Flash-LLM: Enabling Low-Cost and Highly-Efficient Large Generative Model Inference With Unstructured Sparsity
With the fast growth of parameter size, it becomes increasingly challenging to deploy large generative models as they typically require large GPU memory consumption and massive computation. Unstructured model pruning has been a common approach to reduce both GPU memory footprint and the overall computation while retaining good model accuracy. However, the existing solutions do not provide an efficient support for handling unstructured sparsity on modern GPUs, especially on the highly-structured tensor core hardware. Therefore, we propose Flash-LLM for enabling low-cost and highly efficient large generative model inference with the sophisticated support of unstructured sparsity on high-performance but highly restrictive tensor cores. Based on our key observation that the main bottleneck of generative model inference is the several skinny matrix multiplications for which tensor cores would be significantly under-utilized due to low computational intensity, we propose a general Load-as-Sparse and Compute-as-Dense methodology for unstructured sparse matrix multiplication (SpMM). The basic insight is to address the significant memory bandwidth bottleneck while tolerating redundant computations that are not critical for end-to-end performance on tensor cores. Based on this, we design an effective software framework for tensor core based unstructured SpMM, leveraging on-chip resources for efficient sparse data extraction and computation/memory-access overlapping. Extensive evaluations demonstrate that (1) at SpMM kernel level, Flash-LLM significantly outperforms the state-of-the-art library, i.e., Sputnik and SparTA by an average of 2.9X and 1.5X, respectively.(2) At end-to-end framework level on OPT-30B/66B/175B models, for tokens per GPU-second , Flash-LLM achieves up to 3.8X and 3.6X improvement over DeepSpeed and FasterTransformer, respectively, with significantly lower inference cost.
💡 Research Summary
Flash‑LLM addresses the growing challenge of deploying large generative language models (LLMs) that demand massive GPU memory and compute resources. While unstructured pruning can reduce both memory footprint and FLOPs with minimal accuracy loss, existing sparse matrix‑multiply (SpMM) libraries are built around SIMT cores and cannot exploit the far higher throughput of tensor cores. Consequently, they often underperform dense cuBLAS kernels until sparsity exceeds 90‑95 %.
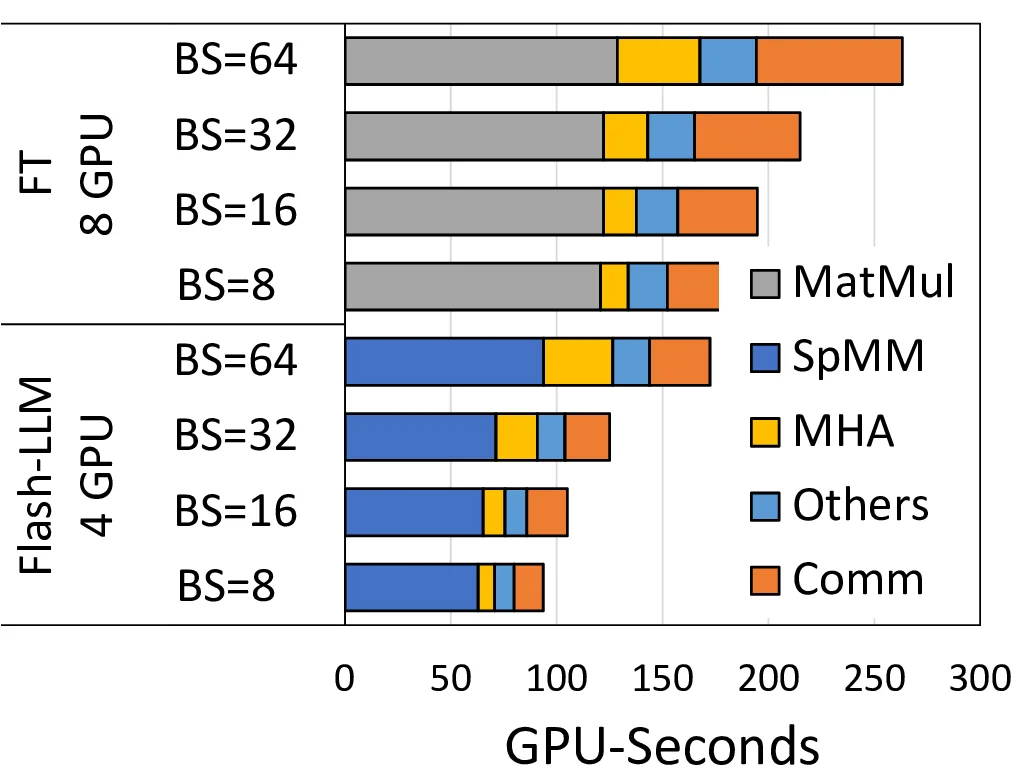
The authors propose a novel “Load‑as‑Sparse, Compute‑as‑Dense” paradigm. Weight matrices are stored and fetched from memory in a sparse format, dramatically cutting memory bandwidth usage. Once on‑chip, the sparse data are transformed into dense tiles that match the 16×16·16 granularity required by tensor‑core WMMA operations. Redundant computations on zero‑filled elements are deliberately tolerated because the dominant bottleneck for the skinny matrix multiplications (M×K × K×N, where N ≪ M, K) is memory bandwidth, not arithmetic capacity. By keeping the tensor cores fully occupied, overall throughput improves despite the extra work.
To realize this idea, Flash‑LLM introduces a new sparse layout called Tiled‑CSL (Compressed Sparse Layout). The weight matrix is partitioned into fixed‑size tiles (e.g., 64×64). Within each tile, non‑zero entries are stored in a CSR‑like structure, enabling efficient on‑chip extraction using registers and shared‑memory buffers. A two‑level overlapping strategy pipelines the workflow: (1) while a weight tile is being loaded and converted, the previous tile’s dense representation is already being fed to the tensor core; (2) simultaneously, the input activation matrix (dense) is streamed into shared memory for the next tensor‑core operation. This overlap hides memory latency and maximizes utilization. An ahead‑of‑time reordering step further reduces shared‑memory bank conflicts, ensuring that the sparse‑to‑dense transformation does not become a new bottleneck.
Flash‑LLM is integrated into the FasterTransformer library, allowing drop‑in replacement for existing dense kernels. Evaluation on OPT‑30B, OPT‑66B, and OPT‑175B models shows that at the kernel level Flash‑LLM outperforms the state‑of‑the‑art sparse libraries Sputnik and SparTA by 2.9× and 1.5× on average, respectively. End‑to‑end, the framework delivers up to 3.8× higher tokens‑per‑GPU‑second compared with DeepSpeed and up to 3.6× versus the original FasterTransformer, while also cutting memory usage by up to 80 %. These gains translate into lower inference cost and the ability to run more model instances on the same hardware.
Key contributions include: (1) the first cost‑effective software stack that brings unstructured sparsity to tensor cores; (2) the Load‑as‑Sparse, Compute‑as‑Dense methodology that trades modest redundant work for substantial bandwidth savings; (3) the Tiled‑CSL format and a two‑level overlapping pipeline that together enable high‑throughput sparse‑to‑dense conversion; and (4) extensive empirical validation across multiple model sizes.
Limitations are acknowledged: the approach assumes moderate to high sparsity (≈80 %) where accuracy remains acceptable; at lower sparsity the extra dense computation may outweigh bandwidth benefits. Moreover, optimal tile sizes and reordering strategies may need retuning for different GPU generations or other accelerator architectures. Future work could explore automatic tuning, support for mixed‑precision accumulation, and extension to other hardware platforms.
Comments & Academic Discussion
Loading comments...
Leave a Comment