Learning How to Autonomously Race a Car: a Predictive Control Approach
In this paper we present a Learning Model Predictive Controller (LMPC) for autonomous racing. We model the autonomous racing problem as a minimum time iterative control task, where an iteration corresponds to a lap. In the proposed approach at each l…
Authors: Ugo Rosolia, Francesco Borrelli
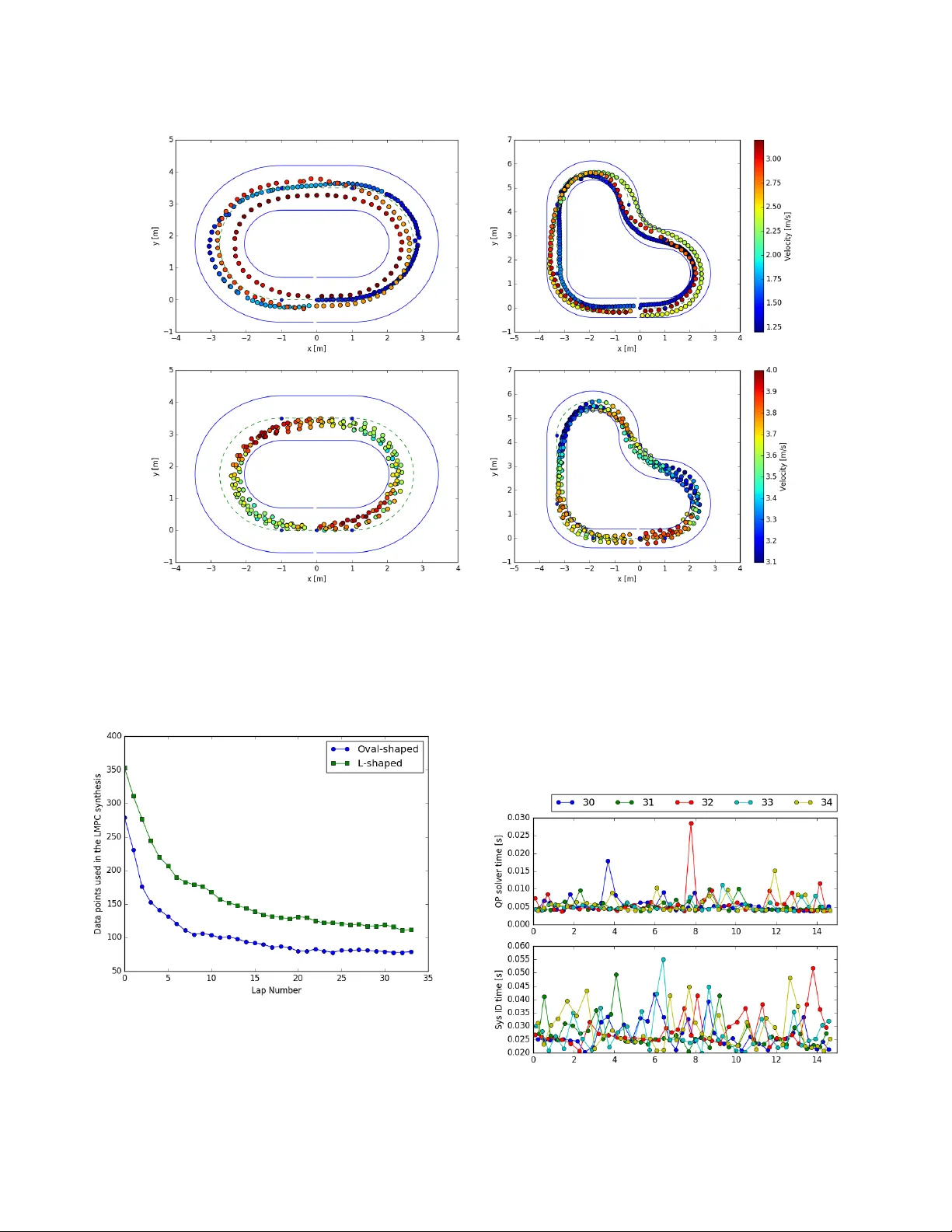
Lear ning How to A utonomously Race a Car: a Pr edictiv e Contr ol A ppr oach Ugo Rosolia and Francesco Borrelli Abstract —In this paper we present a Learning Model Pre- dictive Controller (LMPC) for autonomous racing. W e model the autonomous racing problem as a minimum time iterative control task, where an iteration corr esponds to a lap. The system trajectory and input sequence of each lap are stored and used to systematically update the contr oller for the next lap. In the proposed approach the race time does not increase at each iteration. The first contribution of the paper is to propose a local LMPC which reduces the computational burden associated with existing LMPC strategies. In particular , we show how to construct a local safe set and approximation to the value function, using a subset of the stored data. The second contribution is to present a system identification strategy for the autonomous racing iterative control task. W e use data from previous iterations and the vehicle’s kinematic equations of motion to build an affine time-varying prediction model. The effectiveness of the proposed strategy is demonstrated by experimental results on the Berkeley A utonomous Race Car (BARC) platform. I . I N T R O D U C T I O N Autonomous driving is an active research field. Over the past decades several techniques hav e been proposed for differ - ent driving scenarios [1]–[9]. Depending on the control task (i.e. highway driving, urban driving, emergenc y maneuvers) the behavior of the vehicle can be modelled with linear or nonlinear equations of motions [10], [11]. When the nonlin- earities of the vehicle are excited the control task is inevitably more challenging. In this work we are interested in designing a controller for autonomous racing which can operate the vehicle in the nonlinear regime, close to the limit of the vehicle’ s handling capability . W e formulate the autonomous racing problem as an iterativ e control task, where at each iteration the controller driv es the vehicle around the track trying to minimize the lap time. Recently se veral approaches have been proposed for au- tonomous racing. In [12] the authors reformulated the au- tonomous racing control task as a non-con vex optimization problem and then proposed a linearization strategy to compute an approximate solution. The authors in [13] proposed a Nonlinear Model Predictiv e Control (NMPC) strategy which exploits a Pacejka tire model identified form experimental data. The NMPC is implemented on an experimental set- up using an exact Hessian SQP-type optimization algorithm. NMPC strategies for autonomous racing are tested also in [14], where the authors compared two control methodologies based on dif ferent parametrizations of the vehicle’ s model. In [15] the authors compared two approaches, the first one based on a tracking MPC and the second one based on a MPC formulated in a space dependent frame. A Model Predictive U. Rosolia and F . Borrelli are with the Department of Mechanical Engi- neering, Uni versity of California at Berkele y , Berkeley , CA 94701, USA { ugo.rosolia, fborrelli } @berkeley.edu Contouring Control (MPCC) was presented in [16]. In MPCC the controller objectiv e is a trade-off between the progress along the track and the contouring error . First, an high lev el MPC computes the optimal racing trajectory . Afterward, a lo w lev el controller is used to track the optimal racing line. This strategy is extended in [17] to design a racing controller which guarantees recursiv e constraint satisfaction. Also in [18] the control problem is divided in two steps. First, a reference trajectory is computed using the method proposed in [19]. Afterwards, an iterativ e learning control (ILC) approach is used for tracking. The authors showed the effecti veness of the proposed approach by experimental testing on a full size vehicle. W e proposed to reformulate the autonomous racing problem as an iterati ve control task. The controller is not based on a precomputed racing line and it learns from experience a trajectory which minimizes the lap time. In particular, the closed-loop trajectories at each lap are stored and used to systematically update the controller for the ne xt lap. This paper builds on [20]–[22] and has two main contributions. The first contribution is to propose a local LMPC strat- egy where the terminal cost and constraint are updated at each time step. In particular at each time t , we exploit the planned trajectory at time t − 1 to construct a local terminal cost and constraint. Con versely to our pre vious works [20]– [22], the terminal cost and constraint are computed using a subset of the stored data, therefore the proposed local LMPC enables the reduction of computational burden associated with existing LMPC strategies. The effecti veness of the proposed approach is demonstrated on the Berkeley Autonomous Race Car (BARC) 1 platform. W e show that the proposed controller is able to improv e the lap time, until it con verges to a steady state behavior . Finally , we analyze the lateral acceleration acting on the closed-loop system and we confirm that the controller learns to drive the vehicle at the limit of its handling capability . The second contribution of this work is to propose a system identification strategy tailored to the autonomous racing appli- cation. W e propose to exploit both the kinematic equations of motion and data from pre vious iterations to identify an Affine T ime V arying (A TV) prediction model used for control. In particular, we use a local linear regressor to learn the relationships between the inputs and the vehicle’ s velocities. Furthermore, we linearize the kinematic equations of motion to approximate the ev olution of the vehicle’ s position as a function of the velocities. Conv ersely to our previous works [20], [21], this strategy allow us to reformulate the LMPC as a Quadratic Program (QP) which can be solved efficiently . This paper is or ganized as follows: in Section II we intro- 1 A video of the e xperiment can be found at https://youtu.be/ZBFJWtIbtMo duce the problem formulation. Section III illustrates the LMPC design. In particular, it shows how to construct local safe sets and value function approximations using a subset of the collected data. Section IV illustrates the system identification strategy used in the experiments. Finally , in Section V we present the experimental results on the Berkele y Autonomous Race Car (B ARC) platform. Section VIII provides final re- marks. I I . P R O B L E M F O R M U L AT I O N Consider the following state and input v ectors x = v x , v y , w z , e ψ , s, e y > and u = δ, a > , where w z , v x , v y , are the vehicle’ s yaw rate, longitudinal and lateral velocities. The position of the vehicle is represented in the curvilinear reference frame [23], where s is the distance trav elled along the centerline of the track. The states e ψ and e y are the heading angle and lateral distance error between the vehicle and the centerline of the track, as shown in Figure 1. Finally , δ and a are the steering and acceleration commands. The vehicle is described by the dynamic bicycle model x t +1 = f ( x t , u t ) , (1) where f ( · , · ) is deri ved from kinematics and balancing the forces acting on the tires [10]. A detailed expression can be found in [10, Chapter 2]. Note that in the curvilinear reference frame state and input constraints are conv ex, i.e. x t ∈ X = { x ∈ R n : F x x ≤ b x } , u t ∈ U = { u ∈ R d : F u u ≤ b u } , ∀ t ≥ 0 . e y s distance trav ell ed along the path path’s origin Fig. 1. Representation of the vehicle’ s position in the curvilinear reference frame. The goal of the controller is to driv e the system from the starting point x S to the terminal set X F . More formally , the controller aims to solve the follo wing minimum time optimal control problem min T ,u 0 ,...,u T − 1 T − 1 X t =0 1 s.t. x t +1 = f ( x t , u t ) , ∀ t = [0 , . . . , T − 1] x t ∈ X , u t ∈ U , ∀ t = [0 , . . . , T ] x T = X F , x 0 = x S , (2) where for a track of length L the terminal set X F = { x ∈ R n : [0 0 0 0 1 0] x = s ≥ L } (3) represents the states beyond the finish line. I I I . C O N T R O L L E R D E S I G N In this section, we first sho w how to use historical data to construct a terminal constraint set and terminal cost function. Afterwards, we exploit these quantities to design the controller . A. Stor ed Data As stated in the introduction, we define one iteration as a successful lap around the race track and we store the closed- loop trajectories. In particular, at the j th iteration we define the vectors u j = [ u j 0 , . . . , u j T j ] x j = [ x j 0 , . . . , x j T j ] , (4) which collect the ev olution of closed-loop system and associ- ated input sequence. In the abov e definitions, T j denotes the time at which the closed-loop system reached the terminal set, i.e. x T j ∈ X F . B. Local Con vex Safe Set In this section, we define the local con ve x safe set. Dif- ferently from our previous works [20]–[22], this quantity is constructed using a subset of the stored data points. In particular , the local con ve x safe set around x is defined as the con vex hull of the K -nearest neighbors to x . First, for the j th trajectory we define the set of time indices [ t j, ∗ 1 , . . . , t j, ∗ K ] associated with the K -nearest neighbors to the point x , [ t j, ∗ 1 , . . . , t j, ∗ K ] = argmin t 1 ,...,t K K X i =1 || x j t i − x || 2 D s.t. t i 6 = t k , ∀ i 6 = k t i ∈ { 0 , . . . , T j } , ∀ i ∈ { 1 , . . . , K } . (5) In the above definition || y || 2 D = y > D > D y for the user-defined matrix D , which may be chosen to take into account the relativ e scaling or relev ance of dif ferent variables. W e chose D = diag (0 , 0 , 0 , 0 , 1 , 0) to select the K -nearest neighbors with respect to the curvilinear abscissa s , which represents a proxy for the distance between two stored data points of the same lap. Furthermore, as the vehicle mov es forward on the track, at each lap the stored data are ordered with respect to the trav elled distance s and the computation of (5) is simplified. The K -nearest neighbors to x from the l th to the j th iteration are collected in the following matrix D j l ( x ) = [ x l t l, ∗ 1 , . . . , x l t l, ∗ K , . . . , x j t j, ∗ 1 , . . . , x j t j, ∗ K ] , which is used to define the local conv ex safe set around x C L j l ( x ) = { ¯ x ∈ R n : ∃ λ ∈ R K ( j − l +1) , λ ≥ 0 , 1 λ = 1 , D j l ( x ) λ = ¯ x } . (6) Notice that the above local con ve x safe set C L j l ( x ) represents the con ve x hull of the K -nearest neighbors to x from the l th to j th iteration. Finally , we define the matrix S j l ( x ) = [ x l t l, ∗ 1 +1 , . . . , x l t l, ∗ K +1 , . . . , x j t j, ∗ 1 +1 , . . . , x j t j, ∗ K +1 ] which collects the ev olution of the states stored in the columns of the matrix D j l ( x ) . The above matrix S j l ( x ) will be used in Section III-D to construct the local con vex safe set at each time step. C. Local Con vex Q-function In this section, we exploit the stored data to construct an approximation to the cost-to-go over the local con ve x safe set C L j l ( x ) around x . In particular , we define the local conv ex Q -function around x as the con vex combination of the cost associated with the stored trajectories, Q j l ( ¯ x, x ) = min λ J j l ( x ) λ s.t λ ≥ 0 , 1 λ = 1 , D j l ( x ) λ = ¯ x, (7) where λ ∈ R k ( j − l ) , 1 is a row vector of ones and the row vector J j l ( x ) = [ J l t l, ∗ 1 → T l ( x l t l, ∗ 1 ) , . . . , J l t l, ∗ M → T l ( x l t l, ∗ M ) , . . . , J j t j, ∗ 1 → T j ( x j t j, ∗ 1 ) , . . . , J j t j, ∗ M → T j ( x j t j, ∗ M )] , collects the cost-to-go associated with the K -nearest neighbors to x from the l th the j th iteration. The cost-to-go J j t → T j ( x j t ) = T j − t represents the time to driv e the vehicle from x j t to the finish line along the j th trajectory . W e underline that the cost- to-go is computed after completion of the j th iteration. D. Local LMPC Design The local con vex safe set and the local conv ex Q -function are used to design the controller . At each time t of the j th iteration the controller solves the following finite time optimal control problem J LMPC ,j t → t + N ( x j t , z j t ) = min U j t , λ j t t + N − 1 X k = t h ( x j k | t ) + J j − 1 l ( z j t ) λ j t (8a) s.t. x j t | t = x j t , (8b) λ j t ≥ 0 , 1 λ j t = 1 , D j − 1 l ( z j t ) λ j t = x j t + N | t (8c) x j k +1 | t = A j k | t x j k | t + B j k | t u j k | t + C j k | t , (8d) x j k | t ∈ X , u j k | t ∈ U , (8e) ∀ k = t, · · · , t + N − 1 , where U j t = [ u j t | t , . . . , u j t + N − 1 | t ] ∈ R d × N , λ j t ∈ R ( j − l +1) K and the stage cost in (8a) h ( x ) = ( 1 If x / ∈ X F 0 Else . In the abov e finite time optimal control problem equations (8b), (8d) and (8e) represent the dynamic update, state and input constraints. Finally , (8c) enforces x j t + N | t into the local con vex safe set defined in Section III-B. The optimal solution to (8) at time t of the j th iteration λ j, ∗ t , [ x j, ∗ t | t , . . . , x j, ∗ t + N | t ] and U j, ∗ t = [ u j, ∗ t | t , . . . , u j, ∗ t + N − 1 | t ] (9) is used to compute the following vector z j t = ( x j − 1 N If t = 0 S j l ( z j t − 1 ) λ j, ∗ t − 1 Otherwise , (10) which at time t defines the local con ve x safe set LS j l ( z j t ) and local Q -function Q j l ( x, z j t ) in (8). The above vector z j t represents a candidate terminal state for the planned trajectory of the LMPC at time t . First, we initialize the candidate terminal state z j 0 using the ( j − 1) th trajectory . Afterwards, we update the vector z j t as the conv ex combination of the columns of the matrix S j l ( z j t ) from Section III-B. Notice that if the systems is linear or if a linearized system approximates the nonlinear dynamics over the local conv ex safe set, then there exists a feasible input which driv es the system from x j, ∗ t + N | t = D j − 1 t ( z j t ) λ j, ∗ t to z j t +1 = S j − 1 l ( z j t ) λ j, ∗ t . Finally , we apply to the system (1) the first element of the optimizer vector , u j t = u j, ∗ t | t . (11) The finite time optimal control problem (8) is repeated at time t + 1 , based on the ne w state x t +1 | t +1 = x j t +1 . I V . S Y S T E M I D E N T I FI C ATI O N S T R A T E G Y In this section, we illustrate the system identification strat- egy used to build an Affine Time V arying (A TV) model which approximates the vehicle dynamics. First, we introduce the kinematic equations of motion which describe the evolution of the v ehicle’ s position as a function of the velocities. Afterwards, we present the strategy used to approximate the dynamic equations of motion, which model the ev olution of the vehicle’ s velocities as a function of the input commands. Finally , we describe the A TV model, which is computed online linearizing the kinematic equations of motion and ev aluating the approximate dynamic equations of motion along the shifted optimal solution to the LMPC. A. Kinematic Model As mentioned in Section II, the position of the vehicle is expressed in the Frenet reference frame [23]. In particular , we describe the position of the vehicle in terms of lateral distance e y from the centerline of the road and distance s traveled along a predefined path (Fig. 1). The state e ψ represents the difference between the vehicle’ s heading angle and the angle of the tangent vector to the path at the curvilinear abscissa s . The rate of change of the vehicle’ s position in the curvili- nar reference frame is described by the following kinematic relationships ˙ e ψ = w z − v x cos( e ψ ) − v y sin( e ψ ) 1 − κ ( s ) e y κ ( s ) ˙ s = v x cos( e ψ ) − v y sin( e ψ ) 1 − κ ( s ) e y ˙ e y = v x sin( e ψ ) + v y cos( e ψ ) , where κ ( s ) is the curvature of the centerline of the track at the curvilinear abscissa s [23]. The abov e equations can be Euler discretized to approximate the vehicle’ s motion as a function of the vehicle’ s velocities e ψ k +1 = f e ψ ( x k ) = e ψ k + dt w z k − v x k cos( e ψ k ) − v y k sin( e ψ k ) 1 − κ ( s k ) e y k κ ( s k ) ! s k +1 = f s ( x k ) = s k + dt v x k cos( e ψ k ) − v y k sin( e ψ k ) 1 − κ ( s k ) e y k ! ˙ e y = f e y ( x k ) = e y k + dt v x k sin( e ψ k ) + v y k cos( e ψ k ) ! , (12) where dt is the discretization time. The abov e equations will be linearized to compute an A TV prediction model. It is interesting to notice that equations (12) are independent of the vehicle’ s physical parameters, because these are deriv ed from kinematic relationships between velocities and position. B. Dynamic Model The dynamic equations of motion, which describe the ev o- lution of the vehicle’ s velocities, may be computed balancing the forces acting on the tires [10]. Therefore, the dynamic equations depend on physical parameters associated with the vehicle, tires and asphalt. These parameters may be estimated through a system identification campaign. Ho we ver , the non- linear dynamic equations of motion should be linearized in order to obtain an A TV model which allows us to reformulate the LMPC as a QP . Instead of identifying the parameters of a nonlinear model and then linearize it, we propose to directly learn a linear model around x using a local linear regressor . W e introduce the Epanechnikov kernel function [24] K ( u ) = ( 3 4 (1 − u 2 ) , for | u | < 1 0 , else , which is used to compute a local linear model around x for the longitudinal and lateral dynamics. In particular , for l = { v x , v y , w z } we compute the following regressor vector Γ l ( x ) = argmin Γ X { k,j }∈ I ( x ) K || x − x j k || 2 Q h ! y j,l k (Γ) , (13) where the hyperparameter h ∈ R + is the bandwidth, the ro w vector Γ ∈ R 5 , y j,v x k (Γ) = || v j x k +1 − Γ[ v j x k , v j y k , w j z k , a j k , 1] T || y j,v y k (Γ) = || v j y k +1 − Γ[ v j x k , v j y k , w j z k , δ j k , 1] T || y j,w z k (Γ) = || w j z k +1 − Γ[ v j x k , v j y k , w j z k , δ j k , 1] T || , and I j l ( x ) is the set of indices I j l ( x ) = argmin { k 1 ,j 1 } ,..., { k P ,j P } P X i =1 || x − x j i k i || 2 Q s.t. k i 6 = k n , ∀ j i = j n k i ∈ { 1 , 2 , . . . } , ∀ i ∈ { 1 , . . . , P } j i ∈ { l , . . . , j } , ∀ i ∈ { 1 , . . . , P } , where || y || Q = y > Q > Qy and the matrix Q is user defined. For the stored data from iteration l to iteration j , the set I j l ( x ) collects the indices associated with the P -nearest neighbors to the state x . Finally , the user-defined matrix Q takes into account the relativ e scaling of different variables. Notice that the optimizer in (13) can be used to approximate the ev olution of v ehicle’ s velocities, v x k +1 v y k +1 w z k +1 = Γ v x 1:3 ( x ) Γ v y 1:3 ( x ) Γ w z 1:3 ( x ) v x k v y k w z k + Γ v x 4 ( x ) 0 0 Γ v y 4 ( x ) 0 Γ w z 4 ( x ) a k δ k + Γ v x 5 ( x ) Γ v y 5 ( x ) Γ w z 5 ( x ) , (14) where for l = { v x , v y , w z } the scalar Γ l i ( x ) denotes the i th element of the vector Γ l ( x ) and Γ l 1:3 ( x ) ∈ R 3 is a row vector collecting the first three elements of Γ l ( x ) in (13). C. Affine T ime V arying Model In this section we describe the strategy used to b uild an A TV model, which is then used for control. At time t of the j th iter- ation we define the candidate solution ¯ x j t = [ ¯ x j t | t , . . . , ¯ x j t + N | t ] to Problem (8) using the optimal solution at time t − 1 from (9), ¯ x j k | t = ( x j, ∗ k | t − 1 If k ∈ { t, . . . , t + N − 1 } z j t If k = t + N . Finally at each time t of iteration j , the abov e candidate solution is used to build the following A TV model x j k +1 | t = A j k | t x j k | t + B j k | t u j k | t + C j k | t , (15) where x j k | t = [ v j x k | t , v j y k | t , w j y k | t , e j ψ k | t , s j k | t , e j y k | t ] and the ma- trices A j k | t , B j k | t and C j k | t are obtained linearizing (12) around ¯ x j k | t and ev aluating (14) at ¯ x j k | t , A j k | t = Γ v x 1:3 ( ¯ x j k | t ) 0 0 0 Γ v y 1:3 ( ¯ x j k | t ) 0 0 0 Γ w z 1:3 ( ¯ x j k | t ) 0 0 0 ( ∇ x f e ψ ( x ) | ¯ x j k | t ) > ( ∇ x f s ( x ) | ¯ x j k | t ) > ( ∇ x f e y ( x ) | ¯ x j k | t ) > , B j k | t = Γ v x 4 ( ¯ x j k | t ) 0 0 Γ v y 4 ( ¯ x j k | t ) 0 Γ w z 4 ( ¯ x j k | t ) 0 0 0 0 0 0 (16) and C k = Γ v x 5 ( ¯ x j k | t ) Γ v y 5 ( ¯ x j k | t ) Γ w z 5 ( ¯ x j k | t ) f e y ( ¯ x j k | t ) − ( ∇ x f e y ( x ) | ¯ x j k | t ) > ¯ x j k | t f s ( ¯ x j k | t ) − ( ∇ x f s ( x ) | ¯ x j k | t ) > ¯ x j k | t f e ψ ( ¯ x j k | t ) − ( ∇ x f e ψ ( x ) | ¯ x j k | t ) > ¯ x j k | t . (17) V . R E S U LT S The proposed control strategy has been implemented on a 1/10-scale open source vehicle platform called Berkeley Autonomous Race Car 2 (B ARC). The vehicle is equipped with a set of sensors, actuators and two on-board CPUs to perform low-le vel control of the actuators as well as communication with a laptop, on which the high-lev el control is implemented. The CPUs are an Arduino Nano for low-le vel control of the actuators and an Odroid XU4 for W iFi communication with the i7 MSI GT72 laptop. The actuators are an electrical motor and a servo for the steering. The control architecture has been implemented in the Robot Operating System (ROS) frame- work, using Python and OSQP [25]. The code is av ailable online 3 . Fig. 2. Lap time of the LMPC on the oval-shaped and L-shaped tracks. W e initialize the algorithm performing two laps of path following at constant speed. Each j th iteration collects the data of two consecutiv e laps. Therefore, the local safe set and local Q -function are defined also beyond the finish line. This strategy allows us to implement the LMPC for the repetitive autonomous racing control task, as shown in [20]. At each j th lap, we use the LMPC (8) and (11) to driv e the vehicle from the starting line to the finish line and we use the closed-loop data to update the controller for the next lap. The parameters which define the controller are reported in T able I. W e also added a small input rate cost in order to guarantee a unique solution to the QP associated with the LMPC. T ABLE I P A R AM E T E RS U S E D I N TH E C O N T RO LL E R D E SI G N . l j − 2 K 20 T diag (0 , 0 , 0 , 0 , 1 , 0) Q diag (0 . 1 , 1 , 1 , 0 , 0 , 0) P 80 h 10 N 12 2 A video of the experiment can be found at https://youtu.be/ZBFJWtIbtMo 3 The code is available on the BARC GitHub repository in the “devel-ugo” branch (github.com/MPC-Berkele y/barc) W e tested the controller on an oval-shaped and L-shaped tracks on which the vehicle runs in the counter -clockwise direction. Figure 2 shows that the lap time decreases until con vergence is reached after 29 laps. Furthermore, Figure 4 shows the ev olution of the closed-loop trajectory on the X- Y plane and the velocity profile which is color coded. In the first row we reported the path follo wing trajectory used to initialize the LMPC and the closed-loop trajectories at laps 7 and 15 . W e notice that the controller deviates from the initial feasible trajectory (reported in blue as the vehicle speed is 1 . 2 m/s) in order to explore the state space and to driv e the vehicle at higher speeds, until it con ver ges to a steady-state behavior . The steady-state trajectories from lap 30 to 34 are reported in the bottom row of Figure 4. Notice that the color bar representing the velocity profile changed from the first to second row as the v ehicle runs at higher speed at the end of the learning process. W e underline that the controller understands the benefit of breaking right before entering the curv e and of accelerating when exiting. This beha vior is optimal in racing as shown in [26]. Fig. 3. Recorded lateral acceleration of the vehicle running on the ov al-shaped track (top row) and L-shaped track (bottom row). Figure 3 shows the raw acceleration measurements from the IMU. W e confirm that controller is able to operate the vehicle at the limit of its handling capability , reaching a maximum lateral acceleration close to 1 g 4 . Furthermore, Figure 5 shows the data points used to design the LMPC. Recall from T able I that at the j th lap the LMPC policy is synthesized using the trajectories from lap l = j − 2 to lap j − 1 . Therefore, as the controller drives faster on the track, less data points are needed to design the LMPC. Moreover , in Figure 6 we reported the computational time. It is interesting to notice that on average the finite time optimal control problem (8) is solved in less then 10 ms, whereas it took 90 ms to solve the finite time optimal control problem associated with [20]. W e underline that both strategies have been tested with a prediction horizon of N = 12 and a sampling time of 10 Hz. 4 The maximum allowed lateral acceleration is computed assuming that the aerodynamic effects are negligible and the that lateral force acting on the vehicle is F = µmg for the friction coefficient µ = 1 . Fig. 4. The first row in the above figure shows the closed-loop trajectory used to initialize the LMPC and the closed-loop trajectories after few laps of learning. The second row shows the steady state trajectories at which the LMPC has conv erged. Notice that the scale of the color bar changes from the first to the second row , as the vehicle runs at higher speed after the learning process has conver ged. Fig. 5. Data points used in the LMPC design at each lap. This shows the advantage of using the local con vex safe set in (6), instead of the polynomial approximation to the safe set used in [20], [21]. For more details on the polynomial approximation to the safe set we refer to [21]. Finally , we notice that it would be possible to parallelize the computation of the N − 1 linear models which define the A TV model from (15). Indeed, at time t Equations (16)-(17) may be e v aluated independently and in parallel for each predicted time k . Fig. 6. The first rows sho ws the computational cost associated with the FTOCP . In the second row we reported the computational cost associated with the system identification strategy . V I . C O N C L U S I O N S W e presented a Learning Model Predictiv e Controller (LMPC) for autonomous racing. The proposed control frame- work uses historical data to construct safe sets and approxima- tions to the value function. These quantities are systematically updated when a lap is completed, as a result the LMPC learns from experience to safely driv e the vehicle at the limit of handling. W e demonstrated the effecti veness of the proposed strategy on the Berkele y Autonomous Race Car (B ARC) platform. Experimental results sho w that the controller learns to dri ve the vehicle aggressi vely , in order to minimize the lap time. In particular, the closed-loop system con verged to a steady-state trajectory which cuts curves and reaches a lateral acceleration close to 1 g. R E F E R E N C E S [1] E. J. Rossetter and J. C. Gerdes, “L yapunov based performance guaran- tees for the potential field lane-keeping assistance system, ” Journal of dynamic systems, measurement, and contr ol , vol. 128, no. 3, pp. 510– 522, 2006. [2] Y . Gao, A. Gray , J. V . Frasch, T . Lin, E. Tseng, J. K. Hedrick, and F . Borrelli, “Spatial predictive control for agile semi-autonomous ground vehicles, ” in 11th International Symposium on Advanced V ehicle Contr ol , 2012. [3] Y . Kuwata, J. T eo, G. Fiore, S. Karaman, E. Frazzoli, and J. P . How , “Real-time motion planning with applications to autonomous urban driving, ” IEEE T ransactions on Control Systems T ec hnology , vol. 17, no. 5, pp. 1105–1118, 2009. [4] J. V . Frasch, A. Gray , M. Zanon, H. J. Ferreau, S. Sager, F . Borrelli, and M. Diehl, “ An auto-generated nonlinear mpc algorithm for real-time obstacle avoidance of ground vehicles, ” in Contr ol Conference (ECC), 2013 European . IEEE, 2013, pp. 4136–4141. [5] M. Campbell, M. Egerstedt, J. P . How , and R. M. Murray , “ Autonomous driving in urban environments: approaches, lessons and challenges, ” Philosophical T ransactions of the Royal Society of London A: Math- ematical, Physical and Engineering Sciences , vol. 368, no. 1928, pp. 4649–4672, 2010. [6] D. Gonz ´ alez, J. P ´ erez, V . Milan ´ es, and F . Nashashibi, “ A revie w of motion planning techniques for automated vehicles, ” IEEE T ransactions on Intelligent T ransportation Systems , vol. 17, no. 4, pp. 1135–1145, 2016. [7] C. Katrakazas, M. Quddus, W .-H. Chen, and L. Deka, “Real-time motion planning methods for autonomous on-road driving: State-of-the-art and future research directions, ” Tr ansportation Researc h P art C: Emerging T echnolo gies , vol. 60, pp. 416–442, 2015. [8] B. Paden, M. ˇ C ´ ap, S. Z. Y ong, D. Y ershov , and E. Frazzoli, “ A survey of motion planning and control techniques for self-driving urban vehicles, ” IEEE T ransactions on Intelligent V ehicles , vol. 1, no. 1, pp. 33–55, 2016. [9] G. Williams, P . Drews, B. Goldfain, J. M. Rehg, and E. A. Theodorou, “ Aggressiv e driving with model predictive path integral control, ” in Robotics and Automation (ICRA), 2016 IEEE International Conference on . IEEE, 2016, pp. 1433–1440. [10] R. Rajamani, V ehicle dynamics and contr ol . Springer Science & Business Media, 2011. [11] A. Alleyne, “ A comparison of alternativ e intervention strategies for unintended roadway departure (urd) control, ” V ehicle System Dynamics , vol. 27, no. 3, pp. 157–186, 1997. [12] B. Alrifaee and J. Maczijewski, “Real-time trajectory optimization for autonomous vehicle racing using sequential linearization, ” in 2018 IEEE Intelligent V ehicles Symposium (IV) . IEEE, 2018, pp. 476–483. [13] R. V erschueren, S. De Bruyne, M. Zanon, J. V . Frasch, and M. Diehl, “T ow ards time-optimal race car driving using nonlinear mpc in real- time, ” in 53r d IEEE confer ence on decision and control . IEEE, 2014, pp. 2505–2510. [14] R. V erschueren, M. Zanon, R. Quirynen, and M. Diehl, “Time-optimal race car driving using an online exact hessian based nonlinear mpc algorithm, ” in 2016 Eur opean Control Conference (ECC) . IEEE, 2016, pp. 141–147. [15] R. V erschueren, S. De Bruyne, M. Zanon, J. V . Frasch, and M. Diehl, “T ow ards time-optimal race car driving using nonlinear mpc in real- time, ” in 53r d IEEE Conference on Decision and Contr ol . IEEE, 2014, pp. 2505–2510. [16] A. Liniger, A. Domahidi, and M. Morari, “Optimization-based au- tonomous racing of 1: 43 scale rc cars, ” Optimal Control Applications and Methods , vol. 36, no. 5, pp. 628–647, 2015. [17] A. Liniger and J. Lygeros, “Real-time control for autonomous racing based on viability theory , ” IEEE T ransactions on Control Systems T echnolo gy , no. 99, pp. 1–15, 2017. [18] N. R. Kapania and J. C. Gerdes, “Path tracking of highly dynamic au- tonomous vehicle trajectories via iterative learning control, ” in American Contr ol Conference (ACC), 2015 . IEEE, 2015. [19] P . A. Theodosis and J. C. Gerdes, “Generating a racing line for an au- tonomous racecar using professional driving techniques, ” in ASME 2011 Dynamic Systems and Control Conference and Bath/ASME Symposium on Fluid P ower and Motion Control . American Society of Mechanical Engineers, 2011, pp. 853–860. [20] M. Brunner , U. Rosolia, J. Gonzales, and F . Borrelli, “Repetiti ve learning model predicti ve control: An autonomous racing example, ” in 2017 IEEE 56th Annual Conference on Decision and Contr ol (CDC) , Dec 2017, pp. 2545–2550. [21] U. Rosolia, A. Carvalho, and F . Borrelli, “ Autonomous racing using learning model predictiv e control, ” in 2017 American Control Confer- ence (ACC) , May 2017, pp. 5115–5120. [22] U. Rosolia and F . Borrelli, “Learning model predictiv e control for iterativ e tasks: A computationally efficient approach for linear system, ” IF AC-P apersOnLine , vol. 50, no. 1, pp. 3142–3147, 2017. [23] A. Micaelli and C. Samson, “Trajectory tracking for unicycle-type and two-steering-wheels mobile robots, ” Ph.D. dissertation, INRIA, 1993. [24] V . A. Epanechniko v , “Non-parametric estimation of a multiv ariate prob- ability density , ” Theory of Probability & Its Applications , vol. 14, no. 1, pp. 153–158, 1969. [25] B. Stellato, G. Banjac, P . Goulart, A. Bemporad, and S. Boyd, “Osqp: An operator splitting solver for quadratic programs, ” in 2018 UKACC 12th International Conference on Contr ol (CONTROL) . IEEE, 2018, pp. 339–339. [26] P . A. Theodosis and J. C. Gerdes, “Nonlinear optimization of a racing line for an autonomous racecar using professional driving techniques, ” in ASME 2012 5th Annual Dynamic Systems and Control Conference . American Society of Mechanical Engineers, 2012, pp. 235–241.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment