Latent Filling: Latent Space Data Augmentation for Zero-shot Speech Synthesis
Previous works in zero-shot text-to-speech (ZS-TTS) have attempted to enhance its systems by enlarging the training data through crowd-sourcing or augmenting existing speech data. However, the use of low-quality data has led to a decline in the overa…
Authors: Jae-Sung Bae, Joun Yeop Lee, Ji-Hyun Lee
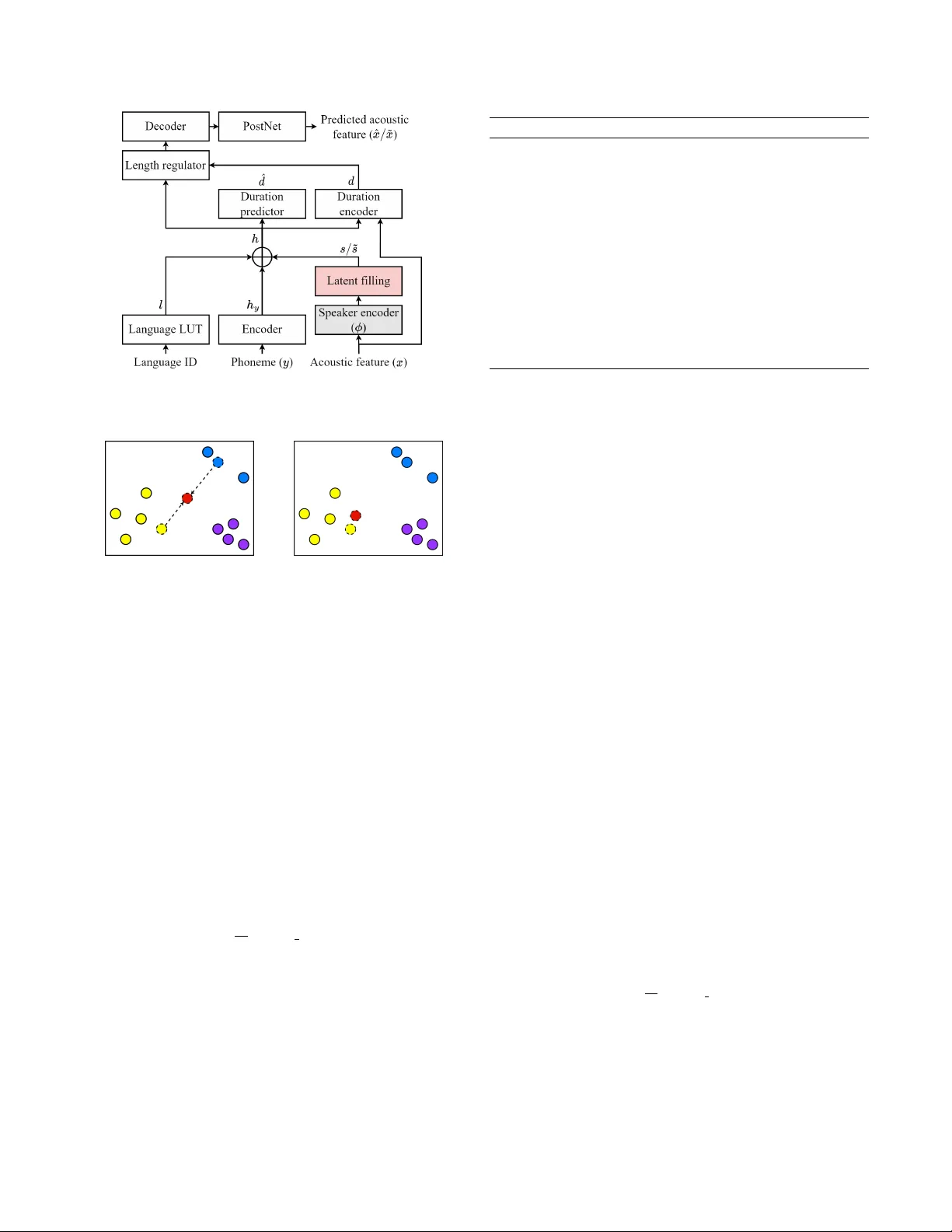
LA TENT FILLING: LA TENT SP A CE DA T A A UGMENT A TION FOR ZER O-SHO T SPEECH SYNTHESIS J ae-Sung Bae † , J oun Y eop Lee † , Ji-Hyun Lee † , Seongkyu Mun † , T aehwa Kang † , Hoon-Y oung Cho † , Chanwoo Kim ‡ ∗ † Samsung Research, Seoul, Republic of K orea ‡ K orea Uni versity , Seoul, Republic of Korea ABSTRA CT Previous works in zero-shot text-to-speech (ZS-TTS) have attempted to enhance its systems by enlarging the training data through crowd- sourcing or augmenting existing speech data. Howe ver , the use of low-quality data has led to a decline in the overall system perfor- mance. T o avoid such degradation, instead of directly augmenting the input data, we propose a latent filling (LF) method that adopts simple but effecti ve latent space data augmentation in the speaker embedding space of the ZS-TTS system. By incorporating a con- sistency loss, LF can be seamlessly integrated into e xisting ZS-TTS systems without the need for additional training stages. Experimen- tal results show that LF significantly improves speaker similarity while preserving speech quality . Index T erms — Speech synthesis, zero-shot, latent space, data augmentation, cross-lingual 1. INTR ODUCTION W ith the advancements in neural text-to-speech (TTS) systems [1– 3], there has been a remarkable improvement in the naturalness of synthesized speech. There is also a growing demand for person- alized TTS systems. Building such systems traditionally inv olves adapting pre-trained TTS systems using a limited number of utter- ances from the target v oice [4, 5]. Howe ver , the process of collect- ing and fine-tuning with personal data remains problematic due to priv acy concerns and the challenges associated with gathering high- quality data. T o address this challenge, zero-shot TTS (ZS-TTS) systems hav e gained significant attention [6–12] as they aim to replicate a target speak er’ s v oice using just a single reference utterance without the need for additional fine-tuning. A common architecture em- ployed in ZS-TTS systems incorporates an external speaker encoder [6, 8], which is pre-trained on a speaker verification task to extract speaker embeddings from reference speeches. T o effectiv ely inter- pret the latent space of speaker embeddings and generate speech from an unseen speaker embedding during inference, ZS-TTS sys- tems require substantial training data encompassing a di verse set of speakers. Howe ver , acquiring high-quality speech-text paired data for training is a costly and time-consuming endeav or . T o ov ercome the data scarcity challenge, recent TTS systems hav e utilized cro wd-sourced speech data [13, 14] or employed data augmentation techniques such as pitch shifting [15] and synthesizing new speech using voice con version or TTS systems [15–17]. Ne ver - theless, these data sources often contain speech with ambiguous pro- nunciation, background noise, channel artifacts, and artificial distor- ∗ W ork performed while at Samsung Research. tions, which result in degradation of the o verall performance of the TTS systems. In this paper , we propose a novel approach called latent filling (LF) to address these challenges. LF aims to fill the une xplored re- gions of the latent space of speaker embeddings through latent space data augmentation [18–21]. Unlike data augmentation techniques applied directly to input data, latent space data augmentation is a straightforward yet ef fectiv e method that augments the latent vectors of neural network systems, enhancing their robustness and general- ization. Although widely used in classification tasks [19–21], latent space data augmentation has not been e xtensiv ely e xplored in gener- ation tasks due to the inherent difficulty of obtaining corresponding target data for augmented latent v ectors. T o tackle this challenge, we introduce a latent filling consistenc y loss (LFCL). LFCL enforces the generated acoustic features deriv ed from augmented speaker embeddings to retain the same speaker em- bedding representation. This allows us to train the entire TTS sys- tem without requiring the corresponding target speech sample for the augmented speak er embedding. Our approach in volves training the ZS-TTS system in two modes. First, when LF is adopted, the entire network is exclusiv ely trained with LFCL. Con v ersely , when LF is not applied, we employ a reconstruction loss and speak er con- sistency loss [6]. By randomly selecting these modes during training iterations, we successfully integrate LF into the training of the ZS- TTS system without the need for additional training stages. W ith minimal modifications to the e xisting code, LF can be eas- ily applied to existing ZS-TTS systems. Furthermore, our experi- ments demonstrate that the incorporation of LF improves the speak er similarity performance of the ZS-TTS system without an y de grada- tion in intelligibility and naturalness. 2. PROPOSED METHOD 2.1. Baseline ZS-TTS system Our baseline ZS-TTS system shares a similar architecture with [12]. It is designed for low-resource and cross-lingual speech generation. The overall architecture is illustrated in Fig. 1. The input phoneme y is encoded into h y by an encoder . Language information is trans- formed into a language embedding l via a look-up table (LUT). A pre-trained speaker encoder ϕ extracts the speaker embedding s from the input acoustic feature x . Notably , the speaker encoder remains frozen during the training phase. Subsequently , h y , l , and s are con- catenated to form the final hidden representation h . T o extract the corresponding duration d from x and h , the duration encoder and alignment method from [22] are employed. The duration predictor predicts ˆ d , which is utilized as duration information during infer- Fig. 1 . Architecture of the baseline ZS-TTS system with our pro- posed latent filling method. (a) (b) Fig. 2 . Illustration of LF of (a) interpolation and (b) noise adding. The red circle indicates an augmented speaker embedding, while the circles in various colors represent speaker embeddings of different speakers. ence. Finally , h is upsampled using the duration information and passed through the decoder and PostNet to generate the final acous- tic feature ˆ x . During the training phase, the system is trained with reconstruc- tion loss, denoted as L Rec , for the duration and acoustic features. L1 and L2 losses are used for the duration and acoustic feature re- construction loss, respectiv ely . Additionally , as in [23] and [6], we employ the speaker consistency loss (SCL) to enhance the speaker similarity of the ZS-TTS system. It encourages the speaker embed- ding of the generated acoustic feature to be close to the input speaker embedding. W e calculate the cosine similarity to measure the simi- larity between two speaker embeddings. With batch size N , the SCL is computed as follows: L S CL = − 1 N N X i cos sim ( s i , ϕ ( ˆ x i )) (1) 2.2. Latent Filling Through the latent filling (LF) method, our aim is to fill the latent space of the speaker embeddings that the training dataset cannot ad- equately express. W e employ two intuitiv e latent space augmenta- tion techniques for the LF: interpolation [18, 19] and noise addition [18]. Illustrations of these methods are provided in Fig. 2. The interpolation method creates a completely ne w speaker embedding Algorithm 1 Latent filling algorithm Require: Speaker embedding s i and s j . Require: Noise adding probability ϵ ∈ [0 , 1] . Require: Beta distribution shape parameter β ∈ (0 , ∞ ) . Require: Standarad deviation of Gaussian noise σ ∈ (0 , ∞ ) . 1: u 1 , u 2 ∼ U (0 , 1) , λ ∼ Beta ( β , β ) , G ∼ N (0 , σ 2 ) 2: if u 1 > ϵ then 3: ˜ s i ← λs i + (1 − λ ) s j ▷ Perform interpolation 4: if u 2 < ϵ then 5: ˜ s i ← ˜ s i + G ▷ Add Gaussian noise 6: end if 7: else 8: ˜ s i ← s i + G ▷ Add Gaussian noise 9: end if 10: retur n ˜ s i in the speaker embedding space by using two different speaker em- beddings, while the adding noise method generates a new speaker embedding that is relativ ely close to the existing one. In the previ- ous work [18], the authors also adopted the extrapolation for latent space data augmentation. Howev er , in our preliminary experiments, we observed that extrapolation is not particularly meaningful in our case. The complete LF process is detailed in Algorithm 1. First, for the speaker embedding s i , we randomly select another speaker em- bedding s j from the training dataset for the interpolation. Our pre- liminary study indicates that ensuring s j has the same language in- formation as s i is crucial for achieving stable performance. W e per- form interpolation between s i and s j with a probability of 1 − ϵ , using the formula λs i + (1 − λ ) s j . Here, ϵ represents the probabil- ity of adding noise, while λ denotes the interpolation rate. Similar to [19], we sample λ from the beta distribution Beta ( β , β ) , where β is the beta distribution shape parameter . When interpolation is con- ducted, Gaussian noise G ∼ N (0 , σ 2 ) with a standard deviation σ is added with a probability of ϵ . Con versely , when the interpolation is not performed, the Gaussian noise is always added. 2.2.1. Latent filling consistency loss Adopting latent space data augmentation for generation tasks has been challenging due to the inherent difficulty of obtaining tar get data corresponding to augmented latent vectors. Similarly , when the LF method is adopted for the speaker embedding, it is impossible to calculate the L Rec because there is no corresponding ground- truth speech containing the speaker information for the augmented speaker embedding ˜ s . T o address this challenge, we propose a latent filling consis- tency loss (LFCL), a modified version of SCL tailored for augmented speaker embeddings. The LFCL can be computed as follows: L LF CL = − 1 N N X i cos sim ( ˜ s i , ϕ ( ˜ x i )) (2) where ˜ x is a generated acoustic feature corresponding to ˜ s . LFCL measures the closeness between the speaker embedding of ˜ x and ˜ s , and encourages ˜ x to have the same speaker characteristics as the input augmented speaker embedding ˜ s . By using the LFCL, we can successfully update the ZS-TTS system with the augmented speaker embedding without the need for L RE C . This allows the ZS-TTS system to be trained with speaker embeddings not contained in the training dataset. The training process incorporating LFCL is detailed in the following section. 2.2.2. T raining pr ocedur e The training procedure for the TTS system using the LF and LFCL is as follows: First, for each training iteration, we make a random decision on whether to perform the LF , with a probability param- eter τ ranging from 0 to 1. When the LF is performed, the entire TTS system is only updated with L LF CL . Con versely , when LF is not applied, the TTS system is updated using L Rec and L S CL . By randomly incorporating LF during training, we seamlessly integrate it into existing TTS systems without requiring additional training stages or degrading performance. According to our preliminary experiments, the parameter τ should be set carefully . When τ was set too high, the TTS system generated speech that lacked coherence with the input text. This occurred because L Rec is not utilized when LF is active, leading the system to prioritize e xpressing speaker characteristics of the input speaker embedding while disregarding content information. Con versely , when τ was set too lo w , the benefits of LF were not effecti vely realized. Based on heuristic analysis, we set τ to a value of 0.25. 3. EXPERIMENTS 3.1. Dataset In our experiments, we utilized a div erse set of datasets for both English and Korean languages. For English, we used VCTK [24], LibriTTS [25] (train-clean-100 and 360 subsets), and LJSpeech [26] dataset, totaling approximately 259 hours of speech data and in- volving 1,245 distinct speakers. W e excluded 11 speakers from the VCTK dataset and used them as English test speakers. For Korean language, we le veraged the multi-speaker 1 and emotion 2 datasets from the AIHub. They were recorded by 3,086 non-professional speakers and 44 professional voice actors, and the lengths of each dataset were approximately 7,414 hours and 264 hours, respectiv ely . W e randomly selected 29 speakers from the AIHub multi-speaker dataset for use as Korean test speakers. W e resampled all utterances to a 24KHz sampling rate. Our test scripts were deriv ed from the utterances of English test speakers, with a focus on those between 4 and 10 seconds in duration. W e used 22-dimensional acoustic features consisting of 20 Bark cepstral coefficients, pitch period, and pitch correlation which were the same as in [12]. T o con vert the acoustic feature to a waveform, Bunched LPCNet2 [27] was used. 3.2. Experimental setup The baseline ZS-TTS system had the same architecture as our pre vi- ous work [12], except for the language LUT and the decoder archi- tecture. The dimension of l was 4 and the Uni-LSTM was used for the decoder instead of the Bi-LSTM to enable streaming. For the LF , we set ϵ to 0.5, β to 0.5, and σ to 0.0001. For the speaker encoder, ECAP A-TDNN [28], the state-of-the-art (SOT A) speaker verifica- tion model, was used. T o compute the SCL and LFCL, we modified the input acoustic feature of the ECAP A-TDNN to ours. It was pre- trained with the same training dataset. Our system was trained with 1 https://aihub .or .kr/aihubdata/data/view .do?dataSetSn=542 2 https://aihub .or .kr/aihubdata/data/view .do?dataSetSn=466 a batch size N of 64. W e adopt the language-balanced sampling fol- lowing [29] and [30] with the upsampling factor of 0.25 to ensure a language-balanced batch. W e used the Adam [31] optimizer with betas 0.9 and 0.999, weight decay of 10 − 6 , and an initial learning rate of 0.0006 with a half-learning rate schedule for e very 100K iter- ations. The system was trained for 1 million iterations. T o generate speech in a zero-shot scenario, we randomly selected one utterance with a duration longer than 4 seconds from each test speaker as a reference speech. 3.3. Comparison Systems For the comparison, we used the following systems. GT and GT - re were the ground-truth speech samples and re-synthesized version of GT through the vocoder , respectiv ely . SC-Glow TTS [8] and Y ourTTS [6] were the open-sourced ZS-TTS systems. Furthermore, we compared the proposed LF method ( Baseline+LF ) with data aug- mentation methods. The Baseline+CS system utilized LibriLight [32] dataset, which is a large amount of crowd-sourced data that consists of a total of 60K hours of unlabelled speech with approx- imately 7,000 speakers. T o generate transcripts, we used a wav2vec [29]-based phoneme recognition model. W e also built Baseline+PS system which utilized pitch shifts to increase the amount and div er- sity of the training data. W e applied pitch shifts to each speech in the training dataset and doubled the amount of training data. PRAA T toolkit [33] within the semitone shift range [-4, 4] w as used for pitch shift. 3.4. Evaluation metrics For the objectiv e test, we ev aluate the speaker similarity and the in- telligibility of each system with averaged speaker embedding co- sine similarity (SECS) and word error rate (WER), respecti vely . The speaker encoder of the Resemblyzer 3 package was used to measure the SECS. The SECS ranges from -1 to 1, and a higher score implies better speaker similarity . T o compute the WER, Whisper [34], an open-source automatic speech recognition (ASR) model, was used. For the subjective ev aluation, we conducted two mean opinion score (MOS) tests; a MOS test on ov erall naturalness of speech, and a speaker similarity MOS (SMOS) test that focused on ev aluating the speaker similarity between generated speech and reference speech. T esters of both tests were requested to ev aluate speech in the range from 1 to 5 with an interval of 0.5, where 5 is the best. For the subjectiv e tests, 90 testers participated via Amazon MT urk. 3.5. Results The objecti ve and subjecti ve results 4 are summarized in T able 1. The proposed Baseline+LF system exhibited outstanding performance in terms of SECS and SMOS metrics for both intra-lingual (En → En) and cross-lingual (K o → En) tests. Specifically , it achie ved the high- est SMOS and SECS scores in the intra-lingual test, and the best SMOS score along with the second-best SECS score in the cross- lingual test. Compared to the Y ourTTS system, it achieved 0.55 and 0.46 higher SMOS scores in the intra- and cross-lingual tests, re- spectiv ely , while employing approximately 60% fe wer parameters. When compared to the baseline system, our proposed sys- tem demonstrated SMOS impro vements of 0.14 and 0.12 in the intra-lingual and cross-lingual tests, respectively , as well as SECS 3 https://github .com/resemble-ai/Resemblyzer 4 Audio samples can be found online: https://srtts.github.io/latent- filling System NP Intra-lingual (En → En) Cross-lingual (Ko → En) SECS WER ( % ) MOS SMOS SECS WER ( % ) MOS SMOS GT - 0.882 1.95 4.12 ± 0.09 3.89 ± 0.11 (0.869) - - (3.66 ± 0.10) GT -re - 0.855 3.32 3.77 ± 0.14 3.37 ± 0.15 (0.836) - - (3.29 ± 0.14) SC-Glow TTS 30.1M 0.599 28.56 2.02 ± 0.14 2.08 ± 0.17 0.667 29.00 2.06 ± 0.14 2.12 ± 0.14 Y ourTTS 40.1M 0.810 4.78 3.16 ± 0.16 2.79 ± 0.16 0.742 7.52 3.39 ± 0.11 2.43 ± 0.14 Baseline 16.2M 0.827 1.02 3.82 ± 0.12 3.20 ± 0.14 0.720 2.16 3.88 ± 0.10 2.77 ± 0.14 Baseline + CS 0.825 1.29 3.81 ± 0.12 3.27 ± 0.15 0.682 2.75 3.55 ± 0.12 2.72 ± 0.14 Baseline + PS 0.814 1.10 3.72 ± 0.14 3.30 ± 0.15 0.722 2.15 3.80 ± 0.10 2.72 ± 0.14 Baseline + LF 0.836 1.10 3.82 ± 0.12 3.34 ± 0.15 0.729 2.14 3.85 ± 0.12 2.89 ± 0.14 T able 1 . Objective and subjectiv e zero-shot experiment results of the intra-lingual test that generated English speech samples from English reference speech (En → En), and the cross-lingual test that generated English speech samples from K orean reference speech (Ko → En). NP indicates a number of parameters. The MOS and SMOS are reported with 95% CIs. Note that the speech samples of GT and GT -re systems of the cross-lingual test were in K orean. System SECS WER ( % ) CSMOS Baseline + LF 0.836 1.10 N/A w/o noise adding 0.838 1.13 -0.031 w/o interpolation 0.837 1.35 -0.115 T able 2 . Objectiv e and CSMOS test results of ablation study on the intra-lingual (En → En) test. improv ements of 0.009 for both tests 5 . These results indicate that by le veraging the LF method to fill the unexplored latent space of the speaker embeddings, the speaker similarity of the ZS-TTS system significantly improv ed. The WER and MOS scores for the intra-lingual and cross-lingual tests were slightly deteriorated, respectiv ely . W e suppose that this was because the LF method gen- erated a new speaker embedding, but without the accompanying content information. Howe ver , the increase in the WER score for the intra-lingual test was marginally small, and the WER score of the Baseline+LF system remained much lower than that of the GT . In contrast, the data augmentation approaches (Baseline+CS and Baseline+PS systems) demonstrated mixed results. While the SMOS score improved in the intra-lingual test, all other ev aluation metrics deteriorated or slightly improv ed when compared to the baseline sys- tem. This decline was attributed to the lo w quality of the augmented speech. Con versely , by performing augmentation in the latent space using the LF method, our proposed approach successfully improved speaker similarity without degrading speech quality , in contrast to input-lev el data augmentation approaches. 3.6. Ablation study T o in vestigate the impact of interpolation and noise addition in the LF method, we constructed separate ZS-TTS systems that utilized LF without noise addition and interpolation. In addition to objecti ve ev aluation, we conducted a comparativ e similarity MOS (CSMOS) test to assess speaker similarity in comparison to the Baseline+LF system. T esters were asked to ev aluate the compared systems on a scale ranging from -3 to 3, with an interval of 0.5. The results are presented in T able 2. When each method was omitted, we observed a degradation in both CSMOS and WER scores compared to when both methods 5 The confidence intervals (CIs) for SECS in both the Baseline and Base- line+LF systems were 0.005 and 0.003 for the intra-lingual and cross-lingual tests, respectiv ely . were employed. Meanwhile, interpolation proved to be more cru- cial for performance improvement compared to noise addition. This observation can be attributed to the fact that noise addition, as illus- trated in Figure 2, typically generates new speaker embeddings that closely resemble existing speaker embeddings. In contrast, interpo- lation generates ne w speak er embeddings in lar ger re gions and plays a more vital role in enhancing the system’ s performance. 4. CONCLUSION In this paper , we proposed a latent filling (LF) method, which lever - ages latent space data augmentation to the speaker embedding space of the ZS-TTS system. By introducing the latent filling consistency loss, we successfully integrated LF into the existing ZS-TTS frame- work seamlessly . Unlike previous data augmentation methods ap- plied to input speech, our LF method improves speaker similarity without compromising the naturalness and intelligibility of the gen- erated speech. 5. REFERENCES [1] J. Shen, R. Pang, R. W eiss, M. Schuster , N. Jaitly , Z. Y ang, et al., “Natural TTS synthesis by conditioning W av eNet on mel spectrogram predictions, ” in Proc. ICASSP , 2018. [2] Y . Ren, C. Hu, X. T an, T . Qin, S. Zhao, Z. Zhao, et al., “Fast- Speech 2: Fast and high-quality end-to-end text to speech, ” in Pr oc. Int. Conf. on Learning Repr esentations (ICLR) , 2021. [3] N. Ellinas, G. V amvoukakis, K. Markopoulos, A. Chalaman- daris, G. Maniati, P . Kakoulidis, et al., “High quality stream- ing speech synthesis with low , sentence-length-independent la- tency , ” in Pr oc. Interspeech , 2020. [4] Y . Chen, Y . M. Assael, B. Shillingford, D. Budden, S. E. Reed, H. Zen, et al., “Sample efficient adaptive text-to-speech, ” in Pr oc. Int. Conf. on Learning Repr esentations (ICLR) , 2019. [5] M. Chen, X. T an, B. Li, Y . Liu, T . Qin, s. zhao, et al., “AdaSpeech: Adapti ve text to speech for custom voice, ” in Pr oc. Int. Conf. on Learning Repr esentations (ICLR) , 2021. [6] E. Casanova, J. W eber, C. D Shulby , A. C. Junior, E. G ¨ olge, and M. A Ponti, “YourTTS: T owards zero-shot multi-speaker TTS and zero-shot voice con version for everyone, ” in Proc. Int. Conf. on Mac hine Learning (ICML) , 2022. [7] M. Kim, M. Jeong, B. Jin C., S. Ahn, J. Y . Lee, and N. S. Kim, “T ransfer learning framework for low-resource text-to- speech using a large-scale unlabeled speech corpus, ” in Pr oc. Interspeech , 2022. [8] E. Casanova, C. D. Shulby , E. G ¨ olge, N. Michael M ¨ uller , F . S. de Oliveira, A. C. J ´ unior , et al., “SC-GlowTTS: An efficient zero-shot multi-speaker text-to-speech model, ” in Pr oc. Inter- speech , 2021. [9] Y . W u, X. T an, B. Li, L. He, S. Zhao, R. Song, T . Qin, and T .-Y . Liu, “AdaSpeech 4: Adaptive te xt to speech in zero-shot scenarios, ” in Proc. Inter speech , 2022. [10] J.-H. Lee, S.-H. Lee, J.-H. Kim, and S.-W . Lee, “PV AE-TTS: Adaptiv e text-to-speech via progressi ve style adaptation, ” in Pr oc. ICASSP , 2022. [11] B. J. Choi, M. Jeong, J. Y . Lee, and N. S. Kim, “SN A C: Speaker -normalized affine coupling layer in flow-based archi- tecture for zero-shot multi-speaker text-to-speech, ” IEEE Sig- nal Pr ocessing Letters , vol. 29, pp. 2502–2506, 2022. [12] J. Y . Lee, J.-S. Bae, S. Mun, J. Lee, J.-H. Lee, H.-Y . Cho, et al., “Hierarchical timbre-cadence speaker encoder for zero- shot speech synthesis, ” in Proc. Inter speech , 2023. [13] C. W ang, S. Chen, Y . W u, Z. Zhang, L. Zhou, S. Liu, et al., “Neural codec language models are zero-shot text to speech synthesizers, ” CoRR , vol. abs/2301.02111, 2023. [14] E. Kharitono v , D. V incent, Z. Borsos, R. Marinier, S. Gir- gin, O. Pietquin, et al., “Speak, read and prompt: High- fidelity text-to-speech with minimal supervision, ” CoRR , vol. abs/2302.03540, 2023. [15] R. T erashima, R. Y amamoto, E. Song, Y . Shirahata, H.-W . Y oon, J.-M. Kim, and K. T achibana, “Cross-speaker emo- tion transfer for low-resource text-to-speech using non-parallel voice con version with pitch-shift data augmentation, ” in Pr oc. Interspeech , 2022. [16] G. Huybrechts, T . Merritt, G. Comini, B. Perz, R. Shah, and J. Lorenzo-Trueba, “Low-resource expressiv e text-to-speech using data augmentation, ” in Proc. ICASSP , 2021. [17] E. Song, R. Y amamoto, O. Kwon, C.-H. Song, M.-J. Hwang, S. Oh, et al., “TTS-by-TTS 2: Data-selectiv e augmentation for neural speech synthesis using ranking support vector machine with variational autoencoder , ” in Pr oc. Interspeech , 2022. [18] T . DeVries and G. W . T aylor , “Dataset augmentation in fea- ture space, ” in Pr oc. Int. Conf. on Learning Representations (ICLR) , 2017. [19] H. Zhang, M. Ciss ´ e, Y . N. Dauphin, and D. Lopez-Paz, “mixup: Be yond empirical risk minimization, ” in Pr oc. Int. Conf. on Learning Repr esentations (ICLR) , 2018. [20] T .-H. Cheung and D.-Y . Y eung, “MOD ALS: Modality- agnostic automated data augmentation in the latent space, ” in Pr oc. Int. Conf. on Learning Repr esentations (ICLR) , 2021. [21] A. F alcon, G. Serra, and O. Lanz, “ A feature-space multimodal data augmentation technique for text-video retriev al, ” in Pr oc. A CM Int. Conf. on Multimedia , 2022. [22] R. Badlani, A. La ´ ncucki, K. J. Shih, R. V alle, W . Ping, and B. Catanzaro, “One TTS alignment to rule them all, ” in Pr oc. ICASSP , 2022. [23] D. Xin, Y . Saito, S. T akamichi, T . K oriyama, and H. Saruwatari, “Cross-lingual speaker adaptation using domain adaptation and speaker consistency loss for te xt-to-speech syn- thesis, ” in Proc. Inter speech , 2021. [24] J. Y amagishi, C. V eaux, and K. MacDonald, “CSTR VCTK Corpus: English multi-speaker corpus for CSTR voice cloning toolkit (version 0.92), ” University of Edinburgh. The Centre for Speech T echnology Research (CSTR), 2019. [25] H. Zen, V . Dang, R. Clark, Y . Zhang, R. J. W eiss, Y . Jia, et al., “LibriTTS: A corpus derived from librispeech for text- to-speech, ” in Proc. Inter speech , 2019. [26] K. Ito and L. Johnson, “The LJ Speech dataset, ” https:// keithito.com/LJ- Speech- Dataset/ , 2017. [27] S. Park, K. Choo, J. Lee, A.V . Porov , K. Osipo v , and J. S. Sung, “Bunched LPCNet2: Efficient neural vocoders cov er- ing devices from cloud to edge, ” in Pr oc. Interspeech , 2022. [28] B. Desplanques, J. Thienpondt, and K. Demuynck, “ECAP A- TDNN: Emphasized channel attention, propagation and aggre- gation in TDNN based speaker verification, ” in Pr oc. Inter- speech , 2020. [29] A. Babu, C. W ang, A. Tjandra, K. Lakhotia, Q. Xu, N. Goyal, et al., “XLS-R: Self-supervised cross-lingual speech represen- tation learning at scale, ” in Proc. Inter speech , 2022. [30] M. Le, A. Vyas, B. Shi, B. Karrer , L. Sari, R. Moritz, et al., “V oicebox: T ext-guided multilingual univ ersal speech genera- tion at scale, ” in Pr oc. Advances in Neural Information Pro- cessing Systems , 2023. [31] D. P . Kingma and J. Ba, “ Adam: A method for stochastic op- timization, ” in Pr oc. Int. Conf. on Learning Repr esentations (ICLR) , 2015. [32] J. Kahn, M. Rivi ` ere, W . Zheng, E. Kharitonov , Q. Xu, P .-E. Mazar ´ e, et al., “Libri-light: A benchmark for ASR with limited or no supervision, ” in Proc. ICASSP , 2020. [33] P . Boersma, “ Accurate short-term analysis of the fundamen- tal frequency and the harmonics-to-noise ratio of a sampled sound, ” in Pr oc. institute of phonetic sciences , 1993, pp. 97– 110. [34] A. Radford, J. W . Kim, T . Xu, G. Brockman, C. McLea ve y , and I. Sutskever , “Rob ust speech recognition via large-scale weak supervision, ” in Pr oc. Int. Conf. on Mac hine Learning (ICML) , 2023.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment