Incentivizing Collaboration in Heterogeneous Teams via Common-Pool Resource Games
We consider a team of heterogeneous agents that is collectively responsible for servicing, and subsequently reviewing, a stream of homogeneous tasks. Each agent has an associated mean service time and a mean review time for servicing and reviewing th…
Authors: Piyush Gupta, Shaunak D. Bopardikar, Vaibhav Srivastava
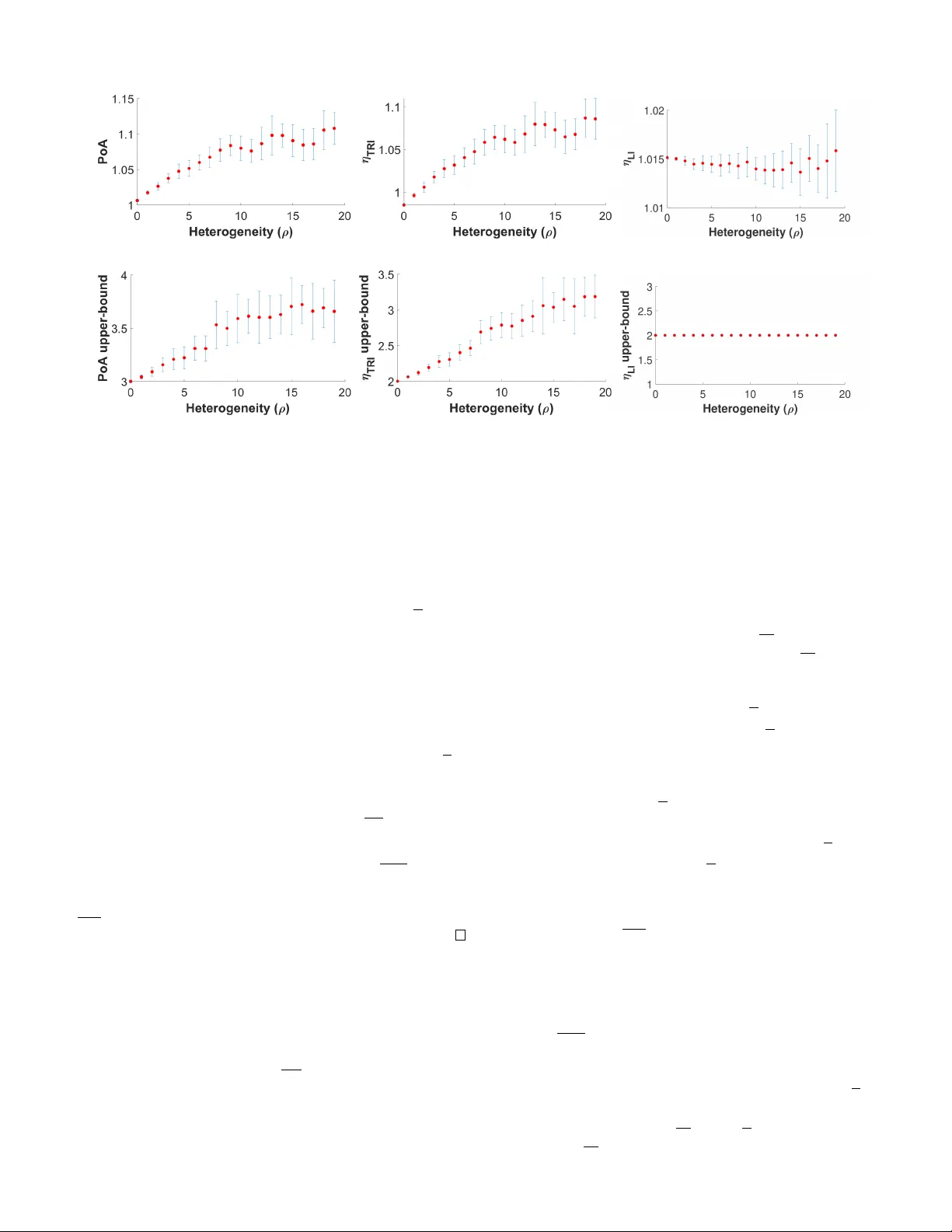
1 Incenti vizing Collaboration in Heterogeneous T eams via Common-Pool Resource Games Piyush Gupta Shaunak D. Bopardikar V aibhav Sri vasta va Abstract —W e consider a team of heter ogeneous agents that is collectively responsible f or servicing, and subsequently reviewing, a stream of homogeneous tasks. Each agent has an associated mean service time and a mean review time for servicing and re viewing the tasks, respectively . Agents receiv e a reward based on their service and re view admission rates. The team objective is to collaboratively maximize the number of “ser viced and re viewed” tasks. W e f ormulate a Common-Pool Resource (CPR) game and design utility functions to incentivize collaboration among heterogeneous agents in a decentralized manner . W e show the existence of a unique Pure Nash Equilibrium (PNE), and establish con vergence of best response dynamics to this unique PNE. Finally , we establish an analytic upper bound on three measures of inefficiency of the PNE, namely the price of anarchy , the ratio of the total re view admission rate, and the ratio of latency , along with an empirical study . Index T erms —Best response potential, CPR game, Price of anarch y , PNE, T eam collaboration, Utility design. I . I N T RO D U C T I O N As we become more connected around the globe, team collaboration becomes a necessity to produce results. Although modern workplaces endea vor to be social and collabora- tiv e aff airs, most workplaces fail to solve the conundrum of achieving efficient collaboration among div erse, dynamic, and dispersed team-members [2]. An effecti ve collaboration requires each team-member to efficiently work on their tasks while backing up other team-members by monitoring and providing feedback. Such team backup behavior improves team performance by mitigating the lack of certain skills in some team-members. Often times, lack of incentives to backup other members results in team-members operating individually and in a poor team performance. Therefore, for effecti ve team performance, it is imperati ve to design appropriate incentives that facilitate collaboration among the agents without affecting their indi vidual performance. Depending on the hierarchical structure, organizations are often distinguished as either mechanistic (bureaucratic), or organic (professional) [3]. While mechanistic org anizations are characterized by a rigid hierarchy , high levels of formalization, and centralized decision making, organic organizations are flexible with weak or multiple hierarchies, and have low lev els of formalization [4]. The flexibility in organic org anizations This work has been supported by NSF A ward IIS-1734272. A preliminary version of this work [1] was presented at the 58th Conference on Decision and Control. W e expand on our work in [1] by providing detailed proofs and analytic upper bound on the measures of inefficienc y for the unique PNE. Piyush Gupta (guptapi1@msu.edu), Shaunak D. Bopardikar (shau- nak@egr .msu.edu) and V aibhav Sriv astava (vaibhav@e gr .msu.edu) are with Department of Electrical and Computer Engineering, Michigan State Uni ver- sity , East Lansing, Michigan, 48824, USA. leads to decentralized decision-making, and therefore, enables quick and easy reaction to changes in the en vironment. Hence, organic organizations cope best with the unpredictable and unstable en vironments that surrounds them, as compared to mechanistic or ganizations which are appropriate in stable en vironments and for routine tasks. For organic organizations, which lack centralized decision-making authority , it is essen- tial to incentivize collaboration among heterogeneous team- members to achieve efficient team performance. CPR games [5, 6] is a class of resource sharing games in which players jointly manage a common pool of resource and make strategic decisions to maximize their utilities. In this paper , we design incenti ves for the heterogeneous agents to facilitate aforementioned team backup behavior . In particular , we connect the class of problems in volving human-team- supervised autonomy [7] with the CPR games, and design utilities that yield the desired behavior . W ithin the queueing theory paradigm that has been used to study these prob- lems [8–10], we show that CPR games provide a formal framew ork to analyze and design organic teams. Specifically , utilizing the CPR framew ork allows us to incenti vize team collaboration among heterogeneous agents in a decentralized manner , i.e., efficient social utility is achiev ed despite self- interested actions of the individuals. Game-theoretic approaches hav e been utilized for problems in distributed control [11], wherein the overall system is driv en to an efficient equilibrium strategy that is close to the social optimum through an appropriate design of utility functions [12]. Price of Anarchy (PoA) [13] is often used to characterize efficienc y of the equilibrium strategies in a game. Associated analysis techniques utilize smoothness property of the utility functions [14], lev erage submodularity of the welfare function [15], or solve an auxiliary optimization problem [16, 17]. These approaches do not immediately apply to our setup. Instead, we follo w a ne w line of analysis to obtain bounds on PoA by constructing a homogeneous CPR game, for which we show that the equilibrium strategy is also the social optimum (PoA=1), and relating its utility to the original game. Human-team-supervised autonomy is a class of motiv ating problems for our setup. Queueing theory has emerged as a popular paradigm to study these problems [8 – 10]. Howe ver , these works predominantly consider a single human operator . There ha ve been limited studies on human-team-supervised autonomy . These include simulation based studies [18], ad hoc design [19], or non-interacting operators [20]. Here, we focus on a game-theoretic approach to study one of the ke y features of the human-team-supervised autonomy: the team backup behavior , which refers to the extent to which team- 2 members help each other perform their roles [21]. W e model team backup behavior in the follo wing way . W e consider an unlimited supply of tasks from which each team- member may admit tasks for servicing at a constant rate. W e assume that each serviced task is stored in a common re view pool for a second revie w . Each team-member can choose to spend a fraction of their time to re view tasks from the common re view pool and thereby provide a backup. In our setup, any agent can revie w tasks from the common revie w pool, independent of who serviced the task. Therefore, an y agent that services tasks can also participate in the revie w process without impacting the quality of revie w process. This is sensible in scenarios in which, for example, the revie w process in volves performing a quality check using machines or verification through software. W ithout any incenti ves, mem- bers may not choose to revie w the tasks as it may affect their individual performance. W e focus on design of incentives, within the CPR game formalism, to facilitate team backup behavior . While we use human-team-supervised autonomy as a mo- tiv ating example, our problem formulation can be applied to broad range of problems inv olving tandem queues [22], where servicing and re viewing of tasks can be considered as the subsequent stages of the queueing-network. T andem queues are utilized to design efficient systems to study problems such as resource allocation, inv entory management, process optimization, and quality control [23]. Existing game theo- retic approaches [24, 25] to service rate control in tandem queues assume that a single server is present at each stage of the tandem queue and each server has its independent resources. In contrast, in our setup, multiple heterogeneous agents allocate their time at different stations based on their skill-sets and maximize the system throughput. Additionally , our mathematical techniques are applicable to many problems in volving dual-screening process. For example, in human-in- the-loop systems which are pervasi ve in areas such as search- and-rescue, semi-autonomous vehicle systems, surveillance, etc., humans often supervise (revie w) the actions (service) performed by the autonomous agents. In such settings, our framew ork incentivizes collaboration among heterogeneous agents. Our CPR formulation has features similar to the CPR game studied in [6, 26]. In these works, authors utilize prospect theory to capture the risk a version beha vior of the players in vesting into a fragile CPR [27] that fails if there is excessi ve in vestment in the CPR. In the case of CPR failure, no player receiv es any return from the CPR. While our design of the common revie w pool is similar to the fragile CPR, our failure model incorporates the constraint that only serviced tasks can be revie wed. In contrast to the agent heterogeneity due to prospect-theoretic risk preferences in [6], heterogeneity in our model arises due to differences in the agents’ mean service and re view times. The major contributions of this work are fiv efold. First, we present a nov el formulation of team backup behavior and design incenti ves, within the CPR game formalism, to f acilitate such behavior (Section II). Second, we show that there exists a unique PNE for the proposed game (Section III). Third, we Fig. 1 : Player i de votes her time to service homogeneous tasks (at a constant service admission rate λ S i ) while reviewing serviced tasks from the common revie w pool (at a constant review admission rate λ R i ). The maximum admission rate for player i for servicing and re viewing the tasks is giv en by µ S i and µ R i , respecti vely . show that the proposed game is a best response potential game as defined in [28], for which both sequential best response dynamics [29] and simultaneous best reply dynamics [30] con verge to the PNE (Section IV). Thus, the best response of self-interested agents in a decentralized team con ver ge to the PNE. Fourth, we provide the structure of the social welfare solution (Section V) and numerically quantify (Section VI) different measures of the inefficienc y for the PNE, namely the PoA, the ratio of the total revie w admission rate (TRI), and the ratio of latency (LI), as a function of a measure of heterogeneity . While PoA is a widely used inefficienc y metric, we define TRI and LI as other relev ant measures for our setup based on the total re view admission rate and latenc y (in verse of throughput), respecti vely . Finally , we pro vide an analytic upper bound for all three measures of the inef ficiency (Section V). I I . B AC K G R OU N D A N D P R O B L E M F O R M U L AT I O N In this section, we describe the problem setup and formu- late the problem using a game-theoretic framework. W e also present some definitions that will be used in the paper . A. Pr oblem Description W e consider a heterogeneous team of N ∈ N agents tasked with servicing a stream of homogeneous tasks. These agents could be autonomous systems or human operators. Each task, after getting serviced by a team-member, gets stored in a common revie w pool for a second revie w . This second revie w is a feedback process in which any team-member can re- examine the serviced task from the common revie w pool for performance monitoring and quality assurance purposes. Each agent i ∈ N = { 1 , . . . , N } may choose to spend a portion of her time to revie w the tasks from the common pool while spending her remaining time to service the incoming tasks. W e consider heterogeneity among the operators due to the difference in their lev el of expertise and skill-sets in servicing and revie wing the tasks. This heterogeneity is captured by the av erage service time ( µ S i ) − 1 ∈ R > 0 and av erage revie w time ( µ R i ) − 1 ∈ R > 0 spent by operator i ∈ N on servicing and revie wing a task, respecti vely . Let λ S i ∈ [0 , µ S i ] and λ R i ∈ [0 , µ R i ] be the deterministic service and revie w admission rates, i.e., the rates at which 3 agent i chooses to admit tasks for servicing and revie wing, respectiv ely . Each agent i can choose their service and revie w admission rate independent of other agents. The range of λ S i and λ R i hav e been chosen to satisfy the stability conditions (including mar ginal stability) for the service and re view queues for operator i ∈ N [31, Chapter 8]. Suppose agent i selects λ S i and λ R i as their service and revie w admission rates, then λ S i µ S i + λ R i µ R i ≤ 1 , where λ S i µ S i (respectiv ely , λ R i µ R i ) is the av erage time the agent spends on servicing (respectively , re viewing) the tasks within a unit time. Thus, if the agent has selected a revie w admission rate λ R i , then the service admission rate satisfies λ S i ≤ µ S i − h i λ R i , (1) where h i := µ S i µ R i is the heterogeneity measure for the player i . W e consider self-interested agents that receive a utility based on their service and revie w admission rates. Hence, we will assume that agents operate at their maximum capacity , and equality holds in (1). Fig. 1 shows the schematic of our problem setup. Note that only serviced tasks are av ailable for revie w , and therefore, N X i =1 λ R i ≤ N X i =1 λ S i . (2) By substituting (1) in (2), we obtain, N X i =1 a i λ R i ≤ N X i =1 µ S i , (3) where a i := (1 + h i ) . Eq. (3) represents the system constraint on the revie w admission rates chosen by agents. W e are interested in incentivizing collaboration among the agents for the better team performance. T owards this end, we propose a game-theoretic setup defined below . B. A Common-P ool Resour ce Game F ormulation W e now formulate our problem as a Common-Pool Re- source (CPR) game. Henceforth, we would refer to each agent as a player . A maximum service admission rate µ S i and a maximum revie w admission rate µ R i are associated with each player i , based on her skill-set and lev el of expertise. W ithout loss of generality , let the players be labeled in increasing order of their heterogeneity measures, i.e., h 1 ≤ · · · ≤ h N . Let S i := [0 , µ R i ] be the strate gy set for each player i , from which the player chooses her revie w admission rate for revie wing the tasks from the common revie w pool. Since we hav e assumed (1) holds with equality , once player i decides her re view admission rate λ R i ∈ S i , her service admission rate for servicing the tasks λ S i is giv en by the right hand side of (1). Let S = Q i ∈N S i be the joint strategy space of all the players, where Q denotes the Cartesian product. Furthermore, we define S − i = Q j ∈N ,j 6 = i S j as the joint strategy space of all the players except player i . For bre vity of notation, we denote the total service admis- sion rate and the total revie w admission rate by λ S T = P N i =1 λ S i and λ R T = P N i =1 λ R i , respectiv ely . Similarly , µ S T = P N i =1 µ S i and µ R T = P N i =1 µ R i denote the aggregated sum of the maxi- mum service admission rates and maximum revie w admission rates of all the players, respectiv ely . Let x ∈ R , defined by x = λ S T − λ R T = µ S T − N X i =1 a i λ R i , (4) be the slackness parameter for system constraint (3). The constraint (3) is violated for negati ve v alues of x , i.e., when total re view rate exceeds the total service rate. In such an ev ent, some players commit to revie w more tasks than that are av ailable in the common re view pool. The slackness parameter characterizes the gap between the total service admission rate and the total revie w admission rate for all the players. In order to maximize high quality team throughput, i.e., the number of tasks that are both serviced and revie wed, we seek to incentivize the team to operate close to x = 0 . Each player i receiv es a constant reward r S ∈ R > 0 for servicing each task. Hence, the service utility u S i : S i 7→ R > 0 for player i servicing the tasks at the service admission rate λ S i is gi ven by: u S i = λ S i r S . (5) T o incentivize collaboration among the agents, we design the revie w utility u R i : S 7→ R > 0 receiv ed for revie wing the tasks from the common revie w pool using two functions: a rate of return, r R : S 7→ R > 0 for each revie wed task and a constraint probability p : S 7→ [0 , 1] of the common revie w pool. The constraint probability p is a soft penalty on the violation of system constraint (3). W e model the rate of return r R and the constraint probability p in terms of the strategy of all the players through slackness parameter x . Furthermore, we assume that r R is strictly decreasing in x . Therefore, for each x ∈ [0 , µ S T ] , system constraint (3) is satisfied, and the rate of return is maximized at x = 0 . The rate of return can be interpreted as the perks that the employer provides to all the employees for high quality service. For example, an employer generates higher rev enue based on the high quality throughput of her compan y , i.e., based on the number of “serviced and re viewed” tasks, which she redistrib utes among her employees as perks as per their contribution to the revie w process. Highest quality throughput is achiev ed by the company when the team efficiently revie ws all the serviced tasks, i.e., when x = 0 . W e introduce the constraint probability p as a soft penalty of the violation of system constraint (3), and therefore, we let p = 1 if the constraint gets violated, i.e. when x < 0 . W e assume that the constraint probability p is non-increasing in x , and approaches 1 as x approaches 0 . The class of sharply decreasing exponential functions, p ( λ R i , λ R − i ) = exp( − Ax ) , where x ∈ [0 , µ S T ] and A ∈ R > 0 , can be a good choice to effecti vely model the system constraint. If the constraint is 4 violated with probability p , then u R i = 0 for each player i . Therefore, we define the utility u R i by u R i ( λ R i , λ R − i ) = ( 0 , with probability p ( λ R i , λ R − i ) , λ R i r R ( λ R i , λ R − i ) , otherwise . (6) Let u i ( λ R i , λ R − i ) = u S i + u R i be the total utility of player i ∈ N . Each player i tries to maximize her expected utility ˜ u i : S 7→ R defined by ˜ u i ( λ R i , λ R − i ) = E [ u S i ( λ R i , λ R − i ) + u R i ( λ R i , λ R − i )] = λ S i r S + λ R i r R ( λ R i , λ R − i )(1 − p ( λ R i , λ R − i )) , (7) where the expectation is computed over the constraint prob- ability p . Since r R and p depend on the re view admission rates of all the players only through the slackness parameter x , with a slight ab use of notation, we express r R ( λ R i , λ R − i ) and p ( λ R i , λ R − i ) by r R ( x ) and p ( x ) , respecti vely . Substituting (1) in (7), we get: ˜ u i = µ S i r S + λ R i r R ( x )(1 − p ( x )) − h i r S =: µ S i r S + λ R i f i ( x ) , (8) where f i : S 7→ R is defined by f i ( λ R i , λ R − i ) = f i ( x ) = r R ( x )(1 − p ( x )) − h i r S . (9) The function f i is the incentiv e for player i to re view the tasks. Note that player i will choose a non-zero λ R i if and only if she has a positiv e incentiv e to re view the tasks, i.e., f i ( x ) > 0 . Otherwise, player i drops out without revie wing any task ( λ R i = 0 ) and focuses solely on servicing of tasks ( λ S i = µ S i ), thereby maximizing her expected utility given by ˜ u i = µ S i r S . In the following, we will refer to the above CPR game by Γ = ( N , { S i } i ∈N , { ˜ u i } i ∈N ) . In this paper , we are interested in equilibrium strategies for the players that constitute a PNE defined belo w . Definition 1 ( Pure Nash Equilibrium ) . A PNE is a strate gy pr ofile λ R ∗ = { λ R i ∗ } i ∈N ∈ S , such that for each player i ∈ N , ˜ u i ( λ R i ∗ , λ R − i ∗ ) ≥ ˜ u i ( λ R i , λ R − i ∗ ) , for any λ R i ∈ S i . Let b i : S − i 7→ S i defined by b i ( λ R − i ) ∈ argmax λ R i ∈ S i ˜ u i ( λ R i , λ R − i ) , be a best r esponse of player i to the revie w admission rates of other players λ R − i . A PNE exists if and only if there exists an in variant strategy profile, λ R ∗ = { λ R i ∗ } i ∈N ∈ S , such that λ R i ∗ = b i ( λ R − i ∗ ) , for each i ∈ N . I I I . E X I S T E N C E A N D U N I Q U E N E S S O F P N E In this section, we study the existence and uniqueness of the PNE for the CPR game Γ under the system constraint (3). Each player i ∈ N chooses a revie w admission rate from her strategy set S i = [0 , µ R i ] and receiv es an expected utility ˜ u i (a) (b) (c) Fig. 2 : Constraint probability of player i as λ R i varies from 0 to µ R i . a) For λ R i = 0 , p i ( λ R i , · ) = 1 , ∀ λ R i ∈ S i , b) for λ R i ∈ (0 , µ R i ) , p i ( λ R i , · ) is con vex for λ R i ∈ [0 , λ R i ) , with p i ( λ R i , · ) 7→ 1 as λ R i 7→ λ R i , and p i ( λ R i , · ) = 1 , ∀ λ R i ∈ [ λ R i , µ R i ] , and c) for λ R i = µ R i , p i ( λ R i , · ) is con vex in λ R i and p i ( λ R i , · ) < 1 , ∀ λ R i ∈ S i . giv en by (8). For any giv en λ R − i ∈ S − i , we obtain an upper bound λ R i : S − i 7→ S i on λ R i defined by λ R i = 0 , if Λ i < 0 , Λ i , if 0 ≤ Λ i ≤ µ R i , µ R i , if Λ i > µ R i , where Λ i := µ S T − P j ∈N ,j 6 = i a j λ R j a i , such that for λ R i ∈ [0 , λ R i ) ⊂ S i , constraint (3) is automatically satisfied, and for λ R i ∈ ( λ R i , µ R i ] ⊂ S i , constraint (3) is violated. F or λ R i = λ R i , constraint (3) is satisfied if λ R i ∈ (0 , µ R i ] , and is violated if λ R i = 0 . W e study the properties of game Γ under following assump- tions. Recall that x = λ S T − λ R T = µ S T − P N i =1 a i λ R i . (A1) For a gi ven λ R − i ∈ S − i , i ∈ N , we assume that the rate of return r R ( λ R i , · ) for revie wing the tasks is continuously differentiable, strictly increasing and strictly concave for λ R i ∈ S i , with r R (0 , 0) = 0 . Equiv alently , x 7→ r R ( x ) is continuously differentiable, strictly decreasing and strictly conca ve for x ∈ [0 , µ S T ] , with r R ( µ S T ) = 0 . (A2) For a giv en λ R − i ∈ S − i , i ∈ N , we assume that the constraint probability p ( λ R i , · ) is (i) continuous on S i ; (ii) is continuously dif ferentiable, non-decreasing and con vex for λ R i ∈ (0 , λ R i ) ⊂ S i ; and (iii) is equal to 1 , for λ R i ∈ ( λ R i , µ R i ] . See Fig. 2 for an illustration. Equiv alently , p ( x ) is continuously differentiable, non- increasing and con vex for x ∈ (0 , µ S T ] , and p ( x ) → 1 , as x → 0 . Furthermore, p = 1 , for ev ery x < 0 . (A3) W e assume f i ( µ R i , 0) = r R ( µ R i , 0)(1 − p ( µ R i , 0)) − h i r S > 0 , for each i ∈ N , i.e., if no other player revie ws any task, then each player i has a positiv e incentiv e to revie w tasks with maximum admission rate µ R i . Remark 1. The rate of return r R and the constraint pr obabil- ity p can be easily designed to accommodate (A1-A3). Under Assumptions (A1) and (A2), the incentive function f i ( λ R i , · ) is strictly concave in λ R i , which means for a fixed λ R − i , the player i has diminishing mar ginal incentive to r eview tasks. W e make Assumption (A3) to pr ovide positive incentives for players to r eview tasks with their maximum r eview admission rate µ R i , if no other player chooses to re view any task. W e can design game Γ to satisfy Assumption (A3) by ensuring that the following conditions hold: (i) r R ( µ R i , 0) > r S , and µ S i ≤ µ R i , for each i ∈ N , and 5 (ii) µ R i µ S T /a i , or equivalently P j ∈N , j 6 = i µ S j µ R i , for each i ∈ N . If the latter condition holds, then x is lar ge, and conse- quently , the constraint pr obability p ( µ R i , 0) ≈ 0 , for each i ∈ N . F or most practical purposes, servicing a task requir es mor e time than r evie wing it, i.e., µ S i ≤ µ R i . Ther efore , condition (i) can be easily satisfied by designing re war ds such that r R ( µ R i , 0) > r S , for each i ∈ N . If the total service admission rate of all the players except player i is much higher than the maximum r eview admission rate of player i , i.e. P j ∈N , j 6 = i µ S j µ R i , for each i ∈ N , then condition (ii) holds. Notice that for a larg e team of agents wher e a single agent does not have much impact on the overall service rate , condition (ii) is true. W e refer the reader to Section VI for an example . Theorem 1 ( Existence of PNE ) . The CPR game Γ , under Assumptions (A1-A3), admits a PNE. Pr oof. See Appendix A for the proof. Let f 0 i ( λ R i , λ R − i ) be the first partial deriv ativ e of f i ( λ R i , λ R − i ) with respect to λ R i . W e now provide a corollary that charac- terizes a PNE of CPR game Γ . Corollary 1 ( PNE ) . F or the CPR game Γ , under Assumptions (A1-A3), the following statements hold for a PNE λ R ∗ = [ λ R ∗ 1 , . . . , λ R ∗ N ] with x ∗ = µ S T − P N i =1 a i λ R ∗ i : (i) f 0 i ( λ R ∗ i , λ R ∗ − i ) < 0 (or d f i dx ( x ∗ ) > 0 ) for every player; (ii) λ R ∗ i = 0 , if and only if, f i ( λ R ∗ i , λ R ∗ − i ) ≤ 0 ; and (iii) λ R ∗ i is non-zer o and satisfies the following implicit equation if and only if f i ( λ R ∗ i , λ R ∗ − i ) = f i ( x ∗ ) > 0 at PNE, wher e λ R ∗ i = min ˜ λ R ∗ i , µ R i , (10) with ˜ λ R ∗ i = − f i ( λ R ∗ i ,λ R ∗ − i ) f 0 i ( λ R ∗ i ,λ R ∗ − i ) = f i ( x ∗ ) a i d f i dx ( x ∗ ) . Pr oof. See Appendix B for the proof. Proposition 1 ( Structure of PNE ) . F or the CPR game Γ with players order ed in incr easing or der of h i , let λ R ∗ = [ λ R ∗ 1 , λ R ∗ 2 , . . . , λ R ∗ N ] be a PNE. Then, the following statements hold: (i) If, for any player k 1 , λ R ∗ k 1 < µ R k 1 , then a k 1 λ R ∗ k 1 ≥ a k 2 λ R ∗ k 2 and λ R ∗ k 1 ≥ λ R ∗ k 2 , for each k 2 > k 1 ; and (ii) if λ R ∗ l = 0 , for any l ∈ N , then λ R i = 0 , for each i ∈ { j ∈ N | j ≥ l } . Pr oof. See Appendix C for the proof. It follo ws from Proposition 1 that the revie w admission rate of a player i at a PNE is monotonically decreasing with the ratio h i . Therefore, at a PNE, as the heterogeneity in terms of h i among the players becomes very large, players with small (respectiv ely , large) h i revie w tasks with high (respectively , zero) re view admission rate. W e will show in Lemma 2 that the PNE shares these characteristics with the social welfare solution, which we define in Section V. W e illustrate this further in Section VI. Theorem 2 ( Uniqueness of PNE ) . The PNE admitted by the CPR game Γ , under assumptions (A1-A3), is unique. Pr oof. See Appendix D for the proof. I V . C O N V E R G E N C E T O T H E N A S H E Q U I L I B R I U M W e now show that the proposed CPR game Γ under As- sumptions (A1-A3) belong to the class of Quasi Aggre gative games [32] as defined below . Definition 2 ( Quasi Aggregative game ) . Consider a set of players N , wher e each player i ∈ N has a strate gy set S i , and a utility function u i . Let S = Q i ∈N S i be the joint strate gy space of all the players, and S − i = Q j ∈N ,j 6 = i S j be the joint strate gy space of all the players except player i . A game Γ = ( N , { S i } i ∈N , { u i } i ∈N ) is a quasi-aggr e gative game with aggr e gator g : S 7→ R , if ther e exists continuous functions F i : R × S i 7→ R (the shift functions) and σ i : S − i 7→ X − i ⊆ R , i ∈ N (the interaction functions) such that the utility functions u i for each player i ∈ N can be written as: u i ( s ) = ˜ u i ( σ i ( s − i ) , s i ) , (11) wher e ˜ u i : X − i × S i 7→ R , and g ( s ) = F i ( σ i ( s − i ) , s i ) , for all s ∈ S and i ∈ N . (12) An alternative, but less gener al way of defining a quasi- aggr e gative game replaces (11) in the definition with: u i ( s ) = u i ( g ( s ) , s i ) , (13) wher e u i : X × S i 7→ R , and X = { g ( s ) | s ∈ S } ⊆ R . For the CPR game Γ , let σ i ( λ R − i ) = P N j =1 ,j 6 = i a j λ R j and g ( λ R ) = F i ( σ i ( λ R − i ) , λ R i ) = P N j =1 ,j 6 = i a j λ R j + a i λ R i be the interaction functions and shift functions, respectiv ely . The expected utility ˜ u i , which is defined in (8), can be re-written in the form ˜ u i ( λ R i , λ R − i ) = ˜ u i ( σ i ( λ R − i ) , λ R i ) . (14) Hence, the CPR game Γ is a quasi-aggreg ativ e game. Specializing [32, Theorem 1] to the CPR game Γ , we obtain that if the best response for all the players is non-increasing in the interaction function σ i ( λ R − i ) = P N j =1 ,j 6 = i a j λ R j , the CPR game Γ is a best response pseudo-potential game [33] as defined belo w . Definition 3 ( Best response (pseudo)-potential game ) . A game Γ = ( N , { S i } i ∈N , { ˜ u i } i ∈N ) is a best response pseudo- potential game if there exists a continuous function φ : S 7→ R such that for every i ∈ N , b i ( λ R − i ) ⊇ argmax λ R i ∈ S i φ ( λ R i , λ R − i ) , wher e b i ( λ R − i ) is the best r esponse of player i to the r eview admission of other players λ R − i . Furthermor e, if b i ( λ R − i ) = argmax λ R i ∈ S i φ ( λ R i , λ R − i ) , 6 then the game Γ is a best r esponse potential game. W e no w establish that the best response for each player is non-increasing in σ i . Lemma 1 ( Non-increasing best response ) . F or the CPR game Γ , under Assumptions (A1-A2), the best r esponse mapping b i ( λ R − i ) is non-increasing in σ i ( λ R − i ) , for each i ∈ N , where σ i ( λ R − i ) = P N j =1 ,j 6 = i a j λ R j . Pr oof. See Appendix E for the proof. Furthermore, Remark 1 in [29] states that a best response pseudo-potential game with a unique best response, is an instance of best response potential game [28]. Therefore, the CPR game Γ , with its unique (Lemma 4) and non-increasing best response b i in σ i ( λ R − i ) (Lemma 1), is a best response potential game. Hence, simple best response dynamics such as sequential best response dynamics [29] and simultaneous best response dynamics [30] con verge to the unique PNE. V . S O C I A L W E L FA R E A N D I N E FFI C I E N C Y O F P N E In this section, we characterize the social welfare solution and provide analytic upper bounds on inefficienc y measures for the PNE. A. Social W elfar e Social welfare corresponds to the optimal (centralized) allocation by players with respect to a social welfare function. T o characterize the effect of self-interested optimization of each agent, we compare the decentralized solution (PNE of the CPR game) with the centralized optimal solution (social welfare). W e choose a typical social welfare function Ψ( λ R ) : S 7→ R defined by the sum of expected utility of all players, i.e., Ψ = N X i =1 ˜ u i = N X i =1 [ µ S i r S + λ R i f i ( x )] = µ S T r S + λ R T r R ( x )(1 − p ( x )) − r S N X i =1 h i λ R i = ( λ R T + x ) r S + λ R T r R ( x )(1 − p ( x )) . (15) A social welfar e solution is an optimal allocation that maximizes the social welfare function. Lemma 2 ( Social welfare solution ) . F or the CPR game Γ with constraint P N i =1 a i λ R i = c , for any given c ∈ R ≥ 0 , and players or dered in incr easing or der of h i , the associated social welfar e solution, λ R ∈ S is given by: λ R = " µ R 1 , µ R 2 , . . . , µ R k − 1 , 1 a k ( c − k − 1 X i =1 a i µ R i ) , 0 , . . . , 0 # , wher e k is the smallest index such that P k − 1 i =1 a i µ R i ≤ c < P k i =1 a i µ R i . Furthermor e, since P N i =1 a i λ R i ∈ [0 , µ S T + µ R T ] , a bisection algorithm can be employed to compute optimal c and hence, the optimal social welfar e solution. Pr oof. Under the constraint P N i =1 a i λ R i = c (equiv alently , x = µ S T − c ), Ψ is a strictly increasing function of λ R T . Therefore, for a fixed P N i =1 a i λ R i = c , λ R T is maximized by selecting k − 1 players with smallest a i ’ s (equi valently , h i ) to operate at their highest revie w admission rate, where the value of k is selected such that P k − 1 i =1 a i µ R i ≤ c < P k i =1 a i µ R i . Finally , the k -th player in the ordered sequence is selected to operate at a revie w admission rate such that the constraint P N i =1 a i λ R i = P k i =1 a i λ R i = c , is satisfied. Therefore, the social welfare solution is of the form, λ R = " µ R 1 , µ R 2 , . . . , µ R k − 1 , 1 a k ( c − k − 1 X i =1 a i µ R i ) , 0 , . . . , 0 # . Furthermore, for the function r R ( x ) and p ( x ) satisfying Assumptions (A1-A2), Ψ is strictly concave in x , i.e., ∂ 2 Ψ ∂ x 2 = λ R T d 2 f i dx 2 < 0 (Lemma 3). With the kno wn form of the social welfare solution, the value of c , which corresponds to the unique maximizer x of Ψ , can be computed efficiently by employing a bisection algorithm [34]. B. Inefficiency of the PNE W e consider three measures of the inefficienc y for the PNE: a) Price of Anarchy (PoA), b) Ratio of total revie w admission rate ( η T RI ), and c) Ratio of Latency ( η LI ), which are described by P oA = (Ψ) S W (Ψ) P N E , η T RI = ( λ R T ) S W ( λ R T ) P N E , η LI = ( P N i =1 a i λ R i ) P N E ( P N i =1 a i λ R i ) S W , respectiv ely . While PoA is a widely used measure of the inefficienc y , η T RI and η LI capture the inefficienc y of the PNE based on the total re view admission rate and the latency (in verse of throughput), respectively . Since incentivizing team collaboration is of interest, all three measures capture the inefficienc y of the PNE well. W e no w provide an analytic upper bound for each of these measures of inefficiency for the PNE. T o this end, we assume that min i { µ S i } > µ S T h N N (1+ h N ) . For scenarios wherein servicing a task requires much more time than re viewing it, i.e., µ S N µ R N ( h N → 0 ), the assumption reduces to min i { µ S i } > 0 . Theorem 3 ( Analytic bounds on PNE inefficiency ) . F or the CPR game Γ , under assumptions (A1-A3), and min i { µ S i } > µ S T h N N (1+ h N ) , the inefficiency metrics for the PNE are upper bounded by P oA < µ S T a N µ S T − x , η T RI < µ S T a N ( µ S T − x ) a 1 , η LI < µ S T µ S T − x , (16) wher e x is the unique maximizer of f i , i.e., d f i dx ( x ) = 0 . Pr oof. See Appendix F for the proof. Example 1: W e sho w analytic upper bounds on inefficienc y measures for the PNE for a specific class of exponential func- tions r R ( x ) = A [1 − exp { B ( x − µ S T ) } ] and p ( x ) = exp( − B x ) , where A and B are positi ve constants, and x ∈ [0 , µ S T ] . Setting d f i dx ( x ) = 0 , we obtain x = µ S T 2 . Using Theorem 3, we get PoA < 2 a N , η T RI < 2 a N a 1 , and η LI < 2 . For µ S N µ R N , PoA < 2 a N → 2 , and η T RI < 2 a N a 1 < 2 a N → 2 . 7 (a) (b) Fig. 3 : Social welfare solution (SW) and pure Nash equilibrium for a) low and b) high heterogeneity among players, respectiv ely . Red circles show the maximum re view admission rate ( µ R i ) for player i . V I . N U M E R I C A L I L L U S T R A T I O N S In this section, we present numerical examples illustrating the uniqueness of PNE and the variation of inef ficiency with increasing heterogeneity among the players. In our numerical illustrations, we obtain the PNE by simulating the sequential best response dynamics of players with randomized initialization of their strategy . W e verify the uniqueness of the PNE for different choices of functions, r R ( x ) and p ( x ) satisfying Assumptions (A1-A2), and by following sequential best response dynamics with multiple random initializations for the strategy of each player . Further- more, in our numerical simulations, we relax Assumption (A3) and still obtain a unique PNE. An example illustration is shown in Fig. 3, where we show the social welfare solution (obtained using fmincon in MA TLAB) and PNE for low and high heterogeneity in terms of variation in h i among players, respectiv ely . For our numerical illustrations, we choose the number of players, N = 6 , and choose the functions r R ( x ) and p ( x ) , satisfying Assumptions (A1-A2) as following: r R ( λ R i , λ R − i ) = r R ( x ) = 5[1 − exp { 0 . 5( x − µ S T ) } ] , p R i ( λ R i , λ R − i ) = p ( x ) = ( 1 , if x ≤ 0 , exp( − 0 . 5 x ) , otherwise , where x = µ S T − P N i =1 a i λ R i is the slackness parameter . T o characterize the heterogeneity among the players, we sample the player’ s maximum service admission rate µ S i and maximum revie w admission rate µ R i at random from normal distributions with fixed means, M µ S ∈ R > 0 , and M µ R ∈ R > 0 , and identical standard de viation, ρ ∈ R > 0 . W e only consider realizations that satisfy µ S i ≤ µ R i for all the players, and hence, h i ≤ 1 . For most practical purposes, where servicing a task requires much more time than re viewing it, the assumption µ S i ≤ µ R i holds true. Any non-positive realizations were dis- carded. W e consider the standard deviation of the distrib utions as the measure of heterogeneity among the players. Fig. 3 shows that in the social welfare solution, players with low ratio of h i revie w the tasks at maximum revie w admission rate and players with high ratio of h i drop out of the game. At PNE, the strategy profile of players follow the characteristics described by Proposition 1. Lastly , with the increase in heterogeneity among the players, the PNE starts to approach the social welfare solution. Fig. 4a-4c and Fig. 4d-4f sho ws the v ariation of different measures of inef ficiency for PNE, and their corresponding analytic upper bounds (see Theorem 3), with increasing hetero- geneity among the players. Fig. 4a shows the plot of PoA with increasing heterogeneity . In case of homogeneous players, i.e., ρ = 0 , we obtain P oA = 1 , which we establish in Lemma 7. As we initially increase the heterogeneity among the players, PNE starts to deviate from the social welfare solution, resulting in an increase in the PoA. W e note that PoA ≤ 1 . 15 , suggesting that the unique PNE is close to the optimal centralized social welfare solution. Fig. 4b and 4c sho ws η T RI and η LI , which are other relev ant measures of inef ficiency for our problem. It is evident from Fig. 4, that all three measures of inef ficiency are close to 1 , therefore suggesting near -optimal PNE solution. V I I . C O N C L U S I O N S A N D F U T U R E D I R E C T I O N S W e studied incentive design mechanisms to facilitate collab- oration in a team of heterogeneous agents that is collectively responsible for servicing and subsequently revie wing a stream of homogeneous tasks. The heterogeneity among the agents is based on their skill-sets and is characterized by their mean service time and mean re view time. T o incentivize collabo- ration in the heterogeneous team, we designed a Common- Pool Resource (CPR) g ame with appropriate utilities and showed the existence of a unique PNE. W e showed that the proposed CPR game is an instance of the best response potential game and by playing the sequential best response against each other , players con verge to the unique PNE. W e characterized the structure of the PNE and showed that at the PNE, the revie w admission rate of the players decreases with the increasing ratio of h i = µ S i µ R i , i.e., the re view admission rate is higher for the players that are “better” at revie wing the tasks than servicing the tasks (characterized by their av erage service and revie w time). Furthermore, we consider three different inefficienc y metrics for the PNE, including the Price of Anarchy (PoA), and provide an analytic upper bound for each metric. Additionally , we provide numerical evidence of their proximity to unity , i.e., the unique PNE is close to the optimal centralized social welfare solution. There are sev eral possible av enues of future research. It is of interest to extend the results for a broader class of games with less restricti ve choice of utility functions, i.e., games that are not quasi-aggregati ve or commonly used games of weak strategic substitutes (WSTS) [29] or complements (WSTC) [29]. An interesting open problem is to consider a team of agents processing stream of heterogeneous tasks. In such a setting, incentivizing team collaboration based on the task-dependent skill-set of the agents is also of interest. A P P E N D I X A. Pr oof of Theor em 1 [Existence of PNE] W e prov e Theorem 1 using Brouwer’ s fixed point theo- rem [13, Appendix C] applied to the best response mapping with the help of following lemmas (Lemmas 3-5). Recall that b i ( λ R − i ) is the best response of player i to the revie w admission rates of other players λ R − i . For brevity of notation, we will rep- resent r R ( λ R i , λ R − i ) , p ( λ R i , λ R − i ) , f i ( λ R i , λ R − i ) , ˜ u i ( λ R i , λ R − i ) using r R , p, f i , ˜ u i , respectively . Furthermore, let q 0 and 8 (a) (b) (c) (d) (e) (f) Fig. 4 : Empirical a) PoA, b) η T RI , and c) η LI , along with analytic upper bounds for d) PoA, e) η T RI , and f) η LI with increasing heterogeneity ( ρ ) among the agents. q 00 , respectiv ely , represent the first and the second partial deriv ativ es of a generic function q with respect to λ R i . Lemma 3 ( Strict concavity of incentive ) . F or the CPR game Γ , under Assumptions (A1-A2), the incentive function f i : S 7→ R is strictly concave in λ R i , for λ R i ∈ [0 , λ R i ] and any fixed λ R − i . Equivalently , f i ( x ) is strictly concave in x for x ∈ [0 , µ S T − P j ∈N ,j 6 = i a j λ R j ] . Pr oof. Recall from (9) that f i ( λ R i , λ R − i ) = f i ( x ) = r R ( x )(1 − p ( x )) − h i r S . The first and the second partial deriv ativ e of the incentiv e function f i with respect to λ R i in the interv al λ R i ∈ [0 , λ R i ] are gi ven by: f 0 i = ( r R ) 0 (1 − p ) − r R p 0 = − a i d f i dx , (17a) f 00 i = ( r R ) 00 (1 − p ) − 2( r R ) 0 p 0 − r R p 00 = a 2 i d 2 f i dx 2 . (17b) From Assumptions (A1) and (A2), we hav e f 00 i < 0 and d 2 f i dx 2 < 0 in the interval where deri vati ve of f i exists, thereby proving the strict concavity of f i in λ R i and x . Lemma 4 ( Best response mapping ) . F or the CPR game Γ , under Assumptions (A1-A2), the best r esponse mapping b i ( λ R − i ) is unique for any λ R − i ∈ S − i and is given by: b i ( λ R − i ) = 0 , if f i ( λ R i , · ) ≤ 0 , ∀ λ R i ∈ S i , α i , if ∃ α i ∈ S i s.t. ∂ ˜ u i ∂ λ R i ( α i ) = 0 , and f i ( α i , · ) > 0 , µ R i , otherwise . Pr oof. W e establish uniqueness of the best response mapping through the following three cases. Case 1: f i ( λ R i , · ) ≤ 0 , for ev ery λ R i ∈ S i . If for a given λ R − i ∈ S − i , f i ( λ R i , · ) ≤ 0 , for every λ R i ∈ S i , then from (8), ˜ u i ( λ R i , λ R − i ) admits a unique maximum at λ R i = 0 , and therefore, b i ( λ R − i ) = 0 is the unique best response. Case 2: There exists a non-empty interv al S i ⊂ S i , such that f i ( λ R i , · ) > 0 , and f 0 i ( λ R i , · ) < 0 , for ev ery λ R i ∈ S i . For any given λ R − i ∈ S − i , recall that the system con- straint (3) is violated for e very λ R i ∈ ( λ R i , µ R i ] ⊂ S i , and p ( λ R i , λ R − i ) = 1 . Therefore, for e very λ R i ∈ ( λ R i , µ R i ] , we hav e f i = − h i r S < 0 . (18) Therefore, b i ( λ R − i ) ∈ [0 , λ R i ] ⊂ S i , for an y gi ven λ R − i ∈ S − i . Furthermore, for a fixed λ R − i , since p is continuously differentiable with respect to λ R i , for each λ R i ∈ (0 , λ R i ) , ˜ u i is a smooth function on the set [0 , λ R i ] × S − i . Hence, the best response, which is a global maximizer of ˜ u i on the interval λ R i ∈ S i , either occurs at the boundary of S i or satisfies the first order condition, ∂ ˜ u i ∂ λ R i ( b i ) = 0 (see [35]). Let there exist α i ∈ S i such that f i ( α i , · ) > 0 , and (19a) ∂ ˜ u i ∂ λ R i ( α i ) = α i f 0 i ( α i , · ) + f i ( α i , · ) = 0 . (19b) Since f i ( α i , · ) > 0 and α i > 0 , (19b) has a solution only if f 0 i ( α i , · ) < 0 . Furthermore, f i ( α i , · ) > 0 implies α i ∈ [0 , λ R i ] (see (18)). Therefore, existence of α i satisfying (19) implies there exists a non-empty set S i ⊂ [0 , λ R i ] ⊂ S i , such that for each α i ∈ S i , f i ( α i , · ) > 0 and f 0 i ( α i , · ) < 0 . For any 9 λ R i ∈ S i , such that f i ( λ R i , · ) > 0 and f 0 i ( λ R i , · ) < 0 , using Lemma 3, we get: ∂ 2 ˜ u i ∂ λ R i 2 = λ R i f 00 i + 2 f 0 i < 0 . (20) Hence, for λ R i ∈ S i , the expected utility ˜ u i is strictly concave with a unique global maximizer α i ∈ S i that satisfies α i = min {− f i ( b i , · ) f 0 i ( b i , · ) , µ R i } (see (19b)). Case 3: There exists a non-empty interv al ˜ S i ⊂ S i , such that f i ( λ R i , · ) > 0 , for e very λ R i ∈ ˜ S i , and f 0 i ( λ R i , · ) ≥ 0 , for any λ R i ∈ S i . Finally , consider the case that f 0 i ( λ R i , · ) ≥ 0 , for ev ery λ R i ∈ S i , and there e xists an interval ˜ S i ⊂ S i where f i ( λ R i , · ) > 0 , for any λ R i ∈ ˜ S i . Since f 0 i ( λ R i , · ) ≥ 0 , for ev ery λ R i ∈ S i , i.e., f i ( λ R i , · ) is increasing in λ R i , and therefore, f i ( λ R i , · ) is maximized at λ R i = µ R i . Since there exists a non- empty interval ˜ S i such that f i ( λ R i , · ) > 0 , for e very λ R i ∈ ˜ S i , monotonically increasing f i ( λ R i , · ) , it follows µ R i ∈ ˜ S i , and f i ( µ R i , · ) > 0 . Therefore, in the interval λ R i ∈ ˜ S i , (19b) has no solution and the expected utility of player i is strictly increasing in λ R i , i.e., ∂ ˜ u i ∂ λ R i > 0 , for e very λ R i ∈ S i . Therefore, the best response is the unique maximum of ˜ u i which occurs at the boundary µ R i . W e state some important intermediate results from three cases of Lemma 4 as a corollary for later discussions. Corollary 2 ( Best response and incentiv e ) . F or the CPR game Γ , under Assumptions (A1-A3), the following statements hold: (i) b i = 0 , if and only if, f i ( λ R i , · ) ≤ 0 , for every λ R i ∈ S i ; furthermor e, f i ( λ R i , · ) ≤ 0 , for every λ R i ∈ S i implies f 0 i ( λ R i , · ) < 0 , for every λ R i ∈ S i ; (ii) if ther e exists an interval S i ⊂ S i , such that f i ( λ R i , · ) > 0 , and f 0 i ( λ R i , · ) < 0 , ∀ λ R i ∈ S i , then the unique best r esponse for player i satisfies the implicit equation b i = min {− f i ( b i , · ) f 0 i ( b i , · ) , µ R i } ∈ S i ; and (iii) if f 0 i ( λ R i , · ) ≥ 0 , for every λ R i ∈ S i , then b i = µ R i . Pr oof. W e only establish the first statement of the corollary . The other statements are established in the proof of Lemma 4. W e have already established in Lemma 4 that if f i ( λ R i , · ) ≤ 0 , then for ev ery λ R i ∈ S i , the expected utility ˜ u i is maximized for b i = 0 . W e now establish the “only if” part. Recall from (8) that ˜ u i ( λ R i , λ R − i ) = µ S i r S + λ R i f i ( λ R i , λ R − i ) . Let b i = 0 be the best response for player i for a fixed λ R − i . If there exists b ∈ S i , such that f i ( b, · ) > 0 , then ˜ u i ( b, · ) > ˜ u i ( b i , · ) , and b i = 0 cannot be a best response. Hence, b i = 0 is the best response for player i , if and only if, f i ( λ R i , · ) ≤ 0 , for e very λ R i ∈ S i . W e now sho w that if f i ( λ R i , · ) ≤ 0 , for e very λ R i ∈ S i , then f 0 i ( λ R i , · ) < 0 , for ev ery λ R i ∈ S i . Since f i is strictly concave in x (from Lemma 3) and f i ( µ R i , 0) = f i ( µ S T − a i µ R i ) > 0 by Assumption (A3), there exist γ 1 , γ 2 ∈ R such that γ 1 < µ S T − a i µ R i < γ 2 and f i ( x ) > 0 if and only if x ∈ ( γ 1 , γ 2 ) . If f i ( λ R i , λ R − i ) = f i ( x ) ≤ 0 for each λ R i ∈ S i and for a giv en λ R − i , then for each λ R i ∈ S i , either x ≤ γ 1 , or x ≥ γ 2 . Suppose x ≥ γ 2 , for each λ R i ∈ S i . Howe ver , for λ R i = µ R i , x = µ S T − a i µ i − P j 6 = i a j λ R j ≤ µ S T − a i µ i < γ 2 , which is a contradiction. Hence, x ≤ γ 1 , for each λ R i ∈ S i . Finally , from strict concavity of f i , f i is increasing in x for x ≤ γ 1 . Equiv alently , f i is decreasing in λ R i , i.e., f 0 i ( λ R i , · ) < 0 , for every λ R i ∈ S i . Theorem 4 ( Berge Maximum Theorem, adapted from [36] ) . Let ˜ u i : S i × S − i 7→ R be a continuous function on S i × S − i , and C : S − i 7→ S i be a compact valued correspondence such that C ( λ R − i ) 6 = ∅ for all λ R − i ∈ S i . Define ˜ u ∗ i : S − i 7→ R by ˜ u ∗ i ( λ R − i ) = max { ˜ u i ( λ R i , λ R − i ) | λ R i ∈ C ( λ R − i ) } , and b i : S − i 7→ S i by b i ( λ R − i ) = argmax { ˜ u i ( λ R i , λ R − i ) | λ R i ∈ C ( λ R − i ) } . If C is continuous at λ R − i , then ˜ u ∗ i is continuous and b i is upper hemicontinuous with nonempty and compact values. Furthermor e, if ˜ u i is strictly quasiconcave in λ R i ∈ S i for each λ R − i and C is con vex-valued, then b i ( λ R − i ) is single-valued, and thus is a continuous function. Lemma 5 ( Continuity of best response mapping ) . F or the CPR game Γ , under Assumptions (A1-A3), the best r esponse mapping b i ( λ R − i ) is continuous for each λ R − i ∈ S − i . Pr oof. Let z ( λ R − i ) : S − i 7→ [ µ S T − P j ∈N ,j 6 = i a j µ R j a i , µ S T a i ] be defined by z ( λ R − i ) := µ S T − P j ∈N ,j 6 = i a j λ R j a i . (21) The mapping z ( λ R − i ) represents an upper bound on the value of λ R i abov e which the system constraint (3) is violated. Therefore, for each λ R i ∈ [ z ( λ R − i ) , ∞ ) ∩ S i , from (9), we get f i = − h i r S < 0 , and f 0 i = − r R p 0 ≤ 0 , (22) where the latter follo ws from monotonicity of p (Assumption (A2)). The mapping z ( λ R − i ) defined in (21) is continuous on S − i and linearly decreasing in λ R j , for every j ∈ N \ { i } . Therefore, to establish the continuity of the best re- sponse mapping b i ( λ R − i ) on S − i , it is sufficient to sho w that b i ( λ R − i ) = φ ( z ( λ R − i )) , for some continuous function φ : [ µ S T − P j ∈N ,j 6 = i a j µ R j a i , µ S T a i ] 7→ [0 , µ R i ] . T o this end, we sho w that for each fixed value of z ( λ R − i ) , b i is unique and varies continuously with z ( λ R − i ) . Let ˆ λ + : S − i 7→ [0 , µ R i ] be defined by ˆ λ + ( λ R − i ) = ( 0 , if f i ( λ R i , λ R − i ) ≤ 0 , ∀ λ R i ∈ S i , sup { λ R i ∈ S i | f i > 0 } , otherwise . (23) The mapping ˆ λ + ( λ R − i ) , when non-zero, represents the maxi- mal admissible revie w admission rate for player i , that yields her a positive incenti ve to revie w the tasks. Fig. 5 shows the 10 (a) (b) (c) Fig. 5 : Best response of player i with varying ˆ λ + . The red curve shows different possibilities for strictly concav e incentive function f i ( λ R i ) w .r.t λ R i ∈ S i = [0 , µ R i ] , based on the value of λ R − i . In (a), f i < 0 and f 0 i < 0 for all λ R i ∈ S i ; in (b), there exists a subset of S i where f i > 0 and f 0 i < 0 ; and in c) f 0 i ≥ 0 for any λ R − i . At z ( λ R i ) (represented by blue), f i < 0 and f 0 i < 0 . a) For ˆ λ + = 0 , b i ( λ R − i ) = 0 ; b) for ˆ λ + ∈ (0 , µ R i ) , b i ( λ R − i ) ∈ S i ; and c) for ˆ λ + = µ R i , b i ( λ R − i ) = µ R i . best response of player i ∈ N for the three possible cases of ˆ λ + . Case 1: z ( λ R − i ) ≤ 0 . From (22) and statement (i) of Corol- lary 2, b i ( λ R − i ) = 0 is the unique (continuous) best response for player i . Case 2: z ( λ R − i ) > 0 . From (22), f i < 0 and f 0 i < 0 for any λ R i ≥ z ( λ R − i ) . Hence, ˆ λ + < z ( λ R − i ) . Now we consider three cases based on the value of ˆ λ + . Case 2.1: ˆ λ + = 0 . In this case, f i ≤ 0 , for e very λ R i ∈ S i , and therefore, from statement (i) of Corollary 2, b i = 0 is the unique best response and continuity holds trivially . Case 2.2: ˆ λ + ∈ (0 , µ R i ) . In this case, for any λ R − i ∈ S − i , there exists an interval S i ⊂ [0 , ˆ λ + ] such that f i > 0 and f 0 i < 0 , for every λ R i ∈ S i . Here, f 0 i < 0 follows from the fact that the supremum in (23) corresponds to the decreasing segment of f i . From statement (ii) of Corollary 2, there e xists a unique b i ( λ R − i ) ∈ S i that maximizes ˜ u i . Application of Berge maximum theorem [36], yields the continuity of the unique maximizer . Since, b i < ˆ λ + , it follo ws that if ˆ λ + → 0 + , then b i → 0 + . Hence, the continuity holds at ˆ λ + = 0 . Case 2.3: ˆ λ + = µ R i . Since ˆ λ + < z ( λ R − i ) , z ( λ R − i ) ∈ ( µ R i , µ S T a i ] . If f 0 ( µ R i , λ R − i ) < 0 , then the continuity follows analogously to Case 2.2. Now consider the case f 0 ( µ R i , λ R − i ) = − δ , for δ > 0 . Since f i is concav e in λ R i and its deri vati ve is decreasing, there exists > 0 such that f 0 < 0 for λ i ∈ ( µ R i − , µ R i ] . Since f i ( λ R i , · ) is strictly concav e in λ R i (Lemma 3), there exists at most one point λ R i , such that f 0 ( λ R i , · ) = 0 . Therefore, in the limit δ → 0 + , → 0 + . Hence, in this limiting case S i = ( µ R i − , µ R i ] , where → 0 + , and the best response b i ( λ R − i ) ∈ S i = ( µ R i − , µ R i ] con verges to µ R i . If f 0 ( µ R i , λ R − i ) ≥ 0 , then it follows from strict concavity of f i that f 0 ( λ R i , λ R − i ) ≥ 0 , for every λ R i ∈ S i . Using statement (iii) of Corollary 2, b i ( λ R − i ) = µ R i is the unique (continuous) best response. Note that when z ( λ R − i ) = µ S T a i , i.e., when no other player revie ws any task ( λ R − i = 0 ), from Assumption (A3), f i ( µ R i , 0) > 0 and therefore b i ( λ R − i ) = µ R i . Hence, b i ( λ R − i ) is continuous for ev ery z ( λ R − i ) , and therefore, is continuous for λ R − i ∈ S − i . Pr oof of Theorem 1: T o prov e the existence of a PNE, define a mapping M : S 7→ S as follows: M ( λ R 1 , λ R 2 , ..., λ R N ) = ( b 1 ( λ R − 1 ) , b 2 ( λ R − 2 ) , ..., b N ( λ R − N )) . (24) The mapping M is unique (Lemma 4) and continuous (Lemma 5), and maps the compact conv ex set S ( S i is con vex and compact, ∀ i ∈ N ) to itself. Hence, application of Brouwer’ s fixed point theorem [13, Appendix C] yields that there exists a strategy profile λ R = { λ R i ∗ } i ∈N ∈ S which is in variant under the best response mapping and therefore is a PNE of the game. B. Pr oof of Cor ollary 1 [PNE]: Since PNE is a best response which remains in variant under the best-response mapping M given by (24), Corollary 1 is a direct consequence of Corollary 2 with a simplification that f 0 i ( λ R ∗ i , λ R ∗ − i ) < 0 at PNE. Therefore, to prove Corollary 1, it is sufficient to sho w statement (i), i.e. f 0 i ( λ R ∗ i , λ R ∗ − i ) < 0 for any player i ∈ N at PNE, which we prove by contradiction. Let there exist a player j such that f 0 j ( λ R ∗ j , λ R ∗ − j ) ≥ 0 at PNE. From (17a), it can be seen that the sign of f 0 i remains the same for all players at a PNE. Therefore, f 0 j ≥ 0 implies f 0 i ≥ 0 for all i ∈ N at that PNE. In such a case, (19b) implies that the expected utility of each player with λ R ∗ i > 0 (therefore, f i > 0 ) is increasing in λ R i at that PNE, and therefore, each of these players can improve their expected utility by unilaterally increasing their revie w admission rate. Therefore λ R ∗ cannot be a PNE, which is a contradiction. Hence, f 0 i ( λ R ∗ i , λ R ∗ − i ) < 0 for any player i ∈ N at a PNE, and the corollary follows. C. Pr oof of Pr oposition 1 [Structure of PNE] Let λ R ∗ k 1 and λ R ∗ k 2 be the revie w admission rates at a PNE for players k 1 and k 2 , respecti vely , with h k 1 ≤ h k 2 . By proving a k 1 λ R ∗ k 1 ≥ a k 2 λ R ∗ k 2 , λ R ∗ k 1 ≥ λ R ∗ k 2 is established trivially since a k 1 ≤ a k 2 . W e assume a k 1 λ R ∗ k 1 < a k 2 λ R ∗ k 2 and prove the first statement by establishing a contradiction argument using two cases discussed belo w . Furthermore, the proof of the second statement is contained within Case 1 below . Case 1: λ R ∗ k 1 = 0 . From statement (ii) of Corollary 1, f k 1 ( λ R ∗ k 1 , λ R ∗ − k 1 ) ≤ 0 . From (9), the incentives f k 1 and f k 2 for players k 1 and k 2 at a PNE satisfies: f k 2 = f k 1 + ( h k 1 − h k 2 ) r S ≤ 0 . Therefore, utilizing statement (ii) of Corollary 1 again implies λ R ∗ k 2 = 0 , which is a contradiction. This case also prov es the second statement. Case 2: λ R ∗ k 1 > 0 . By assumption, a k 1 λ R ∗ k 1 < a k 2 λ R ∗ k 2 , from statement (iii) of Corollary 1, λ R ∗ i , where i ∈ { k 1 , k 2 } , satisfy the implicit equation λ R ∗ i = min ( − f i ( λ R ∗ i , λ R ∗ − i ) f 0 i ( λ R ∗ i , λ R ∗ − i ) , µ R i ) . 11 W e assume that λ R ∗ k 1 < µ R k 1 , and therefore, λ R ∗ k 1 = − f k 1 f 0 k 1 . Using (9) and (17a), we get a k 2 λ R ∗ k 2 = min ( − a k 2 f k 2 f 0 k 2 , a k 2 µ R k 2 ) ≤ − a k 2 f k 2 f 0 k 2 = − a k 1 f k 1 + ( h k 1 − h k 2 ) r S f 0 k 1 ≤ a k 1 λ R ∗ k 1 , which is a contradiction. Hence, if λ R ∗ k 1 < µ R k 1 , then a k 1 λ R ∗ k 1 ≥ a k 2 λ R ∗ k 2 and λ R ∗ k 1 ≥ λ R ∗ k 2 for each k 2 > k 1 . D. Pr oof of Theor em 2 [Uniqueness of PNE] Suppose that the CPR game Γ has multiple PNEs. W e define the support of a PNE as the total number of players with non-zero revie w admission rate. Let PNE 1 = λ 1 = [ λ 1 1 , λ 1 2 , . . . , λ 1 N ] and PNE 2 = λ 2 = [ λ 2 1 , λ 2 2 , . . . , λ 2 N ] , be two dif ferent PNEs with distinct supports m 1 and m 2 , respectiv ely . For brevity of notation, we hav e removed the superscript R from the two PNEs and replaced it by their unique identifier . Without loss of generality , let m 2 > m 1 . Let x 1 = µ S T − P N i =1 a i λ 1 i and x 2 = µ S T − P N i =1 a i λ 2 i be the slackness parameters at PNE 1 and PNE 2 , respecti vely . W e prove the uniqueness of PNE using a six step process. Step 1: W e first show that if ther e exists two differ ent PNEs with distinct supports m 1 and m 2 ( m 1 < m 2 ), then x 1 < x 2 . If m 1 and m 2 are the supports of PNE 1 and PNE 2 , respectiv ely , then λ 1 i = 0 and λ 2 j = 0 , for each i > m 1 , and j > m 2 , respectiv ely (Proposition 1). Additionally , λ 1 i > 0 , and λ 2 j > 0 , for each i ≤ m 1 , and j ≤ m 2 . Hence, m 2 > m 1 implies λ 1 m 2 = 0 , while λ 2 m 2 > 0 . From statement (i) of Corollary 2, b i = 0 , if and only if f i ≤ 0 and f i 0 < 0 (equiv alently d f i dx > 0 ) for all λ R i ∈ S i . Therefore, λ 1 m 2 = 0 implies f 1 m 2 := f m 2 ( λ 1 ) ≤ 0 and d f m 2 dx > 0 e verywhere, while λ 2 m 2 > 0 implies f 2 m 2 := f m 2 ( λ 2 ) > 0 . Since f 2 m 2 > 0 > f 1 m 2 and d f m 2 dx > 0 everywhere, it follo ws that x 1 < x 2 . Step 2: W e now show that x 1 > x 2 using Steps 2-5, which is a contradiction to the r esult of Step 1 , and consequently m 1 = m 2 . From statement (iii) of Corollary 1, the revie w admission rate of any player i , i ≤ m 1 , at PNE k , k ∈ { 1 , 2 } , satisfies λ k i = min ( − f k i f k i 0 , µ R i ) . (25) Step 3: W e show that f 2 i > f 1 i for any player i , i ≤ m 1 . From (9), the incentiv es f i and f j for any two distinct players i and j with j > i at a PNE k , k ∈ { 1 , 2 } satisfies: f k i − f k j = ( h j − h i ) r S > 0 , ∀ j > i. Notice that the right hand side of above equation is indepen- dent of λ R i and therefore, a constant for both PNEs. Hence, for e very i < m 2 f 1 i − f 1 m 2 = f 2 i − f 2 m 2 . Therefore, f 2 m 2 > f 1 m 2 implies f 2 i > f 1 i , for every i ≤ m 1 < m 2 . Step 4: W e show that f 0 1 i < f 0 2 i , for every player i , i ≤ m 1 . Recall that f i is strictly concave in x (Lemma 3). Therefore, x 1 < x 2 (Step 1) implies d f 1 i dx > d f 2 i dx . Therefore, from (17a), f 0 1 i < f 0 2 i , for any player i , i ≤ m 1 . Step 5: W e now show that x 1 > x 2 , which is a contradiction to r esult of Step 1, and consequently m 1 = m 2 . Since for all players i , i ≤ m 1 , f 2 i > f 1 i (Step 3) and − f 0 1 i > − f 0 2 i (Step 4), (25) implies λ 2 i ≥ λ 1 i , for each i ≤ m 1 . Therefore, P N i =1 a i λ 2 i > P m 1 i =1 a i λ 2 i ≥ P m 1 i =1 a i λ 1 i = P N i =1 a i λ 1 i , which implies x 1 > x 2 , which is a contradiction to result of Step 1. Hence, m 1 = m 2 Step 6: W e now show the value of slackness parameter x at any PNE is unique . Steps 1 to 5 sho w that, at a PNE, the number of players with non-zero revie w admission rate are unique. Therefore, let m be the identical support for PNE 1 and PNE 2 . W ithout loss of generality , let x 1 > x 2 . Let g i : R 7→ R , for i ≤ m , be defined by g i ( x ) = − f ( x ) f 0 ( x ) . Differentiating g i ( x ) w .r .t x , we get dg i ( x ) dx = ( d f i ( x ) dx ) 2 − f i ( x ) d 2 f i ( x ) dx 2 a i ( d f i ( x ) dx ) 2 . Recall from statement (iii) of Corollary 1 that players hav e non-zero revie w admission rate at PNE, if and only if, f i > 0 at PNE. Strict conca vity of f i (Lemma 3) implies dg i ( x ) dx > 0 . Consequently , at PNE, the re view admission rate for an y player i , i ≤ m , is increasing with x . Therefore, assumption x 1 > x 2 implies λ 1 i ≥ λ 2 i , for each player i ≤ m . Consequently , x 1 = µ S T − P m i =1 a i λ 1 i ≤ µ S T − P m i =1 a i λ 2 i = x 2 , which is a contradiction. Therefore, x 1 = x 2 . W e now sho w the uniqueness of PNE. Steps 1 to 6 sho w that, at a PNE, the number of players with non-zero revie w admission rate and the slackness parameter x are unique. Therefore, the first order cond i tions (25) giv e the unique revie w admission rate for each player i for unique slack parameter x , thereby implying uniqueness of PNE. E. Pr oof of Lemma 1 [Non-incr easing best r esponse] W e prov e this lemma by considering the three cases of the best response mapping in Lemma 4 (Appendix A): Case 1: b i = 0 . Recall that x = µ S T − P N i =1 a i λ R i . In this case, from statement (i) of Corollary 2, f i ≤ 0 and f 0 i < 0 (equiv alently , d f i dx > 0) , for all λ R i ∈ S i . Since x can be re- written as x = µ S T − a i λ R i − σ i ( λ R − i ) , therefore d f i dx > 0 implies ∂ f i ∂ σ i < 0 . Hence, with increase in σ i ( λ R − i ) , b i = 0 remains the best response. 12 Case 2: b i = − f i ( b i ,σ i ( λ R − i )) f 0 i ( b i ,σ i ( λ R − i )) . In this case, from statement (ii) of Corollary 2, b i ∈ S i such that f i > 0 and f 0 i < 0 , for e very λ R i ∈ S i . Thus, db i dσ i = − f 0 i 2 + f 00 i f i a i f 0 i 2 < 0 . (26) Hence, b i is strictly decreasing in σ i ( λ R − i ) . Case 3: b i = µ R i . Since b i ∈ S i = [0 , µ R i ] , b i either decreases or remains constant with increase in σ i ( λ R − i ) . F . Pr oof of Theorem 3 [Analytic bounds on PNE Inefficiency] W e first establish the analytic upper bound on PoA, followed by upper bounds on η T RI and η LI . Let G be the family of CPR games parameterized by the ratios of the maximum service and re view admission rates of each player i ∈ N . Therefore, the CPR game Γ ∈ G , with the corresponding ratio for player i giv en by h i . Define a set of homogeneous CPR games G H ⊂ G , in which each player has a constant ratio { µ S i } H { µ R i } H =: h , and min i {{ µ R i } H } ≥ { µ S T } H N (1+ h ) . The superscript H is used to distinguish maximum service and revie w admission rates of the homogeneous game Γ H from the CPR game Γ . For any CPR game in G , PoA is giv en by: P oA = (Ψ) S W (Ψ) P N E = [ P N i =1 µ S i r S + P N i =1 λ R i f i ( x )] S W [ P N i =1 µ S i r S + P N i =1 λ R i f i ( x )] P N E . (27) W e no w provide an analytic upper bound on the PoA for the CPR game Γ using following Lemmas. Lemma 6 ( PNE solution for homogeneous CPR game ) . F or any homog eneous CPR game Γ H ∈ G H , such that for eac h player i ∈ N , { µ S i } H { µ R i } H = h , and min i {{ µ R i } H } ≥ { µ S T } H N (1+ h ) , each player participates in the re view pr ocess with equal r eview admission rate λ H i = λ H at PNE. Let λ H T be the total r eview admission rate at PNE for Γ H . The unique PNE solution is given by λ H = λ H T N , wher e λ H T = f ( x ) (1+ h ) d f dx and x = { µ S T } H − (1 + h ) λ H T . Pr oof. For the homogeneous CPR game Γ H , each player has equal incentiv e f ( x ) to revie w the tasks. If f ( x ) ≤ 0 at PNE, all players have λ H i = 0 (statement (ii) of Corollary 1) which contradicts assumption (A3). Hence, at PNE, each players has λ H i > 0 . Let min i {{ µ R i } H } ≥ { µ S T } H N (1+ h ) for Γ H . At PNE, x > 0 . Let D ⊆ N be a non-empty set of player indices such that for any i ∈ D , { µ R i } H ≤ − f ( x ) f 0 ( x ) . At PNE, λ H T = X i ∈D { µ R i } H + X i ∈N \D − f ( x ) f 0 ( x ) ≥ N min i {{ µ R i } H } ≥ { µ S T } H (1 + h ) . Therefore, at PNE, x = { µ S T } H − (1 + h ) λ H T ≤ { µ S T } H − (1 + h ) N min i {{ µ R i } H } ≤ 0 , which is a contradiction. Hence, D is an empty set and each player has equal revie w admission rate at PNE, gi ven by λ H i = λ H = λ H T N . Hence, each player being a maximizer of their expected utility maximizes: ˜ u i = { µ S i } H r S + λ H T N f ( x ) , (28) where x = { µ S T } H − (1 + h ) λ H T . Setting ∂ ˜ u i ∂ λ H T = 0 , we get λ H T = f ( x ) (1+ h ) d f dx . Lemma 7 ( P oA=1 for homogeneous CPR game ) . F or any homogeneous CPR game Γ H ∈ G H , such that for each player i ∈ N , { µ S i } H { µ R i } H = h , and min i {{ µ R i } H } ≥ { µ S T } H N (1+ h ) , P oA=1. Pr oof. For homogeneous CPR game Γ H , social welfare func- tion Ψ H in (15) only depends on λ R T and is given by: Ψ H = { µ S T } H r S + λ R T f ( x ) , (29) where x = { µ S T } H − (1 + h ) λ R T , and f ( x ) is the uniform incentiv e function for each player . Note that d Ψ H dλ R T > 0 when d f dx ≤ 0 , and d 2 Ψ H dλ R T 2 > 0 in the interv al where d f dx > 0 . It is easy to show that Ψ H is maximized by any λ R T satisfying λ R T = f ( x ) (1+ h ) d f dx obtained by setting d Ψ H dλ R T = 0 , and d f dx > 0 at the maximizer . Let λ H T be the total revie w admission rate at PNE for Γ H . The unique PNE satisfies λ H T = f ( x ) (1+ h ) d f dx (Lemma 6), and hence, maximizes social welfare utility resulting in PoA = 1 . Corresponding to the CPR game Γ , construct a homoge- neous game Γ H N ∈ G H with { µ S i } H = µ S i and { µ R i } H = µ S i h N , for each player i ∈ N . Note that for homogeneous players in Γ H N , { µ S i } H { µ R i } H = h = h N , and P N i =1 { µ S i } H = µ S T . Furthermore, the assumption min i { µ S i } > µ S T h N N (1+ h N ) im- plies min i {{ µ R i } H } > { µ S T } H N (1+ h ) . Hence, P oA = 1 for Γ H N (Lemma 7). T o obtain analytic bounds on PoA, we no w compute a lower bound on the social utility obtained at the unique PNE Ψ Γ P N E for the CPR game Γ . In Lemma 8, we show that the social utility obtained at the PNE Ψ H P N E for the homogeneous game Γ H N lower bounds Ψ Γ P N E . For any x ∈ [0 , µ S T ] , homogeneous players with ratio h N in Γ H N hav e a lower cumulati ve incentiv e ( P f ) to revie w tasks than players in Γ , and therefore, have a lower social utility at PNE, i.e., Ψ Γ P N E ≥ Ψ H P N E . W e further lower bound Ψ Γ P N E by computing a lower bound on Ψ H P N E . Lemma 8 ( Lower bound for social welfare at PNE ) . Let Γ H N be a homogeneous game corresponding to CPR game Γ with each player i ∈ N having { µ S i } H = µ S i and { µ R i } H = µ S i h N . Let Ψ Γ P N E and Ψ H P N E be the social welfar e functions for Γ and Γ H N , r espectively , evaluated at their unique PNEs. 13 Then Ψ Γ P N E ≥ Ψ H P N E ≥ µ S T r S + µ S T − x a N f N ( x ) , where x is the unique maximizer of f i , i.e. d f i dx ( x ) = 0 . Pr oof. Let λ ∗ = [ λ ∗ 1 , . . . , λ ∗ N ] and λ H = [ λ H , . . . , λ H ] be the unique PNEs for the CPR games Γ and Γ H N , respectively . Let x ∗ = µ S T − P N i =1 a i λ ∗ i and x H = µ S T − N a N λ H be their slackness parameters at respective PNEs. Step 1: W e show that x H ≥ x ∗ using contradiction. Let x ∗ > x H . Recall that at PNE, d f i dx > 0 (Corollary 1). Using strict concavity of f i (Lemma 3), we have d f i dx ( x H ) > d f i dx ( x ∗ ) > 0 . Therefore, f N ( x ∗ ) d f N dx ( x ∗ ) > f N ( x H ) d f N dx ( x H ) = a N λ H N . Recall that f 1 ( x ) ≥ · · · ≥ f N ( x ) for any x , and d f i dx is independent of i . Hence, f i ( x ∗ ) d f i dx ( x ∗ ) > a N λ H N for any i . Using h N ≥ h i , we get a i µ R i = µ S i + µ S i h i ≥ µ S i + µ S i h N = a N { µ R i } H > a N λ H N . Therefore, a i λ ∗ i = min f i ( x ∗ ) d f i dx ( x ∗ ) , a i µ R i > a N λ H N , for any i . Hence, x ∗ < x H , which is a contradiction. Therefore, x H ≥ x ∗ (equiv alently , P N i =1 a i λ ∗ i ≥ N a N λ H N ) and d f i dx ( x ∗ ) ≥ d f i dx ( x H ) > 0 . Step 2: W e show that P i f i ( x ∗ ) ≥ N f N ( x H ) & P i λ ∗ i ≥ N λ H N . Let d ≤ N be the support for λ ∗ . Therefore, λ ∗ i = min f i ( x ∗ ) a i d f i dx ( x ∗ ) , µ R i for ev ery i ≤ d , , and λ ∗ i = 0 for any i > d . Therefore, P d i =1 f i ( x ∗ ) d f i dx ( x ∗ ) ≥ P d i =1 a i λ ∗ i ≥ N a N λ H N = N f N ( x H ) d f N dx ( x H ) . Using d f i dx ( x ∗ ) ≥ d f N dx ( x H ) > 0 ( d f i dx is indepen- dent of i ), we get P d i =1 f i ( x ∗ ) ≥ N f N ( x H ) . Additionally , P N i =1 a i λ ∗ i ≥ N a N λ H N implies P d i =1 λ ∗ i ≥ P N i =1 a i a N λ ∗ i ≥ N λ H N . Step 3: W e show that Ψ Γ P N E ≥ Ψ H P N E . Using h N ≥ h i , we hav e µ R i = µ S i h i ≥ µ S i h N = { µ R i } H > λ H N . Let d 1 ≤ d be the largest index of player satisfying f i ( x ∗ ) a i d f i dx > λ H N . Since f N ( x ∗ ) a N d f N dx ( x ∗ ) < λ H N , d 1 < N . Therefore, λ ∗ i satisfies, λ ∗ i = min f i ( x ∗ ) a i d f i dx ( x ∗ ) , µ R i > λ H N , for i ≤ d 1 , f i ( x ∗ ) a i d f i dx ( x ∗ ) ≤ λ H N , for d 1 + 1 ≤ i ≤ d. (30) Hence, Ψ Γ P N E = µ S T r S + d X i =1 λ ∗ i f i ( x ∗ ) (1 ∗ ) = µ S T r S + λ H N d X i =1 f i ( x ∗ ) + d 1 X i =1 ( λ ∗ i − λ H N ) f i ( x ∗ ) + d X i = d 1 +1 ( λ ∗ i − λ H N ) f i ( x ∗ ) (2 ∗ ) ≥ µ S T r S + λ H N N f N ( x H ) + d 1 X i =1 ( λ ∗ i − λ H N ) f d 1 +1 ( x ∗ ) + d X i = d 1 +1 ( λ ∗ i − λ H N ) f d 1 +1 ( x ∗ ) = µ S T r S + λ H N N f N ( x H ) + f d 1 +1 ( x ∗ ) d X i =1 ( λ ∗ i − λ H N ) (3 ∗ ) ≥ µ S T r S + λ H N N f N ( x H ) = Ψ H P N E , where (1 ∗ ) follows by adding and subtracting λ H N P d i =1 f i ( x ∗ ) . (2 ∗ ) follows from P d i =1 f i ( x ∗ ) ≥ N f N ( x H ) (Step 2), (30), and the fact that f 1 ( x ∗ ) ≥ · · · ≥ f N ( x ∗ ) . (3 ∗ ) follo ws by recalling that P d i =1 λ ∗ i ≥ N λ H N (Step 2). Step 4: W e show that Ψ Γ P N E ≥ Ψ H P N E ≥ µ S T r S + µ S T − x a N f N ( x ) . Let x be the unique maximizer of f i . From Lemma 7, Ψ H P N E = Ψ H S W = max { Ψ H } ≥ µ S T r S + λ R T f N ( µ S T − a N λ R T ) for an y λ R T . Choosing λ R T = µ S T − x a N , we obtain the desired bounds. Pr oof of Theor em 3: The global optimum of social welfare function is upper bounded by: Ψ Γ S W = µ S T r S + max λ R i ( N X i =1 λ R i f i ( x ) ) ≤ µ S T r S + max λ R i λ R T max x { f i ( x ) } (1 ∗ ) ≤ µ S T r S + µ S T f i ( x ) ≤ µ S T ( r S + r R ( x )(1 − p ( x ))) , (31) where (1 ∗ ) is obtained using the system constraint x > 0 which implies µ S T ≥ P N i =1 a i λ R i ≥ λ R T . From Lemma 8, Ψ Γ P N E is lo wer bounded by: Ψ Γ P N E ≥ µ S T r S + µ S T − x a N f N ( x ) = 1 a N xa N r S + ( µ S T − x )( r S + r R ( x )(1 − p ( x ))) ≥ 1 a N ( µ S T − x )( r S + r R ( x )(1 − p ( x ))) . (32) Using (31) and (32), we get, P oA = Ψ Γ S W Ψ Γ P N E ≤ µ S T a N µ S T − x . Now we establish the bounds on η T RI and η LI . Let x P N E and x S W be the slackness parameter corresponding to the PNE and social welfare, respectiv ely . Recall that d f i dx > 0 (Corollary 1), for x ∈ { x P N E , x S W } . Hence, using strict concavity of f i , we hav e x P N E , x S W ∈ (0 , x ) . Therefore, µ S T − x < P N i =1 a i { λ R i } P N E < µ S T , and µ S T − x < P N i =1 a i { λ R i } S W < µ S T . Hence, η T RI and η LI are upper bounded by: η T RI = ( λ R T ) S W ( λ R T ) P N E < µ S T a N ( µ S T − x ) a 1 , and η LI = ( P N i =1 a i λ R i ) P N E ( P N i =1 a i λ R i ) S W < µ S T µ S T − x . 14 R E F E R E N C E S [1] P . Gupta, S. D. Bopardikar , and V . Sriv astav a, “ Achieving efficient collaboration in decentralized heterogeneous teams using common-pool resource games, ” in 2019 IEEE 58th Confer ence on Decision and Contr ol (CDC) . IEEE, 2019, pp. 6924–6929. [2] M. Haas and M. Mortensen, “The secrets of great teamwork. ” Harvar d Business Revie w , v ol. 94, no. 6, pp. 70–6, 2016. [3] T . Burns and G. Stalker, “Mechanistic and organic systems, ” Organ Behav , v ol. 2, pp. 214–225, 2005. [4] F . C. Lunenburg, “Mechanistic-organic organizations – an axiomatic theory: Authority based on bureaucracy or professional norms, ” Inter- national Journal of Scholarly Academic Intellectual Diversity , vol. 14, no. 1, pp. 1–7, 2012. [5] C. Keser and R. Gardner , “Strategic behavior of experienced subjects in a common pool resource game, ” International Journal of Game Theory , vol. 28, no. 2, pp. 241–252, 1999. [6] A. R. Hota, S. Garg, and S. Sundaram, “Fragility of the commons under prospect-theoretic risk attitudes, ” Games and Economic Behavior , vol. 98, pp. 135–164, 2016. [7] M. A. Goodrich, J. L. Cooper , J. A. Adams, C. Humphrey , R. Zeeman, and B. G. Buss, “Using a mini-U A V to support wilderness search and rescue: Practices for human-robot teaming, ” in Safety, Security and Rescue Robotics, 2007. SSRR 2007. IEEE International W orkshop on . IEEE, 2007, pp. 1–6. [8] J. Peters, V . Sriv astava, G. T aylor, A. Surana, M. P . Eckstein, and F . Bullo, “Human supervisory control of robotic teams: Integrating cognitiv e modeling with engineering design, ” IEEE Control System Magazine , vol. 35, no. 6, pp. 57–80, 2015. [9] V . Sriv astava, R. Carli, C. Langbort, and F . Bullo, “ Attention allocation for decision making queues, ” Automatica , v ol. 50, no. 2, pp. 378–388, 2014. [10] P . Gupta and V . Sriv astava, “Optimal fidelity selection for human-in- the-loop queues using semi-Markov decision processes, ” in American Contr ol Conference , Philadelphia, P A, Jul. 2019, pp. 5266–5271. [11] J. R. Marden and J. S. Shamma, “Game theory and control, ” Annual Review of Control, Robotics, and Autonomous Systems , vol. 1, pp. 105– 134, 2018. [12] G. Arslan, J. Marden, and J. Shamma, “ Autonomous vehicle-target as- signment: A game-theoretical formulation, ” Journal of Dynamic Systems Measur ement and Contr ol-T ransactions of the Asme , vol. 129, 09 2007. [13] T . Bas ¸ar and G. J. Olsder , Dynamic Noncooperative Game Theory . SIAM, 1999, vol. 23. [14] T . Roughgarden, “Intrinsic robustness of the price of anarchy , ” in Pr oceedings of the forty-first annual ACM symposium on Theory of computing , 2009, pp. 513–522. [15] J. R. Marden and T . Roughgarden, “Generalized efficiency bounds in distributed resource allocation, ” IEEE T ransactions on Automatic Contr ol , vol. 59, no. 3, pp. 571–584, 2014. [16] L. Deori, K. Margellos, and M. Prandini, “Price of anarchy in electric vehicle charging control games: When nash equilibria achieve social welfare, ” A utomatica , vol. 96, pp. 150–158, 2018. [17] D. Paccagnan, R. Chandan, and J. R. Marden, “Utility design for distributed resource allocation - part I: Characterizing and optimizing the exact price of anarchy , ” IEEE T ransactions on Automatic Contr ol , pp. 1–1, 2019. [18] F . Gao, M. L. Cummings, and E. T . Solovey , “Modeling teamwork in supervisory control of multiple robots, ” IEEE T ransactions on Human- Machine Systems , vol. 44, no. 4, pp. 441–453, 2014. [19] A. Hong, “Human-robot interactions for single robots and multi-robot teams, ” Ph.D. dissertation, University of T oronto, 2016. [20] V . Srivasta va and F . Bullo, “Knapsack problems with sigmoid utilities: Approximation algorithms via hybrid optimization, ” Eur opean Journal of Operational Researc h , v ol. 236, no. 2, pp. 488–498, 2014. [21] B. Mekdeci and M. Cummings, “Modeling multiple human operators in the supervisory control of heterogeneous unmanned vehicles, ” in Pr oceedings of the 9th W orkshop on P erformance Metrics for Intelligent Systems . ACM, 2009, pp. 1–8. [22] P . Le Gall, “The theory of networks of single server queues and the tandem queue model, ” International Journal of Stochastic Analysis , vol. 10, no. 4, pp. 363–381, 1997. [23] N. T . Thomopoulos, Fundamentals of queuing systems: statistical meth- ods for analyzing queuing models . Springer Science & Business Media, 2012. [24] E. Altman, “ Applications of dynamic games in queues, ” in Advances in dynamic games . Springer , 2005, pp. 309–342. [25] L. Xia, “Service rate control of closed jackson networks from game theoretic perspectiv e, ” Eur opean Journal of Operational Researc h , vol. 237, no. 2, pp. 546–554, 2014. [26] A. R. Hota and S. Sundaram, “Controlling human utilization of failure- prone systems via taxes, ” arXiv preprint , 2018. [27] E. Ostrom, R. Gardner , J. W alker, and J. W alker , Rules, Games, and Common-P ool Resour ces . Uni versity of Michigan Press, 1994. [28] M. V oornev eld, “Best-response potential games, ” Economics letters , vol. 66, no. 3, pp. 289–295, 2000. [29] P . Dubey , O. Haimanko, and A. Zapechelnyuk, “Strategic complements and substitutes, and potential games, ” Games and Economic Behavior , vol. 54, no. 1, pp. 77–94, 2006. [30] M. K. Jensen, “Stability of pure strategy nash equilibrium in best-reply potential games, ” University of Birmingham, T ech. Rep , 2009. [31] C. G. Cassandras and S. Lafortune, Intr oduction to Discrete Event Systems . Springer Science & Business Media, 2009. [32] M. K. Jensen, “ Aggregativ e games and best-reply potentials, ” Economic Theory , v ol. 43, no. 1, pp. 45–66, 2010. [33] B. Schipper, “Pseudo-potential games, ” Univ ersity of Bonn, Germany , T ech. Rep., 2004, working paper . [Online]. A vailable: av ailableatciteseer . ist.psu.edu/schipper04pseudopotential.html [34] R. Burden and J. Faires, “The bisection method, ” Numerical Analysis , pp. 48–56, 2011. [35] D. G. Luenberger and Y . Y e, Linear and Nonlinear Progr amming . Springer , 1984, vol. 2. [36] C. Berge, T opological Spaces: Including a T reatment of Multi-valued Functions, V ector Spaces, and Con vexity . Courier Corporation, 1997.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment