FurcaNeXt: End-to-end monaural speech separation with dynamic gated dilated temporal convolutional networks
Deep dilated temporal convolutional networks (TCN) have been proved to be very effective in sequence modeling. In this paper we propose several improvements of TCN for end-to-end approach to monaural speech separation, which consists of 1) multi-scal…
Authors: Liwen Zhang, Ziqiang Shi, Jiqing Han
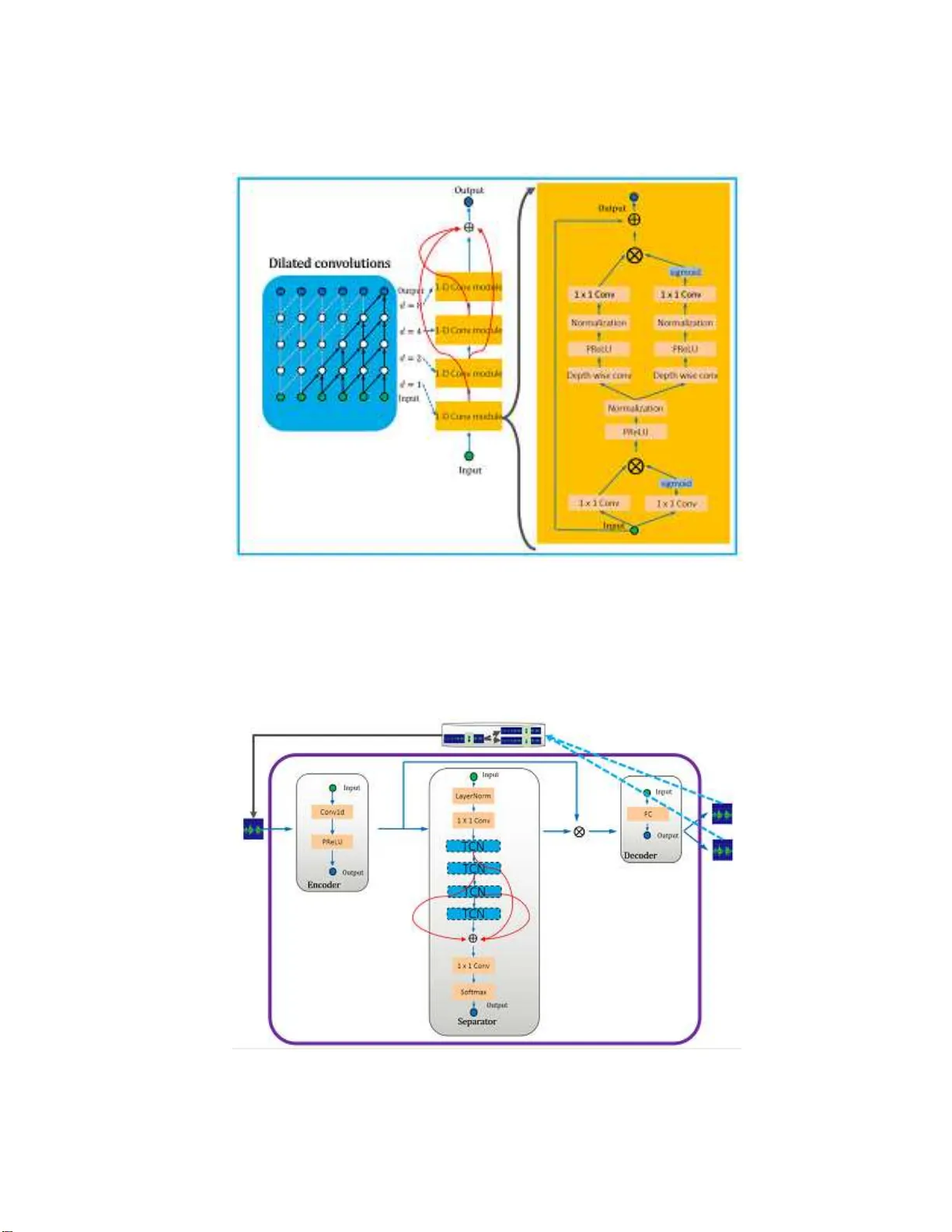
F urcaNeXt: End-to-end monaural sp eec h separation with dynamic gated dilated temp oral c on v olutional net w or ks Liw en Zhang 1 , Ziqiang Shi ∗ 2 , Jiqiang H an 1 , An y a n Shi 3 , and Ding Ma 1 1 Harbin Institute of T e c hnology , Harbin, China 2 F ujitsu R & D Cen ter, Beijing, China 3 Sh uangf eng First, Beijing, China F eb., 2019 Abstract Deep dilated temp oral conv olutional netw orks (TCN) hav e b een prov ed to be very effectiv e in sequence mod eling. In this pap er w e propose sev eral improv ements of TCN for end-to- en d approach to monau- ral sp eech separation, whic h consists of 1) multi-scale dy namic w eigh t ed gated d ilated conv olutional pyramids netw ork (F urcaPy), 2) gated TCN with intra-parall el conv olutional comp onents (F u rcaP a), 3) w eight-shared m u lti-scale ga ted TCN (F urcaSh) , 4 ) dilated TC N with gated difference-conv olutional compon ent (F urcaSu), that all these n etw orks take the mixed utterance of tw o sp eakers and maps it to tw o separated utterances, where eac h utterance con tains only one speaker’s v oice. F or the ob jectiv e, we prop ose to train the net work by directly optimizing utterance lev el signal-to-distortion ratio ( SDR) in a p ermutation inv arian t training (PIT) style. Ou r exp eriments on the the public WSJ0-2mix d ata cor- pus results in 18.4dB SDR improv ement, w hich sho ws our prop osed netw orks can leads to p erformance impro vemen t on th e sp eaker separation task. 1 In tro duction Multi-talker monaural sp eech separation has a v ast range of applications. F o r ex a mple, a home environment or a conference environment in which many people talk, the human auditory sys tem can eas ily track and follow a target sp eaker’s voice from the mult i-talker’s mixed voice. In this c a se, a clean sp eech signal of the targe t s p ea ker needs to b e sepa rated from the mixed sp eech to co mplete the subs equent recognition work. Thu s it is a pr oblem that m ust b e so lved in o rder to achiev e s a tisfactory p er formance in sp eech or s p ea ker rec o gnition ta s ks. There a r e tw o difficulties in this pro ble m, the fir s t is that since we do n’t hav e a ny priori information o f the user , a truly practical sy stem must b e s p e aker-independent. The s e cond difficult y is that there is no wa y to use the be a mforming algorithm for a single micro phone signal. Many traditional metho ds, such as co mputational auditor y scene analysis (CASA) [30, 20, 1 0], Non-negative matrix factorization (NMF) [23, 13], and pr obabilistic mo dels [29], do not so lve these t wo difficulties well. More recently , a larg e num b er of techniques based on deep learning ar e prop osed for this task. These metho ds can b e brie fly gr oup ed into three categor ies. The first ca tegory is based on deep clustering (DPCL) [8, 1 1], which maps the time-freq uency (TF) p oints of the sp ectrogr am into the em bedding vectors, then these em bedding v ectors are clustered in to se veral classes corresp onding to different sp eakers, and fi- nally these cluster s ar e used as masks to inv ersely transfor m the s pe c trogra m to the sepa rated clean voices; the seco nd is the p er mutation inv a r iant training (P IT) [12, 35], which solves the lab el p e rmutation pro blem by minimizing the low est err or output among all p os sible p ermutations for N mixing sources a ssignment; the third ca tegory is end-to- end s p e ech separatio n in time-do main [17, 18, 27], which is a natural w ay to ov er c ome the obstac les of the upp er b ound so urce-to-disto rtion ratio improv ement (SDRi) in short-time ∗ Corresp onding author: shiziqiang@fujitsu.com; shiziqiang7@gmail.com 1 F ourier tra nsform (STFT) mask estimation based metho ds a nd real-time pr o cessing req uirements in a c tual use. This paper is based on the end-to-end metho d [17, 18, 27], which ha s ac hiev ed b etter results than DPCL based o r PIT based appro aches. Since mos t DPCL and PIT ba sed metho ds use STFT as front-end. Spec ific a lly , the mixed sp eech signal is first transfor med from one-dimensional sig nal in time domain to tw o - dimensional sp ectrum signa l in T F doma in, and then the mixed spectrum is se pa rated to result in spectrums corres p o nding to differen t source sp eeches by a deep clustering or mask e s timation metho d, and finally the cleaned source sp eech sig nal ca n be resto red by an inverse STFT o n each sp ectrum. This framework has several limitations. Firstly , it is unclea r whether the STFT is the o ptimal (ev en assume the pa r ameters it depe nds o n are optimal, such as size and o verlap of audio frames, window type and so on) transformation of the signal for s pe e ch separa tion. Secondly , mos t STFT ba sed methods o ften a ssumed that the phase of the separ ated signa l to be equal to the mixture phase, which is g enerally incorr ect a nd imp ose s an obvious upper bound on separation perfor ma nce by using the ideal masks. As an approach to ov ercome the ab ov e problems, several spe ech separation mo dels were recently pro p osed that o p erate directly on time-doma in sp eech signals [17, 18, 27]. Ins pired b y these first results, we prop o se F urcaNeXt, which is a general na me for a series of fully end-to-end time-domain separa tion metho ds , includes 1) multi-scale dynamic w eig hted gated dilated conv o lutional pyramids netw ork (F urcaPy): due to the influence of different word le ng ths or differen t s pe ech spe eds, mult iple branches of a v ariety of temp oral receipt field sca les are introduce to characterize sp eech, and the weights of different sca les a re automatica lly determined by a “weight or” net work; 2) de e p gated dilated tempo ral convolutional netw ork s (TCN) with intra-par a llel co nvolutional comp onents (F urc aPa): repla ce tw o conv olutional related mo dules in each dilated con volutional mo dule by t wo intra-para llel co nv olutiona l mo dules , whic h can reduce the v ar iance of this mo del. The intra-para llel conv olutio nal modules replicate weigh t matrices a nd ta ke the average fr o m the feature maps pro duced by those layers. This convenien t technique can effectiv e ly improv e separation p erfor mance. 3) weigh t-shared m ulti-scale g ated TCN (F urca Sh): a simple design is prop ose d to a chiev e the functions of F urca P y but without increasing the n um ber of netw ork par ameters. 4) dilated TCN with gated difference- c onv olutio na l comp onent (F ur caSu): inspired by the work of Highw ay netw or k [24], in which t w o additional non-linear transformatio ns acts a s ga tes that c an dynamica lly pass part of its inputs a nd suppress the other part, conditioned o n the input itself. Author s simplify the Highw ay netw ork through multiple wa ys [34]. After further simplification w e prop os e to use tw o iden tical transformation function bra nches to implemented a simplified version of the highw ay netw o rk mo dule. The rema inder o f this pap er is orga nized a s follows: section 2 in tro duces mona ur al sp eech s e pa ration with TCN. Section 3 describ e o ur prop o sed F ur caNeXt and the separ a tion alg orithm in deta il. The e x pe rimental setup and results ar e presented in Section 4 . W e conclude this pap er in Section 5. 2 Sp eec h separation with TCN In this section, we review the formal definition o f the monaur al speech separ ation task and the o riginal TCN architecture. The goa l of mo naural sp eech separa tion is to estimate the individua l tar get signals from a linearly mixed single-micro phone signal, in which the target signals ov erlap in the TF domain. Let x i ( t ) , i = 1 , .., S deno te the S target sp ee ch signals and y ( t ) denotes the mixed s pe e ch r e sp ectively . If we a ssume the target sig nals are linearly mixed, which can b e repr esented as: y ( t ) = S X i =1 x i ( t ) , then monaur al sp eech sepa ration aims a t estimating individua l tar get signals from given mixed sp eech y ( t ). In this work it is assumed that the num b er o f target s ig nals is known. In order to deal with this ill-p os ed problem, Luo et al. [18] introduce TCN [14, 2 ] to do this tas k. TCN is prop osed as an alternative to RNN in v arious tas ks [1 4, 2]. Ea ch lay er in the TCN contains a 1-D conv o lution blo ck with a n incr eased dilation factor. The dilation factor is increase d exponentially to ensure a suitable large temp or a l context window to take a dv antage of the long r ange dep endence of the sp eech signa l, a s shown in Figur e 1. Dilated convolution has made a huge success in W a veNet for audio gener ation [2 6]. 2 Figure 1: The structure of TCN. Dilated co nv olutions with differen t dilations have different receptive fields . Stac ked dilated convolution provides a very larg e receptive fields for the netw ork with only a few layers, b e c ause the dilation r ange grows exp onentially . This allows the netw ork to capture the temp o ral dep endence of v ar ious reso lutions with the input sequences. The TCN introduces a time hierarch y: the upp er la yer can ac cess longer input subsequences and lea r n representations o n larger time scales . L o cal information from low er la yers spreads through the hierar chy by means of res iduals and sk ip co nnections. There are tw o imp or tant elements in the or ig inal TCN [2] a s shown in Figure 1, one is the dilated conv olutio ns, and the o ther is re s idual connections. Dilated conv olutions follow the work of [26], it is defined as ( x ∗ d k )( p ) = X s + dt = p x ( s ) k ( t ) , where x is the 1-D input signa l, k is the filter (ak a kernel), and d is the dila tion factor . Therefor e, dilation is equiv alent to in tro ducing a fixed step size b etw een ev e ry tw o adjacent filter taps. The general wa y to incre ase the r eceipt field of the TCN is to increase the dilation factor d . In this w ork we increase d exp onentially with the depth of the netw ork and d = 2 as shown in Figure 1, and this TCN ha s four lay ers of 1-D Con v mo dules with dilation factors of 1 , 2 , 4 , 4 resp ectively . As shown in Figure 1 , Each 1-D Co nv module is a residual blo ck [7], whic h contains o ne lay er of dilated co nv olution (Depth wise co nv [9 ]), tw o lay e r s of 1 × 1 conv olutio ns (1 × 1 Conv), t wo non- line a rity ac tiv a tion layers (Parametric Rectified Linear Unit, P ReLU [6]), and t wo normaliza tion lay er s (Normalization). F or nor malization, w e a pplied global normaliza tion [18] to the conv o lutio nal filters. Luo et al. prop o sed a TCN ba sed sp eech separa tion metho d [18], which c onsists of three pro cessing stages, as shown in Figure 2: enco der (Conv1d is follow ed by a PReLU), separ ator (consisted in the order by a La yerNorm, a 1 × 1conv, 4 TCN layers, 1 × 1 conv, and a softmax op era tion) and deco der (a FC layer). First, the encoder module is us e d to conv ert short segmen ts of the mixed wa veform into their corresp onding rep- resentations. Then, the re pr esentation is used to estimate the mult iplication function (mask) of each sour ce and each enco der output for each time step. The source wa vef orm is then reconstructed by transfor ming the masked enco der features using a linear deco der mo dule. 3 Figure 2: The pip eline o f TCN based sp eech s eparatio n in [18]. Figure 3: The structure of gated TCN. 3 Sp eec h separation with F urcaNeXt The main work of this pap er is to mak e several improvemen ts to the TCN (Figure 1) and TCN base d framework (Figure 2 ) for sp eech separ ation. First, w e in tro duced gating oper ations in this TCN, as shown in Figure 3. Nonlinear ga ted activ a tion had b een use d in prio r work on s e quence modeling [2 6, 4], it can con tr ol the flow of information and may help the netw ork to mo del more co mplex int eractions. Two gates are added to each 1-D conv o lutional mo dule in the plain TCN, one is cor resp onding to the fir s t 1 × 1 conv o lutional lay er in the 1-D conv olutio na l mo dule, the other is corre s p o nding to all the lay er s from the depth-wise conv olutio nal la yer to the o utput 1 × 1 conv o lutional la yer. This g ated TCN based sp eech separation pipeline is called F urca Porta in this w or k. 3.1 F urc aP y: Multi-scale dynamic w eighted gated dilated con v olutional p yra- mids netw ork Since in r e al life the utterance always have the feature o f tempo ral sc a le v a riation caused by different word lengths and pronunciation characteristics (e.g. sp eed) of differ e nt p eo ple , thus differen t temp oral receipt fields may help in sp eech separ ation. The temp o r al r eceipt field is fixed in previous netw ork s tructure. In order to remedy the temp ora l s cale v ariation problem, a multi-scale dynamic weight ed p y ramids gated 4 Figure 4: The structure of F ur caPy . TCNs ba sed pip eline which is called F urcaPy is prop o sed as s hown in Figure 4 and there are three kinds of different temp o ral receipt fields in this descr iption. F urc aPy’s enco der a nd decoder ar e the sa me as the previous F urcaPorta, they differ only in the separa tor. In the sepa rator of F urcaP y , ea ch branch in the pyramid consists of a different n umber of gated TCNs. The length of the tempora l receptive field of each branch is several times the length o f the temp or al receiving field of a single ga ted TCN. If the receptive field of a single gated TCN is assumed to b e L , then the length of the receptive field of all br anches in the Figure 4 is 3 L ,4 L , and 5 L resp ectively . The total output is obtained b y weight ed av er aging the outputs of the differen t branches co rresp onding to different receipt fields. Additionally , a “weightor” mo dule is designed to de ter mine which tempor al r eceipt field is mor e suitable for current input utter a nce sig na l, that means the weigh ts of different ga ted TCNs are determined dynamically b y a “weigh tor” netw ork fo r each utterance. The “weight or” is compo sed of a commo n m ulti lay er 1-D co nvolutional neural netw o rk as shown in Figure 4 and it consist of Conv1d, PReLU, Lay erNormal, 3 lay ers of 1 × 1 Conv and max p o oling , and So ftmax. 3.2 F urc aSh: W eigh t-shared mu lti-scale gated TCN F urcaP y will incr ease the num ber of pa rameters of the netw o rk several times, and the pr o cessing sp eed of the net work will decrease a lot. In many cases, there is no wa y to meet the requirements of rea l-time pro cessing for such netw o r k. In o rder to deal w ith these pr oblems, a new structure is prop o sed that can achiev e the tw o- level multi-scale re c e ptive fields without increa sing the n um ber of netw ork par ameters. As shown in Fig ur e 5 and Figure 6, t wo lev els of m ulti-s cale temp oral receptive fields is int ro duced, o ne is in the dilated 1-D conv mo dule level, that is the o utputs co rresp onding to different dilated factor s ar e summed and av eraged to result in the fina l output of this gated TCN; the o ther is that since there ar e 4 gated TCNs in the F urcaSh pip eline, the outputs of different gated TCNs are summed and averaged to result in the separato r . So there a re tw o different le vels of multi-scale tempo r al receipt field in this structure. 3.3 F urc aPa: Deep gated dilated temp oral conv olutional netw orks ( TCN) with in tr a-parallel con v olutional comp onents The p erfor mance of a single predictive mo del ca n alwa ys b e improv e d by ensemble, that is to combines a set o f indep e ndent ly tra ined netw or ks. The most commonly used metho d is to do the average of the mo del, which can at least help to reduce the v a riance of the perfor mance. As shown in Figur e 7, in the different lay er s of each 1-D conv olutiona l mo dule o f g ated TCN in F urcaPorta, tw o identical pa rallel br anches are 5 Figure 5: The structure of F ur caSh. Figure 6: The structure of F ur caSh. 6 Figure 7: The structure of F ur caPa. added. This s tr ucture is called F urcaPa. The total output of each intra-parallel convolutional co mpo nents is obtained by averaging the outputs of all the differen t br anches. In each single dilated 1 -D con volutional mo dule lay er , tw o intra-parallel conv olutional comp o nents are introduced, the first one is near the input lay er and cov er s the Conv1d, PReLU, and Normalizatio n lay ers; the other one is near the output a nd it cov er s the rest all lay ers, inc luding the Depth wise con v, PReLu, Nor malization and 1 × 1 Conv lay er s. The reason why we do this ensemble in tw o places is to reduce the sub- v a riances of ea ch blo ck. 3.4 F urc aSu: Dilated TCN with gated difference-con volutional comp onen t Highw ay net work can b e simplified and generalized to hav e b etter p erfo r mance [3 4]. F ollow the work of [34], we further simplify the High w ay netw ork mo dule, as shown in Fig ure 8, in each sing le dilated 1 -D conv o lu- tional mo dule lay er , t wo Highw ay netw o r k module o r ga ted difference-conv olutiona l co mp o ne nts as w e c a lled are intro duced, the first o ne is nea r the input layer and covers the Conv1d, PReLU, a nd Nor malization lay- ers; the other o ne is near the output and it cov er s the rest a ll lay e rs, including the Depth wise co nv, PReLu, Normalization and 1 × 1 Con v la yers. Different fr om the original use of three differen t transformation func- tions, in order to simplify the design and improv e perfor mance, here we use three iden tical tra nsformation branches, o ne branch a s the attention gates, the other t wo are sig nal transforma tio ns, a nd their r esults ar e subtracted and then gated. 3.5 P erceptual metric: Utt er ance-lev el SDR ob ject ive Since the loss function of many STFT-based metho ds is not directly applicable to w aveform-based end-to- end sp eech separa tion, p erceptual metric based loss function is tried in this work. The p erception of sp eech is g reatly affected b y dis to rtion [3 3, 1]. Gener ally in or de r to ev aluate the p er formance of s pe e ch separation, the BSS Ev al metr ics signal-to-disto rtion ratio (SDR), signa l- to-Interference ratio (SIR), signal-to-a rtifact ratio (SAR) [5, 28], and shor t-time ob jective in telligibility (STOI) [25] have b een often employ ed. In this work we directly use SDR, which is mo st commo nly us ed metrics to ev a luate the p erfor mance o f s ource separatio n, as the tr aining ob jective. SDR measures the amount of distortion introduce d by the output signal and define it as the ratio b etw ee n the ener g y of the clea n signal and the energy of the distor tion. SDR captures the o v erall separ ation quality of the algorithm. There is a subtle pr oblem here. W e first concatenate the outputs of F urcaNet into a co mplete utterance and then compare with the input full utterance to calculate the SDR in the utterance level instead of calculating the SDR for one frame at a time. 7 Figure 8: The structure of F ur caSu. These tw o metho ds are very differ ent in ways and p er formance. If w e deno te the output of the netw ork by s , which should ideally b e equal to the ta rget so urce x , then SDR can b e given as [5, 28] ˜ x = h x, s i h x, x i x, e = ˜ x − s, SDR = 10 ∗ log 10 h ˜ x, ˜ x i h e, e i . Then our target is to maximize SDR or minimize the neg ative SDR as loss function resp ect to the s . In or der to solve tracing and per mutation pro blem, the P IT training criter ia [12, 35] is employed in this work. W e calculate the SDRs for all the p ermutations, pick the max imum one, and take the neg ative as the loss. It is ca lled the uSDR loss in this work. 4 Exp erimen ts 4.1 Dataset and neural netw ork W e ev aluated our system on tw o - sp eaker speech separatio n problem using WSJ0- 2mix data set [8, 11], which contains 3 0 hours of training and 10 hours of v alida tion data. The mixtures ar e generated by rando mly selecting 49 male and 51 female sp eakers and utterances in W all Stree t Jour nal (WSJ0) tra ining set si tr s, and mixing them a t v ar ious signal- to-noise r a tios (SNR) uniformly b etw een 0 dB and 5 dB. 5 hours of ev aluation set is g enerated in the s ame w ay , using utterances fr om 16 unseen sp eakers from si dt 05 and si et 05 in the WSJ 0 da taset. W e ev alua te the systems with the SDR improvemen t (SDRi) [5, 28] metrics used in [1 1, 16, 32, 3, 12]. The original SDR, that is the av erage SDR of mixed sp eech y ( t ) for the original target sp eech x 1 ( t ) and x 2 ( t ) is 0.15. T able 1 lis ts the av er age SDRi obtained by the differe nt structur es in F urcaNeXt a nd almost all the results in the pas t tw o years, wher e I RM means the ideal ratio mas k M s = | X s ( t, f ) | P S s =1 | X s ( t, f ) | (4.1) applied to the STFT Y ( t, f ) of y ( t ) to obtain the separated sp eech, whic h is ev a luated to show the upp er bo unds of STFT base d metho ds, wher e X s ( t, f ) is the STFT of x s ( t ). 8 In this exp er iment, as bas elines, we re implemen ted several cla s sical approa ches, such as DPCL [8 ], T as- Net [17] and C o nv-T asNet [18]. T a ble 1 lists the SDRis o bta ined by our metho ds a nd a lmost all the results in the pas t t w o y ears, where IRM mea ns the ideal ratio mask. Compa red with these baselines an average increase of nearly 2.6dB SDRi is obtained. F ur caPy has achiev e d the most significa nt performa nce improv e- men t compa red with baseline sy stems, and it break through the upp er b ound of STFT bas ed metho ds a lot (nearly 6dB). T able 1: SDRi (dB) in a compa rative study of differen t sepa ration metho ds o n the WSJ0-2mix data set. * indicates our reimplementation o f the cor resp onding metho d. Metho d SDRi DPCL [8 ] 5.9 uPIT-BLSTM [35] 10.0 cuPIT-Grid-RD [32] 10.2 D ANet [3] 10.5 AD ANet [16] 10.5 DPCL* 10.7 DPCL++ [1 1] 10.8 CBLDNN-GA T [15] 11.0 T asNet [17] 11.2 T asNet* 11.8 Chimera++ [31] 12.0 F urcaX [21] 12.5 IRM 12.7 F urcaNet [22] 13.3 Conv-T asNet [18] 15.0 Conv-T asNet* 15.8 F urcaPorto 17.3 F urcaSu 1 7.9 F urcaSh 1 8.0 F urcaPa 18.2 F urcaP y 18.4 5 Conclusion In this pap er we inv estigated the effectiveness of dee p dila ted temp o ral conv olutional netw or ks mo deling for m ulti-talker monaural sp eech separation. W e pro p ose a ser ies structure under the name of F urcaNeXt do to sp eech separa tio n. Benefits from the streng th of end-to - end pro cess ing, the novel gating manc inis m and dynamic improv ements, the b e st p er formance of structure in F urcaNeXt a chieve 18.4dB SDRi on the the public WSJ0-2mix data corpus, results in 16% r elative improvemen t, and w e a chiev e the new state-o f-the-art on the public WSJ0-2mix data corpus. F or further work, although SDR is widely used and can be useful, but it has some weaknesses [19]. In the future, maybe w e can use SNR to ev aluation our models . It would be in ter e s ting to see how consis tent the SDR and SNR a re. 6 Ac kno wledgmen t W e would like to thank Jian W u at Northw estern Polytechnical Universit y , Yi Luo a t Columbia University , and Zhong-Qiu W ang a t Ohio State Universit y for v alua ble discussions on WSJ0-2mix databas e , DPCL, and end-to-end sp eech separ ation. 9 References [1] Assmann, P ., Summerfield, Q.: The p er ception of sp eech under adverse conditions. In: Sp e e ch proces sing in the auditory system, pp. 231 –308 . Springer (20 04) [2] Bai, S., K olter, J.Z., Ko ltun, V.: An empirical ev aluation of gener ic conv olutiona l and recurr ent netw orks for sequence mo deling. ar Xiv pre pr int a rXiv:180 3.0127 1 (2018) [3] Chen, Z., Luo, Y., Mesga rani, N.: Deep attractor netw or k for single-micro phone sp ea ker s eparation. In: Aco ustics, Sp eech and Sig nal Pro cessing (ICASSP), 2017 IEEE In ternational Conference on. pp. 246–2 50. I E EE (2017 ) [4] Dauphin, Y.N., F a n, A., Auli, M., Grangier , D.: Language modeling with g ated con volutional netw orks. arXiv preprint arXiv:16 12.08 083 (20 16) [5] F ´ evotte, C., Gr ibo nv al, R., Vincent, E.: Bss ev al to olb ox us e r g uide–revisio n 2.0 (2005) [6] He, K ., Zha ng , X., Ren, S., Sun, J.: Delving deep in to rectifiers: Surpassing human-lev el p erformance on imagenet class ification. In: Pro c e edings o f the IEEE international conference on computer vision. pp. 1026 – 1034 (2015) [7] He, K., Zha ng, X., Ren, S., Sun, J.: Deep r esidual learning for image reco gnition. In: P ro ceedings of the IEEE conference on computer visio n a nd pattern reco gnition. pp. 770– 778 (2016) [8] Hershey , J.R., Chen, Z., Le Roux, J., W atanab e, S.: Deep clustering: Discriminative embeddings for seg mentation and separ ation. In: Acous tics, Speech and Signal Pro cessing (ICASSP), 2016 IE EE Int ernational Conference on. pp. 31 –35. IEE E (201 6) [9] Ho ward, A.G., Zh u, M., Chen, B., K alenichenk o , D., W ang , W., W eyand, T., Andreetto, M., Adam, H.: Mo bilenets: Efficient conv olutional neural net w orks for mobile vision applications. arXiv preprint arXiv:170 4.048 61 (201 7) [10] Hu, K ., W ang, D.: An unsup er vised approa ch to co channel sp eech separation. IEEE T ransactions on audio, sp eech, and languag e pro ces sing 21 (1), 1 22–1 3 1 (20 13) [11] Isik, Y., Roux, J .L., Chen, Z., W atanab e, S., Hers hey , J.R.: Single- channel multi-spea ker separatio n using deep clustering. arXiv prepr int ar Xiv:1607 .0217 3 (2016) [12] Kolbæk, M., Y u, D., T an, Z.H., Jensen, J., K olbaek, M., Y u, D., T a n, Z.H., Jensen, J.: Multitalker sp eech sepa r ation with utterance-level p e rmutation inv ar iant training o f deep recurrent neural ne t- works. IEEE/ACM T ransactions o n Audio, Spee ch a nd Lang ua ge Pro cess ing (T ASLP) 2 5(10), 1901– 1913 (2017) [13] Le Roux, J ., W eninger, F.J., Her shey , J.R.: Sparse nmf–half-baked or well done? Mitsubishi Electric Research Labs (MERL), Cambridge, MA, USA, T ech. Rep., no . TR2015-02 3 (20 1 5) [14] Lea, C., Vidal, R., Reiter , A., Hager , G.D.: T e mpo ral conv o lutio nal netw orks: A unified a pproach to action segmentation. In: E urop ean Co nference on Computer Vision. pp. 47– 54. Springer (20 1 6) [15] Li, C., Zhu, L., Xu, S., Gao , P ., Xu, B.: Cbldnn-base d s p ea ker-independent sp eech se pa ration via generative adversarial training (2018 ) [16] Luo, Y., Chen, Z., Mesg arani, N.: Sp eaker-indep endent sp eech separa tion with deep attractor netw ork. IEEE/ ACM T rans actions o n Audio, Sp eech, and L a nguage Pro ces s ing 26(4), 787– 796 (2018) [17] Luo, Y., Mesgara ni, N.: T asnet: time- domain audio sepa ration netw or k for r eal-time, single-channel sp eech separation. arXiv preprint arXiv:1 711.0 0 541 (20 17) [18] Luo, Y., Mesga rani, N.: T a s net: Surpass ing ideal time-fr equency masking for sp ee ch sepa ration. arXiv preprint arXiv:18 09.074 54 (201 8) 10 [19] Roux, J.L., Wisdo m, S., E rdogan, H., Hers hey , J.R.: Sdr - half-baked or well done? ar Xiv prepr int arXiv:181 1.025 08 (201 8) [20] Shao, Y., W a ng, D.: Mo del-ba sed sequential org anization in co channel speech. IEEE T ransactions on Audio, Sp eech, and Languag e Pro cessing 14(1), 289 –298 (200 6 ) [21] Shi, Z., Lin, H., Liu, L., Liu, R., Hay ak awa, S., Han, J.: F urcax: End-to-end monaur al sp eech s e paration based o n deep gated (de)conv o lutional neural networks with adversaria l example tr aining. In: P ro c. ICASSP (2019 ) [22] Shi, Z., Lin, H., Liu, L., Liu, R., Hay a k awa, S., Hara da, S., Han, J.: F urca net: An end-to-end deep gated conv olutional, long short-term memory , deep neural netw ork s for single channel sp e ech separ ation. arXiv preprint arXiv:19 02.00 651 (20 19) [23] Smaragdis , P ., et al.: Conv olutive s pe ech bases and their application to supervis e d speech separ a tion. IEEE T ransa ctions on audio sp eech and la nguage pr o cessing 15(1), 1 (2007 ) [24] Sriv astav a, R.K., Greff, K., Schmidh uber , J.: Highw ay net works. arXiv pr eprint arXiv:1505.0 0387 (2015) [25] T aal, C.H., Hendriks, R.C., Heusdens, R., Jensen, J .: A shor t-time ob jective intelligibilit y measur e for time-frequency weigh ted no isy sp eech. In: Acoustics Sp eech and Signal Pro ces sing (ICASSP), 20 10 IEEE In ternational Conference on. pp. 42 14–42 17. IEE E (201 0) [26] V an Den Oord, A., Dieleman, S., Z en, H., Simony a n, K., Viny als , O ., Graves, A., Kalch brenner, N., Senior, A., Kavuk cuoglu, K.: W avenet: A generative mo del for raw audio . CoRR abs/1 609.0 3 499 (2016 ) [27] V enk atara mani, S., Ca seb eer, J ., Smaragdis, P .: Ada ptive front-ends for end-to-e nd source se paration. In: Pro c. NIPS (201 7) [28] Vincent , E., Grib o nv al, R., F´ ev otte, C.: P erformance mea surement in blind audio source sepa ration. IEEE transactions on audio, sp eech, and languag e pro ce s sing 14(4), 1 462–1 469 (2006 ) [29] Virtanen, T.: Sp eech recognition using factoria l hidden marko v mo dels for sepa ration in the feature space. In: Ninth International Co nference on Spo ken Language Pro ces sing (2006 ) [30] W ang, D., Brown, G.J.: Computatio nal auditor y sce ne analysis: Principles, algor ithms, and applica- tions. Wiley-IEE E pres s (2006 ) [31] W ang, Z.Q., Le Roux, J., Hershey , J.R.: Alternative ob jective functions for deep clus ter ing. In: Pr o c. IEEE In ternational Conference on Acoustics, Sp eech a nd Signal Pr o cessing (ICASSP) (2018) [32] Xu, C., Xiao, X., Li, H., XU, C., RAO, W., XIA O, X., CHNG, E.S., LI, H.: Single channel sp eech separatio n with constrained utterance level p ermutation inv ariant training using grid lstm (201 8) [33] Y ang, W., Benbouch ta, M., Y an torno, R.: Performance of the modified bark spe c tral distortion as a n ob jective sp eech qualit y measure. In: Acoustics, Sp eech a nd Signal Pro cess ing, 1998. Pro c e edings o f the 1998 IEEE International Conference on. vol. 1, pp. 5 4 1–54 4. IE E E (19 98) [34] Y ousef, M., Hussa in, K.F., Moha mmed, U.S.: Accurate, data - efficient, uncons trained text r ecognition with conv olutio nal neural netw o rks. a rXiv preprint arXiv:18 12.11 8 94 (2018) [35] Y u, D., Kolbæk, M., T an, Z.H., Jens e n, J.: Perm utation inv ar iant training of deep mo dels for sp eaker- independent multi-talk er sp eech separa tion. In: Acoustics, Sp eech and Sig na l Pr o cessing (ICASSP), 2017 IEEE International Conference on. pp. 24 1–24 5. IEE E (20 17) 11
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment