New probabilistic interest measures for association rules
Mining association rules is an important technique for discovering meaningful patterns in transaction databases. Many different measures of interestingness have been proposed for association rules. However, these measures fail to take the probabilist…
Authors: Michael Hahsler, Kurt Hornik
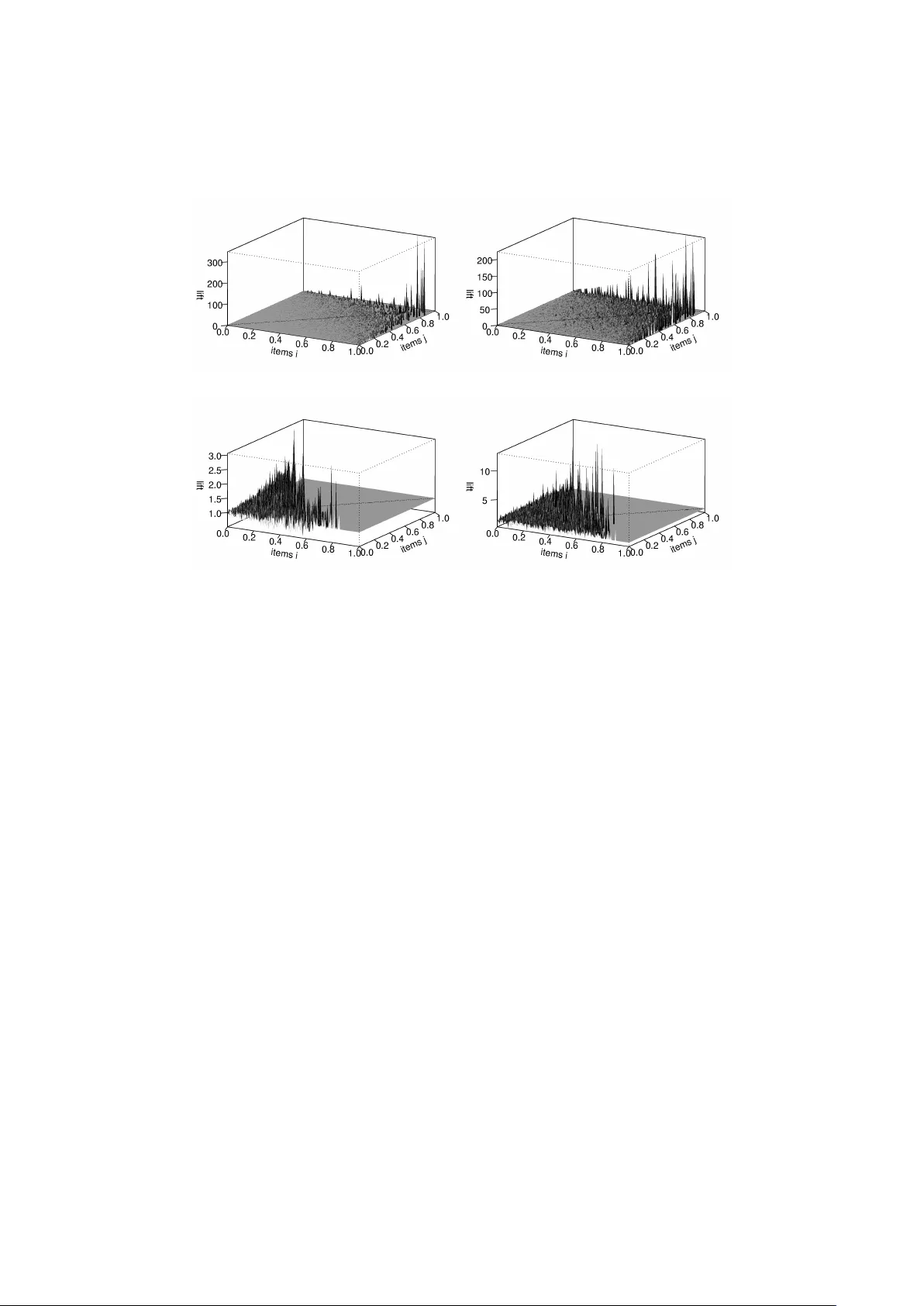
New Probabilistic In terest Measures for Asso ciation Rules Mic hael Hahsler and Kurt Hornik Vienna Universit y of Economics and Business Administration, Augasse 2–6, A-1090 Vienna, Austria. Octob er 26, 2018 Abstract Mining asso ciation rules is an important tec hnique for disco vering meaningful patterns in transaction databases. Man y different measures of in terestingness ha ve b een prop osed for asso ciation rules. Ho wev er, these measures fail to take the probabilistic properties of the mined data in to accoun t. W e start this paper with presen ting a simple probabilistic frame- w ork for transaction data which can b e used to simulate transaction data when no asso ciations are present. W e use such data and a real-world database from a gro cery outlet to explore the b eha vior of confidence and lift, t wo p opular interest measures used for rule mining. The results show that confidence is systematically influenced b y the frequency of the items in the left hand side of rules and that lift p erforms po orly to filter random noise in transaction data. Based on the probabilistic framework w e de- v elop tw o new in terest measures, h yp er-lift and hyper-confidence, whic h can b e used to filter or order mined asso ciation rules. The new measures sho w significantly better performance than lift for applications where spu- rious rules are problematic. Keyw ords: Data mining, asso ciation rules, measures of interesting- ness, probabilistic data mo deling. 1 In tro duction Mining asso ciation rules [3] is an imp ortan t tec hnique for disco vering meaningful patterns in transaction databases. An asso ciation rule is a rule of the form X ⇒ Y , where X and Y are t wo disjoint sets of items (itemsets). The rule means that if w e find all items in X in a transaction it is lik ely that the transaction also contains the items in Y . Asso ciation rules are selected from the set of all possible rules using measures of significance and interestingness. Supp ort , the primary measure of significance, is defined as the fraction of transactions in the database which con tain all items in a specific rule [3]. That is, supp( X ⇒ Y ) = supp( X ∪ Y ) = c X Y m , (1) 1 where c X Y represen ts the num b er of transactions which con tain all items in X and Y , and m is the n umber of transactions in the database. F or asso ciation rules, a minimum supp ort threshold is used to select the most frequen t (and hopefully important) item combinations called fr e quent itemsets . The process of finding these frequent itemsets in a large database is computa- tionally v ery exp ensiv e since it in volv es searc hing a lattice whic h, in the w orst case, grows exp onentially in the num b er of items. In the last decade, researc h has centered on solving this problem and a v ariet y of algorithms were intro- duced whic h render searc h feasible by exploiting v arious properties of the lattice (see [14] for p oin ters to the curren tly fastest algorithms). F rom the frequent itemsets all rules which satisfy a threshold on a certain measures of in terestingness are generated. F or asso ciation rules, Agraw al et al. [3] suggest using a threshold on c onfidenc e , one of many prop osed measures of interestingness. A practical problem is that with supp ort and confidence often to o many asso ciation rules are pro duced. One p ossible solution is to use additional interest measures, suc h as e.g. lift [9], to further filter or rank found rules. Sev eral authors [9, 2, 27, 1] constructed examples to sho w that in some cases the use of confidence and lift can b e problematic. Here, we instead tak e a lo ok at ho w pronounced and ho w imp ortan t suc h problems are when mining asso ciation rules. T o do this, we visually compare the b eha vior of supp ort, confidence and lift on a transaction database from a grocery outlet with a simulated data set whic h only contain random noise. The data set is sim ulated using a simple probabilistic framew ork for transaction data (first presen ted by Hahsler et al. [17]) which is based on indep enden t Bernoulli trials and represen ts a n ull model with “no structure.” Based on the probabilistic approach used in the framework, w e will de- v elop and analyze tw o new measures of interestingness, hyp er-lift and hyp er- c onfidenc e. W e will show how these measures are b etter suited to deal with random noise and that the measures do not suffer from the problems of confi- dence and lift. This paper is structured as follows: In Section 2, w e introduce the proba- bilistic framework for transaction data. In Section 3, w e apply the framew ork to simulate a comparable data set which is free of asso ciations and compare the b eha vior of the measures confidence and lift on the original and the sim ulated data. Two new interest measures are developed in Section 4 and compared on three differen t data sets with lift. W e conclude the paper with the main findings and a discussion of directions for further research. An implementation of the probabilistic framework and the new measures of in terestingness prop osed in this paper is included in the freely av ailable R ex- tension pack age arules [16] 1 . 2 time Tr 1 Tr 2 Tr 3 Tr 4 Tr 5 Tr m-2 Tr m-1 Tr m 0 t Figure 1: T ransactions o ccurring ov er time following a Poisson pro cess. 2 A simple probabilistic framew ork for transac- tion data A transaction database consists of a series of transactions, eac h transaction con taining a subset of the av ailable items. W e consider transactions which are recorded during a fixed time interv al of length t . In Figure 1 an example time in terv al is shown as an arro w with markings at the p oin ts in time when the transactions denoted b y T r 1 to T r m o ccur. F or the mo del we assume that transactions o ccur randomly following a (homogeneous) Poisson pro cess with parameter θ . The num b er of transactions m in time interv al t is then Poisson distributed with parameter θ t where θ is the intensit y with which transactions o ccur during the observed time interv al: P ( M = m ) = e − θt ( θ t ) m m ! (2) W e denote the items whic h o ccur in the database b y L = { l 1 , l 2 , . . . , l n } with n b eing the num b er of different items. F or the simple framework w e assume that all items o ccur indep enden tly of eac h other and that for each item l i ∈ L there exists a fixed probability p i of b eing con tained in a transaction. Each transaction is then the result of n indep endent Bernoulli trials, one for each item with success probabilities given by the vector p = ( p 1 , p 2 , . . . , p n ). T able 1 con tains the t ypical represen tation of an example database as a binary i ncidence matrix with one column for each item. Eac h row lab eled T r 1 to T r m con tains a transaction, where a 1 indicates presence and a 0 indicates absence of the corresp onding item in the transaction. Additionally , in T able 1 the success probabilit y for each item is given in the row lab eled p and the row lab eled c con tains the num b er of transactions each item is contained in (sum of the ones p er column). F ollo wing the mo del, c i , the observed num b er of transactions item l i is con- tained in, can b e interpreted as a realization of a random v ariable C i . Under the condition of a fixed num b er of transactions m , this random v ariable has the follo wing binomial distribution. P ( C i = c i | M = m ) = m c i p c i i (1 − p i ) m − c i (3) Ho wev er, since for a giv en time interv al the num b er of transactions is not 1 R is a free softw are environmen t for statistical computation, data analysis and graph- ics. The R softw are and the extension pack age arules are av ailable for download from the Comprehensive R Archiv e Network (CRAN) under http://CRAN.R- project.org/ . 3 items transactions l 1 l 2 l 3 . . . l n T r 1 0 1 0 . . . 1 T r 2 0 1 0 . . . 1 T r 3 0 1 0 . . . 0 T r 4 0 0 0 . . . 0 . . . . . . . . . . . . . . . . . . T r m − 1 1 0 0 . . . 1 T r m 0 0 1 . . . 1 c 99 201 7 . . . 411 p 0 . 005 0 . 01 0 . 0003 . . . 0 . 025 T able 1: Example transaction database with transaction counts p er item c and items success probabilities p . fixed, the unconditional distribution gives: P ( C i = c i ) = ∞ X m = c i P ( C i = c i | M = m ) · P ( M = m ) = ∞ X m = c i m c i p c i i (1 − p i ) m − c i e − θt ( θ t ) m m ! = e − θt ( p i θ t ) c i c i ! ∞ X m = c i ((1 − p i ) θ t ) m − c i ( m − c i )! = e − p i θt ( p i θ t ) c i c i ! . (4) The term P ∞ m = c i ((1 − p i ) θt ) m − c i ( m − c i )! in the second to last line in Equation 4 is an exp onen tial series with sum e (1 − p i ) θt . After substitution we see that the unconditional probability distribution of each C i follo ws a Poisson distribution with parameter p i θ t . F or short we will use λ i = p i θ t and introduce the param- eter vector λ = ( λ 1 , λ 2 , . . . , λ n ) of the Poisson distributions for all items. This parameter v ector can b e calculated from the success probability vector p and vice versa by the linear relationship λ = pθ t . F or a given database, the v alues of the parameter θ and the success vectors p or alternativ ely λ are unknown but can b e estimated from the database. The b est estimate for θ from a single database is m/t . The simplest estimate for λ is to use the observed counts c i for each item. How ever, this is only a v ery rough estimate which gets esp ecially unreliable for small coun ts. There exist more sophisticated estimation approaches. F or example, DuMouchel and Pregib on [11] use the assumption that the parameters of the count pro cesses for items in a database are distributed according to a contin uous parametric densit y function. This additional information can improv e estimates ov er using just the observed coun ts. Alternativ ely , the parameter v ector p can b e drawn from a parametric distri- bution. A suitable distribution is the Gamma distribution which is very flexible 4 and allo ws to fit a wide range of empirical data. A Gamma distribution together with the indep endence model introduced abov e is kno wn as th e Poisson-Gamma mixture mo del which results in a negative binomial distribution and has appli- cations in many fields [21]. In conjunction with association rules this mixture mo del w as used by Hahsler [15] to develop a mo del-based supp ort constraint. Indep endence mo dels similar to the probabilistic framew ork emplo yed in this pap er hav e b een used for other applications. In the context of query approxi- mation, where the aim is to predict the results of a query without scanning the whole database, Pa vlov et al. [24] inv estigated the indep endence model as an extremely parsimonious mo del. How ever, the quality of the appro ximation can b e p oor if the indep endence assumption is violated significantly b y the data. Cadez et al. [10] and Hollm ´ en et al. [19] used the indep endence mo del to cluster transaction data by learning the comp onen ts of a mixture of indep en- dence mo dels. In the former pap er the aim is to identify typical customer profiles from market basket data for outlier detection, customer ranking and visualization. The later pap er focuses on approximating the joint probability distribution o ver all items by mining frequent itemsets in each comp onent of the mixture model, using the maximum entr opy technique to obtain lo cal mo dels for the comp onen ts, and then combining the lo cal mo dels. Almost all authors use the indep endence mo del to learn something from the data. Ho wev er, the mo del only uses the marginal probabilities p of the items and ignores all in teractions. Therefore, the accuracy and usefulness of the indep endence mo del for such applications is drastically limited and mo dels whic h incorp orate pair-wise or even higher interactions provide b etter results. F or the application in this paper, w e explicitly wan t to generate data with indep enden t items to ev aluate measures of interestingness. 3 Sim ulated and real-w orld database W e use 1 month ( t = 30 days) of real-world point-of-sale transaction data from a typical lo cal gro cery outlet. F or conv enience reasons we use categories (e.g., p op c orn ) instead of the individual brands. In the av ailable m = 9835 transac- tions we found n = 169 differen t categories for which articles were purchased. This database is called “Gro cery” and is freely distributed with the R extension pac k age arules [16]. The estimated transaction intensit y θ for Gro cery is m/t = 327 . 5 transac- tions per day . T o simulate comparable data using the framew ork, we use the P oisson distribution with the parameter θ t to draw the num b er of transactions m (9715 in this exp erimen t). F or simplicity w e use the relative observed item fre- quencies as estimates for λ and calculate the success probability vector p by λ/θ t . With this information we simulate the m transactions in the transaction database. Note, that the simulated database do es not contain any asso ciations (all items are indep enden t), and thus differs from the Gro cery database which is exp ected to contain asso ciations. In the following we will use the sim ulated data set not to compare it to the real-w orld data set, but to show that interest measures used for asso ciation rules exhibit similar effec ts on real-world data as on simulated data without any asso ciations. F or the rest of this section we concentrate on 2-itemsets, i.e., the co-o ccurrences b et w een tw o items denoted by l i and l j with i, j = 1 , 2 , . . . , n and i 6 = j . Al- 5 (a) simulated (b) Gro cery Figure 2: Supp ort distributions of all 2-itemsets (items are ordered by decreasing supp ort from left to right and front to back). though itemsets and rules of arbitrary length can b e analyzed using the frame- w ork, we restrict the analysis to 2-itemsets since interest measures for these asso ciations are easily visualized using 3D plots. In these plots the x and y -axis eac h represent the items l i and l j ordered from the most frequent to the least frequen t from left to right and front to bac k. On the z -axis w e plot the analyzed measure. First we compare the 2-itemset supp ort. Figure 2 shows the supp ort distri- bution of all 2-itemsets. Naturally , the most frequent items also form together the most frequent itemsets (to the left in the front of the plots). The gen- eral forms of the tw o supp ort distributions in the plot are v ery similar. The Gro cery data set reaches higher supp ort v alues with a median of 0 . 000203 com- pared to 0 . 000113 for the sim ulated data. This indicates that the Gro cery data set con tains asso ciated items which co-o ccur more often than exp ected under indep endence. 3.1 The in terest measure confidence Confidence is defined by Agraw al et al. [3] as conf ( X ⇒ Y ) = supp( X ∪ Y ) supp( X ) , (5) where X and Y are tw o disjoin t itemsets. Often confidence is understo od as an estimate of the conditional probability P ( E Y | E X ), were E X ( E Y ) is the even t that X ( Y ) o ccurs in a transaction [18]. F rom the 2-itemsets we generate all rules of the from l i ⇒ l j and present the confidence distributions in Figures 3. Confidence is generally m uch low er for the simulated data (with a median of 0 . 0086 to 0 . 0140 for the real-world data). Finding higher confidence v alues in the real-world data, which are exp ected to con tain asso ciations, indicates that the confidence measure is able to suppress noise. How ever, the plots in Figure 3 also show that confidence alwa ys increases with the item in the righ t hand side of the rule ( l j ) getting more frequent. This b eha vior directly follows from the wa y confidence is calculated. If the frequency of the right hand side of the rule increases, confidence will increase even if the items in the rule are not related (see itemset Y in Equation 5). F or the 6 (a) simulated (b) Gro cery Figure 3: Confidence distributions of all rules containing 2 items. Gro cery data set in Figure 3(b) we see that this effect dominates the confidence measure. The fact that confidence clearly fav ors some rules mak es the measure problematic when it comes to selecting or ranking rules. 3.2 The in terest measure lift T ypically , rules mined using minimum supp ort (and confidence) are filtered or ordered using their lift v alue. The measure lift (also called interest [9]) is defined on rules of the form X ⇒ Y as lift( X ⇒ Y ) = conf ( X ⇒ Y ) supp( Y ) . (6) A lift v alue of 1 indicates that the items are co-o ccurring in the database as exp ected under indep endence. V alues greater than one indicate that the items are asso ciated. F or mark eting applications it is generally argued that lift > 1 indicates complementary pro ducts and lift < 1 indicates substitutes [6, 20]. Figure 4 show the lift v alues for the tw o data sets. The general distribution is again very similar. In the plots in Figures 4(a) and 4(b) we can only see that very infrequent items pro duce extremely high lift v alues. These v alues are artifacts o ccurring when tw o very rare items co-o ccur once together by c hance. Suc h artifacts are usually a voided in asso ciation rule mining by using a minimum supp ort on itemsets. In Figures 4(c) and 4(d) we applied a minimum supp ort of 0.1%. The plots show that there exist rules with higher lift v alues in the Gro cery data set than in the sim ulated data. Ho wev er, in the sim ulated data w e still find 50 rules with a lift greater than 2. This indicates that the lift measure performs p o orly to filter random noise in transaction data esp ecially if we are also interested in relatively rare items with low supp ort. The plots in Figures 4(c) and 4(d) also clearly show lift’s tendency to pro duce higher v alues for rules con taining less frequent items resulting in that the highest lift v alues alw ays o ccur close to the b oundary of the selected minimum support. W e refer the reader to [5] for a theoretical treatmen t of this effect. If lift is used to rank disco vered rules this means that there is not only a systematic tendency tow ards fa voring rules with less frequent items but the rules with the highest lift will also alwa ys change with even small v ariations of the user-sp ecified minimum supp ort. 7 (a) simulated (b) Gro cery (c) simulated with supp > 0 . 1% (d) Gro cery with supp > 0 . 1% Figure 4: Lift distributions of all rules with t wo items. 4 New measures of in terest In the simple probabilistic mo del all items as well as combinations of items o ccur following indep enden t Poisson pro cesses. If we lo ok at the observ ed co- o ccurrence counts of all pairs of t wo items, l i and l j , in a data set with m transactions, we can form an n × n contingency table. Each cell can b e mo deled b y a random v ariable C ij whic h, given fixed marginal counts c i and c j , follows a hyper-geometric distribution. The h yp er-geometric distribution arises for the so-called urn problem, where the urn contains w white balls and b black balls. The num b er of white balls dra wn with k trials without replacement follo ws a hyper-geometric distribution. This mo del is applicable for counting co-o ccurrences for indep enden t items l i and l j in the follo wing wa y: Item l j o ccurs in c j transactions, therefore, we can represen t the database as an urn which contains c j transactions with l j (white balls) and m − c j transactions without l j (blac k balls). T o assign item l i 6 = l j randomly to c i transactions, w e draw without replacement c i transactions from the urn. The num b er of drawn transactions which w e assign item l j to (and th us represe n t the co-o ccurrences b et ween l i and l j ) then has a hyper-geometric distribution. It is straightforw ard to extend this reasoning from tw o items to tw o itemsets X and Y . In this case the random v ariable C X Y follo ws a hyper-geometric distribution with the coun ts of the itemsets as its parameter. F ormally , the probabilit y of counting exactly r transactions whic h contain the tw o indep endent 8 itemsets X and Y is giv en by P ( C X Y = r ) = c Y r m − c Y c X − r m c X . (7) Note that this probability is conditional to the marginal counts c X and c Y . T o simplify the notation, we will omit this condition also in the rest of the pap er. The probability of counting more than r transactions is P ( C X Y > r ) = 1 − r X i =0 P ( C X Y = i ) . (8) Based on this probability , we will develop the probabilistic measures hyper- lift and h yp er-confidence in the rest of this section. Both measures quantify the deviation of the data from the indep endence mo del. This idea is a similar to the use of random data to assess the significance of found clusters in cluster analysis (see, e.g., [7]). 4.1 Hyper-lift The exp ected v alue of a random v ariable C with a hyper-geometric distribution is E ( C ) = k w w + b , (9) where the parameter k represents the n umber of trials, w is the n umber of white balls, and b is the num b er of black balls. Applied to co-o ccurrence counts for the tw o itemsets X and Y in a transaction database this gives E ( C X Y ) = c X c Y m , (10) where m is the num b er of transactions in the database. By using Equation 10 and the relationship b et ween absolute coun ts and support, lift can b e rewritten as lift( X ⇒ Y ) = conf ( X ⇒ Y ) supp( Y ) = supp( X ∪ Y ) supp( X ) supp( Y ) = c X Y E ( C X Y ) . (11) F or items with a relativ ely high o ccurrence frequency , using the exp ected v alue for lift works well. Ho wev er, for relativ ely infrequen t items, which are the ma jority in most transaction databases and v ery common in other domains [28], using the ratio of the observ ed count to the exp ected v alue is problematic. F or example, let us assume that we hav e the t wo indep enden t itemsets X and Y , and b oth itemsets hav e a supp ort of 1% in a database with 10000 transactions. Using Equation 10, the exp ected count E ( C X Y ) is 1. How ever, for the tw o in- dep enden t itemsets there is a P ( C X Y > 1) of 0.264 (using the hyper-geometric distribution from Equation 8). Therefore there is a substantial chance that we will see a lift v alue of 2 , 3 or even higher. Giv en the huge num b er of item- sets and rules generated by combining items (esp ecially when also considering itemsets con taining more than tw o items), this is very problematic. Using larger databases with more transactions reduces the problem. How ever, it is not alwa ys p ossible to obtain a consistent database of sufficient size. Large databases are 9 (a) simulated (b) Gro cery Figure 5: Hyp er-lift for rules with t wo items. usually collected ov er a long p erio d of time and thus may contain outdated in- formation. F or example, in a supermarket the articles offered ma y hav e changed or shopping b eha vior may hav e changed due to seasonal changes. T o address the problem, one can quantify the deviation of the observed co-o ccurrence count c X Y from the indep endence mo del by dividing it by a dif- feren t lo cation parameter of the underlying h yp er-geometric distribution than the mean whic h is used for lift. F or h yp er-lift w e suggest to use the quantile of the distribution denoted by Q δ ( C X Y ). F ormally , the minimal v alue of the δ quan tile of the distribution of C X Y is defined by the following inequalities: P ( C X Y < Q δ ( C X Y )) ≤ δ and P ( C X Y > Q δ ( C X Y )) ≤ 1 − δ. (12) The resulting measure, which we call hyper-lift, is defined as h yp er-lift δ ( X ⇒ Y ) = c X Y Q δ ( C X Y ) . (13) In the following, we will use δ = 0 . 99 which results in hyper-lift b eing more conserv ative compared to lift. The measure can b e interpreted as the num b er of times the observed co-o ccurrence count c X Y is higher than the highest count w e exp ect at most 99% of the time. This means, that hyper-lift for a rule with indep enden t items will exceed 1 only in 1% of the cases. In Figure 5 w e compare the distribution of the hyper-lift v alues for all rules with tw o items at δ = 0 . 99 for the sim ulated and the Grocery database. Fig- ure 5(a) shows that the hyper-lift on the simulated data is more evenly dis- tributed than lift (compare to Figure 4 in Section 3.2). Also only for 100 of the n × n = 28561 rules h yp er-lift exceeds 1 and no rule exceeds 2. This indicates that hyper-lift filters the random co-o ccurrences b etter than lift with 3718 rules ha ving a lift greater than 1 and 82 rules exceed a lift of 2. How ever, hyper- lift also shows a systematic dep endency on the o ccurrence probability of items leading to smaller and more volatile v alues for rules with less frequent items. On the Grocery database in Figure 5(b) we find larger hyper-lift v alues of up to 4.286. This indicates that the Gro cery database indeed contains dep enden- cies. The highest v alues are observed b et ween items with intermediate supp ort (lo cated closer to the cen ter of the plot). Therefore, hyper-lift av oids lift’s prob- lem of pro ducing the highest v alues alwa ys only close to the minimum supp ort b oundary (compare Section 3.2). 10 X = 0 X = 1 Y = 0 m − c Y − c X − C X Y c X − C X Y m − c Y Y = 1 c Y − C X Y C X Y c Y m − c X c X m T able 2: 2 × 2 con tingency table for the counts of the presence (1) and absence (0) of the itemsets in transactions. F urther ev aluations of h yp er-lift with rules including an arbitrary n umber of items will b e presented in Section 4.3. 4.2 Hyper-confidence Instead of lo oking at quantiles of the h yp er-geometric distribution to form a lift-lik e measure, we can also directly calculate the probability of realizing a coun t smaller than the observed co-o ccurrence c oun t c X Y giv en the marginal coun ts c X and c Y . P ( C X Y < c X Y ) = c X Y − 1 X i =0 P ( C X Y = i ) , (14) where P ( C X Y = i ) is calculated using Equation 7 ab o ve. A high probabil- it y indicates that observing c X Y under indep endence is rather unlikely . The probabilit y can b e directly used as the interest measure hyper-confidence: h yp er-confidence( X ⇒ Y ) = P ( C X Y < c X Y ) (15) Analogously to other measures of in terest, w e can use a threshold γ on hyper- confidence to accept only rules for which the probability to observe s uc h a high co-o ccurrence count by chance is smaller or equal than 1 − γ . F or example, if w e use γ = 0 . 99, for each accepted rule, there is only a 1% chance that the observ ed co-o ccurrence count arose by pure c hance. F ormally , using a threshold on hyper-confidence for the rules X ⇒ Y (or Y ⇒ X ) can b e interpreted as using a one-sided statistical test on the 2 × 2 contingency table depicted in T able 2 with the null h yp othesis that X and Y are not p ositiv ely related. It can b e shown that hyper-confidence is related to the p -v alue of a one-sided Fisher’s exact test. The one-sided Fisher’s exact test for 2 × 2 con tingency tables is a simple p erm utation test which ev aluates the probabilit y for realizing an y table (see T able 2) with C X Y ≥ c X Y giv en fixed marginal coun ts [12]. The test’s p -v alue is given by p -v alue = P ( C X Y ≥ c X Y ) (16) whic h is equal to 1 − h yp er-confidence( X ⇒ Y ) (see Equation 15), and gives the p -v alue of the uniformly most pow erful (UMP) test for the null ρ ≤ 1 (where ρ is the o dds ratio) against the alternativ e of p ositiv e asso ciation ρ > 1 [22, pp. 58–59], provided that the p -v alue of a randomized test is defined as the lo west significance level of the test that w ould lead to a (complete) rejection. If we use a significance lev el of α = 0 . 01, we w ould reject the null h yp othesis of no p ositiv e correlation if p -v alue < α . Using γ as a threshold on hyper- confidence is equiv alent to a Fisher’s exact test with α = 1 − γ . 11 Note that hyper-confidence is equiv alent to a sp ecial case of Fisher’s exact test, the one-sided test on 2 × 2 contingency tables. In this case, the p -v alue is directly obtained from the hyper-geometric distribution which is computation- ally negligible compared to the effort of counting supp ort and finding frequent itemsets. The idea of using a statistical test on 2 × 2 contingency tables to test for dep endencies b et ween itemsets was already prop osed by Liu et al. [23]. The authors use the χ 2 test which is an appro ximate test for the same purp ose as Fisher’s exact test in the 2-sided case. The generally accepted rule of thum b is that the χ 2 test’s approximation breaks down if the exp ected counts for any of the contingency table’s cells falls b elow 5. F or data mining applications, where p otentially millions of tests hav e to b e p erformed, it is very likely that man y tests will suffer from this restriction. Fisher’s exact test and thus hyper- confidence do not hav e this drawbac k. F urthermore, the χ 2 test is a tw o-sided test, but for the application of mining asso ciation rules where only rules with p ositiv ely correlated elemen ts are of in terest, a one-sided test as used here is m uch more appropriate. In Figures 6(a) and (b) w e compare the h yp er-confidence v alues pro duced for all rules with 2 items on the Gro cery database and the corresp onding sim u- lated data set. Since the v alues v ary strongly b et w een 0 and 1, we use for easier comparison image plots instead of the p erspective plots used b efore. The inten- sit y of the dots indicates the v alue of hyper-confidence for the rules l i ⇒ l j (the items are again organized left to right and fron t to back by decreasing support). All dots for rules with a hyper-confidence v alue smaller than a set threshold of γ = 0 . 99 are remov ed. F or the simulated data we see that the 108 rules whic h pass the hyper-confidence threshold are scattered ov er the whole image. F or the Gro cery database in Figure 6(b) w e see that many (3732) rules pass the h yp er- confidence threshold and that the concentration of passing rules increases with item supp ort. This results from the fact that with increasing counts the test is b etter able to reject the null hypotheses. In Figures 7(a) and (b) we present the num b er of accepted rules by the set hyper-confidence threshold. F or the simulated data the num b er of accepted rules is directly prop ortional to 1 − γ . This b eha vior directly follows from the prop erties of the data. All items are indep enden t and therefore rules randomly surpass the threshold with the probability given by the threshold. F or the Gro cery data set in Figure 7(b), w e see that more rules than exp ected for random data (dashed line) surpass the threshold. At γ = 0 . 99, for each of the n tests exists a 1% chance that the rule is accepted although it is spurious. Therefore, a rough estimate of the prop ortion of spurious rules in the set of m accepted rules is n (1 − γ ) /m . F or example, for the Gro cery database w e hav e n = 19272 tests and for γ = 0 . 99 we found m = 3732 rules. The estimated prop ortion of spurious rules in the set is therefore 5.2% which is ab out five times higher than the α of 1% used for each individual test. The reason is that w e conduct multiple tests simultaneously to generate the set of accepted rules. If we are not interested in the individual test but in the probability that some tests will accept spurious rules, w e hav e to adjust α . A conserv ativ e approach is the Bonferroni correction [26] where a corrected significance level of α ∗ = α/n is used for each test to achiev e an ov erall alpha v alue of α . The result of using a Bonferroni corrected γ = 1 − α ∗ is depicted in Figures 8(a) and (b). F or the sim ulated data set we see that after correction no spurious rule is accepted while 12 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 items i items j (a) simulated 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 items i items j (b) Gro cery Figure 6: Hyper-confidence for rules with t wo items and γ > 0 . 99 (items are ordered by decreasing supp ort from left to right and b ottom to top). for the Gro cery database still 652 rules pass the test. Since w e used a corrected threshold of γ = 0 . 99999948 ( α = 5 . 2 · 10 − 7 ) these rules represent very strong asso ciations. Bet ween the measures hyper-confidence and h yp er-lift exists a direct connec- tion. Using a threshold γ on hyper-confidence and requiring a hyper-lift using the δ quantile to b e greater than one is equiv alent for γ = δ . F ormally , for an arbitrary rule X ⇒ Y and 0 < γ < 1, h yp er-confidence( X ⇒ Y ) ≥ γ ⇔ h yp er-lift δ ( X ⇒ Y ) > 1 for γ = δ. (17) T o pro ve this equiv alence, let us write F ( c ) = P ( C X Y ≤ c ) for the distribu- tion function of C X Y , so that the h yp er-confidence h = h ( c ) equals F ( c − 1). W e note that F as well as its quantile function Q are non-decreasing and that for integer c in the supp ort of C X Y , Q F ( c ) = c . Hence, pro vided that h ( c ) > 0, Q h ( c ) = c − 1. What w e need to show is that h ( c ) ≥ γ iff c > Q γ . If 0 < γ ≤ h ( c ), it follows that Q γ ≤ Q h ( c ) = c − 1, i.e., c > Q γ . Con versely , if c > Q γ , it follo ws that c − 1 ≥ Q γ and thus h ( c ) = F ( c − 1) ≥ F ( Q γ ) ≥ γ , completing the pro of. Hyp er-confidence as defined ab o ve only uncov ers complementary effects b e- t ween items. T o interpret using a threshold on hyper-confidence as a simple one-sided statistical test makes it also very natural to adapt the measure to find substitution effects, items which co-o ccur significan tly less together than exp ected under indep endence. The h yp er-confidence for substitutes is given by: h yp er-confidence sub ( X ⇒ Y ) = P ( C X Y > c X Y ) = 1 − c X Y X i =0 P ( C X Y = i ) (18) Applying a threshold γ sub can b e again in terpreted as using a one-sided test, this time for negativ ely related items. One could also construct a hyper- lift measure for substitutes using low quantiles; ho wev er, its construction is less straigh tforward. 13 0.0 0.2 0.4 0.6 0.8 1.0 0 5000 10000 15000 hyper−confidence threshold γ accepted rules (a) simulated 0.0 0.2 0.4 0.6 0.8 1.0 0 5000 10000 15000 20000 hyper−confidence threshold γ accepted rules (b) Gro cery Figure 7: Num b er of accepted rules dep ending on the used hyper-confidence threshold. 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 items i items j (c) simulated 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 items i items j (d) Gro cery Figure 8: Hyp er-confidence for rules with tw o items using a Bonferroni cor- rected γ . 14 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 items i items j (a) simulated 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 items i items j (b) Gro cery Figure 9: Hyp er-confidence for substitutes with γ sub > 0 . 99 for rules with tw o items. Database Gro cery T10I4D100K Kosarak T yp e mark et basket artificial click-stream T ransactions 9835 100,000 50,000 Avg. trans. size 4.41 10.10 3.00 Median trans. size 3.00 10.00 7.98 Distinct items 169 870 18,936 T able 3: Characteristics of the used databases. In Figures 9(a) and (b) we show the rules with tw o items whic h surpass a γ sub of 0.99 in the simulated and the Gro cery database. In the simulated data w e see that the 68 falsely found rules are regularly scattered o ver the low er left triangle. In the Gro cery database, the 116 rules which contain substitutes are concen trated for a few items (the line clearly visible in Figure 9(b) corresp onds to the item ‘canned b eer’ which has a strong substitution effect for most other items). As for complements, it is p ossible to use Bonferroni correction. 4.3 Empirical results T o ev aluate the proposed measures, we compare their ability to suppress spu- rious rules with the w ell-known lift measure. F or the ev aluation, we use in ad- dition to the Gro cery database tw o publicly av ailable databases. The database “T10I4D100K” is an artificial data set generated by the pro cedure describ ed by Agra wal and Srik ant [4] which is often used to ev aluate asso ciation rule mining algorithms. The third database is a sample of 50,000 transactions from the “Kosarak” database. This database was provided b y Bo don [8] and con tains clic k-stream data of a Hungarian on-line news p ortal. As shown in T able 3, the three databases hav e very different c haracteristics and thus should cov er a wide range of applications for data from differen t sources and with different database sizes and num b ers of items. 15 Database Gro cery/ sim. T10I4D100K/ sim. Kosarak/ sim. Min. supp ort 0.001 0.001 0.002 F ound rules 40943/8685 89605/9288 53245/2530 lift > 1 40011/5812 86855/5592 51822/1365 lift > 2 27334/ 180 84880/ 0 42641/ 0 h yp er-lift 0 . 99 > 1 30083/ 196 86463/ 150 51151/ 23 h yp er-lift 0 . 99 > 2 1563/ 0 83176/ 0 37683/ 0 h yp er-conf . > 0 . 9 36724/1531 86647/1286 51282/ 240 h yp er-conf . > 0 . 9999 15046/ 1 86207/ 0 51083/ 0 T able 4: Number of rules exceeding a lift and hyper-lift ( δ = 0 . 99) of 1 and 2, and a hyper-confidence of 0.9 and 0.9999 on the three databases and comparable sim ulated data sets. F or each database w e simulate a comparable association-free data set follow- ing the simple probabilistic mo del describ ed ab o ve in this pap er. W e generate all rules with one item in the right hand side which satisfy a sp ecified minimum supp ort (see T able 4). Then we compare the impact of lift and confidence with h yp er-lift and hyper-confidence on rule selection. In T able 4 we present the n um- b er of rules found using the preset minim um supp ort and the num b er of rules whic h also hav e a lift greater than 1 and 2, a h yp er-lift with δ = 0 . 99 greater than 1 and 2, or a hyper-confidence greater than 0 . 9 and 0 . 999, resp ectively . F rom the results in the table we see that, compared to the real databases, in the sim ulated data sets only a m uch smaller num b er of rules reaches the required minim um supp ort. This supp orts the assumption that these data sets do not con tain asso ciations b et ween items while the real databases do. If w e assume that rules found in the real databases are (at least potentially) useful asso cia- tions while w e know that rules found in the sim ulated data sets must b e spu- rious, we can compare the p erformance of lift, h yp er-lift and hyper-confidence on the data. In T able 4 w e see that there obviously exists a trade-off b et ween accepting more rules in the real databases while suppressing the spurious rules in the simulated data sets. In terms of rules found in the real databases versus rules suppressed in the simulated data sets, hyper-lift 0 . 99 > 1 lies for all three databases betw een lift > 1 and lift > 2 while h yp er-lift 0 . 99 > 2 never accepts spurious rules but also reduces the rules in the real databases (esp ecially in the Gro cery database). The same is true for hyper-confidence with a threshold of 0 . 9 the num b er of resulting rules lying in b etw een the results for the t wo lift thresholds and for 0 . 999 hyper-confidence only once (for the Groc ery database) accepts a single rule. T o analyze the trade-off in more detail, we pro ceed as follo ws: W e v ary the threshold for lift (a minimum lift b et w een 1 and 3) and assess the n umber of rules accepted in the databases and the simulated data sets for each setting. Then we rep eat the pro cedure with confidence (a minim um b et ween 0 and 1), with hyper-lift (a minimum hyper-lift b et ween 1 and 3) at four settings for δ (0.9, 0.99, 0.999, 0.9999) and with hyper-confidence (a minim um threshold b et w een 0.5 and 0.9999). W e plot the num b er of accepted rules in the real database b y the n umber of accepted rules in the simulated data sets where the p oints for each measure (lift, h yp er-confidence, and hyper-lift with the same v alue for δ ) are connected by a line to form a curv e. The resulting plots in Figure 10 16 0 1000 2000 3000 4000 5000 6000 15000 20000 25000 30000 35000 40000 simulated (accepted rules) Groceries (accepted rules) hyper−confidence lift confidence ● ● ● ● ● ● ● 0 100 200 300 400 500 10000 15000 20000 25000 30000 simulated (accepted rules) Groceries (accepted rules) ● lift hyper−confidence hyperlift δ = 0.9 hyperlift δ = 0.99 hyperlift δ = 0.999 hyperlift δ = 0.9999 (a) Gro cery 0 1000 2000 3000 4000 5000 86200 86400 86600 86800 simulated (accepted rules) T10I4D100K (accepted rules) hyper−confidence lift confidence ● ● ● ● ● ● ● ● ● ● 0 100 200 300 400 500 86200 86300 86400 86500 simulated (accepted rules) T10I4D100K (accepted rules) ● lift hyper−confidence hyperlift δ = 0.9 hyperlift δ = 0.99 hyperlift δ = 0.999 hyperlift δ = 0.9999 (b) T10I4D100K 0 200 400 600 800 1000 1200 1400 51000 51200 51400 51600 51800 simulated (accepted rules) Kosarak (accepted rules) hyper−confidence lift ● ● ● ● ● ● ● ● ● ● ● ● ● 0 50 100 150 200 51100 51150 51200 51250 simulated (accepted rules) Kosarak (accepted rules) ● lift hyper−confidence hyperlift δ = 0.9 hyperlift δ = 0.99 hyperlift δ = 0.999 hyperlift δ = 0.9999 (c) Kosarak Figure 10: Comparison of num b er of rules accepted by differen t thresholds for lift, confidence, hyper-lift (only in the detail plots to the righ t) and hyper- confidence in the three databases and the simulated data sets. 17 are similar in spirit to R e c eiver Op er ating Char acteristic (ROC) plots used in mac hine learning [25] to compare classifiers and can b e in terpreted similarly . Curv es closer to the top left corner of the plot represen t b etter results, since they pro vide a b etter ratio of true p ositiv es (here p oten tially useful rules accepted in the real databases) and false p ositives (spurious rules accepted in the simulated data sets) regardless of class or cost distributions. Confidence p erforms considerably w orse than the other measures and is only plotted in the left hand side plots. F or the Kosarak database, confidence p er- forms so badly that its curve lies even outside the plotting area. Ov er the whole range of parameter v alues presented in the left hand side plots in Figure 10, there is only little difference visible b etw een lift and hyper- confidence visible. The four hyper-lift curves are very close to the hyper- confidence curve and are omitted from the plot for b etter visibility . A closer in- sp ection of the range with few spurious rules accepted in the sim ulated data sets (righ t hand side plots in Figure 10) sho ws that in this part hyper-confidence and h yp er-lift clearly provides b etter results than lift (the new measures dominate lift). The p erformance of hyper-confidence and h yp er-lift are comparable. The results for the Kosarak database lo ok differen t than for the other t wo databases. The reason for this is that the generation process of clic k-stream data is v ery differen t from market bask et data. F or click-stream data the user clic ks through a collection of W eb pages. On eac h page the hyperlink structure confines the user’s choices to a usually v ery small subset of all pages. These restrictions are not yet incorp orated into the probabilistic framework. How ever, hyper-lift and h yp er-confidence do not dep end on the framew ork and th us will pro duce still consisten t results. Note that in the previous ev aluation, we did not know how many accepted rules in the real databases were spurious. How ever, we can sp eculate that if the new measures suppress noise better for the sim ulated data, it also pro duces b etter results in the real database and the improv emen t ov er lift is actually greater than can b e seen in Figure 10. Only for synth etic data sets, where w e can fully control the generation pro- cess, w e know which rules are non-spurious. W e mo dified the generator de- scrib ed b y Agraw al and Srik ant [4] to rep ort all itemsets whic h were used in generating the data set. These itemsets represent all non-spurious patterns con tained in the data set. The default parameters for the generator to pro duce the data set T10I4D100K tend to pro duce easy to detect patterns since with the used so-called c orruption level of 0.5 the 2000 patterns app ear in the data set only sligh tly corrupted. W e used a muc h higher corruption level of 0.9 which do es not change the basic characteristics rep orted in T able 3 ab o ve but makes it considerably harder to find the non-spurious patterns. W e generated 100 data sets with 1000 items and 100,000 transactions each, where we sav ed all patterns used for the generation. F or each data set, w e generate sets of rules whic h satisfy a minimum supp ort of 0.001 and different thresholds for hyper-confidence, lift and confidence (we omit h yp er-lift here since the results are very close to hyper-confidence). F or each set of rules, we count ho w man y accepted rules represent patterns which were used for generating the corresp onding data set ( c over e d p ositive examples, P ) and how many rules are spurious ( c over e d ne gative examples, N ). T o compare the p erformance of the differen t measures in a single plot, we av erage the v alues for P and N for each measure at each used threshold and plot the results (Figure 11). 18 0 100 200 300 400 0 20000 40000 60000 N (covered negative examples) P (covered positive examples) ● hyper−confidence lift confidence chi−square ● ● ● ● ● ● ● ● ● ● ● ● ● ● Figure 11: Average PN graph for 100 data sets generated with a corruption rate of 0.9. A plot of corresp onding P and N v alues with all points for the same measure connected b y a line is called a PN gr aph in the c over age sp ac e which is similar to the ROC sp ac e without normalizing the X and Y-axes [13]. PN graphs can b e in terpreted similarly to R OC graphs: P oints closer to the top left corner indicate b etter p erformance. Cov erage space is used in this ev aluation since, other than most classifiers, asso ciation rules typically only cov er a small fraction of all examples (only rules generated from frequent itemsets generate rules) which mak es cov erage space a more natural representation than ROC space. Av eraged PN graphs for h yp er-confidence, lift, confidence and the χ 2 statis- tic are presented in Figure 11. Hyp er-confidence dominates lift by a consider- ably larger margin than in the previous experiments rep orted in Figure 10(b) ab o v e. This supp orts the sp eculation that the improv ements ac hiev able with h yp er-confidence are also considerable for real w orld databases. Using a v arying threshold on the χ 2 statistic as prop osed by Liu et al. [23] p erforms b etter than lift and provides only slightly inferior results than h yp er-confidence. W e also insp ected the results for the individual data sets. While the char- acteristics of the data sets v ary sometimes significantly (due to the w ay the patterns used in the generation pro cess are pro duced; see [4]), all data sets sho w similar results with hyper-confidence dominating all other measures. 19 5 Conclusion In this con tribution w e used a simple indep endence mo del (a n ull model with “no structure”) to simulate a data set with comparable characteristics as a real-w orld data set from a gro cery outlet. W e visually compared the v alues of differen t measures of interestingness for all p ossible rules with tw o items. In the comparison we found the same problems for confidence and lift, which other authors already p ointed out. How ever, these authors only argued with sp ecially constructed and isolated example rules. The analysis used in this pap er gives a b etter picture of how strongly these problems influence the pro cess of selecting whole sets of rules. Confidence fav ors rules with high-supp ort items in the righ t hand side of the rule. F or databases with items with strongly v arying supp ort coun ts, this effect dominates confidence which makes it a bad measure for selecting or ranking rules. Lift has a strong tendency to pro duce the highest v alues for rules whic h just pass the set minim um supp ort threshold. Selecting or ranking rules by lift will lead to very unstable results, since even small changes of the minimum supp ort threshold will lead to very different rules b eing ranked highest. Motiv ated by these problems, tw o nov el measures of interestingness, h yp er- lift and hyper-confidence, are developed. Both measures quantify the deviation of the data from a null mo del whic h mo dels the co-o ccurrence count of tw o indep enden t itemsets in a database. Hyp er-lift is similar to lift but uses instead of the exp ected v alue a quantile from the corresp onding hyper-geometric distri- bution. The distribution can b e very skew ed and thus hyper-lift can result in significan tly different ordering of rules than lift. Hyp er-confidence is defined as the probability of realizing a count smaller than the observ ed coun t and from its setup related to a one-sided Fisher’s exact test. The new measures do not show the problematic b eha vior describ ed for con- fidence and lift abov e. Also, b oth measures outp erform confidence, lift, and the χ 2 statistic on real-word data sets from different application domains as well as in an exp erimen t with simulated data. This indicates that the knowledge of ho w independent itemsets co-o ccur can b e used to construct sup erior mea- sures of in terestingness which improv e the quality of the rule set returned by the mining algorithm. A topic for future research is to develop more complicated indep endence mo dels which incorp orate constraints for sp ecific application domains. F or ex- ample, in click-stream data, the link structure restricts which pages can b e reac hed from one page. Also the generation of artificial data sets which incor- p orate mo dels for dep endencies b et ween items is an important area of research. Suc h data sets could greatly improv e the wa y the effectiveness of data mining applications is ev aluated and compared. References [1] J.-M. Adamo, Data Mining for Asso ciation Rules and Sequential Patterns, Springer, New Y ork, 2001. [2] C. C. Aggarwal and P . S. Y u, A new framework for itemset generation, in: PODS 98, Symp osium on Principles of Database Systems, Seattle, W A, USA, 1998, pp. 18–24. 20 [3] R. Agraw al, T. Imielinski and A. Swami, Mining asso ciation rules b etw een sets of items in large databases, in: Pro ceedings of the A CM SIGMOD In ternational Conference on Management of Data, W ashington D.C., 1993, pp. 207–216. [4] R. Agraw al and R. Srik an t, F ast algorithms for mining asso ciation rules in large databases, in: Proceedings of the 20th International Conference on V ery Large Data Bases, VLDB, J. B. Bo cca, M. Jark e and C. Zaniolo, eds., San tiago, Chile, 1994, pp. 487–499. [5] R. J. Bay ardo Jr. and R. Agra wal, Mining the most interesting rules, in: Pro ceedings of the fifth ACM SIGKDD in ternational conference on Knowl- edge discov ery and data mining (KDD-99), A CM Press, 1999, pp. 145–154. [6] R. Betancourt and D. Gautsc hi, Demand complemen tarities, household pro duction and retail assortments, Mark eting Science 9 (1990), 146–161. [7] H. H. Bo ck, Probabilistic models in cluster analysis, Computational Statis- tics and Data Analysis 23 (1996), 5–29. [8] F. Bo don, A fast apriori implementation, in: Proceedings of the IEEE ICDM W orkshop on F requent Itemset Mining Implemen tations (FIMI’03), B. Go ethals and M. J. Zaki, eds., Melb ourne, Florida, USA, 2003, v ol- ume 90 of CEUR W orkshop Pro ceedings. [9] S. Brin, R. Motw ani, J. D. Ullman and S. Tsur, Dynamic itemset counting and implication rules for market basket data, in: SIGMOD 1997, Pro ceed- ings ACM SIGMOD In ternational Conference on Management of Data, T ucson, Arizona, USA, 1997, pp. 255–264. [10] I. V. Cadez, P . Smyth and H. Mannila, Probabilistic mo deling of trans- action data with applications to profiling, visualization, and prediction, in: Pro ceedings of the A CM SIGKDD Inten tional Conference on Kno wl- edge Discov ery in Databases and Data Mining (KDD-01), F. Prov ost and R. Srik ant, eds., ACM Press, 2001, pp. 37–45. [11] W. DuMouchel and D. Pregib on, Empirical Bay es screening for m ulti-item asso ciations, in: Pro ceedings of the ACM SIGKDD Inten tional Confer- ence on Knowledge Disco very in Databases and Data Mining (KDD-01), F. Prov ost and R. Srik ant, eds., A CM Press, 2001, pp. 67–76. [12] R. A. Fisher, The Design of Exp erimen ts, Oliver and Bo yd, Edin burgh, 1935. [13] J. F ¨ urnkranz and P . A. Flach, Ro c ’n’ rule learning – tow ards a b etter understanding of cov ering algorithms, Machine Learning 58 (2005), 39–77. [14] B. Go ethals and M. J. Zaki, Adv ances in frequen t itemset mining imple- men tations: Rep ort on FIMI’03, SIGKDD Explorations 6 (2004), 109–117. [15] M. Hahsler, A mo del-based frequency constraint for mining asso ciations from transaction data, Data Mining and Knowledge Discov ery 13 (2006), 137–166. 21 [16] M. Hahsler, B. Gr¨ un and K. Hornik, arules : Mining Association Rules and F requent Itemsets, 2006, URL http://cran.r- project.org/ , R pack age v ersion 0.4-3. [17] M. Hahsler, K. Hornik and T. Reutterer, Implications of probabilistic data mo deling for mining asso ciation rules, in: F rom Data and Information Anal- ysis to Kno wledge Engineering, Pro ceedings of the 29th Annual Conference of the Gesellschaft f ¨ ur Klassifik ation e.V., Universit y of Magdeburg, Marc h 9–11, 2005, M. Spiliop oulou, R. Kruse, C. Borgelt, A. N¨ urn b erger and W. G aul, eds., Springer-V erlag, 2006, Studies in Classification, Data Anal- ysis, and Knowledge Organization, pp. 598–605. [18] J. Hipp, U. G ¨ untzer and G. Nakhaeizadeh, Algorithms for asso ciation rule mining – A general surv ey and comparison, SIGKDD Explorations 2 (2000), 1–58. [19] J. Hollm´ en, J. K. Sepp¨ anen and H. Mannila, Mixture mo dels and frequen t sets: Combining global and local methods for 0–1 data., in: SIAM In ter- national Conference on Data Mining (SDM’03), San F ransisco, 2003. [20] H. Hruschk a, M. Luk anowicz and C. Buch ta, Cross-category sales promo- tion effects, Journal of Retailing and Consumer Services 6 (1999), 99–105. [21] N. L. Johnson, S. Kotz and A. W. Kemp, Univ ariate Discrete Distributions, John Wiley & Sons, New Y ork, 2nd edition, 1993. [22] E. L. Lehmann, T esting Statistical Hyp otheses, Wiley , New Y ork, first edition, 1959. [23] B. Liu, W. Hsu and Y. Ma, Mining asso ciation rules with m ultiple minimum supp orts, in: Pro ceedings of the fifth ACM SIGKDD international con- ference on Knowledge disco very and data mining (KDD-99), ACM Press, 1999, pp. 337–341. [24] D. P avlo v, H. Mannila and P . Smyth, Beyond indep endence: Probabilistic mo dels for query approximation on binary transaction data, IEEE T rans- actions on Knowledge and Data Engineering 15 (2003), 1409–1421. [25] F. Prov ost and T. F aw cett, Robust classification for imprecise environ- men ts, Machine Learning 42 (2001), 203–231. [26] J. P . Shaffer, Multiple hypothesis testing, Annual Review of Psyc hology 46 (1995), 561–584. [27] C. Silv erstein, S. Brin and R. Motw ani, Beyond market baskets: General- izing asso ciation rules to dep endence rules, Data Mining and Knowledge Disco very 2 (1998), 39–68. [28] H. Xiong, P .-N. T an and V. Kumar, Mining strong affinit y asso ciation patterns in data sets with sk ewed supp ort distribution, in: Pro ceedings of the IEEE International Conference on Data Mining, Nov ember 19–22, 2003, Melb ourne, Florida, B. Go ethals and M. J. Zaki, eds., 2003, pp. 387–394. 22
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment