NELS -- Never-Ending Learner of Sounds
Sounds are essential to how humans perceive and interact with the world and are captured in recordings and shared on the Internet on a minute-by-minute basis. These recordings, which are predominantly videos, constitute the largest archive of sounds …
Authors: Benjamin Elizalde, Rohan Badlani, Ankit Shah
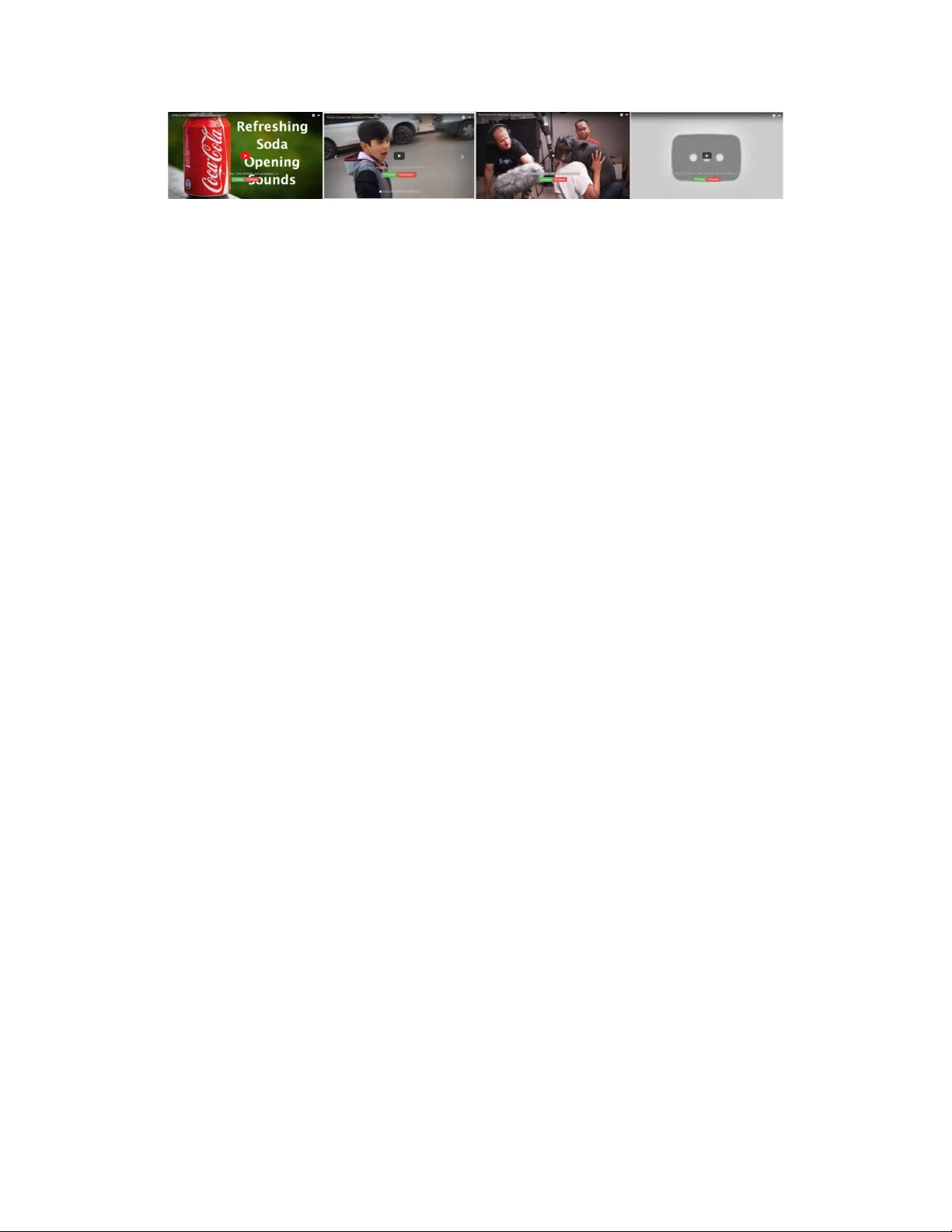
NELS - Ne ver -Ending Lear ner of Sounds Benjamin Elizalde ∗† , Rohan Badlani ∗‡ , Ankit Shah ∗ , Anurag Kumar , Bhiksha Raj ∗ L TI, † ECE, Carnegie Mellon Uni v ersity , Pittsburgh, P A ‡ Department of Computer Science, BITS Pilani, India bmartin1,aps1,alnu @andre w .cmu.edu, rohan.badlani@gmail.com Abstract Sounds are essential to ho w humans percei v e and interact with the world and are captured in recordings and shared on the Internet on a minute-by-minute basis. These recordings, which are predominantly videos, constitute the largest archi v e of sounds we kno w . Howe ver , most of these recordings have undescribed content making necessary methods for automatic sound analysis, indexing and retriev al. These methods ha ve to address multiple challenges, such as the relation between sounds and language, numerous and div erse sound classes, and large-scale e v alua- tion. W e propose a system that continuously learns from the web relations between sounds and language, improves sound recognition models ov er time and e v aluates its learning competency in the large-scale without references. W e introduce the Nev er -Ending Learner of Sounds (NELS), a project for continuously learning of sounds and their associated knowledge, a v ailable on line in nels.cs.cmu.edu . 1 Introduction and Related W ork The ability to automatically recognize sounds is essential in a large number of applications such as identifying emergencies in elderly care and patients in hospitals (choking, falling down) [ 1 , 2 ], where monitoring cameras are unw anted due to pri v ac y concerns [ 3 ], allo wing self-dri ving cars to respond safely to warning sounds and emer gency v ehicles (amb ulance siren) [ 4 ], improving airport and house surveillance, where any number of unusual phenomena ha ve acoustic signatures (alarm, footsteps, glass breaking) [ 5 ], expanding our interaction with digital assistants through non-verbal communication (clapping, laughing), and analyzing and retrieving video by its content, perhaps the most explored application [ 6 , 7 , 8 , 9 , 10 ]. By the year 2021, a million minutes of videos will be uploaded to the Internet each second; this will constitute 82% of all consumer traf fic 2 . The ability to recognize sounds in all these recordings is ke y to or ganizing, understanding, and e xploiting the rapidly growing audio and multimedia data. In recent years, sound recognition research has focused on curated data and guidelines and although successful and necessary , the literature has under explored the challenges of web audio. Curated audio recordings [ 11 , 12 , 4 , 13 ] hav e carefully collected and recorded audio as opposed to be mainly recorded in an unstructured manner; have a defined task-oriented set of sound classes as opposed to an unbounded number of sound classes for a wide range of topics; come with a limited set of classes and samples in contrast to an ev ery-day gro wing number of classes and samples; ha ve rich descriptions of their content in contrast to descriptions that are insufficient, unav ailable or wrong. Hence, we should not only test ho w state of the art sound recognition performs in the web conte xt, but also e xplore ne w paradigms to learn from the e ver -gro wing web audio. Existing sound recognition systems learn from a finite curated source, so their learning is limited to the scope of the source and the optimization objectiv e and do not improve learning over time. T o address these issues, the literature includes nev er -ending learning architectures that learn many ∗ All authors contributed equally . 2 https://www .cisco.com/c/en/us/solutions/collateral/service-provider/visual-networking-index- vni/complete-white-paper-c11-481360.html 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA. types of kno wledge from years of di v erse sources, using pre viously learned kno wledge to impro ve subsequent learning and with sufficient self-reflection to a void learning stagnation, as pointed out by T om Mitchell [14]. The never -ending paradigm has been employed in ongoing projects, Nev er -Ending Language Learner [ 14 ] for text and Ne ver -Ending Image Learner [ 15 ] for images. Howe ver , this paradigm is unexplored for sound learning. Examples of tasks related to the paradigm are to learn associations between sounds and language (metadata, ontologies, descriptiv e terms); continuously grow acoustic vocab ularies and improv e robustness of sound recognizers; and ev aluate the subjectivity of sound recognition in the absence of prior knowledge of the source or generation process. W e introduce the Never -Ending Learner of Sounds (NELS), a project for large-scale continuous learning of sounds and their associated knowledge by mining the web. Examples of associated kno wledge are semantics related to objects, e vents, actions, places [ 16 ], cities [ 17 , 18 ] or qualities [ 19 , 20 ]. Our contribution be gins with a w orking frame work that serves for audio content indexing and for searching the indexed sounds. Since its inception in 2016, NELS has reported in sev eral research publications discussed in Section 3, has won the 2017 Gandhian Y oung T echnological Innovation (GYTI) award in India and w as a selected abstract in the 2018 Qualcomm Innov ation Fello wship. 2 NELS Framework In its current form, NELS is a framework that continuously (24/7) crawls audio & metadata from Y ouT ube videos and creates a content-based index based on a v ocabulary of 600 sounds. The sound recognizers were trained from a variety of sources, including web audio itself. NELS also ev aluates the quality of the recognition through human feedback. The audio content is index ed combining the crawled metadata, sound recognition predictions and human feedback. As of October 20, 2017, we hav e crawled o ver 300 hours of audio corresponding to 4 million video segments of 2.3 seconds. The index ed audio content is av ailable for search and retrie v al using our engine in the website. Figure 1: The framework serves as a continuously audio content indexer , a sound recognition ev aluation and a search engine for the inde x ed audio. 2.1 Crawl In this module, a search query is used to crawl audio and metadata from Y ouT ube videos. The query corresponds to 605 sound ev ent labels from four dif ferent datasets. The video metadata is extracted using the Pafy API 3 and corresponds to 12 attrib utes, such as title, URL and description. The crawled metadata is use to index the audio content. Although NELS will ev entually feed from different sound web archi ves, we selected Y ouT ube as our first source due to its di v ersity of sounds and the a v ailable metadata associated to them. In contrast to audio-only recordings, collecting audio from videos poses se veral challenges. Y ouTube contains massiv e amount of videos and a proper formulation of the search query is necessary to filter videos with higher chances of containing the desired sound e vent. T yping a query composed by a noun such as air conditioner will not necessarily fetch a video containing such sound e vent because the 3 https://pypi.python.or g/pypi/pafy 2 associated metadata often corresponds to the visual content; contrary to audio-only archi ves such as fr eesounds.or g . Therefore, we modified the query to be a combination of k eyw ords: “ sound", for example,“air conditioner sound". Although the results empirically improved, the sound ev ent was not al ways found to be occurring and e v en if it was, sometimes it w as present within a short duration, o verlapping with other sounds and with low volume. W e discarded videos longer than ten minutes and shorter than tw o seconds because the y were either lik ely to contain unrelated sounds or were too short to be processed. 2.2 Hear & Learn In this module, we used 605 sound events from four annotated datasets to train classifiers and run them on the crawled Y ouT ube video segments, which are unlabeled. The class predictions are also used to index the audio content. The framew ork is being developed so that given a set of guidelines, new datasets could be added seamlessly . NELS should be able to take advantage of e xisting curated annotations, howe v er dealing with mismatch conditions. The current four datasets are: ESC50, US8k, TUT16 (T ask-3) and AudioSet. ESC-50 [ 21 ] has 50 classes from fiv e broad categories: animals, natural soundscapes and water sounds, human non-speech sounds, interior/domestic sounds and exterior sounds. The dataset consists of 2,000 audio segments with an av erage duration of 5 seconds each. The US8K or UrbanSounds8K [ 13 ] has 10 classes lik e gun shot, jac khammer , c hildr en playing . The dataset consists of 8,732 audio se gments with an a v erage duration of 3.5 seconds each. TUT 2016 (T ask-3) [ 22 ] has 18 classes like car passing by , bird singing, door banging from two major sound conte xts namely home context and residential area. The dataset consists of 954 audio segments with an average duration of 5 seconds each. AudioSet [ 23 ] has 527 classes and 2.1 million audio segments with an average duration of 10 seconds each. The audio from both the datasets and crawled video segments are preprocessed and classified. NELS is meant to be classifier agnostic. W e currently follow Conv olutional Neural Networks (CNNs) classifier setup described in [ 21 ]. Recordings are segmented into 2.3 seconds and conv erted into 16-bit encoding, mono-channel, and 44.1 kHz sampling rate W A V files as in [ 21 ]. Then, we extracted features comprising of log-scaled mel-spectrograms with 60 mel-bands with a window size of 1024 (23 ms) and hop size is 512. Lastly , the features are used to train multi-class classifiers using CNNs for each of the datasets. 2.3 W ebsite The module is on line in nels.cs.cmu.edu and currently serves for two purposes. First, to ev aluate sound recognition using human feedback, which we include as part of the audio indexing. Second, to provide a search engine of the index ed audio content. The goal is to ev entually be able to search for audio based on descriptiv e (subjecti v e) terms, onomatopoeias and acoustic content [24]. The website provides a search field to capture a term (text-query) for sound searching. The term is mapped to the closest of our sound classes. The mapping uses the tool wor d2vec [ 25 ] and a precomputed vocabulary of 400 thousand words called Glove [ 26 ]. W ord2V ec computes vector representations of the v ocab ulary words and the te xt-query . Then, computes cosine similarity between the te xt-query , the precomputed v ocab ulary and our list of sounds. Giv en that our list of sound classes does not necessarily match with all the words of the precomputed vocab ulary , we only consider words within a similarity threshold of 0.15, else no results will be retriev ed. Additionally , we provide another feature on the website, the user can paste a Y ouT ube video link on a second text field and NELS will yield the dominant sound. Each displayed video segment resulting from the text-based search can be ev aluated by the user with two b utton-options, Corr ect or Incorr ect . That is, whether the human claims that the system’ s predicted class was present within the segment or not Examples can be seen in Figure 2. 3 Discussion In this section we discuss three sound learning challenges where NELS was in volv ed. Relation between sounds and language. Language can describe audio content, be used to search for sounds, and help to define sound v ocabularies [ 27 ]. Howe ver , the relation between sounds and language is still an inchoate topic. T o better understand the usage of language for our inde xing, we carried two studies. 3 Figure 2: Examples of indexed video se gments using NELS. First, shows an example where for a can-opening sound, the title and images are clearly related. Second, shows an example where a sir en wailing sound and title are related, b ut not the visual sound source, which is a child rather than an electronic de vice. Third, shows an example of pig-oink sound, which matches with the visuals, b ut not with the title and text metadata. Fourth, shows the thumbnail of a video that was indexed, b ut ev entually deleted by the user . First, sound recognition results [ 11 , 22 ] evidenced how although two sound e vents: quiet str eet and busy str eet defined audio from streets, the qualifier implied dif ferences in the acoustic content. These kind of nuances can be described with Adjectiv e-Noun Pairs (ANPs) and V erb-Noun Pairs (VNPS) [ 19 ]. W e collected one thousand pair-labels deri ved from different audio ontologies. The audio recordings containing the sound ev ents and their pair-labels were crawled from the collecti ve archiv e freesounds.or g . W e concluded that despite of the subjecti vity of the labels, there is a degree of consistency between sound e vents and both types of pairs. Second, in [ 20 ] we wanted to identify text phrases which contain a notion of audibility and can be termed as a sound ev ents. W e noted that sound-descriptor phrases can often be disambiguated based on whether they can be prefix ed by the words “sound of ” without changing their meaning. Hence, by matching the combination “sound(s) of ” where Y is any phrase of up to four words to identify candidate phrases, followed by the application of a rule-based classifier to eliminate noisy candidates, we obtained a list of ov er 100,000 sound labels. Further , by applying a classifier to features extracted from a dependency path between a manually listed set of acoustic scenes and the discov ered sound labels, we were also able to discov er ontological relations. For example, forests may be associated with the sounds of bir ds singing , breaking twigs , cooing and falling water . Continuous semi-super vised learning of sounds. NELS should take advantage of existing curated sound datasets and non curated web audio to improv e its learning. Previously , semi-supervised self- training approaches hav e been used to improve sound e vent recognizers [ 28 , 29 ]. In [ 29 ], we used an earlier version of NELS. Its classifiers were trained and tested using the US8K dataset consisting of about 8,000 labeled samples for 10 sounds. For re-training, we used 200,000 unlabeled Y ouT ube video segments. Similar to the first paper, b ut with mismatched data, we achiev ed about 1.4% overall precision improv ement. Reg ardless of the improvement, we reached a learning plateau. This could be due to mismatched conditions between training and self-training audio. The initial class bias introduced by the hand-crafted dataset. The use of ambiguous Y ouT ube audio to self-train sound classes. Hence, to learn from the daily growing source of web audio, further e xploration is needed. Evaluation of the learning quality . NELS indexes audio content 24/7, but these segments are unlabeled or have weak or wrong labels. Therefore, it is essential to find methods for automatic ev aluation of quality in the large-scale. A solution is to include human intervention [ 30 ]. Hence, our website allows collection of human feedback to asses correctness of sound ev ent indexing. Nev ertheless, human feedback may be slow or costly , hence it is important to combine it with other methods that estimate performance in the large-scale. In [ 31 ], we used an earlier version of NELS with a recognizer trained on 78 sound ev ents from three different datasets. After , we crawled audio from Y ouT ube videos using the sound event labels from the datasets as the search query . The query was a combination of keyw ords: “< sound event label > sound", for example,“air conditioner sound". Then, we ev aluated the highest-40 recognized segments per sound class based on both types of references (ground truth), human feedback and search query . The search query is a summary of the video’ s metadata describing the whole video, but it was interesting to kno w to what extent it holds at the video’ s segment lev el. Results showed how the performance trends of using both types of references are similar and relati vely close with less than an absolute 10% dif ference of precision. This trend suggests that the query could be used as a lo wer-bound of human inspection. In other words, it could serv e as a preliminary reference to e valuate sound recognition. Further exploration on this and other associated metadata and multimedia cues could be used as alternativ e measurements. 4 References [1] Patrice Guyot, Julien Pinquier , Xavier V alero, and Francesc Alias, “T wo-step detection of water sound ev ents for the diagnostic and monitoring of dementia, ” in Multimedia and Expo (ICME), 2013 IEEE International Confer ence on . IEEE, 2013. [2] BM Rocha, L Mendes, I Chouvarda, P Carvalho, and RP Pai v a, “Detection of cough and adventitious respiratory sounds in audio recordings by internal sound analysis, ” in Pr ecision Medicine P ower ed by pHealth and Connected Health , pp. 51–55. Springer, 2018. [3] Patrice Caire, Assaad Moaw ad, V asilis Efthymiou, Antonis Bikakis, and Yves Le T raon, “Pri vac y challenges in ambient intelligence systems, ” J ournal of Ambient Intellig ence and Smart En vir onments , vol. 8, no. 6, pp. 619–644, 2016. [4] A. Mesaros, T . Heittola, A. Diment, B. Elizalde, A. Shah, E. V incent, B. Raj, and T . V irtanen, “DCASE 2017 challenge setup: T asks, datasets and baseline system, ” in Pr oceedings of the Detection and Classification of Acoustic Scenes and Events 2017 W orkshop (DCASE2017) , Nov ember 2017, submitted. [5] Pradeep K Atrey , Namunu C Maddage, and Mohan S Kankanhalli, “ Audio based e vent detection for multimedia surveillance, ” in Acoustics, Speech and Signal Pr ocessing, 2006. ICASSP 2006 Pr oceedings. 2006 IEEE International Confer ence on . IEEE, 2006, vol. 5. [6] Y u-Gang Jiang, Xiaohong Zeng, Guangnan Y e, Dan Ellis, Shih-Fu Chang, Subhabrata Bhat- tacharya, and Mubarak Shah, “Columbia-ucf trecvid2010 multimedia e vent detection: Com- bining multiple modalities, contextual concepts, and temporal matching., ” in TRECVID , 2010, vol. 2, pp. 3–2. [7] Zhen-zhong Lan, Lei Bao, Shoou-I Y u, W ei Liu, and Alexander Hauptmann, “Double fusion for multimedia ev ent detection, ” Advances in Multimedia Modeling , pp. 173–185, 2012. [8] Hui Cheng, Jingen Liu, Saad Ali, Omar Javed, Qian Y u, Amir T amrakar , Ajay Div akaran, Harpreet S Sawhne y , R Manmatha, James Allan, et al., “Sri-sarnoff aurora system at trecvid 2012: Multimedia ev ent detection and recounting, ” in Proceedings of TRECVID , 2012. [9] Peter Schäuble, Multimedia information r etrieval: content-based information r etrieval fr om lar ge text and audio databases , v ol. 397, Springer Science & Business Media, 2012. [10] Michael S Le w , Nicu Sebe, Chabane Djeraba, and Ramesh Jain, “Content-based multimedia information retriev al: State of the art and challenges, ” A CM T ransactions on Multimedia Computing, Communications, and Applications (T OMM) , vol. 2, no. 1, pp. 1–19, 2006. [11] Dimitrios Giannoulis, Emmanouil Benetos, Dan Sto well, Mathias Rossignol, Mathieu Lagrange, and Mark D Plumbley , “Detection and classification of acoustic scenes and ev ents: an IEEE AASP challenge, ” in 2013 IEEE W ASP AA . IEEE, 2013, pp. 1–4. [12] T uomas V irtanen, Annamaria Mesaros, T oni Heittola, Mark D. Plumbley , Peter Foster , Em- manouil Benetos, and Mathieu Lagrange, Pr oceedings of the Detection and Classification of Acoustic Scenes and Events 2016 W orkshop (DCASE2016) , T ampere University of T echnology . Department of Signal Processing, 2016. [13] J. Salamon, C. Jacoby , and J. P . Bello, “ A dataset and taxonomy for urban sound research, ” in 22st A CM International Confer ence on Multimedia (ACM-MM’14) , Orlando, FL, USA, No v . 2014. [14] T om M Mitchell, W illiam W Cohen, Estev am R Hruschka Jr , Partha Pratim T alukdar , Justin Betteridge, Andre w Carlson, Bhav ana Dalvi Mishra, Matthew Gardner , Bryan Kisiel, Jayant Krishnamurthy , et al., “Nev er ending learning., ” in AAAI , 2015, pp. 2302–2310. [15] Xinlei Chen, Abhinav Shriv astav a, and Abhinav Gupta, “Neil: Extracting visual knowledge from web data, ” in The IEEE International Confer ence on Computer V ision (ICCV) , December 2013. [16] Richard F L yon, “Machine hearing: An emer ging field [exploratory dsp], ” Ieee signal processing magazine , v ol. 27, no. 5, pp. 131–139, 2010. [17] Anurag Kumar and Bhiksha Raj, “ Audio event detection using weakly labeled data, ” in Pr oceedings of the 2016 ACM on Multimedia Confer ence . ACM, 2016, pp. 1038–1047. 5 [18] Benjamin Elizalde, Guan-Lin Chao, Ming Zeng, and Ian Lane, “City-identification of flickr videos using semantic acoustic features, ” in Multimedia Big Data (BigMM), 2016 IEEE Second International Confer ence on . IEEE, 2016, pp. 303–306. [19] Sebastian Sager , Damian Borth, Benjamin Elizalde, Christian Schulze, Bhiksha Raj, Ian Lane, and Andreas Dengel, “ Audiosentibank: Large-scale semantic ontology of acoustic concepts for audio content analysis, ” arXiv pr eprint arXiv:1607.03766 , 2016. [20] Anurag Kumar , Bhiksha Raj, and Ndapandula Nakashole, “Discovering sound concepts and acoustic relations in text, ” arXiv preprint , 2016. [21] Karol J Piczak, “En vironmental sound classification with con volutional neural networks, ” in 2015 IEEE 25th International W orkshop on Machine Learning for Signal Pr ocessing (MLSP) . IEEE, 2015, pp. 1–6. [22] Annamaria Mesaros, T oni Heittola, and T uomas V irtanen, “TUT database for acoustic scene classification and sound ev ent detection, ” in 24th Eur opean Signal Pr ocessing Confer ence 2016 (EUSIPCO 2016) , Budapest, Hungary , 2016. [23] Jort F . Gemmeke, Daniel P . W . Ellis, Dylan Freedman, Aren Jansen, W ade Lawrence, R. Chan- ning Moore, Manoj Plakal, and Marvin Ritter, “ Audio set: An ontology and human-labeled dataset for audio ev ents, ” in Pr oc. IEEE ICASSP 2017 , New Orleans, LA, 2017. [24] Erling W old, Thom Blum, Douglas Keislar , and James Wheaten, “Content-based classification, search, and retriev al of audio, ” IEEE multimedia , vol. 3, no. 3, pp. 27–36, 1996. [25] T omas Mikolo v , Ilya Sutskever , Kai Chen, Greg S Corrado, and Jeff Dean, “Distributed representations of words and phrases and their compositionality , ” in Advances in neural information pr ocessing systems , 2013, pp. 3111–3119. [26] Jeffre y Pennington, Richard Socher , and Christopher D. Manning, “Glov e: Global vectors for word representation, ” in Empirical Methods in Natural Language Pr ocessing (EMNLP) , 2014, pp. 1532–1543. [27] Dan Ellis, T uomas V irtanen, Mark D. Plumbley , and Bhiksha Raj, Futur e P erspective , Springer International Publishing, 2018. [28] W enjing Han, Eduardo Coutinho, Huabin Ruan, Haifeng Li, Björn Schuller , Xiaojie Y u, and Xuan Zhu, “Semi-supervised activ e learning for sound classification in hybrid learning environ- ments, ” PloS one , vol. 11, no. 9, pp. e0162075, 2016. [29] Ankit Shah, Rohan Badlani, Anurag K umar, Benjamin Elizalde, and Bhiksha Raj, “ An approach for self-training audio ev ent detectors using web data, ” arXiv preprint , 2016. [30] Justin Salamon, Duncan MacConnell, Mark Cartwright, Peter Li, and Juan Pablo Bello, “Scaper: A library for soundscape synthesis and augmentation, ” in IEEE W orkshop on Applications of Signal Pr ocessing to Audio and Acoustics (W ASP AA). New P altz, NY , USA , 2017. [31] Rohan Badlani, Ankit Shah, Benjamin Elizalde, Anurag Kumar , and Bhiksha Raj, “Framework for ev aluation of sound event detection in web videos, ” in In submission to IEEE ICASSP 2018 , 2018. 6
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment