K − 2 κ − 1 K K − 1 κ F ( w ( t ) ) + 2 K − 2 κ − 1 K K − 1 κ σ L max F ( w ∗ ) + 1 − σ L max F ( w ( t ) ) = 1 − 2 κσ K ( K − 1) L max ( F ( w ( t ) ) − F ( w ∗ )) , (30) where we used the fact that 2 ( K − 2 κ − 1 ) K ( K − 1 κ ) = 2 κ K ( K − 1) . W e conclude by taking the exp ectation of b oth sides with resp ect to the c hoice of previous blo c ks b 0 , . . . , b t − 1 follo wed by a recursive application of the resulting formula. C SMOOTHNESS AND STR ONG CONVEXITY OF GRAPH LEARNING F ORMULA TION W e derive the (blo c k) smo othness and strong conv exity parameters of the ob jective function h ( w ) when we use g ( w ) = λ k w k 2 − 1 > log( d ( w ) + δ ) . (31) Smo othness. A function f : X → R is L -smo oth w.r.t. the Euclidean norm if its gradient is L -Lipsc hitz, i.e. ∀ ( x, x 0 ) ∈ X 2 : k∇ f ( x ) − ∇ f ( x 0 ) k ≤ L k x − x 0 k . In our case, we need to analyze the smo othness of our ob jectiv e function h for each blo c k of co ordinates indexed b y ( k , K ). Therefore for an y ( w , w 0 ) ∈ R K ( K − 1) / 2 + whic h differ only in the ( k , K )-blo c k, we wan t to find L k, K suc h that: k [ ∇ h ( w )] k, K − [ ∇ h ( w 0 )] k, K k ≤ L k, K k w k, K − w 0 k, K k . Lemma 3. F or any blo ck ( k , K ) of size κ , we have L k, K ≤ µ 1 ( κ +1 δ 2 + 2 λ ) . Pr o of. Recall from the main text that the partial gradien t can b e written as follows: [ ∇ h ( w )] k, K = p k, K + ( µ 1 / 2)∆ k, K + µ 2 v k, K ( w ) , (32) where p k, K = ( c k L k ( α k ; S k ) + c l L l ( α l ; S l )) l ∈K , ∆ k, K = ( k α k − α l k 2 ) l ∈K and v k, K ( w ) = ( g 0 k ( d k ( w )) + g 0 l ( d l ( w )) + g 0 k,l ( w k,l )) l ∈K . In our case, g ( w ) is defined as in (31) so w e hav e v k, K = ( 1 d k ( w )+ δ + 1 d l ( w )+ δ + 2 λw k,l ) l ∈K . Note also that w e set µ 2 = µ 1 , as discussed in the main text. The first t wo terms do not depend on w k, K and can th us b e ignored. W e fo cus on the Lipschitz constant corresp onding to the third term. Let ( w , w 0 ) ∈ R K ( K − 1) / 2 + suc h that they only differ in the blo ck indexed by ( k , K ). W e denote the degree of an user k with resp ect to w and w 0 b y d k ( w ) = P j w k,j and d 0 k ( w ) = P j w 0 k,j resp ectiv ely . Denoting z k, K = ( 1 d k ( w )+ δ + 1 d l ( w )+ δ ) l ∈K , w e hav e: V alentina Zan tedeschi, Aur´ elien Bellet, Marc T ommasi k z k, K − z 0 k, K k = 1 d k ( w ) + δ + 1 d l ( w ) + δ l ∈K − 1 d 0 k ( w ) + δ + 1 d 0 l ( w ) + δ l ∈K = d 0 k ( w ) + δ − d k ( w ) − δ ( d k ( w ) + δ )( d 0 k ( w ) + δ ) + d 0 l ( w ) + δ − d l ( w ) − δ ( d l ( w ) + δ )( d 0 l ( w ) + δ ) l ∈K ≤ 1 δ 2 X j ∈K ( w 0 k,j − w k,j ) l ∈K + w 0 k,l − w k,l l ∈K (33) ≤ 1 δ 2 h k w 0 k, K k 1 − k w k, K k 1 l ∈K + k w k, K − w 0 k, K k i ≤ 1 δ 2 h k w 0 k, K − w k, K k 1 l ∈K + k w k, K − w 0 k, K k i (34) ≤ 1 δ 2 h √ κ X j ∈K ( w 0 k,j − w k,j ) + k w k, K − w 0 k, K k i (35) ≤ 1 δ 2 h √ κ k w k, K − w 0 k, K k 1 + k w k, K − w 0 k, K k i (36) ≤ κ + 1 δ 2 k w k, K − w 0 k, K k , where to obtain (33) w e used the nonnegativit y of the weigh ts and the fact that w and w 0 only differ in the co ordinates indexed by ( k , K ), and (34)-(35)-(36) by classic prop erties of norms. W e conclude by combining this result with the quan tity 2 λ that comes from the last term in v k, K and multiplying b y µ 1 . Observ e that L k, K only depends on the blo ck size κ (not the block itself ). Hence w e also ha ve L max ≤ µ 1 ( κ +1 δ 2 + 2 λ ). It is imp ortan t to note that the linear dep endency of L k, K in the blo c k size κ , whic h is the w orst possible dep endency for blo c k Lipschitz constants (W righ t, 2015), is tight for our ob jective function. This is due to the log-degree term w hic h makes each entry of [ ∇ h ( w )] k, K dep enden t on the sum of all co ordinates in w k, K . This linear dep endency explains the mild effect of the blo c k size κ on the con vergence rate of our algorithm (see the discussion of Section D.2 and the n umerical results of App endix E.2). Strong conv exit y . It is easy to see that the ob jective function h is σ -strongly conv ex with σ = 2 µ 1 λ . D COMMUNICA TION AND MEMOR Y In this section we provide additional details on the communication and memory costs of the prop osed metho d. The section is organized in tw o parts corresp onding to the decentralized b o osting algorithm of Section 4 and the graph learning algorithm of Section 5. D.1 Learning Mo dels: A Logarithmic Communication and Memory Cost W e prov e that our F rank-W olfe algorithm of Section 4 enjoys logarithmic comm unication and memory costs with resp ect to the num b er of base predictors n . Combined with the approach for building sparse collab oration graphs w e introduce in Section 5, we obtain a scalable-by-design algorithm. The follo wing analysis stands for systems without failure (all sent messages are correctly received). W e express all costs in num b er of bits, and Z denotes the bit length used to represent floats. Assume we are given a collab oration graph G = ([ K ] , E , w ) with K no des and M edges. Recall that the algorithm pro ceeds as follows. At each time step t , a random user k w akes up and p erforms the follo wing actions: 1. Up date step: user k p erforms a F rank-W olfe up date on its lo cal mo del based on the most recent information α ( t − 1) l receiv ed from its neighbors l ∈ N k : α ( t ) k = (1 − γ ( t ) ) α ( t − 1) k + γ ( t ) s ( t ) k , with γ ( t ) = 2 K/ ( t + 2 K ) . F ully Decen tralized Joint Learning 2. Communic ation step: user k sends its up dated mo del α ( t ) k to its neigh b orho od N k . Memory . Eac h user needs to store its current mo del, a copy of its neighbors’ mo dels, and the similarit y weigh ts asso ciated with its neighbors. Denoting by | N k | the n umber of neighbors of user k , its memory cost is given by Z ( n + | N k | ( n + 1)), which leads to a total cost for the netw ork of K Z n + P K k =1 | N k | ( n + 1) = Z ( K n + 2 M ( n + 1)) . The total memory is thus linear in M , K and n . Thanks to the sparsit y of the up dates, the dep endency on n can b e reduced from linear to logarithmic b y representing mo dels as sparse vectors. Specifically , when initializing the mo dels to zero vectors, the mo del of an user k who has p erformed t k up dates so far contains at most t k nonzero elemen ts and can b e represented using t k ( Z + log n ) bits: t k Z for the nonzero v alues and t k log n for their indices. Comm unication. A t each iteration, an user k up dates a single co ordinate of its mo del α k . Hence, it is enough to send to the neighbors the index of the mo dified co ordinate and its new v alue (or the index and the step size γ ( t ) k ). Therefore, the communication cost of a single iteration is equal to ( Z + log n ) | N k | . After T iterations, the exp ected total communication cost for our approach is T ( Z + log n ) E k ∼U ( 1 ,K ) [ | N k | ] = 2 T M K − 1 ( Z + log n ) . Com bining this with Theorem 1, the total communication cost needed to obtain an optimization error smaller than ε amoun ts to 12 M ( C ⊗ f + h 0 ) ε Z + log n , hence logarithmic in n . F or the classic case where the set of base predictors consists of a constan t n umber of simple decisions stumps p er feature, this translates into a logarithmic cost in the dimensionality of the data (see the exp erimen ts of Section 6). This can b e m uch smaller than the cost needed to send all the data to a central serv er. D.2 Learning the Collab oration Graph: Communication vs. Conv ergence Recall that the algorithm of Section 5 learns in a fully decentralized wa y a collab oration graph giv en fixed mo dels α . It is defined by: 1. Draw a set K of κ users and request their current mo dels and degree. 2. Up date the asso ciated weigh ts: w ( t +1) k, K ← max 0 , w ( t ) k, K − (1 /L k, K )[ ∇ h ( w ( t ) )] k, K , 3. Send each up dated w eight w ( t +1) k,l to the asso ciated user in l ∈ K . A t each iteration, the active user needs to request from each user l ∈ K its current degree d l ( w ), its p ersonal mo del α ( t α ) l and the v alue of its lo cal loss, where t α is the total num b er of FW mo del up dates done so far in the netw ork. It then sends the up dated weigh t to each user in K . As the exp ected n umber of nonzero en tries in the mo del of an user is at most min ( t α /K, n ), the exp ected communication cost for a single iteration is equal to κ (3 Z + min( t α K , n )( Z + log n )), where Z is the representation length of a float. This can b e further optimized if users hav e enough lo cal memory to store the mo dels and lo cal losses of all the users they communicate with (see Section D.2.1 b elow). In general, Theorem 2 sho ws that the parameter κ can b e used to trade-off the conv ergence sp eed and the amount of communication needed at each iteration, esp ecially when the num b er of users K is large. F or the particular case of g ( w ) = λ k w k 2 − 1 > log ( d ( w ) + δ ) that w e prop ose, w e hav e σ = 2 µλ and L max ≤ µ ( κ +1 δ 2 + 2 λ ) (see Section C). This giv es the following shrinking factor in the conv ergence rate of Theorem 2: ρ ≤ 1 − 4 K ( K − 1) κλδ 2 κ + 1 + 2 λδ 2 . Hence, while increasing κ results in a linear increase in the p er-iteration communication cost (as well as in the n umber of users to communicate with), the impact on ρ in Theorem 2 is mild and fades rather quic kly due to the (tigh t) linear dep endence of L k, K in κ . This suggests that choosing κ = 1 will minimize the total commun ication cost needed to reach solutions of mo derate precision (which is usually sufficient for machine learning). Slightly V alentina Zan tedeschi, Aur´ elien Bellet, Marc T ommasi larger v alues (but still muc h smaller than K ) will provide a b etter balance b etw een the comm unication cost and the n umber of rounds. On the other hand, if high precision solutions are needed or if the n umber of communication rounds is the primary concern, large v alues of κ could b e used. As shown in Section E.2, the numerical b ehavior of our algorithm is in line with this theoretical analysis. D.2.1 Refined communication complexity analysis The communication complexity of our decentralized graph learning algorithm can b e reduced if the users store the mo dels and lo cal losses of all the p eers they communicate with. The communication complexity for a given iteration t then dep ends on the exp ected num b er of no des ¯ κ ( t ) , among the selected K , that the pick ed user has not y et selected: κ 2 Z + ¯ κ ( t ) Z + min t α K , n ( Z + log n )) . The next lemma sho ws that ¯ κ ( t ) decreases exp onen tially fast with the n umber of iterations. Prop osition 1. F or any T ≥ 1 , the exp e cte d numb er of new no des after T iter ations is given by ¯ κ ( T ) = κ 1 − κ K ( K − 1) T − 1 . Pr o of. A t a giv en iteration t , let k ( t ) denote the random user that p erforms the up date and K ( t ) the set of κ users selected b y k ( t ) . W e denote by X ( t ) l,m the random v ariable indicating if no de l selected no de m at that iteration: X ( t ) l,m = ( 0 if no de m was not selected by no de l at iteration t, 1 otherwise. Similarly , X l,m indicates if no de l has ever selected no de m after T iterations. Let us denote by R ( t ) = { X k ( t ) ,j } j ∈K ( t ) the set of random v ariables that hav e to b e up dated at iteration t . The probabilit y that no de m is not selected b y no de l at a given round t is given by P [ X ( t ) l,m = 0] = P [ k ( t ) = l ] P [ X k ( t ) ,m / ∈ R ( t ) | k ( t ) = l ] + P [ k ( t ) 6 = l ] P [ X k ( t ) ,m / ∈ R ( t ) | k ( t ) 6 = l ] = 1 K 1 − κ K − 1 + K − 1 K 1 = K 2 − K − κ K ( K − 1) = 1 − κ K ( K − 1) . As k and K are dra wn indep enden tly from the previous dra ws, the probabilit y that no de m has nev er b een selected b y no de l after T iterations is given by: P [ X l,m = 0] = T − 1 Y t =0 P [ X ( t ) l,m = 0] = 1 − κ K ( K − 1) T . Finally , the exp ected num b er of new no des seen at iteration T is given by ¯ κ ( T ) = E k, K [ |{ X k,l ∈ R ( T ) | X k,l = 0 }| ] = 1 K K X k =1 1 K − 1 κ X K X m ∈K P [ X l,m = 0] = κ 1 − κ K ( K − 1) T − 1 . F ully Decen tralized Joint Learning E ADDITIONAL EXPERIMENTS E.1 Details on Exp erimen tal Setting Hyp erparameter tuning. W e tune the following h yp er-parameters with 3-fold cross v alidation on the training user datasets: β ∈ { 1 , . . . , 10 3 } ( l 1 constrain t for all Adab o ost-based metho ds), µ ∈ { 10 − 3 , . . . , 10 3 } (trade-off parameter for Dada and P erso-lin), and λ ∈ { 10 − 3 , . . . , 10 3 } (graph sparsit y in Dada-Learned and P erso-lin- Learned). Description of Moons dataset. W e describ e here in more details the generation of the synthetic problem Moons used in the main text, which is constructed from the classic tw o in terleaving Mo ons dataset which has nonlinear class b oundaries. W e consider K = 100 users, clustered in 4 groups of resp ectiv ely K c 1 = 10, K c 2 = 20, K c 3 = 30 and K c 4 = 40 users. Each cluster is asso ciated with a rotation angle Θ c of 45, 135, 225 and 315 degrees resp ectiv ely . W e generate a lo cal dataset for each user k b y drawing m k ∼ U (3 , 15) training examples and 100 test examples from the tw o Mo ons distribution. W e then apply a rotation (coplanar to the Mo ons’ distribution) to all the p oin ts according to an angle θ k ∼ N (Θ c , 5) where c is the cluster the user b elongs to. This construction allo ws us to con trol the similarity b et ween users (users from the same cluster are more similar to each other than to those from different clusters). W e build an oracle collab oration graph by setting w k,l = exp ( cos( θ k − θ l ) − 1 σ ) with σ = 0 . 1 and dropping all edges with negligible weigh ts, which w e will give as input to Dada-Oracle and P erso-lin-Oracle. In order to make the classification problems more challenging, we add random lab el noise to the generated lo cal samples b y flipping the lab els of 5% of the training data, and embed all p oin ts in R D space by adding random v alues for the D − 2 empt y axes, similar to (V anhaesebrouck et al., 2017). In the exp erimen ts, we set D = 20. Description of the real datasets. W e give details on datasets used in the main text: • Har ws (Human Activity Recognition With Smartphones) (Anguita et al., 2013), which is comp osed of records of v arious types of physical activities, describ ed by D = 561 features and collected from K = 30 users. W e fo cus on the task of distinguishing when a user is sitting or not, use 20% of the records for training and set the n umber of stumps for the b o osting-based metho ds to n = 1122. • Vehicle Sensor (Duarte and Hu, 2004) con tains data from K = 23 sensors describing vehicles driving on a road, where each record is describ ed by D = 100 features. W e predict b et ween AA V and DW vehicles, using 20% of the records for training, and fix the num b er of stumps to n = 1000. • Computer Buyers 5 consists of K = 190 buyers, who ha ve each ev aluated m k = 20 computers describ ed by D = 14 attributes, with an ov erall score within the range [0 , 10]. W e use a total of 1407 (b et ween 5 and 10 p er user) instances for training and 2393 (b et w een 10 and 15 p er user) for testing. W e tac kle the problem as binary classification, by affecting all instances with a score ab o ve 5 to the p ositiv e class and the remaining ones to the negativ e class, and we set the num b er of stumps to n = 28. • School (Goldstein, 1991) 6 consists of m = 15362 total student examination records describ ed by D = 17 features, with an ov erall score in the range [0 , 70] from K = 140 secondary schools. In total, there are 11471 instances (b et ween 16 and 188 p er user) for training and 3889 (b etw een 5 and 63 p er user) for testing. W e predict b et w een records with scores smaller or greater than 20 and set the num b er of stumps to n = 34. E.2 Effect of the Blo c k Size κ As discussed in Section D.2, the parameter κ allo ws to trade-off the communication cost (in bits as w ell as the num b er of pairwise connections at each iteration) and the conv ergence rate for the graph learning steps of Dada-Learned. W e study the effect of v arying κ on our synthetic dataset Moons . Figure 3 sho ws the evolution of the ob jective function with the num b er of iterations and with the communication cost dep ending on κ when learning a graph using the lo cal classifiers learned with Lo cal-b oost. Notice that the n umerical b ehavior is consisten t with the theory: while increasing κ reduces the num b er of communication rounds, setting κ = 1 5 https://github.com/probml/pmtkdata/tree/master/conjointAnalysisComputerBuyers 6 https://github.com/tjanez/PyMTL/tree/master/data/school V alentina Zan tedeschi, Aur´ elien Bellet, Marc T ommasi 0.0 0.2 0.4 0.6 0.8 1.0 nb iterations 1e6 6 5 4 3 2 1 0 1 obj function 1e4 kappa = 1 kappa = 5 kappa = 10 kappa = 30 kappa = 50 kappa = 99 0 1 2 3 4 5 6 7 8 communication 1e6 6 5 4 3 2 1 0 1 obj function 1e4 kappa = 1 kappa = 5 kappa = 10 kappa = 30 kappa = 50 kappa = 99 Figure 3: Impact of κ on the conv ergence rate and the c omm unication cost for learning the graph on Moons . 4 6 8 10 12 14 nb t raini ng p oin ts 0.4 0.5 0.6 0.7 0.8 0.9 1.0 test a ccur acies Loca l-boost Dada- Learne d Dada- Oracle (a) Moons . 4 6 8 10 12 nb training points 0.4 0.5 0.6 0.7 0.8 0.9 1.0 test accuracies Local-boost Dada-Learned (b) Har ws . Figure 4: Average test accuracies with resp ect to the num b er of training p oin ts of the lo cal sets. minimizes the total amount of communication (ab out 5 × 10 5 bits). By wa y of comparison, the communication cost required to send all weigh ts to all users just once is Z K 2 ( K − 1) / 2 = 1 . 6 × 10 7 bits. In practice, mo derate v alues of κ can b e used to obtain a go o d trade-off b et ween the num b er of rounds and the total communication cost, and to reduce the higher v ariance asso ciated with small v alues of κ . E.3 T est Accuracy with resp ect to Lo cal Dataset Size In the main text, the rep orted accuracies are a veraged ov er users. Here, we study the relation b et ween the lo cal test accuracy of users dep ending on the size of their training set. Figure 4 shows a comparison b etw een Dada-Oracle, Dada-Learned and Lo cal-bo ost, in order to assess the improv ements introduced by our collab orativ e sc heme. On Moons , Lo cal-bo ost shows go o d p erformance on users with larger training sets but generalizes p o orly on users with limited lo cal information. Both Dada-Oracle and Dada-Learned outp erform Lo cal-bo ost, esp ecially on users with small datasets. Remark ably , in the ideal setting where we hav e access to the ground-truth graph (Dada-Oracle), we are able to fully close the accuracy gaps caused by unev en training set sizes. Dada-Learned is able to match this p erformance except on users with smaller datasets, whic h is exp ected since there is very limited information av ailable to learn reliable similarity weigh ts for these users. On Har ws , Dada-Learned generally impro ves up on Lo cal-bo ost, although there is more v ariabilit y due to difference in difficult y across user tasks and unev en num b ers of users in each size group. E.4 T est Accuracy with resp ect to Comm unication Cost W e rep ort the full study of the test accuracies under limited communication budget, summarized in T able 2 of the main text. Figure 5 confirms that Dada-Learned generally allo ws for reaching higher test accuracies with less F ully Decen tralized Joint Learning 1 0 5 1 0 6 1 0 7 1 0 8 communication cost 75 80 85 90 95 100 test accuracy Perso-lin-Learned Dada-Learned Local-boost (a) Har ws ( D = 561). 1 0 5 1 0 6 1 0 7 communication cost 75 80 85 90 test accuracy Perso-lin-Learned Dada-Learned Local-boost (b) Vehicle Sensor ( D = 100). 1 0 5 1 0 6 communication cost 50 55 60 65 70 75 test accuracy Perso-lin-Learned Dada-Learned Local-boost (c) Computer Buyers ( D = 14). 1 0 5 1 0 6 communication cost 66 68 70 72 74 test accuracy Perso-lin-Learned Dada-Learned Local-boost (d) Schools ( D = 17). Figure 5: Average test accuracies with resp ect to the communication cost (# bits). comm unications than P erso-lin-Learned, esp ecially on higher-dimensional datasets, such as Har ws (Figure 5(a)). E.5 Standard Deviat ions due to Random Sampling W e rep ort the means and standard deviations of the test accuracies across 3 random runs to sho w how the randomness of the user selection in the decentralized algorithms (Perso-linear-Learned and Dada-Learned) affects the results. Notice that, b ecause global and lo cal metho ds are deterministic, their standard deviations are zero. E.6 Additional Syn thetic Dataset: Mo ons100 W e rep ort the exp eriments carried out on a synthetic dataset referred to as Moons100 , which is also based on the tw o interlea ving Mo ons dataset but with a different ground-truth task similarity structure. W e consider a set of K = 100 users, eac h asso ciated with a p ersonal rotation axis drawn from a normal distribution. W e generate T able 3: T est accuracy (%) on real datasets. Best results in b oldface and second b est in italic. D A T ASET HAR WS VEHICLE COMPUTER SCHOOL Global-linear 93.64 87.11 62.18 57.06 Local-linear 92.69 90.38 60.68 70.43 Perso-linear-Learned 96.87 ± 0.97 91.45 ± 0.16 69.10 ± 0.05 71.78 ± 0.42 Global-Adabo ost 94.34 88.02 69.16 69.96 Local-Adab o ost 93.16 90.59 66.61 70.69 Dada-Learned 95.57 ± 0.21 91.04 ± 0.70 73.55 ± 0.28 72.47 ± 0.81 V alentina Zan tedeschi, Aur´ elien Bellet, Marc T ommasi 0 2000 4000 6000 8000 10000 12000 14000 nb iterations 60 65 70 75 80 85 90 95 100 train accuracy 0 2000 4000 6000 8000 10000 12000 14000 nb iterations 60 65 70 75 80 85 90 95 100 test accuracy Global-lin Global-boost Local-lin Local-boost Perso-lin-Oracle Dada-Oracle Dada-Learned Figure 6: T raining and test accuracy w.r.t. num b er of iterations on Moons100 . Dada-L ear ned Oracl e (a) Illustration of the learned and oracle graphs. 0 100 200 300 400 500 600 700 800 900 lamb da 0 20 40 60 80 100 Dada- Learne d Oracle avera ge nb nei ghbors 20 40 60 80 avera ge nb nei ghbors 0.76 0.78 0.80 0.82 0.84 0.86 0.88 0.90 test a ccur acy Loca l-boost Dada- Learne d (b) Impact of λ on the sparsity of the learned graph and the test accuracy . Figure 7: Graph visualization and study of the impact of graph sparsity on Moons100 . the lo cal datasets by dra wing a random n umber of p oin ts from the tw o Mo ons distribution: uniformly b etw een 3 and 20 for training and 100 for testing. W e then apply the random rotation of the user to all its p oin ts. W e further add random lab el noise by flipping the lab els of 5% of the training data and embed all the p oin ts in R D space by adding random v alues for the D − 2 empty axes. In the exp erimen ts, the num b er of dimensions D is fixed to 20 and the num b er of base functions n to 200. F or Dada-Learned, the graph is up dated after every 200 iterations of optimizing α . W e build an oracle collab oration graph where the w eights b et ween users are computed from the angle θ ij b et w een the users’ rotation axes, using w i,j = exp ( cos( θ ij ) − 1 σ ) with σ = 0 . 1. W e drop all edges with negligible w eights. Figure 6 sho ws the ev olution of the training and test accuracy o ver the iterations for the v arious approac hes defined in the main text. The results are consistent with those presented for Moons100 in the main text. They clearly sho w the gain in accuracy provided b y our metho d:Dada-Oracle and Dada-Learned are successful in reducing the o verfitting of Lo cal-bo ost, and allo w higher test accuracy than b oth Global-b oost and Perso-lin. Again, we see that our strategy to learn the collab oration graph can effectively make up for the absence of knowledge ab out the ground-truth similarities b et w een users. A t con vergence, the learned graph has an a verage num b er of neighbors p er no de E k [ | N k | ] = 42 . 64, resulting in a communication complexity for up dating the classifiers smaller than the one of the ground-truth graph, which has E k [ | N k | ] = 60 . 86 (see Figure 7). W e can mak e the graph even more sparse (hence reducing the communication complexity of Dada) by setting the hyper-parameter λ to smaller v alues. Of course, learning a sparser graph can also a negative impact on the accuracy of the learned mo dels. In Figure 7(b), we show this trade-off b et ween the sparsity of the graph and the test accuracy of the mo dels for the Moons100 problem. As exp ected, as λ → 0 the graph b ecomes sparser and the test accuracy tends to the p erformance of Lo cal-bo ost. Con versely , larger v alues of λ induce denser graphs, sometimes resulting in b etter accuracies but at the cost of higher communication complexit y .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment