Supervised Random Walks: Predicting and Recommending Links in Social Networks
Predicting the occurrence of links is a fundamental problem in networks. In the link prediction problem we are given a snapshot of a network and would like to infer which interactions among existing members are likely to occur in the near future or w…
Authors: : John Doe, Jane Smith, Michael Johnson
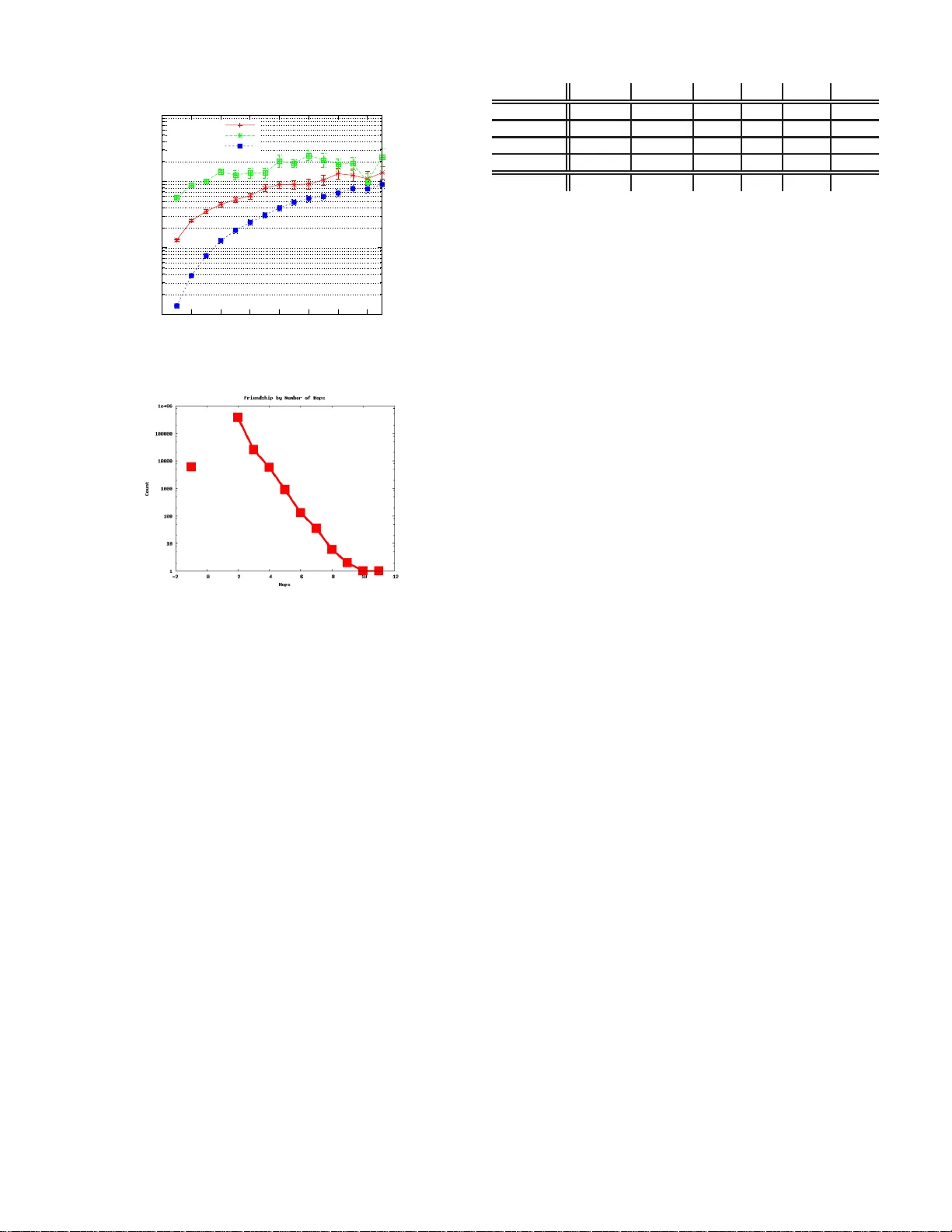
Supervised Random W alks: Predicting and Recommending Links in Social Netw orks Lars Bac kst rom F acebook lars@f acebook.com Ju re Lesk ovec Stanf ord University jure@cs.stanf ord.edu ABSTRA CT Predicting the occurren ce of links is a fundam ental problem in net- works. In the link prediction problem we are giv en a snapshot of a network and would like to infer which interactions among existing members are l ikely t o occur i n the near f uture or which existing interactions are we missing. Although this problem has been ex- tensi vely studied, the challenge of how to ef fectively combine the information from the network st ructure with rich node and edge attribute data remains larg ely open. W e de velop an algorithm based on Supervised Random W alks that naturally comb ines the information from the netw ork structure with node and edge le vel attributes. W e achie ve this by using these attributes to guide a random walk on the graph. W e formulate a supervised learning task where the goal is to learn a function t hat assigns strengths to edg es in the network su ch that a random walker is more likely to visit t he nodes to which new links will be created in the future. W e de velop an efficient training algorithm to directly learn the edge strength estimation function. Our experiments on the Facebook social graph and large collab- oration networks show that our approach outperforms state-of-the- art unsupervised approach es as well as approaches that are based on feature extraction. Categories and Subject Descriptors: H.2.8 [Database Manage- ment] : Database applications— Data mining General T erms: Algorithms; Experimentation . K eywords: Link p rediction, Social networks 1. INTR ODU CTIO N Large real-world networks exhibit a range of interesting proper- ties and patterns [7, 2 0]. One o f the recurring themes in this line of research is to design models that predict and reproduce the emer- gence of such network structures. Research then seeks to dev elop models that wil l accurately predict the glob al structu re o f the net- work [7, 20, 19, 6]. Many types of networks and especially social networks are highly dynamic; they grow and change quickly through the additions of ne w edges which signify the appearance of new interactions be- Permission to make digi tal or hard copies of all or part of this work for personal or cla ssroom use is granted without fee pro vided that copies are not made or distributed for profit or commercial advan tage and that copies bear this notice and the full cita tion on the firs t page . T o copy otherwise , to republi sh, to post on serve rs or to redistri bute to lists, requi res prior speci fic permission and/or a fee. WSDM’11, February 9–12, 2011, Hong Kong, C hina. Copyri ght 2011 A CM 978-1-4503-0493-1/1 1/02 ...$10.00. tween t he nodes of the network. Thu s, st udying the networks at a lev el of individu al ed ge creations is also interesting and in some respects more difficult t han global network modeling. Identifying the mechanisms by which such social networks evo lve at the lev el of i ndi vidual ed ges is a fundame ntal question that is sti ll not well understood, and it forms the moti v ation for our work here. W e consider the classical problem of li nk prediction [21] where we are giv en a snapshot of a social network at time t , and we seek to accurately predict t he edges that wil l be added t o the network during the interv al from t ime t to a gi ven future time t ′ . Mo re con- cretely , we are giv en a large network, say Facebook, at time t and for each user we w ould like to predict what ne w edges (friendships) that user will create between t and some future time t ′ . The prob- lem can be also viewed as a link rec ommendation problem, where we aim to su ggest to each user a list of people that t he u ser is likely to create ne w connections to. The processes guiding link creation are of interest f rom more than a pu rely scientific point of view . The cu rrent F acebook system for suggesting friends is responsible for a sig nificant fraction of li nk creations, and adds v alue for Facebook users. By making better predictions, we will be able to increase the usage of this f eature, and make it more useful to Faceb ook members. Challenges. The link prediction and link recommenda tion prob- lems are challenging from at least two points of vie w . Fi rst, r eal networks are e xtremely sparse, i.e., no des ha ve connec tions to o nly a very small fraction of all nodes in the network. For example, in the case of Fac ebook a typical user is conn ected to about 100 out of more than 500 mill ion nodes of the network. Thus, a very good (but unfortunately useless) way to predict e dges is to predict n o new edges since t his achiev es near perfect predictiv e accuracy (i. e., out of 500 million possible predictions it makes only 100 mistake s). The second challenge is more su btle; to what e xtent can t he li nks of the social network be modeled using the features intrinsic t o the network itself? Si milarly , ho w do charac teristics of u sers ( e .g. , ag e, gender , home town) interact with the creation of new edges? Con- sider the Facebook social network, for example. There can be man y reasons exogeno us to the network for two users to become con- nected: it could be that they met at a party , and then connected on Faceboo k. Howe ver , since they met at a party they are likely to be about the sam e age, and they also probably li ve in the sam e town. Moreo ver , this l ink might also be hinted at by the structure of the network: two people are more likely to meet at the same party if they are “close” in the n etwork. Such a pair of people likely has friends in common, and travel in similar social circles. Thus, de- spite the fact that they became friend s due to the e xogeno us e vent ( i.e. , a party) there are clues in their social networks which sug gest a high probability of a future friendship. Thus the question is h o w d o network and node features interact in the creation of new links. F rom t he l ink creation point of view: ho w important is it to ha ve common interests and characteristics? Furthermore, ho w important is it to be in the same social circle and be “close” in the network in order to ev entually connect. From the technical po int of vie w it is not clear ho w to de velop a me thod that, in a principled way , combines the features of nodes ( i.e. , user pro- file information) and edges ( i .e. , i nteraction information ) with t he network structure. A common, but some what unsatisfactory , ap- proach is to simply extract a set of features describing the network structure (like node degree , number of common friends, shortest path length) around the two nodes of interest and combine it with the user profile information. Present work: Supervised Random W alks. T o address these challenges we develo p a method for both link prediction and link recommendation . W e dev elop a concept of Supervised Random W alks that naturally and i n a principled way combines the network structure with the characteristics (attributes, features) of nodes and edges of the network into a unified link prediction algorithm. W e de velop a method based on Supervised Rando m W alks that in a supervised way learns ho w to bias a PageRank-like random walk on the network [3, 2] so that it visits gi ven nodes ( i.e. , positive training examp les) more often than the others. W e achie ve this by using node and edge features to learn edge str engths ( i .e. , random w alk tr ansition prob abilities) such that the random walk on a such weighted network is more likely to visit “positi ve” than “negati ve” nodes. In the context of link prediction, positi ve nodes are nodes to which new edges wil l be created in the future, and neg ativ e are all other node s. W e formulate a supervised learning task whe re we are give n a source node s and training e x- amples about which nodes s wil l create links to in the future. The goal is to then learn a f unction that assigns a st rength ( i.e. , random walk transition probability) to each edge so that whe n computing the ran dom w alk scores in such a weighted network nodes to which s creates new links ha ve higher scores to s than nodes to which s does not create links. From a technical perspecti ve, we show that suc h edge strength function can be learned directly and efficiently . This means, that we do not po stulate what it means for edge to be “stron g” in an ad- hoc way and then us e this heuristic estimate. Rathe r , we show ho w to directly find the parameters of the edge strength function which gi ve optimal performance. This means we are able to compute the gradient of the parameters of the edge strength function with re- spect to the PageRank-like ran dom walk scores. The formulation results in an optimization problem for which we deriv e an efficient estimation procedure. From the practical p oint of view , we experiment with l arge col- laboration networks and data from the Facebook network, sho w- ing that our approach outperforms state-of-the-art unsupervised ap- proaches as well as sup ervised ap proaches base d on comple x net- work feature extraction . An additional benefit of our approach is that no complex network feature extraction or doma in ex pertise are necessary as our algorithm nicely combines the node attribute and network structure information. Applications and consequ ences. As networks e volv e and g ro w by addition of new ed ges, the li nk prediction problem of fers insights into the factors behind creation o f individual edges as well as into network formation in general. Moreo ver , the link-prediction and the link-recommenda tion prob- lems are relev ant to a number of interesting current applications of social networks. F irst, for online social networking websites, like Faceboo k and Myspace, being able to predict future interactions has direct business consequen ces. More broadly , large organ iza- tions can directly benefit from the interactions w ithin the informal social network among its members and link-prediction methods can be used t o suggest possible new collaborations and interac- tions within the organization. Research in security has recently recognized the ro le of social netwo rk a nalysis for this domain (e.g., terrorist network s). In this conte xt l ink prediction can be used to suggest the most likely l inks that may form in the future. S imilarly , link prediction can also be used for prediction of missing or unob- served links in netwo rks [9] or to suggest which indi viduals may be working t ogether ev en thoug h their interaction has yet been di- rectly observ ed. Applications go well beyo nd social ne tworks, as our techniques can be used to predict unobserved links in protein- protein interaction networks in systems biolog y o r give suggestions to bloggers about which relev ant pages on the W eb to link to. Furthermore, the framework we dev elop is more general than link prediction, and could be used for an y sort of interac tion. For instance, in a collabora tion network, it could easily be used not to predict who s will link to next (write a paper with a previously un-collaborated-with perso n) b ut t o predict who s will coau thor a paper with next, including all those with whom s has previously coauthored. Further related wor k. The link prediction problem in networks comes in many flavors and variants. For example, the network in- ference pro blem [13, 24] can be cast as a l ink prediction problem where no knowled ge of the network is giv en. Moreo ver , ev en mod- els of comple x networks, like Preferential Attachment [7], Forest Fire model [20] an d models based on ran dom walks [19 , 8], can be vie wed as ways for predicting ne w links in networks. The unsup ervised methods for link prediction were e xtensi vely e v aluated by L iben-No well and Kleinberg [21] who found that the Adamic-Adar measu re o f no de similarity [1] performed best. M ore recently approaches ba sed on network community d etection [9, 16] hav e been tested on small networks. Link prediction in supervised machine learning setting was mainly studied by the relational learn- ing community [28, 26]. Ho we ver , the challenge w ith these ap- proaches is primarily scalability . Random walks on graphs have been considered for computing node proximities in l arge graphs [31, 30, 29, 27]. T hey hav e also been used for learning to rank nodes in graphs [3, 2, 23, 11]. 2. SUPER VISED RANDOM W ALKS Next we d escribe our algorithm for link prediction and recom- mendation. The general setting is that w e are given a graph and a node s for which we would l ike to predict/recommend ne w links. The ide a is that s has already created some links and we would like to predict which li nks it will create next (or will be created to it, since the direction of the links is often not clear). For simplicity the following discussion will focu s on a single node s and ho w to predict the links it will create in the future. Note that our setting is much more general than i t appears. W e require that for a node s we are given a set of “positiv e” and “neg- ativ e” training n odes an d our algorithm then l earns how to distin- guish them. This can be u sed for link prediction (po sitiv e nodes a re those to which links are created in the future), link recommenda- tion (positiv e nodes are those which user cli cks on), link anomaly detection (po sitiv e nodes a re tho se to which s has anomalous links) or missing link prediction (positiv e nodes are those to which s has missing li nks), to name a few . Moreo ver , our approach can also be generalized to a setting where prediction/recommend ation is n ot being made for only a single node s but also for a g roup of nodes. General considerations. A first general app roach to link pred ic- tion would be to view it as a classifi cation task. W e take pairs of nodes t o which s has created edges as positiv e training exam- ples, and all other nodes as negati ve training examples. W e then learn a clas sifier that p redicts where n ode s is going to cre ate links. There are several problems with such an approach. The first is the class i mbalance; s will create edges t o a very small fraction of the total no des in the network and learning is particularly hard in do- mains with high class imbalance. Second, extracting the features that the learning algorithm w ould use is a challenging and c umber- some task. Deciding which node features ( e.g . , node d emographics like, age, gender , hometown) and edge features ( e.g. , interaction activ ity) to use is already hard. Howe ver , it is eve n l ess clear how to e xtract good features that describe the network structure and p at- terns of connectivity between the pair of nodes under consideration. Even in a simple undirected graph w ith no node/edge attributes, there are countless ways to describe the proximity of two nodes. For exa mple, we might start by counting the number of common neighbors between the two nodes. W e might then adjust the prox- imity score based on the degrees of the two nodes (with the intuition being that high-deg ree nodes are likely to hav e common neighbors by mere happenstan ce). W e might go further gi ving different length two paths different weights based on things like the centrality or de- gree of the intermediate nodes. The possibilities are endless , and extracting useful features i s typically done by tr ial and err or rather than any principled approach. The prob lem becomes e ven harder when annotations are added to edges. For instance, in many net- works we kno w the creation times of edges, and this is likely to be a useful feature. But how do we combine the creation times of all the edges to get a feature relev ant to a pair of nodes? A second general approach to the l ink prediction problem is to think about it as a task to rank t he nodes of the netw ork. The i dea is to design an algorithm that will assign higher scores to nodes which s created links to than to those that s did not link to. PageR- ank [25] and v ariants like Personalized PageRank [17, 15] and Random W alks with Restarts [31] are popular methods for ranking nodes on grap hs. Thus, on e simple idea wo uld be to start a random walk at node s and compute t he proximity of each other node to node s [30]. This can be done by setting the random jump v ector so that the walk only jumps back to s and thus restarts the walk. The stationary distribution of such rando m walk assigns each node a score ( i.e. , a PageRank score) which gives us a rank ing of how “close” to the node s are other nodes in the network. T his method takes adv antage of the structure of the netw ork but does not con- sider the i mpact of other pro perties, lik e age, gender , and creation time. Over view of our approach. W e combine the two abov e app roaches into a single framewo rk that will at the same t ime consider rich node and edg e features as well as the structure of t he network. As Random W alks with Restarts hav e prov en to be a po werful tool for computing node proximities on graphs we use them as a way to consider the n etwork structure. Ho wev er, we then use the n ode and edge attribute data to b ias the ra ndom walk so that it wi ll more often visit nodes to which s creates edges in the future. More precisely , we are given a source node s . Then we are also gi ven a set of destination node s d 1 , . . . , d k ∈ D to which s will create edges in the near future. Now , we aim to bias the random walk originating f rom s so that it will visit nodes d i more often than other nodes in the network. One way to bias the random walk is to assign each edge a r andom walk transition probability ( i.e. , strength). Whereas the t raditional PageRank assumes that transi- tion probabilities of all edges to be the same, we learn h o w to as- sign each edge a transition probability so that the random walk is more lik ely to visit tar get n odes d i than other nodes of the network. Ho we ver , directly setting an arbitrary transition probability to each edge would make the t ask t rivial, and would result in drastic ov er- fitting. Thus, we aim to learn a model (a function) that will assign the t ransition probability for each edge ( u, v ) based on features of nodes u and v , as well as the fea tures of the ed ge ( u, v ) . The ques- tion we address next i s, ho w to directly and in a principled way estimate the parameters of such random walk biasing function? Problem for mulation. W e are g iv en a directed graph G ( V , E ) , a node s and a set of candidates to w hich s could create an edge. W e label nodes to which s creates edges in the future as destina- tion nodes D = { d 1 , . . . , d k } , while we call other nodes to which s does not create edges no-link nodes L = { l 1 , . . . , l n } . W e la- bel candidate nodes wit h a set C = { c i } = D ∪ L . W e thin k of nodes in D as positiv e and nodes in L as nega tiv e training e xam- ples. Later we generalize to multiple instances of s , L and D . Each node and each edge in G is further described with a set of features. W e assume that each edge ( u, v ) has a corresponding feature v ector ψ uv that describes the node s u and v ( e.g. , ag e, gender , hometown) and the interaction att ributes ( e.g. , when the edge w as created, ho w many messages u an d v exchange d, or how many photos the y ap- peared together in). For edge ( u, v ) in G we compute the strength a uv = f w ( ψ uv ) . Function f w parameterized by w takes the edge fea ture vector ψ uv as input and computes the corresponding edge str ength a uv that models t he random walk transition probability . It is exactly the function f w ( ψ ) that we learn in the training phase of t he algorithm. T o predict new edges of node s , first edge str engths of all edges are calculated using f w . Then a rand om walk wit h r estarts is run from s . The stationary distrib ution p of the random walk assign s each node u a probability p u . Nodes are ordered by p u and top ranked n odes are then p redicted as destina tions of future link s of s . No w our task is to learn t he parameters w of function f w ( ψ uv ) that assigns each edge a transition pro bability a uv . One ca n think of t he weights a uv as edge strengths and t he r andom walk i s more likely to traverse edges of high strength and thus nodes connected to node s via paths of strong edges wi ll likely be visited by the random walk and will thus rank highe r . The optimization problem. The training data contains informa- tion t hat source node s wi ll create edges to nodes d ∈ D and not to nodes l ∈ L . So, we aim to set the parameters w of function f w ( ψ uv ) so that it will assign edge weights a uv in such a way that the random walk will be more lik ely to visit no des in D than L , i.e . , p l < p d , for each d ∈ D and l ∈ L . Thus, we define the optimization prob lem to find the optimal set of parameters w of edge strength function f w ( ψ uv ) as follows: min w F ( w ) = || w || 2 such that ∀ d ∈ D, l ∈ L : p l < p d (1) where p is the vector of PageRank scores. Note that PageRank scores p i depend on edge strengths a uv and thus actually depend on f w ( ψ uv ) that is parameterized b y w . The idea here is that we want to find the parameter vector w such that the PageRank scores of nodes in D will be greater than the scores of nodes in L . W e prefer the shortest w parameter vecto r simply for regularization. Ho we ver , Eq. 1 is a “hard” v ersi on of the optimization problem as it allo ws no constraints to be violated. In practice it i s unlikely that a solution satisfying all the constraints exists. Thus similarly to formulations of Support V ector Machines we make the constraints “soft” by introducing a loss function h that penalizes violated con- straints. The optimization pro blem now becomes: min w F ( w ) = || w || 2 + λ X d ∈ D ,l ∈ L h ( p l − p d ) (2) where λ is the regularization parameter that trades-off between the complex ity ( i.e. , norm of w ) for the fit of the model ( i.e. , how much the constraints can be violated). Moreove r , h ( · ) is a loss func tion that assigns a non -negati ve penalty according to the dif ference of the scores p l − p d . If p l − p d < 0 then h ( · ) = 0 as p l < p d and the constraint is not violated, while for p l − p d > 0 , also h ( · ) > 0 . Solving th e optimization problem. First we need to establish the connection be tween the p arameters w of the edge strength function f w ( ψ uv ) and the rando m walk scores p . T hen we sho w how to ob- tain the deriv ative of the loss function and t he random walk scores p wit h r espect to w and then perform gradient based optimization method to minimize the loss and find the optimal parameters w . Function f w ( ψ uv ) combines the attributes ψ uv and the parame- ter v ector w to output a non-ne gative weight a uv for ea ch edge. W e then build the rand om walk stochastic transition matrix Q ′ : Q ′ uv = ( a uv P w a uw if ( u, v ) ∈ E , 0 otherwise (3) T o obtain t he final random walk transition probability matrix Q , we also incorporate the restart probability α , i.e. , with probability α the random walk jumps back to seed node s and thus “restarts”: Q uv = (1 − α ) Q ′ uv + α 1 ( v = s ) . Note that each ro w of Q sums to 1 and thus each entry Q uv defines the conditional probability that a walk will traverse edge ( u, v ) gi ven that it is currently at node u . The vector p is the stationary distribution of the Random walk with r estarts (also kno wn as Personalized PageRank), and is the solution to the following eigen vector equation: p T = p T Q (4) Equation 4 establishes the connection between the node PageR- ank scores p u ∈ p , and parameters w of function f w ( ψ uv ) via the random walk transition matri x Q . Our goal now is to minimize Eq. 2 with respect to the parameter vector w . W e approach this by first deriving t he gradient of F ( w ) with respect to w , and then use a gradient bas ed optimization metho d to fi nd w that minimize F ( w ) . Note that is non-trivial due to the recu rsiv e relation in Eq. 4. First, we introduce a new variable δ ld = p l − p d and then we c an write the deriv ativ e: ∂ F ( w ) ∂ w = 2 w + X l,d ∂ h ( p l − p d ) ∂ w = 2 w + X l,d ∂ h ( δ ld ) ∂ δ ld ( ∂ p l ∂ w − ∂ p d ∂ w ) (5) For commonly used lo ss fun ctions h ( · ) (like, hinge-loss o r squ ared loss), it is simple to compute the deriv ativ e ∂ h ( δ ld ) ∂ δ ld . Howe ver , it is not clear how to compute ∂ p u ∂ w , the deri vati ve of t he score p u with respect to the vector w . Next we sho w how to do this. Note tha t p is the principal eigen vector of ma trix Q . Eq. 4 can be rewritten as p u = P j p j Q j u and taking the deri v ativ e now giv es: ∂ p u ∂ w = X j Q j u ∂ p j ∂ w + p j ∂ Q j u ∂ w (6) Notice that p u and ∂ p u ∂ w are recursi vely entang led in the equation. Ho we ver , we can still compute the gradient iterati vely [4, 3]. By Initialize PageRank scores p and partial deriv ativ es ∂ p u ∂ w k : fo reach u ∈ V d o p (0) u = 1 | V | fo reach u ∈ V , k = 1 , . . . , | w | do ∂ p u ∂ w k (0) = 0 t = 1 while not con ver ged d o fo reach u ∈ V do p ( t ) u = P j p ( t − 1) j Q j u t = t + 1 t = 1 fo reach k = 1 , . . . , | w | do while not con ver ged do fo reach u ∈ V d o ∂ p u ∂ w k ( t ) = P j Q j u ∂ p j ∂ w k ( t − 1) + p ( t − 1) j ∂ Q ju ∂ w k t = t + 1 return ∂ p u ∂ w ( t − 1) Algorithm 1 : Iterativ e po wer-iterator like computation of PageRank ve ctor p and its deriv ativ e ∂ p u ∂ w . recursi vely applying the chain rule to Eq. 6 we can use a power - method like algorithm to compute the deriv ativ e. W e r epeatedly compute the deriv ativ e ∂ p u ∂ w based o n the estimate obtained in the pre vious iteration. T hus, we first compute p and then update the estimate o f the gradient ∂ p u ∂ w . W e stop the algorithm when both p and ∂ p ∂ w do not change ( i. e. , ε = 10 − 12 in our experiments) between iterations. W e arriv e at Algorithm 1 t hat iterati vely comp utes the eigen vector p as well as the partial deriv ative s of p . Con vergence of Algorithm 1 is similar to those of po wer-iteration [5]. T o solve Eq. 4 we further need to compute ∂ Q ju ∂ w which is the partial deriv ativ e of entry Q j u (Eq. 3). This calculation i s straight- forward. W hen ( j, u ) ∈ E we find ∂ Q ju ∂ w = (1 − α ) ∂ f w ( ψ ju ) ∂ w P k f w ( ψ j k ) − f w ( ψ j u ) P k ∂ f w ( ψ jk ) ∂ w P k f w ( ψ j k ) 2 and otherwise ∂ Q ju ∂ w = 0 . The edge str ength function f w ( ψ uv ) must be dif ferentiable and so ∂ f w ∂ w ( ψ j k ) can be easily computed. This completes t he deriv ation and sho ws how to ev aluate the deri v ativ e of F ( w ) (E q. 5). Now we apply a gradient descent based method, lik e a quasi-Ne wton method, a nd directly minimize F ( w ) . Final rema rks. First we note that our problem is not con vex in general, and thus g radient descent method s w ill not nece ssarily fi nd the global minimum . In practice we resolv e this by using several differe nt starting points to find a good solution. Second, since we are only interested in the v alues of p for nodes in C , it makes sense to e valuate the loss func tion at a slightly dif- ferent point: h ( p ′ l − p ′ d ) where p ′ is a normalized v ersion of p such that p ′ u = p u P v ∈ C p v . This adds one more chain rule application to the deriv ativ e ca lculation, but does not change the algorithm. The effe ct of this is mostly to allow larger va lues of α to be used with- out having to change h ( · ) (W e omit the tick marks in our no tation for the rest of this paper , using p to refer t o the normalized score). So far we only considered training and estimating the parameter vector w for predicting the edges of a particular node s . Howe ver , our aim to estimate w that make good predictions across man y dif- ferent nodes s ∈ S . W e easily extend the algorithm t o multiple source nodes s ∈ S , that may ev en reside in different graphs. W e do this by taking t he sum of losses over all source nodes s and the correspondin g pairs of positiv e D s and negati ve L s training exam- ples. W e slightly modify the Eq. 2 to obtain: min w F ( w ) = || w || 2 + λ X s ∈ S X d ∈ D s ,l ∈ L s h ( p l − p d ) The gradients of each i nstance s ∈ S remain indepen dent, and can thus be computed independently f or all instances of s (Alg. 1). By optimizing parameters w over many indi viduals s , the algorithm is less likely to ov erfit, which improv es t he generalization. As a final implementation note, we point out that gradient de- scent often makes many small steps which have small impact on the eigen vector and it s deriv ativ e. A 20% speedup can be achiev ed by using the solutions from the previous position (in t he gradient descent) as initialization fo r the eigen vector and d eriv ativ e calcula- tions in Alg. 1. Our implementation of S upervised Random W alks uses the L-BFGS algorithm [22]. Give n a function and its par- tial deriv ativ es, the solver iteratively impro ves the estimate of w , con verg ing to a local optima. The exact runtime of the method de- pends on ho w many iterations are required for co n vergenc e of both the P ageRank and deri v ative c omputations, as well as of the ov erall process (quasi-Ne wton iterations). 3. EXPERIMENTS ON SYNTHETIC D A T A Before experimenting with real data, we examine the soundness and rob ustness of the proposed algorithm using synthetic d ata. Our goal here is to generate syn thetic gra phs, edge f eatures and training data (triples ( s, D, L ) ) and then try to recov er the original model. Synthetic data. W e generate scale-free graphs G on 10,000 nodes by using the Copying model [18]: Graph starts with three nodes connected in a triad. Remaining nodes arrive one by one, each creating exactly three edges. When a no de u arri ves, it adds three edges ( u, v i ) . Existing node v i is selected uniformly at random with probability 0 . 8 , an d otherwise v i is selected with probability proportional to its curren t deg ree. For each edge ( u, v ) we create two independent Gaussian features with mean 0 and v ariance 1 . W e set the edge streng th a uv = exp ( ψ uv 1 − ψ uv 2 ) , i.e. , w ∗ = [1 , − 1] . For each G , we randomly select one of the oldest 3 nodes of G as the start node, s . T o generate a set of destination D an d no-link nodes L for a giv en s we use the follo wing approach. On the graph with edg e strengths a uv we run the random walk ( α = 0 . 2 ) starting from s and obtain node PageRan k sc ores p ∗ . W e use these scores to g enerate the destination s D in one of two w ays. First is deterministic and selects the top K nodes ac cording t o p ∗ to which s i s not already connected. Second is probabilistic and selects K nodes, selecting each node u with probability p ∗ u . No w giv en the graph G , attributes ψ uv and targets D our goal is to reco ver the true edge strength parameter v ector w ∗ = [1 , − 1] . T o make the task more interesting we also add random noise t o all of the attributes, so that ψ ′ uv i = ψ uv i + N (0 , σ 2 ) , where N (0 , σ 2 ) is a Gaussian random v ariable with mean 0 and v ariance σ 2 . Results. After applying our algorithm, we are interested in two things. First, how well does t he model perform in terms of t he classification accuracy and second, whether it recovers the edge strength function parameters w ∗ = [1 , − 1] . In the deterministic case of creating D and with 0 noise added, we hope that the al- gorithm is able achiev e near perfect classification. As the noise increases, we expect the performance to drop, but ev en then, we hope that the recov ered valu es of ˆ w will be close to true w ∗ . 0.92 0.93 0.94 0.95 0.96 0.97 0.98 0.99 1 0 0.5 1 1.5 2 AUC Noise Level Performance on Synthetic Data Generated Deterministically Unweighted Pagerank Weights +1,-1 Learned Weights Figure 1: Experiments on synthetic data. Deterministic D . 0.74 0.76 0.78 0.8 0.82 0.84 0.86 0.88 0 0.5 1 1.5 2 AUC Noise Level Performance on Synthetic Data Generated Probabilistically Unweighted Pagerank Weights +1,-1 Learned Weights Figure 2: Experiments on synthetic data. Pr obabilistic D . In r unning the experiment we generated 100 synthetic graphs. W e use d 50 of them for training the weights w , and r eport results on the other 50. W e compute Ar ea under the R OC curve (A UC ) of each of 50 test graphs, and report the mean (A UC of 1.0 means perfect classification, while random guessing scores 0.5). Figures 1 and 2 sho w the results. W e plot t he performan ce of the model that ignores edge weights (red), the model with true weights w ∗ (green) and a model with learned weights ˆ w (blue). For the determin istically generated D (Fig. 1 ), the performance is perfect in the absence of any noise. This is good news as it demonstrates that our training procedure is able to recover the cor- rect parameters. As the noise i ncreases, the performance slowly drops. When the noise reaches σ 2 ≈ 1 . 5 , using the true parame- ters w ∗ (green) actually becomes worse tha n simply ignoring them (red). Mo reov er, o ur algorithm learns the t rue parameters [+1 , − 1] almost perfectly in the noise-free case, an d decreases their magni- tude as the noise lev el increases. This matches the intuition that, as more and more noise is added, the signal in the edge attributes becomes weaker and weaker relatively to the signal i n t he graph structure. Thus, wi th more noise, t he parameter va lues w decrease as they are gi ven less and less credence. In the probabilistic case (Fi g. 2), we see that our algorithm does better (statistically significant at p = 0 . 01 ) than the model with true parameters w ∗ , regard less of the presence or ab sence of noise. Even t hough the data was generated using parameters w ∗ = [+1 , − 1] , these values are not op timal and o ur model gets better A UC by find- ing different (smaller) v alues. Again, as we add noise, the overall performance slo wly drops, but stil l doe s much better than the base- line method of ignoring edge strengths ( red), and continues to do better than the model that uses true parameter v alues w ∗ (green). W e also no te that regardless of where we initialize t he parameter 0.001 0.01 0.1 1 0 2 4 6 8 10 12 14 0.0001 0.001 0.01 0.1 Probability of becoming friends (Hep + Astro) (Facebook) Number of mutual friends Probability of Friendship vs. Number of Mutual Friends Astro Hep-ph Facebook Figure 3: Probability of a new link as a f unction of the number of mutual friends. Figure 4: F acebook Iceland: Hop distance between a pair of nodes just befo re they b ecome friends. Distance x=-1 denotes nodes th at were in separate components, wh ile x=2 (friends of friends) is order of magnitude higher than next highest point. vector w before starting gradient descent, it always con verg es t o the same solution. Having thus validated our algorithm on synthetic data, we no w mov e on to predicting links in real social networks. 4. EXPERIMENT AL SETUP For e xperiments on real data we consider four real physics co- authorship networks and a complete Faceb ook network of Iceland. Generally we focus on predicting l inks to nodes that are 2-hops from the seed no de s . W e do t his for two reasons. First, in online social networks more t han half of all edges at the time of creation close a tr iangle, i.e. , a person connects to a friend of a friend [19]. For instance, Figure 4 sho w s that 92% of all edges created on Face- book Iceland clo se a path of length two, i.e . , a triangle. Second, this also makes the Supervised Random W alks run faster as graphs get smaller . Gi ven that some Facebook users have d egrees in the thou- sands, it is not practical to incorporate them (a user may hav e as many as a hundred million nodes at 3 hop s). Co-authorship networks. First we consider the co-authorship ne t- works from arXiv e-print archiv e [12] where we hav e a time-stamped list of all papers with author names and ti tles submitted to arXiv during 1 992 an d 2002. W e con sider co-au thorship ne tworks fr om four different areas of physics: Astro-physics (Astro-Ph), Con- densed Matter (Cond-Mat), High energ y physics theory (Hep-th) and High energy physics phenomenology (Hep-ph). For each of the networks we proceed as fo llows. For e very node u we compute the total number of co-authors at the end of the dataset ( i.e. , net- N E S ¯ D ¯ C ¯ D/ ¯ C Astro-Ph 19,144 198,110 1,123 18.0 775.6 0.023 Cond-Mat 23,608 94,492 140 9.1 335.5 0.027 Hep-Ph 12,527 118,515 340 29.2 345.3 0.084 Hep-Th 10,700 25,997 55 6.3 110.5 0.057 Faceboo k 174,000 29M 200 43.6 19 87 0.022 T able 1: Dataset statistics. N , E : number of nodes and edges in the fu l l network, S : number of sour ces, ¯ C : avg . n umber of candidates per source, ¯ D : a vg. number of d estination nod es. work de gree) k u and let t u be the time whe n u created it’ s k u / 2 -th edge. Then we define m u to be the number of co-authorship links that u created after time t u and that at th e time of creation spa nned 2-hops ( i. e. , closed a triangle). W e at tempt to make predictions only for “active” authors, where we define a node u to be activ e if k u ≥ K and m u ≥ ∆ . In t his work, we set K = 10 and ∆ = 5 . For e very source node s that is abov e this threshold, we extract the network at time t s and try to predict the d s ne w edges that s creates in the time after t s . T able 1 gi ves dataset statistics. For e very edge ( i, j ) of the netwo rk around the source node u at time t u we generate the follo wi ng six features: • Number of papers i written before t u • Number of papers j written before t u • Number of papers i and j co-autho red • Cosine simil arity between the titles of papers written by i and titles of j ’ s papers • Time since i and j last co-au thored a paper . • The number of common friends between j and s . The Fa cebook network. Our second set of data comes from the Faceboo k online social netwo rk. W e fi rst selected Iceland since it has high Facebook penetration, but relative ly few edges pointing to users in other countries. W e generated our data based on the state of the F acebook graph on No vember 1, 2009 . The destination nodes D from a node s are those that s became friends with be- tween Novem ber 1 2009 and January 13 2010. The Iceland graph contains mo re than 174 thousa nd people, or 55% of the country’ s population. The av erage user had 168 friends, and during the pe- riod Nov 1 – Jan 23, an a verage p erson added 26 new friends. From these users, we randomly selected 200 as the nodes s . Again, we only selected “activ e” nodes, this ti me with the crit e- ria | D | > 20 . As Figure 3 shows, in di viduals without many mutua l friends are e xceedingly unlik ely to become friends. As the Face- book graph c ontains users whose 2-ho p neighborho od have se veral million nodes we can prune such grap hs and speed-up the compu- tations without loosing much on p rediction performance. Since we kno w that individu als with only a few mutual friends are un likely to form friendships, and our goal is to predict the most likely friend- ships, we remove all individu als wi th less than 4 mutual friends with practically no loss in performance. As demonstrated in Fig- ure 3, if a user creates an edge, then the probability that she links to a node with whom she has less than 4 friends is about 0 . 1% .). W e annotated each edge of t he Faceboo k network with seve n features. For each edge ( i, j ) , we created: • Edge age: ( T − t ) − β , where T is the time cuto ff Nov . 1, an d t is the edge creation time. W e create three features like this with β = { 0 . 1 , 0 . 3 , 0 . 5 } . • Edge initiator: Indiv idual making the fri end request is en- coded as +1 or − 1 . • Communication and o bserv ation features. They represent the probability of communication and profile observation in a one week period. • The number of common friends between j and s . All features in all datasets are re-scaled to hav e mean 0 and standard de viati on 1. W e also add a constant feature with valu e 1. Evaluation methodology . For each dataset, we assig n half of the nodes s into training an d half into test set. W e use the training set to train the algorithm ( i.e. , estimate w ). W e e v aluate the method on the t est set, considering two performa nce metrics: the Area under the ROC curve (A UC) and the Precision at T op 20 (Prec@20), i.e. , ho w many of top 20 nodes suggested by our algorithm actually recei ve li nks from s . This measure is particularly appropriate in the c ontext of link -recommendation whe re we present a u ser with a set of friendship su ggestions and aim tha t most of them are correct. 5. EXPERIMENTS ON REAL D A T A Next w e describe the results of on five real datasets: four co- authorship networks and the Facebo ok network of Iceland. 5.1 General considerations First we ev aluate se veral aspects of our algorithm: (A) the choice of the l oss function, (B) the choice of the edge strength function f w ( · ) , (C) the ch oice of random w alk r estart (jump) parameter α , and (D) choice of regularization p arameter λ . W e also consid er the extension where we learn a separate edge weight vecto r depending on the type of the edge, i.e. , whether an edge touc hes s or any of the candidate nodes c ∈ C . (A) Choice of th e loss function. As is the case with most machine learning algorithms, the choice of loss function plays an important role. Ideally we would like to op timize the loss function h ( · ) which directly corresponds to ou r ev aluation metric ( i.e. , A UC or Preci- sion at top k ). Howe ver , as such loss functions are not con tinuous and not dif ferentiable and so i t is not clear how to optimize ov er them. Instead, we ex periment with three common loss functions: • Squared loss with margin b : h ( x ) = max { x + b, 0 } 2 • Huber loss with margin b and windo w z > b : h ( x ) = 0 if x ≤ − b , ( x + b ) 2 / (2 z ) if − b < x ≤ z − b , ( x + b ) − z / 2 if x > z − b (7) • Wilcoxo n-Mann-Whitne y (WMW) loss with width b (P ro- posed to be used when one aims to maximize A UC [32]): h ( x ) = 1 1 + ex p ( − x/b ) Each of these l oss functions is differentiable and needs to be e v aluated for all pairs of nodes d ∈ D and l ∈ L (see Eq. 2). Per- forming this naiv ely t akes approximately O ( c 2 ) where c = | D ∪ L | . Ho we ver , we next show that the first two loss function s h av e the ad- v antage that they can be computed i n O ( c log c ) . For ex ample, we rewrite the squa red loss as: X d,l h ( p l − p d ) = X l,d : p l + b>p d ( p l − p d + b ) 2 = X l X d : p l + b>p d ( p l + b ) 2 − 2( p l + b ) p d + p 2 d = X l |{ d : p l + b > p d }| ( p l + b ) 2 − 2( p l + b ) X d : p l + b>p d p d + X d : p l + b>p d p 2 d 0.6 0.62 0.64 0.66 0.68 0.7 0.72 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 AUC α Effect of α value on Hep-ph performance Learned weights Unweighted Figure 5: Impact of random walk restart parameter α . Once we ha ve the lists { p l } and { p d } sorted, we can it erate o ver the l ist { p l } i n rev erse order . As we do this, we can incrementally update the two terms which sum ov er d abo ve. The Hub er loss can as well be quickly e valuated using a similar calculation. Computation of the W MW loss is mo re ex pensi ve, as there is no way to go around the summation ov er all pairs. Evaluating WMW loss thus takes time O ( | D | · | L | ) . In our case, | D | is typically relativ ely small, and so the computation is not a significant part of total runtime. Howe ver , the primary advan tage of i t is that it performs slightly better . Indeed, in the limit as b goes to 0, i t reflects A UC, as it measures the number of in version s in the ordering [32]. In our experiments we notice that while the gradient descent achie ves significant redu ction in t he value o f the loss for all three loss functions, this only translates to improved A UC and P rec@20 for the W MW loss. In fact, the model trained with the squ ared or the Huber loss do es not perform much better than the ba seline we obtain through unweighted PageRank. Consequ ently , we use the WMW loss function for the remainder of this work. (B) Choice of edge strength functi on f w ( ψ uv ) . The edge strength function f w ( ψ uv ) must be non-negati ve and differen tiable. While more complex f unctions are certainly possible, we exp eriment with two f unctions. In bo th ca ses, we start b y taking the inner product of the weight vector w and the feature vector ψ uv of an edg e ( u, v ) . This yields a single scalar v alue, which may be negati ve. T o trans- form t his into the desired domain, we apply either an e xponential or logistic function: • Exponential edge strength: a uv = exp( ψ uv · w ) • Logistic edge strength: a uv = (1 + exp( − ψ uv · w )) − 1 Our experimen ts show that the choice of the edge str ength func- tion does not seem t o make a significant impact on performance. There is slight eviden ce from our experiments that the logistic func- tion performs better One problem that can o ccur with the e xponen- tial version i s underflo w and overflo w of dou ble precision floating point numbers. As the performance seems quite comparable, we recommend the use of the logistic to av oid this potential pitfall. (C) Choice of α . T o get a handle on the impact of random walk restart parameter α , it is useful to t hink of the extreme cases, fo r un- weighted grap hs. When α = 0 , the PageRank of a node in an undi- rected graph is simply i ts de gree. On the other hand, when α ap- proaches 1, the score wil l be exactly propo rtional to the “Random- Random” model [19] which simply makes two random hops f rom s , as random walks of length greater than 2 become increasingly unlikely , and hence the normalized eigenv ector scores become the same as the Random-Random scores [19]. W hen we add the notion of edge streng ths, these properties remain. Intuiti vely , α controls for how “far” the walk wanders from seed node s before it restarts and jumps back to s . Hi gh v alues of α giv e very short and local random walks, while lo w va lues allow the w alk to go farther aw ay . When ev aluating on r eal data we observe that α plays an impor- tant role in the simple unweighted case when we ignore the edg e strengths, but as we gi ve the algorithm more po wer to assign dif- ferent st rengths to edges, the role of α diminishes, and we see no significant difference in performance for a broad rang e of choices α . Figure 5 illustrates this; in the unweighted case ( i.e. , i gnoring edge strengths) α = 0 . 3 performs best, while in the weighted case a broad range from 0 . 3 to 0 . 7 seem to do about equally well. (D) Regularization parameter λ . Empirically we find that ov er- fitting is not an issue in our model as the number of parameters w is relativ ely small. Sett ing λ = 1 giv es best performance. Extension: Edge t yp es. The Supervised R andom W alks frame- work we hav e presented so far captures the idea that some edges are stronger than others. Howe ver , it doesn’t allow for different types of edges. For instance, it might be that an edge ( u, v ) be- tween s ’ s friends u and v should be treated differently than the edge ( s, u ) between s and u . Our model can easily capture this idea by declaring dif f erent e dges to be of dif ferent ty pes, and learn- ing a different set of feature weights w for each edge type. W e can take the same approach to learning each of these weights, comput- ing partial d eriv ativ es wi th resp ect to eac h one weigh t. T he price for this is potential ov erfit ting and slower runtime. In our exp eriments, we find that dividing the edge s u p into multi- ple types provide s significant b enefit. Gi ven a seed node s we label the edges according to t he hop-distance from s of their endp oints, e.g . , edges ( s, u ) are of type (0,1), edges ( u, v ) are ei ther of type (1,1) (if both u and v l ink to s ) or (1,2) (if v does not link to s ). Since the nodes are at distance 0, 1, or 2 from s , there are 6 p os- sible edge types: (0,1), (1,0), (1,1), (1,2), (2,1) and (2,2). While learning six sets of more parameters w increases the runtime, using multiple edge types gi ves a significant increase in performance. Extension: Social capital. Before moving on to the experimental results, we also briefly examine somewhat counterintuiti ve beh av- ior of the Random W alk wi th Restarts. Consider a graph in Figure 6 with the seed node s . T here are two node s which s cou ld form a ne w connec tion to v 1 and v 2 . These two are symmetric except for the fact that the two paths connecting s to v 1 are connected them- selves. Now we ask, is s more likely to link to v 1 or to v 2 ? Building on the theory of embe ddedness an d social capital [10] one wou ld postulate that s is more likely to link to v 1 than to v 2 . Ho we ver , the result of an edge ( u 1 , u 2 ) is that when α > 0 , v 2 ends up wi th a higher PageRank score than v 1 . This is somewh at counterintuiti ve, as v 1 someho w seems “more con nected” to s than v 2 . Can we remedy this in a natural w ay? One solution could be that carefully setting α resolves the is- sue. Howe ver , there is no valu e of α > 0 which will make the score of v 1 higher than v 2 and changin g to other simple teleport- ing schem es (such as a random jump to a random no de) does no t help either . Howe ver , a simple correction t hat w orks is to add the number of f riends a node w has in common with s , and use this as an additional feature γ on each edge ( u, w ) . If we apply this to the graph sho wn in Figure 6, and set the weight along each edge to 1 + γ , then the PageRank score p v 1 of node v 1 is 1.9 greater than of v 2 (as opposed to 0.1 smaller as in Fig 6). In practice, we find that introducing this additional feature γ helps on the Facebook graph. In Facebook, connection ( u 1 , u 2 ) increases the probability of a link forming to v 1 by about 50%. In the co-authorship networks, the presence of ( u 1 , u 2 ) actually de- creases the link formation probability by 37%. Such behavior of Figure 6: Stationary rand om walk di stribution with α = 0 . 15 . 0.805 0.81 0.815 0.82 0.825 0.83 0 10 20 30 40 50 60 70 80 90 100 18 18.5 19 19.5 20 20.5 AUC Loss Iteration Learning Curve for Facebook Data Training AUC Test AUC Training Loss Testing Loss Figure 7: P erf ormance of S u pervised Random W alks as a fun c- tion of the nu mber of steps of parameter esti mation procedure. co-authorship ne tworks c an be explained by the ar gument that lon g range weak t ies help i n access to ne w information [14] ( i.e. , s i s more lik ely to link to v 2 than v 1 of Fig 6). Having two ind ependent paths is a stronger connection in the co-authorship graph, as this indicates that s ha s written papers with two people, on two differ- ent occasion s, and both o f these pe ople ha ve written with the targ et v , also on two different occasions. Thus, there must be at least four papers between these four people when the edge ( u 1 , u 2 ) is absent, and there may be as fe w as two when it i s pres ent. Note this is exactly the opposite to the social capital argument [10], w hich postulates that individ uals who are well embedded in a network or a community have higher trust and get more support and info rma- tion. This is i nteresting as it shows that Facebook is about social contacts, norms, trying to fit in an d be well emb edded in a circle of friends, while co-authorsh ip networks are about access to informa- tion and establishing long-range weak ties. 5.2 Experimen ts on r eal data Next we e v aluate the predictiv e performance of S upervised Ran - dom W alks (SR W) on real da tasets. W e examine the performance of the parameter estimation and then compare Supervised Random W alks to other link-prediction methods. Parameter estimation. F igure 7 shows the resu lts of gradien t de- scent on the Facebo ok dataset. At iteration 0, we start wi th un- weighted random walks, by setting w = 0 . Usi ng L-BFGS we perform grad ient descent on t he WMW loss. Notice the strong cor- relation between A UC and WMW loss, i.e . , as the va lue of the loss decreases, A UC increa ses. W e also note t hat the method basically con verg es in only about 25 it erations. Comparison to oth er methods. Next we compare the predicti ve performance of S upervised Random W alks (SR W) to a number of simple unsu pervised baselines, along with two supervised mach ine learning methods. Al l results are ev aluated by creating two inde- Learning Method A UC Prec@20 Random W alk with Restart 0.63831 3.41 Adamic-Adar 0.60570 3.13 Common Friends 0.59370 3.11 Degree 0.56522 3.05 DT : Node features 0.60961 3.54 DT : Network features 0.59302 3.69 DT : Node+Network 0.63711 3.95 DT : Path features 0.56213 1.72 DT : All features 0.61820 3.77 LR: Node features 0.64754 3.19 LR: Network features 0.58732 3.27 LR: Node+Netwo rk 0.64644 3.81 LR: Path features 0.67237 2.78 LR: All features 0.67426 3.82 SR W: one edge type 0.69996 4.24 SR W: multi ple edge types 0.71238 4.25 T able 2: Hep-Ph co-authorship network. DT : decision tree, LR: logistic regr ession, and SR W : Supervised Random W alks. Learning Method A UC Prec@20 Random W alk with Restart 0.81725 6.80 Adamic-Adar 0.81586 7.35 Common Friends 0.80054 7.35 Degree 0.58535 3.25 DT : Node features 0.59248 2.38 DT : Network features 0.76979 5.38 DT : Node+Network 0.76217 5.86 DT : Path features 0.62836 2.46 DT : All features 0.72986 5.34 LR: Node features 0.54134 1.38 LR: Network features 0.80560 7.56 LR: Node+Netwo rk 0.80280 7.56 LR: Path features 0.51418 0.74 LR: All features 0.81681 7.52 SR W: one edge type 0.82502 6.87 SR W: multi ple edge types 0.82799 7.57 T able 3: Results for the Facebook dataset. pendent datasets, one for training and one f or testing. Each perfor- mance va lue is the ave rage ove r all of the graphs in the test set. Figure 8 shows the ROC curve for Ast ro-Ph dataset, compar- ing our method to an unweighted r andom walk. Note that much of the improv ement in the curve comes in the area near the ori- gin, correspo nding to the nodes with the high est predicted v alues. This is the area that we most care about, i.e. , since we can only display/recommend about 20 potential tar get nodes to a Facebook user we wa nt the top of the ranking to be p articularly good (and do not care about errors tow ards the bottom of the ranking). W e compare the S upervised Random W alks t o unsupervise d link - prediction methods: plain Random W alk with Restarts, Adamic- Adar score [1], number of common friends, and node de gree. For supervised machine learning methods we experiments with deci- sion trees and l ogistic regression and group the features used f or training them into three groups: • Network features: unweig hted random walk sc ores, Adamic- Adar score, number of common friends, and d egrees of nodes s and the potential target c ∈ C • Node features: avera ge of the edge features for those edges incident to the nodes s and c ∈ C , as described in Section 4 • Path features: ave raged edge features ov er all paths between seed s and the potential destination c . Dataset A UC Prec@20 SR W LR SR W LR Co-authorship Astro-Ph 0.70548 0.67639 2.55 2.15 Co-authorship Cond-Mat 0.74173 0.71672 2.54 2.61 Co-authorship Hep-Ph 0.71238 0.67426 4.18 3.82 Co-authorship Hep-Th 0.72505 0.69428 2.59 2.61 Faceboo k (Iceland) 0.82799 0.81681 7.57 7.52 T able 4: Results for all datasets. W e compar e fa vor ably to lo- gistic features as run on all features. Our Supervised Ran d om W alks (SRW) perform signifi cantly better than the baseline in all ca ses on ROC area. The v ariance is too high on the T op20 metric, an d the two methods are statisti cally tied on this metric. 0 0.2 0.4 0.6 0.8 1 0 0.2 0.4 0.6 0.8 1 Fraction Positives Fraction Negatives ROC Curve for SRW and RW w/ Restart Random Walk w/ Restarts Supervised Randow Walk Figure 8: ROC curv e of Astro-Ph test d ata. T ables 2 and 3 compare the results of various methods on the Hep-Ph co-autho rship and Facebook n etworks. In general, we note very perfo rmance of Superv ised Random W alks (SR W): A UC is in the range 0.7–0.8 an d precision at top 20 i s be tween 4.2–7 .6. W e consider this surprisingly good performance. For example, in case of Facebook this means that out of 20 friendships we recommend nearly 40% of them realize in near future. Overall, Supervised Random W alks (S R W) give a significant im- prov ement o ver the unweighted Random W alk with Restarts (R W R). SR W also giv es gains ov er other techniques such as logistic re- gression which combine features. For example, in co-authorship network (T ab . 2) we note that unsupervised R WR outperforms de- cision trees and slightly trails logistic re gression in terms of A UC and Prec@20. Supervised Rando m W alks outperform all methods. In terms of A UC we get 6% and in terms of P rec@20 near 12% relativ e improv ement. In Facebook (T ab. 3), Random W alk with Restarts already giv es near-optimal A UC, while Supervised Ran- dom W alks still obtain 11% relativ e improv ement in Prec@20. It is important to note that, in addition to outperforming the other methods, Superv ised Rando m W alks do so without the tedious pro- cess of feature extraction. There are many network features relating pairs of unco nnected nod es ( Adamic-Adar was the best out of the dozens examined in [21], for example). Instead, we need only se- lect the set of node and edge att ributes, and Supervised Random W alks take care of determining ho w to combine them with the net- work structure to make pre dictions. Last, T able 4 compares the performance of top two methods: Su- pervised Random W alks and logistic regression. W e note that Su- pervised R andom W alks compare fa vorab ly to logistic re gression. As log istic re gression requires state of the art netwo rk feature ex- traction and Supervised Random W alks outperforms it out of the box and without any ad hoc feature enginee ring. When we examine t he weights assigned, we find that for Fa ce- book the larg est weights are those which are related t o time. This makes sense as if a user has just made a new friend u , she is likely to hav e also recently met some of u ’ s friends. In the co- authorship networks, we find t hat the number of co-authored pa- pers and the cosine similarity amongst titles were the features with highest weights. Runtime. While the e xact runtime o f Supervised Random W al ks is highly dependent on the graph st ructure and f eatures used, w e gi ve some rough guidelines. T he results here are for single runs on a single 2.3Ghz processor on the Faceboo k dataset. When putting all edges in the same category , we hav e 8 weights to learn. It took 98 iterations of t he quasi-Newton method to con- ver ge and minimize the loss. This required com puting the PageR- anks of all the nodes in all the graphs (100 of them) 123 times, along with the partial deri v ativ es of each of the 8 parameters 123 times. On average, each PageRank computation took 13.2 steps of power-iteration before con verging, while each partial deriv ative computation took 6.3 iterations. Each iteration for PageRank or its deriv ativ e takes O ( | E | ) . Overall, the parameter estimation on Faceboo k network took 96 minutes. By contrast, increasing the number of ed ge type s to 6 (which giv es best performanc e) required learning 48 weights, and increase d the training time to 13 hours on the Faceboo k dataset. 6. CONCLUSION W e hav e prop osed Supervised Random W alks, a ne w learning al- gorithm for link prediction and link recommendation. By utilizing node and edge attrib ute data our method guides the random walks to wards the desired target nodes. Experiments on F acebook and co- authorship networks demonstrate good generalization and ov erall performance of Supervised Rando m W alks. T he resulting predic- tions show large improv ements ov er Random W alks with Restart s and compare fav orably to supervised mac hine learning techniques that req uire tedious feature extraction and generation. In con trast, our approach requires no network feature generation and i n a prin- cipled w ay combines rich node and edge feature s with the structure of the network to make reliable pred ictions. Supervised R andom W alks are no t limited to l ink p rediction, and can be applied to many other problems that req uire learning to rank nodes i n a graph, like recommendations, anomaly detection, miss- ing link, and expertise search and ranking . Acknowledgements. W e thank Soumen Chakrabarti for discus- sion. Research was in-part supported by NSF CNS-1010921, NSF IIS-1016909, AFRL F A8650-10-C-705 8, Albert Y u & Mary Bech- mann Foundation , IBM, Lightspeed, Microsoft and Y ahoo. 7. REFERENCES [1] L. Adamic and E. Adar . Friends and neighbors on the web . Social Networks , 25(3):211– 230, 2003. [2] A. Agarwal and S. Chakrabarti. Learning rando m walks to rank nodes in graphs. In ICML ’07 , pages 9–16, 2007. [3] A. Agarwal, S. Chakrabarti, and S. Aggarw al. Learning to rank network ed entities. In KDD ’06 , pages 14–23, 2006. [4] A. Andre w . Iterative computation of deriv ativ es of eigen value s and eigen vectors. IMA Jou rnal of Applied Mathematics , 24(2):209–21 8, 1979. [5] A. L. Andre w . Con vergence of an iterativ e method for deri v ativ es of eigensystems. Jou rnal of Computational Physics , 26:107–11 2, 1978. [6] L. Backstrom, D. P . Huttenloch er , J. M. Kleinberg, and X. Lan. Group formation in large so cial networks: membership, gro wth, and ev olution. In KDD ’06 , pages 44–54, 2006. [7] A.-L . Barabási and R. Albert. Emergen ce of scaling in random networks. Scienc e , 286:509–512, 1999. [8] A. Blum, H. Chan, and M. Rwebangira. A random-surfer web-graph model. In ANALCO ’06 , 2006. [9] A. Clauset, C. Moore, and M. E. J. Newman. Hierarchical structure and the prediction of missing links in network s. Natur e , 453(7191):98–10 1, M ay 2008. [10] J. Coleman. Social Capital in the Creation of Human Capital. The American J ournal of Sociolog y , 94:S95–S120, 1988. [11] M. Diligenti, M. Gori, and M. Maggini. Learning web page scores by error back-propag ation. In IJCAI ’05 , 2005 . [12] J. Gehrke, P . Ginsp arg, and J. M. Kleinber g. Overvie w of the 2003 kdd cup. SIGKDD Explorations , 5(2):14 9–151, 2003. [13] M. Gomez-Rodriguez, J. Lesko vec, and A. Krause. Inferring networks of dif f usion and influence. In KDD ’10 , 2010 . [14] M. S. Granovetter . The strength of weak ties. American J ournal of Sociolog y , 78:1360–1380 , 1973. [15] T . H. Hav eliwala. T opic-sensiti ve pagerank. In WWW ’02 , pages 517–526 , 2002. [16] K. Henderson and T . Eliassi-Rad. Applying latent dirichlet allocation to group discov ery in large graphs. In SA C ’09 , pages 1456–14 61. [17] G. Jeh and J. Widom. Scaling personalized web search. In WWW ’03 , pages 271–27 9, 2003. [18] R. Kumar , P . Ragha van, S. Rajagopalan, D. Siv akumar , A. T omkins, and E. Upfal. Stochastic models for the web graph. In FOCS ’00 , page 57, 2000. [19] J. Lesko vec, L. Backstrom, R. Kumar , and A. T omkins. Microscopic e volution of social netw orks. In KDD ’08 , pages 462–470 , 2008. [20] J. Lesko vec, J. M. Kleinberg, and C. Falou tsos. Graphs ov er time: den sification laws, shrinking diameters and possible explan ations. In KDD ’05 , pages 177–187, 2005. [21] D. Liben-Nowell and J. Kleinber g. The link prediction problem for social netwo rks. In CIKM ’03 , pages 556–559, 2003. [22] D. Liu and J. Nocedal. On the limited memory bfgs method for large sc ale optimization. Mathematical Pr ogr amming , 45:503–5 28, 1989. 10.1007/BF01589116. [23] R. Minko v and W . W . Cohen. Learning to rank typed graph walks: Local and global approaches. In W ebKDD/SNA-KDD ’07 , pages 1–8, 2007. [24] S. Myers and J. Lesko vec. On the con vex ity of latent social network inference. In NIPS ’10 , 201 0. [25] L. Page, S. Brin, R. Motwan i, and T . W i nograd. The pagerank citation ranking: Bringing ord er to the web . T echnical report, Stanford Dig. Lib . T ech. Proj., 1998. [26] A. Popescul, R. Popescul, and L. H. Ungar . Statistical relational learning for link prediction, 2003. [27] P . Sarkar and A. W . Moore. Fast dy namic reranking in large graphs. In WWW ’09 , pages 31–40, 2009. [28] B. T askar, M. F . W ong, P . Abbee l, and D. Ko ller . Link prediction in relational data. In NIPS ’03 , 2003. [29] H. T ong and C. Faloutsos. Center-piece subg raphs: problem definition and fast solution s. In KDD ’06 , pages 404–413, 2006. [30] H. T ong, C. Faloutsos, an d Y . Koren. Fast direction-aw are proximity for graph mining. In KDD ’07 , pages 747–7 56, 2007. [31] T . T ong, C. Faloutsos, and J.-Y . Pan. Fast rand omwalk with restart and its applications. In ICDM ’06 , 2006. [32] L. Y an, R. Dodier , M. Mozer , and R. W olniewicz. Optimizing classifier performance via an approximation to the wilcoxon-mann-wh itney statistic. In ICML ’03 , pages 848–85 5, 2003.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment