When black box algorithms are (not) appropriate: a principled prediction-problem ontology
In the 1980s a new, extraordinarily productive way of reasoning about algorithms emerged. In this paper, we introduce the term "outcome reasoning" to refer to this form of reasoning. Though outcome reasoning has come to dominate areas of data science…
Authors: Jordan Rodu, Michael Baiocchi
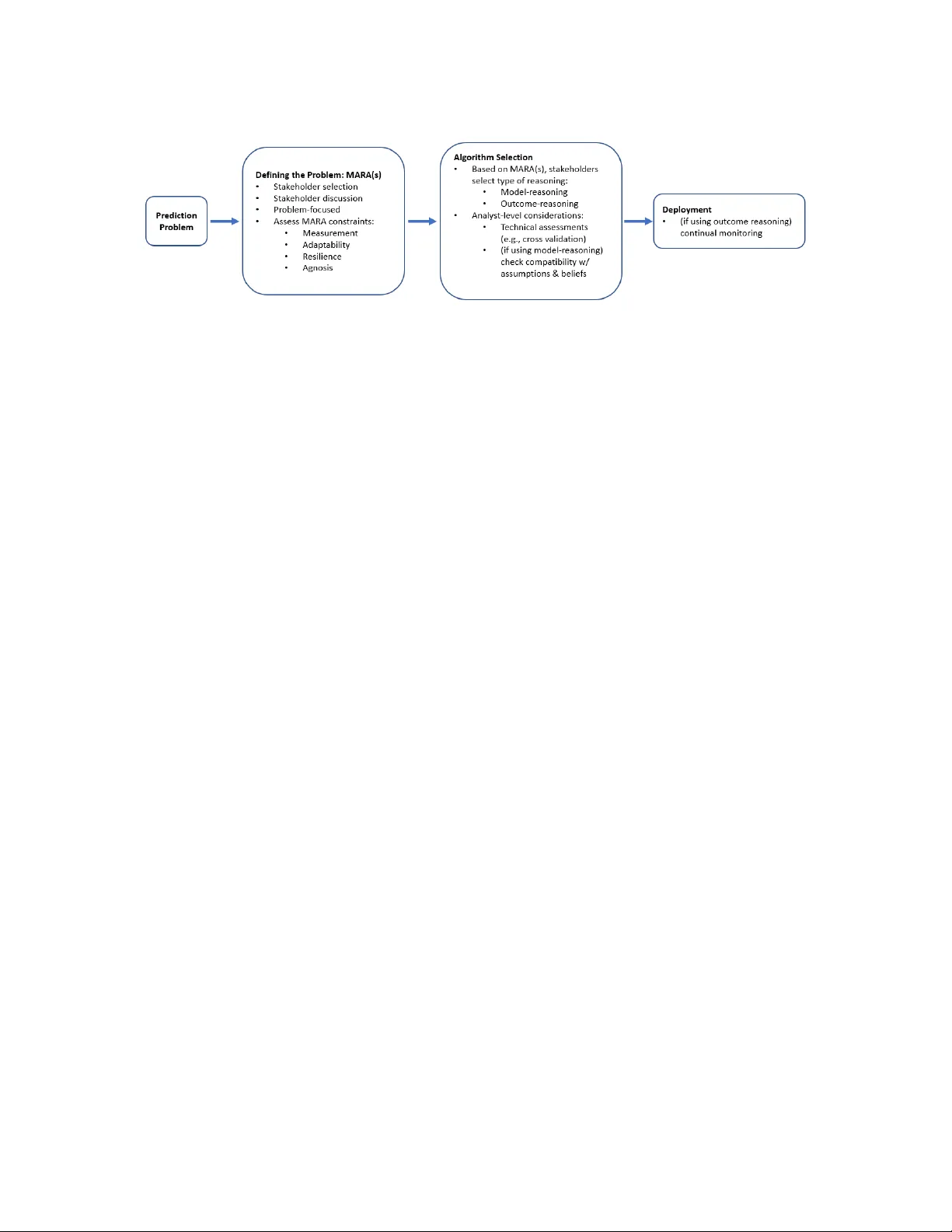
Observ ational Studies () Submitted ; Published When blac k b o x algorithms are (not) appropriate Jordan Ro du jordan.ro du@virginia.edu Dep artment of Statistics University of Vir ginia Charlottesvil le, V A 22904, USA Mic hael Baio cc hi baio cc hi@stanford.edu Epidemiolo gy and Population He alth Stanfor d University Stanfor d, CA 94305, USA Abstract In the 1980s a new, extraordinarily pro ductiv e wa y of reasoning ab out algorithms emerged. In this pap er, we in tro duce the term “outcome reasoning” to refer to this form of reasoning. Though outcome reasoning has come to dominate areas of data science, it has b een under-discussed and its impact under-appreciated. F or example, outcome reasoning is the primary w ay w e reason ab out whether “black b ox” algorithms are performing well. In this pap er we analyze outcome reasoning’s most common form (i.e., as “the common task framew ork”) and its limitations. W e discuss why a large class of prediction-problems are inappropriate for outcome reasoning. As an example, w e find the common task framework do es not provide a foundation for the deplo yment of an algorithm in a real world situation. Building off of its core features, w e identify a class of problems where this new form of reasoning can b e used in deploymen t. W e purp osefully develop a nov el framework so b oth tec hnical and non-tec hnical p eople can discuss and identify key features of their prediction problem and whether or not it is suitable for outcome reasoning. Keyw ords: Blac k Bo x, Accoun tability , Common T ask F ramework, Machine Learning 1. In tro duction It is exciting to witness the developmen t of flexible, fast, and useful predictiv e algorithms. Algorithms are driving cars, identifying breast cancers, enabling glob e-spanning businesses, and organizing unpreceden ted amounts of information; prediction pro vides a strong founda- tion for technological innov ation and scien tific breakthroughs. The excitemen t ab out these algorithms is w arran ted; these achiev ements are unparalleled in history . A very natural question for members of the business, gov ernment, and academic communities is: “how can w e use them?” This simple question is more complicated than it first app ears b ecause mo dern predictive algorithms hav e sev eral v ery distinctiv e features, including: some of the most successful algorithms are so complex that no p erson can describ e the mathematical features of the algorithm that gives rise to the high p erformance (a.k.a. “blac k b o x algo- rithms”). There is an imp ortant tension righ t now b ecause these extraordinary black-box algorithms exist – with so m uch p oten tial to do goo d – despite deep uncertain ty ab out when and ho w to use them. And this tension is w arran ted: for all of their ac hiev ements, blac k-b o x © Jordan Ro du and Michael Baio cchi. R odu and Baiocchi algorithms ha ve sho wn to b e unpredictably brittle in the real world, failing without muc h w arning. This is a consequence of how they are developed. These algorithms hav e come into existence through a confluence of inno v ations. Some of these inno v ations are practical (e.g., the price of computing has con tin ued to drop), some are mark et-based (e.g., online platforms hav e prov ed to b e profitable business mo dels and so corp orations hav e funded muc h of this researc h and developmen t), some are due to p olitical decisions (e.g., emphasis on funding education and dev elopment in STEM fields has created a large pip eline of data scientists), but a ma jor – yet also under-appreciated – shift has come from a new way to r e ason using data , a form of reasoning that do es not require slow-mo ving mathematical pro ofs. While understanding black b o x algorithms in general is not p ossible, by understanding ho w they are b eing developed and assessed we can understand what situations are more – and less – compatible or safe for their use. T o pro vide guidance on using prediction algorithms, this pap er offers a new framework for stak eholders (e.g., business p eople, gov ernment officials, non-statistically minded academics, individuals affected by predictions) to discuss and critique the use of these algorithms. F or reasons whic h will b ecome clear, we call this framework MARA(s). 1.1 Goals of this pap er This pap er addresses several important concerns ab out using machine learning, or blac k b o x algorithms, in real-world scenarios. 1. The framework in tro duced in this pap er allo ws for a principled w ay to determine if a blac k b o x algorithm is appropriate for a prediction problem (see sections 4 and 6 ). 2. This pap er pro vides a framework for discussing and debating the suitability of black b o x algorithms that can accommo date b oth technical and non-technical individuals, without relying on the translation or in terpretation of technical matters for non- tec hnical individuals (see sections 4 and 6 ). 3. The framew ork pro vides guidance for easily generating p ow erful, nov el critiques of deplo ying black b o x algorithms in particular situations (see, for instance, subsection 7.1 for an example in the context of recidivism algorithms). 4. The framework aids users in identifying wa ys that they can b etter mo dify and design their approach to a particular problem of interest so that blac k box algorithms can b e used in targeted wa ys (see subsection 5.5 ). In the next section w e describ e the common task framework (CTF), whic h is the in tellectual-engine that has driv en muc h of the inno v ation in machine learning. Through a careful assessmen t of the CTF, we iden tify a nov el form of reasoning utilized in the develop- men t of machine learning algorithms, which we call “outcome reasoning.” W e argue that, instead of debating ab out the appropriateness of deploying “mac hine learning” or “blac k b o x algorithms” in differen t scenarios, we should consider the suitabilit y of outcome reason- ing for the particular situation. The rest of the pap er in tro duces MARA(s), a framework that offers guidance for ho w to assess the fitness of outcome reasoning for a problem at hand, and improv e this form of reasoning to supp ort algorithms during deploymen t in the real world. 2 When black box algorithms are (not) appropria te 2. Bac kground: the Common T ask F ramew ork Belo w we give a short introduction to the intellectual-engine that has driven m uch of the recen t inno v ation in machine learning, and the one that has consequences on ho w algorithms are deploy ed. The framework offered in this pap er is motiv ated by a careful study of the prop erties of the common task framework. The Common T ask F ramework (CTF) ( Lib erman , 2010 ; Donoho , 2017 ; Breiman , 2001 ) pro vides a fast, lo w-barriers-to-en try means for researchers to settle debates ab out the rela- tiv e utility of comp eting algorithms. This is in con trast to the traditional use of mathemat- ical descriptions of the b eha vior of an algorithm, or simulations of the algorithm’s ability to reco v er parameters of a data generating function. Man y readers are likely familiar with the CTF ev en if the name is unfamiliar; the NetFlix Prize ( Bennett et al. , 2007 ) and Kaggle comp etitions are excellent examples of this framework. The key features of the CTF are: (a) curated data that hav e been placed in a rep ository; (b) static data (all analysts ha ve access to the same data); (c) a w ell defined task (e.g., predict y giv en a v ector of inputs x for previously unobserved units of observ ation); (d) consensus on the ev aluation metric (e.g., the mean squared error of the predictions from the algorithm on a set of observ ations); and (e) an ev aluation data set with observ ations which ha ve not b een accessible to the analysts. T o da y , in practice, some of the features of the CTF are relaxed. In particular, outside of the ma jor comp etitions, feature “e” is often self-p oliced - i.e., the analyst has direct access to the ev aluation data set. When p erformed correctly , the CTF giv es us a wa y of justifying a claim that “Algorithm A p erforms b etter than Algorithm B on these data sets.” More than just a form of justification, the CTF pro vides an efficient environmen t for dev elopmen t. The data exist already . All analysts hav e access to these common data so many p eople can w ork on the problem at the same time. F ast computation tak es the place of proving theorems, and p erformance is quickly assessed using held-out data. The consequences of a p o orly p erforming prediction algorithm in the CTF are minimal — e.g., after a failure the analyst tw eaks the algorithm and tries again. F undamen tally , the CTF tak es complex real-w orld problems and sand-b o xes them. In the CTF, b ecause there is a sp ecific p erformance metric, there is less ambiguit y in the relative ordering of the algorithms conditional on a particular dataset. The order- ing gives rise to a ranking of the algorithms, and the public display of these rankings are called ‘leader b oards.” Leader b oards are cited as using comp etition to motiv ate analysts to reac h high lev els of p erformance ( Mey er et al. , 2011 ; Costello and Stolovitzky , 2013 ; Boutros et al. , 2014 ). The underlying logic of using leader b oards is new and pro duc- tiv e. The CTF/leader boards are the most prominen t example of the form of reasoning w e call “outcome-reasoning.” Giv en the features describ ed in the previous tw o paragraphs, outcome reasoning – if appropriate – is preferred. How ever, man y people are deploying blac k-b o x algorithms, which rely on outcome-reasoning, in problem settings when outcome- reasoning is una v ailable. In these problem settings, “mo del-reasoning” should b e used). Man y curren t debates in the literatures about the suitability of blac k b o x mo dels hinge on (mis)understandings about what kind of reasoning is appropriate for giv en problems (the con trast b et w een forms of reasoning is discussed in detail in 6.1 . One side frames the challenges in terms that are sp ecified by mo del-reasoning; the other side resp onds with adaptations to the CTF which do not map on to the p oints that are most con ten tion in tradi- 3 R odu and Baiocchi tional mo del-reasoning (e.g., there is no need for a “data generating function” in outcome- reasoning). W e susp ect that those most familiar with mo del-reasoning may feel b etter prepared to discuss and critique algorithms generated using outcome-reasoning if its key features are b etter describ ed. The goal of this pap er is not to resolve these debates b etw een the tw o camps but to provide a useful framew ork for understanding the t yp e of problem amendable to outcome-reasoning. 3. Thinking in T erms of “Outcome-Reasoning” Instead of “Blac k Bo x Algorithms” In this section w e ha v e a more detailed discussion of what we mean by “blac k b o x” algo- rithms. W e also p oin t out how p eople are convincing themselves that blac k b o x algorithms “are working.” The classification laid out in Burrell ( 2016 ) is quite useful for discussing ho w an algorithm b ecomes opaque: [Type 1:] opacit y as inten tional corporate or state secrecy , [T yp e 2:] opacit y as technical illiteracy , and [T yp e 3:] an opacit y that arises from the characteristics of machine learning algorithms and the scale required to apply them usefully . The ro ot- causes of the opacity are in teresting, and hav e implications for how to remov e the opacity . Imp ortan t research fo cuses on how to reduce the opacit y of the algorithms without losing the strengths offered b y these algorithms. Instead of fo cusing on the causes of the opacity , w e fo cus on how one go es ab out convincing others that the blac k b ox algorithm is suitable for deploymen t. F or the sake of argumen t, consider an algorithm that satisfies all three definitions of black b o xes as offered by Burrell. T aking this as our example, what do we mean when w e say this algorithm “works well”? F ew understand ho w this complex algorithm is implemented, and none argue the b eha vior of the algorithm is well-understoo d. So describing how it links v ariation in the input space to v ariation in the outcome space is n ot an option; we cannot use mo del-reasoning. It app ears that outcome-reasoning is the dominant wa y to reason ab out the p erformance of this kind of algorithm. P eople b elieve this complex algorithm w orks not b ecause they b elieve the algorithm should w ork for some problem b ecause of ho w the algorithm functions, but rather b ecause p eople hav e observed these algorithms w orking – in a CTF-sense – b y out p erforming other algorithms on predictions tasks. If these algorithms are not justified b y outcome-reasoning then what argumen t, based on data, is used to justify these algorithms? While there are three distinct causes of black b oxes, recognize that regardless of type w e justify a blac k b ox b y using outcome-reasoning. While the CTF w as first developed to address the dev elopmen t of Type 3 black boxes, the logic of outcome-reasoning has been co- opted to justify the other types of blac k b o xes. With outcome-reasoning, organizations can try to convince stakeholders to use their algorithm while withholding details of how their T yp e 1 blac k b o x works. Without outcome-reasoning it is p ossible few er T yp e 1 blac k b o xes w ould b e deplo yed, b ecause it w ould b e harder for corporations and state actors to con vince stak eholders to accept t he algorithm’s utilit y without allowing a deep er interrogation of their algorithm (i.e., blo c king any c hance for mo del-reasoning). It is interesting to think ab out ho w outcome-reasoning has facilitated the proliferation of T yp e 2 blac k b oxes – e.g., b y 4 When black box algorithms are (not) appropria te lo w ering the barriers to assessing an algorithm and therefore lulling more stakeholders in to feeling comfortable deploying these algorithms. Outcome-reasoning do es not require as detailed engagement with the b eha vior of an algorithm, so more p eople can reason ab out the relativ e p erformance of algorithms than if they were required to use mo del-reasoning. It is possible that the simplicity of outcome- reasoning has led to ov erconfidence from non-technical stak eholders as outcome-reasoning feels more accessible than mo del-reasoning. The w ork on algorithmic fairness has help ed dra w attention to the imp ortance, and subtlety that data set selection and p erformance metric sele ction play in outcome-reasoning. 4. In tro duction to MARA(s) In this section we in tro duce a framew ork, deriv ed from the CTF, for ev aluating if a pre- diction problem is suitable for using outcome-reasoning. Here we describ e the MARA(s) framew ork in the simplest p ossible w ay so that we can quic kly in tro duce some basic, instruc- tiv e examples that will help the reader understand outcome reasoning and the MARA(s) framew ork (see 5 ). W e then return to a more detailed description of the MARA(s) frame- w ork that b enefits from exp osure to the simple examples (see 6.2 ). In an y interesting prediction problem, errors will o ccur. Outcome reasoning encourages a differen t view of ho w errors in prediction can and should be used to impro ve the algorithm. This view of ho w errors can b e used is often off-putting to data scientists who largely use mo del-reasoning to assess algorithms. That unease is b ecause outcome-reasoning targets differ ent kinds of pr e diction pr oblems than mo del-reasoning. In mo del-reasoning, the data analyst w orks with stakeholders to prop ose a mo del that maps to what is kno wn ab out the prediction problem and then the mo del is fit. In a simplified telling of ho w mo del-reasoning w orks: if (i) the errors pro duced b y the mo del matc h the mo delling assumptions and (ii) the parameters implied by the fit of the mo del are not too div ergent from what w e believe ab out the problem then we are comfortable deplo ying the mo del in to the real world. Note that we hav e t wo chec ks b efore deplo yment: [tec hnical] are mo deling assumptions violated? and [b elief-based] is the mo del fit compatible with what b eliev e to b e true. By examining these tw o asp ects of the mo del fit, w e can get buy-in from stak eholders b efore deploying the algorithm in to the real w orld. Thus when the mo del starts to accumulate errors in the real-world we ha ve already ac hieved some lev el of buy-in. But in outcome-reasoning w e do not ha v e these c hec ks, so w e need a differen t w ay of getting buy-in from stakeholders b efore deploying. In this section we prop ose a framework for getting this buy-in that we call MARA(s). W e classify problems using four features (“problem-features”), which we refer to collec- tiv ely with the mnemonic “MARA”: 1. [measuremen t] ability to measure a function of individual predictions and actual outcomes on future data, 2. [adaptabilit y] ability to adapt the algorithm on a useful timescale, 3. [resilience] tolerance for accumulated error in predictions, and 4. [agnosis] tolerance for p otential incompatibility with stakeholder b eliefs. 5 R odu and Baiocchi Primary stakeholders classify their problem as either “satisfying” or “not satisfying” eac h problem-feature individually . In some settings it may b e more appropriate to relax the binary classification, which is discussed in detail the “mo ving from binary features to con tin uous features” subsection. If a problem satisfies the MARA problem-features then the problem is suitable for outcome-reasoning. If the problem fails to satisfy ev en one of the features then the problem requires a more complex form of reasoning to justify the algorithm’s deplo ymen t – i.e., mo del-reasoning (discussed in detail in the “mo del- and outcome-reasoning” subsection). W e arrive at MARA(s) by examining the features of the CTF and mo difying those features to b e appropriate to “live” problems, pro viding a principled foundation for assessing the generalizability and transp ortability of an algorithm in to the real-world. That is, if an algorithm was dev elop ed using the CTF then MARA(s) pro vides a wa y of identifying real- w orld prediction problems that resem ble a CTF setting. MARA(s) provides language to clarify a problem’s features and facilitate debate among stakeholders ab out the suitability of using outcome-reasoning to ev aluate the p erformance of an algorithm. W e also emphasize that MARA(s) explicitly starts with the stak eholders. Starting with stak eholders has t wo ma jor implications: (a) the fo cus of this assessment is based on understanding the problem itself rather than the algorithm, and (b) a different set of stak eholders can yield a very different conclusion ab out the appropriateness of a black b o x algorithm (see the recidivism example b elo w for ho w this works). This emphasis on stak eholders has more in common with mo del-reasoning –where one of the first s teps is to “describ e a mo del”– and less with Leo Breiman’s take on algorithmic culture– that data analysts concede the complexit y of the data generating function and instead think about the prop erties of the algorithm Breiman ( 2001 ). Breiman’s line of thinking has led to excising stak eholders (e.g., exp erts, laypeople) from the pro cess, and an increased emphasis on the tec hnical asp ects of the algorithm and its p erformance. W e flag an imp ortan t issue here: there can b e deep ethical concerns ab out how stake- holders are included and excluded. W e do not engage these concerns in this pap er, but w e do wan t to emphasize that we offer a language for critique: (i) “I should ha ve b een a stak eholder when the problem w as b eing defined.” (ii) “If I had b een a stakeholder then I w ould ha v e argued that this problem fails b oth adaptabilit y and agnosis.” It is an imp or- tan t feature of the MARA(s) framework to provide language that can express that different sets of stak eholders – e.g., s 1 and s 2 – will ha ve differen t assessments of satisfying the MARA: M ARA ( s 1 ) 6 = M AR A ( s 2 ). A different theory is needed to think ab out ho w w e should go ab out including and excluding stakeholders. W e provide further discussion ab out stak eholders in the supplemen tary material. This framew ork implies a w orkflow (see Fig 1 ) in which primary stak eholders first engage a prediction problem through MARA(s). This o ccurs prior to any technical considerations (e.g., using cross v alidation to assess the fit of the algorithm). Only after classification under MARA(s), analysts can iden tify suitable algorithms that adhere to the prop er form of algorithmic reasoning, and can assess the p otential algorithms for their technical merits. Finally the analyst can deploy the algorithm with prop er re-assessment, dep ending again on the class of reasoning chosen through MARA(s). 6 When black box algorithms are (not) appropria te Figure 1: W orkflow 5. Simple examples of each part of MARA In this section we discuss several common prediction problems. Each example was cho- sen to highlight particular aspects of MARA(s). Each of the MARA problem-features is considered, as well as how stakeholder selection impacts these considerations. The goal of this section is to pro vide easy to follo w examples of eac h problem-feature, not to pro vide a detailed w orking through of an actual prediction-problem. T o see MARA(s) used in an in-depth wa y through a real-w orld problem see section “using MARA(s) to reason ab out a recidivism algorithm.” 5.1 Canonical case: recommendation systems The goal of a recommendation system is to in tro duce users to products of in terest. T raining data for a recommendation system often is represented as a sparse matrix with individuals on the rows and pro ducts on the columns. If the i th user has engaged with the j th pro duct and rated it, the ij entry of the matrix will contain the user-pro duct rating. Other entries will b e blank. T o select algorithms, some of the kno wn entries are obscured, and the task is to predict the rating for those user-pro duct pairs. In deploymen t, algorithmic p erformance can b e measured as a function of the individual outcome of each recommendation, whic h migh t take the form of a) acceptance of recommendation with a subsequent high rating, b) acceptance with a lo w rating, c) ackno wledgement of the recommendation without taking it, or d) no ac kno wledgemen t of the recommendation. T ec hnically , only some of the predictions are v erified in the wild. When the system predicts that the user will assign a low rating to a pro duct, that pro duct will not b e recommended, and that rating might not b e verified. But the ultimate goal of the recommendation system is to pro vide go od recommendations to mak e money . Often there is a large p o ol of pro ducts, many of which could be recommended to the user with great success. The loss function, then, is asymmetric. If a pro duct is recommended to a user, it is desirable that the product will obtain a high rating. On the other hand, if a pro duct that would otherwise ha ve b een enjo y ed b y a user is not recommended, b ecause of the large p o ol of p otential pro ducts, missing this pro duct is not suc h a big deal. In general, recommendation systems satisfy the MARA problem-features, though sp ecific examples could b e constructed in which some of the problem-features might fail to b e satisfied. 7 R odu and Baiocchi 5.2 V arying stak eholders c hanges resilience and agnosis: financial trading Consider a high-frequency trading group with large reserv es and a goal of profit maximizing. In order to construct a risk-div ersified p ortfolio, one sub-goal in high frequency trading is to predict the instan taneous cov ariance b et ween sto cks. While one cannot directly assess the accuracy of the co v ariance prediction, one could use an external measure of p erformance as a direct consequence of the prediction to monitor the success of the algorithm. F or example, the group can monitor if the ongoing use of the algorithm increases the v alue of their holdings. In this setting, all four problem-features are satisfied. In contrast, a manager of family wealth ma y require an algorithm that can b e ev aluated b y the family so that they can assess whether or not the algorithm’s anticipated b eha vior matc hes their b eliefs ab out the mark et or to v erify that the trading algorithm comp orts with their ethical concerns. In this case, agnosis w ould not b e satisfied. Similarly , a family ma y not b e as resilient to losses as a large high-frequency trading group so may not satisfy the resilience requirement; that is, they don’t hav e deep enough p o ck ets to sustain financial losses as the algorithms are used and improv ed. 5.3 F ailing measuremen t: prediction in lieu of measurement An in teresting application of prediction algorithms is to use them as c heap measuremen ts in lieu of obtaining exp ensive, gold-standard lab els. Consider an automated system for triag- ing mild health symptoms. Instead of using a telephonic nurse-based system, automated prediction algorithms could b e used to offer some level of diagnosis and either recommend a patien t seeks further help or not. F rom the persp ectiv e of a health care administrator, triag- ing mild health symptoms may satisfy all four problem-features b ecause the administrator considers outcomes of many patien ts who interact with the health system. But if adminis- trators take as their goal the delivery of care to a particular patient then the problem fails measuremen t b ecause the prediction is explicitly deplo yed in lieu of an actual diagnosis. That is, the p oint of such a prediction algorithm is to skip the burden of obtaining the desired measurement. Imp ortan tly , if the patient is included as a stak eholder, then the adaptability problem- feature is also violated since this is a one-shot prediction for this patient. This is a general principle: problem-feature satisfaction depends on who is considered as a stak eholder. That is, in general, M ARA ( s i ) 6 = M ARA ( s j ). 5.4 F ailing agnosis and measuremen t: recidivism In an algorithm is used to predict recidivism, if all defendan ts with a score ab ov e a certain threshold are incarcerated then we are unable to observe the correctness of our predictions for p eople who are incarcerated. This arises from a missingness in the outcome, and will happ en in general when the prediction algorithm causes changes in the outcome. The recidivism problem also violates the resilience and agnosis problem-features. In the resilience problem-feature, the debate hinges on the stakeholders’ concerns ab out depriving rights through unnecessary incarceration, balanced against p ossible future criminal acts. F ailure to satisfy agnosis stems from tw o concerns. First, it is necessary to explain to the defendant wh y the decision to incarcerate w as made. Second, even if the algorithm w ere a fla wless 8 When black box algorithms are (not) appropria te predictor, if it did so through morally repugnant means then stakeholders would need to kno w that it is ac hieving its predictions this w a y and these means w ould need to b e debated b y stakeholders (these kinds of concerns are often referred to as “deontological” – roughly: ha ving to do with ethical considerations ab out the actions taken rather than just concerns ab out the outcomes achiev ed). 5.5 Agnosis and causality: optimizing causal predictions Supp ose we run a website that can place only one of three ads – corresp onding to one of three items for purc hase – for eac h customer who arriv es to the website. W e are unsure of whic h ad to place for a given customer. Let us consider if a blac k b ox algorithm is suitable for use in learning an optimal assignment of ads. In this setting, a useful algorithm estimates ho w muc h the probability of buying a pro duct changes if the website shows a certain ad to a particular custom er. At first pass it ma y seem b est to assign customers to the ad that will increase their probabilit y of purchase the most – but that quantit y is estimable only if the analyst knows how the probabilities of purchasing change given an ad, up to some tolerance. The prediction problem is thus to learn these probabilities and the question is whether or not this is a suitable problem for outcome reasoning. Similar to the recidivism example ab ov e, for any particular p erson we can only measure the outcome for one of the ad placements. It is p ossible, though, to target a useful function of these outcomes: the a v erage outcome after exposure to the ad placement conditional on some set of co v ariates (this is often referred to as the conditional a verage treatment effect and can often b e used to build up other p opular estimands). This can be done by ha ving the algorithm assign the ad placements in suc h a w ay that for any p erson there is some c hance of seeing each ad - i.e., 0 < p 1 , p 2 , p 3 < 1. This is ho w randomized trials obtain causal estimates. In con trast to a uniform randomized controlled trial – where the assignment to treatmen t is prop ortional to rolling a die with three equally weigh ted outcomes – in this setting we can use some more sophisticated algorithm that may b e able to obtain b etter estimates of the probabilities more efficiently . This kind of thinking has led to interesting work on contextual bandit theory , and other forms of adaptive trials. Thus, in some prediction settings with causal comp onents, measurement can b e achiev ed through in tro duction of a randomization. Y et there is something different betw een this problem and most randomized controlled trials (RCTs). R CTs take as their goal to ev aluate mechanisms for the observed c hange (for example: do es increasing temperature lead to more plankton in this nic he). The in tent in RCTs is to link v ariation in the input space with v ariation in the outcome. T raditional RCTs fail agnosis b ecause the researchers take as their goal generating information which can b e assessed for its compatibility with existing knowledge and b elief. In contrast in the setting of ad placements, the goal is to sell more pro duct and there is no inten t to understand the mec hanisms giving rise to that increase. It may not b other the website deploying the ads if the black b o x b eing used to optimize the ad placemen t do es it in a w a y that defies their b eliefs. When humans are the sub jects in RCTs, issues related to resilience are considered b y the institutional review b oard. Less obvious, but still a challenge to the agnosis problem- 9 R odu and Baiocchi feature is that an IRB may w an t to ev aluate the assignment mechanism to assess whether it is assigning study participan ts in an ethical manner. If an R CT is using a blac k b o x to assign patients then this precludes ov ersight. When the MARA problem-features are satisfied, this giv es rise to a p eculiar problem t yp e: an atheoretic randomized controlled trial with treatmen t assignment determined by a black b ox algorithm. 6. Reasoning ab out algorithms In this section we compare tw o types of reasoning used for assessing an algorithm. 6.1 Mo del- and Outcome-reasoning In algorithmic prediction, there are tw o common wa ys of using data to reason ab out the p erformance of an algorithm. The first w e discuss is mo del-reasoning, which is the more traditional form of reasoning exemplified by linear mo dels. The second form of is outcome- reasoning. Mo del-reasoning requires c hecking that the mo del conforms to curren t b eliefs. F or ex- ample consider a linear regression; we can use mo del-reasoning b y v erifying the direction of individual co efficients matc hes what is exp ected from our domain knowledge. W e can think of these c hecks as a mapping from the mo del, or “parameters” of the mo del, to the space of curren t b eliefs. In mo del-reasoning, it is therefore p ossible to h yp othesize how a particular instan tiation of a mo del, ˆ f , will p erform on future data without reference to the data used to fit the algorithm. This provides solid ground on whic h exp erts in a field can debate and discuss the fitted algorithm and its suitability for future predictions in a concise manner, with discussions stemming from b eliefs, and not p otential difficult-to-find shortcomings of the data set or algorithm. In con trast, outcome-reasoning relies very little on b eliefs, whic h primarily en ter in to consideration through choice of the p erformance metric. In MARA(s), outcome-reasoning is extended to the ongoing, out-of-sample prediction setting. If the four problem-features are satisfied then the analyst and stak eholders can monitor the p erformance metric during the deploymen t phase in order to assess whether or not their algorithm is working. The t w o t yp es of reasoning lead to tw o different kinds of thinking when comparing al- gorithms. Model-reasoning tends to in v olve discussions of parameters and the algorithm’s abilit y to faithfully recov er the parameters. That is, mo del-reasoning forces the analyst to think carefully ab out how c hanges in the co v ariates should b e link ed to v ariation in the outcome (e.g., should we predict that a taller p erson weigh ts more than a shorter p erson?). But when div ergent algorithms are compared – e.g., sa y an ARMA(p,q) is compared to a decision tree – it is quite c hallenging to translate b etw een differen t conceptualizations of how the input space is linked to the outcome space. Consequently , given the challenge of translating b et ween algorithms using mo del-reasoning, comparisons tend to b e pairwise and slow. In stark con trast, outcome-reasoning assiduously a voids any debates in the in- put space. Instead, outcome-reasoning op erates in the space of the outcome – where all candidate algorithms m ust op erate. An analogy to capture this dynamic: consider tw o economies. Mo del-reasoning is a bit like a barter-based economy; each transaction requires careful consideration of idiosyncratic features and ho w m uch the parties need each of the 10 When black box algorithms are (not) appropria te pro ducts. An economy that uses currency to store v alue allo ws a low er friction form of transactions; each pro duct’s v alue is translated into the currency and then comparisons can b e made rapidly b et ween different pro ducts. Now imagine these tw o economies and their abilit y to dev elop, innov ate, and scale. Man y , though not all, concerns ab out black b ox algorithms can b e framed as issues of extrap olation. While the CTF offers a foundation for comparing algorithms’ p erformance on curren tly av ailable data, the CTF alone do es not offer a principled foundation for reasoning ab out the future, out-of-sample p erformance of an algorithm. Without access to mo del- reasoning, the mec hanisms for reasoning through performance on future data, and not just held-out data, are limited. Suc h reasoning would require careful consideration of the in teraction b et ween prop erties of the data set and the prop erties of the algorithm. In a setting that uses a blac k b ox algorithm that requires massive training data, understanding the data itself can b e imp ossible. Ev en under a smaller data regime, the task of unpacking the data/algorithm interaction can b e difficult, if not imp ossible. Indeed one common fix when a black b ox fails is to add data to the training data set in hop es that a new fit on the new data migh t remedy the failure. The underlying cause for the failure with resp ect to the current ˆ f often remains unknown. An imp ortant distinction b etw een the tw o mo des of reasoning: model-reasoning allows for detailed debate to happ en b efore the deplo yment of the algorithm, whereas outcome- reasoning affords assessmen t purely p ost-deplo ymen t. If an algorithm “b eat out” all other con tender algorithms during a CTF/leader b oard comp etition then there is no guarantee that it w ill con tinue to p erform well on future data, b ecause the CTF/outcome-reasoning do es not provide a foundation for assessing the algorithms’ p erformance on data not cur- ren tly av ailable. Outcome-reasoning requires the algorithms to generate predictions b efore they can b e ev aluated. 6.2 The MARA framework W e now discuss the four problem-features in more detail. Collectively , w e refer to the four problem-features as MARA. 6.2.1 Pr oblem-fea ture 1: measurement The first problem-feature is the ability to measure a function of the predictions and actual outcomes on future data. Let y ∗ b e the v alue of a future outcome asso ciated with predic- tors x ∗ , and ˆ f ( x ) denote the estimated prediction function. F or some agreed-up on notion of close, this problem-feature describ es the ability to track whether ˆ f ( x ∗ ) is close to y ∗ , measured as g ( y ∗ , ˆ f ( x ∗ )), within some reasonable tolerance. This is the most foundational problem-feature for the MARA(s) framework. If this problem-feature isn’t satisfied the analyst will not b e able to verify if the algorithm is p er- forming well. The use of a black b o x mo del for a problem that do esn’t satisfy measurement requires faith. If this problem-feature is satisfied then the algorithm’s p erformance can b e monitored after deploymen t by monitoring the error function g () (notably , b oth Go ogle ( Go ogle , 2019 ) and Ub er ( Hermann et al. , 2018 ) include monitoring predictions after algo- rithm deploymen t as a critical comp onen t of their machine learning workflo ws). Without 11 R odu and Baiocchi this feedback mec hanism, assessmen t must happ en b efore deploymen t. In this case, our framew ork requires that the analyst pursue mo del-reasoning. 6.2.2 Pr oblem-fea ture 2: adapt ability Problem-feature 2 is the abilit y to adapt the algorithm on a useful timescale. In some settings, up on discov ering errors in prediction, an algorithm can b e updated quic kly and will b e presented with sufficient opp ortunity to up date. In other settings, the underlying dynamics of the p opulation of interest change at a rate such that those c hanges dominate algorithm adaptations from observ ed error. The latter situation renders predictions as one-shot extrap olations, at which p oint the observ ation of the function g () is useless. F or instance, predicting the outcome of the United States presiden tial election dep ends on measuring the ebb and flo w of priorities of the v oting p opulation. With an algorithm assessed under outcome-reasoning, the lessons learned from prediction errors in one election ma y not b e informativ e for the next election b ecause the underling priorities of the p opula- tion may hav e shifted. Another common violation of adaptabilit y is when the deplo yment of the algorithm itself changes the wa y the outcomes are generated; this phenomenon has b een describ ed many times in p olicy settings - the Lucas Critique, Go o dhart’s law, and Campb ell’s law b eing famous formulations. 6.2.3 Pr oblem-fea ture 3: resilience Problem-feature 3 describ es the stakeholders’ tolerance for accumulated error in predictions. As errors accum ulate, someone or some group will b e held accountable. Some stakeholders will see errors in prediction as so in tolerable as to bar any unjustified use of an algorithm, for example when an error in prediction ma y lead to a death or a false incarceration. On the other end, settings like recommendation algorithms ma y b e viewed as having minimal consequences to errors in prediction. Most scenarios will b e somewhere in b etw een, where the stakeholders are willing to trade off some unaccounted error in predictions against the accum ulation of v alue gained from b etter predictions. If the group deploying the algorithm has large reserves relative to the accum ulation of costs due to the accumulation of errors then the problem at hand satisfies resilience. 6.2.4 Pr oblem-fea ture 4: agnosis Problem-feature 4 describ es tolerance for incompatibilit y with stakeholder b eliefs. Stake- holders will hold beliefs ab out the pro cess being predicted. T ypically these will b e expressed as how v ariation in the input space is link ed to v ariation in the outcome, though other beliefs can also b e strongly held (e.g., the outcome is b ounded by 0 and 100). These b eliefs ma y tak e the form of prior knowledge or scientific evidence (e.g., taller p eople tend to eat more calories, so an algorithm that lo wers predictions for taller p eople ma y app ear to b e dubious). Other b eliefs may arise from moral or ethical concerns (e.g., racial information should not b e used to assign credit scores). In some cases, stakeholders’ b eliefs ma y b e quite strong and thus they ma y not agree to deploying an algorithm to p ermits violations of their b eliefs. 12 When black box algorithms are (not) appropria te The agnosis problem-feature requires b oth eliciting and clarifying the stakeholders’ b e- liefs about the problem. It also requires understanding stakeholders’ comfort with the algorithm violating their b eliefs. 6.3 Problem-feature discussion In the “examples” section we to ok great care to isolate examples so that eac h problem- feature app eared as clear and distinct as p ossible. In reality , these features interact and in practice should b e discussed collectively as MARA. W e encourage the use of “MARA(s)” to emphasize the role of the stakeholders in assessing the four problem features. Mo del-reasoning requires deductive reasoning, meaning that we understand the mathe- matical structures of the mo del well enough so that once decoupled from the data it w as fit on, stakeholders can reason ab out future b ehavior of the algorithm. Metho ds of assessing an algorithm that are inductive cannot b e used for mo del-reasoning. Inductiv e reasoning is contingen t and depends on the data in hand (e.g. recycled predictions) or on details of hypothesized, future, out-of-sample data. Metho ds of assessmen t built off of these are attempting to approximate mo del-reasoning. 6.4 Moving from binary features to contin uous features F or simplicity we ha v e presented the problem-features as binary , as if a prediction problem either satisfies a problem-feature or do es not. But in realit y that is to o restrictiv e. W e b e- liev e that in practice MARA(s) will b e implemented with contin uous features– a prediction problem might not completely satisfy , nor fail to satisfy , a problem-feature. W e leav e a full sp ecification of con tin uous MARA(s) for future work– work that w e hope will engage div erse think ers across man y disciplines. T o help lay the foundation for that work, we pro vide an example extension of MARA(s) to contin uous problem-features. A Pew Research Cen ter study ( Lam et al. , 2020 ) lo oked at part y and gender gaps in p ostings about sexual assault on F aceb o ok b y mem b ers of Congress. The researc hers needed to lab el 44 , 792 posts as either ha ving or not having conten t about sexual assault. By design, this problem fails to satisfy problem-feature 1, as the whole p oint of using an algorithm is to av oid having to measure all of the p osts. In that study , the researchers hand-lab eled ab out 500 p osts and trained a classifier using outcome-reasoning. After using the classifier on the rest of the p osts, the researc hers sp ot-c hec k ed a small handful of p osts to gauge the accuracy of the classifier on “unseen data”. Ultimately , they found that w omen p osted more than men ab out sexual assault, and that demo crats p osted more than republicans. A binary MARA(s) suggests that this w as the wrong approach b ecause of a failure of measuremen t. But to most p eople the use of outcome-reasoning feels OK here. Why? First, the mo del-reasoning approac hes av ailable to the researc hers would not hav e b een as p ow erful as the outcome-reasoning approaches. This in itself would not b e a comp elling reason to use outcome-reasoning; just because one form of reasoning is problematic do es not mak e another less problematic. It do es suggest a p otential area in which mo del-reasoning approac hes should b e improv ed. But in extreme cases (where lives– or at least significant resources– are at stake) h uman lab eling, though exp ensive, remains a comp etitive alterna- tiv e to outcome-reasoning if mo del-reasoning is not viable. 13 R odu and Baiocchi Second, the conclusions of the study , while in teresting and imp ortan t, are not surprising. Had the conclusions suggested that men (or republicans) p osted more ab out sexual assault, surely the researchers w ould hav e put considerable time into in vestigating wh y this was the case. It would hav e been a surprising result, and further in vestigation would hav e either prompted a more nuanced understanding of why p eople w ere p osting ab out sexual assault, or would ha ve exposed idiosyncrasies in the dataset that led to misclassification errors. Again, while comforting, this confirmation of our prior b eliefs is not in itself justification for using outcome-reasoning. Rather, it sho ws ho w outcome-reasoning could suggest further lines of inquiry if it do es not conform to those b eliefs. Third, while w e do learn from this study– it adds evidence to the idea that there is a gap in the imp ortance members of Congress assign the issue of sexual assault– the consequences of p otential errors are not severe. Nob ody dies if the algorithm mak es mistak es. Important resources are not diverted from those in need. W ere this a study that could, for instance, re-direct millions of dollars of funding, p oten tially causing a negative impact to p eople in need, we would not fee l as comfortable with an algorithm that lea ves the classification of 44 , 000 p osts unchec ked by human observ ers. This third point is key . Neither the relative p o wer of outcome-reasoning vs mo del- reasoning approac hes, nor the unsurprising conclusions of the study , could mitigate a severe consequence as a result of the study . The third p oint speaks to resilience. W e do care ab out the conclusions reached; this study is not simply an exercise. But failure in the algorithm either leav es us with the same impressions w e had b efore the p osts were classified (in the case that the actual conclusions of the P ew Researc h Center study were wrong) or prompts us to further inv estigation (in the case that conclusions of the Pew Researc h Center w en t against our preconceived notions). Ho w do es a contin uous MARA b etter describ e this kind of problem? A con tinuous sp ectrum of resilience implies a knob that con trols some aspect of measurement. In the case laid out here, it con trols how many posts w e verify . Because resilience to incorrect classification is high in this case, sp ot-c hec king a relatively small n um b er of p osts is rea- sonable. As the consequences grow more sev ere, and hence our resilience diminishes, more c hec king is required. In the extreme case, where w e completely fail to satisfy the resilience problem-feature, chec king all the p osts is required under outcome-reasoning 1 . There are other wa ys in whic h w e ma y fail measurement in a binary MARA(s), but can still take adv antage of outcome-reasoning in the con tinuous version. F or instance, in some cases, w e may not get to directly observe if our predictions are accurate, but can measure a proxy . If our problem implies a situation where our resilience to error is low, we might require that pro xy to b e highly correlated with a hypothetical measurement of our success of prediction. In problems where our resilience is high, we might b e OK with a pro xy that is less correlated. Here, resilience do es not toggle the num b er of outcomes we observe, as it do es in the P ew Researc h case, but rather the quality of our measuremen t. While MARA(s) do es not provide a numerical threshold for choosing (for instance) the n um b er of observed predictions, or the quality of our proxy , it provides a framework and language for debating– 1. Imp ortantly , this do es not imply that resilience is not of concern when we hav e full measurement. In the case presented here we receive all unseen observ ations as a single batch. In many cases, we may get observ ations sequen tially . By the time we hav e verified our prediction, that prediction has already been acted upon. If we cannot tolerate acting on incorrect predictions, then resilience is low. 14 When black box algorithms are (not) appropria te among both tec hnical and non-technical stakeholders– the appropriateness of both outcome- and mo del-reasoning to the problem at hand. In man y scenarios, similar to utility functions from the econometrics literature, applied researc hers w orking with stakeholders will find that a quantitativ e des cription (at least a go o d approximation) of the MARA(s) problem-features is av ailable. 7. Using MARA(s) to Reason Ab out a Recidivism Algorithm In this section, we w ork through an example and fo cus on how MARA makes reasoning ab out a prediction problem clearer. Consider an example where a particular coun ty-court w an ts to hav e a decision supp ort to ol to quan tify the p oten tial for recidivism. (Note: it is not clear to us that a decision supp ort to ol in this setting is a wise decision. But this is a scenario that has o ccurred, and it can b e framed as a prediction.) The Court announces its in terest and requests prop osals from companies to create a decision supp ort to ol. Several h undred companies bid on the con tract. Recognizing that this can b e thought of as a prediction problem, the Court pro vides a data set to the companies and then holds a contest using the Common T ask F ramew ork. The Court can thus rank the p erformance of the algorithms using their desired metric(s). The three top p erformers are kept and mov e on to a new round of consideration. The results of the competition were as follows: Company A used a fan tastically complex algorithm and out-p erformed the other algorithms in the contest. Company B, which p erformed a noticeably less successfully compared to Compan y A, used a proprietary algorithm that Compan y B b eliev es should not b e shared publicly (perhaps b ecause they are concerned ab out p eople exploiting w eakness of the algorithm). Company C, which placed third in the comp etition, uses an algorithm that is based on linear regression and they are willing to share it publicly . Because of its b est-in-comp etition p erformance (and p erhaps giv en other considerations such as sp eed and cost) the Court decides to mo ve forward with Company A. Giv en the MARA(s) framework, it should b e recognizable that the data-driven part of the selection pro cess ab o v e was based on outcome-reasoning, whic h ma y or may not b e a go o d wa y to cut down the p o ol of comp etitors according to ho w stak eholders think ab out the MARA features. MARA(s) gives language to stak eholders (particularly non-technical stak eholders) to criticize the pro cess as described ab o ve. The wa y w e’v e told the story so far, it is not clear who selected the data set used for the comp etition and selected the prediction task(s) and performance metric. Ev en in using outcome-reasoning, there are imp ortant roles for the stakeholders. It is likely that if the stak eholders are (i) judges, prosecutors, p oliticians, and la w enforcemen t officers then they will ha ve differen t priorities than a group of stak eholders that includes (ii) public defenders, victims’ families, and prisoner advocates. Again, even within an outcome reasoning situation there are vital roles for the stak eholders. P oten tial stak eholders can offer more fundamental critiques of the pro cess outlined ab o v e; they can reject outcome reasoning. While the contest demonstrated the ordering on the data in existence, the real question for the stak eholders is to reason ab out deplo ying the algorithm in future, unseen data. In order to pro ceed the stakeholders need to ha ve a discussion of how they , as a group, b elieve the prediction problem they are in terested in satisfies the MARA conditions. Given the sensitivities around depriving citizens of their 15 R odu and Baiocchi righ ts, it is lik ely that both resiliency and agnosis are not satisfied for stak eholders lik e public defenders and prisoner advocates. Additionally , when an individual is incarcerated, it is not p ossible to assess the v alidit y of the algorithm’s prediction based on their outcome, so for any one incarcerated there is no measurement av ailable. Without recourse to MARA(s), giv en the relative prow ess of the companies’ prediction algorithms, it may feel hard for stakeholders to articulate their concerns and, further, to iden tify that outcome-reasoning should not be sufficien t to con vince them given the concerns they hav e with the prediction problem. F urther, MARA(s) allows certain types of criticism to b e clearer: (i) Company A’s Type 3 black b ox is concerning b ecause the stak eholders ha v e strong b eliefs suc h as deonotological concerns that no one can reason ab out. It is lik ely Company A needs to b e disqualified. (ii) Company B’s Type 1 black b ox may allo w p eople within the company to reason ab out future functioning of the algorithm (if it is an algorithm that they can model-reason ab out) but the reasoning is not being done by the stak eholders and an y assertions from Company B that the algorithm is consisten t with the stak eholder beliefs requires a lev el of trust and p ossible v erification (i.e., social-psychological argumen ts). It needs to b e clear that Compan y B has not ”successfully” articulated a data- driv en argument that can con vince stakeholders to the same level as Company C. Comp eting successfully in a CTF even t do es not warran t deploymen t. It is imp ortant for stakeholders to know, and hav e the language to hold others account- able for, getting buy-in pre-deploymen t. This buy-in pro cess centers on understanding if the MARA conditions are satisfied. If the MARA are not satisfied then stakeholders should request m odel-reasoning b efore deplo yment. In the next section, we provide examples of using MARA(s) to generate fundamental, no vel critiques to using black b o x algorithms for a recidivism algorithm. 7.1 Example of generating critiques Smart folks are achieving goo d critiques of recidivism algorithms, but it has taken pioneering thinking and intuition. Here we provide an example of how imp ortant critiques can be o v erlo ok ed if w e do not train p eople to be a w are of the assumptions underlying outcome reasoning. Here w e pro vide a handful of examples for how MARA(s) can b e used to generate critiques. Algorithms t ypically provide predictions of the probability of recidivism– say P ( X i ) for individual i – and are used to inform sen tencing (e.g., if P ( X i ) > C for some threshold C then the defendant will b e incarcerated). Critiques ha v e largely fo cused on the differen tial impact of these predictions on subgroups (e.g., racial groups being treated differently b y the recidivism mo del). The language in fairness fo cuses on the implied ethics of the algorithm – e.g., p erp etuating existing unethical practices of racism or sexism. Man y of these debates ha v e taken shap e around fixing the target task – e.g., creating b etter metrics to ev aluate whic h algorithms are p erforming best. The arguments built around this line of thinking are so imp ortant, and so convincing, that they make man y of us uncomfortable ab out the deplo ymen t of algorithms in the setting of predicting recidivism and their use in sentencing. These critiques may b e all that are needed to convince someone to not deploy algorithms in this setting. But they are not the only critiques a v ailable. They are not even the most dev astating, statistically sp eaking. 16 When black box algorithms are (not) appropria te Here, we re-frame the curren t debate on algorithms use to predict recidivism: b ecause the algorithms used to create the predictions are “black b o x” in some sense (see the “think- ing in terms of ’outcome-reasoning’ instead of ’black b o x reasoning”’ section for discussion) an insp ection of the algorithm cannot reveal how the algorithm will p erform. Here are four questions – derived from the MARA(s) framew ork – that are statistically problematic for black b ox algorithms in this setting: (i) After an algorithm has b een fit and deplo yed for use by a court, ho w would we know if the algorithm makes an incorrect prediction for a particular defendant with P ( X ) > C ? [Measuremen t] (ii) What happ ens if ma jor economic or p olitical dynamics shift (e.g., pandemic, ma jor recession); would the probabilities of recidivism change? How would the algorithm adapt? Could we train a new algorithm b efore the situation shifts again? [Adaptabilit y] (iii) F or someone b eing “judged” by suc h an algorithm, what are the costs of it b eing correct vs incorrect in its prediction? Are those costs reasonable to the individual b eing judged? [Resilience] (iv) In many criminal law settings, in addition to establishing the act was p erpetrated b y the defendan t there is a need to establish the defendant’s motiv ation – whic h can b e used to mo dify the punishmen t (e.g., first degree m urder compared to negligen t homicide). That is, in many legal settings, why a set of actions were taken is material. This is particularly true when there are ma jor consequences to the defendan t (e.g., depriving the defendant of rights). With this in mind, how is a blac k b o x algorithm (even one that has pro duced “fair” predictions on historical data) justified if the w a y it arriv es at its conclusions are inexplicable? Said another w ay: if a defendan t is to be deprived of their righ ts then are they o w ed more of a justification than “this algorithm predicts a high probability of recidivism”? [Agnosis] 8. Related W ork Recen tly the CTF, while con tinuing to yield huge success in algorithmic developmen t, has seen a host of criticisms. One concern ab out the CTF is that datasets can b e ov erfit ov er time ( Sculley et al. , 2018 ; Rogers , 2019 ; V an Calster et al. , 2019 ; Ghosh , 2019 ). Despite all attempts to protect against ov erfitting, idiosyncratic asp ects of a particular dataset are learned when heuristic improv ements yield improv ed predictions o v er the state of the art. Additionally , and a potential corollary of this criticism, giv en t w o sets of reference data, it is often unclear why an algorithm performs well on one dataset, but p o orly on the other. This has led some to call for more resources to be dedicated to understanding the theoretical underpinnings of the algorithms that ha v e achiev ed suc h huge success, hoping to a void a catastrophic failure in the future. There hav e b een sev eral debates on the relative merits of careful theoretical justification vs. rapid p erformance impro vemen t (see Rahimi and Rech t ( 2017 ) and rebuttal in LeCun ( 2017 ); see also Barb er ( 2019 )). W e do not enter this debate here. Ho w ev er, the substance of the debate is i mp ortan t in MARA(s). As can b e seen in ho w these algorithms respond to differen t datasets, their p erformance is a complex in teraction of the data, which can often b e quite large, and difficult-to-uncov er asp ects of the algorithms. While some in the aforementioned debates call for more theoretical understanding of these algorithms ahead of rapid innov ation, we take a different tack and ask when we can deploy 17 R odu and Baiocchi a blac k b o x algorithm through outcome-reasoning to mak e predictions in the wild. F or an algorithm whose future p erformance is justified using a measurement of the algorithm’s success in the space of the outcome, as is done in the CTF, this framew ork recognizes an extension to the CTF, at v ery least satisfying the measuremen t problem-feature. In problems that do not satisfy the measurement problem-feature, the algorithm is b eing used to extrap olate without apr iori justification, and w e ha v e no wa y of measuring – or p erhaps ev en b eing a ware of – failures. By construction, such extrap olation do es not exist in the static version of the CTF. This pap er also relates to debates in ethical machine learning through b oth the agnosis problem feature, as well as through stak eholder inclusion. This literature is new, rapidly expanding, and impactful; w e suggest in terested readers consult the following as solid entry p oin ts: Mittelstadt et al. ( 2016 ); Corb ett-Davies and Go el ( 2018 ); Lum and Isaac ( 2016 ); Kusner et al. ( 2017 ); Nabi and Shpitser ( 2018 ); Wiens et al. ( 2019 ). W e use the MARA(s) framew ork in the “examples” section to demonstrate how this framew ork can b e used to clarify concerns of this nature – see the examples on recidivism and prediction in lieu of measuremen t. In the public literature, most discussion of the CTF has been undertaken b y David Donoho ( Donoho , 2017 , 2019 ). (Note: it app ears that m uc h of the developmen t of the CTF happ ened outside of the public-facing, academic literature. See our correspondence with Mark Lib erman in the supplemen tary files) Of particular interest, Donoho develops the notion of hypothetical reasoning in Donoho ( 2019 ), exploring how analysts hav e developed “mo dels” – formalizations of their b eliefs in to statemen ts of probabilit y mo dels – to “... gen uinely allow us to go far b eyond the surface app earance of data and, b y so doing, augmen t our intelligence.” Using language dev elop ed for MARA(s) we might sa y that satisfying the agnosis problem-feature means forgoing the adv an tages Donoho iden tifies accrue b ecause of h yp othetical reasoning. That ma y b e a reasonable choice in some settings, but it should giv e pause to researc hers in terested in generating solid scien tific evidence. Along similar lines, Kitchin ( 2014 ) giv es a fascinating and early discussion of the epistemologies of the emerging big data revolution. Finally , the MARA(s) framework is related to work on explainability/in terpretability of algorithms. The conv ersations on these topics hav e b een happ ening for many years, and in sev eral distinct literatures, so understanding the foundational concerns and identifying the through lines of thinking can b e c hallenging. W e direct readers to tw o touchstone pieces in the literature as a go o d place to start: Breiman ( 2001 ) and Shmueli et al. ( 2010 ); Shmueli and Koppius ( 2011 ). Cyn thia Rudin ( Rudin , 2018 ) explores the suitability of tw o types of mo dels, explainable machine learning mo dels and interpretable mac hine learning mo dels, in the context of high risk and low risk predictions. In Rudin’s dichotom y , she w arns against using explainable mo dels in a high risk prediction due to our inability to mak e sense of the p erformance of the mo del despite the promise of explanation. Instead, for high risk scenarios, she urges the practitioners to use interpretable mo dels that can b e linked directly to domain kno wledge, and encourages researchers to put effort in to finding suitable in terpretable mo dels where none exist. In terms of our framework, Rudin is exploring the join t impact of the resilience and agnosis problem-features. W e direct the reader to Rudin’s pap er for details on why explainable machine learning mo dels are not sufficient for what we iden tify as problems that require mo del-reasoning. 18 When black box algorithms are (not) appropria te 9. Discussion The MARA(s) framew ork fo cuses on features of the prediction problem at hand, rather than the features of the algorithm. The problem itself is selected b y the stakeholders who hav e concerns that include accoun tability . Understanding ho w stak eholders see the problem is the critical first step tow ards selecting an appropriate algorithm. This framework directs attention to the four problem-features that stakeholders should assess: measurement, adaptabilit y , resilience, and agnosis (“MARA”). Once assessed, the appropriate metho d for reasoning ab out the algorithm can b e selected. In con trast to (but not in conflict with) MARA(s), there are other frameworks for decision-making ab out the suitability of an algorithm, technical in nature and useful for understanding the p erformance of different algorithms – e.g. diagnostic to ols or asymptotic p erformance – but these are helpful after the metho d of reasoning has b een selected. While MARA(s) is a statement ab out the problem and not the algorithm, it do es imply a lo ose structure to the set of p ossible algorithms. One wa y to think ab out this implied structure is that mo del-reasoning methods are decoupled from the data, allowing for de- ductiv e reasoning ab out future p erformance, while outcome-reasoning relies on contingen t, inductiv e reasoning. Man y of the curren t approaches to describing blac k-b ox algorithms are inductiv e in nature (see Rudin ( 2018 )). While these can be quite useful, they are still a qual- itativ ely differen t form of reasoning. This is a familiar distinction in the t yp e of evidence w e bring to problems, and the reader need not lo ok hard to find examples in which deductive reasoning is a required comp onen t of our decision making. The gold-standard of inductive reasoning is randomized trials, but in the most consequential settings, the result of the most solid form of inductive reasoning do es not provide sufficient justification. F or exam- ple, when approving a new drug, gov ernment agencies do not t ypically allow evidence from an atheoretical randomized trial to w arran t approv al. Instead agencies require a detailed scien tific hypothesis ab out how the drug’s mec hanism causes the outcome. The addition of deductiv e reasoning and coherence across b eliefs provides a firmer, evidence-based founda- tion. And yet, when appropriate, the use of outcome-reasoning is to b e preferred b ecause it is a p o w erful engine for pro ducing the highest qualit y predictions. Outcome-reasoning is the intellectual-engine of mo dern prediction algorithms. If the data sets are in teresting, the task is useful, and the p erformance metric describ es an ordering that matches how the algorithm will b e used then outcome-reasoning leads to an extraordinary consequence: it allows an analyst to bypass the slo w, tec hnical challenge of mathematically describing the b ehavior of the algorithm. Instead, outcome-reasoning allo ws the analyst to lo ok at the joint distribution of predicted and observ ed outcomes and then rank p erformance of algorithms by creating statistical summaries. Outcome-reasoning lev erages T ukey’s insight that ( T uk ey , 1986 ): “In a w orld in which the price of calculation con tin ues to decrease rapidly , but the price of theorem proving contin ues to hold steady or increase, elemen tary economics indicates that w e ought to spend a larger and larger fraction of our time on calculation.” The p o w er and p opularit y of the CTF has inspired extensions to prediction domains that are not traditionally inv estigated inside the framework. F or instance in Wikle et al. ( 2017 ) the authors propose an extension to spatial prediction whic h, among other additions, includes an abundance of relev ant data sets of differing characteristics on which the algo- 19 R odu and Baiocchi rithm m ust succeed, and additional metrics, lik e assessment of prediction co verage. It seems reasonable that the CTF-SP will enhance rapid innov ation of algorithms for certain types of problems, whic h is an exciting prosp ect for the spatial forecasting comm unity . Ho wev er, w e caution that, like all algorithms that are dev elop ed in the CTF, those algorithms that are not qualified to b e reasoned ab out using mo del-reasoning and should only b e used in a situation that p ermits outcome-reasoning. The MARA(s) framework provides a language to help stak eholders and analysts com- m unicate the k ey features of a problem and then guide the selection of an appropriate algorithm. This language can also b e used by algorithm dev elop ers to help iden tify areas for innov ation. F or instance, in the “examples” section w e discuss “prediction in lieu of measuremen t” and we are unaw are of effective algorithms that could b e used to provide mo del-reasoning. This provides analysts and stakeholders a wa y to identify critical gaps in the existing set of approaches. The unpredictable brittleness of black-box algorithms has pro v oked concern and in- creased scrutiny . But black-box algorithms ha ve also had extraordinary success in some settings. W e are concerned that a desire to use these p o w erful algorithms – combined with the facile strength of outcome-reasoning – has led to o v erconfidence from non-tec hnical stak eholders. In con trast, mo del-reasoning can b e more tec hnically challenging to under- stand and has put limitations on the algorithms that can be deplo yed. W e think these limitations are important to recognize. It has been hard to discuss these limitations be- cause, for an y giv en black-box algorithm, understanding why it might fail or when it migh t fail is c hallenging. In con trast, understanding which settings are appropriate for black- b o x deploymen t only requires understanding how they are dev elop ed – that is, using the Common T ask F ramework (CTF). The MARA(s) framew ork extends the CTF in to real- w orld settings, b y isolating four problem-features – measurement, adaptability , resilience, and agnosis (“MARA”) – that mark a problem as b eing more or less suitable for black-box algorithms. F urther, we suggest that the compact notation MARA(s) makes it clear how the assessmen t of the problem features is a function of the stak eholders. W e hop e MARA(s) will help the t w o cultures of statistical mo deling – and our stakeholders – comm unicate and reason ab out algorithms. 10. Ac kno wledgmen ts W e are grateful to many for helpful feedback on early versions of this work, including Angel Christin, Mark Cullen, Devin Curry , David Donoho, Jamie Doyle, Steve Go o dman, Karen Kafadar, Robert E. Kass, Johannes Lenhard, Mark Liberman, Joshua Loftus, Kristian Lum, Ben Marafino, Blake McShane, Art Owens and his lab, Cynthia Rudin, Kris Sank aran, Joao Sedo c, Dylan Small, Larry W asserman, W en Zhou, The RAND Statistics Group, The Harv ard Institute for Quantitativ e So cial Science, The Quantitativ e Collab orativ e at the Univ ersit y of Virginia, and The Human and Mac hine In telligence Group at the Universit y of Virginia. Finally , we thank the anon ymous review ers whose commen ts improv ed this pap er. 20 When black box algorithms are (not) appropria te References Gregory Barber. Artificial in telligence confron ts a ’reproducibility’ crisis. Wir e d , September 2019. James Bennett, Stan Lanning, and Others. The netflix prize. In Pr o c e e dings of KDD cup and workshop , volume 2007, page 35, 2007. P aul C Boutros, Adam A Margolin, Josh ua M Stuart, Andrea Califano, and Gusta vo Stolo vitzky . T o w ard b etter benchmarking: c hallenge-based metho ds assessment in cancer genomics. Genome biolo gy , 15(9):1–10, 2014. Leo Breiman. Statistical mo deling: The tw o cultures (with comments and a rejoinder b y the author). Stat. Sci. , 16(3):199–231, August 2001. Jenna Burrell. How the machine ‘thinks’: Understanding opacity in machine learning algo- rithms. Big Data & So ciety , 3(1):2053951715622512, 2016. Sam Corb ett-Da vies and Sharad Go el. The measure and mismeasure of fairness: A critical review of fair machine learning. arXiv pr eprint arXiv:1808.00023 , 2018. JC Costello and G Stolovitzky . Seeking the wisdom of cro wds through challenge-based comp etitions in biomedical researc h. Clinic al Pharmac olo gy & Ther ap eutics , 93(5):396– 398, 2013. Da vid Donoho. 50 years of data science. J. Comput. Gr aph. Stat. , 26(4):745–766, Octob er 2017. Da vid Donoho. Commen ts on mic hael jordan’s essa y “the ai rev olution hasn’t happ ened y et”. Harvar d Data Scienc e R eview , 1(1), 6 2019. doi: 10. 1162/99608f92.c698b3a7. URL https://hdsr.mitpress.mit.edu/pub/rim3pvdw . h ttps://hdsr.mitpress.mit.edu/pub/rim3p vdw. P allab Ghosh. Mac hine learning ’causing science crisis’. BBC , F ebruary 2019. Go ogle. Mac hine learning workflo w — AI platform — go ogle cloud. https://cloud. google.com/ml- engine/docs/ml- solutions- overview , 2019. Accessed: 2019-11-6. Jerem y Hermann, Mik e Del Balso, K ˚ are Kjelstrøm, Emily Reinhold, Andrew Beinstein, and T ed Sumers. Scaling mac hine learning at ub er with michelangelo. https://eng.uber. com/scaling- michelangelo/ , Nov ember 2018. Accessed: 2019-11-6. Rob Kitchin. Big data, new epistemologies and paradigm shifts. Big Data & So ciety , 1(1): 2053951714528481, 2014. doi: 10.1177/2053951714528481. URL https://doi.org/10. 1177/2053951714528481 . Matt J Kusner, Joshua Loftus, Chris Russell, and Ricardo Silv a. Coun terfactual fairness. In A dvanc es in Neur al Information Pr o c essing Systems , pages 4066–4076, 2017. 21 R odu and Baiocchi On yi Lam, Adam Hughes, and P atrick v an Kessel. W omen in congress address sexual misconduct on faceb ook more than men, Sep 2020. URL https://www.pewresearch.org/fact- tank/2018/02/01/ theres- a- large- gender- gap- in- congressional- facebook- posts- about- sexual- misconduct/ . Y ann LeCun. Rebuttal to “reflections on random kitc hen sinks”. https://www.facebook. com/yann.lecun/posts/10154938130592143 , 2017. Accessed: 2019-11-5. Mark Lib erman. F red jelinek. Comput. Linguist. , 36(4):595–599, December 2010. Kristian Lum and William Isaac. T o predict and serve? Signific anc e , 13(5):14–19, 2016. P ablo Meyer, Leonidas G Alexopoulos, Thomas Bonk, Andrea Califano, Carolyn R Cho, Alb erto De La F uente, Da vid De Graaf, Alexander J Hartemink, Julia Ho eng, Niko- lai V Iv ano v, et al. V erification of systems biology research in the age of collab orative comp etition. Natur e biote chnolo gy , 29(9):811–815, 2011. Bren t Daniel Mittelstadt, P atrick Allo, Mariarosaria T addeo, Sandra W ac hter, and Lu- ciano Floridi. The ethics of algorithms: Mapping the debate. Big Data & So ciety , 3(2): 2053951716679679, 2016. doi: 10.1177/2053951716679679. URL https://doi.org/10. 1177/2053951716679679 . Razieh Nabi and Ily a Shpitser. F air inference on outcomes. In Thirty-Se c ond AAAI Con- fer enc e on Artificial Intel ligenc e , 2018. Ali Rahimi and Ben Rech t. Reflections on random kitc hen sinks. http://benjamin- recht. github.io/2017/12/05/kitchen- sinks/ , 2017. Accessed: 2019-11-5. Anna Rogers. Ho w the transformers broke NLP leaderb oards. https:// hackingsemantics.xyz/2019/leaderboards/ , June 2019. Accessed: 2019-11-6. Cyn thia Rudin. Stop explaining blac k box machine learning models for high stakes decisions and use interpretable mo dels instead. arxiv , 2018. D Sculley , Jasp er Sno ek, Alex Wiltschk o, and Ali Rahimi. Winner’s curse? on pace, progress, and empirical rigor. ICLR Workshop , 2018. Galit Shmueli and Otto R Koppius. Predictiv e analytics in information systems research. MIS quarterly , pages 553–572, 2011. Galit Shmueli et al. T o explain or to predict? Statistic al scienc e , 25(3):289–310, 2010. John W T uk ey . Sunset salvo. The Americ an Statistician , 40(1):72–76, 1986. Ben V an Calster, Laure Wynants, Dirk Timmerman, Ew out W Stey erb erg, and Gary S Collins. Predictiv e analytics in health care: how can w e kno w it works? J. Am. Me d. Inform. Asso c. , August 2019. Jenna Wiens, Suchi Saria, Mark Sendak, Marzyeh Ghassemi, Vincent X Liu, Finale Doshi- V elez, Kenneth Jung, Katherine Heller, David Kale, Mohammed Saeed, Pilar N Ossorio, Sono o Thadaney-Israni, and Anna Goldenberg. Do no harm: a roadmap for resp onsible mac hine learning for health care. Nat. Me d. , 25(9):1337–1340, September 2019. 22 When black box algorithms are (not) appropria te Christopher K Wikle, No el Cressie, Andrew Zammit-Mangion, and Clint Sh umack. A com- mon task framework (ctf ) for ob jective comparison of spatial prediction metho dologies. Statistics Views , 2017. 23
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment