Hierarchical Event-triggered Learning for Cyclically Excited Systems with Application to Wireless Sensor Networks
Communication load is a limiting factor in many real-time systems. Event-triggered state estimation and event-triggered learning methods reduce network communication by sending information only when it cannot be adequately predicted based on previous…
Authors: Jonas Beuchert, Friedrich Solowjow, J"org Raisch
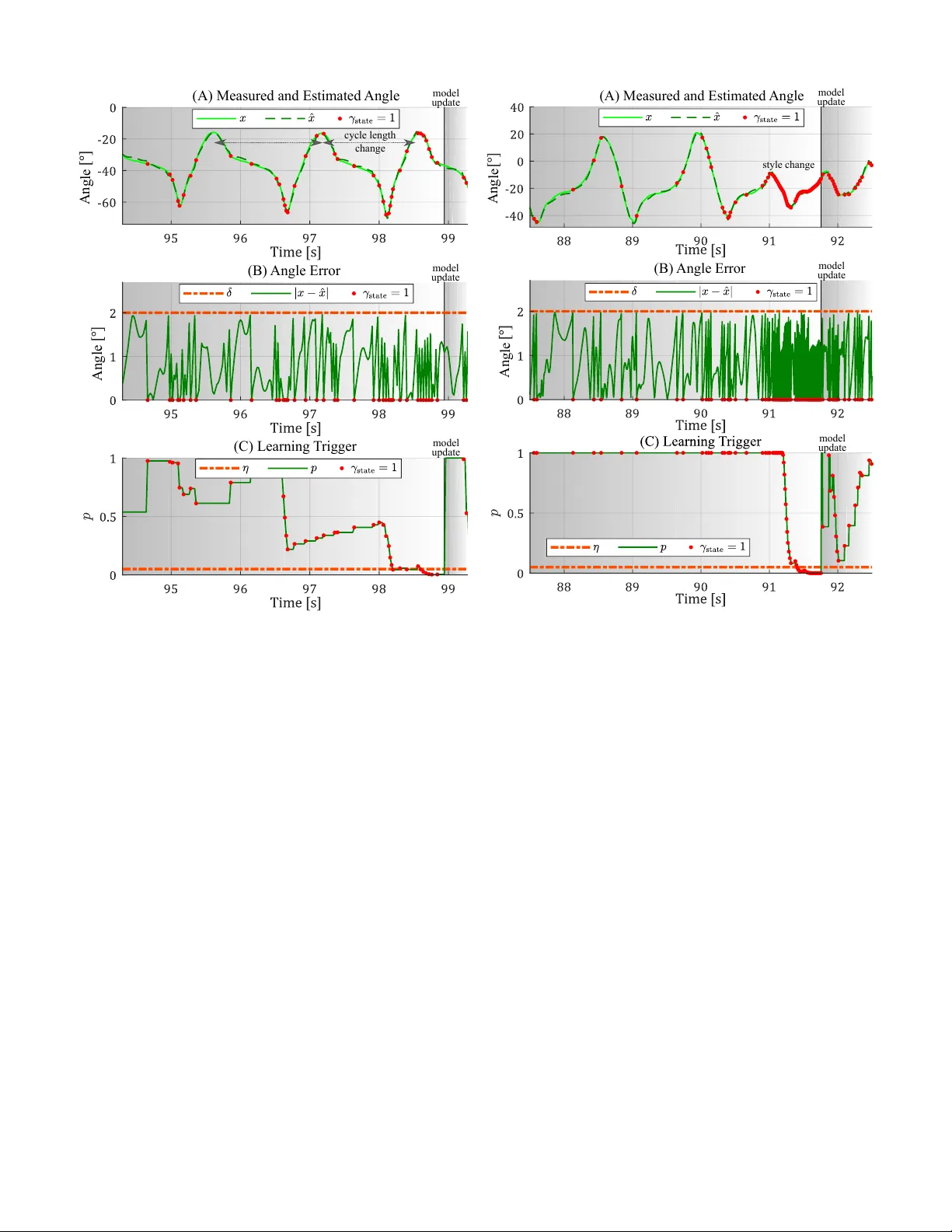
Hierarchical Ev ent-triggered Learning for Cyclically Excited Systems with Application to W ireless Sensor Networks* Jonas Beuchert 1 , Friedrich Solo wjow 2 , J ¨ org Raisch 1 , Sebastian T rimpe 2 , and Thomas Seel 1 ©2019 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating ne w collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works. Abstract —Communication load is a limiting factor in many real-time systems. Event-trigger ed state estimation and event- triggered learning methods reduce network communication by sending information only when it cannot be adequately predicted based on pre viously transmitted data. This paper proposes an event-trigger ed learning appr oach for nonlinear discr ete- time systems with cyclic excitation. The method automatically recognizes cyclic patter ns in data – e ven when they change repeatedly – and reduces communication load whenever the current data can be accurately predicted fr om previous cycles. Nonetheless, a bounded error between original and receiv ed sig- nal is guaranteed. The cyclic excitation model, which is used f or predictions, is updated hierarchically , i.e., a full model update is only performed if updating a small number of model parameters is not sufficient. A nonparametric statistical test enforces that model updates happen only if the cyclic excitation changed with high probability . The effectiveness of the proposed methods is demonstrated using the application example of wireless real- time pitch angle measur ements of a human foot in a feedback- controlled neuroprosthesis. The experimental results show that communication load can be reduced by 70 % while the root- mean-square err or between measured and recei ved angle is less than 1 ◦ . Index T erms —sensor networks, statistical learning I . I N T RO D U C T I O N M ANY applications require real-time transmission of signals over communication channels with bandwidth limitations. A typical example is gi ven by wireless sensor networks in feedback-controlled systems. The number of agents (i.e., network nodes) and their communication rate is limited by the amount of information the wireless network can transmit in real-time. It is, therefore, desirable to reduce the communication load without compromising the accuracy of the transmitted signals. W ell known approaches are ev ent-based sampling [1]–[3] and event-triggered state estimation (ETSE [4]–[6], sometimes referred to as model-based ev ent-based sampling [7]): At each sampling instant, the receiving agent independently predicts the state, which is measured by the sender , based on previous *The work of F . Solowjow and S. Trimpe was supported in part by the Max Planck Society , the IMPRS-IS, and the Cyber V alley Initiativ e. 1 Jonas Beuchert, J ¨ org Raisch, and Thomas Seel are with Control Systems Group, T echnische Universit ¨ at Berlin, 10587 Berlin, Germany jonas.beuchert@campus.tu-berlin.de, seel@control.tu-berlin.de . 2 Friedrich Solowjo w and Sebastian Trimpe are with Intelligent Control Systems Group, Max Planck Institute for Intelligent Systems, 70569 Stuttgart, Germany solowjow@is.mpg.de, trimpe@is.mpg.de . network cycl ic patt ern repea ted mode l identi- fica tion and sha ring origina l signal esti ma ted signal rece iving agent sending agent comm unica tion reduce d Fig. 1. Event-triggered learning in a two-agents network. If the measured signal (e.g., a human foot angle) can be described by a cyclically e xcited system model, the model is shared with the recei ver and the communication is reduced to those samples that cannot be predicted using the model and previously transmitted data. Inaccuracy of the model (e.g., due to change in walking pattern) is detected and a new model is identified and shared. estimations and a model. The sender performs the identical prediction and communicates the measured state if and only if the error between prediction and measurement exceeds a predefined threshold. Otherwise, there is no communication and the receiving agent uses the model-based prediction as estimation (cf. Fig. 1). Since the prediction accurac y heavily depends on the quality of the utilized model, it was recently proposed to learn and update models in an ev ent-triggered fashion as well [8]. Occurrence of communication is treated as a random v ariable, and the model is updated when empirical data does not fit the probability distrib ution that w ould result if the model was the truth. The present paper builds on the idea of [8] and dev elops ev ent-triggered learning (ETL) methods for c yclically excited systems. The main contributions are: • Extension of the concept of ETL to specifically target systems with a locally cyclic excitation. Locally means that cycles close in time are almost identical; howe ver , cycles that are far apart are not necessarily similar . This class of systems is useful for describing both biological and technical processes (e.g., human motion, breath, heartbeat, and production cycles). • Utilization of a learning trigger tailored to the problem at hand (one-sided K olmogorov-Smirno v test [9]), which fires with high probability in case of a model change and with low probability otherwise. • Introduction of the novel idea of a hierarchical model learning strategy , which updates and communicates only a reduced number of model parameters whenev er that is sufficient. • Demonstration of significant communication savings (70 %) using experimental data from cyclic human mo- tion collected with a wearable inertial sensor network. This is the first application of ETL on real-world network data. The paper continues as follows. After defining the consid- ered problem in Sec. II, the ev ent-triggered learning architec- ture from [8] is briefly explained in Sec. III and then extended to cyclically excited systems. Subsequently , the properties of the method are v alidated experimentally in Sec. IV. Finally , Sec. V provides conclusions. I I . S Y S T E M R E P R E S E N TA T I O N A N D P RO B L E M F O R M U L A T I O N Consider a discrete-time system with sample index k ∈ Z and state x [ k ] ∈ R n , which is measured by the sending agent. The system is assumed to be influenced by a cyclic input u [ k ] ∈ R m with cycle length N ∈ N + such that u [ k + N ] = u [ k ] and by zero-mean noise ε [ k ] ∈ R s , which is distributed according to a time-in variant probability distrib ution P . The recursiv e state update law of the system is characterized by the dynamics f : R n × R m × R s → R n , i.e., x [ k ] = f ( x [ k − 1] , u [ k ] , ε [ k ]) . (1) While the dynamics f is assumed to be kno wn, the excitation u [ k ] and its cyclicity N are unknown and may change with time. In the following, whenev er the term model is used, it refers to an approximation of the cyclic excitation u [ k ] . The distribution P of the noise ε [ k ] is known. This paper considers architectures with one sending and one receiving agent. Howe ver , the methods can be directly applied to multi-agent systems and yield the same adv antages therein. The sending and receiving agents have the follo wing capa- bilities, which will be made precise in the next section: • the sender can transmit measured data samples to the receiv er , i.e., perform state updates ; • sender and receiver can estimate current data samples from previously transmitted data and a model, i.e., per- form predictions ; • the sender can estimate excitation trajectories from mea- sured data, i.e., perform model identification ; • the sender can send model parameters to the receiv er , i.e., perform model updates . The main objective is to find a joint strategy for the sender and the receiv er such that the amount of communication (state and model updates) is reduced while the error between the actual measurement signal x [ k ] and the signal estimate ˆ x [ k ] ∈ R n on the receiv er side remains small in the sense of a suitable metric k· , ·k : R n × R n → R + 0 . I I I . A L G O R I T H M D E S I G N The proposed ev ent-triggered learning approach for cycli- cally excited systems is illustrated in Fig. 2. It can be described by the following building blocks: • T wo identical predictors that estimate the measured state x [ k ] based on an internal state ˆ x [ k − 1] and an estimated excitation trajectory ˆ u ∈ R m × ˆ N of one cycle with estimated cycle length ˆ N ∈ N + . • A binary state-update trigger γ state [ k ] ∈ { 0 , 1 } that determines when to update the internal state ˆ x [ k ] of the predictors with the measurement x [ k ] to ensure a bounded error k x [ k ] , ˆ x [ k ] k of the estimation. • A model learning block that estimates the excitation tra- jectory ˆ u used by the predictors or updates the estimated parameters ϑ ∈ R v (e.g., cycle length or amplitude) of the current trajectory ˆ u . • A binary learning trigger γ learn [ k ] ∈ { 0 , 1 } that deter- mines when to update the internal excitation trajectory model ˆ u of the predictors. Ideally , learning shall be triggered if and only if the rate of state updates increases due to a false or inaccurate model ˆ u . A. Pr ediction Let the current model of the cyclic excitation u [ k ] be described by the aforementioned matrix ˆ u such that the current excitation is the ( j [ k ]) th column of ˆ u , i.e., ˆ u j [ k ] is the estimated value of u [ k ] , where the index j [ k ] obeys j [ k + 1] = ( j [ k ] + 1 if γ learn [ k ] = 0 ∧ j [ k ] < ˆ N 1 if γ learn [ k ] = 1 ∨ j [ k ] = ˆ N . (2) The inde x j [ k ] is increased after every prediction step, unless the end of the estimated excitation trajectory is reached ( j [ k ] = ˆ N ) or learning is triggered ( γ learn [ k ] = 1 ). The estimate ˆ x [ k ] is determined by ˆ x [ k ] = ( f ˆ x [ k − 1] , ˆ u j [ k ] , 0 if γ state [ k ] = 0 x [ k ] if γ state [ k ] = 1 . (3) B. State-update T rigger If d [ k ] = x [ k ] , f ˆ x [ k − 1] , ˆ u j [ k ] , 0 reaches or exceeds the predefined threshold δ , then a state update as defined in Sec. III-A is triggered γ state [ k ] = ( 0 if d [ k ] < δ 1 if d [ k ] ≥ δ . (4) T riggers that compare the actual value to a model-based prediction are common in ETSE (cf. [1], [4]–[7], [10]–[12]). Because a state update ( γ state [ k ] = 1 ) leads to zero error, (3) and (4) together ensure that k x [ k ] , ˆ x [ k ] k is bounded by δ . C. Robust Learning T rigger If the model (the estimated excitation trajectory ˆ u ) is exact, then state updates occur only due to noise ε [ k ] . If the model no longer yields valid predictions of the current data, the time durations between two consecuti ve state updates will decrease. The learning trigger aims at detecting this decrease and then triggering a model update. Let the inter-communication time be the discrete time du- ration (number of samples) between two consecuti ve state up- dates and collect these times τ 1 , τ 2 , . . . , τ i in a buf fer, which is emptied whenev er model learning is triggered ( γ learn [ k ] = 1 ). Perform Monte Carlo (MC) simulations of (1), (3), and (4) for the case in which the model ˆ u is perfect and state updates occur only due to noise. This yields a hypothetical e a s i l y e xt e n de d t o a m u l t i - a g e n t s y s t e m . S p e c i f i c a l l y , t h i s p a p e r m a k e s t h e f o l l o w i ng c o n t r i bu t i o n s : … A . S t r u c t ur e o f t h i s Pu b l i c a t i o n A f t e r d e f i ni n g t h e c o n s i d e r e d p r o b l e m i n I I , S ol o w j o w ’ s e v e nt - t r i gg e r e d l e a r n i ng a r c hi t e c t ur e i s br i e f l y e x p l a i n e d i n I I I f o l l o w e d b y e x t e ndi n g i t t o t a r g e t e nh a n c e d p e r f o r m a n c e f or t he s p e c i f i c p r obl e m o f c y c l i c a l l y e xc i t e d s y s t e m s . A f t e r d i s c us s i n g t h e c l os e d l o o p p r op e r t i e s o f t h e p r o pos e d m e t ho d i n I V , i t i s va l i d a t e d i n V u s i ng t h e e xa m p l e o f c y c l i c h u m a n m o t i o n a n d a w e a r a b l e i ne r t i a l s e n s o r n e t w o r k ( F i gur e 1 ) . T h e d e s i gn o f t he s e bod y s e n s o r n e t w or k s o f t e n m u s t c on s i de r t he l i m i t e d b a ndw i d t h a n d, t h e r e f o r e , r e duc e s t h e n um b e r of s e n s o r s or t h e t i m e r e s o l u t i o n of t he t r a ns m i t t e d s i g n a l s [ 1] . A c on c l u s i on ( V I ) p r o vi d e s … I I . S Y S T EM R EP R E S EN TA T I O N A N D P R O B L EM F O R M U L A T I O N A t i m e di s c r e t e s y s t e m w i t h s a m p l e i n d e x 𝑘 ∈ ℤ a n d a s s o c i a t e d 𝑛 - d i m e n s i o n a l m e a s u r a b l e s t a t e 𝑥 [ 𝑘 ] ∈ ℝ i s c on s i d e r e d a n d a s s um e d t o ha v e a c y c l i c e x c i t a t i o n 𝑢 [ 𝑘 ] ∈ ℝ w i t h c y c l e l e ngt h 𝑁 ∈ ℕ : 𝑢 [ 𝑘 + 𝑁 ] = 𝑢 [ 𝑘 ] . I n c o r po r a t i n g G a u s s i a n n o i s e 𝜀 [ 𝑘 ] ∈ ℝ , 𝜀 [ 𝑘 ] ~ 𝒩 ( 0 , Σ ) , Σ ∈ ℝ × , a n d p o s i t i ve d e f i ni t e Σ , i t s r e c u r s i ve u p da t e l a w i s g i v e n by 𝑥 [ 𝑘 ] = 𝑓 ( 𝑥 [ 𝑘 − 1 ] , 𝑢 [ 𝑘 ] , 𝜀 [ 𝑘 ] ) , ( 1 ) w h e r e 𝑓 ∶ ℝ × ℝ × ℝ ↦ ℝ i s t h e d y n a m i c o f t h e s y s t e m . The s t a t e 𝑥 [ 𝑘 ] i s m e a s ur e d b y t h e s e nde r a n d 𝑥 [ 𝑘 ] ∈ ℝ d e n ot e s t h e p r e d i c t e d s t a t e p r o v i d e d b y t he r e c e i v i n g a ge nt . E v e n t - t r i g ge r e d s t a t e e s t i m a t i o n ( ET S E) w i t h t h e s e n d - o n- d e l t a c o n c e p t ( [ 4 ] ) gua r a n t e e s a bo un d e d e r r or b e t w e e n t he s e n d e r ’ s m e a s ur e m e nt a n d t h e r e c e i v e r ’ s pr e d i c t i o n ‖ 𝑥 [ 𝑘 ] , 𝑥 [ 𝑘 ]‖ < 𝛿 ∈ ℝ b a s e d o n a m e t r i c ‖ ⋅ , ⋅ ‖ ∶ ℝ × ℝ ↦ ℝ a nd t r i e s t o m i n i m i z e t h e ne t w o r k c om m u ni c a t i o n a t t h e s a m e t i m e . N e t w o r k c o m m u n i c a t i on c on s i s t s o f s t a t e a n d m o de l u p da t e s , i f e ve nt - t r i g ge r e d l e a r n i ng i s i m pl e m e n t e d i n a ddi t i o n t o E T S E. E v e n t - t r i g ge r e d l e a r ni n g i s a r e a s on a bl e e x t e n s i o n t o E T S E i f t he c y c l e d u r a t i o n 𝑁 a nd / o r t h e s h a p e o f t h e e x c i t a t i o n t r a j e c t or y i n ge n e r a l a r e i n v a r i a n t f or s om e t i m e i nt e r va l s , but c ha n g e du e t o c e r t a i n e v e nt s i n t i m e . Th e s p e c i f i c g o a l o f t h i s p u b l i c a t i o n i s t o d e r i ve a n e ve n t - t r i gg e r e d l e a r n i n g s c h e m a f o r s y s t e m s w h i c h b e h a v e ( onl y ) l o c a l l y a s i nt r o du c e d a b ove ( 1 ) . T h e s c he m a s h ou l d gu a r a n t e e a b o u n d e d e r r o r a s w e l l a s a s i gn i f i c a n t l y r e du c e d n um b e r o f v a l u e s t h a t a r e c om m uni c a t e d be t w e e n t h e a g e nt s . T h e d y n a m i c 𝑓 o f t h e s y s t e m i s a s s u m e d t o be k n o w n a nd i t s s t a t e 𝑥 [ 𝑘 ] i s m e a s u r e d . I n c o n t r a s t t o t h a t , t he n o i s e 𝜀 [ 𝑘 ] , t he e x c i t a t i o n 𝑢 [ 𝑘 ] , a nd i t s c y c l i c i t y 𝑁 a r e u nkn o w n . O n l y t he d i s t r i b u t i o n o f t h e no i s e i n c l ud i n g i t s s t a n d a r d d e vi a t i o n Σ i s gi ve n. F i n a l l y , f o r t h e pr op os e d m e t hod i t i s ne c e s s a r y t h a t e v e r y e x c i t a t i o n 𝑢 [ 𝑘 ] c a n b e e s t i m a t e d b a s e d o n a f i ni t e n u m b e r o f s t a t e m e a s ur e m e n t s a nd kno w n d y n a m i c 𝑓 . I I I . E V EN T - T R I G G E R ED L E A R N I N G F O R C Y C L I C P R O C E S S ES T h e us e d e v e n t - t r i gg e r e d l e a r n i n g a r c hi t e c t u r e i s s h o w n i n F i g ur e 2 . F o r a c om p l e t e d e s c r i p t i on o f e v e nt - t r i gg e r e d l e a r ni n g f o r c y c l i c a l l y e x c i t e d s y s t e m s , d e f i n i t i o n s o f t h e b e h a v i or of t he f ol l ow i ng b l oc k s m u s t b e d e r i ve d: A pr e di c t o r w h i c h e s t i m a t e s t h e m e a s ur e d s t a t e 𝑥 [𝑘 ] b a s e d o n a n i nt e r na l s t a t e 𝑥 [ 𝑘 − 1 ] a nd a n e s t i m a t e d e x c i t a t i on t r a j e c t o r y 𝒖 ∈ ℝ × o f o n e c y c l e w i t h e s t i m a t e d c y c l e l e n g t h 𝑁 ∈ ℕ . A b i n a r y s t a t e - up d a t e t r i g g e r 𝛾 [ 𝑘 ] ∈ { 0 , 1 } w hi c h d e t e r m i n e s w h e n t o up d a t e t h e i nt e r n a l s t a t e 𝑥 [ 𝑘 ] of t he p r e d i c t o r w i t h t he m e a s ur e m e n t 𝑥 [ 𝑘 ] t o e n s u r e a b o un d e d e r r o r ‖ 𝑥 [ 𝑘 ] , 𝑥 [ 𝑘 ]‖ of t h e p r e d i c t i o n . A m ode l l e a r ni n g bl oc k w hi c h e s t i m a t e s t h e e x c i t a t i o n t r a j e c t o r y 𝒖 t ha t i s u s e d b y t h e pr e d i c t o r s o r u p d a t e s t he e s t i m a t e d p a r a m e t e r s 𝑞 ∈ ℝ ( e . g. c y c l e l e n g t h or a m p l i t u de ) o f t h e c u r r e n t t r a j e c t o r y 𝒖 ; 𝜃 ∈ ℕ i s t h e n u m b e r of p a r a m e t e r s . state-update trigger (III.B) process (II) network prediction (III.A) learning trigger (III.C) model learning (III.D, III.E, III.F) prediction (III.A) sending agent receiving agent 𝑥 [ 𝑘 ] 𝑓 𝑥 [ 𝑘 − 1 ] , 𝑢 [ ] , 0 𝛾 [ 𝑘 ] 𝜗 𝜗 𝒖 𝒖 𝑥 [ 𝑘 ] 𝑥 [ 𝑘 ] 𝛾 [ 𝑘 ] F i g ur e 2: E v e n t - t r i g g e r e d l e a r n i n g a r c h i t e c t u r e w i t h o n e s e n d i n g a n d o ne r e c e i v i ng a g e n t p r o p o s e d b y S o l o w j ow e t a l . [ 3 ] ; t h e t r a d i t i o n a l e v e n t - t r i g g e r e d s t a t e e s t i m a t i o n a r c hi t e c t u r e i s s h o w n i n b l a c k . Th e p r o c e s s p r ovi de s t he m e a s u r e d s t a t e 𝑥 [ 𝑘 ] a t e v e r y s a m pl e i n s t a n t 𝑘 . A t t h e s a m e t i m e , t he s t a t e i s e s t i m a t e d b y t h e p r e di c t i o n b l o c k s o f t he s e n d e r a n d t h e r e c e i v e r u s i n g t h e p r e v i o u s e s t i m a t i on 𝑥 [ 𝑘 − 1 ] a n d a t r a j e c t or y m o d e l o f t he e xc i t a t i o n 𝒖 . I f t h e n e w e s t i m a t i o n d i f f e r s s i g ni f i c a nt l y f r om t h e m e a s u r e d s t a t e , t h e n a s t a t e u p d a t e i s t r i g g e r e d ; t he i n t e r n a l s t a t e s o f b o t h p r e di c t i o n b l o c k s a r e s e t t o t he m e a s u r e d s t a t e . To o m a n y s t a t e up d a t e s i n c l o s e s u c c e s s i o n i nd i c a t e a po o r m o de l q ua l i t y a n d, t h e r e f o r e , t r i g g e r m o de l l e a r n i ng . T h i s c a n e i t h e r l e a d t o o n l y a n a dj u s t m e n t o f c e r t a i n p a r a m e t e r s 𝑞 o f t h e c ur r e nt m o d e l t r a j e c t o r y o r t o a c o m p l e t e l y n e w 𝒖 . I n a ny c a s e , t h e ne w m o d e l i n f o r m a t i on i s s ha r e d b e t w e e n s e n de r a n d r e c e i v e r . Fig. 2. One sending and one receiving agent with the typical event-triggered state estimation architecture in black and event-triggered learning in blue (extended from [8]). The process provides the measured state x [ k ] at ev ery sampling instant k . At the same time, the state is estimated by the prediction blocks of the sender and the receiver using the previous estimate ˆ x [ k − 1] and a trajectory model of the excitation ˆ u . If the prediction differs significantly from the measured state, then a state update is triggered, and the internal states of both prediction blocks are set to the measured state. T oo frequent state updates indicate poor model quality and, therefore, trigger model learning. This can either lead to only an adjustment of certain parameters ϑ of the current model trajectory or to a completely new excitation trajectory ˆ u . In any case, the new model information is shared between sender and receiver . cumulativ e distribution function F : N + → [0 , 1] of the inter- communication times. At each sample instant k , the afore- mentioned b uffer provides an empirical cumulati ve distrib ution function ˆ F k : N + → [0 , 1] of the previously observed inter- communication times; i.e., for any value τ ∈ N + , ˆ F k ( τ ) is the proportion of observed inter-communication times less than or equal to τ . The hypothetical and the empirical distribution function of the inter -communication times are compared by the one-sided two-sample K olmogorov-Smirnov test (KS-test) [9], [13], [14]. Its null hypothesis is that the empirical inter-communication times come from the hypothetical distrib ution F ( τ ) . The alternativ e hypothesis is that they come from a different one. The result of the test is an estimated probability p [ k ] ∈ [0 , 1] that the null hypothesis is true. It is compared with a defined significance lev el η ∈ [0 , 1] , i.e., the probability that the test rejects the null hypothesis although it is correct (type I error). If the p [ k ] -value is smaller than η for a predefined minimum holding time duration t min ∈ R + 0 , then a model update is triggered γ learn [ k ] = ( 0 if ∃ l ∈ [ k − t min , k ] : p [ l ] ≥ η 1 if p [ l ] < η ∀ l ∈ [ k − t min , k ] . (5) Note that the null hypothesis is always accepted if no inter- communication times were observed since the last model up- date. Furthermore, for a large class of systems, the hypothetical distribution F ( τ ) will not depend on ˆ u and, therefore, can be determined beforehand, i.e., no MC simulations must be performed in real time. Finally , for sufficiently simple systems, the distribution might ev en be determined analytically , and the one-sided one-sample KS-test can be used. Utilizing the KS-test to design learning triggers was first proposed in [15]. Density-based learning triggers use richer statistical information and have more advantageous properties than learning triggers that are based on the expected value as proposed in [8]. In contrast to [15], the current method uses a one-sided trigger condition because model updates are not required if the inter-communication times are larger than expected. The robustification with a minimum holding time t min prev ents model learning due to unmodeled short-term ef- fects. Furthermore, if a change of the process behavior occurs, then learning should not be triggered before the change is completed. For the theoretical properties of the statistical tests to hold, τ 1 , τ 2 , . . . , τ i are assumed independent and identically distributed (see [8], [15]). While this is not necessarily the case for ev ery system of the form (1), it holds, for e xample, for the application system considered in Sec. IV. D. Model Learning – Small Model Update The model learning block learns a new model trajectory ˆ u based on the pre vious measurements x [ k ] , x [ k − 1] , . . . Howe ver , transferring the complete trajectory ˆ u of a cycle from the sending to the receiving agent leads to a significant amount of communication. Therefore, it is assumed that, in some cases, an appropriate new model trajectory ˆ u + ∈ R m × ˆ N + with a new cycle length ˆ N + can be deriv ed from the old one by employing a parametric deformation function g : R m × ˆ N × R v → R m × ˆ N + with a small number of parameters ϑ ∈ R v such that ˆ u + = g ( ˆ u , ϑ ) . Whenev er a learning update is triggered, the learning block determines the parameters ϑ that lead to the best approxima- tion of the states measured during the last cycle: e ( k , ˜ ϑ ) = k X l = k − ˆ N + +1 k x [ l ] , ˜ x ˜ ϑ [ l ] k 2 , (6) E [ k ] = min ˜ ϑ e ( k , ˜ ϑ ) , ϑ = argmin ˜ ϑ e ( k , ˜ ϑ ) , (7) where ˜ x ˜ ϑ is the state obtained from simulating (1) with excitation ˆ u + = g ( ˆ u , ˜ ϑ ) and with initial state x [ k − ˆ N + ] . This value provides an estimate of how good the model would fit after a small update. Provided the small update is sufficient (see Sec. III-E), the parameters ϑ are transmitted to the receiver and, subsequently , the receiv er determines the new trajectory using the predefined function g and the previous model trajectory ˆ u . For a cyclic process, useful parameters could be cycle length, phase shift, or amplitude, which can be estimated using standard signal processing methods in frequency or time domain to lo wer the computational costs in comparison to solving the optimization problem (6) e xplicitly (for an example see Sec. IV). Learning of these parameters is always carried out as first step of the block model learning in Fig. 2. E. Learning-type T rigger The small update described above requires much less com- munication than an update of the full trajectory ˆ u , but might not always lead to sufficiently precise predictions. W e define a binary trigger γ full [ k ] ∈ { 0 , 1 } that indicates when a small update is not sufficient to achieve a satisfying performance improv ement. If the error E [ k ] exceeds a threshold α ∈ R + 0 , then a full update is triggered γ full [ k ] = ( 0 if γ learn [ k ] = 0 ∨ E [ k ] ≤ α 1 if γ learn [ k ] = 1 ∧ E [ k ] > α (8) and a new full trajectory ˆ u is identified and transmitted as detailed in Sec. III-F. Otherwise ( γ full [ k ] = 0 ), the sensor sends the parameters ϑ as small model update and both agents deform the previous excitation trajectory to obtain the new model ˆ u = ˆ u + . The triggers of both model updates and the state update exhibit a hierarchical dependency: A small model update is only ex ecuted if the (communication- wise cheaper) state updates occur too frequently . Like wise, a (communication-wise expensiv e) full model update is only carried out if a small model update is expected to be insuffi- cient. F . Model Learning – Full Model Update In case of a triggered full update, an appropriate new model ˆ u cannot be obtained from the pre vious one by applying the deformation g . Therefore, the excitation trajectory for the previously measured c ycle is estimated based on the a v ailable state measurements. W e assume that the dynamics f allow for estimating u [ k ] from a finite number of state measurements (as is the case in the considered application, see Sec. IV). This trajectory could be transferred directly to the recei ving agent via the network and used as a precise model by both prediction blocks for the following state estimations. Howe ver , sending all samples of the trajectory w ould require the netw ork to transfer many values in a short time interval. Therefore, the sender compresses the trajectory at first with polynomial regression and the receiver performs reconstruction to obtain ˆ u . Possible alternativ es to polynomial regression for com- pression are, e.g., wav elet transformation with thresholding of the coefficients [16], and (sparse) Gaussian process re gression [17], [18]. The entire approach described in Sec. III is summarized in Algorithm 1. Algorithm 1 ETL for Cyclically Excited Systems (Sender) if j < N then j ← j + 1 else j ← 1 . Update index (2) ˆ x ← f ( ˆ x, ˆ u j , 0) . Predict measurement (3) if k x, ˆ x k < δ then . Prediction error small (4) t ← t + 1 . Increase inter-communication time else . Prediction error large (4) ˆ x ← x . Update state with measurement (3) τ ← τ t . Store inter-communication time t ← 0 . Reset inter-communication time if KST est ( τ ) then l ← 0 else l ← l + 1 . KS-T est (5) x ← x x . Store measurement if l ≥ t min then . Minimum holding time reached (5) j ← 0 . Reset model trajectory index (2) τ ← ∅ . Empty inter-communication time buf fer ϑ ← estimateParam ( x ) . Small update parameter (6), (7) ˆ u ← g ( ˆ u , ϑ ) . Small model update (Sec. III-D) if tra jError ( ˆ u , x ) > α then . Small update poor (7), (8) ˆ u ← identifyU ( x ) . Full model update (Sec. III-F) I V . A P P L I C AT I O N : P I T C H A N G L E O F H U M A N F O OT T o demonstrate the ef fectiveness of the proposed algorithms, we consider a network of wearable sensor units comprising at least an inertial sensing chip, a wireless communication module, and a microcontroller , which is attached to a human body during gait. Such measurement systems are used for real-time biofeedback and control of robotic systems and neuroprostheses [19]. The rate at which the network can communicate reliably in real time is limited by the number of sensors. If the communication load between each sensor and the receiver can be reduced, higher base sampling rates or a larger number of sensors can be used. This challenge w as recently addressed using heuristic approaches [20]. W e now apply the proposed ETL methods to this problem. W e consider the specific example of real-time measurement of the foot pitch angle x [ k ] ∈ R in a feedback-controlled neuroprostheses [19] (cf. Fig. 1). The angle dynamics is mod- eled by cyclic increments u [ k ] ∈ R and zero-mean additiv e Gaussian noise ε [ k ] ∼ N 0 , σ 2 with standard deviation σ ∈ R + 0 , i.e., the state update is x [ k ] = x [ k − 1] + u [ k ] + ε [ k ] . (9) Equation (9) corresponds to (1) and is used for state pre- dictions. For the trigger (4), the absolute difference d [ k ] = | x [ k ] − ˆ x [ k ] | is used as a metric. V alidation is based on measurements of approximately 30 minutes of variable human gait including normal walking with frequent speed and ground inclination changes as well as style changes to different kinds of simulated pathological gait (straightened knee, drop foot, and dragged leg). While walking style changes lead to clearly dif ferent angle trajectories, small gait v elocity changes are well described by time warping of the angle trajectory , i.e., by cycle length changes of the periodic excitation u [ k ] . The small model update is, therefore, designed as follo ws: Determine the new c ycle length ϑ 1 = ˆ N and time shift ϑ 2 of ˆ u that best describe the measurements of the most recent cycle. Both parameters are estimated in the frequency domain (using the auto- or crosscov ariance of the measured states of a small number of pre vious cycles) and further refined in the time domain with local optimization 3 . For a full model update, (9) with ε [ k ] being zero-mean implies that an unbiased estimate of u [ k ] can be obtained by taking the difference of x [ k ] and x [ k − 1] . W e thus calculate ∆ x [ l ] := x [ l ] − x [ l − 1] ∀ l ∈ [ k − ˆ N + 1 , k ] and estimate the full trajectory as ˆ u = ∆ x [ k − ˆ N + 1] · · · ∆ x [ k ] , where k is the index of the sampling instant where learning is triggered. A. P arametrization The measurement sampling rate is set to 50 Hz. The accuracy of IMU-based foot pitch angle measurements is in the range of 3–4 ◦ [21]. Therefore, the maximum admissible angle error δ in (4) is set to 2 ◦ . The significance le vel for the KS-test (5) is set to η = 5 % . The accompanying minimum holding time is t min = 0 . 35 s · 50 Hz , which is about a third of a stride duration. The initial MC simulation to obtain F ( τ ) is carried out with 1000 trials and a standard de viation σ = 0 . 9 ◦ of the noise. This v alue is the observed root-mean-square-error (RMSE) during normal walking. The RMSE-threshold of the learning-type trigger (8) is α = 5 ◦ . Polynomial regression is chosen for compression of ˆ u . The degree is fixed to 18, which leads to a maximum of 20 communicated parameters including the constant offset and the estimated cycle length ˆ N . In contrast, the full trajectory of a stride typically contains 40–80 samples if the rate is 50 Hz. More parameters would increase the risk of overfitting. The MC simulation yields an expected inter-communication time ˆ E [ τ ] ≈ 8 . This implies that a state update is e xpected to happen ev ery 8 th sample on av erage if the model is correct. Furthermore, because of η = 5 % , ev ery 20 th state update is e xpected to trigger an undesired model update, which leads to transmission of either two or 20 model parameters. In total, the parametrization should result in not more than V ETL V full ≤ n + η w n · ˆ E [ τ ] = 1+0 . 05 · 20 8 = 25 % of transmitted v alues in comparison to full communication if the model is correct (i.e., whenev er gait style and velocity do not change). Finally , we initialize the model ˆ u of the excitation trajectory with a vector containing zeros. The first estimated model is transmitted when the first full model update is triggered. B. Results and Discussion The proposed ETL method is compared to alternati ve strate- gies by determining the number of transmitted values and the RMSE between the measured angle and the output of the receiv er . Results are visualized in Fig. 4. The trivial strategy of sending only ev ery second sample (decim.) yields an RMSE of almost 2 ◦ at 50 % communication rate. The same reduction of communication is achieved by pure ETSE (i.e., the scheme in Fig. 2, in black without ETL); howe ver , at an RMSE of less than 1 ◦ . ETL achieves a reduction of traffic to ev en less than 3 Code an detailed description on http://www .control.tu- berlin.de/ EventT riggeredLearning 100 50 48 29 27 full decim ETSE ETL h ETL o 0 50 100 0 1.9 0.8 0.9 0.9 full decim ETSE ETL h ETL o 0 1 2 Fig. 4. Number of transferred values V with respect to full communication V full (left) and resulting RMSE (right). W e compare full communication (full), decimation with factor 2 (decim), ev ent-triggered state estimation (ETSE), and two parametrizations of ev ent-triggered learning (ETL h / ETL o ) for about 0.5 h of highly variable gait. The results show that ETL reduces the communication significantly without changing the accurancy of the transferred signal in comparison to ETSE. 30 %, while the RMSE is still below 1 ◦ . Finally , optimizing the heuristically chosen parameters (ETL h ) with nested cross- validation (ETL o ) leads to small further improv ements (27 %). Fig. 5 sho ws how a small model update is triggered due to a change of the cycle length of the measured process, while Fig. 6 demonstrates how a change of the shape of the trajectory causes a full model update. Both figures also provide evidence that the absolute estimation error is bounded by δ = 2 ◦ . This represents a remarkable improvement with respect to the results in [20]. V . C O N C L U S I O N S A set of methods for e vent-triggered learning for cyclically excited systems is proposed to minimize communication in sensor networks. The approach automatically recognizes c yclic patterns in data – even when they change repeatedly – and reduces communication load whenev er the current data can be accurately predicted from previous cycles. In contrast to previous approaches, the current methods exploit explicitly the periodicity of the dynamics and account for time-v ariant behavior . Additional major adv antages of the methods are that they assure an upper bound on the error of the receiv ed signal and that unnecessary model updates occur only with a low probability , which is controlled by a user -defined significance lev el. The proposed methods are shown to yield significant re- source savings in a wireless body sensor netw ork for orienta- tion tracking of a human foot. The experimental results show that a lar ge reduction of communication load (by 70 %) and a small bounded estimation error (by 2 ◦ ) can be achiev ed at the same time. This means that up to three times as many sensors could be used without jeopardizing latency of the real-time communication. Moreover , the examined sampling rate of 50 Hz is relati vely low; up to 1 kHz is common in IMU networks (200 Hz in wireless ones), which giv es ev en more potential for resource savings with the proposed methods. Future research will focus on quaternion-based estimation of full body segment orientations and a learning trigger with less assumptions on inter-communication times. cycl e le ngth change update model update model update model (C) Learning T rigger Angle Angle (B) Angle Error (A) Measured and Estimated Angle Fig. 5. Small model update ( γ learn [ k ] = 1 ∧ γ full [ k ] = 0 ) triggered at 98.9 s due to a change of cycle length (gait velocity). (A) measured and estimated state; (B) error | x [ k ] − ˆ x [ k ] | and state-update trigger threshold δ ; (C) probability p [ k ] of the KS-test (5) and significance level η . Model learning is triggered because too many state updates ( γ state [ k ] = 1) occur and p [ k ] falls below η for the minimum holding time t min . R E F E R E N C E S [1] D. Laidig, S. Trimpe, and T . Seel, “Event-based sampling for reducing communication load in realtime human motion analysis by wireless inertial sensor networks, ” Current Dir ections in Biomedical Engineering , vol. 2, no. 1, pp. 711–714, 2016. [2] M. Miskowicz, Event-based contr ol and signal processing . CRC press, 2015. [3] M. Lemmon, “Event-triggered feedback in control, estimation, and optimization, ” in Networked Contr ol Systems . Springer, 2010, pp. 293– 358. [4] D. Shi, L. Shi, and T . Chen, “Event-based state estimation, ” Switzerland: Springer , 2016. [5] S. T rimpe and R. D’Andrea, “Event-based state estimation with variance-based triggering, ” IEEE T ransactions on Automatic Contr ol , vol. 59, no. 12, pp. 3266–3281, 2014. [6] J. Sijs and M. Lazar, “Event based state estimation with time syn- chronous updates, ” IEEE Tr ansactions on Automatic Contr ol , vol. 57, no. 10, pp. 2650–2655, 2012. [7] Q. Liu, Z. W ang, X. He, and D. Zhou, “ A surve y of e vent-based strate- gies on control and estimation, ” Systems Science & Contr ol Engineering: An Open Access Journal , vol. 2, no. 1, pp. 90–97, 2014. [8] F . Solowjo w , D. Baumann, J. Garcke, and S. T rimpe, “Ev ent-triggered learning for resource-efficient networked control, ” in American Contr ol Confer ence (ACC) , 2018, pp. 6506–6512. [9] F . J. Massey Jr, “The K olmogorov-Smirnov test for goodness of fit, ” Journal of the American Statistical Association , vol. 46, no. 253, pp. 68–78, 1951. [10] M. Miskowicz, “Send-on-delta concept: An e vent-based data reporting strategy , ” Sensors , vol. 6, no. 1, pp. 49–63, 2006. update model update model update model style cha nge Angle Angle (B) Angle Error (A) Measured and Estimated Angle Fig. 6. Full model update ( γ learn [ k ] = 1 ∧ γ full [ k ] = 1 ) triggered at 91.8 s due to a change of trajectory shape (walking style). Plotted signals and quantities are the same as in Fig. 5. [11] V . Nguyen and Y . Suh, “Networked estimation with an area-triggered transmission method, ” Sensors , vol. 8, no. 2, pp. 897–909, 2008. [12] S. T rimpe and M. C. Campi, “On the choice of the ev ent trigger in ev ent-based estimation, ” in Int. Conference on Event-based Contr ol, Communication, and Signal Processing (EBCCSP) , 2015, pp. 1–8. [13] L. H. Miller, “T able of percentage points of Kolmogoro v statistics, ” Journal of the American Statistical Association , vol. 51, no. 273, pp. 111–121, 1956. [14] G. Marsaglia, W . W . Tsang, J. W ang et al. , “Ev aluating K olmogorovs distribution, ” Journal of Stat. Software , vol. 8, no. 18, pp. 1–4, 2003. [15] F . Solowjo w and S. T rimpe, “Event-triggered learning, ” arXiv:1904.03042 , 2019. [Online]. A vailable: https://arxiv .org/abs/ 1904.03042 [16] A. Antoniadis and G. Oppenheim, W avelets and statistics . Springer Science & Business Media, 2012, vol. 103. [17] C. K. W illiams and C. E. Rasmussen, Gaussian pr ocesses for machine learning . MIT Press Cambridge, MA, 2006, vol. 2, no. 3. [18] J. Qui ˜ nonero-Candela and C. E. Rasmussen, “ A unifying view of sparse approximate gaussian process regression, ” Journal of Machine Learning Resear ch , vol. 6, no. Dec, pp. 1939–1959, 2005. [19] T . Seel, C. W erner , and T . Schauer, “The adaptive drop foot stimulator– multiv ariable learning control of foot pitch and roll motion in paretic gait, ” Med. Eng. & Physics , vol. 38, no. 11, pp. 1205–1213, 2016. [20] T . Zhang, D. Laidig, and T . Seel, “Stop repeating yourself: Exploitation of repetitiv e signal patterns to reduce communication load in sensor network, ” in Eur opean Contr ol Confer ence (ECC) , Naples, Italy , 2019, accepted. [21] T . Seel, D. Graurock, and T . Schauer, “Realtime assessment of foot orientation by accelerometers and gyroscopes, ” Curr ent Directions in Biomedical Engineering , vol. 1, no. 1, pp. 446–469, 2015.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment