Ladder Networks for Emotion Recognition: Using Unsupervised Auxiliary Tasks to Improve Predictions of Emotional Attributes
Recognizing emotions using few attribute dimensions such as arousal, valence and dominance provides the flexibility to effectively represent complex range of emotional behaviors. Conventional methods to learn these emotional descriptors primarily foc…
Authors: Srinivas Parthasarathy, Carlos Busso
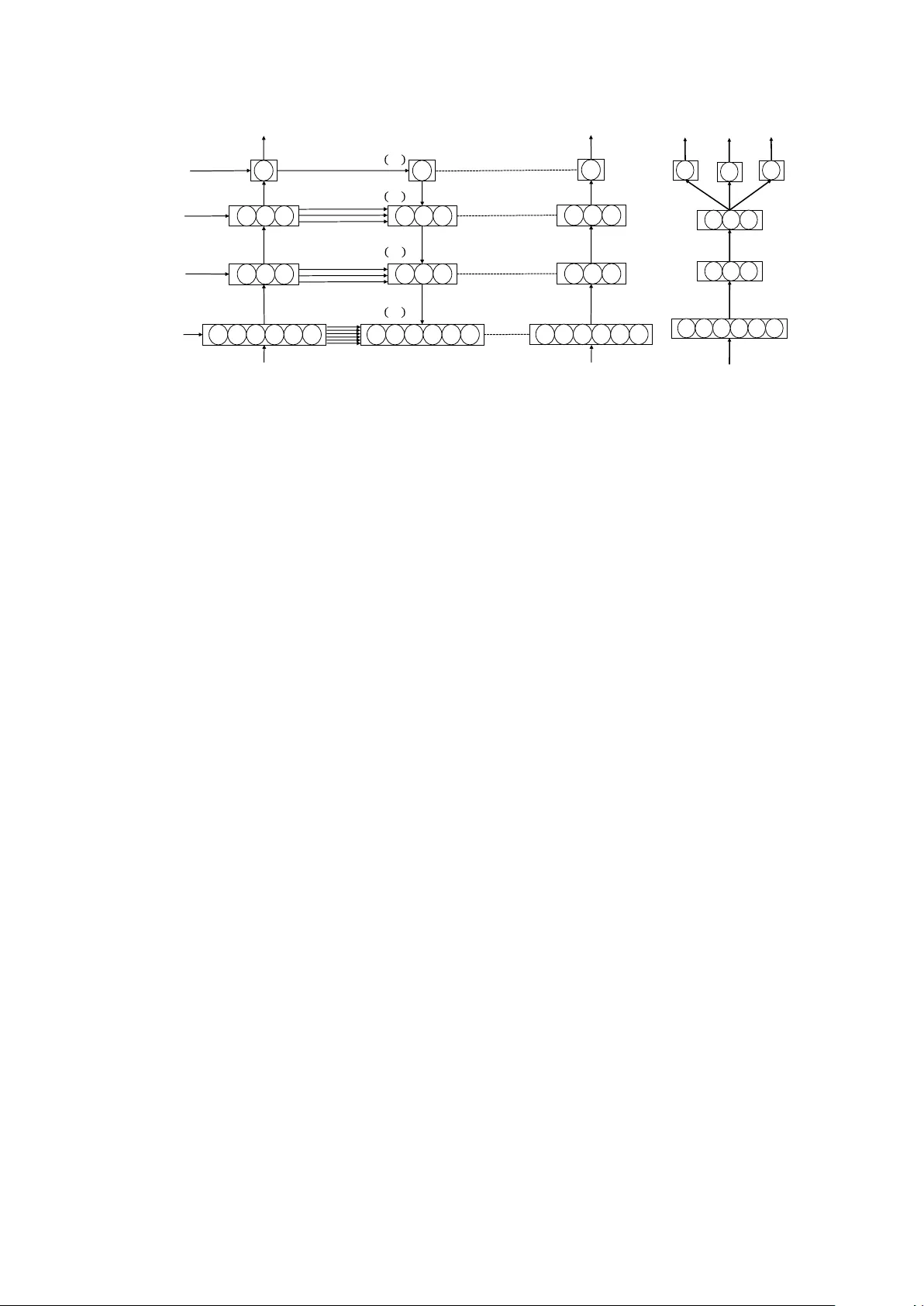
Ladder Networks f or Emotion Recognition: Using Unsupervised A uxiliary T asks to Impr ove Pr edictions of Emotional Attributes Srinivas P arthasar athy and Carlos Busso Multimodal Signal Processing(MSP) lab, Department of Electrical and Computer Engineering The Uni versity of T exas at Dallas, Richardson TX 75080, USA sxp120931@utdallas.edu, busso@utdallas.edu Abstract Recognizing emotions using few attrib ute dimensions such as arousal, v alence and dominance provides the flexibility to ef- fectiv ely represent complex range of emotional beha viors. Con- ventional methods to learn these emotional descriptors primar- ily focus on separate models to recognize each of these at- tributes. Recent work has shown that learning these attributes together regularizes the models, leading to better feature rep- resentations. This study explores new forms of regularization by adding unsupervised auxiliary tasks to reconstruct hidden layer representations. This auxiliary task requires the denois- ing of hidden representations at e very layer of an auto-encoder . The frame work relies on ladder networks that utilize skip con- nections between encoder and decoder layers to learn po werful representations of emotional dimensions. The results show that ladder networks improve the performance of the system com- pared to baselines that individually learn each attribute, and con ventional denoising autoencoders. Furthermore, the unsu- pervised auxiliary tasks have promising potential to be used in a semi-supervised setting, where few labeled sentences are av ail- able. Index T erms : speech emotion recognition, regularization. 1. Introduction Affecti ve computing plays an important role in human com- puter interaction (HCI). Emotions are conv entionally repre- sented with discrete classes such as happiness, sadness, and anger [1–3]. An alternativ e emotional representation is through attribute dimensions such as arousal (calm versus activ e), va- lence (negati ve versus positive) and dominance (weak versus strong) [4–7]. These attribute dimensions provide the flexibil- ity to represent multiple complex emotional behaviors, which cannot be easily captured with cate gorical descriptors. Further- more, attribute dimensions can represent v arying intensities of emotional externalizations which are lost when we use broad categorical descriptors such as “anger” (e.g., cold versus hot anger). Therefore, constructing models that can accurately pre- dict attribute scores is an important research problem. Con ventionally emotional attributes are individually mod- eled [8], assuming that the attribute dimensions are orthogonal to each other . Ho wever , previous studies hav e sho wn significant correlation between different attributes [9]. This observation strongly suggests the need for jointly modeling multiple emo- tional attributes. An appealing way to do this task is through multi-task learning (MTL) where auxiliary tasks representing various emotional attributes are jointly learned [10, 11]. Learn- ing the auxiliary task along with the primary task regularizes the learning process and the models generalize better . While MTL generalizes the models, it requires labeled data (supervised auxiliary tasks). Regularization can also be per- This work was funded by NSF CAREER a ward IIS-1453781. formed with the help of unsupervised auxiliary tasks [12, 13]. One appealing approach is the reconstruction of intermedi- ate feature representations using autoencoders [14]. Generally these unsupervised auxiliary tasks are performed as pre-training which is follo wed by normal supervised training of the primary task [12]. The main criticism of this approach is that the feature representation learned by the autoencoder does not necessarily support the supervised classification or regression tasks, which require the learning of in v ariant features that are discriminativ e for the task. This paper proposes ladder networks for emotion recogni- tion, showing its benefits for emotional attribute predictions. Ladder netw orks con veniently solve unsupervised auxiliary tasks along with supervised primary tasks [15, 16]. The unsu- pervised tasks (with respect to the primary task of predicting emotional attrib ute v alue) inv olve the reconstruction of hidden representations of a denoising autoencoder with lateral (skip) connections between the encoder and decoder layers. The rep- resentations from the encoder are simultaneously used to solv e the supervised learning problem. The reconstruction of the hid- den representations regularizes our primary regression task of predicting emotional attrib utes. The skip connections between the encoder and decoder ease the pressure of transporting in- formation needed to reconstruct the representations to the top layers. Therefore, top layers can learn features that are use- ful for the supervised task, such as the prediction of emotional attributes. Interestingly , the framework also allows us to add multiple supervised tasks creating ladder networks with MTL structures. This paper analyses the benefits of unsupervised auxiliary tasks to predict emotional attrib utes with ladder networks. W e compare performance of these architectures with three base- lines. The first baseline uses features from a denoising autoen- coder that does not consider emotional labels to create the fea- ture representation (i.e., unsupervised autoencoder). The sec- ond baseline is the con ventional supervised single task learn- ing (STL), where the emotional attrib utes are indi vidually pre- dicted. The third baseline is the MTL frame work proposed by Parthasarathy and Busso [10], which does not use unsupervised auxiliary tasks (i.e., ladder networks). The performance sho ws that the architectures that use unsupervised auxiliary tasks con- sistently outperform the baselines. Furthermore, ladder net- works with MTL structures ha ve the best performance, improv- ing the predictions of emotional attributes in the MSP-Podcast dataset. 2. Background 2.1. Related W ork Few studies hav e focused on using auxiliary tasks to improve emotion recognition. Parthasarathy and Busso [10] proposed the joint learning of arousal, v alence, dominance through multi- task learning (MTL). The y sho wed significant improvement in Hidden& Rep res enta ti on Output Input& +& Noise Input (a) Autoencoder Hidden& Rep res ent ati on Output Input (b) STL Hidden& Rep res enta ti on Output&1 Input Output&2 Output&3 (c) MTL Hidden& Rep rese nta tio n Output Input&+& Noise Input (d) Ladder-STL Hidden& Rep res enta ti on Output&1 Input&+& Noise Output&2 Output&3 Input (e) Ladder-MTL Figure 1: V arious arc hitectures with supervised and unsupervised auxiliary tasks for emotion prediction. The first three structur es ar e the baseline systems. The last two ar e the proposed models with ladder networks. performance when attrib utes are jointly predicted compared to single task learning. Chen et al. [11] jointly learned arousal and valence for continuous emotion recognition, leveraging the re- lationship between the attrib utes. Their approach achiev ed im- prov ed performance for the affect subtask on the A VEC 2017 challenge. Xia and Liu [17] proposed a scheme to use the re- gression of emotional attributes as auxiliary task to aid the clas- sification of emotional classes. Chang and Scherer [18] pro- posed a v alence classifier that used predictions on arousal as a secondary task. Their MTL frame work did not show any im- prov ement over learning just the primary task. Kim et al. [19] proposed using gender and naturalness of data as auxiliary tasks to recognize emotions. Finally , Le et al. [20] proposed a clas- sifier that continuously recognized emotional attributes. The attribute values were discretized using the k -means algorithm with k ∈ { 4 , 6 , 8 , 10 } . The discretized attribute values were treated as classes which were jointly predicted with MTL. The proposed approach builds upon ladder networks that ef- fectiv ely combine supervised classification or re gression prob- lems with unsupervised auxiliary tasks. V alpola [16] proposed using lateral shortcut connections to aid deep unsupervised learning. Rasmus et al. [15, 21] further extended this idea to support supervised learning. They included a batch normaliza- tion to reduce co variate shift. They also compared various de- noising functions to be used by the decoder . Finally , Pezeshki et al. [22] studied the various components that affected the ladder network, noting that lateral connections between encoder and decoder and the addition of noise at ev ery layer of the network greatly contributed to their improved performance. W e describe in detail this framew ork in Section 3.2. 2.2. Database This study uses the version 1.1. of the MSP-Podcast dataset [23]. The dataset contains emotionally colored, naturalistic speech from podcasts do wnloaded from audio sharing web- sites. The podcasts are processed and further split into smaller segments between 2.75s and 11s of duration. The segments are long enough so meaningful features can be extracted, and short enough so the emotional content does not change across the speaking turn. The dataset contains 22,630 (38h56m) au- dio segments. W e manually identified the speaker identity of 18,991 sentences spoken by 265 speakers. The speaker infor- mation is used to create the train, development and test parti- tions. The partitions aim to have speaker independent sets. The test set contains 7,181 segments from 50 speakers, the dev el- opment set contains 2,614 sentences from 20 speakers, and the train set includes the rest of the corpus (12,835 sentences). Au- dio segments are emotionally annotated on Amazon Mechanical T urk (AMT). The annotations are collected through perceptual ev aluations from fiv e or more raters. The emotional attributes are annotated with self-assessment manikins (SAMs) on a sev en likert-scale for arousal (1-v ery calm, 7-very acti ve), valence (1- very neg ativ e, 7-very positi ve), and dominance (1- very weak, 7 - very weak). The ground-truth labels for the attributes of a segment are the a verage scores provided by the e valuators. 3. Methodology 3.1. Proposed method An important challenge while designing emotion recognition systems is to make models that generalize across different con- ditions [24]. Con ventional models (Figure 1(b)) sho w poor per - formance when trained and tested on different corpora [10, 25]. Therefore, regularizing deep learning models is crucial in emo- tion recognition to find representations that are not overfitted to a particular domain. Regularization can be implemented with v arious approaches including early stopping criterion and dropout. The approach proposed is this study is to solve auxil- iary tasks along with the primary task of predicting emotional attributes. By training models that are optimized for primary and auxiliary tasks, the feature representations are more gen- eral, avoiding ov erfitting. There are multiple ways to introduce auxiliary tasks to model emotion recognition. Previous studies for emotion recognition have focused on supervised auxiliary tasks, in volving learning multiple emotion attributes [10] (Fig- ure 1(c)), combining emotional classification problem with re- gression of emotional attrib utes [17], and learning other labels such as gender and age along with the emotion [19]. While these approaches are appealing, the supervised nature of the tasks require auxiliary labels for the training samples. Labels for emotional data commonly come from perceptual ev aluations where multiple raters judge the emotional content of the stim- uli. These e valuations are both expensi ve and time consuming. Therefore, annotating additional meta-information is not a fea- sible alternati ve. Its appealing to create unsupervised auxiliary tasks to regularize the network. While traditional autoencoders (Figure. 1(a)) reconstruct input features in an unsupervised fashion, the intermediate la- tent representations are not trained for the underlying re gression or classification task. This paper proposes to employ the unsu- pervised reconstruction of inputs as an auxiliary task to regular- ize the network, while optimizing the performance of an emo- tion regression system. W e efficiently achiev e this goal with ladder network architectures (Figure. 1(d)). The addition of an unsupervised auxiliary task not only regularizes the learning of the primary task, but also helps learning powerful discrimina- tiv e representations of the input features. Furthermore, since there is no constraint on the primary task itself, we can com- bine it with other supervised auxiliary tasks to produce powerful models for predicting emotional attributes (Figure. 1(e)). 3.2. Ladder Networks Ladder networks combine supervised primary task with unsu- pervised auxiliary tasks. The auxiliary tasks reconstruct the hidden representations of a denoising autoencoder . The encoder (a) Ladder Network ! "#$ % & '() ! "*$ & +', & -./ 0 "1$ 0 "2$ (b) MTL Network Figure 2: Arc hitectures using auxiliary tasks for emotion attribute pr ediction. 2(a) illustrates the ladder network with unsupervised auxiliary tasks. 2(b) illustrates the MTL network that jointly learns multiple attrib ute values. of the autoencoder is simultaneously used to train the primary task at hand. The key aspect of the ladder network is the lateral connections between encoder and decoder layers. These skip connections allow the decoder to directly learn the represen- tation from the encoder layer , bypassing the top layers of the encoder which can then learn representations that would help with the primary supervised task. Figure. 2(a) illustrates a con- ceptual ladder network with two hidden layers used for a re- gression task. Note that the true benefits of the ladder network is for semi-supervised setting where few labeled samples for the primary task are available in the target domain. Howe ver , this study focuses on the fully-supervised setting where we have emotional labels for ev ery sample. The semi-supervised case is left as a future work. Encoder: The encoder of the ladder network is a fully con- nected multilayer per ceptron (MLP) network. A Gaussian noise with variance σ 2 is added to each layer of the noisy encoder (Figure. 2(a)). The representation from the final layer ˜ z ( L ) of the encoder is used as the target for the supervised task. The decoder tries to reconstruct the latent representation ˆ z at e very layer using, as tar get, a clean copy of the encoder z . Note that the supervised task, in this study the prediction of emotional attributes, is trained with the noisy encoder which further re gu- larizes the supervised learning. Ho wever , for inference we use the predictions from the clean encoder . W e describe the choice of hyper-parameters for the netw ork in Section 4.3. Decoder: The goal of the decoder is to denoise the noisy la- tent representations. The denoising function, g () , in Figure 2(a) combines top-down information from the decoder and the lat- eral connection from the corresponding encoder layer . With lat- eral connections, the ladder networks perform similar to hier- archical latent variable models. Lower layers are mostly re- sponsible for reconstructing the input vector . This approach allows higher layers to learn more abstract, discriminati ve fea- tures needed for the supervised task. W e use the denoising func- tion proposed by Pezeshki et al. [22], modeled by an MLP with inputs [ u, ˜ z , u z ] , where u is the batch normalized projection of the layer above and represents the Hadamard product. W e use an MLP with 1 hidden layer and 4 hidden nodes to model the denoising function g () . The overall loss function is: C = C c + λ l X l C ( l ) d (1) where C c is the supervised loss, C ( l ) d is the reconstruction loss at layer l and λ l is a hyper-parameter weight for the loss. 3.3. Ladder Network with Multi-task learning While ladder network utilizes the reconstruction cost as an un- supervised auxiliary task, regularization can also be achieved through supervised tasks. W ith emotional attrib utes, MTL can achiev e this goal by joint learning multiple attributes as pro- posed by Parthasarathy and Busso [10]. Figure 2(b) illustrates a two hidden layer MTL network that jointly predicts three emo- tional attributes: arousal, v alence and dominance. The overall loss for the MTL network is gi ven by C MTL = αC ar o + β C val + (1 − α − β ) C dom (2) with 0 < α, β < 1 and α + β ≤ 1 . P arthasarathy and Busso [10] showed that MTL networks perform better than STL networks for predicting emotional attributes. An appeal- ing framework is to combine the proposed ladder network with MTL as sho wn in Figure 1(e). The supervised loss C c in Equa- tion 1 is replaced by the MTL loss C MTL from Equation 2. This approach aims to combine supervised and unsupervised auxiliary tasks, creating an architecture that can learn powerful feature representations targeted for the prediction of emotional attributes. 4. Experimental Evaluation 4.1. Acoustic Featur es W e use the feature set introduced for the Computational Par - alinguistic Challenge at Interspeech 2013 [26]. The feature ex- traction process inv olves two parts. First, low level descrip- tors (LLDs) are extracted on a frame-by-frame basis. The set includes mel frequency cepstral coefficients (MFCCs), funda- mental frequency (F0) and ener gy . V arious statistics, denoted as high level featur es (HLFs) are calculated ov er the LLDs. Over - all, the feature set contains 6,373 features which we use for the various tasks in this study . The features were extracted with OpenSMILE [27]. T able 1: CCC values for the validation and test sets. The evaluations include 256 nodes per layer for arousal ( Aro ), valence ( V al ), and dominance ( Dom ). Bold values indicate the model(s) with the best performance per attribute (multiple cases are highlighted when differ ences ar e statistical significant). ∗ indicates significant impr ovements of the ladder networks compar ed to all the baselines. T ask V alidation T est Aro V al Dom Aro V al Dom Autoencoder 0.358 ± 0.069 0.136 ± 0.141 0.305 ± 0.139 0.272 ± 0.136 -0.006 ± 0.012 0.284 ± 0.148 STL 0.778 ± 0.004 0.443 ± 0.008 0.722 ± 0.004 0.737 ± 0.008 0.292 ± 0.007 0.670 ± 0.007 MTL 0.791 ± 0.003 0.469 ± 0.010 0.735 ± 0.003 0.745 ± 0.008 0.285 ± 0.007 0.676 ± 0.006 Ladder+STL 0.801 ± 0.002 ∗ 0.443 ± 0.007 0.742 ± 0.002 ∗ 0.765 ± 0.002 ∗ 0.294 ± 0.007 0.687 ± 0.003 ∗ Ladder+MTL 0.803 ± 0.002 ∗ 0.458 ± 0.004 0.746 ± 0.001 ∗ 0.761 ± 0.002 ∗ 0.289 ± 0.008 0.689 ± 0.002 ∗ 4.2. Baselines W e compare our results with three baseline networks. Fig- ure 1(b) shows the first baseline, which is a deep neural net- work (DNN) separately trained for each emotional attribute (i.e., STL). Figure 1(a) sho ws the second baseline, which learns feature representations using an autoencoder in an unsupervised fashion. The feature representations learned are then used as in- put for the supervised task. Unlike the ladder networks, the feature representation is independently learned from the super- vised task. The objecti ve of the autoencoder is to learn hidden representations that are useful for denoising the noise added to the features. All weights and activ ations of the encoder are frozen, and an output layer is then added on the top layer of the encoder for the prediction task. Figure 1(c) sho ws the third baseline, which uses MTL to jointly predict the three emotional attributes. F ollowing the work of P arthasarathy and Busso [10], we train three MTL networks, one for each target emotional attribute, optimizing α and β in Equation 2 to maximize the performance for each attribute. By learning all three tasks, we obtain feature representations that generalize well across differ- ent conditions. 4.3. Implementation Details All the deep neural networks in this study hav e two hidden layers with 256 nodes per layer . W e use rectified linear unit (ReLU) activ ation at the hidden layers and a linear activ ation for the output layer . W e optimize the networks using N ADAM with a learning rate of 5 e − 5 . The networks are implemented with dropout p = 0 . 5 at the input and first hidden layer . Following T rigeorgis et al. [28], we use the concor dance corr elation coef- ficient (CCC) as the loss function for training the models. W e also use CCC to e valuate the models. All the hyper -parameters are set maximizing performance on the validation set, including the parameters for MTL ( α, β ). W e train all the networks for 50 epochs with early stopping based on the result s observ ed in the v alidation set. The best model on the v alidation set is then ev aluated on the test set. All the models are trained 10 times with different random initializations, reporting the mean CCC. For the ladder network, we add noise with v ariance σ 2 =0.3 to each layer of the encoder . W e conducted a grid search for the weights for the reconstruction loss with v alues λ l ∈ { 0 . 1 , 1 , 10 , 100 } . A v alue of λ l = 1 gives the best result on the validation set. W e use the mean squared error as the reconstruc- tion cost and a dropout with probability p = 0 . 1 at the input layer and the first hidden layer . Notice that the original paper implementing ladder network did not use dropout. Howe ver , the high dimensionality of our feature vector and the violation of the independence assumption in our features moti vate us to further regularize the network by adding dropout. 5. Results T able 1 illustrates the mean CCC and standard de viation of the proposed architectures and the baselines for the validation and test sets. W e analyze the performance of v arious models using the one-tailed t -test over the 10 trials, asserting significance if p -value < 0.05. W e highlight with an asterisk when the ladder models perform better than the baselines. First, we note that the results on the v alidation set are significantly higher than perfor - mance on the test set for all emotional attrib utes and all models. Comparing the performance of the different architectures on the test set, we note that all the networks perform better than the au- toencoder baseline. This result shows that the feature represen- tation learned by the autoencoder does not fit well for the pri- mary regression task. Next, amongst the baselines we see that MTL models perform the best in all cases, e xcept for v alence on the test set. This result further confirms the benefits of super- vised auxiliary tasks through the joint learning of multiple emo- tional attributes, shown in our previous study [10]. Observing the proposed architectures, we note that in almost all cases the ladder networks perform significantly better than the baselines and giv e the best performance. For valence, while MTL per- forms better than all other methods on the v alidation set, it does not translate to the test set where the Ladder+STL architecture has the best performance. The role of regularization for v alence is an interesting topic which requires further study . Amongst the proposed architectures, Ladder+MTL performs better than Ladder+STL in many cases. The results show the benefits of combining both unsupervised and supervised auxiliary tasks for predicting emotional attributes. Overall, the unsupervised aux- iliary tasks greatly help to regularize our network improving the predictions and providing yet state-of-the-art performance on the MSP-Podcast corpus. 6. Conclusions This work proposed ladder networks with multi-task learning to predict emotional attributes, achieving state-of-the-art per- formance on the MSP-Podcast corpus. W e illustrated the ben- efits of using auxiliary tasks to regularize the netw ork by com- bining unsupervised auxiliary tasks (ladder network) and super- vised auxiliary tasks (multi-task learning). The emotional mod- els generalize better across v arious conditions providing signif- icantly better performance than the baseline systems. There are many future directions for this work. First, the true potential of using unsupervised auxiliary tasks is in har- nessing the almost unlimited amount of unlabeled data. W e can extend the framework to work in a semi-supervised man- ner , where we can combine lar ge number of unlabeled samples with fewer emotionally labeled samples, pro viding a more po w- erful feature representation. Second, the feature representations produced by the ladder network can be further studied and used as general input features for other emotion recognition prob- lems such as classification of emotional categories. Finally , the auxiliary tasks could be extended to cov er multiple modalities generalizing the models ev en more. The promising results in this study suggest that these extensions can lead to important improv ements in emotion prediction performance. 7. References [1] C. Busso, Z. Deng, S. Y ildirim, M. Bulut, C. Lee, A. Kazemzadeh, S. Lee, U. Neumann, and S. Narayanan, “ Analysis of emotion recognition using facial expressions, speech and multimodal in- formation, ” in Sixth International Conference on Multimodal In- terfaces ICMI 2004 . State College, P A: A CM Press, October 2004, pp. 205–211. [2] J. Lee, M. Reyes, T . Smyser , Y . Liang, and K. Thornb urg, “SAfety VEhicles using adaptiv e interface technology (task 5) final report: Phase 1, ” The University of Iowa, Io wa City , IA, USA, T echnical Report, November 2004. [3] B. Schuller , D. Seppi, A. Batliner, A. Maier, and S. Steidl, “T o- wards more reality in the recognition of emotional speech, ” in International Confer ence on Acoustics, Speec h, and Signal Pr o- cessing (ICASSP 2007) , vol. 4, Honolulu, HI, USA, April 2007, pp. 941–944. [4] M. Nicolaou, H. Gunes, and M. Pantic, “Continuous prediction of spontaneous affect from multiple cues and modalities in valence- arousal space, ” IEEE T ransactions on Af fective Computing , v ol. 2, no. 2, pp. 92–105, April-June 2011. [5] J. Russell, “ A circumplex model of af fect, ” Journal of P ersonality and Social Psychology , vol. 39, no. 6, pp. 1161–1178, December 1980. [6] J. Fontaine, K. Scherer, E. Roesch, and P . Ellsworth, “The world of emotions is not two-dimensional, ” Psychological Sci- ence , vol. 18, no. 12, pp. 1050–1057, December 2007. [7] M. Abdelwahab and C. Busso, “Study of dense network ap- proaches for speech emotion recognition, ” in IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP 2018) , Calgary , AB, Canada, April 2018. [8] M. W ¨ ollmer , F . Eyben, S. Reiter, B. Schuller , C. Cox, E. Douglas- Cowie, and R. Cowie, “ Abandoning emotion classes - towards continuous emotion recognition with modelling of long-range de- pendencies, ” in Interspeech 2008 - Eur ospeech , Brisbane, Aus- tralia, September 2008, pp. 597–600. [9] P . A. Lewis, H. Critchley , P . Rotshtein, and R. Dolan, “Neural correlates of processing v alence and arousal in af fective words, ” Cer ebral cortex , vol. 17, no. 3, pp. 742–748, 2007. [10] S. Parthasarathy and C. Busso, “Jointly predicting arousal, va- lence and dominance with multi-task learning, ” in Interspeech 2017 , Stockholm, Sweden, August 2017, pp. 1103–1107. [11] S. Chen, Q. Jin, J. Zhao, and S. W ang, “Multimodal multi-task learning for dimensional and continuous emotion recognition, ” in Pr oceedings of the 7th Annual W orkshop on Audio/V isual Emotion Challenge , ser . A VEC ’17. New Y ork, NY , USA: ACM, 2017, pp. 19–26. [Online]. A vailable: http://doi.acm.org/10.1145/3133944.3133949 [12] G. E. Hinton and R. R. Salakhutdinov , “Reducing the dimension- ality of data with neural networks, ” science , vol. 313, no. 5786, pp. 504–507, 2006. [13] M. Ranzato and M. Szummer , “Semi-supervised learning of com- pact document representations with deep networks, ” in Pr oceed- ings of the 25th international conference on Machine learning . A CM, 2008, pp. 792–799. [14] G. E. Hinton, S. Osindero, and Y .-W . T eh, “ A fast learning algo- rithm for deep belief nets, ” Neural computation , vol. 18, no. 7, pp. 1527–1554, 2006. [15] A. Rasmus, M. Berglund, M. Honkala, H. V alpola, and T . Raiko, “Semi-supervised learning with ladder networks, ” in Advances in Neural Information Pr ocessing Systems , 2015, pp. 3546–3554. [16] H. V alpola, “From neural pca to deep unsupervised learning, ” Ad- vances in Independent Component Analysis and Learning Ma- chines , pp. 143–171, 2015. [17] R. Xia and Y . Liu, “ A multi-task learning framework for emotion recognition using 2d continuous space, ” IEEE T ransactions on Af- fective Computing , 2015. [18] J. Chang and S. Scherer , “Learning representations of emotional speech with deep convolutional generati ve adversarial networks, ” in IEEE International Confer ence on Acoustics, Speech and Sig- nal Pr ocessing (ICASSP 2017) , Ne w Orleans, LA, USA, March 2017, pp. 2746–2750. [19] J. Kim, G. Englebienne, K. P . Truong, and V . Evers, “T owards speech emotion recognition in the wild using aggregated corpora and deep multi-task learning, ” in Interspeech 2017 , 2017, pp. 1113–1117. [20] D. Le, Z. Aldeneh, and E. M. Provost, “Discretized continuous speech emotion recognition with multi-task deep recurrent neural network, ” in Interspeec h 2017 , Stockholm, Sweden, August 2017, pp. 1108–1112. [21] A. Rasmus, H. V alpola, and T . Raiko, “Lateral connections in de- noising autoencoders support supervised learning, ” arXiv pr eprint arXiv:1504.08215 , 2015. [22] M. Pezeshki, L. Fan, P . Brakel, A. Courville, and Y . Bengio, “Deconstructing the ladder network architecture, ” in International Confer ence on Machine Learning , 2016, pp. 2368–2376. [23] R. Lotfian and C. Busso, “Building naturalistic emotionally bal- anced speech corpus by retrie ving emotional speech from existing podcast recordings, ” IEEE T ransactions on Af fective Computing , vol. T o appear , 2017. [24] C. Busso, M. Bulut, and S. Narayanan, “T oward ef fective auto- matic recognition systems of emotion in speech, ” in Social emo- tions in nature and artifact: emotions in human and human- computer inter action , J. Gratch and S. Marsella, Eds. New Y ork, NY , USA: Oxford Univ ersity Press, November 2013, pp. 110– 127. [25] M. Shami and W . V erhelst, “ Automatic classification of expres- siv eness in speech: A multi-corpus study , ” in Speaker Classi- fication II , ser . Lecture Notes in Computer Science, C. M ¨ uller , Ed. Berlin, Germany: Springer-V erlag Berlin Heidelberg, Au- gust 2007, vol. 4441, pp. 43–56. [26] B. Schuller, S. Steidl, A. Batliner, A. V inciarelli, K. Scherer, F . Ringev al, M. Chetouani, F . W eninger , F . Eyben, E. Marchi, M. Mortillaro, H. Salamin, A. Polychroniou, F . V alente, and S. Kim, “The INTERSPEECH 2013 computational paralinguis- tics challenge: Social signals, conflict, emotion, autism, ” in Inter- speech 2013 , L yon, France, August 2013, pp. 148–152. [27] F . Eyben, M. W ¨ ollmer , and B. Schuller , “OpenSMILE: the Mu- nich versatile and fast open-source audio feature extractor, ” in ACM International conference on Multimedia (MM 2010) , Flo- rence, Italy , October 2010, pp. 1459–1462. [28] G. Trigeorgis, F . Ringe val, R. Brueckner , E. Marchi, M. Nico- laou, B. Schuller, and S. Zafeiriou, “ Adieu features? end-to-end speech emotion recognition using a deep conv olutional recurrent network, ” in IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP 2016) , Shanghai, China, March 2016, pp. 5200–5204.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment