Auto-adaptive Resonance Equalization using Dilated Residual Networks
In music and audio production, attenuation of spectral resonances is an important step towards a technically correct result. In this paper we present a two-component system to automate the task of resonance equalization. The first component is a dyna…
Authors: Maarten Grachten, Emmanuel Deruty, Alex
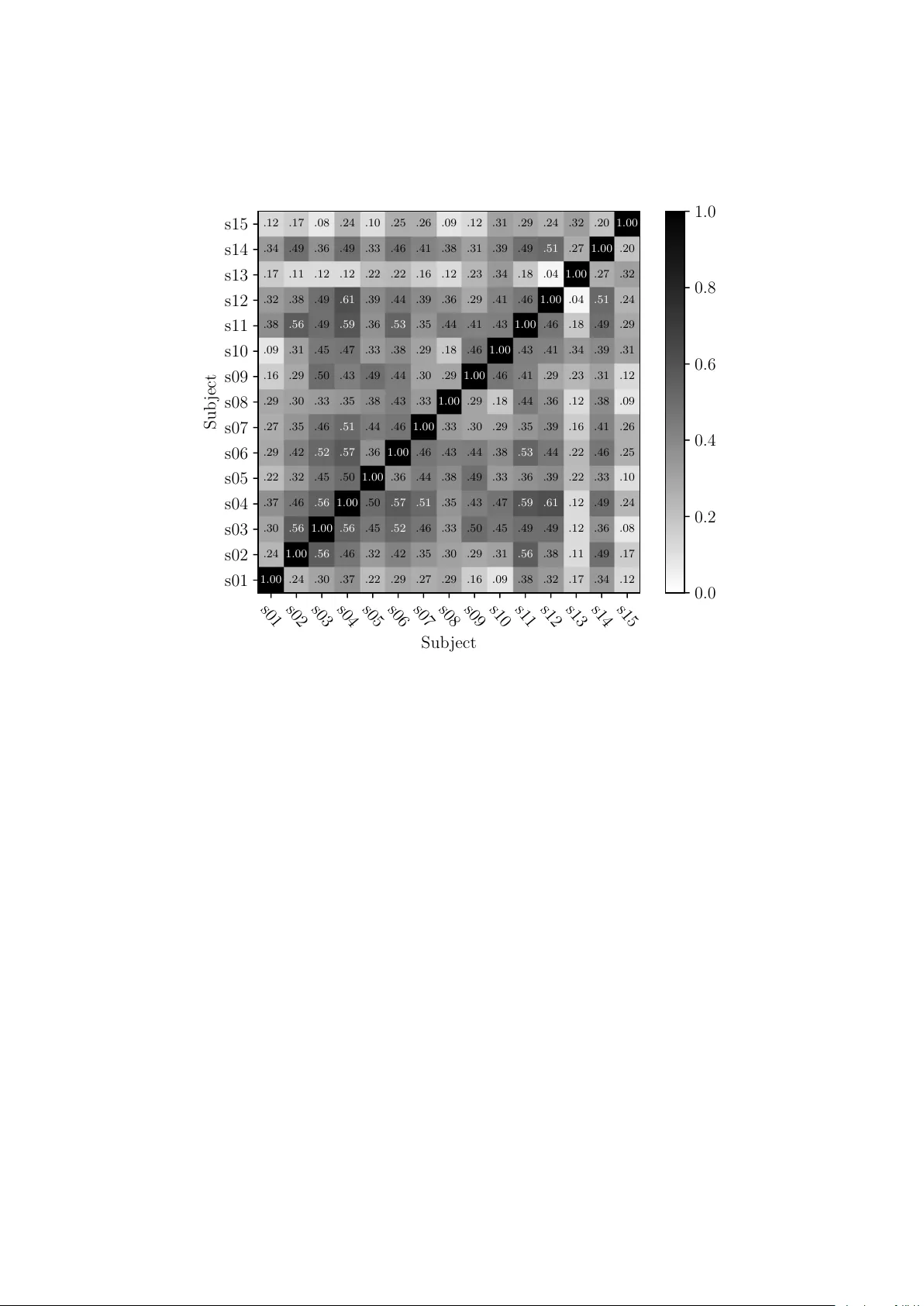
Auto-adaptiv e Resonance Equalization using Dilated Residual Net w orks Maarten Grac hten 1 and Emman uel Deruty 2 and Alexandre T anguy 3 July 24, 2018 1 Con tractor for Son y CSL P aris, F rance 2 Son y CSL Paris, F rance 3 Y ascore, P aris, F rance Abstract In m usic and audio pro duction, attenuation of sp ectral resonances is an imp ortant step tow ards a technically correct result. In this pap er we presen t a tw o-comp onen t system to automate the task of resonance equal- ization. The first comp onen t is a dynamic equalizer that automatically detects resonances and offers to attenuate them b y a user-specified fac- tor. The second component is a deep neural netw ork that predicts the optimal atten uation factor based on the windo wed audio. The netw ork is trained and v alidated on empirical data gathered from an experiment in which sound engineers c ho ose their preferred attenuation factors for a set of tracks. W e test tw o distinct netw ork architectures for the predic- tiv e mo del and find that a dilated residual netw ork op erating directly on the audio signal is on a par with a netw ork architecture that requires a prior audio feature extraction stage. Both architectures predict human- preferred resonance attenuation factors significan tly better than a baseline approac h. 1 In tro duction and related w ork Equalization is part of the audio mixing and mastering process. It is a redis- tribution of the energy of the signal in differen t frequency bands. The pro cess has b een traditionally p erformed by skilled sound engineers or musicians who determine the proper equalization given the c haracter and p eculiarities of the input audio. In recen t years, metho ds hav e b een developed for semi-automatic and automatic equalization. Suc h metho ds ma y b e used by audio professionals to sa ve time, or by recording enth usiasts lac king the skills required to use man- ual equalization tools effectiv ely . These metho ds include automatic detection of frequency resonances [1], automatic equalization derived from expert prac- tices [2], and automatic conformation to a target sp ectrum [3]. Equalization profiles may also b e derived from semantic descriptors [4]. Appropriate equal- ization settings can b e found through different means, for example b y comparing the input source to previously equalized con ten t [5], or b y formulating equal- ization as an optimization problem in which inter-trac k masking is used as the cost function [6]. Some automated equalization functionalities are featured in 1 commercial pro ducts. Examples include the ”learn” function in Neutron 2’s equalizer 1 , and the ”T ame” function in SoundTheory’s Gulfoss 2 . The use of mac hine learning to solv e audio production related tasks is recen t. Aside from an early approach using nearest neigh bor inference to infer equal- ization [5], most applications of machine learning for automatic mixing date from the past few years. Automatic mixing tasks that hav e b een addressed in this wa y include automatic reverbation [7], dynamic range compression [8], and demixing/remixing of trac ks [9]. All three studies use neural net works, whic h are rapidly b ecoming a de facto standard metho d for machine learning. T o our kno wledge, there is no do cumen ted example of the use of neural netw orks for automatic equalization. A particular metho d of equalization is the atten uation of resonating or salient frequencies, i.e. frequencies that are substantially louder than their neigh- b ors [10]. The fo cus of this pap er is the automation of such as pro cess using a deep neural netw ork. Salien t frequencies may originate from different phe- nomena, such as the acoustic resonances of a physical instrument or an acoustic space. They may be considered a deficiency , in the sense that they ma y mask the conten t of other frequency regions. One particular difficulty in resonance atten uation is finding the righ t amount of attenuation. F or example, too muc h atten uation ma y unmask noise that would otherwise remain unheard, or flatten the sp ectrum to the p oin t of garbling the original audio. Our metho d fully automates the resonance attenuation pro cess. It includes, 1) a windo wed, dynamic resonance attenuation pro cess that works on 0.5s win- do ws and can b e con trolled with a single parameter—the attenuation factor , 2) a deep neural netw ork that predicts the atten uation factor from the input audio, making the pro cess auto-adaptiv e [11]. F or the training and v alidation of the predictive mo del we conduct a lis- tening exp erimen t determining optimal resonance attenuation factors for a set of trac ks, as c hosen b y sound engineers. W e describ e and test t wo alternative mo deling approaches, and find that a state-of-the-art conv olutional netw ork for image pro cessing can b e successfully adapted for audio pro cessing. Exp erimen- tal results show that this netw ork arc hitecture, which directly pro cesses the raw audio signal, is on a par with a more traditional approac h of training a neural net work on a set of pre-computed audio descriptors. The pap er is organized as follows. Section 2 describ es the resonance equal- ization pro cess. The listening exp eriment is describ ed in Section 3. The design, training, and ev aluation of the predictive mo dels is presented in Section 4, and conclusions are presen ted in Section 5. 2 Resonance Equalization T raditionally , resonance atten uation has been a man ual task in which a m usi- cian or sound engineer determines the resonating frequencies by ear or using a graphical to ol, in order to reduce the energy of the signal in those frequencies b y an appropriate amount [12]. In this section, we describe a pro cedure that iden tifies resonating frequencies autonomously , and reduces the energy in those frequencies by a factor that is con trolled b y the user. The pro cedure works 1 https://www.izotope.com/en/products/mix/neutron/neutron- advanced.html 2 https://www.soundtheory.com/home 2 PCM Signal a DFT b Po wer Spectrum c Equal Loud- ness W eighting d ELC-weigh ted Po wer Spectrum e Smoothing f Smoothed Po wer Spectrum g Positiv e Difference h p Corrected Po wer Spectrum q inv erse DFT r Corrected PCM Signal s Spectrum Correction o Log-to-linear/freq- interpolation n Po wer Spec- trum Correction m ∗ k − j Atten uation F actor l Resonance i Figure 1: Resonance equalization blo c k diagram; White and gray blo c ks repre- sen t data and pro cesses resp ectiv ely; The green blo c k depicts the single user- con trolled parameter; The symbols , ∗ and − represen t element wise vec- tor/v ector multiplication, elemen twise scalar/vector multiplication, and unary negation resp ectiv ely . on ov erlapping audio windows that must b e large enough to allo w for spectral analysis at a high frequency resolution. Figure 1 displays a blo c k diagram of the resonance attenuation pro cess, where eac h elemen t is denoted b y a letter. In the following, we will use these letters to refer to the corresp onding elemen ts in the diagram. First the audio signal is used to compute a p o wer sp ectrum weigh ted by Equal-Loudness Con- tours (ELC) [13] at a fixed monitoring level of 80 phon (Figure 1, elemen t d) in order to reflect the p erceptual salience of the signal energy at different frequency bands. The v alue of 80 phon is chosen in relation to the procedure detailed in Section 3.3. The ELC-weigh ted pow er sp ectrum (e) consists of 400 log-scaled frequency bands. Resonances (i) are determined by smoothing ELC-w eighted p o wer spectrum (e) to obtain (g) and computing the elemen t wise differences (e) min us (g), setting negativ e elemen ts to zero (h). The negative of the resonances is then scaled b y the user defined attenu ation factor (l), transformed back to a linear scale and con verted back to the shap e of the original sp ectrum using interpolation (h). The result (o) is a vector of scaling factors (one for each DFT bin) that range b et w een 0 and 1 for resonating frequencies and are 1 otherwise. Multiplying the original p ow er sp ectrum (c) with the scaling factors giv es the corrected pow er sp ectrum (q) from whic h the corrected audio signal (s) is reco vered through the in verse DFT (r). 3 Listening exp eriment A listening exp erimen t was carried out to obtain ground truth in terms of opti- mal resonance attenuation v alues for a set of audio trac ks. In the experimental design of the listening test it prov ed unpractical to ask sub jects to set a v ary- ing resonance atten uation factor. Therefore, we chose relativ ely homogeneous sound fragmen ts, and let the sub jects choose a single attenuation factor for the whole fragment. 3 3.1 P articipan ts A group of 15 sub jects was recruited for the exp eriment, in the area of Paris (F rance). All of them are recognized professionals in the industry . Nine sub jects sp ecialize in studio recording (Classic, Jazz, Pop, Ro c k, Movie Music, audio p ost-production), three are exp erts in live m usic, and three are comp oser/m usic pro ducer. The sub jects were b etw een 24 and 42 years old, with an av erage age of 32 years. They were recruited and paid as if they were working on a commercial pro ject. 3.2 Data A set of 150 audio tracks was used for the listening exp erimen t. The tracks are excerpts from longer pieces, with a mean duration of 46 seconds and a standard deviation of 16 seconds. All trac ks were pro cessed using Nugen AMB R128 3 so that they were aligned to the same median loudness. The set comprised p op and ro ck music, as well as film scores. Of this set, 131 tracks were unique recordings, while the remaining 19 tracks w ere v arian ts of some of the unique 131 recordings, with differences in mixing. None of the trac ks w ere previously mastered. 3.3 Pro cedure The listening exp erimen t to ok place in a recording studio, where participants listened to the audio trac ks individually , using studio monitors, at a measured listening loudness of 80 dBC. This v alue was c hosen as being representativ e of a normal listening loudness during audio pro duction. The participants were presen ted with a w eb interface in which they could listen to eac h track with differen t degrees of resonance attenuation, ranging from 0 (no attenuation) to 1 in 17 steps. They could select their preferred degree of resonance attenuation, or alternativ ely decline to select any version, indicating that none of the versions sounded acceptable. The tracks w ere separated from each other b y 10 seconds of pink noise surrounded by a short silence to give the participants a fixed reference. Sessions of 50 tracks were alternated with breaks. 3.4 Results and discussion Basic statistics of the results per sub ject are given in T able 1. Sub ject 13 stands out b ecause of the num b er of missing ratings (21 versus a median of 1 ov er all sub jects). Sub jects 1 and 15 hav e abnormally high rates of 0.0 ratings (72 and 58 resp ectiv ely , versus a median of 16 ov er all sub jects). Finally , Sub ject 7 stands out in terms of median rating (0.469 versus a median of 0.188 ov er all sub jects). Figure 2 shows the distribution of ratings p er sub ject. T o see how strongly the ratings are linearly related among sub jects, we compute the Pearson correlation for each pair of sub jects (Figure 3). Apart from Sub jects 13 and 15 (and to a lesser degree Sub ject 1) who app ear to hav e differen t rating patterns from the ma jority of the sub jects, the figure shows w eak to mo derate p ositive correlations b etw een all sub jects. This suggests that 3 https://nugenaudio.com/amb 4 T able 1: Rating statistics per sub ject. Outlying v alues are highlighted in b old (see text). Sub ject # No rating # 0.0 Min Median Max s01 1 72 0.0 0.062 0.750 s02 0 2 0.0 0.188 0.812 s03 2 25 0.0 0.125 0.812 s04 2 7 0.0 0.250 1.000 s05 4 25 0.0 0.156 0.750 s06 0 22 0.0 0.125 0.875 s07 0 2 0.0 0.469 0.875 s08 8 9 0.0 0.312 1.000 s09 0 9 0.0 0.250 0.750 s10 1 17 0.0 0.188 0.812 s11 1 16 0.0 0.250 1.000 s12 2 25 0.0 0.188 1.000 s13 21 13 0.0 0.312 1.000 s14 0 3 0.0 0.250 0.875 s15 0 58 0.0 0.188 1.000 s01 s03 s06 s05 s02 s10 s15 s12 s09 s04 s14 s11 s08 s13 s07 Sub ject 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 Rating Figure 2: Rating p ercen tiles (in steps of 10%) p er sub ject. Darker areas corre- sp ond to more central percentile ranges, ligh ter areas to more peripheral ranges. The b old line in the left plot sho ws the median ratings. 5 s01 s02 s03 s04 s05 s06 s07 s08 s09 s10 s11 s12 s13 s14 s15 Sub ject s15 s14 s13 s12 s11 s10 s09 s08 s07 s06 s05 s04 s03 s02 s01 Sub ject .12 .17 .08 .24 .10 .25 .26 .09 .12 .31 .29 .24 .32 .20 1.00 .34 .49 .36 .49 .33 .46 .41 .38 .31 .39 .49 .51 .27 1.00 .20 .17 .11 .12 .12 .22 .22 .16 .12 .23 .34 .18 .04 1.00 .27 .32 .32 .38 .49 .61 .39 .44 .39 .36 .29 .41 .46 1.00 .04 .51 .24 .38 .56 .49 .59 .36 .53 .35 .44 .41 .43 1.00 .46 .18 .49 .29 .09 .31 .45 .47 .33 .38 .29 .18 .46 1.00 .43 .41 .34 .39 .31 .16 .29 .50 .43 .49 .44 .30 .29 1.00 .46 .41 .29 .23 .31 .12 .29 .30 .33 .35 .38 .43 .33 1.00 .29 .18 .44 .36 .12 .38 .09 .27 .35 .46 .51 .44 .46 1.00 .33 .30 .29 .35 .39 .16 .41 .26 .29 .42 .52 .57 .36 1.00 .46 .43 .44 .38 .53 .44 .22 .46 .25 .22 .32 .45 .50 1.00 .36 .44 .38 .49 .33 .36 .39 .22 .33 .10 .37 .46 .56 1.00 .50 .57 .51 .35 .43 .47 .59 .61 .12 .49 .24 .30 .56 1.00 .56 .45 .52 .46 .33 .50 .45 .49 .49 .12 .36 .08 .24 1.00 .56 .46 .32 .42 .35 .30 .29 .31 .56 .38 .11 .49 .17 1.00 .24 .30 .37 .22 .29 .27 .29 .16 .09 .38 .32 .17 .34 .12 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 Figure 3: Correlation co efficien ts of ratings among sub jects. in spite of different preferred rating ranges, the sub jects made their judgments according to common criteria. 4 Prediction of optimal atten uation factors In this section we describ e the design and exp erimen tal v alidation of tw o mod- eling approac hes to predict optimal attenuation factors from audio. The mo dels are ultimately intended to b e used in a real-time plugin for audio workstations. Although the details the real-time aspects of the implementation are b ey ond the scop e of this pap er, it do es guide some imp ortan t design decisions for the mo d- eling. Most imp ortan tly it implies a causal design in which the track cannot b e analyzed as a whole in order to estimate the optimal attenuation factor. On the other hand, the audio latency upp er-bound for real-time op eration (maximum observ ed audio latency in real-time commercial plug-ins is 4096 samples) is to o lo w for accurate prediction of the attenuation factor. This implies that the at- ten uation factor that will be applied at time t will be estimated from a windo w ed part of the signal (immediately) b efore t . Whether the predicted attenuation factor is still approximately v alid for the signal at time t dep ends on the length of the window in relation to how quic kly the resonance characteristics of the signal can change. Our p oin t of view is to target phenomena whose time-scale 6 is around three seconds or longer—the same time scale as the short-term loud- ness in EBU R128 [14]. F rom this p ersp ectiv e we consider a window size of 0.5s a go o d trade-off, offering sufficient data for an informed prediction and at the same time b eing short enough to adapt to changes in resonance c haracteristics at the 3s time-scale. W e describ e and test t wo alternativ e neural net work approac hes to the prob- lem of predicting optimal attenuation factors. The first is a more traditional approac h in whic h a feature set is computed from an audio window, from which the atten uation factor is predicted. The second approach skips the in termediate feature representation. Instead, it takes the stereo PCM signal directly as input to a neural netw ork that predicts the atten uation factor. 4.1 Predicting based on audio features (FFN) P erforming regression or classification tasks on audio using feature descriptions of the audio has b een the predominant approac h for the past decades, and is based on the intuition that the prediction is determined by characteristics of the signal that can be defined explicitly and computed from the audio. These descriptors often capture sp ectral characteristics of the signal, but may also appro ximate p erceptual c haracteristics, such as loudness. Many audio descrip- tors that hav e b een prop osed in the literature ov er time are implemented in a soft ware library called Essen tia [15]. The descriptors used in this study are listed in T able 2. All descriptors are a v ailable in the Essentia library , except harmonics-to-noise r atio [16] and ster e o width (tw o descriptors, computed as the correlation b etw een c hannels and absolute difference in RMS b etw een c hannels, resp ectiv ely), for whic h w e used our o wn implemen tation. The features are computed on shorter timescales (typically 1024 samples) than the 0.5s audio window for which our prediction will b e made. Th us the feature computation stage returns a v ector of v alues for each feature. W e sum- marize eac h of these vectors by 7 statistics: the me an , me dian , standar d devi- ation , skew , kurtosis , the 10 th p er c entile , and the 90 th p er c entile . This yields a total of 679 v alues p er data instance, based on which a prediction must b e made. A com mon preprocessing step for high-dimensional input spaces like this is dimension reduction by means of princip al c omp onent analysis (PCA). T ests sho wed that PCA did not lead to an y substan tial impro vemen ts how ever, and w as th us not included in the final exp erimen t. The net work consists in a stack of linear lay ers (also called dense , or ful ly c onne cte d ), each of which is follow ed by a b atch normalization (BN) la yer and a la yer of r e ctifie d line ar units (ReLU). The BN lay er transforms the distribution of the output activ ations of the preceding linear lay er to zero mean and unit v ariance b y k eeping trac k of mean and v ariance during the training of the model. The ReLU lay er p erforms a non-linear transformation b y setting negative output activ ations of the preceding lay er to zero. The num b er of linear lay ers and their sizes are not fixed in adv ance but determined using a hyper-parameter optimization scheme (Section 4.3). A final linear lay er is added after the after the last ReLU lay er. This lay er has a single output—the predicted resonance atten uation factor. 7 T able 2: List of audio descriptors used in the FFN. MF CC (13 v alues) GF CC (13 v alues) inharmonicit y pitc h pitc h salience sp ectral complexity sp ectral crest sp ectral decrease sp ectral energy sp ectral flux sp ectral rms sp ectral rolloff sp ectral strong p eak zero-crossing rate sp ectral flatness dB high frequency co efficien t barkbands (30 v alues) pitc h instantaneous confidence silence rate (at 20/30/60dB) o dd-to-ev en harmonic energy ratio sp ectral energy band (4 v alues) tristim ulus (3 v alues) sp ectral contrast (6 v alues) sp ectral v alley (6 v alues) stereo width (2 v alues) harmonics-to-noise ratio 4.2 Predicting directly from audio: Dilated Residual Net- w orks (DRN) In this section we describ e a conv olutional neural net work that tak es slices of a stereo PCM signal of the audio as input and provides an estimate of the optimal atten uation factor. Note that ev en for a window of moderate size and sample rate this quickly leads to tens of thousands of samples to b e taken as mo del inputs. As opp osed to a feature v ector ho wev er, the inputs are ordered along a meaningful dimension (time), in whic h patterns can b e iden tified. A common w ay do deal with data exhibiting such top ological prop erties (sound, images, video) in neural netw orks is to use c onvolution . This approach, which was pioneered in [17], exploits the fact that suc h data displa y lo cal patterns that ma y o ccur at differen t lo cations in the data. The strength of conv olutional netw orks is that they learn to recognize patterns independently of their absolute lo cation, and at the same time the conv olution op eration is muc h more space efficien t than the “fully-connected” matrix dot pro duct that takes place in regular feed- forw ard neural netw orks, allowing for larger mo dels. By stacking conv olutional la yers on top of eac h other it is p ossible to detect patterns of increasing size, and b y interlea ving the conv olution op eration with so-called p o oling or sub-sampling op erations, the patterns b ecome somewhat inv arian t to lo cal deformations. Ho wev er promising, the p oten tial of traditional conv olutional netw orks has b een limited by a num b er of factors. Tw o of these limitations hav e b een ad- dressed by recent extensions of the traditional con volutional netw ork approac h, namely dilate d c onvolution , and r esidual networks . W e integrate b oth exten- sions in our con volutional netw ork for predicting resonance atten uation factors, and discuss each of them briefly b efore we describe the global arc hitecture of the mo del. 4.2.1 Dilated con v olution An approach often used with traditional con v olution in order to create high-level feature representations of data is p ooling using max or aver age aggregation func- tions. F or instance, max-p ooling sub-samples the input by selecting maximal 8 elemen ts in a sliding window, typically using a sliding step ( stride ) equal to the size of the p ooling window. Stacking con volution/po oling op erations leads to features with increasing r e c eptive fields , meaning that the features can describ e patterns of increasing size. Ho wev er, it comes at the cost of resolution loss: The relativ e p osition of features b ecomes less precise as their size increases. On the contrary , dilated conv olution ac hieves high-level features without loss of resolution. Rather than increasing stride, it increases the receptive field of the features by “dilating” the conv olution kernels. A normal con volution of the k ernel k with the signal s in volv es multiplying kernel elements with contiguous signal samples ( τ is a discrete v ariable that increases in steps of 1): ( k ∗ s )( t ) = ∞ X τ = −∞ k ( τ ) s ( t − τ ) (1) In conv olution with dilation factor d ∈ Z + on the other hand the kernel elemen ts are m ultiplied with signal samples that are equally spaced at d samples: ( k ∗ d s )( t ) = ∞ X τ = −∞ k ( τ ) s ( t − dτ ) (2) By stacking con volutional la yers with increasing dilation factors the higher lev el filter kernels aggregate information ov er input ranges of exp onen tially in- creasing size, even if the size the kernels (in terms of parameters) do es not increase, and the resolution remains intact. This approach has prov en success- ful in image pro cessing tasks suc h as semantic segmen tation [18]. 4.2.2 Residual blocks Another issue with conv olutional net works is that as they grow deep er in order to capture higher level patterns, it b ecomes harder to optimize the lo wer level con volutional la yers. This is directly related to the fact that for lo w lev el feature activ ations to influence the output of the model, they m ust pass through m ultiple la yers of con volutions. Sometimes how ever, it is desirable for low level features to be able to directly influence the output of the mo del, not just to figure as a building blo c k for higher lev el features. This observ ation has led to the prop osal of the r esidual blo ck as a sub- structure used in deep netw orks [19, 20], an adaptation of which is depicted in Figure 4. In this structure the information flo ws from input to output through t wo path wa ys in parallel. The left path wa y inv olves a typical con volution la yer with configurable parameters: the k ernel size k , num b er of kernels n , and the dilation factor d . The conv olution in the right pathw ay uses kernels of size one (the dilation factor is irrelev ant in that case), and th us do es not compute an y features from the input. Instead, it outputs n linear combinations of the input in order to make the input shap e compatible for element wise addition to the n fe atur e maps of the left path wa y . Both pathw a ys further include a batc h normalization op eration. After the elemen twise sum of b oth pathw ays a rectified linear unit allows for a non-linear resp onse. The term “residual” refers to the fact that the left path wa y only needs to accoun t for the part of the output that cannot b e accounted for by linear com- binations of the input—the right path wa y . In this wa y , increasing the num b er 9 Input Dense la y er Batc h Norm ReLU Output Standard Block Input Con volution k , d , n Con volution 1, – , n Batc h Norm Batc h Norm + ReLU Output k : k ernel size d : dilation factor n : num b er of k ernels Residual Block Figure 4: Building blo c ks for the FFN and DRN models. Left: Standard blo c k comp osed of a dense linear la yer follow ed b y batc h normalization and a rectified- linear lay er (See Section 4.1); Righ t: Residual blo c k (See Section 4.2.2). of stack ed conv olution op erations do es not hamper the ability of the net work to accoun t for its output in terms of lo wer lev el features. 4.2.3 DRN arc hitecture Figure 4 shows the complete mo del consisting of multiple residual blo cks. Note that the residual blo cks maintain the original temp oral dimension of the data, whic h amounts to a size of 11025 for 0.5s of audio sampled at 22050Hz. The temp oral p o oling op eration reduces this n umber by down-sampling the output using window-wise av eraging, and is follo wed by tw o dense lay ers with in terme- diate batch-normalization and non-linearity in order to pro duce an estimated resonance attenuation factor. 4.3 Exp erimen ts In this section we describ e the training and ev aluation pro cedure of b oth mo del arc hitectures describ ed ab o ve. W e use the human ratings of the 150 trac ks gathered in the listening experiment to train and ev aluate both architectures. 4.3.1 Pro cedure Ev aluation Criterion Predicting optimal resonance atten uation factors for giv en tracks is a regression problem and as such an obvious choice is to use the mean squared error of the predictions with resp ect to the optimal v alue (the tar get ) as an ob jective to b e minimized. How ever, given the v ariance in the ratings across sub jects in the ground truth, it may b e hard to determine a unique optimal v alue p er track. Using the mean or median of the ratings p er track as a target has the drawbac k that the mean squared error ob jectiv e 10 0.5s Stereo PCM signal F eature Extraction Standard Blo ck . . . Standard Blo ck Dense lay er Resonance Atten uation F actor F eature F eedforward Net w ork 0.5s Stereo PCM signal Residual Blo ck k 1 , n 1 , d 1 . . . Residual Blo ck k N , n N , d N T emp oral p o oling Batc h Norm ReLU Standard Blo ck Dense lay er Resonance Atten uation F actor Dilated Residual Netw ork Figure 5: FFN and DRN arc hitectures. 11 do es not differentiate b et ween trac ks with different degrees of rater consensus. Ideally , w e wish to imp ose a low er p enalt y on errors from the mean rating when the rater consensus is low. W e do so by generalizing the mean squared error ob jective as follows. Rather than defining the ob jectiv e function to b e minimal only for a single v alue, we define it to b e minimal whenever the prediction lies within a specified interv al that v aries from one data instance to another. F or a giv en data instance consisting of an audio track A ∈ A and a set of ratings F w e define the zero p enalt y interv al as [ P l ( F ) , P h ( F ) ], where P l ( F ) and P h ( F ) denote the l -th and h -th percentiles of the ratings F , resp ectively , with l ≤ h . W e refer to this ob jectiv e as the me an squar e d b ounds errr or with bounds l , h , or MSBE ( l , h ) . W e use l = 35 and h = 65 throughout the exp eriments. F ormally , giv en a dataset D consisting of pairs ( A, F ), the MSBE ( l , h ) of a mo del f : A → R is defined as: MSBE ( l , h ) ( f , D ) = 1 | D | X ( A, F ) ∈ D L ( l, h ) A, F ( f ) , (3) where L ( l, h ) A, F ( f ) = [ f ( A ) − P h ( F ) ] + + [ f ( A ) − P l ( F ) ] − 2 . (4) The brack ets [ · ] + and [ · ] − denote the p ositive and negativ e parts resp ec- tiv ely . Hyp er-parameter optimization W e use Bay esian optimization to find the optimal hyper-parameters for each of the mo dels, most importantly the depth of the netw orks and the hidden la yer sizes. This is a heuristic to sp eed up the searc h for appropriate hyper-parameter v alues compared to an exhaustiv e grid search. The particular form of optimization we use is based on a gaussian pro cess appro ximation of the loss as a function of the h yp er-parameters. This appro ximation gives rise to the upp er c onfidenc e b ound [21], which estimates the exp ected loss for hyper-parameter settings that hav e not yet been tested, and is used as a guide to search the space of hyper-parameters [22]. Apart from the depth of the models and the hidden la y er sizes, the optimiza- tion inv olved h yp er-parameters to control the training pro cedure: the le arning r ate , and the thresholds for e arly stopping , and le arning r ate r e duction . Cross-v alidation T o p erform the h yp er-parameter optimization w e use tw o partitions of the dataset into a test set (10 trac ks), a v alidation set (10 tracks), and a train set (130 tracks). F or each of the test tracks we compute the MSBE ( 35 , 65 ) loss on 100 randomly selected 0.5s frames. The criterion used to optimize the hyper-parameters is the av erage frame-wise loss across b oth test sets. With the b est hyper-parameters found for the FFN and DRN arc hitectures, resp ectiv ely , we p erform a further five fold cross-v alidation. T o this end, we use the same dataset, but exclude the 20 test tracks used for h yp er-parameter optimization. W e rep eat the five fold cross v alidation fiv e times using different 12 T able 3: Optimal configuration for the FFN and the DRN arc hitectures as found b y h yp er-parameter optimization. FFN DRN Depth 3 Std. Blo c ks 10 Res. Blo c ks Blo c k Size (Lo w/Mid/High) 500 / 250 / 250 100 / 100 / 300 T emp oral Pooling – 300 Final Std. Blo c k Size – 10 T able 4: Means, standard deviations, and the 95% confidence interv al (CI) for the mean MSBE ( 35 , 65 ) p er mo del. 95% CI Mo del Mean Std. dev. Lo w High Baseline 0 . 237 0 . 103 0 . 194 0 . 280 FFN 0 . 159 0 . 082 0 . 124 0 . 194 DRN 0 . 154 0 . 080 0 . 121 0 . 188 random seeds to reduce the effect of partitioning of the data into folds and mo del parameter initializations on the result. Baseline W e define a baseline approach as a reference for ev aluating the FFN and DRN architectures. This approac h consists in computing the mean reso- nance attenuation factor observed ov er all tracks in the training set, and using this v alue as a prediction for the test set, irresp ectiv e of the input audio. 4.3.2 Results and discussion The optimal configuration for the FFN and the DRN architectures, as found by h yp er-parameter optimization, are shown in T able 3. Figure 6 shows the results of these architectures on the rep eated five fold cross v alidations. A one-wa y rep eated measures ANO V A rev eals a significant effect of model on MSBE ( 35 , 65 ) ( F 2 , 72 = 6 . 55, p = 0 . 002). A p ost-ho c T ukey HSD test at α = 0 . 05 indicates that DRN and FFN differ significan tly from the baseline. The effect size of DRN o ver baseline corresp onds to Cohen’s d = 0 . 88, whereas the FFN o ver baseline effect size is d = 0 . 82. The difference b etw een DRN and FFN is not significant. T able 3 shows that the FFN arc hitecture w orks b est when it is comparativ ely shallo w (three standard blo cks, the minimal depth tested), whereas the DRN arc hitecture p erforms b etter when it is deep (10 residual blo c ks, the maximal depth tested). This trend is consistent in a review of the 10 b est FFN and DRN arc hitectures as found in the hyper-parameter optimization, omitted here for the sak e of brevity . The la yer sizes ho w ever do not show a similarly consisten t trend, and v ary considerably throughout the 10 b est FFN and DRN arc hitectures. The fact that both mo deling approaches show similar accuracies on the at- ten uation factor prediction is in line with a general trend that arises from the deep learning literature, sho wing that curren t techniques in deep learning are p o w erful enough to w ork with raw digitizations of information—such as sampled 13 Baseline DRN FFN Model 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 A v erage MSBE ( 35 , 65 ) per run Figure 6: Average MSBE ( 35 , 65 ) p er run for baseline, FFN, and DRN models; The horizontal lines in the b o xes indicate the median, triangles the mean v alues p er mo del. w av eforms—and still address tasks that require considerable abstraction from that lo w level representation, th us reducing the need for hand designed features. A t the same time, it must b e noted that the roughly equiv alent p erfor- mance of the FFN and DRN measured here is at o dds with a multitude of cases where end-to-end deep netw orks clearly outp erform prior state -of-the-art meth- o ds that rely on a hand-designed feature extraction stage, esp ecially in image pro cessing [23]. F or audio tasks such as automatic tagging ho wev er, end-to- end netw orks do not seem to ha ve a strong adv antage ov er spectrogram-based approac hes [24], and require large training data sets in order to outp erform sp ectrogram-based approaches in audio tagging tasks [25]. Similarly , in the study presented here the small size of the data set—especially in com bination with in ter-sub ject v ariance and the non-uniform distribution of the ratings—is a plausible explanation of wh y the DRN does not outp erform the FFN. 5 Conclusion In this paper we addressed the problem of automatic resonance equalization. W e ha ve prop osed a method to atten uate automatically iden tified resonances by a user-con trolled factor. Using this metho d w e carried out a listening exp erimen t in which sound engineers iden tify optimal attenuation factors for a set of audio trac ks. The results, which sho w general consensus in ratings among sub jects, w ere used to train and ev aluate tw o types of predictive mo dels to estimate optimal resonance attenuation factors based on the con tent of the audio tracks. 14 The results show that an intermediate stage of feature extraction is not strictly necessary for this task: a dilated residual netw ork performs equally well when applied directly to the audio signal. The prop osed system is a fully auto-adaptive resonance equalization sys- tem in which the atten uation factor is c hosen automatically b y a deep neural net work. T o our knowledge, this system is the first do cumented self-adaptiv e equalizer based on neural net works. F uture work includes a real-time implemen- tation of the presented mo del as a real-time plugin that can be used in audio w ork stations. References [1] J. Bitzer, J. LeBo euf, “Automatic detection of salient frequencies,” pre- sen ted at the A udio Engine ering So ciety Convention 126 (2009). [2] B. De Man, J. D. Reiss, “A knowledge-engineered autonomous mixing sys- tem,” presented at the Audio Engine ering So ciety Convention 135 (2013). [3] Z. Ma, J. D. Reiss, D. A. Black, “Implementation of an intelligen t equal- ization to ol using Y ule-W alker for music mixing and mastering,” presen ted at the A udio Engine ering So ciety Convention 134 (2013). [4] M. B. Cartwrigh t, B. Pardo, “So cial-EQ: Crowdsourcing an Equalization Descriptor Map.” presen ted at the ISMIR , pp. 395–400 (2013). [5] D. Reed, “A Perceptual Assistan t to Do Sound Equalization,” presen ted at the 5th International Confer enc e on Intel ligent User Interfac es , pp. 212– 218 (2000). [6] S. Hafezi, J. D. Reiss, “Autonomous multitrac k equalization based on mask- ing reduction,” Journal of the Audio Eng. So c. , vol. 63, no. 5, pp. 312–323 (2015). [7] E. T. Chourdakis, J. D. Reiss, “A Machine-Learning Approach to Appli- cation of Intelligen t Artificial Reverberation,” J. Audio Eng. So c. , v ol. 65, no. 1/2, pp. 56–65 (2017). [8] S. I. Mimilakis, K. Drossos, T. Virtanen, G. Sc huller, “Deep Neural Net- w orks for Dynamic Range Compression in Mastering Applications,” pre- sen ted at the A udio Engine ering So ciety Convention 140 (2016 May). [9] S. I. Mimilakis, E. Cano, J. Ab eßer, G. Sch uller, “New Sonorities for Jazz Recordings: Separation and Mixing using Deep Neural Net works,” pre- sen ted at the 2nd AES Workshop on Intel ligent Music Pr o duction (2016). [10] J. Bitzer, J. LeBo euf, U. Simmer, “Ev aluating p erception of salien t fre- quencies: Do mixing engineers hear the same thing?” presen ted at the A udio Engine ering So ciety Convention 124 (2008). [11] J. Reiss, Ø. Brandtsegg, “Applications of cross-adaptive audio effects: au- tomatic mixing, live p erformance and everything in b et ween,” F r ontiers in Digital Humanities , vol. 5, p. 17 (2018). 15 [12] G. McCandless, D. McInt yre, The Cr aft of Contemp or ary Commer cial Mu- sic (Routledge) (2017). [13] International Standardization Organization, “ISO 226:2003: Acoustics– Normal equal-loudness-level con tours,” Genev a, Switzerland. [14] EBU-R-128, “BU T ech 3341-2011, Practical Guidelines for Pro duction and Implemen tation in Accordance with EBU-R-128,” (2011). [15] D. Bogdano v, N. W ac k, E. Gomez, S. Gulati, P . Herrera, O. May or, G. Roma, J. Salamon, J. R. Zapata, X. Serra, “Essentia: an audio analysis library for music information retriev al,” presented at the 14th International So ciety for Music Information R etrieval Confer enc e (2013 Nov ember 4-8). [16] P . Bo ersma, “Accurate short-term analysis of the fundamental frequency and the harmonics-to-noise ratio of a sampled sound,” presen ted at the IF A 17 , pp. 97–110 (1993). [17] Y. Lecun, L. Bottou, Y. Bengio, P . Haffner, “Gradient-based learning ap- plied to do cument recognition,” presented at the IEEE , vol. 6, pp. 2278– 2324 (1998). [18] F. Y u, V. Koltun, “Multi-Scale Con text Aggregation by Dilated Con volu- tions,” CoRR , v ol. abs/1511.07122 (2015). [19] K. He, X. Zhang, S. Ren, J. Sun, “Deep Residual Learning for Image Recognition,” presented at the IEEE Confer enc e on Computer Vision and Pattern R e c o gnition CVPR , pp. 770–778 (2016). [20] F. Y u, V. Koltun, T. A. F unkhouser, “Dilated Residual Netw orks,” CoRR , v ol. abs/1705.09914 (2017). [21] T. Lai, H. Robbins, “Asymptotically Efficien t Adaptive Allo cation Rules,” A dv. Appl. Math. , vol. 6, no. 1, pp. 4–22 (1985 Mar.). [22] J. Sno ek, H. Laro chelle, R. P . Adams, “Practical bay esian optimization of mac hine learning algorithms,” presen ted at the A dvanc es in neur al infor- mation pr o c essing systems , pp. 2951–2959 (2012). [23] L. Zheng, Y. Y ang, Q. Tian, “SIFT meets CNN: A decade survey of instance retriev al,” IEEE tr ansactions on p attern analysis and machine intel ligenc e , v ol. 40, no. 5, pp. 1224–1244 (2018). [24] S. Dieleman, B. Schrau wen, “End-to-end learning for music audio,” pre- sen ted at the IEEE Int. Conf. on A c oustics, Sp e e ch and Signal Pr o c essing (ICASSP) , pp. 6964–6968 (2014). [25] J. P ons, O. Nieto, M. Pro c kup, E. M. Schmidt, A. F. Ehmann, X. Serra, “End-to-end learning for music audio tagging at scale,” presen ted at the Workshop on Machine L e arning for Audio Signal Pr o c essing (NIPS) (2017). 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment