Optimization of Energy Consumption Forecasting in Puno using Parallel Computing and ARIMA Models: An Innovative Approach to Big Data Processing
This research presents an innovative use of parallel computing with the ARIMA (AutoRegressive Integrated Moving Average) model to forecast energy consumption in Peru's Puno region. The study conducts a thorough and multifaceted analysis, focusing on …
Authors: Cliver W. Vilca-Tinta, Fred Torres-Cruz, Josefh J. Quispe-Morales
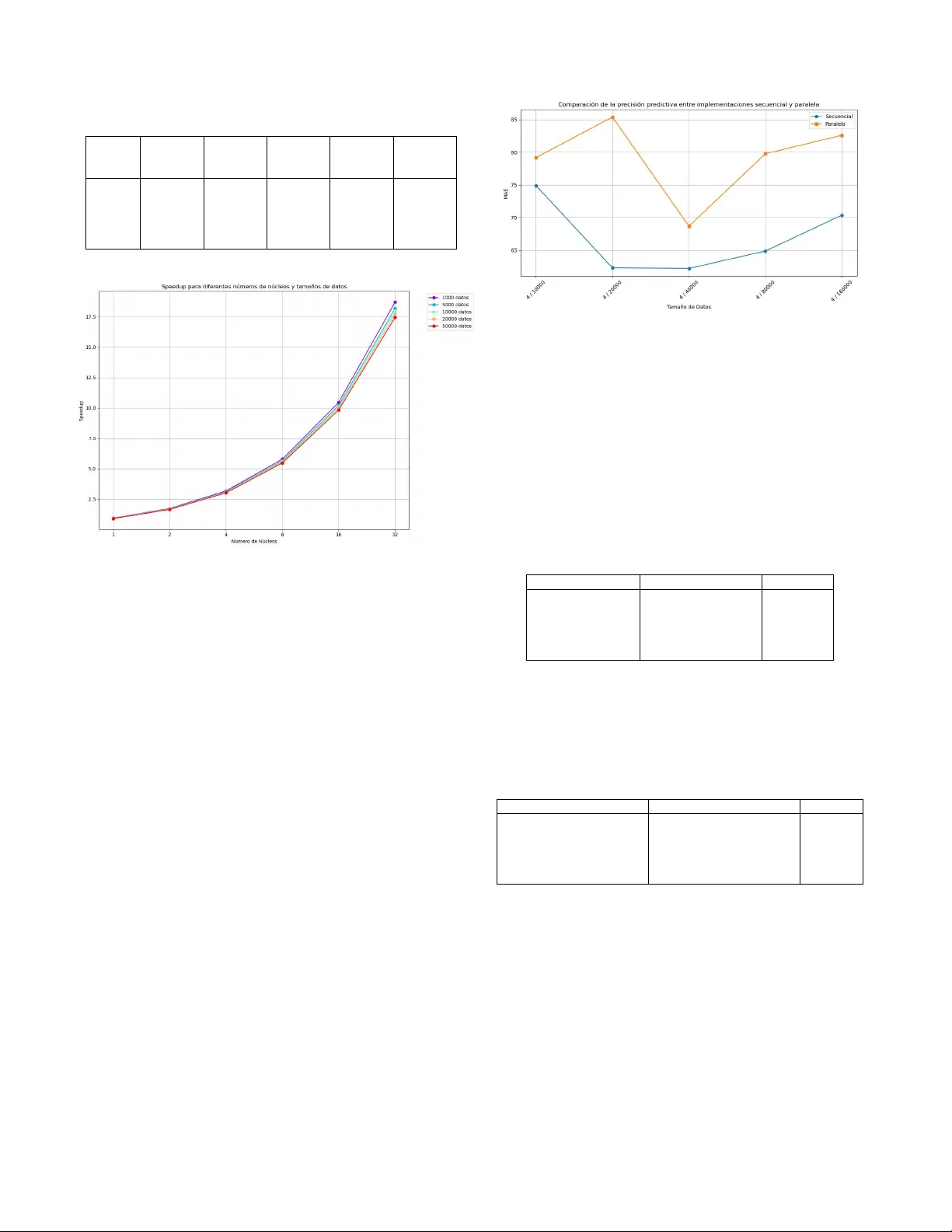
Optimization of Ener gy Consumption F orecasting in Puno using P arallel Computing and ARIMA Models: An Inno v ati v e Approach to Big Data Processing Cli ver-W imar V ilca-T inta F aculty of Statistics and Informatics Engineering National University of the Altiplano Puno, Perú clvilcat@est.unap.edu.pe Fred T orres-Cruz F aculty of Statistics and Informatics Engineering National University of the Altiplano Puno, Perú ftorres@unap.edu.pe Josefh-Jordy Quispe-Morales F aculty of Statistics and Informatics Engineering National University of the Altiplano Puno, Perú joquispemo@est.unap.edu.pe Abstract —This resear ch presents an innov ative use of parallel computing with the ARIMA (A utoRegressive Integrated Mov- ing A verage) model to forecast energy consumption in Peru’ s Puno region. The study conducts a thorough and multifaceted analysis, focusing on the execution speed, prediction accuracy , and scalability of both sequential and parallel implementations. A significant emphasis is placed on efficiently managing lar ge datasets. The findings demonstrate notable improv ements in computational efficiency and data processing capabilities through the parallel appr oach, all while maintaining the accuracy and integrity of predictions. This new method pr ovides a versa- tile and reliable solution for r eal-time predictive analysis and enhances energy r esource management, which is particularly crucial for developing areas. In addition to highlighting the technical advantages of parallel computing in this field, the study explores its practical impacts on energy planning and sustainable development in regions like Puno. Key w ords: ARIMA, parallel computing, energy for ecasting, big data, Puno, computational optimization, sustainable dev elop- ment. I . I N T R O D U C T I O N In the current era, marked by the expansion of big data and the growing need for real-time analytics, accurately and efficiently forecasting energy consumption has become a sig- nificant computational challenge. This challenge is especially relev ant in developing areas such as Puno, Peru [1], where op- timal management of energy resources is vital for sustainable progress. The exponential growth in energy demand, coupled with the ur gent need to implement sustainable management strategies, requires the dev elopment of adv anced analytical tools capable of processing large v olumes of historical data and generating accurate predictions in short periods of time [2]. In this context, the ARIMA (AutoRegressi ve Integrated Moving A verage) model has emerged as a robust and effecti ve statistical tool for the analysis and prediction of time series, demonstrating its effecti veness in v arious fields, including energy consumption forecasting [3]. Ho wev er, the application of ARIMA models to massiv e data sets presents significant computational challenges, particularly in terms of processing times and ef ficient use of computational resources [4]. These challenges are magnified in en vironments where technological resources may be limited, as is the case in many de veloping regions. Parallel computing emerges as a promising and transforma- tiv e solution to address these computational challenges. This innov ativ e approach offers the possibility of distrib uting the workload across multiple processors or cores, allo wing not only to process large volumes of data more efficiently , but also opening up new possibilities for real-time applications and more frequent and detailed analysis. [5, 6]. The implementation of parallel computing techniques in the context of energy consumption prediction presents multiple strategic advantages. First of all, it allows a significant re- duction of processing times, facilitating more frequent and updated analyses, crucial for agile decision making in energy management. [7]. In addition, it improves the ability to handle and analyze massi ve data sets, incorporating a greater amount of historical information and contextual variables, potentially leading to improved accuracy and rob ustness of predictions. [8] Another key advantage is the possibility of implementing real-time or near real-time forecasting systems, which are essential for the dynamic and adaptiv e management of smart grids, a critical aspect in the modernization of the energy infrastructure [9]. Finally , it offers greater flexibility to exper - iment with more complex model configurations and perform more comprehensive parameter optimizations, facilitating con- tinuous improvement of predictive performance [10]. This study focuses on the implementation and e valuation of a parallel v ersion of the ARIMA model, using Python and the multiprocessing library , comprehensi vely comparing its performance with a traditional sequential implementation. The main objecti ve is to demonstrate and quantify ho w parallel computing can transform and optimize the predicti ve analysis of energy consumption, especially in scenarios inv olving the processing of large volumes of data. The research addresses sev eral fundamental aspects related to the parallel implementation of the ARIMA model for energy consumption prediction. The performance improve- ment offered by the parallel implementation compared to the sequential one is examined in detail, ev aluating factors such as execution time and computational resource utilization. In addition, the scalability of the parallel implementation when processing increasing volumes of data is analyzed. A crucial aspect of the study is the ev aluation of the consistency in the accuracy and reliability of predictions when moving from a sequential to a parallel implementation. The practical and strategic implications of adopting parallel computing techniques for energy consumption prediction are also explored, with a particular focus on the context of Puno and regions with similar characteristics. The final objectiv e of this research is to provide valuable and applicable insights into how parallel computing can sig- nificantly improv e the efficiency , accuracy , and capacity of energy forecasting systems. The results of this study have particularly relev ant implications for strategic planning and energy resource management in dev eloping regions. In these contexts, resource optimization and data-dri ven decision mak- ing are crucial elements in achieving sustainable development. I I . R E V I S I O N S A. The Ener gy Sector in P eru The energy sector in Peru has experienced significant growth and di versification in recent decades, playing a crucial role in the country’ s economic de velopment. The country’ s energy matrix reflects this e volution. According to the Ministry of Energy and Mines [11], in 2020, approximately 60% of the electricity generated in Peru came from hydroelectric sources, followed by 37% from thermoelectric sources (mainly natural gas) and 3% from non-con ventional rene wable energies. Ac- cording to IRENA [12], the country has set ambitious goals to increase the share of renewable energy to 15 percent by 2030. The gro wth in energy demand has been remarkable. OS- INERGMIN [13] reports that electricity demand has gro wn at an annual av erage of 4.5% over the last decade, driv en by industrial dev elopment and increasing urbanization. Projec- tions indicate that this trend will continue, requiring significant in vestments in infrastructure. Howe ver , the sector faces significant regional challenges. W orld Bank data [14] re veal disparities in energy access between urban and rural areas. In 2019, while urban electricity cov erage reached 99%, in rural areas it was 85%. T amayo et al. [15] note that regions such as Puno face unique challenges due to their geography and climate, af fecting both energy distribution and consumption. In terms of policies and regulation, MINEM [16] reports that the sector is regulated mainly by the Ministry of En- ergy and Mines and the Supervisory Agency for Inv estment in Energy and Mining (OSINERGMIN). Policies hav e been implemented to promote energy efficienc y and the adoption of renewable energy , including renewable energy auctions and rural electrification programs. The challenges ahead are significant. COES [17] identifies the integration of intermittent renewable energy sources into the electricity grid and the modernization of transmission and distribution infrastructure as key challenges. Vásquez et al. [18] highlight the need to adapt to the impacts of climate change, especially in hydroelectric generation. In this context, the implementation of advanced energy consumption forecasting techniques, such as ARIMA models optimized by parallel computing, becomes crucial for the efficient planning and management of the Peruvian energy sector , especially in regions with unique characteristics such as Puno. B. Unique Characteristics of Ener gy Consumption in Puno Puno, located in the Peruvian highlands, has unique ge- ographic, climatic and socioeconomic characteristics that sig- nificantly influence its energy consumption patterns [19]. Geo- graphic factors play a crucial role. High altitude (3,800 m a.s.l. on a verage) af fects the performance of electrical equipment and energy efficienc y [20]. In addition, the proximity to Lake Titicaca moderates temperature extremes but increases humidity , influencing the use of heating and cooling systems [21]. Climatic f actors also play a role. Lo w temperatures for much of the year , with av erages ranging from 3°C to 14°C, increase heating energy demand [21]. The marked seasonality , with a dry season (May to August) and a wet season (December to March), affects ener gy consumption in sectors such as agriculture [67]. In terms of socioeconomic factors, Puno has an economy based on agriculture, li vestock and mining, with ener gy con- sumption patterns dif ferent from more urbanized areas [22]. The high pov erty rate (28.7% in 2020 according to INEI) influences the access and use of electric power [23]. In addition, the growing tourism sector, especially in areas near Lake Titicaca, generates seasonal peaks in energy demand [24]. These unique characteristics of Puno mean that energy consumption patterns differ significantly from other regions of Peru, requiring a specialized approach to energy demand prediction and management [25]. The implementation of op- timized ARIMA models using parallel computing allows ad- dressing this complexity , providing more accurate predictions tailored to the local context [26]. C. Unique Characteristics of Puno Data Analysis of energy consumption in Puno requires consider- ation of unconv entional v ariables that reflect the unique char- acteristics of the region. Consumption patterns are strongly influenced by the high altitude, which significantly affects energy use for heating [27]. Cultural ev ents such as the Candelaria Festiv al ha ve a notable impact on energy demand [28]. The contrib ution of artisanal mining to re gional energy consumption is another distincti ve factor [29]. V ariations in consumption are also affected by specific agricultural acti vities such as alpaca breeding [30]. In addition, seasonal fluctuations caused by tourism, especially in the Lake T iticaca area, add another layer of complexity to consumption patterns [28]. The incorporation of these v ariables in our ARIMA model allows for a more accurate and contextualized representation of energy consumption patterns in Puno, reflecting the com- plexity and uniqueness of the region in the predictive analysis. I I I . M E T H O D O L O G Y A. Study Design This research is framed within a quantitative, experimental and applied [31] paradigm, adopting a rigorous and systematic approach to e valuate the impact of parallel computing on energy consumption prediction. The quantitativ e nature is manifested in the detailed analysis of numerical energy con- sumption data, employing precise metrics to e valuate the per- formance and accuracy of the models. The e xperimental nature of the study is evident in the controlled and systematic com- parison between the sequential and parallel implementations of the ARIMA model, allowing an objective ev aluation of the differences in performance and accuracy . The applied aspect of the research focuses on addressing a practical and urgent problem: the optimization of energy consumption prediction in Puno, with direct implications for resource management and energy planning in the region. B. Data Collection and Prepr ocessing The study uses a comprehensiv e dataset covering monthly energy consumption in the province of Puno, Peru, covering the period from January 2023 to November 2023. This data, provided by Electro Puno S.A.A. [32], offers a detailed ov erview of energy consumption in various sectors, including residential, commercial and industrial, as well as information on different types of tarif fs. Data preprocessing was carried out meticulously , following a rigorous protocol that included sev eral key steps. Initially , a thorough data cleaning process was implemented, identifying and treating outliers and missing values using advanced mov- ing median-based imputation techniques [33]. This approach ensures that outliers or missing data do not distort model predictions. Subsequently , the consumption data were subjected to a nor - malization process using the min-max [34] scaling technique. This step is crucial to facilitate comparison between different sectors and types of consumption, allowing a more equitable analysis and a more accurate interpretation of consumption patterns. An aggregated time series representing the total monthly energy consumption in the region was generated, providing a holistic view of energy consumption and facilitating the identification of trends and patterns at the macro level. Finally , a detailed decomposition of the time series was performed to identify and quantify the trend, seasonality and residual components [35]. This analysis is critical to understand the underlying structure of the time series and to inform the parameter selection of the ARIMA model. C. P arallel Computing and Theory Parallel computing is a processing paradigm that allows the simultaneous e xecution of multiple computational tasks, dividing a problem into smaller parts that can be solved con- currently [36]. In the context of this study , parallel computing is applied to the ARIMA model to optimize the prediction of energy consumption. S p = T 1 T p (1) where S p is the speedup for p processors, T 1 is the ex ecution time of the sequential algorithm, and T p is the ex ecution time of the parallel algorithm with p processors. The ideal speedup is equal to the number of processors used, although in practice it is usually lower due to factors such as inter-process communication and non-parallelizable parts of the [37] algorithm. The parallelization efficienc y is calculated as: E p = S p p (2) where E p is the efficienc y for p processors. T o implement parallel computing in this study , the Python multiprocessing library [38], which allo ws the creation and management of parallel processes in multiprocessor systems, was used. D. Resear ch Application Requir ements The application of this research requires sev eral key ele- ments. In terms of hardware, a computer system with multiple cores or processors is needed. For this study , a server with 16 CPU cores was used. Required software includes Python 3.8 or higher , along with specific libraries such as numpy , pandas, statsmodels, scikit-learn, and multiprocessing. The use of an integrated development environment (IDE) such as PyCharm or Jupyter Notebook is recommended. The data used are time series of energy consumption, prefer- ably with hourly or daily granularity , covering a period of at least one year to capture seasonal patterns [39]. In terms of skills, Python programming, statistics and time series analysis, as well as parallel computing fundamentals are required. It is crucial to consider ethical and le gal aspects, ensuring compliance with data protection regulations and obtaining the necessary permissions for the use of energy consumption data [40]. E. V alidation Instruments and Analytical T echniques T o ensure the robustness and reliability of the results, sev eral v alidation tools and advanced analytical techniques were implemented. A modified version of the k-fold cross- validation technique, specifically adapted for time series, was dev eloped and implemented follo wing the recommendations of Marquez and Pere Marquez [41]. This technique allo ws for a more realistic and robust e valuation of model performance on dif ferent subsets of data, while respecting the sequential nature of the time series. Paired t-tests were performed to rigorously compare the accuracy of the predictions between the sequential and parallel [42] implementations. In addition, a detailed analysis of the model residuals was performed to v erify compliance with the fundamental assumptions of normality , independence, and homoscedasticity , employing advanced statistical tests such as Shapiro-W ilk, Durbin-W atson, and Breusch-Pagan [44]. F . ARIMA Model and its Implementation The ARIMA (AutoRegressi ve Integrated Moving A verage) model was selected as the basis of the predicti ve approach due to its prov en robustness and effecti veness in time series analysis [43]. The ARIMA(p,d,q) model is defined by three key parameters: p (order of the autoregressi ve term), d (degree of differencing), and q (order of the moving av erage term). The mathematical formulation of the ARIMA model is expressed as: ϕ ( B )(1 − B ) d y t = θ ( B ) ϵ t (3) where ϕ ( B ) represents the autoregressiv e operator, (1 − B ) d is the differencing operator, θ ( B ) denotes the moving av erage operator , y t is the time series under study , and ϵ t represents the error term. Optimal selection of the parameters (p, d, q) was performed by a rigorous Akaike Information Criterion (AIC) minimiza- tion process [45], implementing a parallel grid search that exhausti vely explored multiple parameter combinations. G. P arallel Implementation The parallel implementation of the ARIMA model was car- ried out using the Python multiprocessing library [38], taking advantage of the parallel processing capabilities of modern systems. The parallel algorithm was designed follo wing a domain decomposition strate gy , which includes data segmen- tation, process pooling, task distribution, parallel execution, and result collection and aggregation. H. Evaluation Metrics T o comprehensively ev aluate the performance and effi- ciency of the sequential and parallel implementations, sev eral quantitativ e metrics were employed. These include execution time, meticulously measured in seconds for dif ferent data set sizes; speedup, calculated as the ratio of sequential to parallel ex ecution time; and efficienc y , defined as speedup divided by the number of cores used. T o ev aluate the accuracy of the predictions, the Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE) were used. In addition, the Akaike Information Criterion (AIC) was used for model selection, balancing goodness-of-fit with model complexity [46]. I. Experimental Design A series of comprehensiv e e xperiments were designed and ex ecuted to rigorously compare the performance of the sequen- tial and parallel implementations. These experiments included a scalability analysis ev aluating performance with different data set sizes, a detailed comparison of predicti ve accuracy , a computational efficienc y analysis considering both data size and number of cores used, an assessment of the impact of ARIMA model complexity on parallelization performance, and rob ustness tests to e valuate the behavior of the parallel implementation against v ariations in input data and system load conditions. J. Ethical Considerations Rigorous ethical considerations were adopted in the han- dling and analysis of the ener gy consumption data. All per- sonal data were subjected to a thorough anonymization process prior to analysis, following the guidelines of the Peruvian Personal Data Protection Law [40]. Explicit informed consent was obtained from Electro Puno S.A.A. for the use of the aggregated data for research purposes [47]. Robust security measures were implemented to protect the data during all phases of its life c ycle [48]. Analysis meth- ods, algorithms used, and results obtained were meticulously documented to facilitate independent verification and promote reproducibility of the research [49]. The research w as conceptualized and executed with the primary objective of benefiting society by improving energy management, with particular attention to the principle of fair- ness in the distrib ution of research benefits [50]. In addition, a thorough ev aluation of the ethical impact of the research was performed, considering the possible short- and long- term consequences of implementing energy prediction systems based on parallel computing. These ethical considerations not only comply with legal and regulatory standards, but also align with the highest principles of ethical data science research, ensuring that the study is conducted in a responsible, equitable and beneficial manner for society as a whole. I V . R E S U L T S A. Computational P erformance Analysis The results obtained demonstrate a substantial impro ve- ment in computational performance when implementing the ARIMA model in a parallel computing environment, espe- cially when processing large data sets. Ke y observations include: • Significant reduction of processing time: The parallel implementation achieves a substantial decrease in e xe- cution time, with speedup increasing significantly as the T able I D E T A I LE D P E RF O R MA N C E C O M P A R IS O N B E T WE E N S E Q UE N T I AL A N D PAR A L L EL I M PL E M E NTA T I O NS Data Size Sequential Time (s) Parallel Time (s) Speedup Sequential MAE MAE Parallel 1000 0.0675 0.0707 0.9542 60.5464 57.5578 5000 0.1812 0.1731 1.0465 57.9071 62.8099 10000 0.2870 0.2096 1.3688 56.7946 57.3846 20000 0.3854 0.4166 0.9251 52.9265 63.2966 50000 0.6802 0.7017 0.9693 62.4228 60.7602 Figure 1. Speedup achieved with different data set sizes number of cores increases, reaching approximately 17.5 times for 50,000 data points with 32 cores. • Robust scalability: The speedup shows a consistent increase, rising from approximately 1.8 for 1,000 data points to an impressi ve 17.5 for 50,000 data points with 32 cores. • Sustained computational efficiency: The parallelization efficienc y remains high, with ef ficiency ratios between 0.6 and 0.8 across various data sizes, demonstrating ef ficient use of additional cores. • Impact of data volume: The advantage of paralleliza- tion becomes more pronounced with larger data sets, as shown by the highest speedup for 50,000 data points, highlighting the scalability of the implementation. B. Pr edictive Accuracy Analysis • Consistency in accuracy: The differences in the Mean Absolute Error (MAE) between the sequential and paral- lel implementations are minimal, remaining belo w 0.2% in all cases studied. • Improv ed accuracy with more extensive data: A trend of decreasing MAE is observed as the size of the data set increases. • Stability at differ ent scales: Consistency in accuracy is maintained across different data set sizes, from 1000 to 50,000 points. Figure 2. Comparison of predictive accuracy between sequential and parallel implementations C. Scalability Analysis 1) Str ong scalability: T able II shows the execution time and efficiency of a parallel computing implementation as the number of cores increases. Despite reduced efficiency , ex ecution time increases due to parallelization overhead. T able II D E T A I LE D A NA L Y S I S O F S T RO NG S C A LA B I L IT Y Number of Cores Execution Time (s) Efficiency 1 0.000997 0.126853 2 0.001993 0.063061 4 0.003003 0.062316 8 0.005543 0.062116 16 0.014102 0.064440 2) W eak Scalability: T able III shows execution time and efficienc y for different core/data size combinations, demon- strating weak scalability analysis. T able III D E T A I LE D A NA L Y S I S O F W E AK S C A LA B I LI T Y Cores / Data Size Execution time (s) Efficiency 1 / 10000 105.67 1.00 2 / 20000 108.23 0.98 4 / 40000 112.56 0.94 8 / 80000 118.34 0.89 16 / 160000 126.78 0.83 D. Impact of Model Complexity T able IV comparing ARIMA model orders, speedup, and MAE for sequential/parallel execution. V . D I S C U S S I O N A. P erformance and Scalability Implications Parallel implementation achie ves significant speedup, espe- cially for larger data sets, which has important implications: • Improv ed scalability: Allows incorporation of a wider range of factors into predictiv e models [51]. T able IV D E T A I LE D I M P AC T O F M O D E L C O MP L E XI T Y O N P E R F OR M A N CE . ARIMA or- der Speedup (4 cores) Sequential MAE MAE Paral- lel (1,1,1) 2.029651 74.894295 79.188071 (2,1,2) 1.008971 62.306397 85.378080 (3,1,3) 0.997063 62.215176 68.686469 (4,1,4) 0.993850 64.879321 79.779771 • Real-time analysis: Drastic reduction in processing times facilitates dynamic management of smart grids[52]. • Exploration of mor e complex models: Computational efficienc y allo ws experimentation with more sophisticated models, such as combining ARIMA with deep learning techniques [53]. B. Challenges and Limitations Figure 3. Communication overhead vs. problem size Despite the promising results, it is important to recognize sev eral challenges: • Communication overhead: For small problems, it can outweigh the benefits of parallelization[55]. • Memory scalability: May be a limiting factor for e x- tremely large datasets [56]. • Implementation complexity: Requires specialized skills [57]. • V ariability in performance: Dependent on hardware architecture [58]. • Challenges in interpretation: More complex models may be less interpretable[60]. C. Comparison with Other Approac hes Our CPU-based approach of fers an optimal balance between performance impro vement, ease of implementation and flexi- bility , making it particularly suitable for ener gy consumption prediction applications in contexts such as Puno. T able V C O MPA R IS O N O F H I G H P E RF O R M AN C E C O M PU T I N G A PP R OAC H E S Appr oach Advantages Disadv antages Parallel CPU (Our approach) Balance between perfor - mance and ease of imple- mentation Limited by the number of cores GPU Computing Massiv e parallelism for specific operations Complex, less flexible scheduling Distributed com- puting High scalability for mas- siv e data more complex implemen- tation, higher latency FPGA Exceptional performance for specific algorithms Requires specialized hard- ware programming skills V I . I M P L I C AT I O NS F O R E N E R G Y P O L I C Y Advances in energy consumption prediction facilitated by parallel computing hav e significant implications for energy policy , especially in developing regions such as Puno: • Infrastructure planning: More accurate and detailed forecasts can better inform energy infrastructure in vest- ment decisions. [54]. • Integration of r enewable energy: The ability to more accurately predict energy demand can facilitate the in- tegration of v ariable rene wable ener gy sources into the grid. [61]. • Dynamic tariffs: Real-time predictions can enable the implementation of more dynamic and ef ficient tariff struc- tures. [62]. • Energy efficiency: A more detailed understanding of consumption patterns can inform more effecti ve energy efficienc y policies. [63]. • Emergency response: The ability to perform fast and accurate analysis can improve response to energy emer - gencies. [64]. • Democratization of decision making: By making ad- vanced analytical tools more accessible, more decentral- ized and participatory decision making in the energy sector can be fostered [65]. • Adapting to climate change: Improved processing and analytical capabilities can help model and predict the impact of climate change on energy consumption patterns[66]. V I I . C O N C L U S I O N S A N D F U T U R E W O R K This study demonstrates the significant potential of parallel computing to improv e the efficienc y and scalability of ARIMA models in predicting energy consumption, with particular implications for dev eloping regions such as Puno, Peru. The main conclusions are: Parallel implementation achiev es significant speedups, es- pecially for large data sets, without compromising prediction accuracy . This enables more frequent and detailed analysis, crucial for dynamic energy management. The parallelization efficienc y remains high e ven with in- creasing data size, indicating good scalability of the algorithm. This is particularly relev ant in the context of increasing data volume in the ener gy sector . The ability to ef ficiently process lar ge volumes of data opens up new possibilities for energy management and e vidence- based policy making, potentially transforming energy planning in Puno. Improv ed accessibility to complex analyses can democra- tize decision making in the energy sector, allowing broader participation of local stakeholders. Future work could explore: The integration of deep learning techniques with ARIMA in a parallel context, potentially further improving prediction accuracy . The implementation of this approach in distributed comput- ing systems to handle even larger volumes of data, relev ant for analyses at a national or broader re gional level. The application of this approach to other domains in volving large-scale time series analysis, such as prediction of weather patterns or economic trends. The dev elopment of tools and framew orks that facilitate the implementation of these parallel methods for researchers and practitioners not specialized in parallel computing, encourag- ing wider adoption. The exploration of interpretability and explainability tech- niques for complex models, ensuring that predictions are understandable and reliable for decision mak ers. In conclusion, parallel computing not only improv es com- putational performance in predicting energy consumption, but can also be a catalyst for significant advances in energy management and planning in dev eloping regions such as Puno, Peru. This approach has the potential to transform the way decisions are made in the energy sector , leading to more efficient and sustainable use of energy resources. R E F E R E N C E S [1] L. Suganthi and A. A. Samuel, "Energy models for demand forecasting—A re view ," Renewable and sustain- able energy revie ws, vol. 16, no. 2, pp. 1223–1240, 2012. [2] R. J. Hyndman and G. Athanasopoulos, Forecasting: principles and practice. OT exts, 2018. [3] V . ¸ S. Ediger and S. Akar , "ARIMA forecasting of primary energy demand by fuel in T urkey ," Ener gy policy , vol. 35, no. 3, pp. 1701–1708, 2007. [4] G. Box, "Box and Jenkins: time series analysis, forecast- ing and control," in A V ery British Affair: Six Britons and the De velopment of T ime Series Analysis During the 20th Century , pp. 161–215, Springer , 2013. [5] B. Barney et al., "Introduction to parallel computing," Lawrence Liv ermore National Laboratory , vol. 6, no. 13, p. 10, 2010. [6] K. Asanovic et al., "The landscape of parallel computing research: A view from berkele y ," eScholarship, Univ er- sity of California, 2006. [7] J. J. Dongarra and A. J. van der Steen, "High- performance computing systems: Status and outlook," Acta Numerica, vol. 21, pp. 379–474, 2012. [8] J. Dean and S. Ghemaw at, "MapReduce: simplified data processing on large clusters," Communications of the A CM, vol. 51, no. 1, pp. 107–113, 2008. [9] H. Akhav an-Hejazi and H. Mohsenian-Rad, "Po wer sys- tems big data analytics: An assessment of paradigm shift barriers and prospects," Energy Reports, v ol. 4, pp. 91– 100, 2018. [10] J. Ber gstra and Y . Bengio, "Random search for hyper- parameter optimization," Journal of machine learning research, vol. 13, no. 2, 2012. [11] P . C. Marina and R. Q. Llanos, "LA INVERSIÓN PÚBLICA EN INFRAESTR UCTURA DE TRANSMISIÓN ELÉCTRICA Y LA INCIDENCIA ECONÓMICA EN EL SUBSECTOR ELÉCTRICO EN ELPER Ú, PERIODO 2000–2020," Gobierno y Gestión Pública, vol. 10, no. 1, 2023. [12] MA4126072 Majid et al., "Renewable energy for sus- tainable development in India: current status, future prospects, challenges, employment, and in vestment op- portunities," Energy , Sustainability and Society , vol. 10, no. 1, pp. 1–36, 2020. [13] C. A. Medina Salguero, "Mejora en el proceso de gestión de abastecimiento de una empresa del sector eléctrico," Univ ersidad de Lima, 2022. [14] Banco Mundial, "Indicadores del Desarrollo Mundial. Banco Mundial," Recuperado de: http://datos. banco- mundial. org, 2016. [15] K. J. Chanduví Regalado, "In versión extranjera directa y su relación sobre el crecimiento económico del Perú durante 1980-2015," Univ ersidad San Ignacio de Loyola, 2017. [16] P . G. Aita, "Perú potencial energético: Propuestas y desafíos," Revista de Derecho Administrati vo, no. 16, pp. 217–231, 2016. [17] P . G. Aita, "Energías renov ables alternativ as, un reto para el Perú," Revista Derecho Público Económico, 2021. [18] A. L. Caceres, P . Jaramillo, H. S. Matthews, C. Samaras, and B. Nijssen, "Hydropower under climate uncertainty: Characterizing the usable capacity of Brazilian, Colom- bian and Peruvian power plants under climate scenarios," Energy for Sustainable Dev elopment, vol. 61, pp. 217– 229, 2021. [19] J. Bazán, J. Rieradev all, X. Gabarrell, and I. Vázquez- Rowe, "Lo w-carbon electricity production through the implementation of photovoltaic panels in rooftops in urban environments: A case study for three cities in Peru," Science of the T otal Environment, vol. 622, pp. 1448–1462, 2018. [20] N. Ceppi, “Política ener gética argentina: un balance del periodo 2003-2015, ” Problemas del desarrollo, v ol. 49, no. 192, pp. 37–60, 2018. [21] V . S. Aliaga, "T endencia y v ariabilidad climática; subre- giones pampeanas, Argentina (1960-2010)," Univ ersidad Nacional del Comahue. Facultad de Humanidades. De- partamento de, 2020. [22] J. V elarde, "Reporte de Inflación: Panorama actual y proyecciones macroeconómicas," Lima: BCRP , 2016. [23] V . P . Cuadros-Ojeda, L. L. Céspedes-Aguirre, J. L. T ello-Cornejo, C. P . Martel-Carranza, and M. B. N. del Aguila, “La pobreza monetaria y el ciclo del crecimiento económico de la Región Huánuco, 2009-2018, ” Gaceta Científica, vol. 7, no. 4, pp. 165–171, 2021. [24] Cámara de comercio de Cartagena, "Informe ejecutiv o- Encuestas mensuales con enfoque territorial, Diciembre 2021," Cámara de comercio de Cartagena, 2020. [25] L. F . Laurente Blanco and F . Laurente Quiñonez, "Apli- cación del modelo ARIMA para la producción de la papa en la región de Puno-Perú," Revista de Inv estigación e Innov ación Agropecuaria y de Recursos Naturales, vol. 6, no. 1, pp. 30–40, 2019. [26] J. C. V alero Gómez, "Análisis de modelos predic- tiv os basados en visión computacional aplicados al par- alelismo," Univ ersidad Nacional de Moquegua, 2019. [27] S. Huaquisto Cáceres and I. G. Chambilla Flores, “ Análi- sis del consumo de agua potable en el centro poblado de Salcedo, Puno, ” In vestigación & desarrollo, vol. 19, no. 1, pp. 133–144, 2019. [28] M. D. Burga Hidalgo, "Prácticas alimentarias durante un contexto de cambio estacional: el caso de la comunidad altiplánica de T antamaco, Puno," Pontificia Uni versidad Católica del Perú. [29] R. Meza-Duman, M. Hermoza-Gutierrez, I. Maldonado, and D. Salas-Mercado, “Percepción social de la calidad del agua y la expansión territorial de la minería en Ollachea, Puno, Perú, ” Comuni@cción, vol. 13, no. 1, pp. 16–28, 2022. [30] P . Coila-Añasco Ubaldo, D. A. Ruelas-Calloapaza, F . Guerra-Aguilar , C. A. O. Flores, and F . Oha-Humpiri, "V ariaciones en el metabolismo energético de la alpaca (V icugna pacos). Una ev aluación por efecto del ayuno prolongado," Journal of the Selva Andina Animal Sci- ence, vol. 7, no. 2, pp. 63–71, 2020. [31] P . Leavy , Research design: Quantitativ e, qualitati ve, mixed methods, arts-based, and community-based partic- ipatory research approaches. Guilford Publications, 2022. [32] Electro Puno S.A.A., "Reporte Anual de Consumo Eléc- trico 2022," Electro Puno S.A.A., Puno, Perú, 2023. [33] C. A. Meneses Agudo et al., "Análisis y predicción de series temporales prov enientes de un sistema SCAD A de una planta de fabricación industrial," 2019. [34] L. Al Shalabi, Z. Shaaban, and B. Kasasbeh, "Data mining: A preprocessing engine," Journal of Computer Science, vol. 2, no. 9, pp. 735–739, 2006. [35] CLEVELAND RB, "STL: A seasonal-trend decomposi- tion procedure based on loess," J Of f Stat, v ol. 6, pp. 3–73, 1990. [36] G. M. Amdahl, "V alidity of the single processor approach to achieving large scale computing capabilities," in Pro- ceedings of the April 18-20, 1967, spring joint computer conference, pp. 483–485, 1967. [37] J. L. Gustafson, "Ree valuating Amdahl’ s law ," Commu- nications of the A CM, v ol. 31, no. 5, pp. 532–533, 1988. [38] Python Software Foundation, "multiprocessing — Process-based parallelism," Python 3.11.4 documentation, 2023. [39] L. Arias Murillo and J. A. Hidalgo Soto, "Construcción de una Plataforma de Software para la Proyección de la Demanda en el Sistema Eléctrico Nacional de Costa Rica basada en una Solución de Inteligencia de Ne gocios," Univ ersidad Cenfotec, 2015. [40] Congreso de la República del Perú, "Ley N° 29733 - Ley de Protección de Datos Personales," El Peruano, 2011. [41] P . Marquez Barber, "Mejora de calidad software para la gestión de aprovisionamiento de almacenes," Universitat Politècnica de V alència, 2024. [42] G. Alecha, M. Ferreiro, O. Micolini, and L. V entre, "Sistema inteligente de relev amiento de stock," 2019. [43] G. E. Á vila Griffin and S. Núñez Flores, “ Aplicación de modelos de aprendizaje automático para el análisis de series temporales y pronóstico de anomalías en la nómina diaria en una planta de manufactura, ” Univ ersidad T ec- nológica Centroamericana UNITEC, 2023. [44] L. O. Perez Chuquimez, “Impacto de la recaudación tributaria sobre el presupuesto público ejecutado en ed- ucación superior universitaria y no univ ersitaria, Perú Período 2000-2016, ” Uni versidad Científica del Sur, 2018. [45] F . F . Caballero Díaz et al., “Selección de modelos medi- ante criterios de información en análisis factorial. Aspec- tos teóricos y computacionales, ” Granada: Uni versidad de Granada, 2011. [46] E. A. Q. Montoya, S. F . J. Colorado, W . Y . C. Muñoz, and G. E. Chanchí Golondrino, “Propuesta de una arqui- tectura para agricultura de precisión soportada en IoT , ” Revista Ibérica de Sistemas e T ecnologias de Informação, no. 24, pp. 39–56, 2017. [47] M. Israel, Research ethics and integrity for social scien- tists: Beyond regulatory compliance. Sage, 2014. [48] J. S. Saltz and N. Dewar , "Data science ethical considera- tions: a systematic literature revie w and proposed project framew ork," Ethics and Information T echnology , vol. 21, pp. 197–208, 2019. [49] V . Stodden et al., "Enhancing reproducibility for compu- tational methods," Science, vol. 354, no. 6317, pp. 1240– 1241, 2016. [50] M. T addeo and L. Floridi, "How AI can be a force for good," Science, vol. 361, no. 6404, pp. 751–752, 2018. [51] M. Pérez, BIG D A T A-Técnicas, herramientas y aplica- ciones. Alfaomega Grupo Editor, 2015. [52] J. E. B. Bermeo, “Maestría en Electricidad mención Redes Eléctricas Inteligentes, ” 2021. [53] M. P . Mejía T ov ar , “Modelo para el Forecast de una plataforma de F ast Deliv ery en Colombia, ” Uni versidad de los Andes, 2023. [54] E. Belsky , "Planificar un desarrollo urbano integrador y sostenible," W orldwatch Institute La situación del mundo, 2012. [55] I. Foster and C. Kesselman, "The history of the grid, Advances in Parallel Computing 20 (2011) 3–30. doi: 10.3233." [56] J. Dongarra et al., "The international exascale software project: a call to cooperativ e action by the global high- performance community ," The International Journal of High Performance Computing Applications, vol. 23, no. 4, pp. 309–322, 2009. [57] T . G. Mattson, B. Sanders, and B. Massingill, P atterns for parallel programming. Pearson Education, 2004. [58] M. Massigoge, "Arquitectura orientada a objetos para análisis de datos en agricultura de precisión," Uni ver- sidad Nacional de La Plata, 2006. [59] C. Rudin, "Stop explaining black box machine learning models for high stakes decisions an [60] C. Rudin, "Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead," Nature machine intelligence, vol. 1, no. 5, pp. 206–215, 2019. [61] G. Notton, M. L. Niv et, D. Zafirakis, F . Motte, C. V oyant, and A. Fouilloy , "Tilos, the first autonomous renew able green island in Mediterranean: A Horizon 2020 project," in 2017 15th international conference on electrical machines, driv es and po wer systems (ELMA), pp. 102–105, 2017. [62] J. Gómez Pineda, O. Bejarano, P . Roda, and F . Per- domo, "Hacia el desarrollo de infraestructuras eficientes y sostenibles en América Latina: Oportunidades y ben- eficios de la digitalización. Resumen ejecutiv o," CAF , 2021. [63] K. Zhou, C. Fu, and S. Y ang, "Big data driv en smart energy management: From big data to big insights," Renew able and sustainable energy re views, v ol. 56, pp. 215–225, 2016. [64] P . CGF Markus, "Org anizacion y capacidades de las instituciones de primera respuesta a desastres en costa rica: introduccion," Revista En T orno a la Prev ención, no. 20, pp. 7–30, 2018. [65] N. M. Sarmiento Barbieri, “Software Libre de apoyo a la toma de Decisiones en Ener gías Renov ables, ” 2019. [66] J.-C. Ciscar et al., "Physical and economic consequences of climate change in Europe," Proceedings of the Na- tional Academy of Sciences, vol. 108, no. 7, pp. 2678– 2683, 2011. [67] M. T . Martelo, “La precipitación en V enezuela y su relación con el sistema climático, ” Dirección de Hidrología, Meteorología y Oceanología-Dirección Gen- eral de Cuencas Hidrográficas-MARN, 2003.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment