A recursive linear time modular decomposition algorithm via LexBFS
A module of a graph G is a set of vertices that have the same set of neighbours outside. Modules of a graphs form a so-called partitive family and thereby can be represented by a unique tree MD(G), called the modular decomposition tree. Motivated by …
Authors: Refer to original PDF
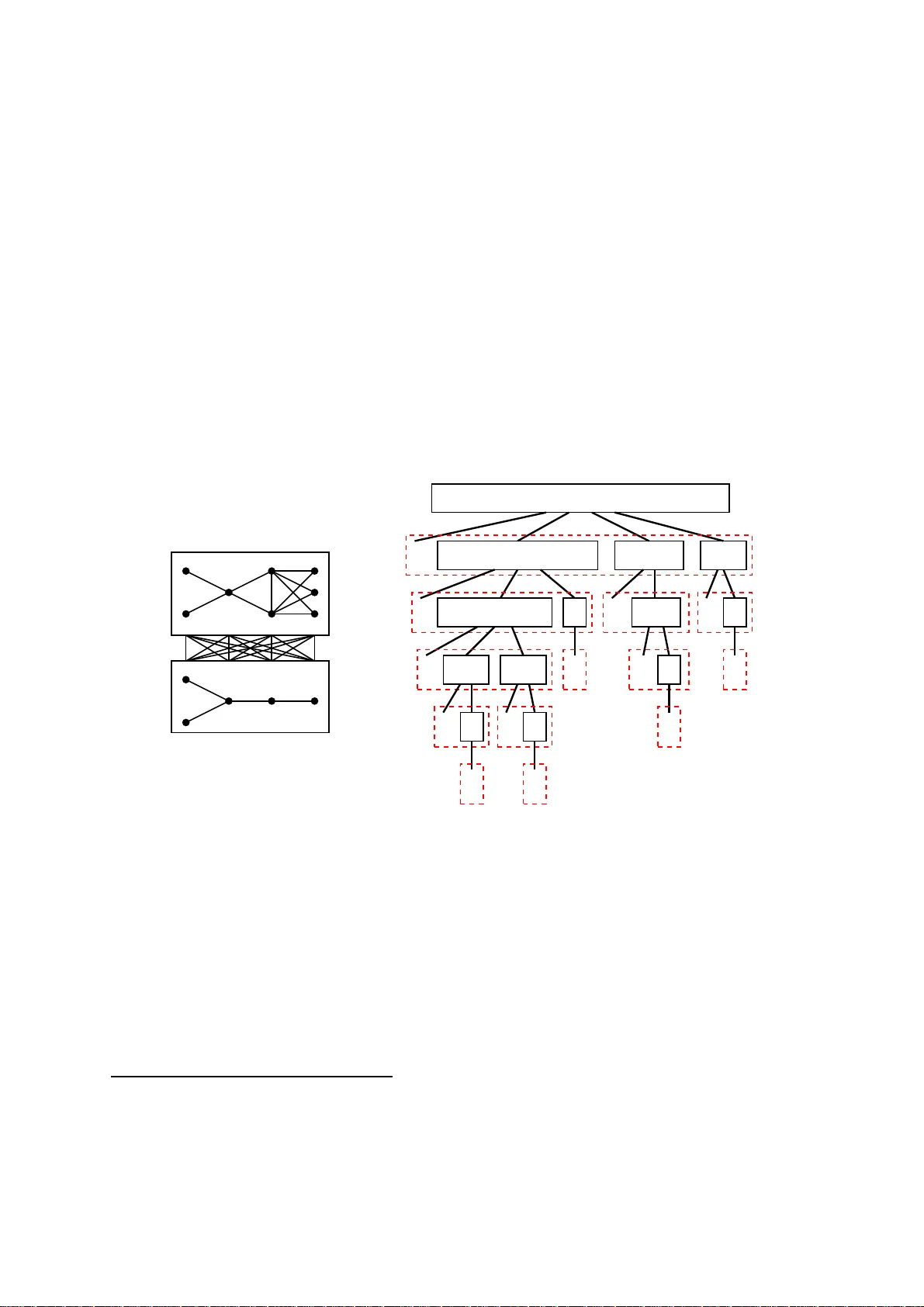
A recursive linear time mo dular de comp osition algorithm via LexBFS ∗ Derek G. Corneil † Mic hel Habib ‡ Christophe P aul § Marc T edder ¶ July 15, 2024 Abstract A mo dule of a graph G is a s et M of vertices that hav e the same set o f neighbours outside of M . Mo dules o f a graphs for m a so-calle d partitiv e f amily and ther eby can b e represented by a unique tree MD ( G ), c a lled the mo dular decomp osition tree . Motiv ated by the central role of modules in n umero us algor ithmic graph theory ques tio ns, the problem of efficient ly computing MD ( G ) ha s b een inv estiga ted since the ea r ly 70’s . T o date the bes t algor ithms r un in linear time but are all r ather co mplicated. By combining prev ious algorithmic par adigms developed for the problem, we are able to present a s impler linear - time alg orithm that relies on very simple data-structure s, namely slice decomp osition a nd sequences of ro oted ordered trees. F orew ords. This pap er is the fu ll and self-con tained v ersion of the result ann ou n ced at ICALP 2008 [50]. An extended abstract w as also a v aila b le as arXiv:0 710.3901 v1 (Octob er 2007) and r evised as arXiv:0 710.3901 v2 (Marc h 2008) . F or a comparativ e history on the successiv e v ersion, the reader should rep ort on the app endix of th e current p ap er. As a follo w-up to sev eral requests o v er the last ye ars, we decided t o work on a fir s t self-con tained version w ith the ob jectiv e to formalize as m uch as p ossible the com binatorial str uctures inv olv ed in the algorithm and its implemen tation. These structures, we b eliev e, could b e of indep enden t in terest. Moreo ver, an implemen tation of the d escrib ed algorithm is no w a v aila ble (see [4]). ∗ Researc h supp orted by t h e F rench-German Collaboration ANR/DFG Pro ject UTMA (A N R-20-CE92-0027), and by the ANR COR EGRAPHIE p ro ject, grant ANR- 20-CE23-0002 of the F rench ANR. † Computer Science Department, T oronto U niversit y , Canada ‡ IRIF, Univ. P aris Cit´ e & CNRS, Paris, F rance § LIRMM, Univ. Mo ntp ellier & CNRS, Montpellier, F rance. ¶ Computer Science Department, T oronto U niversit y , Canada. 1 1 In tro duc tion Ho w to comp ose or decomp ose a graph is a cent ral questio n in graph theory as it allo ws to capture imp ortant structural p rop erties, whic h in tur n ma y serve as the foun d ation of efficient com binatorial algorithms. Among the comp osition op erations, a natural one is called th e sub- stitution op er ation . Giv en a graph G = ( V G , E G ), it consists in substituting a v ertex x ∈ V G b y a graph H = ( V H , E H ) and ma king in the r esulting graph G x → H ev ery vertex of V H adjacen t to eve ry neigh b our of x (see Figure 1). In G x → H , the former vertic es of H that are sub stituted to x f orms a mo dule , that i s a subset o f v ertices M suc h that ev ery v ertex not in M is either adjacen t to every vertex of M or to none of them. x G H G x → H Figure 1: Th e su bstitution in G of th e v ertex x by the graph H results in the graph G x → H . The mo dular de c omp osition aims at capturing how a graph ca n be comp osed (and deco m- p osed) with th e substitution op eration. Gallai [2 7] i n itiated the stud y of the modular decom- p osition of a graph to study the structure of comparability graphs (those graphs whose edge set can b e transitiv ely orien tated), see also [30]. Gallai ob s erv ed th at modu les are cen tral to capture the set of transitiv e orienta tions of a graph. Indeed, for a mo d ule M of a grap h G = ( V , E ), a transitiv e orienta tion o f edge set E M of the indu ced su b graph G [ M ] is ind ep en- den t from th e transitiv e orien tation of the edges of E \ E M . Inte restingly , the notion of mo dule arises in v arious conte xts and thereby app ears in the literature u n der different names, such as close d set [27], clan [24], automonous set [41], clump [3], interval [36]. . . S ince its introdu ction, mo dular d ecomp osition has b een established as a f u ndamenta l tool in graph theory and al go- rithmic graph theory . F or e xample, computin g the modular decomp osition is a p r epro cessing step of recognition algorithms for m an y graph classes among which cographs, P 4 -sparse graph s, in terv al graphs, comparabilit y graphs, p erm utation graphs. . . W e refer to the bo oks [30, 6] for definitions of these graph classes. Among recen t app lications of mo dular decomp osition, the recen tly intro d uced parameter called mo dular width , defined as the maximal size of a p rime no de in the mo dular decomp osition tree of an und irected graph [26], has b een u sed in a num- b er of parameterized algorithms. Let us also men tion the u se of mo du lar decomp osition for diameter computations in s u b qu adratic time [17, 23] for some graph classes. F or m ost of th ese applications, computing the mo du lar decomp osition is a p repro cessing step. As w e will see in Section 2, the set of mo dules of a graph forms a p artitive set family . This more general concept and its v arian ts (bip artitiv e families, w eakly partitiv e families) h as b een indep end en tly introdu ced in [13] and [20] to tac kle generalizatio ns of graphs suc h as digraphs and hyp ergraphs or set sys tems [41]. It has also b een applied to 2-structur es [25], p erm utations [52, 1], b o olean fun ctions [41], submo dular functions [21], matroids [51] and more recent ly 2 Robinson spaces [11 ] to name a few. It sh ould b e n oticed that although mo du lar decomp osition of b o olean functions is NP-hard to compute [2], hyp ergraphs that corresp ond to monotone b o olean functions can b e decomp osed p olynomially [31]. 1.1 Previous algorithms. Not su rprisingly , the problem of computin g the mo du lar decomp osition has receiv ed considerable atten tion and the imp ortance of the problem h as bent efforts to ward a simple and efficien t solution. The first p olynomial-time algo rithm [19] a pp eared in the early 1970’s and r an in time O ( n 4 ). Incremen tal impr ov ements were made o ve r the y ears. [33] d escrib ed a cubic time algorithm, w hic h was late r improv ed to a quadratic time algorithm in [42]. Ev ent u ally , linear time algorithms were dev elop ed indep enden tly in [38], and [18]. These linear time are unfortun ately so complex as to b e viewed primarily as th eoretical con tribu tions. Since the publication of the fi rst t wo linear-time algorithms, the quest of a simple and efficien t algorithm yields th e publication of sev eral alg orithms, some of them ru nning in linear time, others in almost linear time (alwa ys sub-quadratic). These m ore r ecen t algorithms mainly follo w t wo distinct paradigms. In order to sketc h these t wo paradigms and compare ou r alg orithm to them, let us br iefly in tro du ce the notion of mo dular decomp osition tree (for f orm al definition, we let the reader refer to Section 2). Th e mo dular decomp osition tree MD ( G ) of a graph G (= V , E ) is a ro oted tree whose lea v es are m app ed to the v ertices of G and whose internal no des repr esen ts the s o-calle d str ong mo dules of G , that are mo dules th at does not o verlap any ot her mo dules. Indeed if u is an in tern al nod e o f MD ( G ), then the set of lea v es that are d escenden t of u forms a strong mo dule of G . It is w ell kno wn that MD ( G ) repr esen ts the inclusion ordering of th e s et of strong mo dules of G and that ev ery m o dule of G can b e retriev ed from MD ( G ). The skeleton pa radigms. This fir st p aradigm was designed by Eh r enfeuc ht et al. [24] to ob- tain a quadratic time algorithm. Based on a divid e-and-conquer strategy , the sk eleton paradigm yields a significativ e simplification compared to the previous qu adratic time algorithms. A series of a lgorithms later pu b lished implemented this paradigm and a chiev ed sub-qu adratic run n ing time: O ( n + m · α ( n, m )) or O ( n + m ) [22] and fin ally O ( n + m log n ) [40]. The skel eton paradigm is tw o-steps. First, it pic ks a verte x x of the inp ut graph G and computes the set of maximal modu les M x max ( G ) not cont aining x . F or eac h mo d ule M ∈ M x max ( G ), the mod ular decomp osition tree of the sub graph G [ M ] is r ecursiv ely computed. The second step consists in the computation of the x -spine of the mo dular decomp osition tree MD ( G ), that is the path of MD ( G ) b et w een x and the ro ot (see Figure 2). Observ e that the set of no des of the x -spine is precisely the set of s tr ong mo d ules of G con taining x , that we denote M x strong ( G ). Even tually , MD ( G ) is obtained by at tac hing in an accurate w a y , for every mo dule M ∈ M x max ( G ), the mo dular decomp osition tree MD ( G [ M ]) to the x -spine of M D ( G ). F actoring p ermutation paradigm. T his is also a t wo-st ep algo rithm. The first step aims at computing a so-called factoring p ermutation [8, 9] of the inp u t graph G = ( V , E ), that is an ordering of the v ertices in w hic h ev ery strong m o dule G app ears co ns ecutiv ely . O bserve that a factoring p ermutatio n of G is obtained for example by ordering the ve rtices o f G , w hic h are lea v es of MD ( G ), according to a dep th-first-searc h ordering of MD ( G ). Computing a factoring p ermutatio n can b e ac hieve in O ( n + m log n )-time by a simp le algorithm based on the p artition 3 x MD ( G [ M 1 ]) MD ( G [ M 2 ]) MD ( G [ M 3 ]) MD ( G [ M 4 ]) MD ( G [ M 5 ]) Figure 2: T h e sk eleton tree of a mo dular decomp osition tree MD ( G ) for s ome graph G . The maximal mod ules not con taining x are M x max ( G ) = { M 1 , M 2 , M 3 , M 4 , M 5 } . Their modu lar decomp osition sub-tree are attac hed to the x -spine. r efinement te chnique [35, 34]. The second step is an algorithm parsing the factoring p ermutation to r etrieve the strong mo dules of G together with their inclusion tree, th e m o dular decomp osition tree MD ( G ). Sev eral linear time algorithms to compute M D ( G ) fr om a factoring p erm utation of G ha ve b een prop osed [9, 1]. S o for no w, the f actoring p ermutatio n paradigm has led to an O ( n + m log n )-time mo du lar decomp osition algorithm. Let us mentio n that while linear-time w as claimed in [32], the p ap er con tains an error wh ich kills the algorithm’s simp licit y . 1.2 Recursiv e t ree-refinemen t and LexBFS : a mixed paradigm In this p ap er we introd uce the n otion of fact orizing p ermutat ions to the r ecur siv e framew ork describ ed ab o ve to pr o duce a linear-time m o dular decomp osition algorithm. F or a verte x x of a graph G = ( V , E ), w e let M x max ( G ) den ote t h e set of maximal modu les of G not conta inin g x and M x strong ( G ) denote the set of strong m o dules cont aining x . W e fi rst observe that { x } together with M x max ( G ) form a partition of V and that it is p ossible to ord er that p artition in a sequence ~ M ( x ), that we call factoring x -mo dular se quenc e , so that eve ry mo du le of M x strong ( G ) is a factor . Notice that a factoring x -modular sequence extends the c oncept of factoring p er- m utation discussed ab o v e. Then assumin g that for ev ery mo du le M ∈ M x max ( G ), the mo dular decomp osition tree MD ( G [ M ]) has b een recurs iv ely compu ted, as in th e sk eleton paradigm, w e pro ceed to filter these lo cal mo dular decomp osition trees to extract the mo du les of G they con tain. It then r emains to assemble and connect all these filtered trees to the x -spine. Computing the x -spine is done in a similar, but simpler, wa y than computing MD ( G ) from a facto ring p erm utation. The cen tral remaining question is th en ho w to compute a f actoring x -mo dular sequence. This step d eeply relies on the n otions of slic e s , f actoring slic e se quenc es and slic e de c omp osition of a grap h . An x -slice is a subset S of vertic es that has th e prop er ty of not o v erlappin g an y mo d ule of M x max ( G ). The idea is to compute a factoring x -slice sequence, whic h is an order ed partition of a graph that can b e refined in a factoring x -mo du lar sequence and for every x -slice S of the sequence to r ecursiv ely compu te MD ( G [ S ]). W e show h o w to ap p ly an extension of the partition refinement tec hnique t o trees (rather th an sets) in order to clear and r efine the mod ular decomp osition trees of the slices. The ob jectiv es of that clearing step is t w ofold: first, to compute M x max ( G ) and their relativ e mod ular decomp osition trees while preserving an ordering; and also to arrange M x max ( G ) and { x } in a sequence that preserv es the 4 factoring prop ert y for the mo dules of M x strong ( G ). The mixed p aradigm is comp osed b y four distinct successiv e algorithmic steps, all in serted in a global recursiv e sc heme and eac h inv olving sp ecific com binatorial ob jects. The global linear-time complexit y relies on the p repro cessing step that computes a so- called x -slice de- comp osition. W e sho w ho w to p erform this pre-pro cessing step in linear-time by using the celebrated Lexicographic Breadth-First-Searc h algorithm [43]. Let us men tion that identifying the r igh t com binatorial ob jects and their prop er ties main tained along the f ull algorithm allo ws us to pro vide a very simp le a generic time-complexit y analysis. 1.3 Organization of t he pap er After a b rief introdu ction on m o dular decomp osition and the und erlying notion of partitiv e families, Section 2 int ro duces the cen tral concept of factoring mo d u lar sequence. Then Section 3 is dedicate d to the description of the prepro cessing step of our alg orithm. T o that aim, it in tro du ces the c oncept of laminar decomp osition, slices and slice decomposition wh ic h allo ws to pro vide the aforement ioned generic time-complexit y analysis. In S ection 4, we d escrib e h o w to efficien tly clear, refin e the local mo du lar decomp osition trees, those ind uced b y the slices. Then the spine computation is presented in Section 5 and fi n ally the fu ll algorithm is compiled and analyzed in Section 6. 2 Preliminaries 2.1 Basic concepts Sets and part it ions. In this pap er, w e only consider finite sets. L et A and B b e tw o su bsets of a set X . T he symmetric differ enc e of A and B is A △ B = ( A \ B ) ∪ ( B \ A ). W e say that A and B overlap if A ∩ B 6 = ∅ , A \ B 6 = ∅ , and B \ A 6 = ∅ wh ic h is d enoted A ⊥ B . W e let 2 X denotes the set of subsets of X . A p artition of X is a set P ⊂ 2 X suc h that ∀ A ∈ P , A 6 = ∅ and for ev ery pair of distinct s u bsets A ∈ P , B ∈ P , A ∩ B = ∅ an d if S A ∈P A = X . Sequences and (forest) partitioning sequences. A se que nc e on a set X is a pair ~ X = ( X, ≺ ~ X ) where ≺ ~ X is a total order on X . W e also d enote ~ X = h x 1 , . . . , x n i the ordered set ( X, ≺ ~ X ) with the meaning th at if i < j , then x i ≺ ~ X x j . When clear from th e con text, w e will simply wr ite x i ≺ x j . The empt y sequence will b e d enoted h ε i . If ~ S and ~ S ′ are tw o sequ ences on disjoin t sets X and Y , then ~ S · ~ S ′ is the concatenation sequence on X ∪ Y defined in the natur al w a y . If ~ S is a sequence on X , th en for a su bset Y ⊆ X we let ~ S [ Y ] denote the subs equence of ~ S induced by the elemen ts of Y , that is, f or every x, y ∈ Y , x ≺ ~ S [ Y ] y if and only if x ≺ ~ S y . A p artitioning se quenc e (also call ed ordered partition) of a set X is a sequence ~ P = h P 1 , . . . , P k i su c h that P = { P 1 , . . . , P k } is a partition of X . Using the n otations ab o v e, if x ∈ P i and y ∈ P j for some 1 ≤ i < j ≤ k , then w e sa y that x ≺ ~ P y or that x ≺ ~ P P j . L et ~ Q = h Q 1 , . . . , Q ℓ i b e a partitioning sequen ce of X . W e sa y that ~ Q is an extension of (or is thinner than) ~ P , or that ~ P is c o arser th an ~ Q , if for every x, y ∈ X , x ≺ ~ P y implies that x ≺ ~ Q y . So ~ Q is an extension of ~ P if eve ry part of ~ Q is conta ined in some part of ~ P and th e ordering b et ween the parts of ~ P is p reserv ed in ~ Q . A f actor of a sequence ~ X is a subset S of elemen ts of X th at are consecutiv e in ~ X , th at is, if x / ∈ S then, for eve ry y ∈ S , either x ≺ ~ X y or y ≺ ~ X x . Let ~ P = h P 1 , . . . , P k i b e a partitioning 5 sequence on X . Th en a subset S ⊆ X is a factor of ~ P if there exist i and j , w ith 1 ≤ i ≤ j ≤ k , suc h that for ev ery i < ℓ < j , if any , P ℓ ⊂ S and for ev ery h with h < i or h > j , if any , S ∩ P h = ∅ . Graphs. All graphs considered here are finite, simple, lo opless and undir ected. Let G = ( V , E ) b e a graph with n ve rtices and m ed ges. W e let xy denote the edge b et w een t wo adjacen t v ertices x and y of G . The neighbourh o o d o f a vertex x of G is denoted N G ( x ), wh ile its non-neigh b ourho o d is den oted N G ( x ). The complemen tary graph of G is the graph G = ( V , E ) where E = { xy / ∈ E | x, y ∈ V , x 6 = y } . Th e subgraph of G induced by a subset W ⊆ V of v ertices is G [ W ] = ( W, E ∩ W 2 ). Let P = { V 1 , . . . , V k } b e a p artition of the v ertex set of a graph G = ( V , E ). Then the quotient gr aph of G with resp ect to P , denoted G / P = ( V / P , E / P ), is the graph such that V / P = { x i | V i ∈ P } and E / P = { x i x j | ∃ x ∈ V i , ∃ y ∈ V j , xy ∈ E } . Ro oted trees. A ro oted tree T = ( T , r ) is a pair comp osed of a tree T and a distinguished no de r , called the r o ot . A le af of a ro oted tree is a n o de w ithout an y c hild r en (observ e that the ro ot no de may b e a l eaf ). Ev ery n o de that is not a leaf is ca lled an internal no d e and has at least tw o c hildren. An internal e dge of a ro oted tree T is an edge that is not inciden t to a leaf. A r o ote d for est is a graph wh ose connected comp onen ts are ro oted trees. Let u and v b e t w o distinct no d es of th e rooted tree T . The no d e u is a desc endant of v if v b elongs to th e unique path f rom u to the ro ot r , and v is then an anc estor of u . The le ast c ommon anc estor of u and v is denoted lca T ( u, v ). W e let L T ( u ) denote the leaf set of T d escend ing from u and C T ( u ) d enote the set of children o f u in T . Th en the lea f set of the ro oted tree T is L ( T ) = L T ( r ). Unless explicitly stated, all trees (or forests) in this pap er are ro oted tr ees. Definition 1. A se q u enc e ~ T = h T 1 , . . . , T k i is a forest partitioning sequence of the set X if for every i ∈ [1 , k ] , T i is a for est such that {L ( T 1 ) , . . . , L ( T k ) } is a p artition of X . Observe that a partitioning s equ ence is a forest p artitioning sequen ce in which eve ry part is a forest con taining a uniqu e (r o ot) no de. If u is a no d e of a ro oted forest T i ∈ ~ T , for i ∈ [1 , k ], w e sa y that u is a no de of ~ T and abusiv ely denote by L ~ T ( u ) th e set L T i ( u ). Y et, the partial order ≺ ~ T on X is defin ed as in partitioning s equences. Laminar f a milies and laminar trees. As defined in [45], a laminar family on a groun d set X is a su bset F ⊆ 2 X suc h that for all x ∈ X , { x } ∈ F and for all A, B ∈ F , either A ⊆ B or B ⊆ A or A ∩ B = ∅ . O bserv e a la minar family F on X is naturally represente d b y a ro oted forest, denoted T F and called F -laminar for est , suc h that for ev ery se t A ∈ F , T F con tains a no de u A suc h that L T F ( u A ) = A . Observ e that if X ∈ F , then T F is a ro oted tree. 2.2 P artitive fami lies Definition 2. [13] A family F ⊆ 2 V is a partitiv e family 1 on gr ound set V i ff it satisfies the fol lowing axioms: (i) ∅ ∈ F and for every x ∈ V , { x } ∈ F ; 1 In the usual definition t he ground set V is an element of F . 6 (ii) if A ∈ F and B ∈ F ar e such that A ⊥ B , th en A ∩ B ∈ F , A ∪ B ∈ F , A \ B ∈ F , B \ A ∈ F and A △ B ∈ F . An element A of a s et family F ⊆ 2 V is str ong if for ev ery B ∈ F , A and B do not ov erlap. Clearly , ev ery singleton set in F is strong. Observ e that the inclusion ordering of the set of strong ele ments of a family F is a laminar family (that is, ev ery pair of e lements is either disjoin t, or one is a su bset of the other). Th e transitiv e reduction of this inclusion ordering forms a V -forest, denoted T F , that w e called the str ong for est of F . Notice that T F is a tree if V ∈ F . Ob serv e that, b y defi nition, there is a b ijection mapping ev ery strong elemen t A ∈ F to the no de u A of T F suc h that A = L T F ( u A ), and that, for tw o strong elemen ts A, B ∈ F , the no de u A is a descendan t of the no d e u B in T F if a n d only if A ( B . W e say that the s trong elemen t A ∈ F is a c hild of the strong elemen t B ∈ F , or that B is the paren t of A , if the no de u A is a child of u B . W e also sa y that A and B are siblings if they are c hildren of the same strong elemen t of F . A strong element A ∈ F can b e of t w o differen t typ es : it is de gener ate (in F ) if for every non-trivial sub set C of c hildr en of A , S B ∈C B ∈ F ; and A is prime (in F ) if for ev ery non-trivial subset C of c hild ren of A , S B ∈C B / ∈ F . O b serv e that, if A has exac tly tw o c hildren, we sa y that A is degenerate. Theorem 1. [13] L et F ⊆ 2 V b e a p artitive family on g r ound set V . Every str ong element of F is either de gener ate or prime. M or e over, for every element A ∈ F tha t is not str ong, ther e exists a no de u in T F and a non-trivial sub se t C ⊂ C T F ( u ) of childr en of u such that A = S v ∈C L T ( v ) . The p artitive for est of a p artitiv e fa mily F , d enoted T ∗ F , is obtained by assigning to every in ternal no d es u of the strong forest T F a lab el type F ( u ) 2 whic h is either p rime o r degene rate dep end ing of the typ e of the corresp onding strong element. As a consequence of th e ab o ve theorem, T ∗ F is a compact represent ation of F . Indeed, although F ma y contai n exp onen tially man y subs ets of V , T ∗ F has size linear in | V | . 2.3 Mo dular decomp osit ion. Let G = ( V , E ) b e a graph. Let X b e a subset of v ertices and x b e a v ertex not in X . W e sa y that x is universal to X if X ⊆ N ( x ) and that x is isolate d from X if X ⊆ N ( x ). If a v ertex x is isolated from X or universal to X , then we say that X is N ( x )-uniform . I f X is not N ( x )-uniform, then N ( x ) is a splitter of X . W e ma y a lso a bu siv ely sa y th at the vertex x is a splitter of X . Definition 3. A mo d u le of a gr aph G = ( V , E ) is a subset M ⊆ V such that for every x / ∈ M , M is N ( x ) -unif orm. Hereafter, we let M ( G ) d enote the set of mo du les of a graph G . Obser ve th at M ∈ M ( G ) if and only if M ∈ M ( G ). Beside the singleton sets and the full ve rtex set, wh ich form the trivial mo d u les, ev ery connected comp onen t of G a n d the union of any su bset of connected comp onent s form mo dules of G . W e sa y that a graph G is prime if ev ery mo du le of G is trivial. Using Definition 3 it is not hard to b e con vinced b y the follo wing statemen t. Lemma 1. [13] F or eve ry g r aph G = ( V , E ) , M ( G ) is a p artitive family . 2 When clear from the context, we simply write type ( u ) instead of type F ( u ). 7 As b eing a partiti ve family , M ( G ) con tains strong elements, that w e call str ong mo dules , whic h are either prime or de gener ate . Hereafter, w e let M strong ( G ) denote the set of str on g mo dules of a graph G . As we will see, M strong ( G ) con tains tw o t yp es of d egenerate mo dules. A mo dular p artition of a graph G = ( V , E ) is a partition M of V suc h that every part M ∈ M is a mo du le of G . T o ev ery mo du lar partiti on M of a graph, one ca n asso ciate the quotien t graph G / M . Observe that since mo du les are u niform with resp ect to eac h another, G / M is a su bgraph of G induced b y a subset S of vertice s obtained by selecting for ev ery mo du le M ∈ M , an arbitrary vertex x M . Then, in G / M , t wo v ertices, corresp ond ing to mo du les M and M ′ , are adjacen t if and only if, in G , eve ry ve rtex of M is adjacen t to ev ery ve rtex of M ′ . Theorem 2. [27] Every gr aph G = ( V , E ) sa tisfies exactly one of the fol lowing c onditions: 1. G is not c onne cte d; or 2. G is not c onne cte d; or 3. the quotient gr aph G / M , wher e M is the mo dular p artition o f G c ontaining the maximal str ong mo dules distinct f r om V , is prime. Using t h e ab ov e theorem, w e can distinguish three typ es of strong mo dules of a graph G . Let M be a strong m o dule and let M M b e th e mo dular partition of th e ind u ced sub graph G [ M ] con taining the maximal strong mo d ules of G [ M ] distinct from M . By Theorem 2, observ e th at the quotien t graph G [ M ] / M M is either a complete graph, or a n edge-l ess graph, or a pr ime graph. In the first case, we set t yp e ( M ) = series , in the second case, type ( M ) = pa rall el and in the latter case type ( M ) = prime . W e can now define the mo dular de c omp osition tr e e of a graph G , denoted MD ( G ), by labelling eve ry in ternal no de u of the strong tree T M strong ( G ) with the t yp e of the corresp onding strong mo dule M u = L T M strong ( G ) ( u ). W e observe th at th e series and pa rall el strong mo dule are the degenerate strong elemen ts of the partitiv e family M ( G ). S ee Figure 3 for an example of the mo dular decomp osition tree of a graph. While the no des of the mo du lar decomp osition tree MD ( G ) are in bijection with the elemen ts of M strong ( G ), using Theorem 1 applied to the f amily of m o dules of a graph explains ho w to deriv e M ( G ) from MD ( G ). In some sense MD ( G ) r epresen ts M ( G ). It s hould b e noticed th at | M ( D ) | ∈ O ( n ) but M ( G ) could b e of exp onential size. Corollary 1. L et MD ( G ) b e the mo dular de c omp osition tr e e of a gr aph G . Then M ⊆ V is a mo dule of G if and only if MD ( G ) c ontains a no de u such that either M = L MD ( G ) ( u ) , or u is de gener ate and M = S v ∈C L MD ( G ) ( v ) for some non trivial subset C ⊂ C MD ( G ) ( u ) of childr en of u . In the first c ase, M is str ong, while in the latter c ase, M is not str ong. 2.4 F actoring partitions and p erm utations Definition 4. L et x b e a vertex of a gr aph G = ( V , E ) . A mo dule M of G is an x -modu le if x ∈ M and it is an x -mo dule otherwise. We let M x strong ( G ) denote the set of str ong x -mo dules while M x max ( G ) denotes the set o f x -mo dules that ar e maxima l under inclusion. Notice that the m o dules of M x strong ( G ) corresp ond to the ancestors of the leaf x in M D ( G ). Let u s observe that th e mo d u les of M x max ( G ) a re not necessarily s tr ong and thereb y ma y not corresp ond to n o des of MD ( G ). F or an example of su c h a mo dule of M x max ( G ) that is not strong, consider the set { y , z } in the graph of Figure 3. 8 w v u c d x y z b e a f g x P arallel Prime Series y z Series c d u P arallel v w Prime g P arallel f a e b Figure 3: A graph G = ( V , E ) and its mo dular decomp osition tree MD ( G ). Ev ery ve rtex of S = { a, b, e, f , g } is adjacen t to ev ery vertex of V \ S . Colored r ed in MD ( G ), th e no des corresp ondin g th e M x max ( G ). Observe th at the mo du le { y , z } b elongs to M x max ( G ) but is not a strong mo d ule. Colored b lue, the n o des corresp onding to M x strong ( G ). The sequence ~ M ( x ) = h{ a, b, e, f , g } , { c, d } , { x } , { y , z } , { u } , { v , w }i is a factoring x -mo dular sequence (see Definition 6) and the sequence ~ S ( x ) = h{ a, b, c, d, e, f , g } , { x } , { y , z , u } , { v , w }i is a f actoring x -slice sequence (see Definition 10). Lemma 2. L e t x b e a vertex of a gr aph G = ( V , E ) . F or every mo dule M ∈ M x max ( G ) , ther e exists an anc estor u of x in M D ( G ) suc h that one of the two fol lowing c ases ho lds: • either type ( u ) = prime and u has a c hild v such that M = L MD ( G ) ( v ) ; • or u is de gener ate (that is, type ( u ) = series or type ( u ) = parallel ) and M = S v ∈C L MD ( G ) ( v ) wher e C = v ∈ C MD ( G ) ( u ) | x / ∈ L MD ( G ) ( v ) . Pr o of. By Corollary 1, for every mo d ule M o f G , th ere exists a un ique no de u of MD ( G ) suc h that M ( L MD ( G ) ( u ). O bserve that for a mo d ule M ∈ M x max ( G ), u has to b e an ancestor of x , as otherwise M ′ = L MD ( G ) ( u ) is an x -mo dule whic h con tains M , contradict ing M ∈ M x max ( G ). By Co rollary 1 , if typ e ( u ) = p rime , then M = L MD ( G ) ( v ) for s ome child v of u . Otherwise, u is degenerate (that is, type ( u ) = series or t yp e ( u ) = parallel ) and then, M = S v ∈C L MD ( G ) ( v ) where C = v ∈ C MD ( G ) ( u ) | x / ∈ L MD ( G ) ( v ) . As a consequen ce of Lemma 2 , if a mo dule M ∈ M x max ( G ) is not strong, then there exists a degenerate m o dule M ′ ∈ M x strong suc h that M is th e u nion of all the mo d ules that are c hildren of M ′ in M D ( G ) and that do n ot con tain x . Moreo v er, for ev ery p air of vertic es y and z b elonging to an x -mo dule M , w e hav e that lca MD ( G ) ( x, y ) = lca MD ( G ) ( x, z ). W e let lca MD ( G ) ( x, M ) denote that no de. Th e follo win g observ ation is a direct consequence of the definition of mo d ule. Observ ation 1. L et x , y and z b e thr e e vertic es of a gr aph G = ( V , E ) such th at xy ∈ E and xz / ∈ E . If y z / ∈ E , then lca MD ( G ) ( x, z ) is not a strict desc endant o f lca MD ( G ) ( x, y ) , and if y z ∈ E , th en l ca MD ( G ) ( x, y ) is not a strict desc endant of lca MD ( G ) ( x, z ) . Pr o of. Observ e fir s t that the no des lca MD ( G ) ( x, y ) and l ca MD ( G ) ( x, z ) are b oth an cestors of x in MD ( G ). Supp ose that y z / ∈ E , then y is a splitter of { x, z } . This implies that ev ery mo dule con taining x and z also con tains y a nd thereby lca MD ( G ) ( x, z ) cannot b e a strict d escendan t of 9 lca MD ( G ) ( x, y ). Similarly , if y z ∈ E , then z is a s plitter of { x, y } . This implies that eve ry mo dule con taining x and y also con tains z and thereby lca MD ( G ) ( x, y ) cannot b e a str ict descendant of lca MD ( G ) ( x, z ). Definition 5. [9] A vertex se quenc e ~ σ of a gr aph G = ( V , E ) is a factoring p er mutation , if every str ong mo dule M of G i s a factor of ~ σ , i.e. the vertic es of M ar e c onse cutive in ~ σ . W e observ e that a factoring p erm utation is obtained by ordering the vertice s of G , whic h corresp ond to the lea v es of MD ( G ), according to a depth-fi r st-searc h ordering of MD ( G ). Observ ation 2. L et x b e a vertex of a gr aph G = ( V , E ) . The set { x } and the mo dules of M x max ( G ) form a p artition of V . Pr o of. Ob viously , ev ery ve rtex y 6 = x b elongs to some mo d ule of M x max ( G ). Supp ose that M 1 , M 2 ∈ M x max ( G ) int ersect. Using th e fact that m o dules form a p artitiv e family M 1 ∪ M 2 is also a mo dule not con taining x , w hic h con tradicts the maximalit y o f M 1 and M 2 . Let u s now examine ho w to order the ab o v e partition so th at the mo du les of M x strong ( G ) are factors 3 . Definition 6. L et x b e a vertex of a gr aph G = ( V , E ) . Then, an x -mo dular sequence is a p artitioning se quenc e ~ M ( x ) of V that c ontains the set { x } and t he mo dules of M x max ( G ) . We say that ~ M ( x ) is a factoring x -mo dular sequence if every str ong mo dule M ∈ M x strong ( G ) is a factor of ~ M ( x ) . Mor e over, ~ M ( x ) i s cen tered at x when y ∈ N ( x ) if and only if y ≺ ~ M ( x ) x . Figure 4 b elo w d epicts a factoring x -mo d ular s equence ~ M ( x ) of the graph G of Figure 3 . Ob- serv e that ~ M ( x ) is not cen tered at x . Ho wev er, the x -mo dular sequ ence ~ M ′ ( x ) = h{ a, b, e, f , g } , { c, d } , { x } , { y , z } of the g rap h of Figure 3 is factoring and cent ered at x . Prop erties of factoring x -mo du lar se- quence are established in the next t w o lemmas. Th e latter one sh o ws th at x -mo du lar factoring sequence cen tered at x alw a ys exist and p ro vide a wa y to build one. x P arallel Prime Series y z Series c d u P arallel v w Prime g P arallel f a e b Figure 4: The mo du lar decomp osition tree MD ( G ) of the graph G of Figure 3 dr a wn to certify that the s equ ence ~ M ( x ) = h{ x } , { y , z } , { u } , { v , w } , { c, d } , { b, c, a, f , g }i is a factoring x -mo du lar sequence. 3 Refer to Subsection 2.1 for a definition of factor . 10 Lemma 3. L et x b e a vertex of a gr aph G = ( V , E ) a nd ~ M ( x ) = h M 1 , . . . , { x } , . . . , M p i b e a factoring x -mo dular se qu e nc e. F or e v ery str ong mo dule M ∈ M x strong ( G ) , ther e exists r < ℓ such that M = { x } ∪ ∪ r ≤ i ≤ ℓ M i . Pr o of. F rom the definition of a factoring x -mo dular sequ ence, ev ery mo d ule M ∈ M x strong ( G ) is a factor of ~ M ( x ). The fact of M b eing strong implies that M do es not o verlap any mo dule M i from ~ M ( x ). The statemen t follo ws. Lemma 4. L et x b e a vertex of a gr aph G = ( V , E ) . L et ~ M ( x ) b e an x -mo d u lar sequence . Then ~ M ( x ) is a factoring x -mo dular se quenc e c e nter e d at x if and only if it fulfil ls the fol lowing c onditions: (i) If M ∈ M x max ( G ) is c ontaine d in N ( x ) , then M ≺ ~ M ( x ) { x } , otherwise { x } ≺ ~ M ( x ) M . (ii) Supp ose that M , M ′ ∈ M x max ( G ) ar e c ontaine d in N ( x ) . If lca MD ( G ) ( M , x ) is a strict anc estor o f lca MD ( G ) ( M ′ , x ) , then M ≺ ~ M ( x ) M ′ . (iii) Supp ose that M , M ′ ∈ M x max ( G ) ar e c ontaine d in N ( x ) . If lca MD ( G ) ( M , x ) is a strict anc estor o f lca MD ( G ) ( M ′ , x ) , then M ′ ≺ ~ M ( x ) M . Pr o of. Supp ose that ~ M ( x ) is a factoring x -mo dular sequence cente red at x . T hen by definition, w e h a v e N ( x ) ≺ ~ M ( x ) x ≺ ~ M ( x ) N ( x ). As every mo dule of M x max ( G ) is either a sub set of N ( x ) or of N ( x ), th e first condition holds. Let M and M ′ b e t wo mo dules of M x max ( G ). Sup p ose that b oth M and M ′ are cont ained in N ( x ) a nd that lca MD ( G ) ( M , x ) is a strict ancesto r of lca MD ( G ) ( M ′ , x ). Ob serv e that if M ′ ≺ ~ M ( x ) M , then the mo dule L MD ( G ) ( lca MD ( G ) ( M ′ , x )), that b elongs to M x strong ( G ), i s not a facto r of ~ M ( x ). S o the sec ond condition holds. Supp ose now that b oth M and M ′ are cont ained in N ( x ) and th at lca MD ( G ) ( M , x ) is a strict ancesto r of lca MD ( G ) ( M ′ , x ). Ob serv e that if M ≺ ~ M ( x ) M ′ , then the mo dule L MD ( G ) ( lca MD ( G ) ( M ′ , x )), that b elongs to M x strong ( G ), is not a factor of ~ M ( x ). This imp lies the thir d condition. Let u s n o w assume that ~ M ( x ) is an x -mo d u lar sequen ce satisfying the thr ee cond itions. By Lemma 3 every mo d ule of M x strong ( G ) is the union of { x } and a subset of mo dules of M x max ( G ). F or the sak e of cont radiction, supp ose that a mo dule M ∈ M x strong ( G ) is n ot a factor of ~ M ( x ). This implies the existence of a mo dule M ′ ∈ M x max and t wo v er tices y , z ∈ M (one of whic h could b e x ) su c h that y ≺ ~ M ( x ) M ′ ≺ ~ M ( x ) z . Supp ose firs t that M ′ ⊂ N ( x ). Then by the first condition, w e ha ve y ∈ N ( x ). Observe that M ′ is a strict ancestor of M y , the modu le of M x max ( G ) con taining y . By the second condition, we should h av e M ′ ≺ ~ M ( x ) M y : con tradiction. The case M ′ ⊂ N ( x ) is sym metric. By the fi rst condition z ∈ N ( x ). Obs er ve that M ′ is a strict ancestor of M z , the mo du le of M x max ( G ) con taining z . By the third condition, we should ha ve M y ≺ ~ M ( x ) M ′ : contradict ion. W e remark that if t wo mo dules M , M ′ ∈ M x max ( G ) v erify lca MD ( G ) ( M , x ) = lca MD ( G ) ( M ′ , x ), then in an x -mo dular se quenc e ~ M ( x ), w e can either h a v e M ≺ ~ M ( x ) M ′ or M ′ ≺ ~ M ( x ) M . Let us observe that if MD ( G ) conta ins a prime n o de u that is a n ancestor of x , then there exist seve ral factoring x -mo du lar sequences cente red at x . Ind eed, the rela tive order of the mo dules (con tained in N ( x ) or in N ( x )) that are children of u but that do not con tains x is arbitrary . F or example, ~ M ′′ ( x ) = h{ b, c, a, f , g } , { c, d } , { x } , { u } , { y , z } , { v , w }i is an alternativ e factoring x -mo dular sequence cen tered at G for the graph of Figure 3 , that is obtained from ~ M ′ ( x ) b y r ev ersing the order b et ween { u } an d { v , w } . 11 Lemma 5. L e t x b e a vertex of a gr aph G = ( V , E ) . If ~ M ( x ) is a factoring x -mo dular se q uenc e of G , then ther e exists a factoring p ermutation of G that is an extension of ~ M ( x ) . Pr o of. If ev ery mo dule in M x max ( G ) is a singleton, then ~ M ( x ) is already a factoring p ermutatio n of G . S o for ev ery mo d ule M ∈ M x max ( G ) that is not a singleton, w e pro ceed as follo ws. Thanks to Lemma 2, there are t w o cases to consider: • If M is a strong mo du le of G , th en w e consider ~ σ ( M ) a factoring permutatio n o f G [ M ]. Observe that ev ery strong m o dule of G that is a subset of M is a strong mo du le of G [ M ] and thereb y is a factor of ~ σ ( M ). • If M is not a strong mo du le of G , then M is disjoint union of strong mo du les M 1 , M 2 , . . . , M t of G an d w e consider the vertex sequence ~ σ ( M ) = ~ σ ( M 1 ) · ~ σ ( M 2 ) · · · · · ~ σ ( M t ) wher e f or ev ery 1 ≤ i ≤ t , ~ σ ( M i ) is a factoring per mutation of G [ M i ]. Ob serv e that every strong mo dule of G that is a subset of M is a s trong mo d ule of some G [ M i ], for 1 ≤ i ≤ r , and thereb y is a factor of ~ σ ( M ). Let ~ σ b e the v ertex sequence of G ob tained by s ubstituting in ~ M ( x ) every mo dule M ∈ M x max ( G ) b y the sequ ence ~ σ ( M ). Clearly ~ σ is a factoring p erm utation of G . Ind eed, as in ~ M ( x ) ev ery mo dule of M x strong ( G ) is a fact or of ~ σ . Moreo ver ev ery other strong modu le of G is con tained in some mo dule M ∈ M x max ( G ) and is by constru ction a factor of ~ σ ( M ), and ther eby of ~ σ . Lemma 5 pro ves that computin g a factoring x -mo d ular sequence is a s tep to w ards the com- putation of a facto ring p ermutation. F rom no w on, unless explicitl y stated, w e will alw a ys assume that a factoring x -mo dular sequence is cen tered at x . Definition 7. L et x b e a vertex of a g r aph G = ( V , E ) . If ~ M ( x ) = h M 1 , . . . , { x } , . . . , M p i is a factoring x -mo dular se quenc e, then ~ MD ( x ) = h MD ( G [ M 1]) , . . . , { x } , . . . , M D ( G [ M p ]) i is a factoring x -mo dular MD -sequence . 3 Prepro c essing step: slice decomp osition In this section, we in tro du ce t wo imp ortan t concepts, n amely laminar de c omp osition and slic e de c omp osition , which ma y b e of in terest b ey ond our mo du lar decomp osition alg orithm. Th ey will drive the complexit y analysis and the correctness of our algorithm. Th e laminar decomp o- sition is a v ery generic m anner to decomp ose a graph b y means of recursive vertex partitions. It offers a fr amework that provides sufficient conditions f or th e existence of a linear time algorithm. The correctness of our algorithm relies on the notion of slic e and of slic e de c omp osition . These are an abstr action derived fr om the concept of L exBFS slic es and L exBFS slic e de c omp osition (see Su bsection 3.3) related to the celebrated Lexicographic-Breadth-First-Searc h algorithm [43] and used in man y graph algorithms (see [7, 14]). 3.1 Laminar decomp osition and rec ursive computation Definition 8. L e t G 1 = ( V 1 , E 1 ) and G 2 = ( V 2 , E 2 ) b e two gr aphs on distinct set of vertic es. • The d isjoin t union (or p ar al lel c omp osition) of the gr aphs G 1 and G 2 , denote d union ( G 1 , G 2 ) is the gr aph G = ( V , E ) suc h that V = V 1 ∪ V 2 and E = E 1 ∪ E 2 . 12 • F or A ⊆ V 1 × V 2 , the A -merge of the gr aphs G 1 and G 2 , denote d merge ( G 1 , G 2 , A ) is the gr aph G = ( V , E ) such that V = V 1 ∪ V 2 and E = E 1 ∪ E 2 ∪ A . Observe th at merge ( G 1 , G 2 , ∅ ) = un ion ( G 1 , G 2 ). W e also observe that if A = V 1 × V 2 , then merge ( G 1 , G 2 , A ) corresp onds to the stand ard series comp osition of G 1 and G 2 (also kn o wn as the 1-join comp osition). Theorem 3. L et A b e an algorithm that is given a gr aph G = ( V , E ) on n vertic es and m e dges as input. L et G 1 = ( V 1 , E 1 ) and G 2 = ( V 2 , E 2 ) b e two gr aphs on distinct set of vertic es such that V = V 1 ∪ V 2 and E = E 1 ∩ E 2 ∪ A with A ⊆ V 1 × V 2 b e a non-empt y set. F or i = 1 , 2 , we denote n i = | V i | and m i = | E i | . If A runs in time f A ( G ) and satisfies the fol lowing c onditions: 1. if | V | = 1 , then f A ( G ) = O (1) ; 2. if G = uni on ( G 1 , G 2 ) , then f A ( G ) = f A ( G 1 ) + f A ( G 2 ) + O (1) ; 3. if G = merge ( G 1 , G 2 , A ) , then f A ( G ) = f A ( G 1 ) + f A ( G 2 ) + O ( | A | ) ; then f A ( G ) ∈ O ( n + m ) . Pr o of. Observ e that there exists tw o constan ts a and b su ch that f A ( G ) ≤ f A ( G 1 ) + f A ( G 2 ) + a + b · | A | . Since A 6 = ∅ , an easy induction yields f A ( G ) ≤ c · ( n + m ) for every c ≥ 2 · max { a, b } . This implies that algorithm A runs in linear time. In the merge op er ation the edge set A is called hereafter the set of active edges. Th e disjoint union and t h e merge op erations naturally ge n er alize to an arbitrary num b er k of graphs and Theorem 3 still holds. Th is motiv ates the defin ition of a laminar de c omp osition of a graph Definition 9. A laminar decomp osition of a gr aph G = ( V , E ) , denote d LD ( G ) is an or der e d r o ote d tr e e 4 whose le aves ar e the ve rtex set V and such that every non-le af no de has at le ast two childr en. 5 Mor e over, every internal no de u with se quenc e of childr e n h u 1 , . . . u k i is asso ciate d to the subset of e dges of G : A LD ( G ) ( u ) = { xy ∈ E | u = lca LD ( G ) ( x, y ) } . Her e after, an e dge xy ∈ A LD ( G ) ( u ) i s c al le d activ e at no de u . An example of a laminar decomp osition of a graph is giv en in Figure 5. Observ ation 3. L et LD ( G ) b e a laminar de c omp osition of the gr aph G = ( V , E ) . The set {A LD ( G ) ( u ) | u is a no de of LD ( G ) } is a p artition of E . It fol lo ws that to every l aminar decomp osition LD ( G ) of a graph G corresp onds a regular expression defi n ing G = ( V , E ) using the union an d merge op erations and the additional • a op erator that b uilds the graph w ith a uniqu e v ertex a . W e pr o ceed as f ollo ws. If | V | = 1 (the ro ot of LD ( G ) as no child), th en G = • a . Otherwise, let u 1 , . . . u k ( k ≥ 2) b e the c hildren of the ro ot of LD ( G ). F or 1 ≤ i ≤ k , we denote V i = L LD ( G ) ( u i ), G i = G [ V i ] and A = E ∩ ( V 1 × · · · × V k ). Then: 4 At this step of the discussion, a laminar decomp osition may only b e considered as a rooted tree. The prop erty of b eing ordered will b ecome imp ortant later when dealing with sp ecific laminar decompositions. 5 A laminar family F ⊆ 2 X on th e ground set X satisfies that if A, B ∈ F then either A ∩ B = ∅ , or A ⊂ B , or B ⊂ A . O bserve t h at the set of no des of a laminar decomp osition LD ( G ) represents a laminar family F of subsets of vertices of G : F = { S ⊆ V | ∃ u, L LD ( G ) ( u ) = S } . 13 • if | V | > 1 and A = ∅ , then G = union ( G 1 , . . . , G k ); • if | V | > 1 and A 6 = ∅ , then G = merge ( G 1 , . . . , G k , A ). Observe that the graph G in Figure 5 is obtained from the follo wing regular expression: G = merge ( merge ( • a , • b , { ab } ) , union ( merge ( • c , • d , { cd } ) , • e ) , merge ( • f , • g , { f g } ) , A ) , where A = { af , bd, bf , d f , eg } . a b c d e f g h{ a, b } , { c, d, e } , { f , g }i A = { af , bd, bf , d f , eg } h{ a } , { b }i { ab } h{ c, d } , { e }i ∅ h{ f } , { g }i { f g } h{ c } , { d }i { cd } a b c d e f g Figure 5: A laminar decomp osition LD ( G ) of the graph G = ( V , E ). In ev ery no de, the p artition of the lea v es defin ed by the c hildren is represen ted (in blac k) and the set of activ e edge is give n (in red). As we will see, the prep ro cessing step of our mo du lar decomp osition algorithm will consist in computing a sp ecial laminar decomp osition of th e input graph, called slic e de c omp osition . W e will then pro ve that u sing a slice decomp osition, we can design an algorithm that satisfies the complexity h yp othesis of T h eorem 3. The c hallenge is then to compute in lin ear time suc h an exp ected laminar decomp osition. 3.2 Slice sequences and slice decomp osition The n otions of slices, slice sequences and slice decomp osition are central to the recur siv e strategy of our algorithm sin ce they will allo w to p erform the union and merge op erations efficien tly . The concept of slic e was fi r st introdu ced to un derstand structural prop erties of the LexBFS ord erings (see [16]). Here, we provide an abstract defin ition of s lice whic h p u t in ligh t the precise prop erties that will b e used in the correctness pr o of of our algorithm. Definition 10 ( Slice sequence) . L et x b e a vertex of a gr aph G = ( V , E ) . An x -slice sequence of G , denote d ~ P ( x ) = h S 0 = { x } , S 1 , . . . , S k i , is a p artitioning se qu enc e of V such th at, for every i ≥ 0 , the set S i +1 is a sub se t of V \ V i , wher e V i = S 0 ≤ j ≤ i S j , that satisfies the fol lowing thr e e pr op erties: 14 1. [uniform prop erty] for every y ∈ V i , S i +1 is N ( y ) -u ni f orm; 2. [inclusion prop erty] N ( S i +1 ) ∩ V i is maximal for the i nclusion among the sets N ( z ) ∩ V i for e very z ∈ V \ V i ; 3. [maximality prop erty] and, S i +1 is maximal with r esp e ct to the two pr evious pr op erties. The vertex x is c al le d the pivo t o f ~ P ( x ) and the sets S 1 , . . . , S k ar e c al le d x -slices of G . Supp ose th at ~ P ( x ) = h S 0 = { x } , S 1 , . . . , S k i i s an x -slice sequence of a graph G . O bserv e that if x is isolated, then ~ P ( x ) = h S 0 = { x } , S 1 = V \ { x }i , and otherwise S 1 = N ( x ). Ho w eve r, a graph m a y enjoy sev eral x -slic e sequences and fr om one sequence to another, the r esp ectiv e set of x -slices ma y d iffer. Observe th at an x -slice sequence ~ P ( x ) of a graph G yields a trivial laminar decomp osition in w h ic h e very internal n o de is a c hild of the root a n d corresp onds to an x -slice of ~ P ( x ). W e can thereby consid er the set of active e dges asso ciated to ~ P ( x ), hereafter denoted A ( ~ P ( x )), as the set of ed ges inciden t to v ertices of distinct slices. The follo wing observ ation will b e cent ral in the complexit y analysis of our algorithm. Observ ation 4. L et x b e a vertex of a gr aph G = ( V , E ) and let ~ P ( x ) = h S 0 = { x } , S 1 , . . . , S k i b e an x - slic e se qu enc e of G . If G is c onne cte d, then Σ 1 ≤ i ≤ k | S i | ≤ |A ( ~ P ( x )) | . Pr o of. W e prov e that for ev ery i ≥ 1, ev ery v ertex y ∈ S i is adjacent to a v ertex z suc h that z ≺ ~ P ( x ) y . Observe that b y the uniform p r op ert y of Definition 10, it suffices to s h o w that an arbitrary v ertex, s ays y ∈ S i has a suc h a pr ior neighbour z . W e first notice that, by Definition 10, S 1 = N ( x ), implying that the p rop erty h olds for i = 1. Let u s consider S i with i > 1 and assu me that the p r op ert y is not satisfied. Since G is connected, there must b e an edge z z ′ ∈ E su c h that z ≺ ~ P ( x ) S i ≺ ~ P ( x ) z ′ . Let S j , with j > i , b e the slice con taining z ′ . O bserv e that N ( y ) ∩ V i − 1 = ∅ , then N ( y ) ∩ V i − 1 ⊂ N ( z ′ ) ∩ V i − 1 , con tradicting the inclusion prop ert y of Definition 10. This implies that y and every ve rtex of S i is incident to an activ e edge z suc h that z ≺ ~ P ( x ) y . Since ~ P is a p artitioning sequence of V , w e hav e that Σ 1 ≤ i ≤ k | S i | ≤ |A ( ~ P ( x )) | . The next t wo lemmas sh o ws th at x -slice sequences b eha v e w ell with resp ect to the set M x strong ( G ) and M x max ( G ) of mo dules of G . They allo w to design t he recursive pro cess and to compute a factoring p ermutatio n of G . Lemma 6. L e t x b e a vertex of a gr aph G = ( V , E ) and let ~ P ( x ) = h S 0 = { x } , S 1 , . . . , S k i b e an x - slic e se quenc e o f G . Supp ose that M is a mo dule o f G . 1. If M do es not c ontain x , then ther e exists i , 1 ≤ i ≤ k , such that M is c ontaine d i n S i and M is a mo dule of G [ S i ] . 2. If M c ontains x , then ther e exists i , 1 < i ≤ k , such that for every 1 < j < i (if any), S j ⊆ M and for every i < j ≤ k (if any), S j ∩ M = ∅ . Pr o of. The c ase x is isolate d in x is trivial since ~ P ( x ) = h{ x } , V \ { x }i . So assume x is not isolated. 1. Fi rs t, it is clear that if M ⊆ S i , then M is a mo du le of the induced sub graph G [ S i ]. Observe no w that ev ery mo dule not cont aining x is either a su bset of N ( x ) or of N ( x ). As 15 S 1 = N ( x ), it suffices to pro ve the statemen t for mo du les con tained in N ( x ). Let M b e su c h a mo dule. Let i b e the smallest in teger suc h that M co ntains a vertex u i ∈ S i . Supp ose that M also conta ins a v ertex u j ∈ S j for some 0 < i < j ≤ k . Then, b y the inclusion prop ert y of the slices, there exists v ≺ ~ P ( x ) u i suc h th at v ∈ N ( u i ) \ N ( u j ), con tradicting the assum ption that M is a mo d ule. 2. Supp ose that M ⊆ S 1 ∪ { x } , then setti ng i = 2 fulfills the condition of the statement . Otherwise, let i > 1 b e the large st index s u c h that S i con tains a v ertex y ∈ M . Let j > 1 b e the smallest index suc h that S j con tains a v ertex z / ∈ M . Supp ose th at j < i . Th en b y the inclusion prop erty of th e slices, there exists a ≺ ~ P ( x ) z su c h that z ∈ N ( a ) and y / ∈ N ( a ). If a ∈ S 1 , then a is a splitte r for { x, y } and thereb y b elongs to M . But then z is a splitte r for M as is it adj acen t to a but not to x , contradicti on. So we can assume th at a / ∈ S 1 . Observ e again that a / ∈ M as otherwise, z would b e a sp litter for the mo d ule M . But then a ≺ ~ P ( x ) z con tradicts the c hoice of j . Observe that Lemma 6 esp ecially applies to mo dules of M x strong ( G ) and mo d ules of M x max ( G ). Lemma 7. L et x b e a vertex of a gr aph G = ( V , E ) and l et ~ P ( x ) = h{ x } , S 1 , . . . , S k i b e an x - slic e se quenc e of G . Then ther e e xists a factoring p ermutation of G that is an extension of the se quenc e ~ S ( x ) = h S 1 , { x } , S 2 , . . . , S k i , i f x is not isolate d, or of ~ S ( x ) = h{ x } , V \ { x }i otherwise. Pr o of. The c ase x is isolate d in x is trivial since ~ P ( x ) = h{ x } , V \ { x }i . So assume x is not isolated. The set M x max ( G ) defines a partitio n of V \ { x } and, by L emma 6 , ev ery mo dule of M x max ( G ) is con tained in some slice S i of ~ P ( x ). It follo ws that ev ery slice S i of ~ P ( x ) is also partitioned in mo dules of M x max ( G ). Supp ose that for ev ery mo dule M ∈ M x max ( G ), we are giv en a factoring p erm utation σ M of G [ M ], then we define a p ermutation ~ σ of G as follo ws: • for y , z ∈ N ( x ): if there exists M ∈ M x max ( G ) con taining y and z and y ≺ ~ σ M z , or if lca ( x, y ) is an ancestor of lca ( x, z ), then y ≺ ~ σ z . O therwise, breaks ties arbitrarily . • for y , z ∈ N ( x ): if y ≺ ~ P ( x ) z or if there exists M ∈ M x max ( G ) cont aining y and z and y ≺ ~ σ M z , or if lca ( x, z ) is an ancestor of lca ( x, y ), then y ≺ ~ σ z . Otherwise, breaks ties arbitrarily . W e claim that ~ σ is a factoring p ermutat ion of G . Eve ry strong mo du le M ′ of G that is con tained in some m o dule M ∈ M x max ( G ) app ears consecutiv ely in ~ σ M . Therefore, by Lemma 6 and by construction of ~ σ , M ′ app ears consecutiv ely in ~ σ as wel l. Consider no w a strong mo dule M ∈ M x ( G ). By Lemma 6, M o v erlaps at most one slice S i , i > 1 and ev ery slice S j with 1 < j < i is a subset of M . So the ab ov e construction guaran tees t h at the vertice s of M are gathered next to x while the vertic es not in M are pushed a wa y from x . This imp lies that the mo dules of M x ( G ) also app ears consecutiv ely . It follo ws that ~ σ is a factoring p erm utation of G . This ab ov e Lemm a 7 sho ws that computing an x -slice sequen ce of G is a step forward computing a factoring p ermutation of G . Definition 11. L et x b e a v e rtex of a gr aph G = ( V , E ) . If x is not iso late d in G and ~ P ( x ) = h{ x } , S 1 , . . . , S k i is an x -slic e se quenc e, then the se quenc e ~ S ( x ) = h S 1 , { x } , . . . , S k i is c al le d a factoring x -slice sequence . Mor e over th e p artitive tr e e se quenc e ~ T ( x ) = h MD ( G [ S 1 ]) , { x } , MD ( G [ S 2 ]) , . . . , MD ( G [ S k ]) i , 16 wher e for every i ∈ [1 , k ] , S i is an x -slic e , wil l b e c al le d a factoring x -slice MD -sequence . In th e c ase x is isola te d, ~ S ( x ) = h{ x } , V \ { x }i is a factoring x -slic e se quenc e and ~ T ( x ) = h MD ( { x } , M D ( G [ V \ { x } ]) i a factoring x - slic e M D -se quenc e. F rom Definition 10, one can deriv e a brute force polynomial time algorithm that, giv en a graph G = ( V , E ) and a vertex x ∈ V , computes a factoring x -slice sequence ~ S ( x ). I f moreo v er, for ev ery slice S of ~ S ( x ), we compu te the mo dular d ecomp osition tree MD ( G [ S ]), we then obtain a factoring x -slice MD -sequence. Let us no w int ro duce the concept of slice decomp osition that will guide the recur s iv e com- putation of the mo du lar decomp osition of G . Definition 12. L et G = ( V , E ) b e a gr aph. A slice decomp osition of G is a laminar de c om- p osition 6 SD ( G ) o f G such that, for e v ery no n-le af no de u of SD ( G ) , if ~ C ( u ) = h u 0 , u 1 , . . . u t i is the se quenc e of child r e n of u , then L SD ( u 0 ) = { x } for some vertex x ∈ V and ~ S SD ( G ) ( x ) = h{ x } , L SD ( G ) ( u 1 ) , . . . , L SD ( G ) ( u t ) i i s an x -slic e se quenc e of the induc e d sub gr aph G [ L SD ( G ) ( u )] . w v u c d x y z b e a f g x a b c d e f g y z u v w x a b c d e f g y z u v w a b c d e f g y z u v w b c d e f g z u w c d e f u d f Figure 6: A slice-decomp osition SD ( G ) (on the right ) of the graph G = ( V , E ) (on the left). The blac k b o xes rep resen ts slices and the dashed r ed b o xes represents the slice-sequences defined by the c hildren of eac h no d e. F or example, S = { a, b, c, d, e, f , g } is an x -slice of G and ~ S SD ( G ) ( a ) = h{ a } , { b, c, d, e, f } , { g }i is an a -slice sequence of G [ S ]. The set o f activ e edges a sso ciate d to ~ S SD ( G ) ( a ) is A SD ( G ) ( a ) = { ab, ac, ad, ae, af , cg , dg , f g } . F urth ermore we notice that th e abov e tree is a particular case of laminar-tree as defined in section 3.1. Figure 6 ab o ve pr o vides an example of a slice d ecomp osition S D ( G ) of a graph G = ( V , E ). W e observ e that for ev ery vertex x ∈ V , a slice decomp osition SD ( G ) defin es an x -slice sequence ~ S SD ( G ) ( x ) of the su bgraph G [ S SD ( G ) ( x )] where S SD ( G ) ( x ) is the sm allest s lice in SD ( G ) cont aining 6 F ormally , a slice d ecomp osition should not b e defined as a laminar decomp osition since, as one can observe on th e example of Figure 6, some internal n o de may have a uniqu e child. But observe th at when this happ ens, the sli ce represented b y suc h a nod e u is a singleton and hence u is the parent no de of a leaf. F or a slice decomp osition, w e p refer to allo w this feature in order to b etter refl ect t h e full structure of the set of slices. 17 x . Notice that S = L SD ( G ) ( u ) w ith u b eing the paren t no de of x in SD ( G ). This observ ation allo w s to defi ne for the vertex x , the set of x -active e dges as A SD ( G ) ( x ) = A SD ( G ) ( u ) . w v u c d x y z b e a f g x y z Series c d u P arallel P arallel v w Prime g P arallel f a e b Figure 7: The factoring x -slice p erm utation ~ S G ( x ) = h{ b, e, a, f , g , d, c } , { x } , { y , z , u } , { v ; w }i of the graph G = ( V , E ) (in the left) obtained from the x -slice sequence ~ S SD ( G ) ( x ) from Figure 6. The mo dular decomp osition trees of the x -slices of ~ S G ( x ). The x -activ e edges of A SD ( G ) ( x ) are dra wn b elo w the slice sequence (in blac k, r ed and blue). 3.3 Computing a slice decomp osition with LexBFS The celebrated Lexicographic Breadth-First-Searc h (LexBFS for short) returns a sequence of v ertices of the input graph, that we call L exBFS se quenc e . In a n u tshell, LexBFS is a sea rch algorithm that emplo ys a lexicographic tie-breaking r u le to c ho ose the next v ertex to b e visited. Ev ery un visited v ertex main tains a lab el cont aining, at ea ch s tep of the searc h, the list o f its visited neighbors ordered with resp ect to th e searc h ordering computed s o far. The next ve rtex is selecte d among the u n visited ones with lexicographically largest lab el (see Algorithm 1). Algorithm 1 : L exicographic Breadth First Searc h (LexBFS) [43] Input: A graph G = ( V , E ). Output: A LexBFS sequence ~ σ on the vertices of V . 1 be g in 2 every vertex x is a ssigned the empty lab el ℓ ( x ) ← h ε i ; 3 let ~ σ ← h ε i b e the empty sequence, U ← V a nd i ← n ; 4 while U 6 = ∅ do 5 let x ∈ U be s uch tha t ℓ ( x ) is lexicogra phically larges t among all lab els of vertices of U ; 6 U ← U \ { x } ; 7 for every vertex y ∈ U ∩ N ( x ) do ℓ ( y ) ← ℓ ( y ) · h i i ; 8 ~ σ ← ~ σ · h x i and i ← i − 1; 9 end 10 end 11 return ~ σ ; 18 Theorem 4. [43] Given a gr aph G = ( V , E ) , Algorithm 1 c omputes a L exBFS se quenc e of V in time O ( n + m ) . F rom th e description of Algorithm 1, it is not obvious ho w to implemen t LexBFS in linear time (see for example [30]). In [34], a simple imp lementat ion based on the partition refinement tec hnique wa s describ ed. It a v oids th e managemen t of the lab els. Based on this partition refinement v ersion of LexBFS, we will show how LexBFS can b e extended (see Algorithm 2) to compute, in linear time, a slice decomp osition of the inpu t graph . Supp ose that ~ σ is a sequence on the v ertex set V of a graph G = ( V , E ). F or ev ery v ertex, x ∈ V , the set of vertic es that o ccur b efore x in ~ σ is denoted: V − ~ σ ( x ) = { y ∈ V | y ≺ ~ σ x } . Definition 13. L et ~ σ b e a L e xBFS se quenc e of the gr aph G = ( V , E ) . F or every ve rtex x , the LexBFS-slice of ~ σ starting at x is the set: S ~ σ ( x ) = { y ∈ V | x ~ σ y and N ( x ) ∩ V − ~ σ ( x ) = N ( y ) ∩ V − ~ σ ( x ) } . A su bset S ⊆ V is a L exBFS-slice of ~ σ if ther e exists a ve rtex x such that S = S ~ σ ( x ) . Observe that, if ~ σ is a LexBFS sequence of a graph G = ( V , E ), then f or ev ery v ertex x ∈ V , the LexB FS-slice S ~ σ ( x ) is precisely the set con taining ev ery v ertex y suc h that, at the step x is select ed by Algorithm 1, ℓ ( x ) = ℓ ( y ) (that is S ~ σ ( x ) is t he set of unn umb ered ve rtices with lexicographicall y large st lab el). Notice also, that for ev ery v ertex x , the LexBFS-slice S ~ σ ( x ) is a factor of ~ σ . Lemma 8. [16] L et ~ σ b e a L e xBFS se quenc e of a gr aph G = ( V , E ) . F or every L exBFS-slic e S of ~ σ , the se que nc e ~ σ [ S ] is a L exBFS se quenc e of G [ S ] . Let ~ σ b e a LexBFS sequence o f a graph G = ( V , E ). T o ev ery vertex x ∈ V , w e asso ciate the LexBFS-slice sequence on 2 S ~ σ ( x ) as ~ S ~ σ ( x ) = h{ x } , S 1 , . . . S k i , where th e sets S 1 , . . . S k are th e maximal LexBF S -slices of ~ σ that a re con tained in S ~ σ ( x ) and suc h that for ev ery 1 ≤ i < j ≤ k , S i ≺ ~ σ S j . Lemma 9. L et ~ σ b e a L e xBFS se quenc e of the gr aph G = ( V , E ) and let x b e a vertex of G . Then for e very vertex x , th e L exBFS-slic e se que nc e ~ S ~ σ ( x ) is an x -slic e se quenc e of G [ S ~ σ ] . Pr o of. By Lemma 8, it is sufficient to pro ve the statemen t for ~ S ~ σ ( x ) where x is th e first ve rtex of ~ σ , that is S ~ σ ( x ) = V . O bserve that the lexicog raph ic tie-breaking rule guarantee s that at eve ry step of Algorithm 1, among all u nvisited v isited, the intersect of neigh b orho o d of th e s elected v ertex y with the set of visited v ertices is maximal. Moreo ve r by Definition 13, ev ery set S i , 1 ≤ i ≤ k satisfies the u niform, the inclusion and the maximalit y p rop erties o f Definition 10, pro ving th e statemen t. As a direct consequence of Definition 13, it is easy to see that the LexBFS-slices of a LexBFS sequence ~ σ f orm s a laminar f amily . F rom Lemma 9, we conclude that a slice decomp osition SD ~ σ ( G ) of a graph G can b e obtained by accurately ordering the inclusion tree of the LexBFS- slices of a LexBFS sequence ~ σ . This is p recisely what Algorithm 2 implemen ts. 19 Algorithm 2 : E xtended Lexicographic Breadth First Searc h (LexBFS) [34] Input: A graph G = ( V , E ). Output: A LexBFS sequence ~ σ of G and the c orresp onding slice decomp osition SD ~ σ ( G ). 1 be g in 2 ~ σ ← h V i b e a se quence o n 2 V ; 3 SD ~ σ ( G ) is an o r dered tree with a unique internal no de (the ro o t) and who se le aves are mapp ed to the sets S ⊆ V b elo nging to the se q uence ~ σ ; 4 for i = 1 to | V | − 1 do 5 let x be a vertex of the i-th set S ~ σ ( i ) in ~ σ ; 6 if S ~ σ ( i ) 6 = { x } then 7 let ℓ b e the le a f of SD ~ σ corres p o nding to S ~ σ ( i ); 8 if S ~ σ ( i ) ∩ N ( x ) 6 = ∅ and S ~ σ ( i ) \ N ( x ) 6 = ∅ then 9 replace in ~ σ , the set S ~ σ ( i ) by the sequence h{ x } , S ~ σ ( i ) ∩ N ( x ) , S ~ σ ( i ) \ N ( x ) i ; 10 create, in SD ~ σ ( G ), three new leav es r esp ectively mapp ed to { x } , S ~ σ ( i ) ∩ N ( x ), and S ~ σ ( i ) \ N ( x ) attached, in this o r der, to ℓ ; 11 else 12 replace in ~ σ , the set S ~ σ ( i ) by the sequence h{ x } , S ~ σ ( i ) \ { x }i ; 13 create, in SD ~ σ ( G ), tw o new leaves re sp e ctively mapp ed to { x } , S ~ σ ( i ) \ { x } attached, in this order, to ℓ ; 14 end 15 end 16 for y ∈ N ( x ) su ch t hat y ∈ S ~ σ ( j ) with i < j do 17 if S ~ σ ( j ) \ N ( x ) 6 = ∅ then 18 replace in ~ σ , the set S ~ σ ( j ) by the seq uence h S ~ σ ( j ) ∩ N ( x ) , S ~ σ ( j ) \ N ( x ) i ; 19 replace in SD ~ σ ( G ) the no de corresp onding to S ~ σ ( j ) by tw o sibling no des S ~ σ ( j ) ∩ N ( x ) , S ~ σ ( j ) \ N ( x ) (in this order ); 20 end 21 end 22 end 23 for every non-le af no de u of SD ~ σ ( G ) do compute A SD ~ σ ( G ) ( u ); 24 return ~ σ (now c onsider e d as a se quenc e on V ) and SD ~ σ ( G ); 25 end Lemma 10. Given a gr aph G = ( V , E ) , A lgorithm 2 c omputes a L e xBFS se quenc e ~ σ of G and a slic e de c omp osition S D ~ σ ( G ) . The time c omplexity of A lgorithm 2 is O ( m + n ) with n = | V | and m = | E | . Pr o of. Be side the compu tation of SD ~ σ ( G ), the fact that Algorithm 2 computes a LexBFS se- quence ~ σ of G in time O ( n + m ) follo ws from [34]. Let u s prov e that SD ~ σ ( G ) is a slice decomp o- sition of G . It can b e obs erv ed that at ev ery step 1 ≤ i ≤ | V | − 1, th e set S ~ σ ( i ) is p recisely the LexBFS-slice S ~ σ ( x ), where x is the i -th selected verte x (see [34]). O bserve that by construction, SD ~ σ ( G ) con tains a no de u suc h that L SD ~ σ ( u ) = S ~ σ ( x ) and that this node u is a c h ild of the no de v suc h that L SD ~ σ ( v ) is the smallest LexBFS-slice o f ~ σ con taining S ~ σ ( i ). Moreo ver that, b y constru ction again, th e s equence of c h ild ren of u is precisely t he s equence ~ S ~ σ ( x ), w h ic h by Lemma 9 is an x -slice sequence of G [ S ~ σ ]. It follo ws that SD ~ σ ( G ) is a slice decomp osition of G . Let us no w analyse the time complexit y of Algorithm 2. O bserv e firs t that build in g the ordered inclusion tree of LexBF S slices can be done in linear time in the n um b er o f LexBFS slices, that is O ( n ). It remains to d escrib e ho w to compute the set of activ e edges for ev ery no de 20 u of SD ~ σ ( G ). T o th at aims, let u s assume that the lexicographic lab el ℓ ~ σ ( x ) (see Algorithm 1) of ev ery v ertex x is computed. Observe also that for ev ery non-leaf no de u , the set L SD ~ σ ( G ) ( u ) is a factor of ~ σ , d enoted I ~ σ ( u ), that can also b e computed along the computation of SD ~ σ ( G ) w ithout additional co mp lexit y cost. No w to c ompu te th e s et of activ e edges A SD ~ σ ( G ) ( u ) associated to no de u , we p r o ceed as follo ws. Consider the LexBFS-slice S = L SD ~ σ ( G ) ( u ) and let ~ S ~ σ ( x ) = h x, S 1 , . . . S k i b e th e asso ciated LexBFS-slice s equence of G [ S ]. F or 1 ≤ i ≤ k , w e let x i denote the fi rst v ertex in ~ σ of S i . Obs erv e that x is the first child of u in SD ~ σ ( G ) and that for 1 ≤ i ≤ k , x i is the first c hild of u i , the c hild of u su c h that S i = L SD ~ σ ( G ) ( u i ). Th en: A SD ~ σ ( G ) ( u ) = { y z | ∃ 1 ≤ i ≤ k , y ∈ S i , z ∈ ℓ ~ σ ( x i ) \ ℓ ~ σ ( x ) } . Since for 1 ≤ i ≤ k , ℓ ~ σ ( x ) is a pr efi x of ℓ ~ σ ( x i ), an a mortized co mp lexity argument sho ws that b y searc hing eac h lexico graphic label O (1) times, one can compute the sets A SD ~ σ ( G ) ( u ) for ev ery non-leaf no d e u . It follo ws that the SD ~ σ ( G ) can b e computed in O ( n + m ), proving the statemen t. It is worth noticing that Algorithm 2 computes a s lice-decomposition tree in a Depth-First- Searc h mann er. Definition 9 does not sp ecify the w ay the sets of a ctiv e edges has to b e stored. The pr o of ab o ve yields a list represent ation of these sets. Within the same complexit y cost, for eac h vertex x it is p ossib le to build the adjacency lists o f the sub graph G x of G wh ose v ertices are S ~ σ ( x ) and edges A SD ~ σ ( G ) ( u ) where u is the no de of SD ~ σ ( G ) suc h that S ~ σ ( x ) = L SD ~ σ ( G ) ( u ). Slice sequence, slice decomp osition and graph searc hes. Ob serv e that as an o rd ered tree, a slice decomp osition S D ( G ) of a graph G is asso ciated with a v ertex sequence ~ σ SD ( G ) . It is natural to ask whether su c h verte x sequences corresp ond sequences generated by graph searc h algorithm. T o answer th is qu estion, let us observe that some slice sequences cannot b e computed usin g LexBFS (see Figure 8). If, instead of selecting a v ertex with lexicographicall y maxim um lab el, w e searc h a graph b y s elected a vertex wh ose neigh b ourh o o d in the set of visited vertic es is maximal for the inclusion, we obtain the so-called M aximal Inclusion Se ar ch (MIS) [46, 1 5]. It can b e sho wn that ev ery slice sequence of a graph can b e obtained from a MIS ordering. Ho w eve r, the con ve rs e is false. There are MIS ord erings b reaking the maximalit y of s lices (for example the ordering ~ τ in Figure 8). This can b e fixed by imp osing that once the MIS search e nters a slice, it visits the whole slice. Th is yields what c an b e c alled a r ecursiv e MIS searc h. 4 F rom lo c al to global mo dules In this section, we present an algorithm that, giv en a factoring x -slice MD -sequence, returns a factoring x -mo dular M D -sequence. T o p r o v e t h e corr ectness of the algorithm, we first mak e a detour to explain ho w a partitive f amily F on a groun d set S can b e fi ltered with resp ect to a set X ⊂ S into a new partitiv e family , denoted F | X , such that no element Y ∈ F | X o v erlaps X (see Subsection 4.1). Based on this result, w e d esign a marking algorithm that t ake s as input the mo dular d ecomp osition tree MD ( G [ S ]) of an x -slice of G and returns a partitiv e forest wh ose comp onent s corresp ond to the mo dular deco mp osition trees of the m o dules o f M x max ( G ) that are con tained in S . Applyin g this algorithm to the mo du lar d ecomp osition trees of a factoring 21 a b c d e f g Figure 8: The ve rtex o rd ering ~ σ = h a, b, c, d, f , g , e i is not a LexBFS ordering. Ho w ev er the partitioning s equ ence h{ a } , { b, c, d } , { f , g } , { e }i is a a -slice sequence. W e obs er ve that ~ σ is a MIS ordering. But ~ τ = h a, b, c, d, f , e, g i is also a MIS ordering in whic h the a -slice { f , g } is not consecutiv e. x -slice M D -sequence and by carefully ord ering the r esu lting comp onen ts, w e can then compu te a factoring x -mo dular MD -sequence of G (see Sub section 4.2). 4.1 Filtering a partit iv e family , the marking algorithm Let A ( S b e an elemen t of F ⊆ 2 S . Recall that a s ubset X ( S is a splitter of A , if A ∩ X 6 = ∅ and A \ X 6 = ∅ , and that if X is not a s plitter of A , then A is u ni f orm with resp ect to X (or X - u niform ). Finally , w e sa y that F is X -uniform if every A ∈ F is X -u niform. F or a subset X ( S , we let F | X denote the sub -family of F defin ed as follo w s (see Figure 9 for an example): F | X = A ∈ F | A is X -uniform . Lemma 11. L et F ⊆ 2 S b e a p artitive family on gr ound set S . If X is a subset of S , then F | X is a p artitive f amily on gr ound set S . Pr o of. Observ e that axiom (i) of Definition 2 trivially h olds. Ind eed, for ev ery x ∈ S , either x ∈ X or x ∈ S \ X , implying that { x } ∈ F | X . T o pro ve axiom (ii) , let u s consider A and B t wo o v erlapping elements of F | X . Observe that, since A ∩ B 6 = ∅ , either A ∩ X = ∅ and B ∩ X = ∅ , or A ⊆ X and B ⊆ X . I n b oth cases, the subsets A ∩ B , A \ B , B \ A , A △ B and A ∪ B are X -uniform. Since A and B b elong to F , w hic h is partitiv e, th ese subsets also b elong to F . Moreo ver, as eac h of them is X -un iform, they all b elong to F | X . As F | X is a partiti ve family , it is represen ted b y a partitiv e forest T F | X . Let us stud y the relationship b et w een T F | X and T F . Esp ecially , w e wa nt to un derstand ho w th e t yp es of the no des of T F | X are related to the type of the no des of T F . Observe th at if F is X -uniform, then F = F | X . So let u s assume th at F is not X -u niform. Th en T F | X is a forest con taining seve ral comp onent s and if T is one of these comp onen ts, th en either L ( T ) ∩ X = ∅ , in which case we sa y that T is X -e mpty , or L ( T ) ⊆ X , in wh ic h case we sa y that T is X -ful l . Finally , a no de u of T F is X -uni f orm if L T F ( u ) do es not o v erlap X . Lemma 12. L et F ⊆ 2 S b e a p artitive family on gr ound set V and c onsider X ⊆ S and A ∈ F . Then: (1) Supp ose that A is X -unif orm. Then, every set B ∈ F , such that B ⊆ A , b elongs to F | X . Mor e over, if A is str ong in F , th en A is str ong in F | X and type F ( A ) = t yp e F | X ( A ) . 22 0 1 2 3 4 5 6 7 8 T F 9 10 11 12 13 14 0 1 2 T F | X 3 4 5 6 7 8 9 10 11 12 13 14 Figure 9: On the left, a partitiv e tree T F . The circle in tern al no des are degenerat e while the square no d es are prime. Ob serv e that { 3 , 4 } / ∈ F as their paren t node is prime, while { 9 , 10 } ∈ F as their paren t no d e is degenerate. S imilarly , w e h a v e { 5 , 6 , 7 , 8 } ∈ F . On the righ t, the p artitive forest T F | X represent s th e family F | X where X = { 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 13 } (red lea ves). Observ e that { 9 , 10 } ∈ F | X and { 5 , 6 , 7 , 8 } ∈ F | X while { 3 , 4 } / ∈ F | X . (2) Supp ose that X is a splitter of A . Then, every set B ∈ F , such that A ⊆ B , do es not b elong to F | X . Pr o of. (1 ) If A is X -uniform, then, by d efi nition, ev ery set B ⊆ A is X -uniform since A ⊆ X or A ∩ X = ∅ imp lies B ⊆ X or B ∩ X = ∅ . Observ e that by definition of F | X , ev ery elemen t of F | X is an elemen t of F . So if A is not strong in F | X , there exists B ∈ F | X o v erlaping A . But then B also b elongs to F , implying that A is not strong in F . Supp ose n o w that t yp e F ( A ) = degenerate . By Theorem 1, for every sub set C ⊆ C T F ( A ) of c hildren of A , S B ∈C B b elongs to F . By the argumen t ab o ve, sin ce S B ∈C B is a subs et of A , it b elongs to F | X . This implies that typ e F | X ( A ) = degenerate . The same argument shows that if t yp e F | X ( A ) = degenerate , then t yp e F ( A ) = degenerate . This also implies that t yp e F | X ( A ) = prime if and only if t yp e F ( A ) = p rime . (2) Su pp ose th at X is a s plitter of A . Th en ev ery set B conta inin g A as a subset verifies B ∩ X 6 = ∅ and B \ X 6 = ∅ . So X is a sp litter for B a nd B / ∈ F | X . Lemma 13. L et F ⊆ 2 S b e a p artitive fam ily on gr ound set S and let A b e an element of F | X with X ⊆ S . (1) If A is str ong in F , then type F ( A ) = t yp e F | X ( A ) . (2) Otherwise, ther e exists a str ong element B ∈ F such that type F ( B ) = deg enerate and a non-trivial subset C ⊆ C T F ( B ) of childr en of B such that A = S C ∈C C is X -unif orm. And mor e over, A is a r o ot of F | X and t yp e F | X ( A ) = degenerate . Pr o of. Observ e that by d efinition of F | X , A ∈ F and th ereb y T h eorem 1 applies to A . By Lemma 12 , if A is strong in F | X , then typ e F | X ( A ) = type F ( A ). S o assume that F con tains a strong element B s uc h that type F ( B ) = degenerate , A = S C ∈C A C for some non-trivial su bset of C F ( B ), the children of B in F | X . Since C is a non trivial subset of c hildren of B , there exists a non trivial su bset C ′ ⊂ C F ( B ) ov erlapp ing C . As t yp e F ( B ) = degenerate , th e set A ′ = S C ′ ∈C ′ C ′ is an ele ment of F that ov erlaps A . O bserve that X is a sp litter of A ′ . Th en, b y Lemma 12, X is a splitter of B and thereby no elemen t of F cont aining B b elongs to F | X . Th is imp lies that A is a ro ot of F | X . Finall y , o bs er ve th at ev ery children of B in C A is X -uniform and that 23 for ev ery su b set C ′ ⊆ C A , S C ∈C ′ C is X -uniform and th us b elongs to F | X . This implies that t yp e F | X ( A ) = degenerate . The definition of F | X naturally extends to a subset X ⊆ 2 S . W e let denote F |X = A ∈ F | ∀ X ∈ X , A is X -uniform . The follo wing ob s erv ation is an easy consequence of the d efinition of F X . It implies that an easy ind uction on the size of X sho w s that the statemen ts of th e three lemmas ab o ve naturally generalize to a set X ⊆ 2 S . Observ ation 5. L et F b e a p artitive family on gr ound set S and let X ⊆ S b e a subset b elonging to X ⊂ 2 S . If X ′ = X \ { X } a nd F ′ = F |X ′ , then F |X = F ′ | X . Let u s now describ e a marking algorithm (Algorithm 3) that, giv en a partitiv e forest T F of a p artitiv e f amily F on the groun d s et S , and a subset X ⊂ 2 S computes the p artitiv e forest T F |X . More precisely , the algorithm returns a p artitiv e tree T S whose no des are equip p ed with lab els in { empt y , homogeneous , dead , b rok en } and flag in {◦ , ⋆ } (see line 3, 22 and ?? ). The lab els allo w s to ident ify T F |X whic h is con tained in T S (see Lemma 14). The fl ags are required b y Algorithm 4 and will b e d iscu ssed in Su bsection 4.2. Giv en that T is the curr en t partitiv e tree, Algorithm 3 pro ceeds in t wo steps: 1. First, for eac h su bset X ∈ X (line 4), Algorithm 3 searc hes T in a b ottom-up mann er (line 7) in o rd er to identify t wo sets of no d es, namely Full ( X ) and Ma rk ed ( X ). The set F ull ( X ) conta ins ev ery node u of T su c h that L T ( u ) is X -full. The no d es in Full ( X ) are assigned the lab el homogeneo us (l ine 13). When the b ottom-up searc h te rm inates, th e set M a rk ed ( X ) conta ins the lo w est no d es in T that are not X -uniform . Cons equen tly , the no des in Mark ed ( X ) are assigned the lab el dead (line 20), indicating that the corresp onding sets of lea ve s do n ot b elong to F |X . If a no de u in Mark ed ( X ) is degenerate, it ma y b e refined (line 14 ) to create new degenerate c hildr en, one u A , lab elled homogeneous , gathering the former c hildren of u that b elongs to F ull ( X ), th e other u B , lab elled empty , gathering the other c hildren of u . Obser ve that u A and u B corresp onds to strong elemen ts of F |X . 2. In the second step, once ev ery set X ∈ X has b een pro cessed to s earch and refin e T , Algorithm 3 tra v erses T in a p ostorder (li ne 27) to pro cess the nodes that k ept their initial lab el empty . There are tw o cases for a no de u suc h that Lab el T ( u ) = empt y : (i) Suc h a no de u ma y ha v e a descendent v su c h that Lab el T ( v ) = dead . Observe that, in this case, L T ( u ) is not X -un iform and thereby do es not b elong to F |X . Th ese no d es will be assigned label b rok en (the distinctio n b et we en the lab els dead and bro ke n is only required for the sak e of Algorithm 4 and will b e discussed in Sub s ection 4.2). (ii) O therwise, observe that for eve ry descendent v of u , Lab el T ( v ) = empty . Then L T ( u ) is X -empt y (and th us X -uniform) and thereby b elongs to F |X . When pro cessing a dead or b rok en degenerate no de u (line 33), Algorithm 3 gathers und er a sin gle new degenerate nod e u A , ev ery c hild w such that Lab el T ( w ) ∈ { empt y , homogeneous } . Indeed, L T ( u A ) is an X -emp ty set and thereb y b elongs to F |X . W e set Lab el T ( u A ) = empt y . 24 T o summarize, for a no de u of the lab elled partitiv e tree returned by Algorithm 3 , w e remark that: • if Lab el T ( u ) = empt y or Lab el T ( u ) = h omoge neous , then L T ( u ) is X -uniform. In the former case, we ha ve L T ( u ) is X -empt y . In the latter case, there exists X ∈ X such that L T ( u ) is X -full. • if Lab el T ( u ) = dead or Lab el T ( u ) = b rok en , then L T ( u ) is not X -uniform. In the former case, th ere exists X ∈ X a nd tw o c hildren v A and v B of u such that L T ( u ) is n ot X -uniform , L T ( v A ) is X -fu ll and L T ( v B ) is not X -empt y . In th e latter case, u has a descenden t v suc h that L T ( u ) = dead . Lemma 14. L et F b e a p artitive family on gr ound set S . Supp ose that T S is the lab el le d p artitive for est r eturne d by Algorithm 3 if T F and X ⊂ 2 S ar e given as input. L et U b e the subset of no des of T such that, for every no de u ∈ U , Lab el T S ( u ) = homogene ous or La b el T S ( u ) = empt y . Then F |X is the p artitive fam ily r epr esente d by the subfor est T S [ U ] of T S induc e d by the no des of U . Pr o of. Let us observe that the tree T pro cessed by Algorithm 3 s atisfies the follo wing inv ariants an prop erties. Let u b e a no de of T . W e obs erv e that: (i) if at some step Lab el T ( u ) = homogene ous , then at eve ry further step Lab el T ( u ) 6 = empt y ; (ii) if at some s tep Lab el T ( u ) = dead , th en at ev ery f u rther step Lab el T ( u ) = dead ; (iii) if at some step Lab el T ( u ) = b rok en , then at ev ery fu rther s tep Lab el T ( u ) = b rok en ; Observe fir st that during the m ost exte rn al lo op at line 4-25, th en for ev ery no de u of T , Lab el T ( u ) ∈ { empty , homogeneous , dead } . Moreo ver, the lab el e mpty is only assigned to newly created no de (line 18 and line 33). S o in v arian t (i) holds . Observ e also, once the lab el dead has b een assigned to a no de (at line 20) is never u p dated. Th is is also the case for lab el bro ke n . This is still true d u ring the p ostorder trav ersal (line 27 -line 36), since the lab el brok en is assigned to no de not lab elled dead (line 29). S o in v arian ts (ii) and (iii) h old. Claim 1. L et v b e an anc estor of the no de u in T S . If Lab el T S ( u ) ∈ { dead , b rok en } , then Lab el T S ( v ) ∈ { dead , brok en } This is a consequence of inv arian ts (ii) and (iii) and of the f act that in the p ostorder trav ersal of T (line 27-line 36), empt y or homogeneo us lab els are only assigned to newly created no des (line 32-line 33). Claim 2. F T S [ U ] = F |X . Pr o of o f Claim: By Theorem 1, showing that F T S [ U ] = F |X reduces to prov e th at the set of strong elemen ts of F T S [ U ] and of F |X are the same and that a strong ele ment A of F T S [ U ] is degenerate if and only if it is degenerate in F |X . (1) F T S [ U ] ⊆ F |X : Observe that by construction, the partitiv e forest T S returned by Algorithm 3 is a refinement of the partitive f orest T F giv en as inpu t. By Claim 1, if u is a n o de of U , th en ev ery descendent nod e v of u also b elongs to U . Moreo ver, for ev ery n ewly in tro duced no d e u , we ha ve typ e T S ( u ) = degenerate and if v is the f ather of u , then type T S ( v ) = degenerate . It 25 Algorithm 3 : M a rk P artitive F o rest Input: A partitive forest T F representing a partitive family F on gr ound s e t S and a family of subsets X ⊆ 2 S . Output: A partitive fore s t T S whose no des a re lab elled e mpty , homo geneous , dead or broken . 1 be g in 2 T ← T F ; 3 foreac h no de u of T do Lab el T ( u ) ← empty a nd Fla g T ( u ) ← ◦ ; 4 foreac h X ∈ X do 5 let Explore ( X ) b e the leaves of T cor resp onding to elements of X ; 6 Mark ed ( X ) ← ∅ and Full ( X ) ← ∅ ; 7 while E xplore ( X ) 6 = ∅ do 8 let u be a no de o f Explore ( X ), p be its parent no de a nd S ( u ) b e its sibling s; 9 mov e u fro m Explore ( X ) to Full ( X ); 10 if p / ∈ Mark ed ( X ) then add p to Mark ed ( X ); 11 if p ∈ Mar ked ( X ) and ∀ v ∈ S ( u ) , v ∈ F ull ( X ) then mov e p from Mark ed ( X ) to Explore ( X ) ; 12 end 13 foreac h no de u ∈ F ull ( X ) such t hat Lab el T ( u ) = empty do La be l T ( u ) = homog eneous ; 14 foreac h no de u ∈ Mark ed ( X ) do 15 let A b e the se t c o ntaining every child v of u such that v ∈ Full ( X ), and let B b e the set co nt aining the children of u not in A ; 16 if ty p e T ( u ) = degenerate then 17 if | A | > 1 the n in T , cre a te a no de u A such that ty p e T ( u A ) = deg enerate the father of which is u , the no des in A b e c ome the children o f u A , and Lab el T ( u A ) ← homog eneous , Flag T ( u A ) ← ⋆ ; 18 if | B | > 1 then in T , crea te a no de u B such that ty p e T ( u A ) = degenerate the father of which is u , the no des in B b eco me the children o f u B , and Lab el T ( u B ) ← empty , Flag T ( u B ) ← ◦ ; 19 end 20 if Lab el T ( u ) 6 = dead then 21 Label T ( u ) ← dead ; 22 foreac h child v of u such t hat v ∈ Full ( X ) do Flag T ( v ) ← ⋆ ; 23 end 24 end 25 end 26 let σ = h u 1 , . . . , u t i be a p osto rder of T ; 27 for j = 1 to t do 28 if Lab el T ( u j ) = dead or Lab el T ( u j ) = brok en then 29 if Lab el T ( v ) 6 = dead , with v the p ar ent no de of u j , then Lab el T ( v ) ← brok en ; 30 if Lab el T ( u j ) = br oken and u j is de gener ate then 31 let A b e the se t containing every child w of u j such that Lab el T ( w ) ∈ { empty , ho mogeneo us } ; 32 if | A | > 1 and ∃ w ∈ A , Lab el T ( w ) = homogen eous then in T , cr eate a no de u A inheriting u j ’s type, the no des in A b e c ome the children o f u A , make u j the father of u A , Lab el T ( u A ) ← ho mogeneo us and Flag T ( u A ) ← ◦ ; 33 if | A | > 1 and ∀ w ∈ A , Lab el T ( w ) = empty then in T , crea te a no de u B inheriting u j ’s type, the no des in A b e c ome the children o f u B , make u j the father of u B , Lab el T ( u B ) ← emp ty and Flag T ( u B ) ← ◦ ; 34 end 35 end 36 end 37 return T S ← T ; 38 end 26 follo ws that F T S ⊆ F . Moreo ve r, b y definition of U , ev ery ele ment A ∈ F T S [ U ] is X -uniform, whic h implies th at F T S [ U ] ⊆ F |X . (2) F |X ⊆ F T S [ U ] : Let A b e a strong elemen t of F |X . Sup p ose t h at X = { X 1 , . . . X i } . Sin ce A ∈ F w e h a v e tw o cases to consider: • A is strong in F and then t yp e F ( A ) = t yp e F |X ( A ). Let u b e the n o de of T F suc h that A = L T F ( u ). S in ce A is X -un iform, for every X ∈ X , we h a v e either A ⊆ X j or A ∩ X = ∅ . Supp ose fi rst that for ev ery X ∈ X , A ∩ X = ∅ . Then observe that Lab el T S ( u ) = empt y and for eve ry descendant v of u , La b el T S ( v ) = empt y . Other w ise, let 1 ≤ j ≤ i b e the smallest in teger suc h that A ⊆ X j . Then Algorithm 3 (line 13 dur ing the lo op p ro cessing X j ) sets Lab el T S ( u ) = homoge neous and for ev ery descendan t v of u , Lab el T S ( v ) = homogeneous (if i t w as not already the case). Since A is X -uniform, b y in v arian t (i), this lab el k eeps unc hanged du ring fur ther lo ops. In b oth cases the subtree of T S ro oted at u is includ ed in a comp onent of the sub f orest T S [ U ] and thereby A ∈ F T S [ U ] . • F con tains a strong ele ment B su c h that t yp e ( B ) = dege nerate and A = S w ∈C L T F ( w ) with C a non-trivial subset of c hildren of the no de w of T F suc h that B = L T F ( w ). Since A is X -uniform, for eve ry X j , 1 ≤ j ≤ i , we ha v e either A ⊆ X j or A ∩ X j = ∅ . Supp ose that wh en the for-lo op (line 4-line 25) fin ishes, the curr en t partitive tree T con- tains a nod e u su c h that A = L T ( u ). Then o bs er ve that u is a degenerate no d e (see line 17 or line 18) and the c hildren of u form a sub set of children of w in T F . Moreo ver, if for ev ery X ∈ X w e ha ve A ∩ X = ∅ , then Lab el T S ( u ) = empt y (line 18) and for eve ry descendan t v of u , Lab el T S ( v ) = e mpty . Otherwise, w e ha v e Lab el T S ( u ) = homogeneous (line 17) and for ev ery descendant v of u , Lab el T S ( v ) = homogeneous . If follo ws that th e subtree of T S ro oted at u is included in a comp onen t of the su bforest T S [ U ] and thereb y A ∈ F T S [ U ] . Let us assume that when the for-lo op (line 4-line 25) has fin ished, the curren t tree T do es not con tains a no d e u suc h that A = L T ( u ). As T is a refinement of T F , there exists a degenerate n o de w in T such that A = S C ∈C L T F ( C ) w ith C a n on-trivial subset of c h ildren of the node w . Observe that Lab el T ( w ) 6 = dead , as ot h er w ise, C w ould ha ve b een s ep arated from the other children of w in the p r evious for-lo op (line 4-line 25). Observe moreo ver that for ev ery child v / ∈ C , L T ( v ) is not X -u niform. This imp lies that v h as a descendan t n o de v ′ suc h that Lab el T ( v ′ ) = dead . I n turn, by Claim 1, since Lab el T ( w ) 6 = dead , we obtain that Lab el T ( w ) = brok en . Thereby the conditions o f the test of line 30 h old and a new degenerate no d e u su c h that A = L T ( u ) is created (line 32 or line 33). As in the pr evious case, if for ev ery X ∈ X w e ha v e A ∩ X = ∅ , then Lab el T S ( u ) = empty (line 33) and for every descendant v of u , Lab el T S ( v ) = empty . Otherwise, we hav e Lab el T S ( u ) = homogene ous (line 32) and for every d escendan t v of u , Lab el T S ( v ) = homogene ous . If follo ws th at the subtree of T S ro oted at u is included in a comp onent of the subf orest T S [ U ] and thereby A ∈ F T S [ U ] . ⋄ Since the ord er in wh ic h the sets of X are p ro cessed has n o impact on the fin al r esult, the correctness of Algorithm 3 follo ws fr om the ab o ve claim. Lemma 15. The time c omplexity o f Algorithm 3 is O ( | S | + P X ∈X | X | ) . 27 Pr o of. F or eac h set X ∈ X , Algorithm 3 searches the curr en t partitiv e tree T in a b ottom-up manner starting from the lea ve s b elonging to X . Ob serv e that, after th e w hile loop (line 7), for ev ery searched no de u , u ∈ M a rk ed ( X ) ∪ F ull ( X ). Since T do es n ot contai n unary internal no de, we hav e that | Mark ed ( X ) ∪ F ull ( X ) | ≤ 2 · | X | . S o th is tra versal can b e p erformed in time O ( | X | ). Moreo v er, the cost of creating new internal node, if needed at line 17 a nd line 18, is also in time O ( | X | ). Finally , a postorder sequence σ is computed and a fu ll t rav ersal of T is then p erformed (line 27). Pro cessing node u j during the p ostorder tra versal ma y require the creation of a new node. Obs er ve that this operation is linear in th e n umber of c h ildren of u i . This implies that the p ostorder tra versal of T can b e p erformed in time linear in | T | whic h is O ( | S | ). T o conclude this section, let u s observ e that to apply Algorithm 3 in the setting of m o dular decomp osition of a graph, one need the follo wing m o dification to handle the creation of new degenerate no d es. Indeed, in the mo dular d ecomp osition, degenerate no d es are either series or p ar al lel no des. It suffices that at line 17, 18 and 33 of Algorithm 3, th e newly created no de, sa y the c hild v of u , satisfies type T ( v ) = t yp e T ( u ) (see Figure 10). As a dir ect corollary of Lemma 14 and Lemma 15, w e obtain the follo wing theorem: Theorem 5. L et S b e a subset of vertic es of a gr aph G = ( V , E ) . Algorith m 3 app lie d on MD ( G [ S ]) and X = N ( x ) ∩ S | x / ∈ S c omputes, in O ( | S | + P X ∈X | X | ) -time, a lab el le d p arti- tive for est T S such that the p artitive for est M D ( G [ S ]) |X , r epr e senting the set of mo dules of G that ar e su bsets of S , is the subfor est of T S induc e d by the no des with lab els in { empt y , homogeneous } . 0 3 4 7 8 1 2 5 6 9 10 11 MD ( G [ S ]) 0 3 4 7 8 1 2 5 6 9 10 11 ⋆ u v w ⋆ ⋆ ⋆ T S Figure 10: L et G = ( V , E ) b e a graph suc h that V = S ∪ { y } with N ( y ) = { 1 , 2 , 5 , 6 , 9 , 10 , 1 1 } and M D ( G [ S ]) is d epicted on the left. Square, circle and diamond no des resp ectiv ely r epresen t prime, series and p arallel nod es. I n T S , the b lac k no d es are dead while th e red nod es are homogene ous . Applyin g Algo rithm 3 to G an d M D ( G [ S ]) return s the tree T S . O bserv e that as { 0 , 1 , 2 } is a parallel mo d ule of G [ S ], so is { 1 , 2 } . This i s why a new parallel homo geneous no de u with leaf set { 1 , 2 } is generated in T S . Th e s ame h app ens for { 9 , 10 , 11 } . How ever, as { 3 , 4 , 5 , 6 } is a p rime mo dule of G [ S ], { 5 , 6 } is not a mo du le of G [ S ] nor of G . S o the prime no de with leaf set { 3 , 4 , 5 , 6 } is lab elled dead . Finally , the ro ot no de is series and it has one u niform c hild and three non-uniform c hild ren. Th is generate s a new series no de v initial ly labelled empt y . Since this no de v has t wo dead c hild ren and t w o children w ith empty lab el, a nother series no d e w with Lab el T S ( w ) = empty is created as the f ather of lea v es 7 and 8. Observ e that Lab el T S ( v ) = brok en . F ou r no des receiv e th e ⋆ fl ag. F rom Theorem 5, wh en applied on M D ( G [ S ]) and on X = { N ( x ) ∩ S | x / ∈ S } , Algorithm 3 returns a lab elled partitiv e tree that allo ws to retriev e M D ( G [ M ]) for eve ry (maximal) mo du le M of G th at is cont ained in S . When S is an x -slice, the remaining task is to ord er these 28 mo dular d ecomp osition trees in order to b uild a factoring x -mo du lar MD -sequence of G . Ho w to ac hiev e this is d escrib ed in Subsection 4.2. Before mo ving to this task, let u s mak e s ome additional observ ations on the r esu lt of Algorithm 3. Observ ation 6. L et S b e a subset of vertic es of a gr aph G . L et T S b e the lab el le d p artitive tr e e r eturne d by Algorithm 3 applie d on MD ( G [ S ]) and X = N ( x ) ∩ S | x / ∈ S . Then: 1. for every no de u of MD ( G [ S ]) , ther e exists a no de u ′ of T S such that L MD ( G [ S ]) ( u ) = L T S ( u ′ ) and t yp e MD ( G [ S ]) ( u ) = t yp e T S ( u ′ ) . Her e after, we say tha t u and u ′ ar e no de- mates of e ach other; 2. for e v ery no de u ′ of T S , ther e exists a no de u of MD ( G [ S ]) such that L T S ( u ′ ) ⊆ L MD ( G [ S ]) ( u ) and t yp e T S ( u ′ ) = t yp e MD ( G [ S ]) ( u ) ; 3. mor e over, eve ry no de u ′ of T S that is not the no de-mate of a no de of MD ( G [ S ]) is de g en- er ate and has exactly two childr en. 4.2 Extracting and sort ing Let us consider a connected graph G . Observe that otherwise th e mo dular decomp ositio n tree of G derive s easily from the mo du lar d ecomp osition tree of its connected comp onents. Let ~ T ( x ) b e a factoring x -slice MD -sequence resulting from the factoring x -slice sequence ~ S ( x ). S upp ose no w that Algorithm 3 has b een applied to ev ery mo dular decomp osition tree M D ( G [ S i ]), with S i an x -slice of ~ S ( x ), using the sets X i = N ( y ) ∩ S | y ∈ V and S i ≺ ~ S ( x ) y . And let T S i ’s b e the resulting lab elled partitiv e trees. The task of Algorithm 4 is t wofo ld. First, to effectiv ely extract the MD ( G [ S i ]) |X i ’s from the T S i ’s, wh ic h thanks to Theorem 5 corresp onds to no des with lab els in { empty , homogeneous } . Seco nd , in the meanwhile, Algorithm 4 has to s ort the corresp onding subtrees in order to co mp u te a factoring x -mo dular MD -sequence ~ T m ( x ). T o that aim, the c hildren of de ad and b rok en no des need to b e sorted in a d ifferen t manner. Before describing and pro ving Algorithm 4, we c haracterized the mo dules of M x max ( G ) that are con tained in a slice. Lemma 16. L et x b e a vertex of a gr aph G = ( V , E ) and let ~ P ( x ) = h{ x } , S 1 , . . . , S k i b e an x -slic e se quenc e. Consider for 1 ≤ i < k the set X i = { N ( y ) | y ∈ S j , j > i } and set X k = ∅ . Then a mo dule M b elongs to M x max ( G ) if and only if ther e exists a slic e S i , 1 ≤ i ≤ k , and a r o ot no de r of MD ( G [ S i ]) |X i , suc h that M = L MD ( G [ S i ]) |X i ( r ) . Pr o of. Supp ose th at M ∈ M x max ( G ). Then b y Lemma 6, th ere exists an x -slice S i suc h that M ⊆ S i . By Th eorem 1, MD ( G [ S i ]) |X i con tains a no de u suc h that either M = L MD ( G [ S i ]) |X i ( u ) or there exists a subset C of u ’s c hildren suc h that M = S v ∈C L MD ( G [ S i ]) |X i ( v ). But as M is maximal, the former case holds and moreo v er u is a ro ot of MD ( G [ S i ]) |X i . Supp p ose th at for some slice S i and some r o ot r of M D ( G [ S ]) |X i , M = L MD ( G [ S i ]) |X i ( r ). Observe that the partitive family F i represent ed by MD ( G [ S i ]) |X i con tains the mo dules of G that are con tained in S i and thereb y that d o not con tain x . Indeed, by co nstr uction of MD ( G [ S i ]) |X i , ev ery set M ′ ∈ F i is a mo d ule of G [ S i ] that i s N ( z )-uniform for every v ertex z suc h that S i ≺ ~ P ( x ) z . As S i is an x -slice, M ′ is also N ( y )-uniform for every vertex y s u c h that y ≺ ~ P ( x ) S i . This implies that M ′ is a mo dule of G n ot con taining x . As M = L MD ( G [ S i ]) |X i ( r ), among the mo du le of G not con taining x and included in S i , M is maximal. By Lemma 6, ev ery mo dule of G n ot contai nin g x is a subset of some x -slice. This implies that M ∈ M x max ( G ). 29 As a consequence of Lemma 16 and Theorem 5, the mo du les in M x max ( G ), and the mo du lar decomp osition tree of their induced su b graphs, corresp ond to the ro ots of the su btrees ind uced b y n o des with lab els in { empt y , homogeneous } . Giv en a factoring x -slice M D -sequence ~ T s ( x ), Algorithm 4 first calls Algorithm 3 to lab el the mo du lar decomp osition tree of eac h x -slice with resp ect to the v ertex sets defined with the activ e edges of ~ T s ( x ). Then, when pr o cessing the subtree T i corresp ondin g to the x -slice S i , the c hildr en of eve ry no de u su ch that Lab el T i ( u ) ∈ { dead , b rok en } are sorted as follo ws: 1. If Lab el T i ( u ) = dead , then the set of c hildr en of u with fl ag ⋆ is pu shed aw a y fr om x (line 8). Observe that these children are label hom ogeneous and th eir leaf set are fu lly cont ained in the n eighourho o d of a v ertex y t hat b elongs to a slice S j with i < j . In tuitiv ely , this guaran tees that the v er tices b elonging to mo du les of M x strong not con taining y are k ept close to x . 2. If Lab el T i ( u ) = b rok en , then the set of children of u w ith lab el in { dead , b rok en } is p ushed a w a y from x (line 13). Obser ve th at the complementa ry set precisely conta ins the c hildr en of u with la b el empt y . The leaf sets of these latter c hildren co ntai n v ertices that d o n ot ha v e an y neigh b our i n an y slice S j with i < j . F or a verte x y in S j , t hese v ertices ma y b elong to mo du les of M x strong not con taining y . They hav e to b e k ept close to x . Finally , the ro ot of trees in the sequ ence w ith lab el dead or b rok en are p runed and the resulting subtrees a re sorted acco rd ing to the ordering of their c hildr en (li ne 19). See Figure 11 for an illustration of the result of Algorithm 4 on a graph. Before pro ving the correct n ess of the algo rithm , w e mak e some e lementa ry observ ations of its result. This firs t one is a direct consequence of Obs er v ation 6 (1) and of the fact that Algorithm 4 only nev er sp lits a n o de (only c hildren r eord erings are p erformed). Observ ation 7. L et ~ T m ( x ) b e the se quenc e r eturne d by A lgorithm 4 when ap plie d on the fac- toring x - slic e MD -se que nc e ~ T s ( x ) . If M is a str ong mo dule of G [ S ] for some x -slic e S of ~ T s ( x ) , then M is a factor of ~ T m ( x ) . T o pro v e that the sequence ~ T m ( x ) returned by Algorithm 4 is a factoring x -mo dular MD - sequence, we ha ve to sho w that the mo dules of M x strong are factors of the sequence (see Lemma 18 b elo w). Let u s first examine whic h of the stron g mo dules of an x -slice S ma y o v erlap a m o dule of M x strong . Observ ation 8. L et G = ( V , E ) b e a gr aph and let C b e a c onne cte d c omp onent of G (or of G ). If M is a mo dule of G , then C and M do not overlap. Pr o of. It is a direct consequence of Lemma 1: since a connected comp onen t C is a strong mo dule, it do es not o verlap any other mo dule. Lemma 17. L et S b e an x -slic e of a gr aph G = ( V , E ) and let M b e a mo dule of G in M x strong ( G ) . If S = N ( x ) and C is a c onne cte d c omp onent of G [ S ] , or if S ⊆ N ( x ) and C is a c onne cte d c omp onent of G [ S ] , then C and M do not overlap. Pr o of. Let u s assume that S = N ( x ) (the case S ⊆ N ( x ) is symmetric). F or the sak e of con tradiction, supp ose that M ∈ M x strong ( G ) o v erlaps some connected comp onen t C of G [ S ]. Observe that as C ⊆ N ( x ) and x ∈ M , every v ertex of C \ M is adj acen t to ev ery vertex of C ∩ M : contradicti ng C b eing connected in G [ S ]. 30 Algorithm 4 : Extra ct a nd so rt Input: A vertex x of a connected graph G = ( V , E ) a nd a factoring x -slice MD-sequence ~ T s ( x ) = h MD ( G [ S 1 ]) , { x } , MD ( G [ S 2 ]) , . . . , MD ( G [ S k ]) i . Output: A factoring x -mo dular MD -sequenc e ~ T m ( x ). 1 be g in 2 ~ T m ( x ) ← ~ T s ( x ); 3 foreac h i ∈ [1 , k − 1] do 4 X i ← N ( y ) ∩ S i | y ∈ V , S i ≺ ~ T s ( x ) y ; 5 T i ← Mark Pa rtitive For est ( MD ( G [ S i ]) , X i ) (Algorithm 3); 6 end 7 foreac h i ∈ [1 , k − 1] do 8 foreac h no de u of T i such that Lab el ( u ) = dead do 9 let A be the s et containing every child v of u such that Flag ( v ) = ⋆ ; 10 if i = 1 then o rder the children o f u s o that those in A a ppe a r first; 11 else order the c hildre n of u so that those in A app ear last; 12 end 13 foreac h no de u of T i such that Lab el ( u ) = broken do 14 let A b e the se t c o ntaining every child v of u such that Lab el ( v ) = dead o r Lab el ( v ) = brok en ; 15 if i = 1 then o rder the children o f u s o that those o f A app ear firs t; 16 else order the c hildre n of u so that those of A app ear last; 17 end 18 ~ T i ← h T i i ; 19 while ther e exists T ∈ ~ T i whose r o ot r T satisfies Lab el ( r T ) ∈ { dead , b roken } do 20 let h u 1 , . . . , u ℓ i be the s equence of children of r T in T ; 21 replace T in ~ T i by the sequence h T u 1 , . . . T u ℓ i of subtre es r esp ectively ro oted at u 1 , . . . , u ℓ ; 22 end 23 replace T i by ~ T i in ~ T m ( x ); 24 end 25 return ~ T m ( x ); 26 end Let us n otice that Lemma 17 will b e used in a latter step of our mo d ular decomp osition algorithm in order to c ompu te the mo dules of M x strong . As a consequence of Lemma 17, w e obtain: Corollary 2. L et S b e an x -slic e of a gr aph G and M b e a mo dule of G in M x strong . The uni q ue str ong mo dule of G [ S ] that may overlap M is S . Pr o of. Let us a ssu me that S = N ( x ) (the case S ⊆ N ( x ) is symetric). First observe that if the ro ot of M D ( G [ S ]) is a p rime or a parallel no de, th en G [ S ] is connected. By Lemma 17, S is included in eve ry mo du le of M x strong that in tersects S . If the ro ot of MD ( G [ S ]) is a series no de, then eve ry c hild u of th e r o ot is a prime or a parallel no d e. T hen C = L MD ( G [ S ]) ( u ) is connected in G , implying by Lemm a 17 that C is includ ed in ev ery modu le of M x strong that in tersects C . W e obs erv e th at in the case S o ve rlaps a mo dule of M x strong , then th e ro ot of S is a series 31 no de if S = N ( x ) and a parallel no de if S ⊆ N ( x ). Lemma 18. L et x b e a vertex of a c onne cte d gr aph G = ( V , E ) and ~ T s ( x ) b e a factoring x - slic e MD -se q u enc e of G . Then, Algo rithm 4 , applie d on x , G and ~ T s ( x ) , r eturns a f actoring x -mo dular MD - se que nc e ~ T m ( x ) of G . Pr o of. Supp ose that ~ T s ( x ) = h MD ( G [ S 1 ]) , { x } , MD ( G [ S 2 ]) , . . . , MD ( G [ S k ]) i . First obs erv e that the x -slice S k is a mod ule of M x max ( G ). By Theorem 5, ev ery tree ~ T i in the sequence ~ T m ( x ), distinct fr om MD ( G [ S k ]), r eturned b y Algorithm 4 is a connected c omp onen t of MD ( G [ S i ]) |X i for some x -slices S i , w ith i < k and X i = N ( y ) ∩ S i | y ∈ V , S i ≺ ~ T s ( x ) y . By Lemma 16, M is a mo d ule of M x max ( G ) if and only if M = L ( T ) wh ere ~ T is one of the trees of ~ T m ( x ). Observ e moreo v er, that ~ T corresp ond s to MD ( G [ M ]). So to prov e the state ment, it remains to sho w that e very module of M ∈ M x strong ( G ) is a factor of the returned sequence ~ T m ( x ). W e obs er ve that, b y construction, ~ T m ( x ) is an extension of ~ T s ( x ), meanin g that for a ny t wo v ertices y and z , if y ≺ ~ T s ( x ) z , then y ≺ ~ T m ( x ) z . Moreo ver, b y Lemma 7, ~ T s ( x ) is a factoring x -slice MD -sequence. This implies that M ma y ov erlap S 1 and S i for some i ∈ [2 , k ], and t h at for 2 ≤ j < i , S i ⊆ M and for i < j , M ∩ S j = ∅ . As a consequence of Corollary 2, if this is the case, none of the strong mo dules of G [ S 1 ] (resp. G [ S i ]) corresp ondin g to a c hild of th e r o ot of MD ( G [ S 1 ]) (resp. MD ( G [ S i ])) o v erlaps M . It follo ws that w e only hav e to pro ve that Algorithm 4 correctly sorts these no des. Supp ose that M o v erlaps S 1 and let ~ T 1 b e the s u bsequence of p artitiv e trees in ~ T m ( x ) that w as extract ed from MD ( G [ S 1 ]). By Corol lary 2 , the r o ot no d e r of M D ( G [ S 1 ]) is series. Let ˜ c i and ˜ c j b e tw o c hildren of r su c h that L MD ( G [ S 1 ]) ( c i ) ∩ M = ∅ and L MD ( G [ S 1 ]) ( c j ) ⊂ M . By Observ ation 6, ~ T 1 con tains t w o no de-mates c i and c j of ˜ c i and ˜ c j (as th ey ha v e the same leaf sets, w e will abu siv ely identify the notations c i , c j and ˜ c i , ˜ c j ). W e ha ve tw o cases to consider: 1. Supp ose first that c i and c j are not siblings in ~ T 1 . Let y ∈ N ( x ) b e the first v ertex used b y Algorithm 3 suc h that N ( y ) ∩ S 1 separates c i from c j , t hat is L MD ( G [ S 1 ]) ( c i ) ⊂ N ( y ) and L MD ( G [ S 1 ]) ( c j ) ∩ N ( y ) = ∅ . O bserv e that the father u of c i and c j is lab elled dead and that c i then receiv es the flag ⋆ (but n ot c j ). Th is implies that Algorithm 4 sets c i ≺ ~ T 1 c j . Supp ose that y / ∈ M . Then, as x ∈ N ( y ), w e hav e M ⊆ N ( y ). In tu rns, this implies that L MD ( G [ S 1 ]) ( c i ) ∩ M = ∅ , whic h is safe with c i ≺ ~ T 1 c j . So sup p ose that y ∈ M . Then, as S 1 = N ( x ), we ha ve that S 1 \ M ⊆ N ( y ). In turns , this imp lies th at L MD ( G [ S 1 ]) ( c j ) ⊂ M , whic h is safe w ith c i ≺ ~ T 1 c j . 2. Supp ose no w that c i and c j are siblings in ~ T 1 and let u b e their father. If Lab el ~ T 1 ( u ) = dead , then th e same argumen ts than in the p revious case apply . So sup p ose that Lab el ~ T 1 ( u ) = b rok en . Su pp ose that for every y ∈ N ( x ) \ M , y is u n iv ersal to L MD ( G [ S 1 ]) ( c i ) ∪L MD ( G [ S 1 ]) ( c j ) or isolated to L MD ( G [ S 1 ]) ( c i ) ∪ L MD ( G [ S 1 ]) ( c j ). W e claim that M ′ = ( M \ L MD ( G [ S 1 ]) ( c j )) ∪ L MD ( G [ S 1 ]) ( c i ) is a mo du le. Consider a v ertex z / ∈ M ′ . If z ∈ N ( x ), then M ⊆ N ( y ) and since by assump tion z do es not separate L MD ( G [ S 1 ]) ( c i ) from L MD ( G [ S 1 ]) ( c j ), w e also ha v e L MD ( G [ S 1 ]) ( c i ) ⊆ N ( z ), implyin g that M ′ ⊆ N ( z ). Sup p ose that z ∈ N ( x ), since c i and c j are children of the ro ot no de of MD ( G [ S 1 ]) that is series, M ′ ⊆ N ( z ). The fact that M ′ is a mo dule ov erlapp in g M con tradicts the assum ption that M is strong (since it b elongs to M x strong ). S o there exists a v ertex y ∈ N ( x ) \ M , s u c h that N ( y ) ∩ N ( x ) 32 separates L MD ( G [ S 1 ]) ( c i ) ∪ L MD ( G [ S 1 ]) ( c j ). But, b y assumption Lab el ~ T 1 ( u ) = brok en , this implies that neither c i nor c j obtained the flag ⋆ . In other w ords, y is not un iv er- sal to L MD ( G [ S 1 ]) ( c i ), neither to L MD ( G [ S 1 ]) ( c j ). It follo ws that y is isolated to one of L MD ( G [ S 1 ]) ( c i ) or L MD ( G [ S 1 ]) ( c j ) and separates th e other, s a y L MD ( G [ S 1 ]) ( c i ). Consequently Lab el ~ T 1 ( c i ) ∈ { dead , bro ke n } (and thereby con tains a n eigh b our of y ) and Lab el ~ T 1 ( c l ) = empt y , and thereby Algorithm 4 sets c i ≺ ~ T 1 c j . Since y ∈ N ( x ) \ M and since Lab el ~ T 1 ( c i ) con tains a n eigh b our of y and do es not o v erlap M , we ha v e that L MD ( G [ S 1 ]) ( c i ) ∩ M = ∅ , whic h is safe w ith c i ≺ ~ T 1 c j . Supp ose that M o ve rlaps S i , with i ≥ 2, and let ~ T i b e the subsequence of partitiv e trees in ~ T m ( x ) th at was extracted from MD ( G [ S i ]). The p ro of is similar to the one for t h e case M o v erlaps S 1 . But if a module M ∈ M x strong o v erlaps S i , then the root no de r of MD ( G [ S i ]) is parallel and none of the children of r ov erlaps M . Again th e strategy of Algorithm 4 consisting of o rd ering first the c hild ren of a no de t hat con tains some neig hb our of a v er tex y ∈ S j with i < j i s compatible with ev entuall y obtaining a factoring x -mo du lar MD -sequence of G . The d efinition of x -activ e edges defined in the con text of a slice d ecomp osition n aturally apply to slice sequences. If ~ S ( x ) = h S 0 = { x } , S 1 , S 2 , . . . , S k i is an x -slice s equ ence of the graph G = ( V , E ), w e d enote: A ( ~ S ( x )) = { y z ∈ E | ∃ 0 ≤ i < j ≤ k , y ∈ S i , y ∈ S j } . Lemma 19. L et ~ S ( x ) = h S 1 , { x } , S 2 , . . . , S k i b e a factoring x - slic e se quenc e of the c onne cte d gr aph G = ( V , E ) . Then, A lgorithm 4 with input the factoring x -slic e se q u enc e ~ T s ( x ) = h MD ( G [ S 1 ]) , { x } , MD ( G [ S 2 ]) , . . . , MD ( G [ S k ]) i runs i n O ( |A ( ~ S ( x )) | ) . Pr o of. By Lemma 15, t h e successiv e calls to Alg orithm 3 in the lo op of line 4 has complexit y O P 1 ≤ i r , K i is non-adjacen t to K j } . 8 Observ ation 12 . If ~ K ( x ) = h K 1 , . . . , { x } , . . . , K q i is a factor ing x -m-cluster se quenc e of a non-c onne cte d gr aph G , then Left ( K 1 ) = 1 , Right ( K q ) = q . Pr o of. This is a direct consequence of Obs erv ation 10. Lemma 22. L et x b e a non-isolate d vertex of a gr aph G = ( V , E ) . L et M and M ′ b e two str ong mo dules in M x strong ( G ) and let u M and u M ′ b e the c orr e sp onding no des in MD ( G ) . Supp ose that u M ′ is a child o f u M . Then: 1. u M is a series no de if and only if M \ M ′ ⊆ N ( x ) and M \ M ′ ∈ M x max ( G ) ; 2. u M is a p ar al lel no de if a nd only if M \ M ′ ⊆ N ( x ) and M \ M ′ ∈ M x max ( G ) ; 3. u M is a prime no de if and only i f M \ M ′ c ontains at le ast two mo dules o f M x max ( G ) . Mor e over, in c ases u M is series or p ar al lel, M \ M ′ is an m-cluster. Pr o of. W e first pr ov e the statemen t for the case u M is a s eries n o de. The pro of for p arallel no des is simila r. Observe that, for ev ery vertex y ∈ M \ M ′ , M is the smallest strong mo dule con taining x and y . Since u M is series, xy ∈ E . Moreo v er as u M is a d egenerate no d e, by Theorem 1, the u nion of any (strict) subset of children of M forms a mo du le of G . This imp lies that M \ M ′ is a m o dule of G . By Lemma 2, w e then hav e M \ M ′ ∈ M x max ( G ). F or the con v erse, observ e that, by Th eorem 1, M \ M ′ ∈ M x max ( G ) implies that M is not prime. Since M \ M ′ ⊆ N ( x ), u M is a series no de. 8 The v alues Left ( K i ) and Right ( K i ) plays a role similar to the notion of right and left fracture introduced in [9, 1] to extract the strong mod ules of a graph from a factoring p ermutation. 37 Let us no w prov e that if u M is series or parallel, then M \ M ′ is an m-cluster. Let ~ S ( x ) = h S 1 , { x } , S 2 . . . S k i b e a factoring x -slice sequence of a graph G . As M \ M ′ ∈ M x max ( G ), b y Lemma 6 , M \ M ′ is contai ned in some x -slice S i of ~ S ( x ). An d moreo v er, by Th eorem 1, M \ M ′ is the disjoin t union of strong mo dules of G not con taining x (p ossib ly M \ M ′ is itself a strong mo dule of G not conta ining x ). Notice that, by construction of MD ( G [ S i ]), eac h of th ese strong mo dules is a c hild of the ro ot of MD ( G [ S i ]). It follo ws by Defin ition 14 that M \ M ′ forms an m-cluster. Supp ose that now th at u M is a prime n o de. Then observe that M \ M ′ in tersects b oth N ( x ) and N ( x ), implyin g that M \ M ′ con tains at least t w o mo dules of M x max ( G ). Supp ose that M \ M ′ con tains tw o mo dules M 1 and M 2 of M x max ( G ). As b y defin ition of M x max ( G ), M 1 ∪ M 2 is not a mo dule of G , b y Theorem 1, u M has to b e a p rime no de. Lemma 23. L et x b e a no n-i solate d vertex of a gr aph G = ( V , E ) . L et us c onsider a factoring x -m-cluster se quenc e ~ K ( x ) = h K 1 , . . . , { x } , . . . , K q i that i s an extension of a factoring x - slic e se quenc e ~ S ( x ) . L et K ℓ and K r b e two m- clusters such that K ℓ ~ K ( x ) { x } ~ K ( x ) K r . Then M ℓ,r = { x } ∪ S ℓ ≤ i ≤ r K i ∈ M x strong ( G ) if and only if for e v ery ℓ ≤ i ≤ r , ℓ ≤ Left ( K i ) and Right ( K i ) ≤ r . Pr o of. Supp ose that M ℓ,r ∈ M x strong (G). Consider an m-cluster K j of ~ K ( x ). Observe that, if j < ℓ , then K j ⊂ N ( x ), and if r < j , then K j ⊂ N ( x ). Since x ∈ M ℓ,r , this implies that for ev ery i suc h that ℓ ≤ i ≤ r , if j < ℓ then K j is adjacen t to K i and, if r < j , then K j is non-adjacen t to K i . It follo ws that for ev ery ℓ ≤ i ≤ r , ℓ ≤ Left ( K i ) and R ight ( K i ) ≤ r . Supp ose that for every ℓ ≤ i ≤ r , ℓ ≤ Left ( K i ) and Right ( K i ) ≤ r . Sup p ose moreo ver that for every ℓ ′ and r ′ with [ ℓ ′ , r ′ ] ⊂ [ ℓ, r ] that satisfies the condition, M ℓ ′ ,r ′ = { x } ∪ S ℓ ′ ≤ i ≤ r ′ K i b elongs to M x strong ( G ). Let M ′ = M ℓ ′ ,r ′ b e the largest s uc h mo dule. Observe first that, for ev ery j ∈ [1 , q ] such th at j / ∈ [ ℓ, r ] and for every y ∈ K j , M ℓ,r is N ( y )-un iform. More pr ecisely , b y definition of Left ( · ) and R ight ( · ), if j < ℓ then K j is adjacent to M ℓ,r and if r < j , then K j is non-adjacen t to M ℓ,r . This implies that M ℓ,r is a mo dule. F or the sake of con tradiction, assu m e that M ℓ,r is not strong. Let M b e the smallest modu le of M x strong ( G ) cont aining K ℓ and K r . Observe that M ′ ⊂ M ℓ,r ⊂ M . As ~ K ( x ) is f actoring, by Lemma 20, the fir st inclus ion implies that K ℓ ∩ M ′ = ∅ or K r ∩ M ′ = ∅ , while the second inclusion implies that either K ℓ − 1 ⊂ M or K r +1 ⊂ M . So at least t wo among th e m -clusters K ℓ − 1 , K ℓ , K r , K r +1 are conta ined in M \ M ′ . Th is implies that M \ M ′ con tains at least t wo mo dules of M x max ( G ). By Lemm a 22, this implies th at M is a prime mo du le. But th en, b y Theorem 1, this con tradicts th e fact that M ℓ,r is a mo dule of G whic h is the un ion of at least tw o c hildr en of M . It is clear that Lemma 23 yields a p olynomial time algorithm (see Algorithm 5) that allo ws to compu te, fr om a f actoring x -m-cluster sequence, the modu les of M x strong ( G ). Moreo v er the nested p rop erty of the mo dules of M x strong ( G ) allo ws to derive the p ath fr om x to the ro ot of MD ( G ). Finally , ob s erv e that Lemma 22 yields a simple criteria to lab el the no des of that path with their t yp e ( series , parallel and p rime ). Lemma 24. A lgorithm 5 r eturns a neste d set M x of intervals such that M ℓ,r = S ℓ ≤ j ≤ r K j ∈ M x strong ( G ) if and only if [ ℓ, r ] ∈ M x . Pr o of. As the int erv al [ p, p ] corresp onds to the set { x } , it has to b elong to M x . Let us assu me that for ℓ ≤ p , r ≥ p , M ℓ,r ∈ M x strong ( G ) and that Algorithm 5 has iden tified every in terv al 38 Algorithm 5 : Pa rse Input: A graph G = ( V , E ) with a non-is o lated vertex x and a facto ring x -m-cluster seq ue nc e ~ K ( x ) = h K 1 , . . . , K p = { x } , . . . , K q i extending a factoring x -slice sequence ~ S ( x ). Output: A nested set M x of interv als such that M ℓ,r = S ℓ ≤ j ≤ r K j ∈ M x strong ( G ) if a nd o nly if [ ℓ, r ] ∈ M x . 1 be g in 2 ℓ ← p , r ← p and M x ← { [ p, p ] } ; 3 while ℓ 6 = 1 or r 6 = q do 4 if l = 1 or r = q then ℓ ′ ← 1 , r ′ ← q a nd I ← ∅ ; 5 else 6 if K ℓ − 1 and K r +1 ar e not adjac ent then ℓ ′ ← ℓ − 1, r ′ ← r and I ← { ℓ ′ } ; 7 else ℓ ′ ← ℓ , r ′ ← r + 1 and I ← { r ′ } ; 8 end 9 while I 6 = ∅ do 10 Pick i ∈ I a nd set I ← I \ { i } ; 11 if Left ( K i ) < ℓ ′ then I ← I ∪ [ Left ( K i ) , ℓ ′ [ and ℓ ′ ← Left ( K i ) ; 12 if Right ( K i ) > r ′ then I ← I ∪ ] r ′ , R ight ( K i )] and r ′ ← R ight ( K i ) ; 13 end 14 ℓ ← ℓ ′ , r ← r ′ and M x ← M x ∪ { [ ℓ, r ] } ; 15 end 16 return M x ; 17 end [ ℓ ′ , r ′ ] ⊆ [ ℓ, r ] corresp ond in g to a mo dule of M x strong ( G ). L et M b e the inclusion minimal mo d ule of M x strong ( G ) c ontai nin g M ℓ,r . Sup p ose that when ente rin g the while loop at lin e 2, w e ha v e ℓ = 1 (the case r = q is symmetric). Then observe that ∪ r
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment